| Скачать .docx |
Курсовая работа: Построение неполной квадратичной регрессионной модели по результатам полного факторного эксперимента
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ УКРАИНЫ
ВОСТОЧНОУКРАИНСКИЙ НАЦИОНАЛЬНЫЙ
УНИВЕРСИТЕТ имени ВЛАДИМИРА ДАЛЯ
ПОЯСНИТЕЛЬНАЯ ЗАПИСКА
к курсовой работе по дисциплине
“Организация эксперимента ”
Тема: «Построение неполной квадратичной регрессионной модели по результатам полного факторного эксперимента 23 »
СТУДЕНТ: Черных Н.В.
ГРУППА: ММ – 961
РУКОВОДИТЕЛЬ: Шевченко А.В.
Луганск 2009 г.
Раздел 1. Построение неполной квадратичной регрессионной модели по результатам полного факторного эксперимента 23
Принципы решения многофакторных оптимизационных задач. Метод крутого восхождения
Задачи материаловедения весьма разнообразны. В наиболее общем виде их можно разделить на две группы:
- экстремальные задачи, целью которых является поиск оптимальных в том или ином смысле составов материалов, режимов их термической обработки, условий литья, сварки, напыления, обработки давлением и т. п.;
- задачи описания, целью которых является изучение общих закономерностей явлений, происходящих в материалах при изменении их составов, в процессе их изготовления, во время последующих обработок. Задачи описания и экстремальные задачи часто решаются вместе.
Во всех случаях ситуация заметно упрощается, если для того или иного явления удается построить некоторую математическую модель.
Предположим, требуется изучить влияние химического состава, условий литья, обработки давлением и последующей термической обработки на свойства материалов выбранной системы. Целью этого исследования является попытка выявить общие закономерности изменения свойств материалов в зависимости от их химического состава и условий обработок, а также поиск материала, обладающего некоторым заданным комплексом свойств. Понятно, что цели исследования легко было бы достигнуть, если бы имелись математические модели, связывающие механические, технологические, эксплуатационные и любые другие свойства материалов изучаемой системы с их химическим составом, режимами литья, деформации, термической обработки, особенностями поверхностных свойств. Решение и задачи описания, и экстремальной задачи представляло бы тогда просто анализ имеющихся моделей.
Возникает вопрос, каким же образом получить такого рода модели? Существуют, по крайней мере, два способа.
Модели можно попытаться построить на основе знаний механизмов явлений, происходящих в материалах при изменении их состава и во время обработок, т. е. теоретическим путем. Построенные таким способом модели представляют исключительную ценность, поскольку их можно использовать не только для решения данной конкретной задачи, но и во многих других случаях.
К сожалению, механизмы большинства явлений или процессов, происходящих в различных материалах, к настоящему времени изучены явно недостаточно. Во всяком случае, строгих количественных теорий, как правило, не существует, а потому только из теоретических соображений построить модели для каждого конкретного случая почти никогда не удается. Тем не менее, рассматриваемая задача является стандартной в технологии металлов, материаловедении, порошковой металлургии и в технологии нанесения покрытий, а сами задачи такого рода, конечно же, решаются. Следовательно, решаются они при неполном знании (а иногда и вообще при незнании) механизмов явлений, протекающих в материалах. И способ решения вполне определенный – эмпирический, экспериментальный . Отсюда следует, что наиболее реалистичным путем построения математических моделей является эксперимент.
Итак, необходимо с помощью эксперимента, который будет проводиться при неполном знании или незнании механизмов явлений, научиться строить и анализировать математические модели, связывающие свойства материалов со всеми теми переменными, от которых эти свойства зависят.
Сразу же отметим, что поставленная проблема является задачей кибернетики. Действительно, если считать кибернетику наукой, изучающей системы любой природы, способные воспринимать, хранить и перерабатывать информацию для целей оптимального управления, то такой кибернетической системой в данном случае является исследуемый материал, и эту систему можно представить в виде так называемого “черного ящика”. Она будет иметь входы (независимые переменные, факторы) х1 , х2 , ..., xk (в нашем случае это состав, режимы литья, напыления, термической обработки, деформации) и выходы (зависимые переменные, отклики, параметры оптимизации, целевые функции) h1 , h2 , ..., hq (свойства материала). Существенным является то обстоятельство, что каждому набору уровней входов отвечают определенные значения выходов. Другими словами, сплав, порошковый материал или покрытие фиксированного состава, полученные и обработанные по определенной схеме и режимам, имеют некоторый комплекс свойств. Сплав другого состава, обработанный по другим режимам, имеет и другие свойства. Точно ответить на вопрос, почему при изменении состава и режимов обработок изменились свойства сплава, нельзя (механизм явления либо плохо, либо совсем не известен), но важен лишь сам факт изменения свойств. Если теперь предположить, что между выходами и входами системы существует определенная связь (а она, без сомнения, существует), задача сводится к постановке минимально возможного числа экспериментов (выбору некоторого числа наборов уровней входов), фиксации выходов, а затем к построению и анализу математических моделей, связывающих выходы с входами.
Таким образом, нужно получить некоторое представление о так называемых функциях отклика:

Вид функций j исследователю заранее неизвестен. Поэтому, получая в опытах выборочные оценки выходов y , он вынужден строить приближенные уравнения функций отклика:

Эти уравнения в многомерном пространстве факторов называются факторным пространством . Они имеют некоторый геометрический образ – поверхность отклика . Следовательно, задача сводится к получению представления о поверхности отклика. Если задача экстремальная, надо найти экстремум (минимум или максимум) этой поверхности или сделать вывод, что экстремума нет. Если решается задача описания, необходимо попытаться выявить причины именно такого характера поверхности.
Свойства материалов, как и вообще любых других систем, можно описывать различными математическими моделями. Наибольшее применение нашли модели в виде алгебраических полиномов. Обычно используют разложение неизвестной функции отклика в ряд Тейлора в окрестности любой точки из области ее определения в факторном пространстве:
![]()
где ![]() ;
;  ;
;  .
.
Этот степенной ряд в общем случае бесконечен, но на практике ограничиваются конечным числом его членов, аппроксимируя тем самым неизвестную функцию j (х1 , х2 ,..., хk ) полиномом некоторой степени. Подобная аппроксимация имеет смысл, если функция отвечает ряду требований. Важнейшим из них является требование непрерывности и достаточной «гладкости» . Поскольку заранее неизвестно, насколько это требование выполняется, приходится делать допущения о том, что это так.
Модель строят по результатам экспериментов, т. е. определяют выборочные оценки коэффициентов b0 , bi , bij , bii :
![]()
где у – выборочная оценка функции отклика h.
Эксперимент можно проводить по-разному. В случае, когда исследователь наблюдает за каким-то неуправляемым процессом, не вмешиваясь в него, или выбирает экспериментальные точки интуитивно, эксперимент считают пассивным . В частности, такая ситуация возникает почти всегда, когда пользуются традиционными методами экспериментирования, изучая вначале влияние на свойства материала одной переменной при остальных постоянных, затем другой и т. д. Поскольку при этом немыслимо перебрать все возможные варианты, выполняют лишь часть опытов, причем обоснование выбранных вариантов почти никогда не бывает достаточно строгим. В этих случаях статистические методы применяют обычно после окончания экспериментов, когда данные уже получены. Здесь используют такие приемы, как подбор функций распределения, определение средних величин и мер рассеяния, анализ корреляций, регрессий и т. п.
Опыт показал, что указанный подход, особенно в задачах оптимизации, является неэффективным. Не останавливаясь на всех причинах этого обстоятельства, отметим лишь, что по результатам пассивного эксперимента можно, например, судить о наличии или отсутствии статистической связи между переменными, построить подходящие уравнения связи. Но этими уравнениями можно пользоваться только для интерполяции . Например, можно оценить в виде аналитического выражения, как изменяется прочность того или иного материала в зависимости от его состава и условий изготовления, но интерпретировать полученную модель, придавать какое-либо значение ее коэффициентам, использовать для целей оптимизации, как правило, нельзя. В настоящее время пассивный эксперимент достаточно широко используют в технологии металлов и материаловедении. Тем не менее, будущее, вероятно, не за ним, хотя в некоторых случаях и из пассивных наблюдений удается извлечь весьма ценную информацию.
