| Скачать .docx |
Реферат: Математические модели в менеджменте и маркетинге
КОНСПЕКТ
по дисциплине «Математические модели в менеджменте и маркетинге»
1. МЕТОДЫ МНОГОКРИТЕРИАЛЬНОЙ ОПТИМИЗАЦИИ
В реальных системах управления задачу оптимизации приходится решать с учетом нескольких критериев эффективности одновременно. В общем случае задача многокритериальной (векторной) оптимизации ставится следующим образом.
Имеется множество X различных (альтернативных) вариантов решения задачи управления. Вариант решения - это конкретное значение вектора параметров управления, то есть конкретный вариант плана производства, или вариант загрузки оборудования, или вариант стратегии управления и т.п.
Каждый вариант решения х € Х оценивается вектором критериев
![]()
Очевидно вариант Х° является строго оптимальным, если
![]()
где yiext - минимальное или максимальное значение критерия yi , в зависимости от требований оптимизации.
Однако в реальныхсистемах существование строго оптимального решения У° маловероятно, а часто и невозможно из-за противоречивости взаимосвязанных критериев. Например, при росте объемов производства растет и расход ресурсов, хотя объем надо максимизировать, а ресурсы минимизировать.
Практический интерес представляет поиск существующих вариантов, близких к оптимальному. Такими вариантами являются так называемые Парето-оптимальные варианты, составляющие множество P Ì X •
Вариант x*ÎР если значение частного критерия yi ( x *) для любого i, можно улучшить лишь за счет ухудшения других частных критериев. Другими словами, вариант X оптимален по Парето, если не найдется ни одного другого варианта X'€Х , такого, для которого
![]()
причем хотя бы для одного i выполняется
![]()
Здесь и далее предполагается, что все частные критерии надо минимизировать.
Для поиска Х ÎР используется два подхода:
- векторный критерий У преобразует (сворачивают) в обобщенный скалярный критерий Yc а затем применяют известные однокритериальныеметоды оптимизации (линейное, нелинейное, стохастическое программирование и т.п.) ;
- применяют специальные методы многокритериальной оптимизации непосредственно по векторному критерию У . .
Рассмотрим некоторые способы свертки. Наиболее простой способ - взвешенное линейное суммирование частных критериев .
где a- коэффициент важности (вес) частного критерия Yi . . Для определения значений коэффициентов применяют экспертные методы. Использовать линейную свертку суммированием нельзя, если существует нелинейная зависимость частных критериев между собой.
Если один из частных критериев намного важнее остальных, для которых известныих предельно допустимые значения bi , то оптимизация производится по наиболее важному (главному) критерию Ус=Yi а для остальных критериев устанавливаются ограничения:
![]()
Если удалось упорядочить все частные критерии по важности, но не удалось определитьих вес a и предельные значения b, то можно попытаться использовать метод последовательных уступок. В этом методе на первом шаге производится поиск X1 * , оптимального по самому важному критерию y1 . Остальные критерии при этом игнорируются. На 2-ом шаге выполняется поиск Х*2 , оптимального по критерию y2 а на ухудшение критерия y1 накладывается ограничение
![]()
где D1
![]() - уступка, характеризующая допустимое отклонение y
1
от егоминимального значения, найденного на 1-ом шаге.
- уступка, характеризующая допустимое отклонение y
1
от егоминимального значения, найденного на 1-ом шаге.
Для простоты предполагается, что все критерии надо минимизировать.
На t , - ом шаге отыскивается Xt * , для которого
![]()
Наконец, на n. -ом шаге отыскивается X *= Xn , для которого
![]()
Еще один способ свертки - выбор в качестве обобщенного скалярного критерия эвклидова расстояния анализируемого варианта X до строго оптимального (идеального) варианта Х°. Сам вариант X0 может не существовать , но таккак измерение расстояния выполняется в критериальном пространстве, то должны быть известны экстремальные значения этих критериев.
Свертка в этом случае имеет вид
![]()
Замечание I. Для оптимизации по У с, (взвешенное суммирование, эвклидово расстояние ) или для пошаговой оптимизации по частным критериям (методы главного критерия и последователь ных уступок) необходимо вычислять значения частных критериев
В сущности необходимо решать задачи прогноза и оптимизации по каждому yi и по yc для чего используются известные модели и методыоптимизации.
Замечание 2. При оптимизации по yc необходимо, чтобы критерии yi были нормализованы, то есть принимали значение в фиксированном интервале, например [0, l] и были безразмерны. Если известны верхняя yв и нижняя yн границы изменения критерия yi , то нормализованное значение yi определяетсякак
![]()
Пример, Имеется два проекта программного обеспечения автоматизированной подсистемы оперативного управления прокатным производством. Каждый вариант характеризуется следующим набором частных критериев:
y1 - затраты на разработку, руб. ;
y2 - срок разработки, год ;
y3 - время решения задач на ЭВМ, ч;
y4 - необходимое количество разработчиков, чел.;
y5 - количество высвобождаемых штатных сотрудников после внедрения системы, чел.
Определить лучший проект программного обеспечения, используя для получения обобщенного критерия оптимальности метод Эвклидовой метрики.
Исходные данные для расчета приведены в таблице.Номер варианта и характеристики частных критериев |
Частные критерии |
||||
y1 |
y2 |
y3 |
y4 |
y5 |
|
| Вариант I | 25000 | 3 | 2,5 | 10 | I |
| Вариант 2 | 30000 | 2 | 2,2 | 12 | 2 |
Вариант заказчика (идеальней yiext ) |
20000 |
3 |
2 |
10 |
2 |
| Относительный коэффициент значимости частных критериев ( a i ) | 0,4 | 0,3 | 0,1 | 0,1 | 0,1 |
Минимально допустимое значение частного критерия (yi H ) |
20000 | 2 | 2 | 10 | 1 |
Максимально допустимое значение частного критерия (yB ) |
30000 | 3 | 2,5 | 15 | 3 |
Решение задачи. Порядок решения задачи следующий:
!• Определение нормализованных значений частных критериев по формуле ,
![]()
2. Вычисление обобщенного критерия эффективности по формуле
![]()
2. МОДЕЛИ УПРАВЛЕНИЯ ЗАПАСАМИ
Возникновение теории управления запасами можно связать с работами Ф. Эджуорта и Ф. Харриса, появившимися в конце XIX — начале XX в., в которых исследовалась простая оптимизационная модель определения экономичного размера партии поставки для складской системы с постоянным равномерным расходом и периодическим поступлением хранимого продукта.
Запасами называется любой ресурс на складе, который используется для удовлетворения будущих нужд. Примерами запасов могут служить полуфабрикаты, готовые изделия, материалы, различные товары, а также такие специфические товары, как денежная наличность, находящаяся в хранилище. Большинство организаций имеют примерно один тип системы планирования и контроля запасов. В банке используются методы контроля за количеством наличности, в больнице применяются методы контроля поставки различных медицинских препаратов.
Существуют причины, побуждающие организации создавать запасы:
1) дискретность поставок при непрерывном потреблении;
2) упущенная прибыль;
3) случайные колебания;
а) в спросе за период между поставками,
б) в объеме поставок,
в) в длительности интервала между поставками;
4) предполагаемые изменения конъюнктуры:
а) сезонность спроса,
б) сезонность производства,
в) ожидаемое повышение цен.
Имеются также причины, побуждающие предприятия стремиться к минимизации запасов на складах:
1) плата за физическое хранение запаса,
2) потери в количестве запаса,
3) моральный износ продукта.
Существует проблема классификации имеющихся в наличии запасов. Для решения этой задачи используется методика административного наблюдения . Цель ее заключается в определении той части запасов предприятия, которая требует наибольшего внимания со стороны отдела снабжения. Для этого каждый компонент запасов рассматривается по двум параметрам: а) его доля в общем количестве запасов предприятия; б) его доля в общей стоимости запасов предприятия.
Методика 20/80. В соответствии с этой методикой компоненты запаса, составляющие 20% его общего количества и 80% его общей стоимости, должны отслеживаться отделом снабжения более внимательно.
Методика АВС . В рамках этой методики запасы, имеющиеся в распоряжении предприятия, разделяются на три группы: группу А (10% общего количества запасов и 65% его стоимости); группу В (25% общего количества запасов и 25% его стоимости); группу С (65% общего количества запасов и около 10% его стоимости).
