| Похожие рефераты | Скачать .zip |
Реферат: Лингвистика
Билет 1
1. Сущность прикладной лингвистики как особого подхода к языковым явлениям. Характерные черты прикладных методик.
В языкознании всегда присутствовали три глобальных исследовательских направления:
· теоретическое (объяснение языковых систем и процессов)
· описательное (конкретное описание языковых явлений)
· прикладное (совершенствование языковой системы).
В рамках последнего направления сформировалась научная дисциплина, которая получила название прикладной лингвистики. Ее отличает подход к языку как к деятельности, а не мертвому продукту.
Прикладная лингвистика
· это комплексная научная дисциплина, изучающая язык в различных ситуациях его применения и разрабатывающая методы совершенствования языковых систем и языковых процессов.
· учение о методах решения разнообразных практических задач с использованием знаний о языке
· учение о совершенствовании языковой способности человека и общества в целом.
Термин прикладная лингвистика появился в конце 20 гг. 20 в., когда была осознана необходимость строгого научного решения прикладных задач с использованием методов формального лингвистического анализа письменных и акустико-лингвистического анализа устных сообщений.
За рубежом под ПЛ часто понимают совершенствование методов преподавания языка (дидактическая лингвистика). В нашей стране ПЛ понимают как компьютерную лингвистику, которая становится сейчас все более широкой дисциплиной почти синонимом ПЛ.
Синонимы ПЛ: компьютерная Л, структурная Л, машинная Л, статистическая Л, математическая Л, искусственный интеллект (ИИ), ...
ПЛ требует строгого структурного подхода к языку и отводит важную роль математике.
Основные задачи ПЛ:
· автоматическое распознавание и синтез речи
· автоматические методы переработки текстовой информации
· создание автоматизированных систем информационного поиска
· составление автоматических словарей и систем машинного перевода
· разработка методов автоматического аннотирования, реферирования и перевода
· разработка экспертных систем
· лингвистическое обеспечение АСУ
· стандартизация научно-технической терминологии
Прикладные модели отличаются определенным упрощением, огрублением языковой реальности, но это не значит , что они игнорируют реальную сложность моделируемого объекта. Методология прикладного исследования должна учитывать многоаспектность, многоуровневость, открытость языкового механизма.
Методология - совокупность общих принципов, определяющая способ исследования какого-либо явления; определяет взгляд на объект, как к нему подойти; философские принципы исследования явлений.
Метод - определенный тип способа исследования, определяемый инструментами, которые используются при изучении объекта исследования (метод компьютерного моделирования, статистический метод)
Собственно лингвистические методы:
· дистрибутивный метод
· трансформационный метод
· метод компонентного анализа
· метод различительных признаков
Методика - конкретный способ исследования, определяемый целью исследования; может объединять несколько методов (методика построения ассоциативных тезаурусов).
Характерные черты прикладных методик
· ведущая роль метода моделирования
· экспериментальный характер прикладных методик
· применение точного метаязыка
· формализованность самих операций исследования (хотя результат может быть приближенным)
· использование искусственного метаязыка описания
· комплексное сочетание разных наук
2. Автоматизированные переводные словари. Принципы построения.
АС - это словарь, который при переводе некоторые операции делает за человека. Компьютерный словарь - аналог бумажного на магнитных носителях. АС = ТБД с общеупотребительной лексикой. EURODICAUTOM (11, 1.200.000 ЛЕ), LEXIS (8, 1.500.000 ЛЕ).
Отличительные свойства АС:
многоязычие
· обратимость ( полная: всякая ЛЕ может выступать в роли входной при запросе и выходной при ответе; частичная: наличие индекса)
· гибкость (удобное, упрощенное обращение к словарю: несколько входов в словарь)
· динамичность (постоянное пополнение словарного состава; оперативность редактирования)
· состав (структура) словаря:
макроструктура - структура словаря:
микроструктура - структура словарной статьи
основная единица словаря
· слово (композиционно)
· словосочетание (статистически); 80% обращений к словарю - СС; причина -уклон в терминологию
3 главных компонента АС:
· блок обработки запроса (блок лемматизации - сведения текстовых форм к их словарным (каноническим) форме)
· блок лексических массивов (в АС ЛЕ могут храниться и в виде основ, и виде словоформ)
(· блок морфологического анализа) (иногда)
· блок выдачи ответа (ПЭ; главная задача - варьирование ответа в зависимости от пожеланий пользователя)
Желательно также, чтобы АС обладал:
· блоком лемматизации
· алгоритмом обработки некорректных запросов
· алгоритмом словообразовательного анализа)
АС не СМП, он берет на себя только работу с лексемой, оставляя человеку проблему выбора ПЭ и синтеза текста. На вход АПС поступают отдельные слова и СС, с помощью анализа которых можно получить сведения о грамм. классе слова и его грамм. форме. решить на основании этой информации проблемы омонимии и многозначность, определить синтас. функцию ПЭ в тексте невозможно, поэтому разработчики АПС таких задач перед собой и не ставят. Тем не менее индекс тематической принадлежности в какой-то мере разрешает многозначность лексики.
Словарная статья:
Ее структура и наполнение определяется назначением словаря.
Структура словарной статьи (13 зон):
1. Заголовок - основа, СС (больше всех по количеству), морфема, фрагменты текста
2.Зона лексического грамматического класса - ЛЕ по частям речи, далее - категоризация.
3. Зона морфологической информации
4. Рубрика подрубрика стиль (вся информация - в виде цифровых кодов)
5. Зона индекса надежности отражает степень общепринятости данного ПЭ:
А - официальный стандарт
Б - уважаемые словари
В - тетради новых терминов
Г - плавающие
6. Зона ПЭ (при нескольких ПЭ - у каждого свой номер)
7. Зона пояснительных помет - уточнение значения данной ЛЕ
· семантические
· лексические
· синтаксические (обязат. управление)
8. Зона толкований (для многозначных слов и новых терминов)
9. Зона примеров употребления выполняет две функции:
· иллюстративную
· смыслоразличительную
10. Зона фразеологии.
11. Составитель словарной статьи
12. Источник составления словарной статьи -> необязательные
13. Дата составления словарной статьи
Билет 7
1. Лексикография как прикладная дисциплина. Внутренняя и внешняя типология словарей.
Лексикография - прикладная лингвистическая дисциплина, занимающаяся практикой и теорией составления словарей.
Словарь - способ организации и представления знаний. Чем полнее и адекватнее в словаре представлены знания, тем лучше словарь выполняет свою функцию.
Лексикография как научная дисциплина носит комплексный характер, но определяющей чертой лексикографии является ее прикладная направленность. Все многообразие различных типов словарей (нормативные, учебные, переводные, терминологические, идеологические, этимологические ... ) получает практическую ориентацию исходя из целевой установки словаря.
Лексикография разрабатывает оптимальные средства выявления и фиксации семантических фактов определенных практических целях. Главная проблема в разработке оптимальной стратегии новых словарей - проблема обоснованности словарей как с точки зрения их состава, так и в плане адекватности подаваемой в них информации. Лексикография в широком смысле охватывает все множество инвентарей языковых единиц с приписанной им информацией того или иного рода. Наиболее богата и сложна для отражения семантическая информация.
Лексикографическая деятельность распадается на ряд этапов:
1. разработка системы требований, касающихся внешних параметров словаря (назначения, круга пользователей, инф. области ...)
2. разработка системы требований, касающихся внутренней параметров словаря (единиц описания, основных свойств метаязыка. объема, структуры, видов словарной информации ...)
3. формальная инвентаризация выбранных подъязыков (отбор текстов, расписывание контекстов, характеристика грамм. форм, составление предварительных словников ...)
4. экспериментальные исследования семантики описываемых единиц (дистрибутивный анализ текстов, тесты с носителями языка ...)
5. обобщение экспериментальных данных
6. построение дефиниций на соответствующем метаязыке и их проверка в ходе новых экспериментов
7. сбор и систематизация дополнительной информации о каждой языковой единице
8. оформление словарных статей
9. системный анализ и упорядочение словарных статей
10. оформление словаря в целом, включая вспомогательные указатели.
Аспекты лексикографии:
· историко-филологический - изучение истории словарей как части истории культуры общества
· гносеологический (когнитивный) - изучение словарей как сокровищниц знаний. накопленных обществом
· семантико-лексикологический - использование словарей для лексико-семантического описания языка
· прикладной (самый важный) - прикладная лексикография направлена на совершенствование словарей с точки зрения тех или иных практических требований к словарям
Виды информации подаваемой в словаре определяют внутреннюю типологию словарей:
I. Объекты описания:
1) формальные/ семантические
2) природа объектов (лекс.-семантический или морфо-семантический уровень; в парадигматическом или в синтагматическом аспекте)
3) статус объекта (является ли словарь нормативным или описательным)
4) хронологический период
5) по сфере общения (подъязык)
6) степень охвата языка
II. Системные свойства
1) какая грамматическая информация дается об описываемых единицах?
2) какие стилистические пометы используются?
3) какой тип определения (дефиниции) дается?
4) включается ли экстралингвистическая информация?
5) в какой мере учитываются семантические отношения?
6) объясняется ли мотивированность описываемой единицы?
III. Актуализация в языковой жизни
1) указывается ли происхождение единиц?
2) указывается ли активность единицы в языковой жизни (частотность)?
3) показывается ли реализация единиц в контексте
IY. Прагматика пользователя
1) количество входов в словарь
2) каков порядок расположения единиц в словаре (по формальному или семантическому признаку?
3) имеются ли в словаре указатели?
4) даются ли металингвитсические сведения (история изучения, разные трактовки)?
Y. Связь с другими языками
1) производится ли генетическое сопоставление единиц и их значений с родственными языками?
2) производится ли типологическое сопоставление материала неродственных языков?
Цели словаря задают внешнюю (функциональную) типологию словарей:
|
Типы словарей |
Цель |
| учебные словари | обучение |
| переводные словари | перевод |
| нормативные словари | нормирование |
| терминологические словари | систематизация, уточнение научных понятий |
Типология словарей по Ожегову:
· большой (представляет совр. русский язык в широкой ист. перспективе)
· средний (с детальной разработкой исторически оправданного стилистического многообразия лит. РЯ)
· краткий (популярного типа, стремящийся к активной нормализации совр. лит. речи)
Типология словарей по Щербе:
· словарь-справочник - словарь академического типа
· энциклопедический - общий словарь
· тезаурус - обычный толковый или переводной словарь
· обычный толковый или переводной словарь - идеологический словарь
· толковый словарь - переводной словарь
2. Автоматизированные информационно-поисковые системы: их структуры, функции, критерии оценки. Информационные языки.
АИПС предназначены для инф. обслуживания пользователей информации в заданной тематической области.
2 основные задачи АИПС:
· хранение информации
· поиск и выдача информации
Из сведений о ТО. поступающих на хранение в систему формируется информационный массив (ИМ). От потребителя поступают запросы, и система ищет сведения в ИМ, Соответствующие данному запросу. Всякая поисковая операция в системе сводится к сравнению поступившего запроса с имеющимися в системе сведениями. в современных ИПС все это происходит автоматически. Для этого и запрос и сведения должны быть представлены на таком языке, который обладает смысловой однозначностью - ИПЯ.
Индексирование - перевод содержания текста, хранящегося в ИМ на ИПЯ. в результате индексирования образуется поисковый образ, у документа - ПОД, у запроса - ПОЗ.
Критерий смыслового соответствия - мера соответствия между содержанием запроса и документа, достаточная для признания данного документа релевантным данному запросу. Вводится совокупность признаков, на основании которых устанавливается степень необходимого и достаточного соответствия между поисковым предписанием и поисковым образом документа, выраженными на одном и том же ИПЯ.
Результатом поисковой операции является выборка релевантных ПОДов.
Абстрактная ИПС - некий логико-семантический аппарат, состоящий из ИПС, правил индексирования и критерия выдачи.
В зависимости от характера сведений и запроса различаются документальная и фактографическая ИПС. Фактографическая ИПС не хранит документы, а только факты. Документальная хранит документы. Но существует прием, позволяющий в процессе поиска определенного документа извлекать факт: В документальной системе хранится информация о содержании документа + документографическая информация (автор, год ...)
выделение нужной пользователю информации осложняется двумя обстоятельствами:
· несоответствие между формулировкой запроса и реальной информацией нужной потребителю
· перевод запроса в ПОЗ
Мера соответствия документа информационной потребности называется пертенетностью.
Соответствие документа запросу называется релевантностью:
· смысловая (соответствие запроса поисковому предписанию) - просто релевантность, зависит от ИПЯ (его семантической силы, глубины индексирования, совершенства логико-сем. аппарата)
· формальная (соответствие документа поисковому предписанию)
ИПЯ - специализированный ИЯ, предназначенный для эксплицитной записи содержания документов и запросов в форме, удобной для автоматического поиска.
Классификация ИПЯ:
|
предкоординированные ИПЯ присутствует заранее заданная классификационная схема |
посткоординируемые ИПЯ отсутствует заранее заданная классификационная схема |
Типы классификаций
|
иерархическая задает дерево знаний, например всей литературы по лингвистике |
алфавитно-предметная например, телефонный справочник |
фасетная опирается на разные аспекты описания, задается так называемая фасетная формула (Ж1 Ц2 Ф1), представляющая собой шаблон, рассматривается класс, аспект предмета |
Фасетная классификация: фильмы:
| жанр | цвет | формат |
|
Ж1 Ж2 |
Ц1 цветной Ц2 черно-белый |
Ф1 широкоформатный |
фасетная формула: Ж1 Ц2 Ф1
Общие недостатки предкоординированных ИПЯ:
· не позволяют вести поиск по заранее непредусмотренному сочетанию признаков
· все классификации имеют недостаточную глубину
· процесс индексирования принципиально не автоматизирован, т. е ручное индексирование
Посткоординируемые ИПЯ:
|
семантические коды в ЛЕ в явном виде заданы парадигматические отношения |
дескрипторы оперируют монолитными СЕ, в основу положен принцип координированного индексирования, который выражается в том. что основная тема документа выражается в виде набора слов или СС, т. о документ помещается в n-мерное пространство |
|||||
|
Семантические коды Перри и Кента (США) м.б простыми и составными, простая ЛЕ - сем. множитель; RX коды ручное индексирование |
грамматики мешочного типа (теоретико-множественные грамматики) задаются отношением совместного вхождения в класс, ПОД составляется вручную, ПОД -перечень ключевых слов. |
позиционно-скобочные грамматики сохранение всего исходного текста документа с явным указанием порядка следования, деления на абзацы, предложения: |
сетевые грамматики в явном виде задается смысл связи между элементами текста (Скрэгг) |
|||
ИПЯ с ПСГ:
· индексирование без лексического контроля, до индексирования могут не иметь словаря, словарь формируется в результате индексирования.
· индексирование с лексическим контролем - все словоформы приводятся к стандартному виду
2. Назначение и принципы организации Субд на ПЭВМ
СУБД состоит из совокупности взаимосвязанных данных и набора программ, обеспечивающих доступ к данным и манипуляцию ими. Совокупность взаимосвязанных данных принято называть БД. [Henry F. Korth]
Более узкое определение СУБД - набор компьютерных программ, предназначенных для создания, поддержки, и использования БД
СУБД обеспечивает доступ к данным в процессе диалога с пользователем, отвечая на его вопросы (запросы).
Выделяется три уровня абстракции, на которых можно просмотреть данные.
· Физический уровень - уровень минимальной абстракции; на нем хранятся физические данные.
· Концептуальный уровень содержит описание данных, хранящихся в БД и отношений между ними. Он описывает всю БД в целом, используя несколько относительно простых структур - концептуальных схем; предназначен для администратора БД.
· Уровень представления - уровень максимальной абстракции; предназначен для основной массы пользователей БД. В одной БД может одновременно существовать несколько уровней представления.
· Модель данных представляет собой набор концептуальных инструментов для описания данных, отношений между ними, семантики данных и ограничений их целостности (consistency constraints).
Выделяют три класса моделей:
· логические модели, опирающиеся на понятие объекта (object-based logical models);
· логические модели, опирающиеся на понятие записи; (record-based logical models);
· физические модели данных (physical data models).
Объектные логические модели.
Объектные логические модели описывают данные на концептуальном уровне и уровне представления. Они позволяют определять структуру и ограничения целостности. На сегодняшний день существует свыше 30 моделей этого класса. Из них самые известные:
· модель сущность-связь;
· бинарная модель;
· семантическая модель данных;
· инфологическая модель.
Модель сущность-связь - основной представитель класса объектных моделей. Она считается наиболее адекватной для архитектуры БД и наиболее распространенной.
В основе модели сущность-связь лежит представление о реальном мире как о совокупности основных объектов, называемых сущностями и связей между ними.
· Под сущностью понимают любой реально существующий объект, отличный от других объектов. Чтобы отличить один объект от другого, каждому из них приписывается набор атрибутов, описывающих данный объект.
· Связь - это соединение между несколькими сущностями. Для того, чтобы различать сущности и связи, каждому набору сущностей приписывается первичный ключ.
· Первичный ключ - это один или несколько атрибутов, позволяющих однозначно идентифицировать сущность в наборе сущностей.
БД, удовлетворяющая диаграмме сущность-связь, может быть представлена в виде набора таблиц. Для каждого набора сущностей, как и для каждого набора отношений, создается отдельная таблица, которой присваивается имя соответствующего набора. В свою очередь, каждая таблица состоит из столбцов, каждый из которых имеет свое название.
Логические модели, опирающиеся на понятие записи.
Логические модели, опирающиеся на понятие записи, как и объектные логические модели, описывают данные на концептуальном уровне и уровне представления, но, в отличие от последних, эти модели определяют не только архитектуру БД, но и дают общее описание ее реализации. Однако модели этого класса уже не позволяют вводить ограничения на содержимое БД, как это делают объектные логические модели.
Самые распространенные модели:
· реляционная
· сетевая
· иерархическая.
Реляционная модель была предложена в 1970 году Е.Ф. Коддом и на сегодняшний день является признанным лидером среди моделей своего класса. Она основана на математическом понятии отношения.
Согласно реляционной модели, общая структура данных (отношение) может быть представлена в виде таблицы, в которой каждая строка значений (кортеж) соответствует логической записи, а заголовки столбцов являются названиями полей (элементов) в записях. Таким образом, данные и отношения между ними в реляционной модели представлены в виде набора таблиц, аналогичным по своей структуре таблицам модели сущность-связь.
Примеры реляционных БД: dBASE IY, FoxPro, Paradox.
Наиболее уязвимой частью реляционной модели являются проблемы целостности. Для их разрешения приняты ограничения, соответствующие строгой реляционной модели. До сих пор не удавалось создать СУБД полностью реляционную СУБД. Можно говорить лишь о большей или меньшей степени реляционности в отношении коммерческих СУБД. Однако для того чтобы называться реляционной СУБД должна обязательно отвечать следующим условиям:
· данные в ней должны храниться в таблицах;
· указатели и связи не должны быть видны пользователю;
· язык запросов должен быть реляционно полным.
Сетевая модель появилась в конце 1960-х гг. Она более привязана к реализации БД, чем реляционная модель.
Сетевая БД состоит из набора записей, соединенных друг с другом при помощи ссылок (links), которые могут быть видны пользователю как указатели (pointers). Ссылка соединяет ровно две записи. Записи организованы в виде произвольного графа (arbitrary graph).
Иерархическая модель представляет собой разновидность сетевой.
Иерархическая БД, как и сетевая, состоит из совокупности записей, соединенных между собой при помощи ссылок. Каждая запись состоит из набора полей, каждое из которых содержит ровно один параметр данных.
Основное отличие иерархической модели от сетевой заключается в способе организации записей. В иерархической модели записи организованы в виде деревьев, а не произвольных графов, как в сетевой модели. Общая логическая структура иерархической БД описывается при помощи диаграммы структуры дерева (tree- structure diagram), состоящей из записей и ссылок.
Пример иерархической БД: ACCESS.
Физические модели данных.
Физические модели данных используются на уровне минимальной абстракции. Это самый малочисленный класс моделей. Наиболее известные из них: отождествляющая модель (unifying model) и модель фреймовой памяти (frame memory).
Язык определения данных.
План БД определяется набором выражений (дефиниций), написанных на специальном языке, который называется язык определения данных (ЯОД) (data definition language).
Результатом компиляции выражений на ЯОД является набор таблиц, хранящийся в специальном файле, который называется словарь данных (data dictionary). В словаре данных хранятся метаданные, то есть данные о данных.
Разновидностью ЯОД является язык хранения и определения данных (data storage and manipulation language), на котором написаны выражения, определяющие методы доступа к данным и способ хранения структуры.
Язык манипуляции данными.
Под манипуляцией данными понимают:
· извлечение информации, хранящейся в БД;
· добавление новой информации в БД;
· уничтожение хранящейся в БД информации.