Совсем иная картина наблюдается, когда исследователь начинает применять статистические методы на всех этапах исследования и, прежде всего, перед постановкой опытов, разрабатывая схему эксперимента, а также в процессе экспериментирования, при обработке результатов и после эксперимента, принимая решение о дальнейших действиях. Такой эксперимент называют активным , и он предполагает планирование эксперимента .
Под планированием эксперимента обычно понимают процедуру выбора числа и условий проведения опытов, необходимых и достаточных для решения поставленной задачи с требуемой точностью.
Основные преимущества активного эксперимента связаны с тем, что он позволяет:
- минимизировать общее число опытов;
- выбирать четкие, логически обоснованные процедуры, последовательно выполняемые экспериментатором при проведении исследования;
- использовать математический аппарат, формализующий многие действия экспериментатора;
- одновременно варьировать всеми переменными и оптимально использовать факторное пространство;
- организовать эксперимент таким образом, чтобы выполнялись многие исходные предпосылки регрессионного анализа;
- получать математические модели, имеющие более широкую область практического применения, нежели модели, построенные по результатам пассивного эксперимента;
- рандомизировать условия опытов, т. е. многочисленные несущественные факторы превратить в случайные величины;
- оценивать элемент неопределенности, связанный с экспериментом, что дает возможность сопоставлять результаты, получаемые разными исследователями.
Для того чтобы лучше себе представить, как реализуются идеи активного эксперимента, рассмотрим схему одного из наиболее широко используемых в настоящее время методов планирования эксперимента – метода крутого восхождения , предназначенного для решения экстремальных задач.
В этом методе, как и во многих других методах планирования эксперимента, задача решается поэтапно. На первом этапе, варьируя в каждом опыте сразу все факторы, исследователь ищет лишь направление движения к области экстремума. Для этого поверхность отклика изучают только на небольшом участке и строят для этого участка линейную модель:
![]() .
.
Анализ полученного уравнения позволяет наметить направление движения из исходной точки, наиболее быстро приводящее к оптимизации выбранного параметра. В дальнейшем на каждом этапе в соответствии с результатами, полученными на предыдущих этапах, ставят небольшую серию опытов, результаты которых вместе с интуитивными решениями исследователя определяют следующий шаг. Эта процедура заканчивается в области экстремума. Здесь ставят несколько большую серию опытов, и поверхность отклика описывают нелинейными функциями.
Анализ нелинейного уравнения позволяет точно определить координаты экстремума или сделать вывод, что экстремума не существует, а также наметить последующий путь оптимизации.
Сравним классический металловедческий подход и метод крутого восхождения на следующем примере. Предположим, что требуется найти состав наиболее прочного сплава на основе никеля, варьируя в нем содержание алюминия (х1 ) и тантала (х2 ). Предположим далее, что зависимость прочности (у) от состава для данных сплавов имеет вид, показанный на рис. 1, чего исследователь, приступая к решению задачи, естественно, не знает.
По интуитивным соображениям или на основании данных других исследований эксперимент начинают со сплава, отвечающего составу точки S1 . При традиционном экспериментировании исследователь начинает изменять в этом сплаве содержание одной из добавок при постоянном количестве другой, затем содержание другой при постоянном количестве первой. При таком подходе, начиная с точки S1 , вообще можно не найти оптимальный состав сплава (точка S6 ), поскольку движение по прямой от точки S1 в любую сторону не приводит к существенному упрочнению сплава (см. рис. 1).
Если далее экспериментатор сумеет перейти к другой исходной точке S2 , то, последовательно изменяя содержание алюминия и тантала, он найдет наиболее прочный сплав, однако этот путь будет достаточно длинным (S2 -S3 -S4 -S5 -S6 ).
Таким образом, традиционное экспериментирование, предполагающее поочередное изменение переменных, ведет к нерациональному расходованию времени и средств, тем более, что большая часть информации, полученная после подобной работы, часто вообще не представляет практического интереса, поскольку относится к области, далекой от оптимальных условий.
Та же задача методом крутого восхождения решается следующим образом. Вблизи точки S1 , начиная от которой при обычном экспериментировании успех вообще мог быть не достигнут, ставят небольшую серию из четырех опытов (точки 1, 2, 3, 4 на рис. 1). Цель этих опытов – еще не поиск состава наиболее прочного сплава. Определение прочности первых четырех сплавов позволяет исследователю приближенно описать неизвестную поверхность отклика на небольшом участке вблизи точки S1 , т. е. рассчитать коэффициенты регрессии уравнения:
![]() .
.

Рис. 1. Схема метода крутого восхождения: I – y = b0 + b1 x1 + b2 x2 ; II – y = b'0 + b'1 x1 + b'2 x2
Найденные по результатам опытов коэффициенты b1 и b2 определяют направление градиента для данной аппроксимирующей плоскости, т. е. направление изменения содержания алюминия и тантала в сплаве, приводящее к возможно более быстрому повышению прочности сплава. Сделав несколько опытов в этом направлении, т. е. осуществив крутое восхождение по поверхности отклика в направлении градиента линейного приближения (отсюда название метода), исследователь выбирает новую исходную точку S7 , возле которой вновь проводит аналогичную серию из четырех опытов, рассчитывает коэффициенты нового линейного приближения теперь уже вблизи точки S7 :
y = b'0 + b'1 x1 + b'2 x2
и осуществляет движение по градиенту этого уравнения. Движение по градиенту производят до попадания в область оптимума, после чего строят и анализируют нелинейную модель этой области. На рис. 1 градиент совпадает с прямой, перпендикулярной изолиниям, т. е. с самым крутым склоном, ведущим от данной точки к вершине. Для поверхности отклика, показанной на рис. 1, оказалось достаточно двух серий опытов, чтобы при крутом восхождении найти состав наиболее прочного сплава.
Даже рассмотренный пример показывает, что планирование эксперимента принципиально отличается от традиционного экспериментирования. При планировании используется многофакторная схема эксперимента , когда эффект влияния какого-либо фактора оценивается по результатам всех опытов. При традиционном экспериментировании (изменении одного фактора при постоянных остальных факторах) используется однофакторная схема , при которой эффект влияния фактора оценивается лишь по некоторой части опытов. Многофакторная схема существенно эффективней. Покажем это на простом примере.
Предположим, что необходимо определить массу трех образцов А, В и С. Рассмотрим два способа проведения эксперимента.
В первом случае схема взвешивания будет такой, как показано в табл. 1. Здесь первый опыт представляет собой холостое взвешивание, т. е. по сути дела, определение нулевого положения весов.
Следующие опыты – поочередное взвешивание каждого из образцов. Масса каждого образца оценивается по результатам только двух опытов: того опыта, в котором взвешивается образец, и холостого взвешивания. Например, масса образца А = у2 - у1 ; образца В = у3 - у1 ; образца С = у4 - у1 .
Схема взвешивания во втором случае показана в табл. 2.
Здесь в первом опыте взвешивают все три образца вместе (холостое взвешивание не производится), а в следующих опытах – каждый образец в отдельности. В этом случае массу каждого образца оценивают по результатам всех опытов. Действительно, масса образца ![]() ; образца
; образца ![]() ; образца
; образца ![]() .
.