Необходимо отметить, что классификация запасов может быть основана не только на показателях доли в общей стоимости и в общем количестве. Ряд их видов может быть причислен к более высокому классу на основании таких характеристик, как проблемы с поставкой, проблемы качества и т.д. Преимущества методики деления видов запасов на классы заключаются в возможности выбора порядка контроля и управления для каждого из них. Если в ходе классификации мы основывались на методе АВС анализа, имеет смысл обратить внимание на следующие моменты политики управления запасами.
1. Виды запасов класса А требуют более внимательного и частого проведения инвентаризации состояния запасов, правильность учета запасов этой группы должна подтверждаться чаще.
2. Планирование и прогнозирование, касающиеся запасов класса А, должны характеризоваться большей степенью точности, нежели относящиеся к запасам групп В и С.
3. Для категории А нужно стараться создать страховой запас, чтобы избежать больших расходов, связанных с отсутствием запасов этой группы.
4. Методы и приемы управления запасами, рассматривающиеся далее, должны прежде всего применяться к запасам групп А и В. Что касается запасов группы С, обычно момент возобновления заказа по ним определяют исходя из конкретных условий, а не на основе количественного метода, чтобы свести к минимуму расходы на их контроль.
Рассмотрим определяющие понятия теории управления запасами.
Издержки выполнения заказа (издержки заказа) — накладные расходы, связанные с реализацией заказа. В промышленности такими издержками являются затраты на подготовительно-заготовочные операции.
Издержки хранения — расходы, связанные с физическим содержанием товаров на складе, плюс возможные проценты на капитал, вложенный в запасы. Обычно они выражаются или в абсолютных единицах, или в процентах от закупочной цены и связываются с определенным промежутком времени.
Упущенная прибыль — издержки, связанные с неудовлетворенным спросом, возникающим в результате отсутствия продукта на складе.
Совокупные издержки за период представляют собой сумму издержек заказа, издержек хранения и упущенного дохода. Иногда к ним прибавляются издержки на покупку товаров.
Срок выполнения заказа — срок между заказом и его выполнением. Точка восстановления — уровень запаса, при котором делается новый заказ.
1. Краткая характеристика моделей управления запасами
1.1. Модель оптимального размера заказа.
Предпосылки: 1) темп спроса на товар известен и постоянен;
2) получение заказа мгновенно;
3) отсутствуют количественные скидки при закупке больших партий товара;
4) единственные меняющиеся параметры — издержки заказа и хранения;
5) исключается дефицит в случае своевременного заказа.
Исходные данные: темп спроса, издержки заказа и хранения.
Результат: оптимальный размер заказа, время между заказами и их количество за период.
1.2. Модель оптимального размера заказа в предположении, что получение заказа не мгновенно. Следовательно, нужно найти объем запасов, при котором необходимо делать новый заказ.
Исходные данные: темп спроса, издержки заказа и хранения, время выполнения заказа.
Результат: оптимальный размер заказа, время между заказами, точка восстановления запаса.
1.3. Модель оптимального размера заказа в предположении, что допускается дефицит продукта и связанная с ним упущенная прибыль. Необходимо найти точку восстановления.
Исходные данные: темп спроса, издержки заказа и хранения, упущенная прибыль.
Результат: оптимальный размер заказа, время между заказами, точка восстановления запаса.
1.4. Модель с учетом производства (в сочетании с условиями 1.1—1.3). Необходимо рассматривать уровень ежедневного производства и уровень ежедневного спроса.
Исходные данные: темп спроса, издержки заказа, хранения и упущенная прибыль, темп производства.
Результат: оптимальный уровень запасов (точка восстановления запаса).
1.5. Модель с количественными скидками. Появляется возможность количественных скидок в зависимости от размера заказа. Рассматривается зависимость издержек хранения от цены товара. Оптимальный уровень заказа определяется исходя из условия минимизации общих издержек для каждого вида скидок.
2. Модели типа 1.1—1.5 с вероятностным распределением спроса и времени выполнения заказа
Вместо предпосылки о постоянстве и детерминированности спроса на товар используется более реалистичный подход о предполагаемой известности распределения темпа спроса и времени выполнения заказа.
Рассмотрим подробнее модели с фиксированным размером заказа. Модели с вероятностным распределением спроса и времени выполнения заказа рассмотрены в следующем разделе, где они решаются на основе имитационного подхода.
Модель 1.1 наиболее экономичного размера заказа. Заказ, пополняющий запасы, поступает как одна партия. Уровень запасов убывает с постоянной интенсивностью пока не достигает нуля. В этой точке поступает заказ, размер которого равен Q, и уровень запасов восстанавливается до максимального значения. При этом оптимальным решением задачи будет тот размер заказа, при котором минимизируются общие издержки за период (рис. 11.1).
Пусть Q — размер заказа; Т — протяженность периода планирования; D — величина спроса за период планирования; d — величина спроса в единицу времени; К — издержки заказа; Н — удельные издержки хранения за период; h — удельные издержки хранения в единицу времени.
Тогда:
(D/Q)K — совокупные издержки заказа;
Модель 1.3 оптимального размера заказа в предположении, что допускается дефицит продукта и связанная с ним упущенная прибыль (рис. 11.3).
Пусть р — упущенная прибыль в единицу времени, возникающая в результате дефицита одной единицы продукта;
Р — упущенная прибыль за период, возникающая в результате дефицита одной единицы продукта. Тогда:
Q* =( 2dK/h)l/2 х ((Р+hVp)1/2 =
=( 2DK/H)1/2 х ((Р+Н)/P)1/2 — оптимальный размер заказа;
S* =( 2dK/h)1/2 x (p/(h+p))1/2 =
=(2DK/H)1/2 х (Р/(H+Р))1/2 — максимальный размер запаса;
R = Q*— S* — максимальный дефицит.
Модель 1.4 производства и распределения. В предыдущей модели мы допускали, что пополнение запаса происходит единовременно. Но в некоторых случаях, особенно в промышленном производстве, для комплектования партии товаров требуется значительное время и производство товаров для пополнения запасов происходит одновременно с удовлетворением спроса. Такой случай показан на рис. 11.4.
Спрос и производство являются частью цикла восстановления запасов. Пусть u — уровень производства в единицу времени, К — фиксированные издержки производства.
Тогда:
совокупные издержки хранения = (средний уровень запасов) х Н = Q/2[l-d/u] Н;
средний уровень запасов = (максимальный уровень запасов)/2;
максимальный уровень запасов = u t — d t = Q(l—d/u);
время выполнения заказа t = Q/u; издержки заказа == (D/Q) К;
оптимальный размер заказа Q* =(2dK/h [(l-(d/u)])1/2 = (2DK/H [(l-(d/u)])1/2 ;
максимальный уровень запасов S* = Q*((l—(d/u))).
Модель 1.5 с количественными скидками. Для увеличения объема продаж компании часто предлагают количественные скидки своим покупателям. Количественная скидка — сокращенная цена на товар в случае покупки большого количества этого товара. Типичные примеры количественных скидок приведены в табл. 11.1.
Пусть I — доля издержек хранения в цене продукта с. Тогда h = (Ixc) и Q* =( 2dK/(Ixc))l/2 — оптимальный размер заказа.
Пример 2. Рассмотрим пример, объясняющий принцип принятия решения в условиях скидки. Магазин "Медвежонок" продает игрушечные гоночные машинки. Эта фирма имеет таблицу скидок на машинки в случае покупок их в определенном количестве (табл. 11.1). Издержки заказа составляют 49 тыс .р. Годовой спрос на машинки равен 5000. Годовые издержки хранения в отношении к цене составляют 20%, или 0,2. Необходимо найти размер заказа, минимизирующий общие издержки.
Решение.
Рассчитаем оптимальный размер заказа для каждого вида скидок, т.е. Ql*, Q2* и Q3*, и получим Q1* = 700; Q2* = 714;Q3* = 718.
Так как Ql* — величина между 0 и 999, то ее можно оставить прежней. Q2* меньше количества, необходимого для получения скидки, следовательно, его значение необходимо принять равным 1000 единиц. Аналогично Q3* берем равным 2000 единиц. Получим Ql* = 700; Q2* = 1000; Q3* = 2000.
Далее необходимо рассчитать общие издержки для каждого размера заказа и вида скидок, а затем выбрать наименьшее значение.
Рассмотрим следующую таблицу.
Выберем тот размер заказа, который минимизирует общие годовые, издержки. Из таблицы видно, что заказ в размере 1000 игрушечных гоночных машинок будет минимизировать совокупные издержки.