Язык манипуляции данными (ЯМД) обеспечивает пользователю доступ и манипуляцию данными. Различают два основных типа ЯМД:
· процедурный, который требует от пользователя указать тип нужных ему данных и способ их получения, то есть содержит процедуры поиска данных;
· непроцедурный, который требует указать только тип данных, не уточняя способ их получения, то есть не включает процедуры поиска.
Часть ЯМД, отвечающая за выборку данных, называется языком запросов.
Запрос (query) - выражение, задающее поиск данных в СУБД.
Менеджер БД - программный модуль, обеспечивающий интерфейс между данными низкого уровня, хранящимися в БД, прикладными программами и адресованными системе запросами.
Развернутая структура СУБД: СУБД состоит из модулей, каждый из которых выполняет определенную функцию. Некоторые функции СУБД могут выполняться операционной системой. Архитектура СУБД должна обеспечивать интерфейс между СУБД и операционной системой. СУБД состоит из следующих функциональных компонентов:
· Менеджер файлов управляет распределением места на диске и структурами данных; обеспечивает взаимодействие между данными низкого уровня, хранящимися в БД, прикладными программами и запросами, адресованными системе.
· Процессор запросов переводит выражения на языке запросов в инструкции, понятные менеджеру БД.
· Прекомпилятор ЯМД переводит выражения на ЯМД, вложенные в прикладную программу.
· Компилятор ЯОД переводит выражения на ЯОД в набор таблиц, содержащих
Структуры данных
· Файлы данных содержат собственно данные.
· Словарь данных содержит информацию о структуре БД.
· Индексы служат для быстрого поиска данных с конкретными значениями (атрибутами).
Билет 9
1. Формальные модели синтаксической структуры предложения.
Динамические и статистические модели
1. Дескриптивная модель Задача - описание структуры языка
нормирование (определение всех правил синтаксических структур)
исчисление
1) Грамматика зависимостей (европейская традиция, близка к НС, один из авторов - Гладкий) - указание для каждого слова тех слов, которые ему непосредственно подчинены.
Дерево синтаксических зависимостей есть дерево, множество узлов которого служит множеством вхождений слов в предложение. Деревом называется множество, между элементами которого - узлами - установлено бинарное отношение - отношение подчинения и графически изображают стрелками. идущими от подчиняющих узлов к подчиненным,- такое, что:
· среди узлов имеется один - корень - неподчиненный никакому другому узлу
· каждый из остальных узлов подчинен точно одному узлу
· нельзя, отправившись из к.л. узла вдоль стрелок вернутся в тот же узел.
ДЗ (дерево зависимостей) обычно используется в описаниях языков со свободным порядком слов (в частности, русского). Стрелки ДЗ обычно помечаются символами синтаксических отношений (предикативное, определительное и т.п.).
2) Метод НС составляющие - Для описания синтаксической структуры предложения выделяются группы слов, функционирующие как отдельные синт. единицы - составляющие.
Система составляющих - это множество отрезков предложения которое обладает тем свойством, что каждые два входящих в него отрезка либо не пересекаются либо один из них содержится в другом.
· Одна из НС - ядро конструкции, остальные - маргинальные элементы.
· При графическом изображении система составляющих тоже приобретает вид дерева (дерева непосредственных составляющих - ДНС).
· ДНС используются преим. в описаниях языков с жестким порядком слов.
· Составляющие обычно помечаются символами грамм. категорий (именная группа, группа переходного глагола и т.п.)
2. Трансформационная грамматика (Харрис, 50-е гг.) (грамматика деревьев) служит не для порождения предложений, а для преобразования деревьев, интерпретируемых как деревья подчинения или деревья составляющих, например грамматика - система правил преобразования деревьев, интерпретируемых как "чистые" деревья подчинения предложений (без линейного порядка слов).
три уровня описания
1) правила НС
2) трансформационные правила
3) морфологические правила
Допущения:
· синт. система может быть разбита на ряд подсистем, одна из которых - исходная (ядерная), остальные - производные. Ядерная Т - набор предложений (утвердительных, простых, с глаголом в изъяв. форме, активного залога, наст. времени.)
· ядерное предложение описывает элементарные ситуации, а класс ЯП - все множество элем. ситуаций.
· любой сложный синт. тип можно получить при применении упорядоченного набора обязательных и факультативных трансформаций к ядерному предложению.
Представление синт. структуры предложения - указание ядерного типа, лежащего в основе предложения и трансформаций, которые к нему применялись, а также их последовательности.
Метод явился основой порождающей грамматики Хомского.
3. Порождающая грамматика Хомского, представляющая собой упорядоченную систему Г =(V,W,П,R), где V и W - непересекающиеся конечные множества - основное (терминальное) и вспомогательное (нетерминальное), П - элемент W, называемый начальным символом и R - конечное множество правил вида , где цепочки (конечные последовательности) из основных и вспомогательных символов. Множество тех цепочек из основных символов, которые выводимы в Г из ее начального символа, называют языком, порождаемым грамматикой Г и обозначают L(Г). Если все правила Г имеют вид , где - правый и левый контексты, то Г называется грамматикой составляющих или грамматикой непосредственно составляющих (ГНС). Чаще всего основные символы интерпретируются как слова, вспомогательные - как символы грамматических категорий, начальный символ - как символ категории "предложение".
4. Реляционная модель
5. Аппликационная модель (Шаумяна?)
Доминационная грамматика, которая порождает множество цепочек, интерпретируемых обычно как предложения и вместе с их синтакс. структурами в виде ДЗ.
Грамматики Монтегю служат одновременно для описания синтакс. и семант. структуры предложения. В них используется сложный математико-логический аппарат (так называемая интенциональная логика).
2. Экспертные системы и их архитектура. Функции основных компонентов.
Экспертная система - это компьютерная программа, которая моделирует рассуждение человека-эксперта в определенной области, используя для этого БЗ, содержащую факты и правила об этой области и некоторую процедуру логического вывода.
Разработка ЭС - сравнительно новое направление в системах ИИ; второе название - инженерия знаний (термин ввел в 1977 Фегенбаум), сформировалась в середине 70 гг.
Раньше была цепочка: аналитик - программист - оператор - пользователь; теперь пользователь может обращаться прямо к ЭВМ (либо только через инженера по знаниям).
Структура ЭС:
|
раньше: входные данные программ |
теперь: входные данные интерпретатор БЗ БЗ |
Обычные программы имеют фиксированную последовательность шагов, строго определенную программистом, ЭС пользуются нахождением удовлетворительного решения методом проб и ошибок.
ЭС решают трудно формализуемые задачи. не имеющие алгоритмического решения () медицина, геология, управление, юридические науки).
Попов: три причины появления ЭС:
· ориентированы на решение задач в неформализованных областях
· предназначены для пользователей, не имеющих спец. навыков программирования
· ЭС решают задачи лучше, чем человек.
3 принципа разработки ЭС:
1. мощность ЭС определяется мощностью БЗ и процедурами ее пополнения, т.о. компонент приобретения знаний важнее компонента логического вывода. (Раньше большее внимание уделялось лог. выводу).
2. Знание. используемое ЭС, является в основном эвристическим, экспериментальным, поэтому используется коэффициент достоверности.
3. ЭС реализуется в форме диалоговой системы.
ЭС должна обладать способностью приобретать знания.
2 источника приобретения знаний:
1) от эксперта
2) из текстов (не разработано)
ЭС решают практические задачи. а не экспериментальные; решения ЭС могут быть объяснены пользователю, т.е обладают свойством прозрачности, для этого существует специальный компонент - объяснительный.
Формальная основа ЭС: базовое понятие - правило продукции или формальные процедуры системы: правила вида условие -> действие если -> то (если была разлита горючая жидкостью то вызовите пожарных).
Термин продукция ввел Пост (1943)
Свойство продукции - всякая формальная система. оперирующая символами, может быть реализована одной из продукционных систем.
Архитектура ЭС
|
Пользователь ЭС Общение на ЕЯ |
Лигвитсический компонент анализа с синтеза входных сообщений |
рабочая память текущее состояние проведения экспертизы |
объяснительный компонент |
|||
|
интерпретатор |
||||||
|
компонент приобретения знаний |
||||||
|
БЗ |
· БЗ имеет динамический характер, содержит факты и правила в форме продукций
· интерпретатор (решатель) имеет дело с процедурами логического вывода, на основе имеющихся данных решает задачу
· лингвистический процессор осуществляет диалог с пользователем
· рабочая память хранит данные
· компонент приобретения знаний - с его помощью знания извлекаются из эксперта или текста и заносятся в БЗ
· объяснительный компонент отвечает на вопрос, почему принято данное решение и чем мотивирован выбор.
2 режима работы ЭС:
· приобретение знаний: участвует эксперт и инженер по знаниям (посредник)ручные и автоматизированные методы (brainstorm)
· режим решения задач: главный участник - пользователь, заинтересованный в результате.
Типы ЭС:
· демонстрационные прототипы (56)
· исследовательские (92)
· действующие (12)
· промышленные (4)
· коммерческие (9)
Примеры ЭС
две старейшие ЭС:
DENDRAL (химическая тематика, определяет структуру хим. элементов)
MAXIMA (решение мат. задач)
Система FOBS
Санджай, Чадна и др., "Использование известных ситуаций (cases) для построения" ЭС MEDIA (выбор оптимального СМИ для маркетинга на материале Harvard Business School) на основе оболочки ADVISOR. Система задает вопросы и анализирует все факторы, связанные с продуктом (поведение покупателя, ориентация на конкретного покупателя, конъюнктура), рекомендует средство рекламы, перечисляет возможные альтернативы и аргументирует свой выбор.
Билет 10
1. Типы экспериментальных методов в лингвистике
Экспериментальные методы в лингвистике - это методы , позволяющие изучать факты языка в условиях. управляемых и контролируемых исследователем. Философской основой применения экспериментальных методов в лингвистике является тезис о единстве теоретического и эмпирического уровней познания.
В современной лингвистике термин "экспериментальный метод" не является четким; лингвисты часто говорят об эксперименте там, где имеет место наблюдение, прежде всего наблюдение над текстами (письменными и устными). Существенно. что текст как таковой, будучи данностью не может быть объектом ЭМ; именно поэтому ЭМ не применимы к изучению истории языка, особенностей стиля автора и т.п. в этих случаях следует говорить о наблюдении. Объектом ЭМ является человек - носитель языка, порождающий текст, воспринимающий тексты и выступающий как информант для исследователя. в лингвистическом эксперименте исследователь может иметь в качестве подобного объекта самого себя или других носителей языка; в первом случае следует говорить об интроспекции, во втором - об объективном эксперименте.
Экспериментальная работа с информантами (нередко в сочетании с наблюдением) непосредственно в среде носителей языка называется обычно полевой лингвистикой.
Историю применения ЭМ в лингвистике можно разделить на три периода:
1. Активное освоение ЭМ в фонетике, акцент на сходстве ЭМ в лингвистике и точных науках (труды Богородицкого, Щербы, Матусевича)
2. Осознание ЭМ в лингвистике как важнейшего способа получения данных о живом языке вообще , включая его морфологию. синтаксис, семантику, а также проблемы языковой нормы, языкового общения, патологий речевого развития и т.д. эта научная программа была впервые сформулирована Щербой ("О трояком аспекте языковых явлений и об эксперименте в языкознании")
3. Реализация указанной научной программы, и как следствие углублении методологических разработок (Апресян, Фрумкина). В социолингвистике и психолигвистике ЭМ занимают доминирующие место.
Последовательное применение ЭМ в исследовании языка и речевых процессов сделало необходимым использование статистических методов при планировании эксперимента и обработке результатов (лингв. статистика). существенно. что лигвист, изучающий речевое поведение человека, имеет дело с объектом, равным ему самому по сложности. В силу этого отношение исследователь - объект в лингвистике превращается в симметричное отношение между двумя исследователями: информант может иметь свою теорию об экспериментаторе и соответственно изменять свое поведение в процессе эксперимента, что может негативно повлиять на результаты Э. Особой сферой использования ЭМ являются машинные эксперименты, проверяющие адекватность формализованных действующих моделей языка.
Процесс Э:
· общая задача
· рабочая гипотеза
· формальные выводы, изменения
· новые гипотезы
Цель Э - проверка гипотез. Человек не должен знать целевую установку экспериментатора.
Типы экспериментов:
· моделирующие эксперименты (в социолингвистике): порождается ряд гипотез, отбираются социальные параметры, которые варьируются
· имитационные эксперименты (лабораторные) - имитация усеченной действительности
· натурные эксперименты включают условия, позволяющие демонстрировать поведение, максимально похожее на реакцию в аналогичной естественной ситуации.
Типы методов (по количеству информантов):
· индивидуальный
· межгрупповой
· многоуровневый, многофакторный
(Хофман) Экспериментальные методы в семантике:
· ассоциативный эксперимент - испытуемому дается слово-стимул и предлагается реагировать на это слово первым пришедшим в голову словом или словосочетанием
· метод семантического дифференциала (экспер. семантика) - один из методов построения субъективных сем. пространств ( градуированные оценочные шкалы)
· метод классификации (в психолигвистике - испытуемым предлагается разбить материал на произвольное количество классов.)
· эксперимент п членению денотативного континуума (Фрумкина: смысловые отношения в группе слов цветообозначений + Лабов "Структура денотативных значений" - сосуды - cup, bowl, glass -> размытость и взаимозависимость денотативных границ; модели, основанные на компонентном анализе, не объясняют вышеназваного свойства, вывод - более адекватна теория прототипов, которая только начинает применяться в семантике).
2. Эволюция систем автоматизированного перевода.
1947 г. - Memorandum by Warren Weaver об автоматическом переводе
1954 г. - Джорджтаунский эксперимент (Массачусетс)
Типы систем:
· системы машинного перевода (СМП)
· системы человеко машинного перевода (АС)
· ТБД
Три поколения СМП (условная классификация, Марчук не признавал деления на поколения):
I поколение:
· содержали полный алгоритм морфологического анализа
· имели имели алгоритм снтаксического анализа, но всегда одновариантный
· синтез - блок морфологического синтеза, болк синтаксического синтеза
· в словарной статье - только переводной эквивалент, остальная информация - в алгоритмах
· работа только в пакетном режиме
II поколение (SYSTRAN, АМПАК, Georgetown System, ):
· мощный блок синтаксическогоанализа и синтеза
· многовариантный синтаксический анализ
· увеличение числа и объема словарных статей: ПЭ + синтаксические модели управления и сочетаемости (информация об управлении должна находится в словаре, а не в алгоритме)
· недостаточное внимание семантике ( нет сем. дефиниций, моделей упраления в терминах сем. классов)
· работа и пакетном и в интерактивном режимах
III поколение (ЭТАП-1 (350 слов), ЭТАП-2 (4000 слов), модель "Смысл-текст", Апресян):
· широкое использование семантики на всех уровнях: в словаре, алгоритме
· только исследовательские системы, нет ни одной промышленной
Марчук "Проблемы МП" - 3 периода, Слокум "Обзор разработок по МП":
1. 1946 - 1957
· выдвинута концепция языка как кода
· созданы первые машинные словаридля МП
· разработана общая концепция МП (алгоритмы наализа и синтеза, рпограммное обеспечение)
· опробованы первые СМП
· повышенный интерес к проблеме, связанный с надеждами на возможность скоростного высококачественного перевода текстов любого типа, щедрое финансирование
2. 1957 - 1967
· доклад консультативного Комитета по автоматизированной обработке ЕЯ (ALPAC) при Национального Академии Наук США - доказана невозможность полностью автоматизированного высококачественного перевода -> свертывание разработок, сокращение финансирования текущих исследований (но не долгосрочных)
· успешные попытки промышленной эксплуатации СМП
· широкие теоретические исследования: возникла идея языка-посредника, методика контекстного анализа для рзрешения основных лигв. проблем.
3. 1967 - настоящее время
· возрождение интереса к МП
· Люксембург, конференция "Преодоление языковых барьеров"
· активная промышленная эксплуатация СМП
Развитие МП происходило согласно гегелевской триаде - тезис, антитезис, синтез.
| СМП | АС | ТБД |
|
SYSTRAN (1070, автор -Peter Toma, 15 пром. пар языков, пакетный режим работы, язык посредник Interlingua, 200.000 - 300.000 ) АНРАП (ВЦП), СПРИНТ PC, ЭТАП-1 (Апресян, модель "Смысл-текст", словарь -350 слов), ЭТАП-2, словарь -4000 слов |
EURODICAUTOM (1.200.000 заголовков) LEXIS (1.500.000) SIEMENS (1.500.000) |
TERMIUM (> 2 млн.) |
Билет 11
1. Общенаучный метод моделирования и специфика его применения в лингвистике
Метод моделирования центральный исследовательский метод в науке.
Моделирование в науке - это выяснение свойств какого-либо предмета при помощи построения его модели.
Моделью можно назвать образ какого-либо объекта, используемый в определенных условиях в качестве его заместителя (фотография в паспорте - модель человека).
Свойства моделей:
· условность
· образ может быть не только материальным, но и мысленным и передаваться посредством знаковой системы
· моделью может быть не только образ, но и праобраз оригинала
· модель чаще всего является гомоморфной оригиналу (то есть многим элементам оригинала соответствует меньшее количество элементов модели в отличие от изоморфизма)
Модель в лингвистике - искусственно создаваемое лингвистом реальное или мысленное устройство, воспроизводящее, имитирующее своим поведением (обычно в упрощенном виде) поведение оригинала в лингвистических целях.
Собственно лингвитсические модели:
· модели речевой деятельности, процессуальный модели (самые сложные)
· модели языковой системы, языковой структуры (тоже очень сложные)
· модель памяти и др.
Лингвистическое моделирование необходимо предполагает использование абстракции и идеализации. Отображая релевантные существенные (с точки зрения исследования) свойства оригинала и отвлекаясь от несущественных, модель выступает как некоторый абстрактный идеализированный объект. Всякая модель строится на основе гипотезы о возможном устройстве оригинала и представляет собой функциональный аналог оригинала. что позволяет переносить знания с модели на оригинал. Критерием адекватности модели является эксперимент.
В идеале модель должна быть формальной (т.е. в ней должны быть в явном виде и однозначно заданы исходные объекты, связывающие их отношения и правила обращения с ними) и обладать объяснительной силой (т.е. не только объяснять факты или данные экспериментов, необъяснимые с точки зрения уже существующей теории, но и предсказывать неизвестное раньше, хотя и принципиально возможное поведение оригинала, которое позднее должно подтверждаться данными наблюдения или экспериментов).
Понятие лингвистической модели возникло в структурной лингвистике, но вошло в научный обиход в 60-70 гг. 20 в. с возникновением мат. лингвистики и проникновением в лингвистику мат. методов.
Содержание термина "модель" в современной лингвистике в значительной степени охватывалось ранее термином "теория" (особенно Ельмслевым). Считается, что наименования модель заслуживает лишь такая теория. которая достаточно эксплицитно изложена и в достаточной степени формализована (в идеале каждая модель должна допускать реализацию на ЭВМ).
Контруирование модели - не только одно из средств отображения языковых явлений, но и объективный практический критерий проверки истинности знаний о языке. В единстве с другими методами изучения языка моделирование выступает как средство углубления познания скрытых механизмов речевой деятельности, его движения от относительно примитивных к более содержательным моделям, полнее раскрывающим сущность языка.
Внутри языка как системы существует принцип моделирования: одни его подсистемы моделируют другие, например, система письменной речи является моделью устной речи; внутри письменной речи мы имеем дело с несколькими моделями (печатной, рукописной); план выражения является моделью плана содержания.
Метод моделирования обычно опирается на знаковые систем, но язык - сам знаковая система, т.е. слова мы моделируем при помощи слов.
Главная цель моделирования в лингвистике - это моделирование целостной языковой способности человека.
Синтез речи.
1 Ограничения на синтез речи.
Cуществуют различные методы синтеза речи. Выбор того или иного метода определяется различными ограничениями. Рассмотрим те 4 вида ограничений, которые влияют на выбор метода синтеза.
Задача.
Возможности синтезированной речи зависят от того, в какой области она будет применятся. Когда необходимо произносить ограниченное число фраз ( и их произнесение линейно не меняется ), необходимый речевой материал просто записывается на пленку. С другой стороны, если задача состоит в стимулировании познавательного процесса при чтении вслух, используется совершенно другой ряд методик.
Голосовой аппарат человека.
Все системы синтеза речи должны производить на выходе какую-то речевую волну, но это не произвольный сигнал. Чтобы получить речевую волну определенного качества, сигнал должен пройти путь от источника в речевом тракте, который возбуждает действие артикуляторных органов, которые действуют как изменяющиеся во времени фильтры. Артикуляторные органы также накладывают ограничения на скорость изменения сигнала. Они также имеют функцию сглаживания: гладкого сцепления отдельных базовых фонетических единиц в сложный речевой поток.