Таблица 1
Схема однофакторного эксперимента по взвешиванию образцов А, В и С
| Номер опыта | А | В | С | Результаты взвешивания |
| 1 | - | - | - | y1 |
| 2 | + | - | - | y2 |
| 3 | - | + | - | y3 |
| 4 | - | - | + | y4 |
Таблица 2
Схема многофакторного эксперимента по взвешиванию образцов А, В и С
| Номер опыта | А | В | С | Результаты взвешивания |
| 1 | + | + | + | y1 |
| 2 | + | - | - | y2 |
| 3 | - | + | - | y3 |
| 4 | - | - | + | y4 |
Какой же из способов взвешивания лучше? Будем считать лучшим способом тот, который дает более высокую точность. Если воспользоваться законом сложения дисперсий, для первого способа взвешивания получим:
![]()
где ![]() – дисперсия результатов взвешивания образцов; Sy
– среднеквадратичная ошибка взвешивания.
– дисперсия результатов взвешивания образцов; Sy
– среднеквадратичная ошибка взвешивания.
Для второго способа ![]()
Оказывается, второй способ обеспечивает точность вдвое выше по сравнению с первым, хотя общее число опытов в обоих случаях одинаково. Произошло это по вполне понятной причине. Первый способ взвешивания является традиционной схемой эксперимента – типичной однофакторной. Несмотря на то, что здесь всего было сделано четыре опыта, массу каждого образца определяли только по результатам взвешивания двух образцов. Второй же способ представляет собой схему многофакторного эксперимента. Здесь массу образца определяли по результатам всех опытов, а это и дает выигрыш в точности. Чтобы получить результаты с той же точностью при традиционном экспериментировании, придется повторить все опыты, т. е. проделать по сути дела вдвое большую работу. Легко показать, что с увеличением числа факторов эффективность многофакторного эксперимента растет.
2. Исходные данные
В разделе “Исходные данные” следует привести факторный план эксперимента, который выдается в табличной форме в задании на самостоятельную работу, дать характеристику факторного плана по равномерности дублирования экспериментов в каждом опыте и дать краткое описание (расшифровку) факторного плана.
По равномерности дублирования экспериментов различают факторные планы с равномерным (табл. 3) и неравномерным дублированием. Под дублированием понимается не серия измерений в одном опыте (“несколько образцов на точку”), а полное повторение опыта: приготовление сплава заново, новое проведение всех технологических операций механической обработки образцов и их подготовки к испытаниям.
Равномерное дублирование предполагает повторение экспериментов в каждой серии опытов одинаковое число раз (дублей). В рассматриваемом примере полного факторного плана с равномерным дублированием (табл. 3) количество дублей составляет 3 на каждую серию опытов, а количество опытов – 8. Таким образом, для постановки эксперимента необходимо 24 образца.
Неравномерное дублирование предполагает повторение экспериментов в каждой серии опытов неодинаковое число раз. На практике неравномерное дублирование экспериментов используется сравнительно редко из-за сложности построения регрессионных моделей по получаемым опытным данным.
При решении прикладных задач материаловедения количество дублей в каждом опыте принимают не менее 3-х. Это обусловлено следующим обстоятельством. При изучении свойств большинства материалов одними из наиболее существенных факторов, которые эти свойства определяют, являются элементы химического состава материалов. Следовательно, план эксперимента предусматривает приготовление ряда сплавов определенного химического состава. Но готовить сплавы точно заданного состава (а этого требуют предпосылки регрессионного анализа ) не всегда просто. В том случае, когда попадание в состав неудовлетворительно, как и во всех остальных случаях непопадания факторов на заданный уровень, можно попытаться учесть ошибки в определении факторов. Однако когда фиксация факторов на заданных уровнях происходит с очень большими нарушениями, факторы (независимые переменные) можно считать случайными переменными, значения которых меняются от одного опыта к другому в соответствии с некоторым распределением. В этом случае следует вообще отказаться от использования регрессионного анализа и воспользоваться, например, конфлюэнтным анализом.
Расшифруем матрицу планирования с равномерным дублированием экспериментов, приведенную в табл. 3. Цельюисследований являлось изучение влияния химического состава чугунных тормозных колодок на их износостойкость (y) в условиях сухого трения в трибосопряжении с контртелом из закаленной стали 45. Всего было произведено восемь серий опытов. Каждый опыт дублировался 3 раза, следовательно, дублирование равномерное.
Варьируемыми факторами (независимыми переменными) являлись концентрации легирующих элементов в чугуне: алюминия (x1 ), марганца (x2 ), углерода (x3 ). Пределы варьирования химического состава чугуна (см. табл. 3): Al – 10,8…11,0 %, интервал варьирования 0,1 %; Mn – 1,2…1,8 %, интервал варьирования 0,3 %; С – 31,4…32,6 %, интервал варьирования 0,6 %. Условно содержание легирующих элементов по верхнему и нижнему пределам (уровням) обозначены через кодированные значения факторов “Хi = +1” и “ Хi = -1”. Верхний уровень “ Хi = +1” соответствует максимальному содержанию легирующего элемента, нижний уровень “ Хi = -1” – минимальному его содержанию.
Таким образом, переменные хi задают химический состав сплава через концентрацию легирующих элементов в натуральном виде, а переменные Хi – в кодированном виде соответственно через верхний (Хi = +1) и нижний (Хi = -1) уровни (табл. 3). В дальнейшем для построения регрессионной модели сначала будут использоваться кодированные значения факторов Хi , а затем будет производиться переход от кодированных значений факторов к их фактическим значениям хi .
Таблица 3
Матрица плана ПФЭ 23 с равномерным дублированием экспериментов
| Варьируемый фактор | Натуральные (фактические) значения факторов | Значения yiu (интенсивность изнашивания, г/см2 ) | ||||
| х1 (% Al) | х2 (% Mn) | х3 (% С) | ||||
| Основной уровень, хi0 | 10,9 | 1,5 | 32,0 | |||
| Интервал варьирования, Dхi | 0,1 | 0,3 | 0,6 | |||
| Верхний уровень, хi(max) (Хi = +1) | 11,0 | 1,8 | 32,6 | |||
| Нижний уровень, хi(min) (Хi = -1) | 10,8 | 1,2 | 31,4 | |||
| № опыта, u | Кодированные значения факторов и соответствующие им (в скобках) натуральные значения | Номер дубля | ||||
| Х1 (Al) | Х2 (Mn) | X3 (С) | 1 | 2 | 3 | |
| u = 1 | -1 (10,8 %) | -1 (1,2 %) | -1 (31,4%) | 97,8 | 99,4 | 94,6 |
| u = 2 | +1 (11,0 %) | -1 (1,2 %) | -1 (31,4%) | 128,3 | 130,0 | 124,4 |
| u = 3 | -1 (10,8 %) | +1 (1,8 %) | -1 (31,4%) | 152,1 | 149,4 | 159,6 |
| u = 4 | +1 (11,0 %) | +1 (1,8 %) | -1 (31,4%) | 73,8 | 71,2 | 70,7 |
| u = 5 | -1 (10,8 %) | -1 (1,2 %) | +1(32,6%) | 110,3 | 118,5 | 112,2 |
| u = 6 | +1 (11,0 %) | -1 (1,2 %) | +1(32,6%) | 93,8 | 91,1 | 90,4 |
| u = 7 | -1 (10,8 %) | +1 (1,8 %) | +1(32,6%) | 126,2 | 130,3 | 124,8 |
| u = 8 | +1 (11,0 %) | +1 (1,8 %) | +1(32,6%) | 114,2 | 110,4 | 111,9 |
В соответствии с данными табл. 3 для построения регрессионной зависимости интенсивности изнашивания чугунных тормозных колодок от содержания в них углерода, алюминия и кремния необходимо произвести 24 эксперимента. Для того чтобы исключить влияние систематических ошибок, вызванных различными внешними условиями, данные эксперименты проводятся рандомизированно во времени, т. е. в случайной последовательности.