3. ИМИТАЦИОННЫЕ МОДЕЛИ МАССОВОГО ОБСЛУЖИВАНИЯ
Имитация — это попытка дублировать особенности, внешний вид и характеристики реальной системы. Идея имитации состоит в:
1) математическом описании реальной ситуации,
2) изучении ее свойств и особенностей,
3)формировании выводов и принятии решений, связанных с воздействием на эту ситуацию и основанных на результатах имитации. Причем реальная система не подвергается воздействиям до тех пор, пока преимущества или недостатки тех или иных управленческих решений не будут оценены с помощью модели этой системы.
Метод Монте-Карло. Имитация с помощью метода Монте-Карло состоит из пяти простых этапов:
1. Установление распределения вероятностей для существенных переменных.
2. Построение интегрального распределения вероятности для всех переменных.
3. Установление интервала случайных чисел для каждой переменной.
4. Генерация случайных чисел.
5. Имитация путем многих попыток.
Проимитируем спрос на автомашины в салоне ЛОГОВАЗ в течение 10 последовательных дней. Для этого из таблицы случайных чисел мы выбираем значения, начиная из верхнего левого угла и двигаясь вниз в первом столбце.
39 — спрос за 10 дней. 39/10 = 3,9 — средний ежедневный спрос.
Пример 2. Груженые баржи, отправляемые вниз по Волге из индустриальных центров, достигают Астрахани. Число барж, ежедневно входящих в док, колеблется от 0 до 5. Вероятность прихода 0,1,...,5 барж показана в таблице. В этой же таблице указаны интегральные вероятности и соответствующие интервалы случайных чисел для каждого возможного значения.
Аналогичная информация дана о числе разгружаемых барж.
Имитация очереди на разгрузку барж в порту Астрахани представлена в следующей таблице.
4. ИМИТАЦИОННЫЕ МОДЕЛИ УПРАВЛЕНИЯ ЗАПАСАМИ
Магазин электрооборудования Проводкова продает электрические дрели. В течение 300 дней Проводкой регистрировал дневной спрос на дрели. Распределение вероятностей величины спроса показано в таблице. Интегральные вероятности величин спроса показаны в четвертом столбце табл. В пятом столбце определены интервалы случайных чисел для определения возможных значений спроса.
Когда Проводков делает заказ, чтобы возобновить свои запасы электрических дрелей, его выполнение происходит с лагом в 1, 2 или 3 дня. Это означает, что время восстановления запаса подчиняется вероятностному распределению. В табл. показаны данные, позволяющие определить вероятности сроков выполнения заказов и интервалы случайных чисел на основе информации о 50 заказах.
Первая стратегия резервирования, которую хочет имитировать Проводков, — делать заказ в объеме 10 дрелей при запасе на складе 5 штук.
Реализуется четырехшаговый процесс имитации.
1. Каждый имитируемый день начинается с проверки, поступил ли сделанный заказ. Если заказ выполнен, то текущий запас увеличивается на величину заказа (в данном случае — на 10 единиц).
2. Путем выбора случайного числа генерируется дневной спрос для соответствующего распределения вероятностей.
3. Рассчитывается итоговый запас, равный исходному запасу за вычетом величины спроса. Если запас недостаточен для удовлетворения дневного спроса, спрос удовлетворяется, насколько это возможно. Фиксируется число нереализованных продаж.
4. Определяется, снизился ли запас до точки восстановления (в примере — 5 единиц). Если да, причем не ожидается поступления заказа, сделанного ранее, то делается заказ.
Первый эксперимент Проводкова. Объем заказа — 10 штук, точка восстановления запаса — 5 штук.
среднее число упущенных продаж = 2 упущенные продажи / 10 дней =0,2 шт./день.
Второй эксперимент Проводкова. Проводков оценил, что каждый заказ на дрели обходится ему в 10 000 р., хранение каждой дрели — в 5000 в день, одна упущенная продажа — в 80 000 р. Этой информации достаточно, чтобы оценить средние ежедневные затраты для этой стратегии управления запасами. Определим три составляющие затрат:
ежедневные затраты на заказы = (затраты на один заказ) х (среднее число заказов в день) = 10000 х 0,3 = 3000;
ежедневные затраты на хранение = (затраты на хранение одной единицы в течение дня) х (средняя величина конечного запаса) = 5000 х 4,1 = 20500;
ежедневные упущенные возможности = (прибыль от упущенной продажи) х (среднее число упущенных продаж в день) = 80000 х 0,2 = 16000,
общие ежедневные затраты = затраты на заказы + затраты на хранение + упущенные продажи = 39500.
5. ПРОИЗВОДСТВЕННЫЕ ФУНКЦИИ
1. Основные понятия
Производственная функция - это функция, независимая переменная которой принимает значения объемов затрачиваемого или используемого ресурса (фактора производства), а зависимая переменная - значения объемов выпускаемой продукции
![]()
Точное толкование понятий затрачиваемого (или используемого) ресурса и выпускаемой продукции, а также выбор единиц их измерения зависят от характера и масштаба производственной системы, особенностей решаемых (с помощью ПФ) задач (аналитических, плановых, прогнозных), наличия исходных данных.
На микроэкономическом уровне затраты и выпуск могут измеряться как в натуральных, так и в стоимостных единицах (показателях). Годовые затраты труда могут быть измерены в человеко-часах (объем человеко-часов - натуральный показатель) или в рублях выплаченной заработной платы (ее величина - стоимостный показатель); выпуск продукции может быть представлен в штуках или в других натуральных единицах (тоннах, метрах и т.п.) или в виде своей стоимости.
На макроэкономическом уровне затраты и выпуск измеряются, как правило, в стоимостных показателях и представляют собой стоимостные (ценностные) агрегаты, т.е. суммарные величины произведений объемов затрачиваемых (или используемых) ресурсов и выпускаемых продуктов на их цены.
Производственная функция нескольких переменных - это функция, независимые переменные которой принимают значения объемов затрачиваемых или используемых ресурсов (число переменных л равно числу ресурсов), а значение функции имеет смысл величин объемов выпуска:
![]()
При построении ПФ для региона или страны в целом в качестве величины годового выпуска Y (будем обозначать объем выпуска, или дохода, на макроуровне большой буквой) чаще берут совокупный продукт (доход) региона или страны, исчисляемый обычно в неизменных, а не в текущих ценах, в качестве ресурсов рассматривают основной капитал (х1 (=К) - объем используемого в течение года основного капитала), живой труд (х2 (=L) - количество единиц затрачиваемого в течение года живого труда), исчисляемые обычно в стоимостном выражении. Таким образом строят двухфакторную f(х1 , х2 ), или Y = f { K , L ). От двухфакторных ПФ переходят к трехфакторным. В качестве третьего фактора иногда вводят объемы используемых природных ресурсов. Кроме того, если ПФ строится по данным временных рядов, то в качестве особого фактора роста производства может быть включен технический прогресс.
ПФ у =f(х1 , х2 ) называется статической, если ее параметры и ее характеристика f не зависят от времени t , хотя объемы ресурсов и объем выпуска могут зависеть от времени t, т.е. могут иметь представление в виде временных рядов.
Пример . Для моделирования отдельного региона или страны в целом (т.е. для решения задач на макроэкономическом, а также и на микроэкономическом уровне) часто используется ПФ вида у = a 0 x 1 a 1 x 2 a 2 , где а0, а1 , а2 - параметры ПФ. Это положительные постоянные (часто а1 + а2 = 1). ПФ только что приведенного вида называется ПФ Кобба-Дугласа (ПФКД) по имени двух американских экономистов, предложивших ее использовать в 1929 г. ПФКД активно применяется для решения разнообразных теоретических и прикладных задач благодаря своей структурной простоте. ПФКД принадлежит к классу так называемых мультипликативных ПФ (МПФ). В приложениях ПФКД х1 = K равно объему используемого основного капитала (объему используемых основных фондов - в отечественной терминологии), x 2 = L - затратам живого труда, тогда ПФКД приобретает вид, часто используемый в литературе:
![]()
Пример . Линейная ПФ (ЛПФ) имеет вид: у= а0 + а1 х1 + a 2 x 2 . (двухфакторная) и у= а0 + а1 х1 + a 2 x 2+ …+ an xn (многофакторная). ЛПФ принадлежит к классу так называемых аддитивных ПФ (АПФ). Переход от мультипликативной ПФ к аддитивной осуществляется с помощью операции логарифмирования. Для двухфакторной мультипликативной ПФ
Выполняя обратный переход, из аддитивной ПФ получим мультипликативную ПФ.