Структура языка.
Ряд возможных звуковых сочетаний опредляется природой той или иной языковой структуры. Было обнаружено, что еденицы и структуры, используемые лингвистами для описания и объяснения языка, могут также использоваться для характеристики и построения речевой волны. Таким образом, при построении выходной речевой волны используются основные фонологические законы, правила ударения, морфологические и синтаксические структуры, фонотактические ограничения.
Технология.
Возможности успешно моделировать и создавать устройства для синтеза речи в сильной степени зависят от состояния технико-технологической стороны дела. Речевая наука сделала большой шаг вперед благодаря появлению различных технолоний, в том числе: рентгенография, кинематография, теория фильтров и спектров, а главным образом - цифровые компьютеры. С приходом интегральных сетевых технологий с постоянно возрастающими возможностями стало возсожно построение мощных, компактных, недорогих устройств, действующих в реальном времени. Этот факт, вместе с основательными знаниями алгоритмов синтеза речи, стимулировал дальнейшее развитие систем синтеза речи и переход их в практическую жизнь, где они находят широкое применение.
2 Методы синтеза.
Различные подходы могут быть сгруппированы по областям их применения, по сложности их воплощения.
Синтезаторы делят на два типа: с ограниченным и неограниченным словарем. В устройствах с ограниченным словарем речь хранится в виде слов и предложений, которые выводятся в определенной последовательности при синтезе речевого сообщения. Речевые единицы, используемые в синтезаторах подобного типа, произносятся диктором заранее, а затем преобразуются в цифровую форму, что достигается с помощью различных методов кодирования, позволяющих компрессировать речевую информацию и хранить ее в памяти синтезирующего устройства. Существует несколько методов записи и компоновки речи.
Волновой метод кодирования.
Самый легкий путь - просто записать материал на пленку и по необходимости проигрывать. Этот способ обеспечивает высокое качество синтезируемой речи, т.к. позволяет воспроизводить форму естественного речевого сигнала. Однако этот путь синтеза не позволяет реализовать построение новой фразы, т.к. не предусматривает обращение к различным ячейкам памяти и вызов из памяти нужных слов. В зависимости от используемой технологии этот способ может представлять задержки в доступе и иметь ограничения, связанные с возможностями записи. Никаких знаний об устройстве речевого тракта и структуре языка не требуется. Единственно серьезное ограничение в данном случае имеет объем памяти. Существуют способы кодирования речевого сигнала в цифровой форме, позволяющие в несколько раз уплотнять информацию: простая модуляция данных, импульсно-кодовая модуляция, адаптивная дельтовая модуляция, адаптивное предиктивное кодирование. Данные способы могут уменьшить скорость передачи данных от 50кбит/сек (нормальный вариант) до 10кбит/сек, в то время как качество речи сохраняется. Естественно, сложность операций кодирования и декодирования увеличивается со снижением числа бит в секунду. Такие системы хороши, когда словарь сообщений небольшой и фиксированный. В случае же, когда требуется соединить сообщения в более длинное, сгенерировть высококачественную речь трудно, т.к. значения параметров речевой волны нельзя изменить, а они могут не подойти в новом контексте. Во всех системах синтеза речи устанавливается некоторый компромисс между качеством речи и гибкостью системы. Увеличение гибкости неизбежно ведет к усложнению вычислений.
Параметрическое представление.
С целью дальнейшего уменьшения требуемой памяти для хранения и обеспечения необходимой гибкости было разработано несколько способов, которые абстрагируются от речевой волны как таковой, а представляют ее в виде набора параметров. Эти параметры отражают наиболее характерную информацию либо во временной, либо в частотной области. Например, речевая волна может быть сформирована сложением отдельных гармоник заданной высоты и заданными спектральными выступами на данной частоте. Альтернативный путь состоит в том, чтобы форму речевого тракта описать в терминах акустики и искусственным путем создать набор резонансов. Этот метод синтеза экономичнее волнового, т.к. требует значительно меньшего объема памяти, но при этом он требует больше вычислений, чтобы воспроизвести исходный речевой сигнал. Данный способ дает возможность манипулировать теми параметрами, которые отвечают за качество речи (значение формант, ширина полос, частота основного тона, амплитуда сигнала). Это дает возможность склеивать сигналы, так что переходы на границах совершенно не заметны. Изменения таких параметров как частота основного тона на протяжении всего сообщения дают возможность существенно изменять интонацию и временные характеристики сообщения. Наиболее популярным в наст.вр. методами кодирования в устройствах, использующих параметрическое представление сигналов, является метод, основанный на формантных резонансах и метод линейного предсказания (LPC - linear predictive coding). Для синтеза используются единицы речи различной длины: параграфы, предложения, фразы, слова, слоги, полуслоги, дифоны. Чем меньше единица синтеза, тем меньшее их количество требуется для синтеза. При этом, требуется больше вычислений, и возникают трудности коартикуляции на стыках. Преимущества этого метода: гибкость, немного памяти для хранения исходного материала, сохранение индивидуальных характеристик диктора. Требуется соответствующая цифровая техника и знание моделей речеобразования, при этом, лингвистическая структура языка не используется.
Синтез по правилам.
Описанные выше методы синтеза ориентированы на такие речевые единицы, как слова, предварительно введенные в устройство с голоса диктора. Данный принцип лежит в основе функционирования синтезаторов с ограниченным словарем. В синтезаторах с неограниченным словарем элементами речи являются фонемы или слоги , поэтому в них применяется метод синтеза по правилам, а не простая компоновка. Данный метод весьма перспективен, т.к. обеспечивает работу с любым необходимым словарем, однако качество речи значительно ниже, чем при использовании метода компоновки.
При синтезе речи по правилам также используются волновой и параметрический методы кодирования, но уже на уровне слогов.
Метод параметрического представления требует компромисса между качеством речи и возможностью изменять параметры. Исследователи обнаружили, что для синтеза речи высокого качества необходимо иметь несколько различных произношений единицы синтеза (например, слога), что ведет к увеличению словаря исходных единиц без каких бы то ни было сведений о контекстной ситуации, оправдывающей тот или иной выбор. По этой причине процесс синтеза получает еще более абстрактный характер и переходит от параметрического представления к разработке набора правил, по которым вычисляются необходимые параметры на основе вводного фонетического описания.Это вводное представление содержит само по себе мало информации. Это обычно имена фонетических сегментов ( напр, гласные и согласные) со знаками ударения, обозначениями тона и временных характеристик. Таким образом, метод синтеза по правилам использует малоинформационное описание на входе ( менее 100 бит/сек). Этот метод дает полную свободу моделирования параметров, но необходимо подчеркнуть, что правила моделирования несовеншенны. Синтезированная речь хуже натуральной, тем не менее, она удовлетворяет тестам по разборчивости и понятности. На уровне предложения и параграфа правила предоставляют необходимую степень свободы для создания плавного речевого потока.
3 Конвертация текста в речь.
Синтез по правилам требует детального фонетического транскрибирования на входе. Хотя для запоминания этой информации требуется мало памяти, чтобы извлечь из нее необходимые параметры, необходимы знания эксперта. Для конвертации неограниченного английского текста в речь необходимо сначала проанализировать его с целью получения транскрипции, которая затем синтезируется в выходную речевую волну. Анализ текста по своей природе задача лингвистическая и включает в себя определение базовых фонетических, слоговых, морфемных и синтакисическмих форм, плюс - вычленение семантической и прагматической информации. Системы конвертации текста в речь являются наиболее комплексными системами синтеза речи, включающие в себя знания об устройстве речевого аппарата человека, лингвистической структуре языка, а также которые должны учитывать ограничения, накладываемые областью применения системы, технико-технологической базой. Необходимо заметить, что и текст и речь являются поверхностными представлениями базовых лингвистических форм, поэтому задача преобразования текста в речь состоит в выявлении этих базовых форм, а затем в воплощении их в речи.
4 Система преобразования текста в речь MITalk.
На примере этой системы проиллюстрируем сильные и слабые стороны коммерческих версий. Разработка системы началась в конце 60-х гг. Изначально предполагалось разработать читающую машину для слепых, но система MITalk может применяться в любых ситуациях, где необходимо преобразовать текст в речь. Система имеет блок морфологического анализа, правила преобразования буква-звук, правила лексического ударения, просодический и фонематический синтез.
5 Анализ текста
Преобразование символов в стандартную форму.
В самых различных текстах можно обнаружить символы и аббревиатуры, которые не принадлежат к категории " правильно образованных слов". Такие символы как "%" и "&", аббревиатуры типа "Mr" и "Nov" должны быть преобразованы в нормальную форму. Были разработаны подробные руководства по транскрибированию чисел, дат, сум денег. Иногда возникают двусмысленные ситуации, такие как, например, использование знака дефиса в конце строки. Человек в таких случаях, чтобы определить подходящее произношение, обращается к контексту и к практическим знаниям, которые не поддаются алгоритмизации.
Морфологический анализ
В вводном тексте границы слов легко определяются. Можно хранить произношение всех английских слов. Размер словаря будет большим, но в таком подходе есть несколько привлекательных сторон. Во-первых, в любом случае необходим словарь слов, произношение которых является исключением из общих правил. Такими являются, например, заимствованные слова ( parfait, tortilla). Более того, все механизмы преобразования цепочки букв в фонетические значки допускают ошибки. Интересный класс исключений составляют часто употребительные слова. Например, звук /th/ в начале слова произносится как глухой фрикативный в большинстве слов (thin, thesis, thimble). Но в наиболее частотных, таких как короткие функциональные слова the, this, there, these, those, etc. начальный звук произносится как звонкий. Также /f/ всегда произносится глухо, за исключением слова "of". Другой пример. В словах типа "shave", "behave" конечный /e/ удлиняет предшествующий гласный, но в таком частом слове как "have" это правило не действует. Наконец, конечный /s/ в "atlas", "canvas" глухой, но в функциональных словах is, was, has он произносится звонко. Таким образом, приходим к выводу, что все системы должны иметь такой словарь исключений. Что касается нормальных слов, то здесь имеется два варианта. Первый крайний случай состоит в том, чтобы составить полный словарь. Хотя число слов ограничено, составить абсолютно полный словарь невозможно, т.к. постоянно появляются новые слова. Кроме того, в словарь необходимо будет внести все изменяемые формы слова. Другой крайний подход состоит в установлении ряда правил, которые бы преобразовывали цепочки букв в фонетические значки. Хотя эти правила очень продуктивны, нельзя избежать ошибок, что ведет к созданию словаря исключений. Чтобы правильно определить фонетическую транскрипцию слова, нужно правильно разбить слово на структурные составляющие. Было обнаружено, что важную роль в определении произношения играет морфема, минимальная синтаксическая единица языка. Система MITalk использует морфемный лексикон, что может рассматриваться как некоторый компромиссный подход между двумя крайними, упомянутыми выше. Многие английские слова можно расчленить на последовательность морфов, таких как префиксы, корни, суффиксы. Так слово "snowplows" имеет два корня и окончание, "relearn" имеет приставку и корень. Такие морфы являются атомными составляющими слова и они относительно стабильны в языке, новые морфы формируются в языке очень редко. Эффективный лексикон может иметь не более 10,000 морфов. Морфемный словарь действует вместе с процедурами анализа. Этот подход эффективен и экономичен, т.к. хранение морфемного словаря не занимает много места, а хранить все изменяемые формы слова не нужно. Так как морфы являются основными составляющими слова, проиллюстрируем их полезность при определении произношения. При соединении морфов они часто меняют свое произношение. Например, при образовании множественного числа существительных "dog" и "cat" конечный /s/ будет звонким в первом случае и глухим во втором. Это пример морфофонемного правила, касающегося реализации морфемы множественного числа в различных окружениях. Становится очевидным, что для эффективного и легкого определения произношения нужно распознать составляющие морфемы слова и обозначить их границы. Еще один плюс морфемного анализа - обеспечение подходящей базы для использования правил преобразования буква-звук. Большинство таких правил рассматривают слово как неструктурированную последовательность букв, используя окно сканирования для нахождения согласных и гласных кластеров, которые преобразуются в фонетические значки. Буквы "t" и "h" в большинстве случаев выступают как единый согласный кластер, но в слове "hothouse" кластер /th/ разрывается границей двух разных морфем. Гласный кластер /ea/ представляет много трудностей для алгоритмов буква-звук, но в слове changeable он явно разрывается. В системе MITalk морфемный анализ всегда проводится перед правилами преобразования букв в звуки. Лежащие в основе слова морфы не всегда очевидны. Например, некоторые морфы множественного числа не всегда легко определить: mice, fish. Подобные формы заносятся в словарь. При помощи морфемного лексикона и соответствующего алгоритма анализа 95-98% слов анализируется удовлетворительно. В результате им приписывается фонетическая транскрипция и часть речи.
Правила "буква-звук" и лексическое ударение
В системе MITalk нормализованный вводный текст подвергается морфологическому анализу. Может быть, что целое слово есть в словаре морфов, как, например, слово "snow". С другой стороны, слово может быть проанализировано как последовательность соединенных морфов. В английском языке среднее число морфов в слове, примерно два. В случае, если ни целое слово не может быть найдено в словаре морфов, ни проанализировано как последовательность морфов, в этом случае применяются правила преобразования "буква-звук". Важно подчеркнуть, что этот метод никогда не применяется, если морфемный анализ удался. Конвертация последовательности букв в последовательность звуков при помощи этих правил проходит в три этапа. Первый этап - отделение префиксов и суффиксов. Возможность отделения аффиксов не такая сильная, как в морфемном анализе, но действует удовлетворительно. Предполагается, что после отделения префиксов и суффиксов остается одна центральная часть слова, которая состоит из одного морфа, подвергаемого затем правилам преобразования.
Второй этап состоит в преобразовании согласных в фонетические значки, начиная с наиболее длинного согласного кластера до тех пор, пока все отдельные согласные не будут преобразованы. Последний этап - оставшиеся гласные преобразуются при помощи контекстов. Гласные преобразуются последними, потому что это наиболее трудная задача, зависящая от контекста. Например, гласный кластер /ea/ имеет 14 разных произносительных контекстов и несколько произношений (reach, tear, steak, leather).
В системе MITalk правила преобразования букв в звуки действуют в паре с широким набором правил расстановки лексического ударения. Еще 25 лет назад лингвистам не удавалось обнаружить никакой системы расстановки ударений в английских словах. В Настоящее время разработан ряд правил, эффективно справляющихся с этой задачей. Ударения зависят от синтаксической роли слова, например, прилагательное "invalid" отличается от существительного. Таких слов немного, но учитывать их необходимо. Кроме того, на некоторые суффиксы автоматически падают ударения в словах, как, например, в "engineer". Но бывают более сложные случаи, которые разрешаются применением циклических правил.
В системе MITalk разработаны несколько наборов таких правил, некоторые из которых включают в себя до 600 правил. Конечно, большинство из них употребляются довольно редко. Подразумеваются, что все сильные и неправильные формы преобразуются на стадии морфологического анализа. Правила же "буква-звук" используются для преобразования новых и неправильно написанных слов. Например, слово "recieved" получает правильную транскрипцию, благодаря этим правилам преобразования.
Парсинг.
Каждая схема преобразования неограниченного текста в речь должна включать синтаксический анализ. Необходимо определить синтаксическую роль слова, т.к. она часто влияет на произношение и ударение. Кроме того синтаксический анализ важен для определения правильного тонального контура и временных характеристик. Просодические характеристики важны для синтеза речи, чтобы она звучала живо и естественно. К сожалению, полный синтаксический анализ на уровне сложного предложения (clause-level parsing) осуществить нельзя. Тем не менее, возможно провести синтаксический анализ на уровне фразы (phrase-level parsing), в результате которого определяется большая часть необходимой для синтеза речи структуры, хотя в некоторых ситуациях неизбежны ошибки из-за отсутсвия анализа целого предложения. Встречается множество синтаксически двусмысленных предложений, таких как "he saw the man in the park with a telescope", для которых фразовый анализ достаточен.
В английском языке существует ряд синтагматических маркеров, по которым можно формально разграничить фразы: это вспомогательные глаголы, детерминативы в номинативных фразах. Система MITalk широко использует это и проводит высокоточный грамматический анализ (augmented-transition-network grammas). Фразовый анализ показал удовлетворительные результаты, хотя эффективный анализатор предложений несомненно улучшил бы работу системы. Пока анализаторы предложений сталкиваются со значительными трудностями, когда встречают неполное или синтаксически омонимичное предложение. По завершении деятельности блока синтаксического анализа система приписывает словам маркеры функциональных частей речи, отмечает синтаксические паузы как основу для дальнейшего уточнения произношения, временных харатеристик, частоты основного тона.
Модификация ударения и фонологические уточнения.
Последняя фаза анализа состоит в некоторых незначительных поправках к имеющейся уже фонетической транскрипции на основе анализа контекстного окружения. Простой пример определения произношения артикля "the", которое зависит от начального звука последующего слова. Кроме того, на этом этапе используются некоторые эвристические методы проверки правильного соотношения общего контура предложения с контурами отдельных слов. На этом этапе заканчивается подготовка исходного текста собственно к самому процессу синтеза.
6 Синтез.
Важно осознать, что в системе MITalk не используются готовые речевые волны даже в параметрическом представлении. Система не хранит параметрические представления множества морфов или слов. Вместо этого были разработаны правила контроля параметров, так что можно реализовать любую желаемую речевую волну на выходе.
Просодическая рамка.
Первый шаг в создании выходной речевой волны - создание временного контура и частоты основного тона ( основные корреляты интонации ), на основе которых строится детальная артикуляция отдельных фонетических элементов. Распределение ударения, которое было вычислено на стадии анализа, во многом ответственно за контур временного распределения и тональный контур. Часто интенсивность принимают за коррелят ударения, тогда как главными ключами являются длительность и изменения в тональном контуре. Согласные мало меняются по длительности, в то время как гласные более пластичны и могут легко сжиматься или растягиваться. Существует также тенденция растягивать слова на границе основных абзацев предложения, и наоборот, сжимать интервалы на относительно невыделенных участках. Кроме того, на основе временной рамки задается частота основного тона (или тональный контур). В утвердительных предложениях обычно высота тона резко поднимается на первом ударном слоге, затем плавно снижается до последнего ударного слога, где она резко падает. Вопросительные и повелительные предложения имеют различные тональные контуры. Кроме целостного контура предложения существуют еще локальные ударения. Большее ударение получают слова, выражающие отрицание или сомнение ( например, слово might ), значение частоты основного тона на них возрастает; новая информация в предложении также больше выделяется ударением. С другой стороны, высота тона используется в семантических и эмоциональных целях, что не может быть выведено из письменного текста. Необходимо лишний раз подчеркнуть важность составления правильного просодического контура, т.к. неправильный просодический контур может привести к трудностям в восприятии.
Синтез фонетических сегментов.
Когда завершено создание просодической рамки, создаются параметры, соответствующие модели речевого тракта. Обычно таких параметров 25, которые изменяются с интервалом 5 - 10 мсек. В настоящее время используются около 100 контекстных правил описания траектории изменения параметров. Когда значения параметров вычислены, они должны быть перенесены на соответствующую модель речевого тракта (обычно это формантная модель или LPC-модель). Выходная дискретная модель создается обычно на частоте 10 Кгц.
7 Оценка синтетической речи.
С точки зрения понятности, разборчивости качество синтезированной речи достаточно хорошее. Был проведен тест, где одна группа испытуемых прослушивала синтезированную речь с письменным вариантом перед глазами, а другая - без. Выяснилось, что результаты прослушивания мало отличаются друг от друга. Тем не менее, синтезированной речи не хватает живости и естественности, поэтому воспринимать ее на протяжении длительного времени трудно. Исследования показали, что фрикативные и назальные звуки требуют дальнейшего улучшения качества.
Билет 12
1. Типы лингвистических моделей; основные требования к ним и критерии их оценки.
Модель в лингвистике - искусственно создаваемое лингвистом реальное или мысленное устройство, воспроизводящее, имитирующее своим поведением (обычно в упрощенном виде) поведение оригинала в лингвистических целях.
Типы лингвистических моделей:
1. по охвату структуры языка:
· общие
(глобальные)
стремятся
охватить весь
язык:
· частные: фонетическая модель русского языка, модель системы гласных
2. по типологическому статусу:
· универсальные
стремятся
охватить все
языки мира:
· специфические характерны для определенного языка или группы языков: мягкость - твердость согласных рус. языка (не действует в англ., франц.)