3. Расчет дисперсии опыта
Построчная дисперсия ![]() для каждого эксперимента определяется по формуле:
для каждого эксперимента определяется по формуле:
 (1)
(1)
![]() (2)
(2)
где g и nu
- номер и количество дублей эксперимента соответственно; ![]() - результат g-го повторения u-го эксперимента;
- результат g-го повторения u-го эксперимента; ![]() - среднее арифметическое значение всех дублей u - го эксперимента; fu
- число степеней свободы в u - м опыте при определении u - й построчной дисперсии
- среднее арифметическое значение всех дублей u - го эксперимента; fu
- число степеней свободы в u - м опыте при определении u - й построчной дисперсии ![]() .
.
Число степеней свободы – понятие, учитывающее в статистических ситуациях связи, ограничивающие свободу изменения случайных величин. Это число определяется как разность между числом выполненных опытов и числом констант (средних, коэффициентов и пр.), подсчитанных по результатам тех же опытов.
В нашем случае nu = 3, fu = 3 - 1 = 2. Тогда выражение (1) можно переписать следующим образом:
 (3)
(3)
Построчная дисперсия по выражению (3) рассчитывается для каждого u - го опыта отдельно. Результаты расчетов построчной дисперсии приведены в табл. 4.
Таблица 4
Результаты расчета построчной дисперсии
Номер опыта, u |
Номер дубля, g | Удельная потеря массы, |
Среднее арифметическое значение интенсивности изнашивания, |
Построчная дисперсия, |
| 1 | 1 | 97,8 | 97,3 | 5,975 |
| 2 | 99,4 | |||
| 3 | 94,6 | |||
| 2 | 1 | 128,3 | 127,6 | 8,245 |
| 2 | 130,0 | |||
| 3 | 124,4 | |||
| 3 | 1 | 152,1 | 153,7 | 27,93 |
| 2 | 149,4 | |||
| 3 | 159,6 | |||
| 4 | 1 | 73,8 | 71,9 | 2,77 |
| 2 | 71,2 | |||
| 3 | 70,7 | |||
| 5 | 1 | 110,3 | 113,7 | 18,43 |
| 2 | 118,5 | |||
| 3 | 112,2 | |||
| 6 | 1 | 93,8 | 91,8 | 3,225 |
| 2 | 91,1 | |||
| 3 | 90,4 | |||
| 7 | 1 | 126,2 | 127,1 | 8,17 |
| 2 | 130,3 | |||
| 3 | 124,8 | |||
| 8 | 1 | 114,2 | 112,2 | 3,665 |
| 2 | 110,4 | |||
| 3 | 111,9 |
регрессия дисперсия дублирование
Приведем пример расчета построчной дисперсии в первом опыте (u = 1):

После определения построчных дисперсий производят проверку воспроизводимости экспериментальных данных. Проверка выполняется в том случае, если имеет место дублирование опытов, что является обязательным правилом при проведении планированного эксперимента. На этой стадии проверяется гипотеза о постоянстве дисперсии шума с использованием критерия Кохрена. Проверка данной гипотезы позволяет судить об однородности или неоднородности ряда дисперсий. Если ряд дисперсий однороден, различные значения функции отклика (y) определяются с одинаковой точностью. Если ряд дисперсий неоднороден, различные значения функции отклика (y) определяются с разной точностью.
Процедура проверки статистических гипотез в общем случае формально предусматривает сравнение некоторого критерия, рассчитанного по экспериментальным данным, с его табличным значением при выбранном заранее уровне значимости a. Уровень значимости a определяет наибольшую вероятность отвергнуть правильную гипотезу, т. е. наибольшую вероятность предположения о том, что экспериментальный результат ошибочен. Например, если уровень значимости выбирают равным 0,05 (что, очень часто делается в технических задачах), то это означает, что допускается 5%-ная вероятность неверного решения и доверительная 95%-ная вероятность верного.
Если найденное по экспериментальным данным значение критерия попадает в область, соответствующую уровню значимости, то проверяемая гипотеза неверна и ее следует отвергнуть, совершив ошибку с вероятностью a. Если же экспериментальное значение критерия попадает в область, соответствующую вероятности (1-a), то проверяемую гипотезу принимают, совершив ошибку, связанную уже с альтернативной гипотезой.
Расчетное значение критерия Кохрена рассчитывается по формуле:
 , (4)
, (4)
где ![]() - наибольшая в ряду дисперсия, которую сравнивают со значением G - критерия, взятым из табл. А1 (приложение А) в зависимости от уровня значимости a, числа степеней свободы fu
и числа опытов N: G(a; fu
; N). В рассматриваемом случае fu
= 2; N = 8.
- наибольшая в ряду дисперсия, которую сравнивают со значением G - критерия, взятым из табл. А1 (приложение А) в зависимости от уровня значимости a, числа степеней свободы fu
и числа опытов N: G(a; fu
; N). В рассматриваемом случае fu
= 2; N = 8.
Из табл. 4 находим максимальную построчную дисперсию ![]() и
и![]() Тогда G pacч
= 27,93/78,4 = 0,356.
Тогда G pacч
= 27,93/78,4 = 0,356.
Приняв значение уровня значимости a = 0,05, для числа степеней свободы fu
= 2 и числа опытов N = 8 получим следующее табличное значение G-критерия: ![]() .
.
Если G pacч
< ![]() , ряд дисперсий однороден. Если G pacч
>
, ряд дисперсий однороден. Если G pacч
>![]() , ряд дисперсий неоднороден.
, ряд дисперсий неоднороден.
В рассматриваемом примере G pacч
>![]() , т.е. ряд дисперсий неоднороден. Обычно такая ситуация возникает, если среди анализируемых экспериментальных данных имеются грубые ошибки или промахи, связанные с ошибками, допущенными при проведении эксперимента. В таком случае эксперимент следует повторить, тщательно проанализировав его с методологической точки зрения и уделив особое внимание методике сбора и обработки экспериментальных данных. Если при тщательном анализе экспериментальных данных грубых ошибок и промахов не выявлено, неоднородность ряда дисперсий означает, что значения функции отклика (y) действительно определены с разной точностью, однако в каждом отдельном опыте уровень шумов (ошибок) не выходит за границы допустимых значений. Именно такой вывод справедлив для результатов измерений и расчетов, представленных в табл. 4. Во всех дублях значения функции отклика
, т.е. ряд дисперсий неоднороден. Обычно такая ситуация возникает, если среди анализируемых экспериментальных данных имеются грубые ошибки или промахи, связанные с ошибками, допущенными при проведении эксперимента. В таком случае эксперимент следует повторить, тщательно проанализировав его с методологической точки зрения и уделив особое внимание методике сбора и обработки экспериментальных данных. Если при тщательном анализе экспериментальных данных грубых ошибок и промахов не выявлено, неоднородность ряда дисперсий означает, что значения функции отклика (y) действительно определены с разной точностью, однако в каждом отдельном опыте уровень шумов (ошибок) не выходит за границы допустимых значений. Именно такой вывод справедлив для результатов измерений и расчетов, представленных в табл. 4. Во всех дублях значения функции отклика ![]() очень плотно группируются относительно средних значений
очень плотно группируются относительно средних значений ![]() .
.
4. Расчет коэффициентов регрессии
Модель изучаемого процесса представим в виде обобщенного уравнения:
y = b0 + S(bi Xi ) + S(bij Xi Xj ) + b123 X1 X2 X3 . (5)
Применительно к трехфакторному эксперименту уравнение (5) можно записать в виде:
y = b0 + b1 X1 + b2 X2 + b3 X3 + b12 X1 Х2 + b13 X1 Х3 + b23 X2 Х3 + b123 X1 X2 X3 , (6)
где X1 , X2 , X3 – кодированные значения уровней факторов (табл. 3). Кодированные значения уровней факторов в уравнении (6) могут принимать значения +1 и -1.