Если а1 + а2 = 1, то ее можно записать в несколько другой форме:
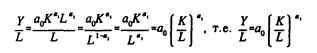
![]()
называются соответственно производителностью труда и капиталовооруженностью труда. Используя новые символы, получим
![]()
т.е. из двухфакторной ПФКД получим формально однофакторную ПФКД. В связи с тем, что 0 < a1 < 1, из последней формулы следует, что производительность труда растет медленнее его капиталовооруженности. Однако этот вывод справедлив для случая статической ПФКД в рамках существующих технологии и ресурсов.
Отметим здесь, что дробь Y / K — называется производительностью капитала или капиталоотдачей, обратные дроби K / Y и L / Y называются соответственно капиталоемкостью и трудоемкостью выпуска.
ПФ называется динамической, если:
1) время t фигурирует в качестве самостоятельной переменной величины (как бы самостоятельного фактора производства), влияющего на объем выпускаемой продукции;
2) параметры ПФ и ее характеристика f зависят от времени t.
Отметим, что если параметры ПФ оценивались по данным врменных рядов (объемов ресурсов и выпуска) продолжительностью T0 лет (т.е. базовый промежуток для оценки параметров имеет продолжительность T0 лет), то экстраполяционные расчеты по такой ПФ
следует проводить не более чем на T0 / 3 лет вперед (т.е. промежуток экстраполяции должен иметь продолжительность не более чем T0 /3 лет).
При построении ПФ научно-технический прогресс (НТП) может быть учтен с помощью введения множителя НТП еpt , где параметр (число) p ( p >0) характеризует темп прироста выпуска под влиянием НТП:
![]()
Эта ПФ - простейший пример динамической ПФ; она включает нейтральный, то есть не материализованный в одном из факторов, технический прогресс. В более сложных случаях технический прогресс может воздействовать непосредственно на производительность труда или капиталоотдачу: Y ( t ) = f ( A ( t )- L ( t ), K ( t )) или Y ( t ) = f ( A ( t ) K ( t ), L ( t )). Он называется, соответственно, трудосберегающим или капиталосберегающим НТП.
Пример .. Поиведем вариант ПФКД с учетом НТП v ( t } =
![]()
Выделение существенных видов ресурсов (факторов производства) и выбор аналитической формы функции fназывается спецификацией ПФ .
Преобразование реальных и экспертных данных в модельную информацию, т.е. расчет численных значений параметров ПФ на базе статистических данных с помощью регрессионного и корреляционного анализа, называется параметризацией ПФ .
Проверка истинности (адекватности) ПФ называется ее верификацией.
Выбор аналитической формы ПФ (т.е. спецификация) диктуется прежде всего теоретическими соображениями, которые должны явно (или даже неявно) учитывать особенности взаимосвязей между конкретными ресурсами (в случае микроэкономического уровня) или экономических закономерностей (в случае макроэкономического уровня), особенности реальных или экспертных данных, преобразуемых в параметры ПФ (т.е. особенности параметризации). На спецификацию и параметризацию в процессе совершенствования ПФ оказывают влияние результаты верификации ПФ. Отметим здесь, что оценка параметров ПФ обычно проводится с помощью метода наименьших квадратов .
2. Предельные (маржинальные) и средние значения производственной функции

называется средней производительностью i-го ресурса (фактора производства) (СПФ) или средним выпуском по i-му ресурсу (фактору производства). Символика: А i =f(x)/xi .
Напомним, что в случае двухфакторной ПФКД ![]() для средних производительностей Y/K и Y/L основного капитала и труда были использованы соответственно термины капиталоотдача и производительность труда. Эти термины используют и применительно к любым двухфакторным ПФ, у которых х1
=К
иx
2
=
L
.
для средних производительностей Y/K и Y/L основного капитала и труда были использованы соответственно термины капиталоотдача и производительность труда. Эти термины используют и применительно к любым двухфакторным ПФ, у которых х1
=К
иx
2
=
L
.

называется предельной (маржинальной) производительностью i-го ресурса (фактора производства) (ППФ) или предельным выпуском по i-му ресурсу (фактору производства). Символика: Mi =df(x)/dxi .
Следовательно, ППФ (приближенно) показывает, на сколько единиц увеличится объем выпуска у, если объем затрат х i-го ресурса вырастает на одну (достаточно малую) единицу при неизменных объемах другого затрачиваемого ресурса.
Отношение предельной производительности Mi i-го ресурса к его средней производительности А i называется (частной) эластичностью выпуска по i-му ресурсу (по фактору производства) (ЭВФ). Символика:
![]()
Сумма Е1 + Е2 = Е x называется эластичностью производства.
Е (приближенно) показывает, на сколько процентов увеличится выпуск у, если затраты i-го ресурса 1 увеличатся на один процент при неизменных объемах другого ресурса.
Обратим внимание на то, что i - номер заменяемого ресурса, j -номер замещающего ресурса. Используется также термин: предельная технологическая норма замены (замещения) i-ого ресурса (фактора производства) j-м ресурсом (фактором производства). Приведем более краткий (но менее точный) термин: (предельная) норма замены (замещения) ресурсов.
Непосредственно проверяется, что для двухфакторной ПФ справедливо равенство
![]()
т.е. (предельная) норма замены первого ресурса вторым равна отношению эластичностей выпуска по первому и второму ресурсам, умноженному на отношение объема второго ресурса к объему первого ресурса. Если х1 = К, х2 = L , то отношение x1 /x2 =K/L называется капиталовооруженностью труда. В этом случае (предельная) норма замены основного капитала трудом равна отношению эластичностей выпуска по основному капиталу и труду, поделенному на капиталовооруженность труда.
Пусть ПФ - двухфакторная. При постоянном выпуске у и малых приращениях Дх1 , и Дх2 , имеем приближенное равенство

Предельная норма замены ресурсов R 12 (приближенно) показывает, на сколько единиц увеличатся затраты второго ресурса (при неизменном выпуске у = а), если затраты первого ресурса уменьшатся на одну (малую) единицу.
3. Пример
Имеются статистические данные по производственному объединению “Угледобыча":
| Условное время t | Средн. годовая списочн. численность Х1, тыс .чел | Балансовая стоим. основных фондов Х2, млн.грн. | Валовая продукция Y, млн.грн | |
| 1 | 3,6 | 100 | 416 | |
| 2 | 4,1 | 105 | 464 | |
| 3 | 3,8 | 90 | 400 | |
| 4 | 3,2 | 110 | 432 | |
| 5 | 3,5 | 125 | 480 | |
Балансовая стоимость основных фондов и валовая продукция производственного объединения даны с учетом пересчета по индексу цен.
Вычислить производственную функцию Кобба-Дугласа; определить коэффициенты эластичности валовой продукции по списочной численности и стоимости основных фондов, а также предельные производительности по этим факторам. По результатам расчетов сформулировать выводы.
Решение:
Производственная функция Кобба-Дугласа имеет следующий вид
![]()
где b0 , b1 , b2 – параметры уравнения.
Для оценки параметров прологарифмируем уравнение и выполним замену переменных:
ln y =ln b0 + b1 ln x1 + b2 ln x2
b’0 = ln b0 , y’= ln y, x’1 = ln x1 , x’2 = ln x2 .
В результате этих преобразований получим линейную модель
y’= b’0 + b1 x’1 + b2 x’2 .
Для определения значений коэффициентов этой модели прологарифмируем исходные значения у и х1 , х2 , а затем используем метод наименьших квадратов.
В результате вычислений с помощью функции ЛИНЕЙН пакетаEXCEL получим
b1 = 0,424, b2 = 0,680,
ln b0 = 2,369откуда b0 = 10,690.
Следовательно, производственная функция Кобба-Дугласа имеет следующий вид
Y=10,690X1 0,424 X2 0,68 .
Коэффициент эластичности валовой продукции по списочной численности (по х1) равен b1 = 0,424.
Коэффициент эластичности валовой продукции по стоимости основных фондов (по х2) равен b2 = 0,680.
Следовательно, можно сделать вывод, что при увеличении списочной численности на 1% объём валовой продукции увеличится на 0,424% , а при увеличении стоимости основных фондов на 1% объём валовой продукции увеличится на 0,68%.
Предельная производительность по списочной численности равна
M1 = b1 * Y / X1 = 0,424* Y / X1 = 0,424* 10,690X1 –0,576 X2 0,68 ,
где Y / X1 - производительность труда.
Предельная производительность по стоимости основных фондов равна
M2 = b2 * Y / X2 = 0,680* Y / X2 =0,680* 10,690X1 0,424 X2 –0,32 ,
где Y / X2 -фондоотдача.