3. по гносеологическому статусу:
· модели языка
· модели лингвистических знаний различные фонетические школы
· модели деятельности лингвиста
4. по отраженному аспекту языка и речевой деятельности:
Модели различаются не только по направленности на определенный объект, но и по используемым средствам моделирования (алгоритму или исчислению)
Алгоритм - строгая последовательность предписывающих правил
Исчисление - множество разрешающих правил (порядок выполнения не важен)
· анализирующие модели моделируют процесс понимания, используют логическое средство алгоритм
· синтезирующие модели моделируют процесс вербализации, смысла речевого отрезка
· порождающие модели автор Хомский объект моделирования - множество правильных речевых отрезков составляются правила различения приемлемого и неприемлемого; логический средство - исчисление
; не служат выражением смысла; на выходе - цепочки элементов (грамм. правильных предложений)
· собственно структурные модели основа всех остальных объект моделирования - структура языка как таковая; логический аппарат - логика отношений и классов. Пример: грамматический словарь Железняка
5. по конечной цели исследования
· теоретические
· описательные
· прикладные
6. по используемым методам
· математические модели
· психологические модели
· социологические модели
7. по функциональному статусу
· абстрактно обобщающие модели
· действующие
8. по используемым материальным средствам
· графические
· символьные
· компьютерные
Частная модель обычно входит в набор частных моделей, описывающий определенный уровень языка:
1. фонологический уровень
2. морфологический уровень
3. синтаксический
4. лексико-семантический
Основные теоретические требования к модели:
1. полнота модели - способность отражать все факты, на которые она рассчитана, на охват которых она претендует
2. простота - удобство, использования как можно меньшего числа средств (символов, правил) для достижения поставленной научной цели
3. объяснительная сила - способность модели вскрывать причины наблюдаемых фактов и предсказывать новые факты (например. модели исторического изменения слова; системы машинного перевода в очень малой степени объяснительные)
4. адекватность - свойство максимальной похожести на моделируемый объект, на оригинал, можно свести к объяснительной силе или теоретико-множественному соответствию
5. экономность - экономичное использование энергетических и временных ресурсов при применении модели
6. точность - возможность выполнения операций представляемым моделью формальным аппаратом
7. эстетические свойства - красота модели
Прикладные критерий: главное - удобство модели. Для моделирования языка очень важны логические средства реализации модели (компьютерное воплощение модели).
Синтаксический анализ. При использовании синтаксического анализа происходит интерпретация отдельных частей высказывания, а не всего высказывания в целом. Обычно сначала производится полный синтаксический анализ, а затем строится внутренне представление введенного текста, либо производится интерпретация.
Деревья анализа и свободно-контекстные грамматики. Большинство способов синтаксического анализа реализовано в виде деревьев. Одна из простейших разновидностей - свободно-контекстная грамматика, состоящая из правил типа S=NP+VP или VP=V+NP и полагающая, что левая часть правила может быть заменена на правую без учета контекста. Свободно-контекстная грамматика широко используется в машинных языках, и с ее помощью созданы высокоэффективные методы анализа. Недостаток этого метода - отсутствие запрета на грамматически неправильные фразы, где, например, подлежащее не согласовано со сказуемым в числе. Для решения этой проблемы необходимо наличие двух отдельных, параллельно работающих грамматик: одной - для единственного, другой - для множественного числа. Кроме того, необходима своя грамматика для пассивных предложений и т.д. Семантически неправильное предложение может породить огромное количество вариантов разбора, из которых один будет превращен в семантическую запись. Всё это делает количество правил огромным и, в свою очередь, свободно-контекстные грамматики непригодными для NLP.
Трансформационная грамматика. Трансформационная грамматика была создана с учетом упомянутых выше недостатков и более рационального использования правил ЕЯ, но оказалась непригодной для NLP. Трансформационная грамматика создавалась Хомским как порождающая, что, следовательно, делало очень затруднительным обратное действие, т.е. анализ.
Расширенная сеть переходов. Расширенная сеть переходов была разработана Бобровым (Bobrow), Фрейзером (Fraser) и во многом Вудсом (Woods) как продолжение идей синтаксического анализа и свободно-контекстных грамматик в частности. Она представляет собой узлы и направленные стрелки, “расширенные” (т.е. дополненные) рядом тестов (правил), на основании которых выбирается путь для дальнейшего анализа. Промежуточные результаты записываются в ячейки (регистры). Ниже приводится пример такой сети, позволяющей анализировать простые предложения всех типов (включая пассив), состоящие из подлежащего, сказуемого и прямого дополнения, таких, как The rabbit nibbles the carrot (Кролик грызет морковь). Обозначения у стрелок означают номер теста, а также либо признаки, аналогичные применяемым в свободно-контекстных грамматиках (NP), либо конкретные слова (by). Тесты написаны на языке LISP и представляют собой правила типа если условие=истина, то присвоить анализируемому слову признак Х и записать его в соответствующую ячейку.
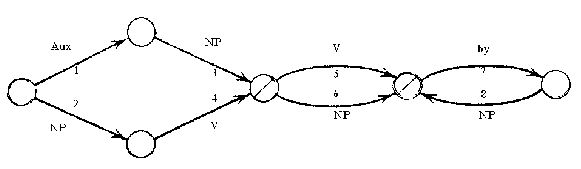
Разберем алгоритм работы сети на вышеприведенном примере. Анализ начинается слева, т. е. с первого слова в предложении. Словосочетание the rabbit проходит тест, который выясняет, что оно не является вспомогательным глаголом (Aux, стрелка 1), но является именной группой (NP, стрелка 2). Поэтому the rabbit кладется в ячейку Subj, и предложение получает признак TypeDeclarative, т.е. повествовательное, и система переходит ко второму узлу. Здесь дополнительный тест не требуется, поскольку он отсутствует в списке тестов, записанных на LISP. Следовательно, слово, стоящее после the rabbit - т. е. nibbles - глагол-сказуемое (обозначение V на стрелке), и nibbles записывается в ячейку с именем V. Перечеркнутый узел означает, что в нем анализ предложения может в принципе закончиться. Но в нашем примере имеется еще и дополнение the carrot, так что анализ продолжается по стрелке 6 (выбор между стрелками 5 и 6 осуществляется снова с помощью специального теста), и словосочетание the carrot кладется в ячейку с именем Obj. На этом анализ заканчивается (последний узел был бы использован в случае анализа такого пассивного предложения, как The carrot was nibbled by the rabbit). Таким образом, в результате заполнены регистры (ячейки) Subj, Type, V и Obj, используя которые, можно получить какое-либо представление (например, дерево).
Расширенная сеть переходов имеет свои недостатки:
немодульность;
сложность при модификации, вызывающая непредвиденные побочные эффекты;
хрупкость (когда единственная неграмматичность в предложении делает невозможным дальнейший правильный анализ);
неэффективность при переборе с возвратами, т.к. ошибки на промежуточных стадиях анализа не сохраняются;
неэффективность с точки зрения смысла, когда с помощью полученного синтаксического представления оказывается невозможным создать правильное семантическое представление.
Билет 13
1. Метаязыки формального описания семантических структур.
Семантические метаязыки различаются:
по объекту, который они описывают (морфема, лексема, словосочетание, предложение, текст в целом).
по аспекту языковой структуры, который они отражают: (парадигматический аспект
синтагматический аспект)
Сходимость МЯ - возможность переводить с одного МЯ на другой.
По описываемому объекту:
1. значение морфем МЯ
· МЯ компонентного анализа (Найда, Апресян, Катс)
· МЯ пресуппазиционного анализа (прототипический анализ): если высказывание подвергнуть отрицанию, то отрицается только имплицитно выраженная часть, то, что не отрицается - ассерция
2. значение лексем исследуется
в синтагматичсеком аспекте - сочетаемость лексем:
· теория семантической валентности, понятие модели управления (Апресян)
в парадигматическом аспекте:
· глубинные падежи (агенс, интсрументалис ...), падежная рамка Филлмора
3. значение словосочетаний исследуется
в парадигматическом аспекте при помощи тех же МЯ описания, что и лексемы,
в синтагматическом плане:
· язык лексических параметров и функций (Апресян), понятие лекс. параметра связано с понятием устойчивой сочетаемости слов в словосочетании
4. значение предложения
в парадигматическом аспекте:
· семантическая сеть (Скрэгг: "Семантическая сеть как модель памяти")
· язык исчисления предикатов (Дж. Лакофф "Постулаты речевого общения", импликация, пресуппозиция, пропозиция, условия искренности. условия мотивированности)
5. значение текста в целом
в парадигматическом аспекте используются такие макроструктуры, как сценарии. фреймы, планы, сцены,
фрейм - базовая структура представления знаний
сценарий динамический - набор фреймов, развертывающийся во времени.
· семантическая сеть ()
Чейф: - теория организации памяти
три вида памяти:
поверхностная (surface)
кратковременная (shallow)
долговременная (deep)
иерархия событий -> иерархия событий различной личностной значимости
личностная зависимость
понятие текущего сознания (consciousness)
· язык концептуальных зависимостей (Шенк)
· язык шаблонов (templates, Уилкс:)
6. процессы
· понимания (Шенк)
· вербализации (Маккьюин)
Роджер Шенк: знания не могут быть истолкованы в лингвистических терминах -> язык концептуальных зависимостей: P-Trans (физическое перемещение), M-Trans (интеллектуальное перемещение).
Шенком была постулирована независимость языкового представления от ЕЯ, тем не менее язык КЗ оказался привязан к поверхностному синтаксису английского языка. Каждое высказывание запускает цепочку концептуальных выводов (inferences), позволяющих правильно понимать ситуацию (Мила была голодна, она взяла путеводитель Митчелина).
Модель SAM (Script Applying Mechanism) является компьютерной программой, которая позволяет понимать связность текста за счет применения сценариев:
· POLITICS (ведет диалог, моделирует политическую идеологию)
· PAM -> TALE-SPIN - порождение сказок
· FRUMP - машинное реферирование сообщений на нескольких языках, чтение , опирающееся на понятие интереса (Integral Partial Parser)
Категории, встречающиеся у Шенка:
· интерес
· объяснение
· память (организация концептуальной памяти)
· ожидание
· понимание движимого ошибками
Уилкс, "Анализ предложений английского языка": вводит единую форму представления - шаблон (template), интуитивным соответствием которого можно считать базисную форму представления "агенс - действие - объект. Шаблоны строятся из более мелких блоков - формул, соответствующих толкованиям отдельных лексем. Для того, чтобы построить полное сем. представление текста (сем. блок), шаблоны объединяются с помощью структур более высокого уровня - надшаблонов (paraplates) и правил вывода умозаключений;
· каждая из готовых структур построена на базе 80 атомарных сем. элементов, а также функций и предикатов, задаваемых на этом множестве.
· система на LISPe, переводит тексты с англ. на фр.
· для разрешения неоднозначности используется цепь умозаключений
· нет синтаксического анализа в обычном понимании, сразу переходит к сем. представлениям; не содержит в явном виде никакой синт. информации, только формула (Ф), которая имеет вид ДЗ; главным считается самый правый элемент Ф, который задает фундаментальную категорию для всей Ф.
· содержит глубинные падежные элементы
· большая гибкость при описании смысла, чем у метода Фодора и Катса, в которых нет глубинных падежных элементов
· шаблоны имеют вид сети, состоящей из Ф
· шаблон состоит из 3 узлов: агенс, действие. объект.
2. Гипертекстовые системы
Гипертекст - это текст. смысловые элементы которого могут читаться в разной последовательности.
Последовательность чтения - произвольная. Между текстовыми фрагментами указаны разрешенные переходы. Как правило, от одного фрагмента можно перейти к нескольким другим. Читать можно с любого элемента в разных направлениях. Компьютеры позволяют мгновенно переходить от одного фрагмента текста к другому, что позволяет читать нелинейные так же легко, как линейные.
Гипертекст - компьютаризованный нелинейный текст. Нельсон и Энгельбарт впервые реализовали ГТ в конце 60 гг.
Особенности ГТ по сравнению с традиционными нелинейными текстами (текст с комментариями, ссылками, энциклопедия):
1. явная выраженность сетевой структуры: узлы (текстовые фрагменты) и связи (возможность перехода от одного ТФ к другому -> навигация). Связь может быть однонаправленной от фрагмента к комментарию или двунаправленной между двумя фрагментами. Связь может носить иерархический характер - от общего к целому.
Пользовательский интерфейс:
· переход - не более двух клавиш
· пользователь должен иметь средства ориентации: При каждом узле дается оглавление - локальная ориентация. Глобальная ориентация - наглядное изображение структуры гипертекстов ой сети, в которой помечается путь, пройденный пользователем
· многооконная система позволяет видеть одновременно несколько ФТ на экране.
2. открытость гипертекста (для включения новых ФТ, читатель может выступать соавтором)
Пример ГТ: изобразительная и звуковая система Гипермедиа (комплексное использование информации разной природы, синтез разных искусств)
Динамический ГТ постоянно дополняется новыми текстовыми фрагментами (необходимо находить связи для поступающих извне ФТ)
ГТ - сама форма организации материала и технология, без которой невозможна его организация. Гт - накопление информации в БД, доступ к данным - через запросы. связь важна для пользователя, поэтому в БД ГТ системы нет заранее установленных связей. Выдача информации - воспроизведение фрагментов сетей, сформированных к этому моменту в БД. выдаются отд. узлы и участки сети в графической форме вместе с маршрутами движения. В ГТ сети можно легко отражать идеи участников проекта, для дальнейшего изучения их в интерактивном режиме сразу несколькими участниками.
4 вида ГТС (обзор Конилина):
1. библиотечные макросистемы (шире, чем поиск литературы) XANADU, Нельсон система хранения и актуализации информации), TEXTNET (принцип динамического упорядочения, перечень узлов)
2. средства исследования проблем: IBIS, Риштель (аспекты, позиции, аргументы); ; JOG (изучение справочной энциклопедической литературы, выведение страниц)
3. системы для просмотра БД (подобны библиотечным. но меньше, служат для получения справочных данных) Browsing Systems, WE среда нужна для описания системы просмотра, легкость доступа, добавление новой информации не разрешено
4. системы широкого назначения (экспериментирование в разл. направлениях): INTERMEDIA фирмы XEROX
Билет 14
1. Автоматизация анализа письменного текста: основные подходы к решению проблемы.
Существует 2 основные стратегии решения проблемы:
1. модульный подход - последовательный анализ по уровням (морфологический, синтаксический, семантический, прагматический)
2. интегральный подход (более современный и более адекватный, Р. Шенк)
1. Системы модульного типа (Леонтьева):
| модуль морфологического анализа |
-> полное морф. представление |
| модуль синтаксического анализа |
-> полное синт.представление |
| модуль семантического анализа |
-> частичное (фрагментарное) представл. |
|
прагматический анализ (пока не реализован) |
Для широких ПО может быть использован в нескольких системах:
· СМП (SYSTRAN)
· системах извлечения знаний
· ИПС
2. Системы интегрального типа
Концептуальный анализ |
-> |
фрагментарные концептуальные представления: | ||
морф.анализ |
синт.анализ |
сем. анализ |
сценарии, фреймы. планы. | |
· Ищет в тексте диагностические слова
· заполняет пустые слоты в сценарии
· делает ряд концептуальных выводов (inferences) о смысле текста (в результате чего способна отвечать на поставленные вопросы по содержанию)
· на определенных этапах подключает процедуры
· нельзя получить уровневое представление
· тексты узко ограниченной тематики
Пример: интегральная система анализа Шенка:
1. MARGE (Memory Response Generation in English) - обработка концептуальной информации. В основе лежит теория концептуальных зависимостей - комплексная теория человеческого мышления.
Работает в двух режимах:
· перефразирование (перевод входной фразы на ЯКЗ)
· концептуальный вывод
2. Модель SAM (Script Applying Mechanism) является компьютерной программой, которая позволяет понимать связность текста за счет применения сценариев:
· POLITICS (ведет диалог, моделирует политическую идеологию)
· PAM -> TALE-SPIN - порождение сказок
· FRUMP - машинное реферирование сообщений на нескольких языках, чтение , опирающееся на понятие интереса (Integral Partial Parser)
2. Терминологические банки данных: структуры, функции, методы построения.
ТБД - автоматизированная система инвентаризации и машинного представления терминологической лексики и ее семантизации в системах машинного и человеко-машинного речевого общения. Это единая служба с удобным доступом, описывающая все сведения о термине и ликвидирующая неравномерность описания терминологии.
Научные задачи:
· моделирование терминологической системы РЯ как системы подсистем
· построение общенаучных и общетеоретических тезаурусов
· исследование русской терминологии
Типы традиционного использования ТБД:
· справочно-информационное обслуживание специалистов различных областей знания
· обеспечение традиционного перевода научно-технической литературы
· обеспечение АСОТ, включая системы машинного перевода
· лингвистическое обеспечение авт. систем информации
· обеспечение работ по упорядочению терминологии
· подготовка и издание терминологических словарей
· унификация определенных терминов
· подготовка научных отчетов о составе РЯ
Организационная структура ТБД:
· терминологические центры
· службы переводов (переводческая функция)
· службы стандартизации (нормативная функция)
· университеты (исследовательская функция)
· всероссийские органы НТИ (по АСУ и ИПС)
Функциональная структура ТБД:
1. Головной ТБД - справочно-поисковый аппарат по видовым банкам данных:
· ведение коммуникативного формата данных
· организация и руководство работами по передаче данных в ТБД
· обработка и ввод данных
· обслуживание предприятий
2. Специализированные ТБД (сбор, хранение , обработка информации), могут включать существующие ТБД, словарно-терминологические службы НТИ:
отбор представительного массива источников
ввод и обновление терминологической информации в БД
передача информации другим СТБД и ГТБД
эксплуатация СТБД в соответствии с конкретными задачами организации.
ТБД состоит из ряда массивов, которые называются подфондами.
Подфонды - массивы терминов, которые создаются и хранятся в центральном органе МФРЯ (Машинный фонд РЯ) на базе массивов первичного типа.
Подфонды:
специальных и межотраслевых терминов, фигурирующих в отдельных отраслях знаний и деятельности
общенаучных и общетехнических терминов
терминоэлементов (используются в нескольких терминосистемах).
3. Примеры оформления сложных документов (сноски, газетная верстка, колонтитулы и т. д) в MS Word 5.0.
Сноски:
1. курсор на месте символа ссылки на сноску
2. Format, Footnote
3. в поле reference mark ввести ссылку на сноску (не более 28 символов)
4. enter
5. ввести текст сноски (до нескольких абзацев)
перемещение между сноской и текстом: Jump Footnote
использование окна сносок: Esc W S F
переход из окна в окно: F1
местоположение сносок:
· по умолчанию - на той же стр., где ссылка
· Format Division Layout: same page, end
Газетная верстка:
колонки:
1. Options: Show Layout Yes или Alt-F4
2. Esc Format Division Layout
колонтитулы:
1. курсор в начало документа
2. ввести текст + enter
3. курсор внутрь текста или выделить текст
4. Esc Format Running Head: Position:
Top Bottom None Odd Even First Alignment: left margin Edge-of-paper
5. enter
Быстрое создание колонтитулов:
1-3 - то же самое
4. верхний колонтитул: Ctrl+F2
нижний колонтитул: Alt+F2
На каждой странице может быть не более двух колонтитулов: верхний и нижний
Выравнивание колонтитулов: Format Paragraph или Alt C, Alt R.
Вывод номера страницы/даты:
1. курсор в то место колонтитула, где будет страница.
2. набрать page/date
3. F3
Билет 15
1. Когнитивная лингвистика и ее основные исследовательские программы.
Когнитивная наука
· некий раздел научного знания, центральное понятие которого знание и репрезентация
· исследовательская дисциплина изучающая устройство человеческого сознания, используя различные способы репрезентации и компьютерную метафору
· совокупность современных эмпирических знаний, направленных на поиск ответов на давние эпистимологические вопросы, особенно о природе знания
Когнитивная лингвистика - подход, который допускает в лигвитсике применение методов когнитивной науки.
Когнитивная наука изучает устройство и функционирование концептуальных структур в человеческом сознании, обеспечивающее специфическое для человека взаимодействие с другими людьми и окружающим миром в целом.
КН возникла как реакция на господство позитивистских установок (обезличенная наука, например, мат. логика - постулаты сложнее самих высказываний). В 60-70 гг. произошла ревизия идей позитивизма в пользу реализма и учета человеческого фактора.
Началом КН можно считать 11 сентября 1956, когда в г. Кембридж штата Масачусетс открылся семинар по теории информации, где были зачитаны работа Ньюэлла и Саймона "Logic Theoretic", в которой исследовались процессы принятия административных решений (в последствие эта работа была удостоена Нобелевской премии по экономике).
Характерные черты когнитивной науки:
· междисциплинарность (существует комплекс наук, которые называются когнитивными: когнитивная лингвистика, когнитивная философия, когитология)
· использование репрезентации знаний в качестве центрального понятия
· использование компьютерной метафоры (сначала аппаратная hardware компьютерная метафора: человеческий мозг подобен компьютеру; затем программная software компьютерная метафора: в сознании человека существуют структуры подобные компьютерным программам; одно из доказательств - наличие кратковременной и долговременной памяти у человека;)
· обращение к когнитивным структурам (сценариям и фреймам)
· исследовательский метод - вычислительный эксперимент (термин Герберта Саймона) - метод интроспекции, т.е. наблюдения над языком.