Коэффициенты уравнения регрессии (6) рассчитываются по зависимости:
 (7)
(7)
где u - номер опыта; ![]() - кодированные значения уровней варьируемых факторов /независимых переменных X1
(Al), X2
(Mn), X3
(С) / (табл. 3);
- кодированные значения уровней варьируемых факторов /независимых переменных X1
(Al), X2
(Mn), X3
(С) / (табл. 3); ![]() - средние арифметические значения функции отклика (интенсивности изнашивания) (табл. 4).
- средние арифметические значения функции отклика (интенсивности изнашивания) (табл. 4).
Распишем уравнение (7) для всех коэффициентов, входящих в регрессионную модель (6):



 (8)
(8)




Для расчета коэффициентов регрессии составим расширенную матрицу планирования (табл. 5).
Таблица 5
Расширенная матрица плана 23
Номер опыта |
Х0 | Х1 | Х2 | Х3 | Х4 = Х1 Х2 | Х5 = Х1 Х3 | Х6 = Х2 Х3 | Х7 = Х1 Х2 Х3 | |
| 1 | +1 | -1 | -1 | -1 | +1 | +1 | +1 | -1 | 97,3 |
| 2 | +1 | +1 | -1 | -1 | -1 | -1 | +1 | +1 | 127,6 |
| 3 | +1 | -1 | +1 | -1 | -1 | +1 | -1 | +1 | 153,7 |
| 4 | +1 | +1 | +1 | -1 | +1 | -1 | -1 | -1 | 71,9 |
| 5 | +1 | -1 | -1 | +1 | +1 | -1 | -1 | +1 | 113,7 |
| 6 | +1 | +1 | -1 | +1 | -1 | +1 | -1 | -1 | 91,8 |
| 7 | +1 | -1 | +1 | +1 | -1 | -1 | +1 | -1 | 127,1 |
| 8 | +1 | +1 | +1 | +1 | +1 | +1 | +1 | +1 | 112,2 |
Рассчитаем коэффициенты в уравнении регрессии (6) по зависимостям (8) с учетом знаков Хi в столбцах табл. 5:





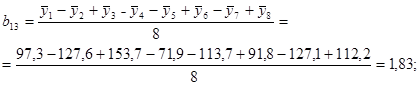


Таким образом, получены следующие значения коэффициентов уравнения регрессии:
b0 = 111,9; b12 = b4 = -13,14;
b1 = -11,03; b13 = b5 = 1,83;
b2 = 34,5; b23 = b6 = 4,13;
b3 = -0,7125; b123 = b7 = 14,89.
Если ввести обозначения b12 = b4 ; b13 = b5 ; b23 = b6 ; b123 = b7 и учесть обозначения, принятые в табл. 5, регрессионное уравнение (6) запишется в виде:
y = b0 + b1 X1 + b2 X2 + b3 X3 + b4 X4 + b5 X5 + b6 X6 + b7 X7. (9)
5. Проверка статистической значимости коэффициентов регрессии
Коэффициенты регрессии, рассчитанные по уравнению (7), строго говоря, определены не точно, а с некоторой погрешностью. Мерой этой погрешности является дисперсия оценок коэффициентов
. Неизбежное наличие погрешности в определении коэффициентов регрессии обусловлено колебаниями значений функции отклика при дублировании экспериментов в каждом опыте. С учетом этого уравнение (7) можно записать в следующем виде:  Очевидно, что при достаточно малых значениях коэффициентов bi
абсолютная погрешность их определения 2×Dbi
, обусловленная погрешностью определения значений функции отклика, может оказаться недопустимо большой. В этом случае значение коэффициента следует признать статистически незначимым, а сам коэффициент исключить из регрессионной модели. Статистическая незначимость коэффициента означает отсутствие его влияния на исследуемый процесс.
Очевидно, что при достаточно малых значениях коэффициентов bi
абсолютная погрешность их определения 2×Dbi
, обусловленная погрешностью определения значений функции отклика, может оказаться недопустимо большой. В этом случае значение коэффициента следует признать статистически незначимым, а сам коэффициент исключить из регрессионной модели. Статистическая незначимость коэффициента означает отсутствие его влияния на исследуемый процесс.
Поскольку дублирование экспериментов равномерное, дисперсию оценок коэффициентов уравнения регрессии можно рассчитать по зависимости:
 , (10)
, (10)
где nu
– количество дублей в каждом опыте (nu
= 3); N – количество опытов (N = 8); ![]() - средняя дисперсия эксперимента.
- средняя дисперсия эксперимента.
Если ряд дисперсий однороден, средняя дисперсия эксперимента рассчитывается по уравнению:
 , (11)
, (11)
где ![]() - значения построчных дисперсий (табл. 4).
- значения построчных дисперсий (табл. 4).
Если ряд дисперсий неоднороден (значения функции отклика в разных опытах определены с различной точностью), но в результатах измерений значений функции отклика отсутствуют грубые ошибки и промахи, в качестве средней дисперсии эксперимента принимается максимальная построчная дисперсия
. В соответствии с данными табл. 4 максимальная построчная дисперсия получена в первом опыте: ![]() . Ее значение и принимаем как среднюю дисперсию эксперимента:
. Ее значение и принимаем как среднюю дисперсию эксперимента:![]() . Тогда дисперсия оценок коэффициентов регрессии равна
. Тогда дисперсия оценок коэффициентов регрессии равна ![]()
Среднеквадратичная ошибка ![]() оценки коэффициентов регрессии определяется как:
оценки коэффициентов регрессии определяется как:
![]() . (12)
. (12)
Для рассматриваемого случая ![]()
Рассчитаем доверительный интервал коэффициентов регрессии ![]() :
:
![]() , (13)
, (13)
где ![]() - критерий Стьюдента, зависящий от уровня значимости a и числа степеней свободы f2
при определении дисперсии эксперимента:
- критерий Стьюдента, зависящий от уровня значимости a и числа степеней свободы f2
при определении дисперсии эксперимента:
![]()
Для полного факторного эксперимента 23 f2 = (3-1)×8 = 16.
Выбрав уровень значимости a = 0,05, при числе степеней свободы f2
= 16 из табл. Б1 (приложение Б) найдем табличное значение критерия Стьюдента (t-критерия) t0,05;16
= 2,12. По выражению (13) рассчитаем доверительный интервал коэффициентов регрессии: ![]()
Коэффициенты уравнения регрессии, абсолютная величина которых равна доверительному интервалу или больше его, следует признать статистически значимыми. Т.е. для статистически значимых коэффициентов должно выполняться условие:
![]() или
или ![]() . (14)
. (14)
Условие (14) означает, что абсолютные значения статистически значимых коэффициентов регрессии bi
должны не менее чем в ![]() раз превышать абсолютную ошибку их определения
раз превышать абсолютную ошибку их определения ![]() .
.
Статистически значимыми коэффициентами, точность оценки которых можно считать удовлетворительной, являются коэффициенты b0 , b1 , b2 , b12 = b4, b13 = b5 , b23 = b6 и b123 = b7 .
Статистически незначимые коэффициенты (b3 ) из модели следует исключить, поскольку их значения не могут считаться достоверными.
Подставляя значения статистически значимых коэффициентов в выражение (9), получим следующее уравнение регрессии:
![]() . (15)
. (15)
6. Проверка адекватности модели
Процедура проверки адекватности модели сводится к выполнению ряда последовательных вычислений:
1. Расчет теоретических значений функции отклика в каждом опыте по уравнению (15).
2. Сопоставление расчетных и экспериментальных значений функции отклика и нахождение дисперсии неадекватности.
3. Расчет критерия Фишера и окончательный вывод на основе сопоставления его расчетного и табличного значений об адекватности или неадекватности модели.
С помощью полученного уравнения (15) определим расчетные значения функции отклика (удельной потери массы y). Все значения Хi в данное уравнение входят в кодовом масштабе. Например, в 4-м опыте х1 = +1, х2 = +1, х3 = -1, х4 = +1, х7 = -1 (табл. 3, 5). Тогда расчетное значение удельной потери массы в этом опыте будет равно:
у(4) = 111,9-11,03+34,5-13,14-1,83-4,13-14,89= 101,38 г/см2 .