5. Применение аппарата теории игр для анализа проблем микроэкономики
1. Основные понятия
Важным случаем в теории игр является ситуация, когда выигрыш одного из игроков равен проигрышу другого, т.е. налицо прямой конфликт между игроками. Классическими примерами здесь являются ситуации, где, с одной стороны, имеется один покупатель, с другой - продавец (ситуация монополия-монопсония). Подобные игры называются играми с нулевой суммой, или антагонистическими играми.
В зависимости от возможности предварительных переговоров между игроками различают кооперативные и некооперативные игры.
Игра, в которой игроки не могут координировать свои стратегии подобным образом, называется некооперативной. Очевидно, что все антагонистические игры могут служить примером некооперативных игр.
Кооперативной игрой называется игра с ненулевой суммой, в которой игрокам разрешается обсуждать перед игрой свои стратегии и договариваться о совместных действиях, т.е. игроки могут образовывать коалиции. Основная задача в кооперативной игре состоит в дележе общего выигрыша между членами коалиции. Примером кооперативной игры может служить ситуация образования коалиций в парламенте для принятия путем голосования решения, так или иначе затрагивающего интересы участников голосования.
Проблемы рыночного взаимодействия близки к проблемам теории игр и могут быть эффективно описаны и исследованы в ее терминах.
Представим себе экономику, в которой имеется два субъекта: Игрок1 (Фирма1) и Игрок2 (Фирма2), и два товара х1 и х2 , (естественно, число игроков и товаров может быть большим, но в случае 2х2 все введенные понятия имеют наглядную интерпретацию.)
Каждыйиз игроков имеет свою функцию полезности , (функцию дохода) заданную на наборе товаров:h 1 ( х1 ,х2 ), h 2 ( х1 ,х2 ). В начале игры в экономике имеется общее количество Х1 первого товара и X 2 - второго товара. Предположим, что это начальное количество благ как-то распределено между игроками: 1-й Игрок обладает количеством Х1 1 первого товара и X2 1 - второго, 2-й Игрок - количествами X1 2 и X2 2 , 1-го и 2-го товаров соответственно, так что X1 1 + X1 2 =Х1 и X2 1 + X2 2 = X 2 .
Встают вопросы: могут ли игроки путем обмена имеющимися у них товарами улучшить свое положение, т.е. увеличить значение функций полезности h1 , и h2 , по сравнению с начальными уровнями h 1 (Х1 1 , X 2 1 ) и h 2 ( X 1 2 , X 2 2 ) ; каковы свойства такого решения?
Для наглядного представления экономики с двумя игроками и двумя товарами традиционно используется так называемый ящик Эджворта (рис. 1). 1-го Игрока, пунктирными - кривые безразличия 2-го Игрока)
В ящике Эджворта длина горизонтальной оси, соответствующей первому товару, равна общему количеству этого товара Х1 , длина вертикальной оси - общему количеству товара X2 . Выделенное пространство является множеством всех возможных распределений имеющихся товаров между двумя игроками. Нижний левый угол считается началом координат для 1-го Игрока, верхний правый угол - началом координат для 2-го Игрока.
На выделенном пространстве представлены также два множества кривых безразличия (линий уровня функций выигрыша), принадлежащих каждому из игроков. При этом точка начального распределения товаров имеет координаты (Х1 1 , X2 1 ) в системе отсчета 1-го Игрока (и, соответственно, (X1 2 ,X2 2 ); в системе отсчета 2-го Игрока).
2. Парето-оптимальное множество решений
Рассмотрим для начала проблему эффективного распределения товаров между игроками. Единственным требованием к распределению, которое мы можем предъявить на начальном этапе анализа, является требование Парето-оптимальности. Распределение называется Парето-оптимальным, если положение ни одного из игроков нельзя улучшить, не ухудшая при этом положение его партнера.
Множество Парето-оптимальных распределений может быть наглядно представлено с помощью ящика Эджворта. В случае 2-х игроков Парето-оптимальное решение может быть найдено с помощью фиксации уровня полезности одного из игроков (скажем, Игрока 2) и поиска максимума функции полезности другого игрока.
В терминах ящика Эджворта это означает, что необходимо найти такую точку на фиксированной кривой безразличия Игрока 2, в которой Игрок 1 получает максимум своей функции полезности.
Очевидно, что такой точкой является точка, где кривые безразличия касаются друг друга, так как в противном случае Игрок 1 может, продвигаясь вдоль фиксированной линии уровня Игрока 2 внутрь, увеличить значение своей функции полезности (рис. 2).
Опираясь на этот факт, можно показать, что множество Парето-оптимальных распределений в ящике Эджворта будет множеством всех точек, в которых кривые безразличия Игрока 1 и Игрока 2 касаются друг друга (рис. 3).
Множество Парето-оптимальных распределений в пространстве товаров называется контрактным множеством, поскольку игрокам в общем случае имеет смысл договариваться между собой именно на этом наборе эффективных распределений.
3. Переговорное множество решений
Рассмотрим теперь ситуацию, когда каждый игрок обладает некоторым начальным количеством каждого из товаров. Встает вопрос: может ли это начальное распределение быть улучшено путем обмена товарами между игроками? Исследуем эту проблему с помощью ящика Эджворта.
Пусть (Х1 1, X21) - точка начального распределения товаров; проведем через эту точку кривые безразличия для Игрока 1 и Игрока 2 (рис. 4).
Если две кривые не касаются друг друга (т.е. если начальное распределение не является Парето-оптимальным), то в своем пересечении они образуют область, двигаясь внутрь которой каждый из игроков может увеличивать значение обеих функций полезности. При этом. как легко показать, часть контрактного множества оказывается внутри области, образованной проведенными кривыми безразличия.
Игрокам имеет смысл вести переговоры относительно распределений, находящихся на контрактном множестве, а с учетом начального распределения - относительно участка контрактного множества, заключенного между двумя кривыми безразличия.
Эти кривые называются линиями угрозы, а выделяемый ими участок на контрактном множестве - переговорным множеством.
Линии угрозы в данном случае означают, что за их пределами (т.е. ниже и левее исходной кривой безразличия для Игрока 1 и выше и правее кривой безразличия для Игрока 2) какому-либо из игроков становится незачем вести переговоры - ему лучше (или, по крайней мере, не хуже) оставаться в ситуации начального распределения.
Для того чтобы переместиться на переговорное множество, в случае рис.4 Игрок 1 должен передать (продать) некоторое количество имеющегося у него товара 1 Игроку 2 в обмен на определенное количество товара 2, имеющегося у Игрока 2.
На переговорном множестве выделяется точка решения Нэша N, в которой достигается максимум произведения приращений дохода каждого из игроков по сравнению с доходом, который может быть получен без вступления в коалицию.
В результате проведенного анализа можно сделать вывод, что игроки могут улучшить свое первоначальное положение, обмениваясь товарами, и Игроку 1 выгодно уступить Игроку 2 некоторое количество товара 1 в обмен на товар 2.
4. Задача о дуополии
Рассмотрим в заключение решение задачи о дуополии.
В этой задаче две фирмы сталкиваются с проблемой удовлетворения спроса на некоторый товар. Объем спроса зависит от уровня назначаемых цен и описывается функцией d(р) (ей соответствует нисходящая линия на рис.5). Объем предложения товара каждой из фирм также зависит от уровня цен и в микроэкономике описывается функциями предложения s1(p}, s2(р); эти функции определяются уровнем предельных издержек каждой из фирм.
Предположим для простоты, что Фирма 1 и Фирма 2 имеют одинаковые функции предложения s1(p)=s2(p) .
Поиск решения в задаче о дуополии (т.е. определение уровня цен и объемов предложения каждой из фирм) базируется на принципах, общих для решения задач теории игр: каждая из сторон располагает информацией о себе и своем партнере (в данном случае - о функциях предложения каждой из фирм), об условиях игры (в данном случае - о функции спроса) и действует, исходя из предположения, что ее партнер располагает такой же информацией и действует рационально (т.е. стремится максимизировать свой доход).