· пониженный интерес к культурным и социологическим аспектам функционирования знаний
Метанаучные элементы и ценности (вся совокупность представлений о предмете, которые в рамках данной научной концепции считаются истинными и не могут быть фальсифицированными (аксиомы)):
В основе КН лежит реалистическая традиция: человеческое мышление познаваемо и к нему могут быть применены конкретные исследовательские методы. Это воплощается в понятии материально символьная система. Она состоит из символов - материальных образований, которые могут выступать в качестве выражений. Символьная структура - набор процессов создания, модификации и операций с выражениями.
Предполагается, что существует некоторый уровень анализа, на котором можно отвлечься от физической природы вещей, некоторый уровень изучения психических функций человека, отличный от нейро-хирургического, - уровень концептуальных репрезентаций. Репрезентативный уровень оперирования символьными системами не зависит от материального носителя информации. Он изучается с других уровней.
Когнитивные единицы:
· концепты
· пропозиции
· схемы (типа гештальдов)
· динамические фреймы (сценарии)
Когнитивная лингвистика - выяснение лингвистической адекватности когнитивных построений.
Основные исследовательские программы КН:
1. Программа Чейфа - теория организации памяти
три вида памяти:
· поверхностная (surface)
· кратковременная (shallow)
· долговременная (deep)
· иерархия событий -> иерархия событий различной личностной значимости
· личностная зависимость
· понятие текущего сознания (consciousness)
текущее сознание
| восприятие | поверх. память | кратк. память | долговр. память | воображаемое событие |
2. Программа Роджера Шенка и его учеников (Stanford, конец 60-нач. 70 гг.): MARGE (Memory Response Generation in English) - обработка концептуальной информации. В основе лежит теория концептуальных зависимостей - комплексная теория человеческого мышления.
Работает в двух режимах
· перефразирование (перевод входной фразы на ЯКЗ)
· концептуальный вывод
Шенк утверждал, что знания не могут быть истолкованы в лингвистических терминах и разработал язык концептуальных зависимостей: P-Trans (физическое перемещение), M-Trans (интеллектуальное перемещение).
Шенком была постулирована независимость языкового представления от ЕЯ, тем не менее язык КЗ оказался привязан к поверхностному синтаксису английского языка. Каждое высказывание запускает цепочку концептуальных выводов (inferences), позволяющих правильно понимать ситуацию (Мила была голодна, она взяла путеводитель Митчелина).
Модель SAM (Script Applying Mechanism) является компьютерной программой, которая позволяет понимать связность текста за счет применения сценариев:
· POLITICS (ведет диалог, моделирует политическую идеологию)
· PAM -> TALE-SPIN - порождение сказок
· FRUMP - машинное реферирование сообщений на нескольких языках, чтение , опирающееся на понятие интереса (Integral Partial Parser)
Достижения Шенка:
· процедурная адекватность
· демонстрация роли знаний в процессе понимания ЕЯ
· построение ряда конкретных когнитивных моделей
· демонстрация роли когнитивных ожиданий в понимании
Категории, встречающиеся у Шенка:
· интерес
· объяснение
· память (организация концептуальной памяти
· ожидание
· понимание движимого ошибками
3. Программа Джорджа Лакоффа:
· порождающая семантика
· лингвистические гештальды (целое - не есть сумма частей)
· теория семантического прототипа (базисный уровень)
· теория метафоры (неосознанные и творческие когнитивные процессы)
Эксперименциальная лингвистика
1. Концептуализация двух сортов:
· базового уровня (семантика прототипов)
· образные схемы (image schemas): контейнер, вместилище; путь; контакт; часть-целое
2. Когнитивные творческие процессы:
· метафоризация
· метонимия
· схематизация
· категоризация
3. Когнитивные нетворческие (базовые) процессы
· фокусировка
· сканирование
· сдвиг точки зрения
4. Теория ментальных пространств
· пространство прошлого
· пространство будущего
· непосредственное действие (?)
· вымышленная ситуация
4. Программа Тальми об отношении грамматики к мышлению
Грамматика - одна из когнитивных сфер человека.
Цели:
· Изучение семантико-постранственных отношений
· Фигура и фон
· Изучение каузативов (пить - поить)
Когнитивные категории:
1. измерение:
-
недискретность
пространство
материя
время
деятельность
дискретность
предметы
события
2. плексность (plexity):
|
униплексность Он вздохнул |
мультиплексность Она вздыхала |
3.граничный статус:
|
неограниченные сущности вода спать |
ограниченные сущности море одеваться |
4. расчлененность:
|
дискретные сущности |
недискретные сущности |
5. Степень распространения:
|
ограниченная лестница |
неограниченная река |
6. Модель дистрибуции
Категория динамики сил задумана тальми как обобщение казуальности.
Билет 2
1. Понятие репрезентации в науках о языке и мышлении человека.
Понятие репрезентации знаний является одним из центральных в когнитивной науке вообще, и в когнитивной лингвистике в частности.
1.Репрезентация - (общефилософский смысл) сущность произвольной природы, выступающая в познавательной деятельности человека в качестве заместителя некоторой другой сущности.
Человек творит мир артефактов:
материальные (орудия)
когнитивные (орудия мысли)
Репрезентация - когнитивный артефакт.
2.Репрезентация - символьное выражение на специальном репрезентационном языке, выступающие в познавательной деятельности человека в качестве заместителя некоторой сущности иной природы. Например мат. модели, любые теории.
3.Репрезентация - (в лингвистике) символьное выражение на специальном репрезентационном языке, рассматриваемое как отличное от непосредственно данной формы осуществления некоторого другого символьного же выражения, а также сама эта непосредственно данная форма, рассматриваемая в ряде других форм.
4.Репрезентация - некоторая гипотетическая ментальная структура, замещающая ту или иную сущность из внешнего мира.
Предполагается, что существует некоторый уровень анализа, на котором можно отвлечься от физической природы вещей, некоторый уровень изучения психических функций человека, отличный от нейро-хирургического, - уровень концептуальных репрезентаций. На этом уровне моделируются когнитивные процессы (символьно/на ЭВМ).
Типология репрезентаций:
1. представление знаний (концептуальные репрезентации) vs представление языковых структур (фонологические, синтаксич., семантические репрезентации)
Репрезентация языковых структур - представление высказывания, предложения, текста (требование лингвистической релевантности). Понимание-> анализ -> сем. репрезентация. Компоненты языковой структуры - компоненты языка, а концептуальные репрезентации ими не являются.
|
2. сентенциональные |
vs |
идеограмматические |
|
|
(логические) построены по законам ЕЯ: язык исчисления предикатов |
(аналоговые репрезентации,) хранятся в виде образа в человеческом мозге |
||
Иногда сюда включают еще и списочные представления (таблицы, БД)
|
3. декларативные (знания "что") |
vs |
процедурные (знания "как") |
|
|
экономный способ (указание на факты) (структурирование предметной области) |
точный способ (указание на действие) | ||
4. формализованные vs неформализованные
5. внешние vs внутрисистемные
|
6. логические |
vs |
эвристические |
|
представления знаний исчисление предикатов |
сетевые. фреймовые, продукционные | |
Понятие репрезентации также активно используется в порождающей семантике. Так, например, семантическая репрезентация речевого отрезка интерпретируется как его запись на каком-либо семантическом метаязыке.
2. Операционные системы как основной вид программного обеспечения для ПЭВМ. Операционная система MS-DOS, основные группы команд.
Операционная система - это программа, которая загружается при включении компьютера. Она производит диалог с пользователем, осуществляет управление компьютером, его ресурсами (оперативной памятью, местом на диске и т.д.), запускает другие (прикладные) программы на выполнение. ОС обеспечивает пользователю и прикладным программам удобный способ общения (интерфейс с устройствами компьютера.
Функции ОС:
· управление памятью
· управление вводом-выводом
· управление файловой системой
· управление взаимодействием процессов
· диспетчеризация процессов
· защита и учет использования ресурсов
· обработка командного языка
MS-DOS (Microsoft):
· PC-DOS (IBM, вариант MS-DOS), DR-DOS (Digital Research, совместима с MS-DOS);
· OS-2 (для машин IBM PS-2 series), UNIX, Macintosh OS, MAINFRAMES (?).
Версии 1.0 (1981) - 6.0 (1992: память cache, disk defragmentation utility for speed disk data access, optional dynamic file compression, that can double disk storage space, automatically loads itself into upper and high memory leaving more conventional memory free).
Модульная структура MS-DOS:
1. BIOS
2. Boot Record
3. IBMBIO.com
4. IBMDOS.com
5. Command.com
6. Utilities
Список внутренних команд ( недоступны для просмотра, выполняются COMMAND.COM):
|
break cd cls copy CTTY date del |
dir erase mkdir path prompt rename rmdir |
set time type ver verify vol exit |
Остальные команды - внешние. Они располагаются в каталоге DOS и являются самостоятельными программами (tree, label, diskcopy, diskcomp, chkdsk и т.д.) .
Основные группы команд MS-DOS:
|
1. Команды работы с каталогами (10): cd md dir rd append join subst path tree xcopy |
2. Команды работы с файлами (21): 2.1 исходные: copy type del rename erase comp 2.2 команды-фильтры: find sort more 2.3 attrib append path join subst restore backup fastopen FC (аналог compare) recover share |
3. Команды работы с дисками (14): 3.1 основные format label chkdsk diskcopy diskcomp sys vol 3.2 команды начальной работы с диском fdisk select assing backup restore fastopen recover |
4. Команды управления ресурсами ПЭВМ: (настройка компьютера на пользователя): ver date time assign cls graphics prompt break set keyb nlsfunc fastopen chcp command CTTY mode verify graphtable |
СЕМАНТИЧЕСКИЕ СЕТИ.
Семантическая сеть - структура для представления знаний в виде узлов, соединенных дугами. Самые первые семантические сети были разработаны в качестве языка-посредника для систем машинного перевода, а многие современные версии до сих пор сходны по своим характеристикам с естественным языком. Однако последние версии семантических сетей стали более мощными и гибкими и составляют конкуренцию фреймовым системам, логическому программированию и другим языкам представления.
Начиная с конца 50-ых годов были создано и применены на практике десятки вариантов семантических сетей. Несмотря на то, что терминология и их структура различаются, существуют сходства, присущие практически всем семантическим сетям:
1. узлы семантических сетей представляют собой концепты предметов, событий, состояний;
2. различные узлы одного концепта относятся к различным значениям, если они не помечено, что они относятся к одному концепту;
3. дуги семантических сетей создают отношения между узлами-концептами (пометки над дугами указывают на тип отношения);
4. некоторые отношения между концептами представляют собой лингвистические падежи, такие как агент, объект, реципиент и инструмент (другие означают временные, пространственные, логические отношения и отношения между отдельными предложениями;
5. концепты организованы по уровням в соответствии со степенью обобщенности так как, например, сущность, живое существо, животное, плотоядное,;
Однако существуют и различия: понятие значения с точки зрения философии; методы представления кванторов общности и существования и логических операторов; способы манипулирования сетями и правила вывода, терминология. Все это варьируется от автора к автору. Несмотря не некоторые различия, сети удобны для чтения и обработки компьютером, а также достаточно мощны, чтобы представить семантику естественного языка.
ИСТОРИЧЕСКАЯ СПРАВКА.
Фрег представил логические формулы в виде деревьев, которые однако мало напоминают современные семантические сети. Еще одним пионером стал Чарльз Сандерз Прис, который использовал графические записи в органической химии.
Он сформулировал правила выводы с использованием экзистенциональных графов.
В психологии Зельц использовал графы для представления наследственности некоторых характеристик в иерархии концептов. Научные изыскания Зельца имели огромное влияние на изучение тактики в шахматах, который в свою очередь повлиял на таких теоретиков, как Саймон и Ньюэлл.
Что касается лингвистики, то первым ученым, занимавшимся разработкой графических описаний, стал Теньер. Он использовал графическую запись для своей грамматики зависимостей. Теньер оказал огромное влияние на развитие лингвистики в Европе.
Впервые семантические сети были использованы в системах машинного перевода в конце 50-х - начале 60-х годов. Первая такая система, которую создала Мастерман, включала в себя 100 примитивных концептов таких, как, например, НАРОД, ВЕЩЬ, ДЕЛАТЬ, БЫТЬ. С помощью этих концептов она описала словарь объемом 15000 единиц, в котором также имелся механизм переноса характеристик с гипертипа на подтип. Некоторые системы машинного перевода базировались на корреляционных сетях Цеккато, которые представляли собой набор 56 различных отношений, некоторые из которых - падежные отношения, отношения подтипа, члена, части и целого. Он использовал сети, состоящие из концептов и отношений для руководства действиями парсера и разрешения неоднозначностей.
В системах искусственного интеллекта семантические сети используются для ответа на различные вопросы, изучение процессов обучения, запоминания и рассуждений. В конце 70-х сети получили широкое распространение. В 80-х годах границы между сетями, фреймовыми структурами и линейными формами записи постепенно стирались. Выразительная сила больше не является решающим аргументом в пользу выбора сетей или линейных форм записи, поскольку идеи записанные с помощью одной формы записи могут быть легко переведены в другую. И наоборот, особо важное значение получили второстепенные факторы, как читаемость, эффективность, неискусственность и теоретическая элегантность, также учитываются легкость введения в компьютер, редактирование и распечатка.
РЕЛЯЦИОННЫЕ ГРАФЫ.
Самые простые сети, которые используются в системах искусственного интеллекта, - реляционные графы. Они состоят из узлов, соединенных дугами. Каждый узел представляет собой понятие, а каждая дуга - отношения между различными понятиями. На рисунке 1 представлено предложение “Собака жадно гложет кость”. Четыре прямоугольника представляют понятия собаки, процесса гложения, кости и такой характеристики, как жадность. Надписи над дугами означают, что собака является агентов гложения, кость является объектом гложения, а жадность - это манера гложения.
Терминология, использующаяся в этой области различна. Чтобы добиться некоторой однородности, узлы, соединенные дугами, принято называть графами, а структуру, где имеется целое гнездо из узлов или где существуют отношения различного порядка между графами, называется сетью. Помимо терминологии, использующейся для пояснения, также различаются способы изображения. Некоторые используют кружки вместо прямоугольников; некоторые пишут типы отношений прямо над дугами, не заключая их в овалы; некоторые используют аббревиатуры, например О или А для обозначения агента или объекта; некоторые используют различные типы стрелок. На рисунке 2 изображен граф концептуальных зависимостей Шенка. <=> означает агента. INGEST (поглощать) - один из примитивов Шенка: ЕСТЬ - ПОГЛОЩАТЬ твердый объект; ПИТЬ - ПОГЛОЩАТЬ жидкий объект; ДЫШАТЬ - ПОГЛОЩАТЬ газообразный объект. Дополнительная стекла слева показывает, что кость переход из неуказанного места к собаке.
Поскольку довольно сложно ввести в компьютер некоторые диаграммы и при этом они занимают много места при печати, многие ученые записывают свои графы в более компактном варианте. Например, то же предложение Сова предложил записать в линейном виде с использованием некоторых элементов из рисунка 1:
[ЕСТЬ]-
(AGNT) -> [СОБАКА]
(OBJ) -> [КОСТЬ]
(MANR) -> [ЖАДНОСТЬ]
В этом варианте записи квадратные скобки обозначают понятия, а круглые скобки содержат в себе названия отношений. Все линейные формы записи очень похожи на фреймовые структуры.
ГРАФЫ С ЦЕНТРОМ В ГЛАГОЛЕ.
Глаголы соединяются с группой существительного с использованием падежных отношений. Например, с предложении “Mary gave a book to Fred”, Mary агент давания, book объект этого процесса, а Fred реципиент глагола “давать”. Помимо падежных отношений в предложении в естественном языке также имеются средства для связи отдельных предложений. Такие отношения необходимы для следующего:
Союзы. Самый простой способ соединить предложения - это поставить между ними союз. Некоторые союзы, как например “и”, “или”, “если” обозначают логическую связь; некоторые, такие как “после того, как”, “когда”, “пока”, “с тех пор, как” и “потому что”, выражают временные отношения и причину.
Глаголы, требующие подчиненное предложение. Падежные фреймы многих глаголов требуют подчиненного предложения, являющегося обычно прямым дополнением. К такому типу относятся глаголы “говорить”, “считать”, “думать”, “знать”, “быть убежденным”, “угрожать”, “пытаться” и др.
Определители, относящиеся к целому предложению. Многие наречия и пропозиционные фразы относятся только к глаголу, но некоторые определяют целое предложение. Такие наречия, как “обычно”, “вероятно”, в большинстве случаев ставятся в начале предложения. А например, слово “однажды” определяет весь рассказ, следующий после него.
Модальные глаголы и времена. Такие глаголы, как “may”, “can”, “must”, “should”, “would” и “could” имеют модальное значение и относятся ко всему предложению, где они встречаются. Временное отношение может быть выражено как формой прошедшего времени глаголов, так и обстоятельствами “сейчас”, “завтра” или “однажды” и другими.
Связанный дискурс. Помимо отношений, выраженных в одном предложении, существуют также отношения более высокого порядка между отдельными предложениями рассказа или какого-либо другого повествования. Многие из них не выражены эксплицитно: временные отношения и следование аргументов может быть, например, имплицитно выражено порядком следования предложения друг за другом в тексте.
Именно потому, что глагол отводится такая важная роль в предложении, многие теория делают его своим центральным связующим звеном. Этот подход берет свое начало из Индо-Европейской языковой семьи, где модальность и временные отношения выражаются изменением глагольной формы. Рассмотрим следующий пример: “While a dog was eating a bone, a cat passed by unnoticed”. В этом предложении сообщено, что, когда предложение “While a dog was eating a bone” являлось истинным, второе предложение “A cat passed unnoticed” также является истинным. На рисунке 3 изображен граф с центром в глаголе. Союз “while” (WHL) соединяет узел PASS-BY с узлом EAT. На рисунке 3 показано, что собака является агентом незамечания (not noticing).
Графы с центром в глаголе - это реляционные графы, где глагол считается центральным звеном любого предложения. Маркеры времени и отношения пишутся прямо рядом с концептами, которые представляют глаголы. Графы концептуальных зависимостей Роджера Шенка также используют этот подход.
Несмотря на то, что графы с центром в глаголе довольно гибкие по своей структуре, они обладают рядом ограничений. Одно из них заключается в том, что они не проводят разграничение между определителями, которые относятся только к глаголу, и определителями, относящимися к предложению целиком. Рассмотрим следующие примеры:
The dog greedily ate the bone.
Greedily, the dog ate the bone.
Эти графы также плохо справляются с предложениями, находящимися внутри других предложений.
При работе с реляционными графами возникают проблемы с передачей всего многообразия временных отношений и отношений модальности. Несмотря на то, что многие учение используют эти графы для решения сложных проблем, они так до сих пор и не разработали общего метода для их разрешения. В выше приведенном примере пометка PAST должна относится ко всему предложению, которое говорит о том, что собака ест кость, а не только к глаголу EAT, поскольку очевидно, что кость позже была съедена собакой целиком. Также должно быть указано, что процесс прохождения кошки и процесс не замечания ее собакой происходили в одно и то же время.
ПРОПОЗИЦИОННЫЕ СЕТИ.
В пропозиционных сетях узлы представляют целые предложения. Эти узлы являются точками соприкосновения для отношений между отдельными предложениями связанного текста. С другой стороны они определяют время и модальность для всего контекста. Представленные ниже примеры иллюстрируют отношения, для записи которых необходимы пропозиционные узлы:
Sue thinks that Bob believes that a dog is eating a bone.
If a dog is eating a bone, it is unwise to try to take it away from him.
В первом предложении для глаголов “think” и “believe” целое предложение является дополнением: Боб считает, что “А dog is eating a bone”, то, что думает Сью представляет собой более сложное предложение-“Bob believes that a dog is eating a bone”. Такое гнездование предложений внутри других предложений может повторятся сколь угодно большое количество раз. Чтобы изобразить такое предложение, необходимо использовать пропозиционные узлы, которые содержат гнездящиеся графы. На рисунке 4 изображена пропозиционная сеть для этого предложения. Отметим, что (EXP) - experiencer, то есть тот кто испытывает, соединяет THINK с Сью, а BELIEVE с Бобом, однако EAT и DOG соединены между собой агентивным отношением (AGNT). Причиной разного типа отношений является тот факт, что думать и считать-это состояния, испытываемые людьми, а поедание-это действие осуществляемое агентом.