Подсчитанные таким образом значения удельной потери массы приведены в табл. 6. Данные табл. 4 будем использовать для определения дисперсии неадекватности. При равномерном дублировании экспериментов дисперсия неадекватности ![]() определяется по зависимости:
определяется по зависимости:
 ;
; ![]() , (16)
, (16)
где ![]() и
и ![]() - значения функции отклика в u-м эксперименте, соответственно рассчитанные по уравнению регрессии и определенные экспериментально; f1
– число степеней свободы;
- значения функции отклика в u-м эксперименте, соответственно рассчитанные по уравнению регрессии и определенные экспериментально; f1
– число степеней свободы; ![]() - число оставленных коэффициентов уравнения регрессии, включая b0
(
- число оставленных коэффициентов уравнения регрессии, включая b0
(![]() ); N - число опытов плана (N = 8). Тогда f1
= 8 - 7 = 1.
); N - число опытов плана (N = 8). Тогда f1
= 8 - 7 = 1.
Таким образом, если из регрессионной модели исключен, хотя бы один статистически незначимый коэффициент (а это неизбежно, если варьируемые факторы действительно являются независимыми переменными), массив разностей ![]() будет содержать информацию об ошибках в предсказании значений функции отклика.
будет содержать информацию об ошибках в предсказании значений функции отклика.
Таблица 6
Сопоставление экспериментальных и расчетных данных
| Номер эксперимента, u |  |
|||
| 1 | 97,3 | 66,36 | 30,94 | 957,3 |
| 2 | 127,6 | 96,7 | 30,9 | 954,8 |
| 3 | 153,7 | 183,16 | -29,46 | 867,9 |
| 4 | 71,9 | 101,38 | -29,48 | 869,1 |
| 5 | 113,7 | 84,22 | 29,48 | 869,1 |
| 6 | 91,8 | 62,32 | 29,48 | 869,1 |
| 7 | 127,1 | 157,98 | -30,88 | 953,6 |
| 8 | 112,2 | 143,08 | -30,88 | 953,6 |
В рассматриваемом случае построенная модель (15) включает шесть коэффициентов: ![]() . Тогда в соответствии с выражением (16)
. Тогда в соответствии с выражением (16) ![]() .
.
Гипотеза об адекватности модели (15) проверяется по критерию Фишера. Его расчетное значение находим по уравнению:
 . (17)
. (17)
![]() .
.
Из выражения (17) следует, что расчетное значение критерия Фишера представляет собой отношение дисперсии неадекватности к дисперсии опыта. По сути дела он позволяет ответить на вопрос: во сколько раз модель предсказывает значения функции отклика хуже по сравнению с опытом? Тогда табличное значение критерия Фишера должно регламентировать допустимое отклонение расчетных значений функции отклика относительно опытных данных.
Табличное значение критерия Фишера определяется в зависимости от уровня значимости a и числа степеней свободы f1
и f2
, определенных ранее: F(a; f1
; f2
). При уровне значимости a = 0,05 табличное значение F - критерия (табл. В1, приложение В) равно ![]() .
.
7. Анализ модели
Все соображения о направлении и силе влияния изученных факторов на износостойкость чугунных тормозных колодок можно высказать только для выбранных интервалов их изменения.
Из анализа полученного уравнения регрессии (15), можно сделать вывод о том, что наиболее существенно увеличивает износостойкость фактор X3 (С), а значит, для изготовления тормозных колодок следует использовать чугун с максимальным содержанием углерода: 3,8 мас. %.
Установлено, что наименьшие удельные потери массы (0,071 г/cм2 ) получены на образце № 7 (Al - 2,5 %, Mn - 12 %, С - 3,8 %) (табл. 6).
ПРИЛОЖЕНИЕ А
Таблица А1
Критические значения G-критерия (критерия Кохрена) при уровне значимости a = 0,05
| Число опытов, N | Число степеней свободы, |
||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 16 | 36 | 144 | |
| 2 | 0,999 | 0,975 | 0,939 | 0,906 | 0,858 | 0,853 | 0,833 | 0,816 | 0,801 | 0,788 | 0,734 | 0,66 | 0,581 |
| 3 | 0,967 | 0,871 | 0,798 | 0,746 | 0,707 | 0,677 | 0,653 | 0,633 | 0,617 | 0,603 | 0,547 | 0,475 | 0,403 |
| 4 | 0,907 | 0,768 | 0,684 | 0,629 | 0,59 | 0,56 | 0,537 | 0,518 | 0,502 | 0,488 | 0,437 | 0,372 | 0,309 |
| 5 | 0,841 | 0,684 | 0,598 | 0,544 | 0,506 | 0,478 | 0,456 | 0,439 | 0,424 | 0,412 | 0,365 | 0,307 | 0,251 |
| 6 | 0,781 | 0,616 | 0,532 | 0,48 | 0,445 | 0,418 | 0,398 | 0,382 | 0,368 | 0,357 | 0,314 | 0,261 | 0,212 |
| 7 | 0,727 | 0,561 | 0,48 | 0,431 | 0,391 | 0,373 | 0,356 | 0,338 | 0,325 | 0,315 | 0,276 | 0,228 | 0,183 |
| 8 | 0,68 | 0,516 | 0,438 | 0,391 | 0,36 | 0,336 | 0,319 | 0,304 | 0,293 | 0,283 | 0,246 | 0,202 | 0,162 |
| 9 | 0,64 | 0,478 | 0,403 | 0,358 | 0,329 | 0,307 | 0,29 | 0,277 | 0,266 | 0,257 | 0,223 | 0,182 | 0,145 |
| 10 | 0,602 | 0,445 | 0,373 | 0,331 | 0,303 | 0,282 | 0,267 | 0,254 | 0,244 | 0,235 | 0,203 | 0,166 | 0,131 |