Если Фирма 1 назначит цену на предлагаемый ею товар р1, а Фирма 2 примет эту цену, то Фирма 1 сможет продать объем товара, равный
![]()
Функция r1(p) называется остаточной функцией спроса, с которой сталкивается Фирма 1 (рис.5). Поскольку величина r1, описывает объем спроса, приходящийся только на продукцию Фирмы 1, то она получит максимум дохода, полностью удовлетворив этот спрос, т.е. при условии, что
![]()
В итоге Фирма 1, опираясь на имеющуюся у нее информацию, решает задачу поиска равновесного уровня цен р , при которых
![]()
Аналогичную задачу поиска равновесных цен решает Фирма 2
![]()
Учитывая, что s1(p)=s2(p), мы получим, что в ситуации равновесия
![]()
а доход каждой из фирм будет равен
![]()
Таким образом, в задаче о дуополии фирмы должны найти такой уровень цен р*, при котором они смогут полностью удовлетворить спрос на продукцию d(p*), распределив между собой производство этой продукции поровну и получив при этом одинаковый доход. Уровень равновесных цен и объем предложения каждой из фирм определяют в данной задаче ситуацию равновесия по Нэшу.
6. ВРЕМЕННЫЕ РЯДЫ И ПРОГНОЗИРОВАНИЕ
(Эддоус М., Стэнсфилд Р. Методы принятия решения. -М.:"Аудит",1997, Глава 9.)
Каким бы видом бизнеса вы ни занимались, вам приходится планировать предпринимательскую деятельность на будущий период. При составлении как краткосрочных, так и долгосрочных планов менеджеры вынуждены прогнозировать будущие значения таких важнейших показателей, как, например, объем продаж, ставки процента, издержки и т.д. В этой главе мы рассмотрим возможности применения в целях прогнозирования фактических данных за прошлые промежутки времени.
В предыдущей главе при характеристике регрессионных методов колебания зависимой переменной объяснялись на основе изучения соответствующих значений независимой переменной. В данной главе мы будем использовать аналогичный подход, причем в качестве независимой будет выступать переменная времени. К примеру, мы хотим объяснить колебания объемов продаж только через изменение значений этого показателя во времени, без учета каких-либо других факторов. Если удается выявить определенную тенденцию изменения фактических значений, то ее можно использовать для прогнозирования будущих значений данного показателя. Множество данных, в которых время является независимой переменной, называется временным рядом.
Модель, построенную по ретроспективным данным, не всегда можно использовать в прогнозировании отдельных показателей. Например, план некоторой компании может коренным образом измениться, если эта компания несет убытки. Кроме того, существует множество внешних факторов, которые могут полностью изменить тенденцию, существовавшую ранее. К таким факторам можно отнести существенные изменения цен на сырье, резкое увеличение уровня инфляции в мире в целом или стихийные бедствия, которые непредсказуемым образом могут повлиять на предпринимательскую деятельность.
В разделе 9.2 мы рассмотрим временные ряды, которые содержат такие элементы, как собственно тренд, сезонная вариация и циклическая вариация. Эти элементы можно объединять с помощью нескольких способов. Остановимся на двух типах моделей: модели с аддитивной компонентой и модели с мультипли-кативной компонентой. Как следует из их названий, элементы в этих моделях либо складываются друг с другом, либо перемножаются. Каждой из моделей соответствуют различные методы расчета компоненты тренда. Мы будем использовать сочетание методов скользящего среднего и линейной регрессии.
Следует иметь в виду, что описанные выше методы — это далеко не весь, а иногда и не лучший инструментарий для составления прогнозов. Существует множество других, более изощренных статистических методов. Помимо количественных, существуют также качественные методы, которые используются в условиях недостаточного количества или отсутствия фактических данных. Среди них можно назвать, например, метод Дельфи, который используется экспертами для прогнозирования возможных будущих последствий, и метод написания сценария.
ЭЛЕМЕНТЫ ВРЕМЕННОГО РЯДА
Значения некоторой переменной (например, объемы продаж) изменяются во времени под воздействием целого ряда факторов. Если, к примеру, некоторая компания предлагает на рынке новый вид продукции, то с течением времени объемы продаж этой продукции возрастают. Общее изменение значений переменной во времени называется трендом и обозначается через Т. В примерах, которые будут рассмотрены ниже, тренд является линейным. Это означает, что модель тренда легко построить, используя для расчета параметров прямой, наилучшим образом аппроксимирующий данный тренд, метод регрессии. Затем данная модель может использоваться для прогнозирования будущих значений тренда. В действительности тренд в чистом виде либо не существует, например, при колебании значений спроса вокруг некоторой фиксированной величины, либо в большинстве случаев он является нелинейным. На приведенных ниже рис. 9.1 и 9.2 проиллюстрирован тренд значений спроса в соответствии с различными стадиями жизненного цикла продукта. Новым видам продукции соответствует возрастающий тренд, тогда как устаревшим продуктам на заключительной стадии их жизненного цикла — убывающий.
Метод скользящего среднего, изложенный ниже, можно использовать для выделения тренда из модели, содержащей сезонную компоненту. Этот метод позволяет выравнивать тренд фактических значений через сглаживание сезонных колебаний. Однако тренды, полученные с использованием метода скользящего среднего, как правило, не используются для прогнозирования будущих значений, поскольку процесс их получения предполагает высокий уровень неопределенности.
В большинстве случаев значения переменных характеризуют не только тренд. Часто они подвержены циклическим колебаниям. Если эти колебания повторяются в течение небольшого промежутка времени, то они называются сезонной вариацией. Колебания, повторяющиеся в течение более длительного промежутка времени, называются циклической вариацией. Модели, содержащие сезонную компоненту, которые будут рассмотрены в данной главе, основаны на традиционном понятии сезона, однако, в более широком смысле термин «сезон» в прогнозировании применим к любым систематическим колебаниям. Например, при изучении товарооборота в течение недели под термином «сезон» подразумевается 1 день. При исследовании транспортных потоков дня или в течение недели также может использоваться модель с сезонной компонентой. Любые колебания относительно тренда, построенного по годовым значениям некоторого показателя, можно описать в виде модели с циклической компонентой. Не будем рассматривать примеры с циклическим фактором. Этот фактор можно выявить только по данным за длительные промежутки времени в 10, 15 или 20 лет, однако в данном случае колебания значений тренда могут быть вызваны воздействием общеэкономических факторов.
Наличие подобных циклических факторов можно легко обнаружить в данных за 1960—75 гг. В этот период было разработано множество методов прогнозирования, однако впоследствии тенденции общеэкономического развития претерпели значительные изменения. Остановимся подробнее на моделировании более коротких промежутков времени и не будем учитывать воздействие циклической компоненты.
Последняя предпосылка нашей модели также следует из метода линейной регрессии. Она связана со значением ошибки, или остатка, т.е. той части значения наблюдения, которую нельзя объяснить с помощью построенной модели. Величину ошибок можно использовать в качестве меры степени соответствия модели исходным данным. Обычно применяют два вида таких мер. Это среднее абсолютное отклонение (meanabsolutedeviation — MAD ):
равное отношению суммы величин всех ошибок без учета их знака к общему числу наблюдений, и среднеквадратическая ошибка (meansquareerror — MCE ):
которая представляет собой отношение суммы квадратов ошибок к общему числу наблюдений. Последняя из указанных мер резко возрастает при наличии высоких ошибок.
В процессе анализа временного ряда мы стараемся определить все имеющиеся факторы и построить модель, которая соответствующим образом отражала бы их.
Пример 9.1 Представленные ниже данные — это количество продукции, проданной компанией "Lewplanpic" в течение последних 13 кварталов.
Необходимо проанализировать указанное множество данных и установить, можно ли обнаружить тенденцию. Если устойчивая тенденция действительно существует, данная модель будет использоваться нами для прогнозирования количества проданной продукции в следующие кварталы.
Решение
На рис. 9.3 нанесены соответствующие значения. При построении диаграммы временного ряда полезно последовательно соединить точки отрезками, чтобы более четко увидеть любую тенденцию.
Как следует из диаграммы, возможен возрастающий тренд, содержащий сезонные колебания. Объемы продаж в зимний период (1 и 4) значительно выше, чем в летний (2 и 3). Сезонная компонента практически не изменится в течение трех лет. Тренд показывает, что в целом объем продаж возрос примерно с 230 тыс. шт. в 19X6 г. до 390 тыс. шт. в 19X8 г., однако увеличения сезонных колебаний не • произошло. Этот факт свидетельствует в пользу модели с аддитивной компонентой (см. 9.3).
АНАЛИЗ МОДЕЛИ С АДДИТИВНОЙ КОМПОНЕНТОЙ: A = T + S + E
Моделью с аддитивной компонентой называется такая модель, в которой вариация значений переменной во времени наилучшим образом описывается через сложение отдельных компонент. Предположив, что циклическая вариация не учитывается, модель фактических значений переменной А можно представить следующим образом:
Фактическое значение = Трендовое значение + Сезонная вариация + Ошибка,
т.е.
А = Т + S + Е.