Во втором примере представлены два предложения, находящиеся в отношении условия. Антецедентом является предложение “А dog is eating a bone”, а консеквентом предложение “It is unwise to try to take it away from him”. Инфинитивы “to try” и “to take” указывают на другие, гнездящиеся предложения. На гнездящиеся предложения также указывает оборот “it is unwise”. Для этого предложения также необходимо указать соответствие между “it”, “him” и “bone” и “dog”. Связи соответствия обозначены пунктиром. Для формальной записи этого предложения также используются кванторы общности и существования и некоторые элементы логики.
Все реляционные графы и графы с центром в глаголе имеют много общего. Однако среди них существуют также и отличия:
1. Включение контекста или всего лишь его условное обозначение с отсылкой на схеме.
2. Строгое гнездование: один и тот же концепт может или не может встречаться в двух разных контекстах, ни один из которых не гнездиться в другом.
3. Указание связей соответствия. При перекрещивающемся контексте, то есть когда они один и тот же концепт встречается в двух разных контекстах, эти связи не указываются.
Однако это всего лишь стилистические расхождения, которые не влияют существенно на логику построения.
ИЕРАРХИЯ ТИПОВ.
Иерархия типов и подтипов является стандартной характеристикой семантических сетей. Иерархия может включать сущности: ТАКСА<СОБАКА<ПЛОТОЯДНОЕ<ЖИВОТНОЕ<ЖИВОЕ СУЩЕСТВО<ФИЗИЧЕСКИЙ ОБЪЕКТ<СУЩНОСТЬ. Они также могут включать в себя события: ЖЕРТВОВАТЬ<ДАВАТЬ<ДЕЙСТВИЕ<СОБЫТИЕ или состояния: ЭКСТАЗ<СЧАСТЬЕ<ЭМОЦИОНАЛЬНОЕ СОТОЯНИЕ<СОСТОЯНИЕ. Иерархия Аристотеля включала в себя 10 основных категорий: субстанция, количество, качество, отношение, место, время, состояние, активность и пассивность. Некоторые учение дополнили его своими категориями.
Символ < между более общим и более частным символом читается как: “Х-тип/подтип У”.
Термин
“иерархия”
обычно обозначает
частичное
упорядочение,
где одни типы
являются более
общими, чем
другие. Упорядочение
является частичным,
потому, что
многие типы
просто не подлежат
сравнению между
собой. Сравним
HOUSE
Ацикличный граф. Любое частичное упорядочение может быть изображено, как граф без циклов. Такой граф имеет ветви, которые расходятся и сходятся вместе опять, что позволяет некоторым узлам иметь несколько узлов-родителей. Иногда такой тип графа называют путанным.
Деревья. Самым распространенным видом иерархии является граф с одной вершиной. В такого рода графах налагаются ограничения на ацикличные графы: вершина графа представляет собой один общий тип, и каждый другой тип Х имеет лишь одного родителя У.
Решетка. В отличие от деревьев узлы в решетке могут иметь несколько узлов родителей. Однако здесь налагаются другие ограничения: любая пара типов Х и У как минимум должна иметь общий гипертип ХиУ и подтип ХилиУ. Вследствие этого ограничения решетка выглядит, как дерево, имеющее по главной вершине с каждого конца. Вместо всего одной вершины решетка имеет одну вершину, которая является гипертипом всех категорий, и другую вершину, которая является подтипом всех типов.
НАСЛЕДОВАНИЕ.
Основным свойством иерархии является возможность наследования подтипами качеств гипертипов: все характеристики, которые присущи ЖИВОТНОМУ, также присущи МЛЕКОПИТАЮЩЕМУСЯ, РЫБЕ и ПТИЦЕ. В основе теории наследования лежит теория силлогизмов Аристотеля: Если А - характеристика В, а В - х-ка С, то А хар-ка всех С.
Преимущества иерархии и наследования:
Иерархия типов является отличной структурой для индексирования базы знаний и ее эффективной организации.
Следование по какой-либо ветви с помощью иерархии осуществляется гораздо быстрее.
СИНТАКСИЧЕСКИЙ АНАЛИЗ ЯЗЫКА И ЕГО ПОРОЖДЕНИЕ.
Семантические сети могут помочь парсеру разрешить семантическую неоднозначность. Без такого рода представления вся тяжесть анализ языка падает на синтаксические правила и семантические тесты. Структура же семантической сети ясно показывает, как отдельные концепты соединены между собой. Когда парсер встречает какую-либо неоднозначность, он может использовать семантическую сеть для того, чтобы выбрать тот или иной вариант. При работе с семантическими сетями используется несколько техник парсинга.
Парсинг, в основе которого лежит синтаксис. Работа парсера контролируется грамматикой непосредственных составляющих и операторами построения структур и их тестирования. В то время, как данные на входе анализируются, операторы построения структур создают семантическую сеть, а операторы тестирования проверяют ограничения на частично построенной сети. Если никакие ограничения не найдены, то используемое при этом грамматическое правило отвергается и парсер проверяет другую возможность. Это самый распространенный подход.
Синтаксический анализатор с использованием семантики. Синтаксический анализатор с использованием семантики оперирует также как и парсер, в основе которого лежит синтаксис. Однако он оперирует не с синтаксическими категориями типа группа подлежащего и группа сказуемого, а с концептами высокого уровня типа КОРАБЛЬ и ПЕРЕВОЗИТЬ.
Концептуальный парсинг. Семантическая сеть предсказывает возможные ограничения, которые могут встретится в отношениях между словами, а также прогнозировать слова, которые позже могут встретиться в предложении. Например, глагол давать требует одушевленного агента и а также прогнозирует возможность реципиента и объекта, который будет дан. Шенк был одним из самых активных сторонников концептуального парсинга.
Парсинг, основанный на экспертизе слов. Вследствие существования большого количества неправильных образований в естественном языке, многие люди вместо того, чтобы обращаться к каким-либо универсальным обобщениям, используют специальные словари, представляющих собой совокупность некоторых независимых процедур, которые называются экспертами слов. Анализ предложения рассматривается как процесс, осуществляемый совместно различными словарными экспертами. Главным сторонником этого подхода был Смол.
Аргументы за и против различных техник парсинга часто основывался не на конкретные данные, а больше на уже устоявшемся мнении. И лишь один проект на практике сравнил несколько видов парсинга - это Язык Семантических Репрезентаций, проект разработанный в Университете Берлина. В течение нескольких лет они создали четыре разных вида парсеров для анализа немецкого языка и его записи на Язык Семантических Репрезентаций, который представляет собой сеть.
Первым парсером был парсер, созданный по подобию концептуального парсера Шенка. Было отмечено, что хотя добавление в его лексикон новых слов было довольно легко, анализ однако мог проводиться только на простых предложениях и только относительных придаточных. Расширить область синтаксической обработки этого парсера оказалось сложной задачей.
Второй парсер был семантически ориентированные расширенные сети перехода. В нем было легче обобщить синтаксис, однако аппарат синтаксиса работал медленнее, чем у первого рассмотренного парсера.
Затем работа велась с парсером словарных экспертов. Здесь легко велась обработка особых случаев, однако разбросанность грамматики между отдельными составляющими делала практически невозможным ее общее понимание, поддержку и модифицирование.
Парсер, который был создан относительно недавно, - это синтаксически ориентированный парсер, основанный на общей грамматике фразовой структуры. Он наиболее систематичен и обобщен и относительно быстр.
Эти результаты в принципе соответствуют мнению других лингвистов: синтаксически ориентированные парсеры наиболее целостны, однако для них необходим определенный набор сетевых операторов для плавного взаимодействия между грамматикой и семантическими сетями.
Порождение языка по семантической сети представляет собой обратный парсинг. Вместо синтаксического анализа некоторй цепочки с целью порождения сети генератор языка производит парсинг сети для получения некоторой цепочки. Существует два варианта порождения языка из семантической сети.
1. Генератор языка просто следует по сети, превращая концепты в слова, а отношения, указанные рядом с дугами, в отношения естественного языка. Этот метод имеет много ограничений.
2. Подходы, ориентированные на синтаксис контролируют порождение языка с помощью грамматических правил, которые используют сеть для того, чтобы определить, какое следующее правило нужно применить.
Однако на практике оба метода имеют много сходств: например, первый способ представляет собой последовательность узлов, которые обрабатываются генератором языка, ориентированным на синтаксис.
ОБУЧЕНИЕ МАШИН.
Графы и сети представляют собой простые понятия для программ, которые изучают новые структуры. Их преимущество при обучении заключается в легкости добавления и удаления, а также сравнения дуг и узлов. Ниже представлены программы, которые для обучения использовали семантические сети.
Винстон использовал реляционные графы для описания таких структур, как арки и башни. Машине предлагались примеры верного и неверного описания этих структур, а программа создавала графы, которые указывали все необходимые условия для того, чтобы эта структура была именно аркой или башней.
Салветер использовал графы с центром в глаголе для представления падежных отношений, которые требуют различные глаголы. Его программа MORAN для каждого глагола выведет падежный фрейм, сравнивая одни и те же ситуации до и после их описания с использованием этого глагола.
Шенк разработал теорию Memory-Organization Packets для объяснения того, как люди узнают новую информацию из конкретных жизненных ситуаций. При этом MOP-это это обобщенная абстрактная структура, которая не имеют отношения ни к одной конкретной ситуации в отдельности.
ПРИМЕНИЕ НА ПРАКТИКЕ.
Семантические сети могут быть записаны практически на любом языке программирования на любой машине. Самые популярные в этом отношении языки LISP и PROLOG. Однако многие версии были созданы и на FORTRANе, PASCALе, C и других языках программирования. Для хранения всех узлов и дуг необходима большая память, хотя первые системы были выполнены в 60-х годах на машинах, которые были гораздо меньше и медленнее современных компьютеров.
Один из самых распространенных языков, разработанных для записи естественного языка в виде сетей, - это PLNLP (Programming Language for Natural Language Processing) Язык Программирования для Обработки Естественного Языка, созданный Хайдерном. Этот язык используется для работы с большими грамматиками с обширным покрытием. PLNLP работает с двумя видами правил:
1. с помощью правил декодирования производится синтаксический анализ линейной языковой цепочки и строится сеть.
2. с помощью правил кодирования сканируется сеть порождается языковая цепочка или другая трансформированная сеть.
Помимо специальных языков для семантических сетей было также разработано специальное аппаратное обеспечение. На обычных компьютерах могут быть успешно выполнены операции с языками синтаксического анализа и операции сканирования сетей. Однако для больших баз знаний нахождение нужных правил или доступ к предзнаниям может потребоваться очень много времени. Чтобы позволить различным процессам поисках проходить одновременно Фальман разработал систему NETL, которая представляет собой семантическую сеть, которая может использоваться с параллельным аппаратным обеспечением. Таким образом он хотел создать модель человеческого мозга, в котором сигналы могут двигаться по различным каналам одновременно. Другие ученые разработали параллельное программное обеспечение для поиска наиболее вероятной интерпретации двусмысленных фраз естественного языка.
Теорияфреймов
- это парадигма для представления знаний с целью использования этих знаний компьютером . Впервые была представлена Минским как попытка построить фреймовую сеть , или парадигму с целью достижения большего эффекта понимания . С одной стороны Минский пытался сконструировать базу данных , содержащую энциклопедические знания , но с другой стороны , он хотел создать наиболее описывающую базу , содержащую информацию в структурированной и упорядоченной форме . Эта структура позволила бы компьютеру вводить информацию в более гибкой форме , имея доступ к тому разделу , который требуется в данный момент . Минский разработал такую схему , в которой информация содержится в специальных ячейках , называемых фреймами , объединенными в сеть , называемую системой фреймов . Новый фрейм активизируется с наступлением новой ситуации . Отличительной его чертой является то , что он одновременно содержит большой объем знаний и в то же время является достаточно гибким для того , чтобы быть использованным как отдельный элемент БД . Термин «фрейм» был наиболее популярен в середине семидесятых годов , когда существовало много его толкований , отличных от интерпретации Минского .
Чтобы лучше понять эту теорию , рассмотрим один из примеров Минского , основанный на связи между ожиданием , ощущением и чувством человека , когда он открывает дверь и входит в комнату . Предположим , что вы собираетесь открыть дверь и зайти в комнату незнакомого вам дома . Находясь в доме , перед тем как открыть дверь , у вас имеются определенные представления о том , что вы увидите , войдя в комнату . Например , если вы увидите к-л пейзаж или морской берег , поначалу вы с трудом узнаете их . Затем вы будете удивлены , и в конце концов дезориентированы , так как вы не сможете объяснить поступившую информацию и связать ее с теми представлениями , которые у вас имелись до того . Также у вас возникнут затруднения с тем , чтобы предсказать дальнейший ход событий. С аналитической точки зрения это можно объяснить как активизацию фрейма комнаты в момент открывания двери и его ведущую роль в интерпретации поступающей информации . Если бы вы увидели за дверью кровать , то фрейм комнаты приобрел бы более узкую форму и превратился бы во фрей кровати . Другими словами , вы бы имели доступ к наиболее специфичному фрейму из всех доступных .Возможно ,б что вы используете информацию , содержащуюся в вашем фрейме комнаты для того чтобы распознать мебель , что называется процессом сверху-вниз , или в контексте теории фреймов фреймодвижущим распознаванием . Если бы вы увидели пожарный гидрант , то ваши ощущения были бы аналогичны первому случаю. Психологи подметили , что распознавание объектов легче проходит в обычном контексте, чем в нестандартной обстановке . Из этого примера мы видим , что фрейм - это модель знаний , которая активизируется в определенной ситуации и служит для ее объяснения и предсказания . У Минского имелись достаточно расплывчатые идеи о самой структуре такой БД , которая могла бы выполнять подобные вещи . Он предложил систему , состоящую из связанных между собой фреймов , многие из которых состоят из одинаковых подкомпонентов , объединенных в сеть . Таким образом , в случае , когда к-л входит в дом , его ожидания контролируются операциями , входящими в сеть системы фреймов . В рассмотренном выше случае мы имеем дело с фреймовой системой для дома , и с подсистемами для двери и комнаты . Активизированные фреймы с дополнительной информацией в БД о том , что вы открываете дверь , будут служить переходом от активизированного фрейма двери к фрейму комнаты . При этом фреймы двери и комнаты будут иметь одинаковую подструктуру . Минский назвал это явление разделом терминалов и считал его важной частью теории фреймов .
Минский также ввел терминологию , которая могла бы использоваться при изучении этой теории ( фреймы , слоты , терминалы и т. д.) . Хотя примеры этой теории были разделены на языковые и перцептуальные , и Минский рассматривал их как имеющих общую природу , в языке имеется более широкая сфера ее применения . В основном большинство исследований было сделано в контексте общеупотребительной лексики и литературного языка .
Как наиболее доступную иллюстрацию распознаванию , интерпретации и предположению можно рассмотреть две последовательности предложений , взятых из Шранка и Абельсона . На глобальном уровне последовательность А явно отличается от В .
A John went to a restaurant
He asked the waitress for a hamburger
He paid the tip & left
B John went to a park
He asked the midget for a mouse
He picked up the box & left
Хотя все эти предложения имеют одинаковую синтаксическую структуру и тип семантической информации , понимание их кардинально различается . Последовательность А имеет доступ к некоторому виду структуры знаний высшего уровня , а В не имеет . Если бы А не имело такой доступ , то ее понимание сводилось бы к уровню В и характеризовалось бы как дезориентированное . Этот контраст является наглядным примером мгновенной работы высшего уровня структуры знаний .
Была предложена программа под названием SAM , которая отвечает на вопросы и выдает содержание таких рассказов . Например , SAM может ответить на следующие вопросы , ответы на которые не даны в тексте , с помощью доступа к записи предполагаемых событий , предшествующих обеду в ресторане .
Did John sit down in the restaurant ?
Did John eat the hamburger ?
Таким образом , SAM может распознать описанную ситуацию как обед в ресторане и затем предсказать оптимальное развитие событий . В нашем случае распознавание не представляло трудностей , но в большинстве случаев оно довольно непростое и является самой важной частью теории .
Рассмотрим другой пример :
C He plunked down $5 at the window .
She tried to give him $ 2.50 , but he wouldn’t take it .
So when they got inside , she bought him a large bag of popcorn .
Он интересен тем , что у большинства людей он вызывает цикл повторяющихся неправильных или незаконченных распознаваний и реинтерпретаций .
В случаях с многозначными словами многозначность разрешается с помощью активизированного ранее фрейма . Для этих целей необходимо создать лексикон к каждому фрейму . Когда фрейм активизируется , соответствующему лексикону отдается предпочтение при поиске соответствующего значения слова . В контексте ТФ это распознавание процессов , контролируемых фреймами , которые , в свою очередь , контролируют распознавание входящей информации . Иногда это называется процессом сверху - вниз фреймодвижущего распознавания .
Применение этих процессов нашло свое отражение в программе FRAMP , которая может суммировать газетные сводки и классифицировать их в соответствие с классом событий , например терроризм или землетрясения . Эта программа хранит набор объектов , которые должны быть описаны в каждой разновидности текстов , и этот набор помогает процессу распознавания описываемых событий .
Манипуляция фреймами
Детали спецификации Ф и их репрезентации могут быть опущены , так же как и алгоритмы их манипуляции , потому что они не играют большой роли в ТФ .
Такие вопросы , как размер Ф или доступ к нему , связаны с организацией памяти и не требуют специального рассмотрения .
Распознавание
В литературе имеется много рассуждений по поводу процессов , касающихся распознавания фреймов и доступа к структуре знаний высшего уровня . Несмотря на то , что люди могут распознать фрейм без особых усилий , для компьютера в большинстве случаев это довольно сложная задача . Поэтому вопросы распознавания фреймов остаются открытыми и трудными для решения с помощью ИИ .
Размер фрейма
Размер фрейма гораздо более тесно связан с организацией памяти , чем это кажется на первый взгляд . Это происходит потому , что в понимании человека размер фрейма определяется не столько семантическим контекстом , но и многими другими факторами . Рассмотрим фрейм визита к доктору , который складывается из подфреймов , одним из которых является комната ожидания . Таким образом мы можем сказать , что размер фрейма не зависит от семантического содержания представленного фрейма / такого , как , например , визит к врачу / , но зависит от того , какие компоненты описывающей информации во фрейме / таком , как комната ожидания / используются в памяти . Это означает , что когда определенный набор знаний используется памятью более чем в одной ситуации , система памяти определяет это , затем модифицирует эту информацию во фрейм , и реструктурирует исходный фрейм так , чтобы новый фрей использовался как его подкомпонент .
Вышеперечисленные операции также остаются открытыми вопросами в ТФ .
Инициализационные категории
Рош предложил три уровня категорий представления знаний : базовую , субординатную и суперординационную . Например в сфере меблировки концепция кресла является примером категории основного уровня , а концепция мебели - это пример суперординационной категории . Язык представления знаний подвержен влиянию этой таксономии и включает их как различные типы данных . В сфере человеческого общения категории основного уровня являются первейшими категориями , которые узнают человек , другие же категории вытекают из них . То есть суперординационная категория - это обобщение базовой , а субординатная - это подраздел базовой категории .
пример
суперординатная идеи события
базовая события действия
субординатная действия прогулка
Каждый фрейм имеет свой определенный так называемый слот . Так , для фрейма действие слот может быть заполнен только к-л исполнителем этого действия , а соседние фреймы могут наследовать этот слот .
Некоторые исследователи предположили , что случаи грамматики падежей совпадают со слотами в ТФ , и эта теория была названа теорией идентичности слота и падежа . Было предложено число таких падежей , от 8 до 20 , но точное число не определено . Но если агентив полностью совпадает со своим слотом , то остальные падежи вызвали споры . И до сих пор точно не установлено , сколько всего существует падежей .
Также вызвал трудность тот факт , что слоты не всегда могут быть переходными . Например , в соответствие с ТФ можно сказать , что фрейм одушевленный предмет может иметь слот живой , фрейм человек может иметь слот честный , а фрейм блоха не может иметь такой слот , и он к нему никогда не перейдет .
Другими словами , связи между слотами в ТФ не являются исследованными до конца . Слоты могут передаваться , могут быть многофункциональны , но в то же время не рассматриваются как функции . Гибридные системы
СФ иногда адаптируются для построения описаний или определений . Был создан смешанный язык , названный KRYPTON , состоящий из фреймовых компонентов и компонентов предикатных исчислений , помогающих делать к-л выводы с помощью терминов и предикатов . Когда активизируется фрейм , факты становятся доступными пользователю . Также существует язык Loops , который объединяет объекты , логическое программирование и процедуры .
Существуют также фреймоподобные языки , которые за исходную позицию принимают один тип данных в памяти , к-л концепцию , а не две / напр фрейм и слот / , и представление этой концепции в памяти должно быть цельным .