| 12 | 0,541 | 0,392 | 0,326 | 0,288 | 0,262 | 0,244 | 0,23 | 0,219 | 0,21 | 0,202 | 0,174 | 0,14 | 0,11 |
| 15 | 0,471 | 0,335 | 0,276 | 0,242 | 0,22 | 0,203 | 0,191 | 0,182 | 0,174 | 0,167 | 0,143 | 0,114 | 0,089 |
| 20 | 0,389 | 0,271 | 0,221 | 0,192 | 0,174 | 0,16 | 0,15 | 0,142 | 0,136 | 0,13 | 0,111 | 0,088 | 0,068 |
| 24 | 0,343 | 0,235 | 0,191 | 0,166 | 0,149 | 0,137 | 0,129 | 0,121 | 0,116 | 0,111 | 0,094 | 0,074 | 0,057 |
| 30 | 0,293 | 0,198 | 0,159 | 0,138 | 0,124 | 0,114 | 0,106 | 0,1 | 0,096 | 0,092 | 0,077 | 0,06 | 0,046 |
| 40 | 0,237 | 0,158 | 0,126 | 0,108 | 0,097 | 0,089 | 0,083 | 0,078 | 0,075 | 0,071 | 0,06 | 0,046 | 0,035 |
| 60 | 0,174 | 0,113 | 0,09 | 0,077 | 0,068 | 0,062 | 0,058 | 0,055 | 0,052 | 0,05 | 0,041 | 0,032 | 0,023 |
| 120 | 0,1 | 0,063 | 0,05 | 0,042 | 0,037 | 0,034 | 0,031 | 0,029 | 0,028 | 0,027 | 0,022 | 0,017 | 0,012 |
ПРИЛОЖЕНИЕ Б
Таблица Б1
Критические значения t-критерия (критерия Стьюдента)
| Число степеней свободы, |
Уровень значимости, a | Число степеней свободы, |
Уровень значимости, a | ||||
| 0,1 | 0,05 | 0,01 | 0,1 | 0,05 | 0,01 | ||
| 1 | 6,31 | 12,7 | 63,66 | 16 | 1,75 | 2,12 | 2,92 |
| 2 | 2,92 | 4,3 | 9,93 | 17 | 1,74 | 2,11 | 2,9 |
| 3 | 2,35 | 3,18 | 5,84 | 18 | 1,73 | 2,1 | 2,88 |
| 4 | 2,13 | 2,78 | 4,6 | 19 | 1,73 | 2,09 | 2,86 |
| 5 | 2,02 | 2,57 | 4,03 | 20 | 1,73 | 2,08 | 2,85 |
| 6 | 1,94 | 2,45 | 3,71 | 21 | 1,72 | 2,08 | 2,83 |
| 7 | 1,9 | 2,37 | 3,5 | 22 | 1,72 | 2,07 | 2,82 |
| 8 | 1,86 | 2,31 | 3,36 | 23 | 1,71 | 2,07 | 2,81 |
| 9 | 1,83 | 2,26 | 3,25 | 24 | 1,71 | 2,06 | 2,8 |
| 10 | 1,81 | 2,23 | 3,17 | 25 | 1,71 | 2,06 | 2,79 |
| 11 | 1,8 | 2,2 | 3,11 | 26 | 1,71 | 2,06 | 2,78 |
| 12 | 1,78 | 2,18 | 3,06 | 27 | 1,7 | 2,05 | 2,77 |
| 13 | 1,77 | 2,16 | 3,01 | 28 | 1,7 | 2,05 | 2,76 |
| 14 | 1,76 | 2,15 | 2,98 | 29 | 1,7 | 2,04 | 2,75 |
| 15 | 1,75 | 2,13 | 2,95 | 30 | 1,7 | 2,04 | 2,75 |
ПРИЛОЖЕНИЕ В
Таблица В1
Значения критерия Фишера (F-критерия) при уровне значимости a = 0,05
| Число степеней свободы, |
Число степеней свободы, |
|||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 12 | 14 | 16 | 20 | 24 | 30 | |
| 2 | 18,51 | 19 | 19,16 | 19,25 | 19,3 | 19,33 | 19,36 | 19,37 | 19,38 | 19,39 | 19,41 | 19,42 | 19,43 | 19,44 | 19,45 | 19,46 |
| 3 | 10,13 | 9,55 | 9,28 | 9,12 | 9,01 | 8,94 | 8,88 | 8,84 | 8,81 | 8,78 | 8,74 | 8,71 | 8,69 | 8,66 | 8,64 | 8,62 |
| 4 | 7,71 | 6,94 | 6,59 | 6,39 | 6,26 | 6,16 | 6,09 | 6,04 | 6 | 5,96 | 5,91 | 5,87 | 5,84 | 5,8 | 5,77 | 5,74 |
| 5 | 6,61 | 5,79 | 5,41 | 5,19 | 5,05 | 4,95 | 4,88 | 4,82 | 4,78 | 4,74 | 4,68 | 4,64 | 4,6 | 4,56 | 4,53 | 4,5 |
| 6 | 5,99 | 5,14 | 4,76 | 4,53 | 4,39 | 4,28 | 4,21 | 4,15 | 4,1 | 4,06 | 4 | 3,96 | 3,92 | 3,87 | 3,84 | 3,81 |
| 7 | 5,59 | 4,74 | 4,35 | 4,12 | 3,97 | 3,87 | 3,79 | 3,73 | 3,68 | 3,63 | 3,57 | 3,52 | 3,49 | 3,44 | 3,41 | 3,38 |
| 8 | 5,32 | 4,46 | 4,07 | 3,84 | 3,69 | 3,58 | 3,5 | 3,44 | 3,39 | 3,34 | 3,28 | 3,23 | 3,2 | 3,15 | 3,12 | 3,08 |
| 9 | 5,12 | 4,26 | 3,86 | 3,63 | 3,48 | 3,37 | 3,29 | 3,23 | 3,18 | 3,13 | 3,07 | 3,02 | 2,98 | 2,93 | 2,9 | 2,86 |
| 10 | 4,96 | 4,1 | 3,71 | 3,48 | 3,33 | 3,22 | 3,14 | 3,07 | 3,02 | 2,97 | 2,91 | 2,86 | 2,82 | 2,77 | 2,74 | 2,7 |
| 11 | 4,84 | 3,98 | 3,59 | 3,36 | 3,2 | 3,09 | 3,01 | 2,95 | 2,9 | 2,86 | 2,79 | 2,74 | 2,7 | 2,65 | 2,61 | 2,57 |
| 12 | 4,75 | 3,88 | 3,49 | 3,26 | 3,11 | 3 | 2,92 | 2,85 | 2,8 | 2,76 | 2,69 | 2,64 | 2,6 | 2,54 | 2,5 | 2,46 |
| 13 | 4,67 | 3,8 | 3,41 | 3,18 | 3,02 | 2,92 | 2,84 | 2,77 | 2,72 | 2,67 | 2,6 | 2,55 | 2,51 | 2,46 | 2,42 | 2,38 |
| 14 | 4,6 | 3,74 | 3,34 | 3,11 | 2,96 | 2,85 | 2,77 | 2,7 | 2,65 | 2,6 | 2,53 | 2,48 | 2,44 | 2,39 | 2,35 | 2,31 |
| 15 | 4,54 | 3,68 | 3,29 | 3,06 | 2,9 | 2,79 | 2,7 | 2,64 | 2,59 | 2,55 | 2,48 | 2,43 | 2,39 | 2,33 | 2,29 | 2,25 |
| 16 | 4,49 | 3,63 | 3,24 | 3,01 | 2,85 | 2,74 | 2,66 | 2,59 | 2,54 | 2,49 | 2,42 | 2,37 | 2,33 | 2,28 | 2,24 | 2,2 |
| 17 | 4,45 | 3,59 | 3,2 | 2,96 | 2,81 | 2,7 | 2,62 | 2,55 | 2,5 | 2,45 | 2,38 | 2,33 | 2,29 | 2,23 | 2,19 | 2,15 |
| 18 | 4,41 | 3,55 | 3,16 | 2,93 | 2,77 | 2,66 | 2,58 | 2,51 | 2,46 | 2,41 | 2,34 | 2,29 | 2,25 | 2,19 | 2,15 | 2,11 |
| 19 | 4,38 | 3,52 | 3,13 | 2,9 | 2,74 | 2,63 | 2,55 | 2,48 | 2,43 | 2,38 | 2,31 | 2,26 | 2,21 | 2,15 | 2,11 | 2,07 |
| 20 | 4,35 | 3,49 | 3,1 | 2,87 | 2,71 | 2,6 | 2,52 | 2,45 | 2,4 | 2,35 | 2,28 | 2,23 | 2,18 | 2,12 | 2,08 | 2,04 |
| 21 | 4,32 | 3,47 | 3,07 | 2,84 | 2,68 | 2,57 | 2,49 | 2,42 | 2,37 | 2,32 | 2,25 | 2,2 | 2,15 | 2,09 | 2,05 | 2 |