В моделях как с аддитивной, так и с мультипликативной компонентой общая процедура анализа примерно одинакова:
Шаг 1. Расчет значений сезонной компоненты.
Шаг 2. Вычитание сезонной компоненты из фактических значений. Этот процесс называется десезонализацией данных. Расчет тренда на основе полученных десезонализированных данных.
Шаг 3. Расчет ошибок как разности между фактическими и трендовыми значениями.
Шаг 4. Расчет среднего отклонения (MAD) или среднеквадратической ошибки (MSE) для обоснования соответствия модели исходным данным или для выбора из множества моделей наилучшей.
Расчет сезонной компоненты в аддитивных моделях
П Пример 9.2. Вернемся к примеру 9.1 предыдущего параграфа, в котором рассматриваются квартальные объемы продаж компании Lewplanpic. Мы уже выяснили, что этим данным отвечает аддитивная модель, т.е. фактически объемы продаж можно выразить следующим образом:
A = T + S + E.
Для того чтобы элиминировать влияние сезонной компоненты, воспользуемся методом скользящей средней. Просуммировав первые четыре значения, получим общий объем продаж в 19X6 г. Если поделить эту сумму на четыре, можно найти средний объем продаж в каждом квартале 19X6 года, т. е. (239 + 201 + 182 + 297)/4 = 229,75.
Полученное значение уже не содержит сезонной компоненты, поскольку представляет собой среднюю величину за год. У нас появилась оценка значения тренда для середины года, т.е. для точки, лежащей в середине между кварталами II и III. Если последовательно передвигаться вперед с интервалом в три месяца, можно рассчитать средние квартальные значения на промежутке: апрель 19X6 — март 19X7 (251), июль 19X6 - июнь 19X7 (270,25) и т.д. Данная процедура позволяет генерировать скользящие средние по четырем точкам для исходного множества данных. Получаемое таким образом множество скользящих средних представляет наилучшую оценку искомого тренда.
Теперь полученные значения тренда можно использовать для нахождения оценок сезонной компоненты. Мы рассчитываем:
А - Т = S + Е.
К сожалению, оценки значений тренда, полученные в результате расчета скользящих средних по четырем точкам, относятся к несколько иным моментам времени, чем фактические данные. Первая оценка, равная 229,75, представляет собой точку, совпадающую с серединой 19X6 г., т.е. лежит в центре промежутка фактических значений объемов продаж во II и III кварталах. Вторая оценка, равная 251, лежит между фактическими значениями в III и IV кварталах. Нам же требуются десезонализированные средние значения, соответствующие тем же интервалам времени, что и фактические значения за квартал. Положение десезонализированных средних во времени сдвигается путем дальнейшего расчета среднего для каждой пары значений. Найдем среднюю из первой и второй оценок, центририруем их на июль-сентябрь 19X6 г., т. е. (229,75 + 250)/2 = 240,4.
Это и есть десезонализированная средняя за июль-сентябрь 19X6 г. Эту десезонализированную величину, которая называется центрированной скользящей средней, можно непосредственно сравнивать с фактическим значением за июль-сентябрь 19X6 г., равным 182. Отметим, что это означает отсутствие оценок тренда за первые два или последние два квартала временного ряда. Результаты этих расчетов приведены в табл. 9.2.
Для каждого квартала мы имеем оценки сезонной компоненты, которые включают в себя ошибку или остаток. Прежде чем мы сможем использовать сезонную компоненту, нужно пройти два следующих этапа. Найдем средние значения сезонных оценок для каждого сезона года. Эта процедура позволит уменьшить некоторые значения ошибок. Наконец, скорректируем средние значения, увеличивая или уменьшая их на одно и то же число таким образом, чтобы общая их сумма была равна нулю. Это необходимо, чтобы усреднить значения сезонной компоненты в целом за год. Корректирующий фактор рассчитывается следующим образом: сумма оценок сезонных компонент делится на 4. В последнем столбце табл. 9.2 эти оценки записаны под соответствующими квартальными значениями. Сама процедура приведена в табл. 9.3. производилось округление двух значений сезонной компоненты до ближайшего большего числа, а двух значений — до ближайшего меньшего числа таким образом, чтобы общая сумма была равна нулю.
Значения сезонной компоненты еще раз подтверждают наши выводы, сделанные на основе диаграммы. Объемы продаж за два зимних квартала превышают среднее трендовое значение приблизительно на 40 тыс. шт., а объём продаж за два летних периода ниже средних на 21 и 62 тыс. шт. соответственно
Аналогичная процедура применима при определении сезонной вариации за любой промежуток времени. Если, например, в качестве сезонов выступают дни недели, для элиминирования влияния ежедневной «сезонной компоненты» также рассчитывают скользящую среднюю, но уже не по четырем, а по семи точкам. Этаскользящая средняя представляет собой значение тренда в середине недели, т.е в четверг; таким образом, необходимость в процедуре центрирования отпадает.
Десезонализация данных при расчете тренда
Шаг 2 - состоит в десезонализации исходных данных. Она заключается в вычитании соответствующих значений сезонной компоненты из фактических значений данных за каждый квартал, т.е. А — S = Т + Е, что показано ниже.
Новые оценки значений тренда, которые еще содержат ошибку, можно использовать для построения модели основного тренда. Если нанести эти значения на исходную диаграмму, можно сделать вывод о существовании явного линейного тренда.
Уравнение линии тренда имеет вид:
Т = а + b *номер квартала,
где а и b характеризуют точку пересечения с осью ординат и наклон линии тренда. Для определения параметров прямой, наилучшим образом аппроксимирующей тренд, можно использовать метод наименьших квадратов. Таким образом, как мы знаем из предыдущей главы о линейной регрессии, уравнения для расчета параметров а и b будут иметь вид:

где х — порядковый номер квартала, у — значение (Т + Е) в предыдущей таблице. С помощью калькулятора подсчитаем:
![]()
Подставив найденные значения в соответствующие формулы, получим:
b = 19,978,а = 180,046.
Следовательно, уравнение модели тренда имеет следующий вид:
Трендовое значение объема продаж, тыс. шт. = 180,0 + 20,0 * номер квартала.
Расчет ошибок
Шаг 3 нашего алгоритма, предшествующий составлению прогнозов, состоит врасчете ошибок или остатка. Наша модель имеет следующий вид:
A = T + S + E.
Значение S было найдено в разделе 9.3.1, а значение Т — в разделе 9.3.2. Вычитая каждое это значение из фактических объемов продаж, получим значение ошибок.
Последний столбец этой таблицы можно использовать в шаге 4 при расчете среднего абсолютного отклонения (MAD) или средней квадратической ошибки (MSE):

![]()
В нашем случае ошибки достаточно малы и составляют от 1 до 2%. Тенденция, выявленная по фактическим данным, достаточно устойчива и позволяет получить хорошие краткосрочные прогнозы.
Прогнозирование по аддитивной модели
Прогнозные значения по модели с аддитивной компонентой рассчитываются как
F = Т + S (тыс. шт. за квартал),
где трендовое значение Т = 180 + 20 х номер квартала, а сезонная компонента S составляет +42,6 в январе-марте, - 20,7 в апреле-июне, 62,0 в июле-сентябре и +40,1 в октябре-декабре.
Порядковый номер квартала, охватывающего ближайшие три месяца с апреля по июль 19X9 г., равен 14, таким образом, прогнозное трендовое значение составит: Т14 = 180 + 20 х 14 = 460 (тыс. шт. за квартал) .
Соответствующая сезонная компонента равна - 20,7 тыс. шт. Следовательно, прогноз на этот квартал определяется как:
F (апрель-июнь 19X9 г.) = 460 - 20,7 = 439,3 тыс. шт.
Не следует забывать: чем более отдаленным является период упреждения, тем меньшей оказывается обоснованность прогноза. В данном случае мы предполагаем, что тенденция, обнаруженная по ретроспективным данным, распространяется и на будущий период. Для сравнительно небольших периодов упреждения такая предпосылка может действительно иметь место, однако ее выполнение становится менее вероятным по мере составления прогнозов на более отдаленную перспективу.
АНАЛИЗ МОДЕЛИ С МУЛЬТИПЛИКАТИВНОЙ КОМПОНЕНТОЙ: А = Т х Sx E
В некоторых временных рядах значение сезонной компоненты не является константой, а представляет собой определенную долю трендового значения. Таким образом, значения сезонной компоненты увеличиваются с возрастанием значений тренда.
Пример 9.3. Компания CDpic осуществляет реализацию нескольких видов продукции. Объемы продаж одного из продуктов за последние 13 кварталов представлены в таблице 9.6.