Объектно - ориентированные языки
Параллельно с языками фреймов существуют объектно - ориентированные программные языки , которые используются для составления программ , но имеют некоторые св-ва языков фреймов , такие , как использование слотов для детальной , доскональной классификации объектов . Отличие их от языков фреймов в том , что фреймовые языки направлены на более обобщенное представление информации об объекте .
Одной из трудностей представления знаний и языка фреймов является отсутствие формальной семантики . Это затрудняет сравнение свойств представления знаний различных языков фреймов , а также полное логическое объяснение языка фреймов .
Теорияфреймов
- это парадигма для представления знаний с целью использования этих знаний компьютером . Впервые была представлена Минским как попытка построить фреймовую сеть , или парадигму с целью достижения большего эффекта понимания . С одной стороны Минский пытался сконструировать базу данных , содержащую энциклопедические знания , но с другой стороны , он хотел создать наиболее описывающую базу , содержащую информацию в структурированной и упорядоченной форме . Эта структура позволила бы компьютеру вводить информацию в более гибкой форме , имея доступ к тому разделу , который требуется в данный момент . Минский разработал такую схему , в которой информация содержится в специальных ячейках , называемых фреймами , объединенными в сеть , называемую системой фреймов . Новый фрейм активизируется с наступлением новой ситуации . Отличительной его чертой является то , что он одновременно содержит большой объем знаний и в то же время является достаточно гибким для того , чтобы быть использованным как отдельный элемент БД . Термин «фрейм» был наиболее популярен в середине семидесятых годов , когда существовало много его толкований , отличных от интерпретации Минского .
Чтобы лучше понять эту теорию , рассмотрим один из примеров Минского , основанный на связи между ожиданием , ощущением и чувством человека , когда он открывает дверь и входит в комнату . Предположим , что вы собираетесь открыть дверь и зайти в комнату незнакомого вам дома . Находясь в доме , перед тем как открыть дверь , у вас имеются определенные представления о том , что вы увидите , войдя в комнату . Например , если вы увидите к-л пейзаж или морской берег , поначалу вы с трудом узнаете их . Затем вы будете удивлены , и в конце концов дезориентированы , так как вы не сможете объяснить поступившую информацию и связать ее с теми представлениями , которые у вас имелись до того . Также у вас возникнут затруднения с тем , чтобы предсказать дальнейший ход событий. С аналитической точки зрения это можно объяснить как активизацию фрейма комнаты в момент открывания двери и его ведущую роль в интерпретации поступающей информации . Если бы вы увидели за дверью кровать , то фрейм комнаты приобрел бы более узкую форму и превратился бы во фрей кровати . Другими словами , вы бы имели доступ к наиболее специфичному фрейму из всех доступных .Возможно ,б что вы используете информацию , содержащуюся в вашем фрейме комнаты для того чтобы распознать мебель , что называется процессом сверху-вниз , или в контексте теории фреймов фреймодвижущим распознаванием . Если бы вы увидели пожарный гидрант , то ваши ощущения были бы аналогичны первому случаю. Психологи подметили , что распознавание объектов легче проходит в обычном контексте, чем в нестандартной обстановке . Из этого примера мы видим , что фрейм - это модель знаний , которая активизируется в определенной ситуации и служит для ее объяснения и предсказания . У Минского имелись достаточно расплывчатые идеи о самой структуре такой БД , которая могла бы выполнять подобные вещи . Он предложил систему , состоящую из связанных между собой фреймов , многие из которых состоят из одинаковых подкомпонентов , объединенных в сеть . Таким образом , в случае , когда к-л входит в дом , его ожидания контролируются операциями , входящими в сеть системы фреймов . В рассмотренном выше случае мы имеем дело с фреймовой системой для дома , и с подсистемами для двери и комнаты . Активизированные фреймы с дополнительной информацией в БД о том , что вы открываете дверь , будут служить переходом от активизированного фрейма двери к фрейму комнаты . При этом фреймы двери и комнаты будут иметь одинаковую подструктуру . Минский назвал это явление разделом терминалов и считал его важной частью теории фреймов .
Минский также ввел терминологию , которая могла бы использоваться при изучении этой теории ( фреймы , слоты , терминалы и т. д.) . Хотя примеры этой теории были разделены на языковые и перцептуальные , и Минский рассматривал их как имеющих общую природу , в языке имеется более широкая сфера ее применения . В основном большинство исследований было сделано в контексте общеупотребительной лексики и литературного языка .
Как наиболее доступную иллюстрацию распознаванию , интерпретации и предположению можно рассмотреть две последовательности предложений , взятых из Шранка и Абельсона . На глобальном уровне последовательность А явно отличается от В .
A John went to a restaurant
He asked the waitress for a hamburger
He paid the tip & left
B John went to a park
He asked the midget for a mouse
He picked up the box & left
Хотя все эти предложения имеют одинаковую синтаксическую структуру и тип семантической информации , понимание их кардинально различается . Последовательность А имеет доступ к некоторому виду структуры знаний высшего уровня , а В не имеет . Если бы А не имело такой доступ , то ее понимание сводилось бы к уровню В и характеризовалось бы как дезориентированное . Этот контраст является наглядным примером мгновенной работы высшего уровня структуры знаний .
Была предложена программа под названием SAM , которая отвечает на вопросы и выдает содержание таких рассказов . Например , SAM может ответить на следующие вопросы , ответы на которые не даны в тексте , с помощью доступа к записи предполагаемых событий , предшествующих обеду в ресторане .
Did John sit down in the restaurant ?
Did John eat the hamburger ?
Таким образом , SAM может распознать описанную ситуацию как обед в ресторане и затем предсказать оптимальное развитие событий . В нашем случае распознавание не представляло трудностей , но в большинстве случаев оно довольно непростое и является самой важной частью теории .
Рассмотрим другой пример :
C He plunked down $5 at the window .
She tried to give him $ 2.50 , but he wouldn’t take it .
So when they got inside , she bought him a large bag of popcorn .
Он интересен тем , что у большинства людей он вызывает цикл повторяющихся неправильных или незаконченных распознаваний и реинтерпретаций .
В случаях с многозначными словами многозначность разрешается с помощью активизированного ранее фрейма . Для этих целей необходимо создать лексикон к каждому фрейму . Когда фрейм активизируется , соответствующему лексикону отдается предпочтение при поиске соответствующего значения слова . В контексте ТФ это распознавание процессов , контролируемых фреймами , которые , в свою очередь , контролируют распознавание входящей информации . Иногда это называется процессом сверху - вниз фреймодвижущего распознавания .
Применение этих процессов нашло свое отражение в программе FRAMP , которая может суммировать газетные сводки и классифицировать их в соответствие с классом событий , например терроризм или землетрясения . Эта программа хранит набор объектов , которые должны быть описаны в каждой разновидности текстов , и этот набор помогает процессу распознавания описываемых событий .
Манипуляция фреймами
Детали спецификации Ф и их репрезентации могут быть опущены , так же как и алгоритмы их манипуляции , потому что они не играют большой роли в ТФ .
Такие вопросы , как размер Ф или доступ к нему , связаны с организацией памяти и не требуют специального рассмотрения .
Распознавание
В литературе имеется много рассуждений по поводу процессов , касающихся распознавания фреймов и доступа к структуре знаний высшего уровня . Несмотря на то , что люди могут распознать фрейм без особых усилий , для компьютера в большинстве случаев это довольно сложная задача . Поэтому вопросы распознавания фреймов остаются открытыми и трудными для решения с помощью ИИ .
Размер фрейма
Размер фрейма гораздо более тесно связан с организацией памяти , чем это кажется на первый взгляд . Это происходит потому , что в понимании человека размер фрейма определяется не столько семантическим контекстом , но и многими другими факторами . Рассмотрим фрейм визита к доктору , который складывается из подфреймов , одним из которых является комната ожидания . Таким образом мы можем сказать , что размер фрейма не зависит от семантического содержания представленного фрейма / такого , как , например , визит к врачу / , но зависит от того , какие компоненты описывающей информации во фрейме / таком , как комната ожидания / используются в памяти . Это означает , что когда определенный набор знаний используется памятью более чем в одной ситуации , система памяти определяет это , затем модифицирует эту информацию во фрейм , и реструктурирует исходный фрейм так , чтобы новый фрей использовался как его подкомпонент .
Вышеперечисленные операции также остаются открытыми вопросами в ТФ .
Инициализационные категории
Рош предложил три уровня категорий представления знаний : базовую , субординатную и суперординационную . Например в сфере меблировки концепция кресла является примером категории основного уровня , а концепция мебели - это пример суперординационной категории . Язык представления знаний подвержен влиянию этой таксономии и включает их как различные типы данных . В сфере человеческого общения категории основного уровня являются первейшими категориями , которые узнают человек , другие же категории вытекают из них . То есть суперординационная категория - это обобщение базовой , а субординатная - это подраздел базовой категории .
пример
суперординатная идеи события
базовая события действия
субординатная действия прогулка
Каждый фрейм имеет свой определенный так называемый слот . Так , для фрейма действие слот может быть заполнен только к-л исполнителем этого действия , а соседние фреймы могут наследовать этот слот .
Некоторые исследователи предположили , что случаи грамматики падежей совпадают со слотами в ТФ , и эта теория была названа теорией идентичности слота и падежа . Было предложено число таких падежей , от 8 до 20 , но точное число не определено . Но если агентив полностью совпадает со своим слотом , то остальные падежи вызвали споры . И до сих пор точно не установлено , сколько всего существует падежей .
Также вызвал трудность тот факт , что слоты не всегда могут быть переходными . Например , в соответствие с ТФ можно сказать , что фрейм одушевленный предмет может иметь слот живой , фрейм человек может иметь слот честный , а фрейм блоха не может иметь такой слот , и он к нему никогда не перейдет .
Другими словами , связи между слотами в ТФ не являются исследованными до конца . Слоты могут передаваться , могут быть многофункциональны , но в то же время не рассматриваются как функции . Гибридные системы
СФ иногда адаптируются для построения описаний или определений . Был создан смешанный язык , названный KRYPTON , состоящий из фреймовых компонентов и компонентов предикатных исчислений , помогающих делать к-л выводы с помощью терминов и предикатов . Когда активизируется фрейм , факты становятся доступными пользователю . Также существует язык Loops , который объединяет объекты , логическое программирование и процедуры .
Существуют также фреймоподобные языки , которые за исходную позицию принимают один тип данных в памяти , к-л концепцию , а не две / напр фрейм и слот / , и представление этой концепции в памяти должно быть цельным .
Объектно - ориентированные языки
Параллельно с языками фреймов существуют объектно - ориентированные программные языки , которые используются для составления программ , но имеют некоторые св-ва языков фреймов , такие , как использование слотов для детальной , доскональной классификации объектов . Отличие их от языков фреймов в том , что фреймовые языки направлены на более обобщенное представление информации об объекте .
Одной из трудностей представления знаний и языка фреймов является отсутствие формальной семантики . Это затрудняет сравнение свойств представления знаний различных языков фреймов , а также полное логическое объяснение языка фреймов .
Билет 4
1. Различные наименования области прикладной лингвистики и их смысловые различия. Универсальные прикладные проблемы.
Прикладная лингвистика - это комплексная научная дисциплина, изучающая язык в различных ситуациях его применения и разрабатывающая методы совершенствования языковых систем и языковых процессов.
Термин прикладная лингвистика появился в конце 20 гг. 20 в., когда была осознана необходимость строгого научного решения прикладных задач с использованием методов формального лингвистического анализа письменных и акустико-лингвистического анализа устных сообщений.
За рубежом под ПЛ часто понимают совершенствование методов преподавания языка (дидактическая лингвистика). В нашей стране ПЛ понимают как компьютерную лингвистику, которая становится сейчас все более широкой дисциплиной почти синонимом ПЛ.
Лингвистика входит в ядро складывающегося в настоящее время комплекса когнитивных наук, объединяемых по их интересу к проблемам организации, представления, обработки и использования знаний.
Синонимы ПЛ:
· Компьютерная лингвистика (машинная лингвистика) - дисциплина, которая разрабатывает лингвистические аспекты компьютеризации.
· Вычислительная лингвистика
Термин компьютерная лингвистика шире термина вычислительная лингвистика, так как задает общую ориентацию на использование компьютеров для решения разнообразных научных и практических задач, никак не ограничивая способы решения этих задач. Термин же вычислительная лингвистика может пониматься более узко, так как даже при широкой трактовке понятия вычисление за его пределами остаются такие стороны решения линг. задач, как, например, представление знаний, организация банков языковых данных, психолингвистические аспекты взаимодействия человека и компьютера и др. Т. о. можно считать, что термин компьютерная лингвистика (по своей внутренней форме) шире, чем вычислительная лингвистика. Английский эквивалент computational linguistics может переводиться и как компьютерный и как вычислительный (как и русском компьютер - синоним ЭВМ).
· Структурная лингвистика - совокупность взглядов на язык м методов его исследования, в основе которых лежит понимание языка как знаковой системы с четко выделенными структурными элементами (единицами языка, их классами и пр.) и стремление к строгому (как в точных науках) формальному описанию языку. Свое название СЛ получила благодаря особому вниманию к структуре языка, которая представляет собой сеть отношений (противопоставлений) между элементами языковой системы, упорядоченных и находящихся в иерархической зависимости в пределах определенных уровней. Структурное описание языка предполагает такой анализ реального текста, который позволяет выделить обобщенные инвариантные единицы (схемы предложений, морфемы, фонемы) и соотнести их с конкретными речевыми сегментами на основе строгих правил реализации Эти правила определяют границы допустимого варьирования яз. единиц в речи. В зависимости от уровня анализа правила реализации формулируются как правила позиционного распределения конкретных, например, принцип дополнительной дистрибуции в фонологии и морфологии (дистрибутивный анализ), или как трансформационные правила в синтаксисе (при трансформационном анализе) регулирующие переход от инвариантной глубинной структуры предложения к множеству ее реализации. На базе СЛ развилась порождающая грамматика (генеративная лингвистика); идеи структурного анализа во многом определили постановку и решение задач, связанных с машинным переводом; СЛ открыла дорогу для широкого проникновения в лингвистику мат. методов (математическая лингвистика). На СЛ оказали влияние: Сепир, Блумфилд. Ф.де Соссюр, один из создателей и ведущих теоретиков -Якобсон; у нас - Реформатский (знаковая теория языка), Ревзин (общая теория моделирования), Холодович; практическое применение методов СЛ: Апресян, Арутюнова, Гак, Зализняк, Звегинцев, Мельчук, Успенский и др.
· Математическая лингвистика - математическая дисциплина, предметом которой является разработка формального аппарата для описания строения естественных и некоторых искусственных языков. Возникла в 50 годы 20 в.; одним из главных стимулов появления математической лингвистики послужила назревшая потребность в уточнения основных лингвистических понятий. Методы МЛ имеют много общего с с методами мат. логики - мат. дисциплины, занимающейся изучением строения мат. рассуждений, - и в особенности таких ее разделов, как теория алгоритмов и теория автоматов.
· Контрастивная лингвистика (сопоставительная лингвистика) - сопоставительное изучение двух, реже нескольких языков для выявления их сходств и различий на всех уровнях языковой структуры с целью типологической классификации языков. Как правило, контрастивная лингвистика оперирует материалами на синхронном срезе языка. КЛ появилась и интенсивно развивалась в 50 гг. 20 в., однако ее появление подготовили работы Е.Д. Поливанова, Бодуена де Куртенэ, Л.В. Щербы с изложением теор. основ сравнения родного и ин. языков. В 70 гг. контрастивные исследования в одт. странах (гл. образом в США) использовали порождающую модель Хомского, с возведением явлений двух сопоставляемых языков к общей глубинной структуре; в наст. время наблюдается отход от этой методики в пользу сруктурно-функционального подхода.
· Искусственный интеллект
· Автоматический перевод - выполняемое на компьютере действие по преобразованию текста на одном ЕЯ в эквивалентный по содержанию текст на другом языке.
Универсальные прикладные проблемы:
· создание и совершенствование алфавитов и письменности (решена полностью и успешно) 3 стадии: (1) появление письменности, (2) книгопечатание, (3) компьютеризация.
· создание систем транскрипции устной речи, систем транслитерации иноязычных слов
· составление словарей (лексикография) (первые словари - глоссарии - комментарии к церковным текстам) составление автоматических словарей, тезаурусов
· унификация и стандартизация научно-технической терминологии
· изучение процессов и создание правил образования новых названий изделий, товаров и т.п.
· устный и письменный перевод, разработка систем машинного перевода, АРМов
· обучение родному и иностранным языкам, разработка соответствующих методик (обучение детей и взрослых, обучение эмигрантов, ...)
· создание и совершенствование ИЯ для для записи информации
· автоматическое распознавание и синтез речи
· автоматические методы переработки текстовой информации
· создание автоматизированных систем информационного поиска
· составление автоматических словарей и систем машинного перевода
· разработка методов автоматического аннотирования, реферирования и перевода
· разработка экспертных систем
· лингвистическое обеспечение АСУ
· проблемы языка и пола (politically correct non-sexist language)
· создание систем стенографии, систем письма для слепых
· лечение речевых расстройств
· анализ дискурса
Билет 5
1. Понятие уровня в теоретической и прикладной лингвистике
Идея уровневой организации языка получила широкое распространение в сер. 20 гг. сначала в в американской дескриптивистской лингвистике, а позднее и в других направлениях, в том числе в отечественной лингвистике.
(ЛЭС) Уровни языка - некоторые части языка; подсистемы общей языковой системы, каждая из которых характеризуется совокупностью относительно однородных единиц и набором правил, регулирующих их использование и группировку в различные классы и подклассы.
Членение на уровни в рамках теоретической лингвистики:
· фонемный
· морфемный
· лексический (уровень слова)
· синтаксический (уровень предложения)
Уровнеобразующими свойствами обладают только те единицы языка, которые подчиняются правилам уровневой сочетаемости, т.е. обладают способностью вступать в парадигматические и синтагматические отношения только с единицами того же уровня. С единицами другого уровня единицы какого-либо уровня вступают только в иерархические отношения типа "состоит из ...", "входит в ...". Так фонемы могут образовать классы и сочетаться в речевой цепи только с фонемами, морфемы - с морфемами, слова - только со словами. В тоже время фонемы входят в звуковые оболочки морфем, морфемы - в слова, слова - в предложения. Группировки единиц языка внутри уровней , например. фонем (гласные и согласные), морфем (корневые, аффиксальные), слов (знаменательные. служебные и т.д.) не являются уровнеобразующими.
Уровень языка следует отличать от уровня анализа языка - фаз или этапов рассмотрения языка. В лингвистической практике онтологический уровень языка и процедурный уровень анализа (операционный) нередко смешиваются, хотя между ними нет прямого соответствия. Уровни анализа зависят от целей и задач исследования, т.е. во многом определяются точкой зрения исследователя на изучаемый объект.
(Городецкий, К проблеме семантической типологии): Уровень языка - это совокупность сходно функционирующих единиц вместе со связывающих их отношениями.
Структура языка делится на два относительно замкнутых (самостоятельных и независимых) плана: план выражения и план содержания, внутри каждого из которых различают индивидуальный набор уровней, т.е. уровни плана содержания не изоморфны уровням плана выражения (полисемия, омонимия, синонимия; русским гласным не соответствуют никакие единицы ПС).
Как и языковая структура в целом уровни управляют обеими сторонами речевой деятельности анализом и синтезом, являясь их структурной основой, однако не следует привязывать языковой уровень к конкретной процедуре анализа/синтеза. Языковой уровень - лингвистическая универсалия.
Состав уровней ПВ:
1) уровень фонемы
2) уровень морфемы
3) уровень слова
4) уровень словосочетания
5) уровень предложения
Состав уровней ПС:
1) морфо-семантическийуровень (единицы - значения морфем)
2) лексико-семантическийуровень (единицы - лексемы (значения слов)
Различаются в размере соответствующих формальных единиц.
Морфема - наименьший двуплановый речевой отрезок с ПС состоит
Понимание речи
Понимание речи обычно трактуют как преобразование акустического представления речи в смысловое. При создании практических систем смысл можно определить, как представление, из которого извлекаются действия, совершенные системой. Понимание речи следует отличать от распознования речи, где целью является сопоставить речевое высказывание с соответствующими словами в словаре. До начала 70-ых большинство исследований было направлено на распознование речи. 5 лет потребовалось на создание системы ARPA, первоначальная исследовательская цель которой заключалась в распознавании речи, а конечные результаты в понимании. Казалось, что способность системы давать разумный ответ на речь была более значимым критерием для развития речевых систем. К тому же считалось, что речевой сигнал является недостаточным источником информации, и знание контекста речевого высказывания важно только для успешного распонавания и интерпретации. Системы по распознованию речи, основанные на динамическом программировании и соответствии с образцами, развивали для речевых высказываний, которые состояли почти полностью из изолированных слов, выбираемых из небольшого вокабуляра. Однако такой подход, при котором ищется наиболее точное соответствие между определенными произнесенными словами и вокабуляром акустическох образцов слов, меньше всего подходил к связанной речи, так как входной акустической сигнал в этом случае не может быть эффективно смоделирован, как простое сочетание произнесенных частей лексических единиц. В связанной речи изменчивость, выявляемая при соответствии с образцами, передает полезную информацию и для распознования, и для интерпретации. Однако, необходимо начинать с основных лингвистических единиц, таких как фонемы, и сохранять информацию о ритме и длительности речевого высказывания. Если следуют таким путем, то подход к обработке речи, основанный скорее на знании, чем на соответствиях с образцами, становится неизбежным, так как, чтобы извлекать преимущества из распознавания конкретных лингвистических единиц в сигнале, необходимо знать, как данная единица связана с остальной частью языка.