| 22 | 4,3 | 3,44 | 3,05 | 2,82 | 2,66 | 2,55 | 2,47 | 2,4 | 2,35 | 2,3 | 2,23 | 2,18 | 2,13 | 2,07 | 2,03 | 1,98 |
| 23 | 4,28 | 3,42 | 3,03 | 2,8 | 2,64 | 2,53 | 2,45 | 2,38 | 2,32 | 2,28 | 2,2 | 2,14 | 2,1 | 2,05 | 2 | 1,96 |
| 24 | 4,26 | 3,4 | 3,01 | 2,78 | 2,62 | 2,51 | 2,43 | 2,36 | 2,3 | 2,26 | 2,18 | 2,13 | 2,09 | 2,02 | 1,98 | 1,94 |
| Число степеней свободы, |
Число степеней свободы, |
|||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 12 | 14 | 16 | 20 | 24 | 30 | |
| 25 | 4,24 | 3,38 | 2,99 | 2,76 | 2,6 | 2,49 | 2,41 | 2,34 | 2,28 | 2,24 | 2,16 | 2,11 | 2,06 | 2 | 1,96 | 1,92 |
| 26 | 4,22 | 3,37 | 2,98 | 2,74 | 2,59 | 2,47 | 2,39 | 2,32 | 2,27 | 2,22 | 2,15 | 2,1 | 2,05 | 1,99 | 1,95 | 1,9 |
| 27 | 4,21 | 3,35 | 2,96 | 2,73 | 2,57 | 2,46 | 2,37 | 2,3 | 2,25 | 2,2 | 2,13 | 2,08 | 2,03 | 1,97 | 1,93 | 1,88 |
| 28 | 4,2 | 3,34 | 2,95 | 2,71 | 2,56 | 2,44 | 2,36 | 2,29 | 2,24 | 2,19 | 2,12 | 2,06 | 2,02 | 1,96 | 1,91 | 1,87 |
| 29 | 4,18 | 3,33 | 2,93 | 2,7 | 2,54 | 2,43 | 2,35 | 2,28 | 2,22 | 2,18 | 2,1 | 2,05 | 2 | 1,94 | 1,9 | 1,85 |
| 30 | 4,17 | 3,32 | 2,92 | 2,69 | 2,53 | 2,42 | 2,34 | 2,27 | 2,21 | 2,16 | 2,04 | 2 | 1,99 | 1,93 | 1,89 | 1,84 |
| 32 | 4,15 | 3,3 | 2,9 | 2,67 | 2,51 | 2,4 | 2,32 | 2,25 | 2,19 | 2,14 | 2,07 | 2,02 | 1,97 | 1,91 | 1,86 | 1,82 |
| 34 | 4,13 | 3,28 | 2,88 | 2,65 | 2,49 | 2,38 | 2,3 | 2,23 | 2,17 | 2,12 | 2,05 | 2 | 1,95 | 1,89 | 1,84 | 1,8 |
| 36 | 4,11 | 3,26 | 2,86 | 2,63 | 2,48 | 2,36 | 2,28 | 2,21 | 2,15 | 2,1 | 2,03 | 1,98 | 1,93 | 1,87 | 1,82 | 1,78 |
| 38 | 4,1 | 3,25 | 2,85 | 2,62 | 2,46 | 2,35 | 2,26 | 2,19 | 2,14 | 2,09 | 2,02 | 1,96 | 1,92 | 1,85 | 1,8 | 1,76 |
| 40 | 4,08 | 3,23 | 2,84 | 2,61 | 2,45 | 2,34 | 2,25 | 2,18 | 2,12 | 2,07 | 2 | 1,95 | 1,9 | 1,84 | 1,79 | 1,74 |
| 42 | 4,07 | 3,22 | 2,83 | 2,59 | 2,44 | 2,32 | 2,24 | 2,17 | 2,11 | 2,06 | 1,99 | 1,94 | 1,89 | 1,82 | 1,78 | 1,73 |
| 44 | 4,06 | 3,21 | 2,82 | 2,58 | 2,43 | 2,31 | 2,23 | 2,16 | 2,1 | 2,05 | 1,98 | 1,92 | 1,88 | 1,81 | 1,76 | 1,72 |
| 46 | 4,05 | 3,2 | 2,81 | 2,57 | 2,42 | 2,3 | 2,22 | 2,14 | 2,09 | 2,04 | 1,97 | 1,91 | 1,87 | 1,8 | 1,75 | 1,71 |
| 48 | 4,04 | 3,19 | 2,8 | 2,56 | 2,41 | 2,3 | 2,21 | 2,14 | 2,08 | 2,03 | 1,96 | 1,9 | 1,86 | 1,79 | 1,74 | 1,7 |
| 50 | 4,03 | 3,18 | 2,79 | 2,56 | 2,4 | 2,29 | 2,2 | 2,13 | 2,07 | 2,02 | 1,95 | 1,9 | 1,85 | 1,78 | 1,74 | 1,69 |
| 55 | 4,02 | 3,17 | 2,78 | 2,54 | 2,38 | 2,27 | 2,18 | 2,11 | 2,05 | 2 | 1,93 | 1,88 | 1,83 | 1,76 | 1,72 | 1,67 |
| 60 | 4 | 3,15 | 2,76 | 2,52 | 2,37 | 2,25 | 2,17 | 2,1 | 2,04 | 1,99 | 1,92 | 1,86 | 1,81 | 1,75 | 1,7 | 1,65 |
| 65 | 3,99 | 3,14 | 2,75 | 2,51 | 2,36 | 2,24 | 2,15 | 2,08 | 2,02 | 1,98 | 1,9 | 1,85 | 1,8 | 1,73 | 1,68 | 1,63 |
| 70 | 3,98 | 3,13 | 2,74 | 2,5 | 2,35 | 2,23 | 2,14 | 2,07 | 2,01 | 1,97 | 1,89 | 1,84 | 1,79 | 1,72 | 1,67 | 1,62 |
| 80 | 3,96 | 3,11 | 2,72 | 2,48 | 2,33 | 2,21 | 2,12 | 2,05 | 1,99 | 1,95 | 1,88 | 1,82 | 1,77 | 1,7 | 1,65 | 1,6 |
| 100 | 3,94 | 3,09 | 2,7 | 2,46 | 2,3 | 2,19 | 2,1 | 2,03 | 1,97 | 1,92 | 1,85 | 1,79 | 1,75 | 1,68 | 1,63 | 1,57 |
| 125 | 3,92 | 3,07 | 2,68 | 2,44 | 2,29 | 2,17 | 2,08 | 2,01 | 1,95 | 1,9 | 1,83 | 1,77 | 1,72 | 1,65 | 1,6 | 1,55 |
| 150 | 3,91 | 3,06 | 2,67 | 2,43 | 2,17 | 2,16 | 2,07 | 2 | 1,94 | 1,89 | 1,82 | 1,76 | 1,71 | 1,64 | 1,59 | 1,54 |
| 200 | 3,89 | 3,04 | 2,65 | 2,41 | 2,26 | 2,14 | 2,05 | 1,98 | 1,92 | 1,87 | 1,8 | 1,74 | 1,69 | 1,62 | 1,57 | 1,52 |
| 400 | 3,86 | 3,02 | 2,62 | 2,39 | 2,23 | 2,12 | 2,03 | 1,96 | 1,9 | 1,85 | 1,78 | 1,72 | 1,67 | 1,6 | 1,54 | 1,49 |
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1. Статистические методы обработки эмпирических данных / В.А. Грешников, Б.Н. Волков, А.И. Кубарев - М.: Изд-во стандартов. – 1978. - 232с.
2. Барабашук В.И. Планирование эксперимента в технике. - К.: Техніка. – 1984. - 200с.
3. Эрнесто Рафалес-Ламарка. Методология научно-технического исследования. – Луганск. – 1992. – 218с.
4. Волченко В.Н. Статистические методы управления качеством по результатам неразрушающего контроля. – М.: Машиностроение. – 1976. – 64с.
5. Ноулер Л., Хауэлл Дж., Голд Б. Статистические методы контроля качества продукции. – М.: Изд-во стандартов. – 1984. – 104с.
6. Новик Ф.С., Арсов Я.Б. Оптимизация процессов технологии металлов методами планирования экспериментов. – М.: Машиностроение. – 1980. – 304с.
7. Розанов Ю.Н. Методы математической статистики в материаловедении. – Л.: Машиностроение. – 1990. – 232с.
8. Дьяконов В.П., Абраменкова И.В. MathCAD в математике, физике и в Internet. – М.: Нолидж, 1999. – 352с.