Построим по этим данным точечную диаграмму:
Объем продаж этого продукта так же, как и в предыдущем примере, подвержен сезонным колебаниям, и значения его в зимний период выше, чем в летний. Однако размах вариации фактических значений относительно линии тренда постоянно возрастает. К таким данным следует применять модель с мультипликативной компонентой:
Фактическое значение = Трендовое значение * Сезонная вариация * Ошибка, т. е.
А = Т х S х Е.
В нашем примере есть все основания предположить существование линейного тренда, но чтобы полностью в этом убедиться, проведем процедуру сглаживания временного ряда.
Расчет значений сезонной компоненты
В сущности, эта процедура ничем не отличается от той, которая применялась для аддитивной модели. Так же вычисляются центрированные скользящие средние для трендовых значений, однако оценки сезонной компоненты представляют собой коэффициенты, полученные по формуле А/Т = S х Е, Результаты расчетов, приведены в табл. 9.7.
Значения сезонных коэффициентов получены на основе квартальных оценок по аналогии с алгоритмом, который применялся для аддитивной модели. Так как значения сезонной компоненты — это доли, а число сезонов равно четырем, необходимо, чтобы их сумма была равна четырем, а не нулю, как в предыдущем случае. (Если бы в исходных данных предполагалось семь сезонов в течение недели по одному дню каждый, то общая сумма значений сезонной компоненты должна была бы равняться семи). Если эта сумма не равна четырем, производится корректировка значений сезонной компоненты точно таким же образом, как это уже делалось ранее. В таблице оценки, рассчитанные в последнем столбце предшествующей табл. 9.8, расположены под соответствующим номером квартала.
Как показывают оценки, в результате сезонных воздействий объемы продаж в январе—марте увеличиваются на 11,6% соответствующего значения тренда (1,116). Аналогично сезонные воздействия в октябре-декабре приводят к увеличению объема продаж на 5,5% от соответствующего значения тренда. В двух других кварталах сезонные воздействия состоят в снижении объемов продаж, которое составляет 90,7 и 92,2% от соответствующих трендовых значений.
Десезонализация данных и расчет уравнения тренда
После того как оценки сезонной компоненты определены, можем приступить к процедуре десезонализации данных по формуле A /S = Т х Е. Результаты расчетов этих оценок значений тренда приведены в табл. 9.9.
Полученные трендовые значения наносятся на исходную точечную диаграмму.
Точки, образующие представленный на графике тренд, достаточно сильно разбросаны. Объемы продаж в данном случае не образуют такой строгой последовательности, как в предыдущем примере с компанией Lewplanpic. Скорее всего, пример с CDpic более близок к реальной действительности.
Теперь нужно принять решение о том, какой вид будет иметь уравнение тренда. Очевидно, что линия тренда — не кривая, наоборот, она несколько больше напоминает прямую, хотя отдельные точки, особенно значения за 19X6 г, расположены хаотически. Предположим для простоты, что тренд линейный, и для расчета параметров прямой, наилучшим образом его аппроксимирующей, будем применять метод наименьших квадратов. Воспользовавшись той же процедурой, что и в разделе 9.3.2, находим, что
Т = 64,6 + 1,36 * номер квартала (тыс. шт. в квартал) .
Это уравнение будем использовать в дальнейшем для расчета оценок трендовых объемов продаж на каждый момент времени.
Расчет ошибок:
А/(Т х S ) = Е или А — (Т х S ) = Е
Итак, мы нашли значения тренда и сезонной компоненты. Теперь мы можем использовать их для того, чтобы рассчитать ошибки в прогнозируемых по модели объемах продаж Т х S по сравнению с фактическими значениями А. В табл. 9.10 эти ошибки рассчитаны как отношение Е = А/(Т х S).
Для каждого рода ошибки достаточно велики, что видно из графика десезонализированных значений. Однако, начиная с первого квартала 19X7 г. величина ошибки составляет в среднем 2-3% от фактического значения, и можно сделать вывод о соответствии построенной модели фактическим данным.
Прогнозирование по модели с мультипликативной компонентой
При составлении прогнозов по любой модели предполагается, что можно найти уравнение, удовлетворительно описывающее значения тренда. В обоих изложенных выше примерах эта предпосылка была успешно выполнена. Тренд, который нами рассматривался, был очевидно линейным. Если бы исследуемый тренд представлял собой кривую, мы были бы вынуждены моделировать эту связь с помощью одного из методов формализации нелинейных взаимосвязей, рассмотренных в предыдущей главе. После того как параметры уравнения тренда определены, процедура составления прогнозов становится совершенно очевидной. Прогнозные значения определяются по формуле:F = Т х S, где
Т = 64,6 + 1,36 * номер квартала (тыс. шт. за квартал),
а сезонные компоненты составляют 1,116 в первом квартале, 1,097 — во втором 0,922 — в третьем и 1,055 в четвертом квартале. Ближайший следующий квартал — это второй квартал 19X9 г., охватывающий период с апреля по июнь и имеющий во временном ряду порядковый номер 14. Прогноз объема продаж в этом квартале составляет:
F = Т х S = (64,6 + 1,36 х 14) х 0,907 = 83,64 х 0,907 = 75,9 (тыс. шт. за квартал).
С учетом величины ошибки прогноза мы можем сделать вывод, что даннг-г оценка будет отклоняться от фактического значения не более чем на 2-3*4 Аналогично, прогноз на октябрь-декабрь 19X9 г., рассчитывается для квартала : порядковым номером 16 с использованием значения сезонной компоненты для Г-квартала года:
F = Т х S = (64,6 + 1,36 х 16) х 1,055 = 83,36 х 1,055 = 91,1 (тыс. шт. за квартал) .
Разумно предположить, что величина ошибки данного прогноза будет несколько выше, чем предыдущего, поскольку этот прогноз рассчитан на более длительную перспективу.
РЕЗЮМЕ
Под временным рядом понимается любое множество данных, относящихся к определенным моментам времени. Это могут быть, скажем, годы, кварталы месяцы или недели. В моделях временного ряда ретроспективная тенденция используется для прогнозирования поведения переменной в будущем. Краткосрочные прогнозы являются более точными, чем долгосрочные. Если прогноз составлялся на более длительный период времени при условии, что существующая тенденция сохранится в будущем, то тем больше величина ошибки.
Для моделирования временных рядов используются два типа моделей -аддитивная и мультипликативная. В обоих случаях предполагается, что значение переменной включает в себя ряд компонент. Временной ряд может состоять из собственно тренда — общей тенденции изменения значений переменной; сезонной вариации — краткосрочных периодических колебаний значений переменной; циклической вариации — долгосрочных периодических колебаний значений переменной; ошибки или остатка. В данном учебном пособии не рассматривались массивы данных за длительные промежутки времени, содержащие циклическую вариацию
Рассмотренные нами модели имеют следующий вид:
Аддитивная А = Т + S + Е , Мультипликативная А = Т х S х Е .
В обоих видах моделей для десезонализации данных применяется метод скользящего среднего. Затем десезонализированные данные используются при построении модели тренда. По этой модели составляют прогнозы будущих значений тренда. В случае линейной модели для нахождения параметров прямой наилучшим образом аппроксимирующей фактические значения, используется метод наименьших квадратов. Процесс построения нелинейных моделей гораздо более сложен.
В отличие от линейных регрессионных моделей для оценки обоснованности или точности прогнозных моделей статистические методы, как правило, не используются. Наилучшую среди нескольких моделей выбирает специалист, составляющий прогноз. Чтобы определить, насколько точно рассматриваемая модель аппроксимирует прошлые данные, применяются два показателя: Среднее абсолютное отклонение и Среднеквадратическая ошибка.
Литература
1.Замков О.О., Толстопятенко А.В., Черемных Ю.Н. Математические методы в экономике. -М.:"ДИС",1997.
2.Эддоус М., Стэнсфилд Р. Методы принятия решения. -М.:"Аудит",1997.
3.Аронович А.Б., Афанасьев М.Ю., Суворов Б.П. Сборник задач по исследованию операций. -М.:Издательство Московского университета,1997.
4.Исследование операций в экономике:Учебное пособие для вузов. Н.Ш. Кремер и др. -М.: Банки и биржи, ЮНИТИ, 1997. (гл.15, гл.16)
5.Ю.А. Толбатов. Економетрика. - К., 1997.
6.С.И. Шелобаев. Математические методы и модели в экономике, финансах, бизнесе. -М.:ЮНИТИ,2000.