Системы понимания речи (СПР) имеют дело со связанными единицами речи, такими как, фразы, предложения и даже параграфы, так как "понимание" изолированных слов может означать только тривиальный процесс сопоставления некоторого значения к каждому слову словаря системы. Понимание связанной речи - очень сложная задача, и на проект СПР повлияли исследования в таких разных областях, как акустическая обработка сигнала, нейро-физиология, психолингвистика, психология. СПР была создана, чтобы понимать всего нескольких дикторов одного диалекта, производя грамматически ограниченное подмножество языка со словарем около тысячи слов. Сейчас хотя и имеются много потенциальных прикладных программ для СПР их эффективность и надежность все еще недостаточна, чтобы широко использоваться. Системы, зависимые от диктора, распознающие изолированные слова с небольшим словарем, использующие в качестве образцов-соответствий целые слова уже нашли свое применение, типа обработки багажа на авиалиниях. Тем не менее признано, что усовершенствование такого типа систем (большие словари, независимость от диктора) требует подхода, основанного на более глубоких знаниях.
Теоретические предпосылки
Посредником при преобразовании речи в ее значение должны служить определенные компоненты, которые используют разнообразные источники знания (ИЗ), т.к. речевой сигнал кодирует много различной информации, необходимой для восстановления значения. Например, вариативность в произношении слов в связанной речи больше не является помехой при подборе образца соответствия, но это довольно важный источник информации, например, относительно расположения границ слова или контекстуально важной (выделенной ударением) информации в произнесении. Единственной возможной организацией СПР и основных ИЗ является следующая: РЕЧЬ - ОБРАБОРТКА АКУСТИЧЕСКОГО СИГНАЛА - ФОНЕТИЧЕСКИЙ АНАЛИЗ - ФОНОЛОГИЧЕСКИЙ АНАЛИЗ - МОРФОЛОГИЧЕСКИЙ АНАЛИЗ - ЛЕКСИЧЕСКИЙ ДОСТУП К СЛОВАРЮ - СИНТАКСИЧЕСКИЙ АНАЛИЗ - СЕМАНТИЧЕСКИЙ АНАЛИЗ - ЗНАЧЕНИЕ. При такой организации СПР информация течет вверх по мере того, как каждый элемент создает промежуточные представления, кодируя (частичные) гипотезы относительно ввода на основе ему доступного знания.
Акустическая обработка отцифровывает сигнал с входной частотой, которая сохраняет сигнал для понимания. Акустическая обработка также трансформирует отцифрованный сигнал различными способами, чтобы представить его в той форме, которая поддается фонетическому декодированию. Например, спектральный анализ будет выполнен для каждого проанализированного фрейма, и дополнительные параметры, такие как частота основного тона, подсчитаны. Параметрический сигнал может затем быть помечен как дискретная последовательность фонем. Например, если сигнал с низкой амплитудой равномерно распространяется поперек спектра, то этот звук вероятно фрикативный, типа [f] или [v]. Кроме того, для каждой фонемы характерны такие особенности, как высота тона, длительность и амплитуда. Акустическо - фонетическое преобразование является решающим для эффективной работы СПР, но все еще одно из наиболее слабых сторон речевой обработки. И это являлось главным недостатком СПР, разработанной на основе ARPA в 1970-ых.
Фонологический анализ выполняется на фонетическом представлении, которое определяет лингвистически важные различия, имеющиеся в фонетическом представлении произнесения, например, уровни и расположение ударения, интонационный контур, структуры слога, последовательности фонем, лежащих в основе произнесения. Фонологический анализ необходим для лексического доступа, т.е. процесса, который сопоставляет фонетическую форму произнесения с каноническими фонемными представлениями слов в словаре, чтобы восстановить информацию, хранящуюся там относительно их морфологических, синтаксических, и семантических свойств. Это отменяет такие эффекты быстрой речи, как ассимиляция или сокращения. Например, слова “did” и "you" могли бы иметь в словаре следующие последовательности фонем: /dld/ и /ju:/. Однако, акустическо - фонетическое преобразование могло бы восстанавливать фактические звуки или фонемы, типа [dIje]; связывать эту фонетическую последовательность c каноническими фонемными представлениями “did” и "you". Это необходимо, если нужно узнать, что палатализация произошла на границе слова, заменив [dj] на [j], и что неударный гласный "you" был редуцирован до нейтрального безударного. Аналогично, фонологическое знание относительно допустимых последовательностей фонем в слогах может использоваться, чтобы распознать слог, и следовательно, границы слова. Например, в /houmhelp/ должна быть граница между /m/ и вторым /h/, потому что никакой слог в английском не может содержать /mh/.
Как только фонологический анализ завершен, дальнейшая обработка ввода будет подобна пониманию текста. Дальнейшие морфологический, синтаксический, семантический и прагматический анализы способствуют распознаванию, эксплуатируя избыточность речи, в информационно - теоретическом смысле. В некоторых из проектов APRA задача синтаксического анализа заключалась в том, чтобы исключить гипотезы слова на основе синтаксически недопустимых последовательностей.
Прежде, чем слова, выделенные в речевом сигнале будут сопоставлены с лексическими входам в словаре системы, необходимо провести морфологический анализ, который приведет слова к их основной форме, например, устранит окончание множественного числа /s/ или /z/, которые сильно бы расширили число входов в словарь.
После морфологического анализа возникшее морфофонологическое представление речевого ввода может быть найдено в словаре системы, чтобы получить синтаксическую и семантическую информацию относительно гипотезы последовательности слов. Синтаксический, семантический, и прагматический анализ - в основном тот же самый для речевого и текстового понимания. Однако, должно быть взаимодействие между этими и более низкими уровнями анализа не только, потому что они будут дополнять правильное распознавание произнесения, но также потому что некоторые аспекты фонологического анализа, особенно касающиеся ударения и интонации, будут способствовать интерпретации. Ударение, например, необходимо для определения контекстуально новой информации и для нахождению зависимых слов для местоимений.
Это краткое описание вклада различных ИЗ в понимание речи только раскрывает основные процессы. ИЗ, использованные в понимании речи, являются прежде всего лингвистическими. Однако, эффективность СПР зависит во много как от эффективного использования этих ИЗ так и от разработки их содержания.
Акустическо - фонетический Анализ
Несомненно наиболее важная область в обработке речи, нуждающаяся в исследованиях, - это акустическо - фонетический анализ. Если акустическо - фонетический анализ слабый, то ошибочные гипотезы выдадут в итоге неправильный анализ. Сегментация и идентификация акустического сигнала в последовательности лингвистических единиц чрезвычайно трудна. Сначала, речь - это код, а не шифр; то есть, акустическое сигналы, ассоциирующиеся с сегментами, непосредственно с ними не связанны; на эти сигналы сильно влияют соседние сегменты. Например, спектрограммы /d/ в /di/ и /du/ очень различны, т.к. на них влияют последующий гласный. Кроме того, не возможно разделить акустической сигнал на /d/ и следующий гласный. Эти наблюдения создали следующую теорию: конечное количество этих сегментов не всегда можно достичь из-за непрерывного движения вокального трактата. Такой синтезирующий анализ был бы, однако, очень в вычислительном отношении дорогой, так как он требовал бы, чтобы СПР умел генерировать всех возможные произнесения и сопоставлять их с акустическом вводом. Однако во-первых, акустическое сигналы, в противоположность фонемам или алафонам, содержат инвариантные сигналы. Во-вторых, акустическое сигналы часто сильно редуцируются в безударном положении. Это часто вызывает много неправильных гипотез в системах, где акустическо - фонетический компонент будет принимать за гипотезу сегмент из фиксированного инвентаря. В-третьих, акустическое сигналы варьируют от диктора диктору из-за физиологических особенностей вокального тракта, различия в характеристиках речи и т.д.. Люди способны компенсировать эти различия быстро и плавно, но все еще мало понятно, как сделать этот процесс автоматическим. Большинство коммерческих систем распознавания речи требует длинного обучения, повторяя за пользователем каждое слово в словаре системы несколько раз и - следовательно очень зависимо диктора. В ARPA несколько из разработанных СПР достигли определенной степени независимости от диктора, пытаясь ввести параметр в акустическо - фонетический анализ для нового диктора на основе обучающегося предложения, которое знала система, пользователю же следовало его проговорить.
Во всех ARPA проектируют СПР, где акустическо - фонетический анализ фактически не существовал и сегментный анализ не был точным. Конечное представление каждой системы было главным образом определено эффективностью более высоких уровней анализа при исправлении ошибок на фонетическом уровне. Более современные системы используют более сложный акустическо - фонетический анализ, интегрируя информацию из ряда преобразований акустического сигнала и создавая несколько типов фонетических представлений, но эффективность все еще ограничивается в среднем 70% успешным распознаванием фонем из речевого высказывания, произнесенных небольшим количеством дикторов.
Фонологический Анализ
Фонологический компонент необходим для любой, обрабатывающей речь, системы, основанной на знаниях, потому что система требует знания относительно фонологических процессов, активных в языке и в прикладных программах, чтобы восстанавливать канонические произношение слов, которые могут быть сопоставлены с соответствующими входами словаря, и получать дальнейшие сигналы к синтаксической и семантической/прагматической интерпретации речевого высказывания. Фонологические компоненты были разработаны для СПР и других систем ARPA. Однако, они были в значительной степени ограничены лексическими, сегментными процессами и обычно имели дело с фонологически управляемыми изменениями, генерируя альтернативное произношение для индивидуальных лексических единиц и сохраняя их в дополнительном словаре. Этот подход не может иметь дело адекватно с фонологическими процессами, которые соединяют границы слова, типа палатализации. Самая большая область прикладной программы для фонологического правила - интонационная фраза; следовательно, фонологию нельзя рассматривать в терминах различного произношения для лексических единиц. Фонологический анализ обеспечивает много важной информации для СПР; например, различные виды фонологического правила блокированы различными лингвистическими границами между сегментами. Полезно разложить на слоги и слова речь, сегментация может также обеспечить сведения для синтаксического анализа; палатализация соединяет границы слова, но блокирована на границах главных синтаксических составляющих, так что ее отсутствие может использоваться, чтобы решить неоднозначность относительно присутствия такой границы в данном месте речевого сигнала. Фонологические правила также изменяются среди диалектов. Следовательно, СПР, способные к пониманию дикторов с различными диалектами, требовали бы знания относительно этих различий и способности реконфигурировать себя для их речи. Палатализация, например, происходит чаще в американских диалектах, чем в британских или английских.
В конце семидесятых стали развиваться новые подходы к фонологии, такие как автосегментная, метрическая зависимости, фонология зависимости, для которых центральным является сверхсегментальный аспект. Некоторые из этих достижений были включены в СПР.
Интерпретация, основанная на источнике знаний
ИЗ бесполезны в СПР, если знание, которое они кодируют, не может быть представлено таким образом, который позволяет интерпретацию с помощью машины. Например, специалисты по фонетики обычно используют Международный Фонетический Алфавит для фонетической записи. Однако, так как выбор представления воздействует на прикладную программу знания, системы представления ИЗ в СПР часто являлись компромиссом между описательной адекватностью и вычислительной эффективностью. Например, в ARPA проектируют каждый СПР, используя идею синтаксического представления, чтобы не выражать все грамматические возможности английского языка. Формальный язык и теория автоматов предлагают эффективные алгоритмы для прикладной программы ИЗ, выраженные в наборах правил с соответствующими формальными свойствами. Например, минимально увеличенные контекстно - свободные записи для адекватного описания английского синтаксиса и фонологии. Однако, успехи этого вида не ведут автоматически в вычислительном отношении к ИЗ, так как наборы правил, требуемые, чтобы выразить знание в этой форме могут быть чрезвычайно большие. Кроме того, кажется маловероятно, что все ИЗ, используемые в СПР могут быть выражены внутри таких ограниченных записей. Тем не менее, более специализированные и мощные методы также были разработаны, типа интерпретаторов для промышленных систем или увеличенные сети переходов. Появляются некоторые экспертные оболочки системы, являющееся многообещающими прикладными программами для акустическо - фонетического преобразования. Чем лучше понимание специфической области, тем больше возможность представления знания адекватно и эффективно. Кроме того, вероятно, что различные схемы представления будут наиболее эффективны для различных ИЗ; следовательно, структура СПР, которая навязывает, одинаковую схему для всех ИЗ, типа HAERSAY-11 или HARPY, не идеальна.
На выбор представления воздействуют факторы, другие чем доступность методики интерпретации для специфической схемы; например, несколько СПР не пытаются отображать непосредственно между акустическом сигналом и фонетическим алфавитом, но создавать промежуточные представления, отмечая акустическо яркие особенности типа назальности, помогать процессу распознавания фонем. На представления также воздействует порядок, в котором расположены различные ИЗ, относящиеся к речевому сигналу и полной структуре СПР. Недавно было предложено, чтобы начальный фонетический анализ отмечал согласные, гласные, а также ударные и безударные слоги и что это простое представление должно использоваться, чтобы получить набор слов-кандидатов из соответственно организованного словаря. Детализированный фонетический анализ затем применялся бы к безударному слогу(слогам), чтобы распознать его между кандидатами.
Структура Системы
Большая часть литературы по СПР касается межкомпонентной связи во время обработки. Эта проблема является основной, т.к. неоднозначности должны быть решены быстро, чтобы избежать ненужного вычисления, и также потому, что избыточность между ИЗ может использоваться, чтобы разложить на множители неправильные гипотезы, вызванные или ошибками системы или подлинной неоднозначностью в речевом сигнале. Например, акустическо - фонетический компонент мог бы предложить аспирированный /p/ или /b/, за которым следует гласные и /t/, результатом этого предположения могут стать такие слова-кандидаты, как “put” и "but". Однако, вероятно, одно из них будет отклонено на основе синтаксического анализа, так как глаголы и союзы не играют одинаковую роль в предложении. Аналогично, подлинная синтаксическая неоднозначность имеется в высказывании, типа " He gave her dog biscuits ", где сочетание "her” может функционировать и как прилагательное и как существительное. Но в этом случае неоднозначность может быть решена с помощью ударения и интонации, которые будут сопровождать обе интерпретации.
Предложенные структуры - иерархические, с последовательным потоком информации через цепочку компонентов ИЗ, и неиерархические, без ограничения на поток информации между компонентами.
Преимущество иерархического подхода в том, что имеется естественный порядок для прикладной программы ИЗ, чтобы вводить речь; синтаксический анализ может осуществляться только на основе лексической информации и т.д. Кроме того, в целом управление системы просто. Однако, имеются много случаев, когда непоследовательные взаимодействия между цепочкой компонентов полезны; например, аспекты просодической, сверхсегментальной структуры высказывания будут релевантны по отношению к фонологической, синтаксической, семантической, и прагматической интерпретации. Непоследовательное взаимодействие может быть достигнуто внутри иерархической модели, передавая все возможные анализы, совместимые с данным компонентом следующему, который затем выбирает подмножество анализов. Но это только тогда сработает, если промежуточные представления, переданные через СПР настолько обогащены, что можно было бы использовать всю проанализированную информацию в следующих компонентах. Таким образом, ввод синтаксического компонента в дополнение к синтаксической информации относительно слов должен включить всю доступную информацию для синтаксического анализа, типа просодической информации, и вся информация, относящаяся семантическому/прагматическому анализу должна быть также включена. Это усложняет схему представления, и дорого в вычислительном отношении, т.к. создает много неправильных гипотез. Неправильных гипотез можно избежать, т.к. информация, в которой отсутствует неоднозначность временно доступна, она закодирована в той части речевого сигнала, который уже проанализирован на более низких уровнях, но в иерархической модели этот способ не применяется, пока ввод не достигает соответствующего компонента в последовательной цепочке.
Неиерархические системы избегают неэффективности, позволяя компонентам применять в наиболее эффективном порядке сложные межкомпонентные связи. Каждый компонент нужно обеспечить средствами, чтобы запрашивать и получить информацию из других компонентов или начинать определенную обработку в другом компоненте. Это требует специальных каналов связи между компонентами в системе. Разработка адекватной системы управления для такой модели невозможна, т.к. должна предусматривать все возможные потоки управления в стадии проекта. Практически, реальные неиерархические модели для СПР были ограничены однородными представлениями из ИЗ и одиночной глобальной структурой данных, как в (blackboard systems) рабочих системах.
Стратегии Обработки
Различные стратегии обработки использовались в разных структурах СПР, чтобы сократить вычисление, требуемое для успешного анализа. И иерархические и неиерархические системы могут работать со способами управления данными как снизу-вверх, так и сверху-вниз при использовании знания, чтобы создать гипотезы относительно ввода. Однако, самые современные СПР используют способ снизу-вверх из-за довольно слабого предсказания речи на основе ИЗ. Аналогично, СПР может исследовать пространство, определяя его глубину и ширину. Большинство систем оперирует с шириной пространства из-за сомнительного или ошибочного характера многих гипотез, но использует подсчитывающие методы, чтобы сохранить размер активного исследуемого пространства. Одна из таких методик, подсчитывающая неудачи, которая включает измерение совокупности множества индивидуальных слов-кандидатов в соотношении с теоретической верхней границей и обработку гипотезы, гарантирует, что СПР найдет наиболее полную подсчитывающую гипотезу для первого высказывания. Однако это не гарантирует, что наиболее привлекательная гипотеза является правильной; эффективность компонентов, которые способствуют порождению гипотез слова, все еще является определяющим фактором в полном представлении системы. Этим оценкам должны отвечать все компоненты, и они должны отражать различные добавления каждого ИЗ. Однако, значение, которое должно быть присоединено к любому ИЗ, должно измениться в соответствии с контекстом. Например, при распознавании безударного и фонетически редуцированного предлога, синтаксический анализ должен чаще обращаться к акустическому анализу, чем при распознавании ударного слога. Кроме того, исследования должны быть оценены с помощью времени. Хотя некоторые схемы оценки, которые использовались в готовых СПР, улучшают эффективность, это связано или по теоретическим причинам, с подсчитывающей методикой, например, подсчитывающей неудачи, или, потому что они были разработаны на основе испытаний и ошибок и оценивались исключительно по эффективности, связанной со временем выполнения, например механизм фокуса внимания в рабочей системе HEARSAY-11.
Анализ речевого сигнала может проходить слева направо через линейный сигнал или из середины островов большей акустической надежности в обоих направлениях. Подход, использующий острова надежности, имеет преимущество в принятии свободных от ошибок фонетических данных за начальную отметку за счет более сложной структуры управления и организации системы, как в HWIM. По-видимому слушатели обращают большее внимание на ударные слоги, которые вообще более ясно произносятся, и следовательно более легко анализируются фонетически. Кроме того, фонологическая структура английского словаря вынуждена быть составленной таким способом, при котором каждое слово может быть получено даже при грубом фонетическом анализе структуры слога вместе с детальным анализом ударного слога. Следовательно, подход, использующий острова надежности по существу правилен, хотя и был бы более эффективен, если обработка началась в ударных слогах.
Текущие Тенденции
Начиная с проекта ARPA в 70-ых имел место период в исследовании речевого понимания, скорее ориентированный на проблемы, чем на построение систем. Многие из этих исследований сосредоточились на акустическо-фонетическом преобразование в результате новых доказательств, показывающих информационное богатство акустического сигнала. Сейчас же возобновлен интерес к построению полных систем, включающий исследования, касающиеся структуры системы. Однако, большинство развивающихся систем, основанных на знаниях, ограничено скорее распознаванием непрерывной речи, чем пониманием. Усовершенствования в акустическо-фонетическом анализе предполагают, чтобы верхние уровни анализа не были определяющими для распознавания непрерывной речи, вопреки преобладающему мнению во времена проекта ARPA. Но проблемы понимания, такие как способы представление знаний, остаются нерешенным.
Системы
Главные СПР, разработанные в проекте ARPA, были HARPY, HWIM, HTEARSAY-11, и SRI/SDC. HARPY оказался наиболее близким по критерию эффективности, определенном для проекта. Однако, структура HARPY требовала составления всего ИЗ в одну конечную сеть, так что язык, воспринимаемый системой был более ограничен, чем в других системах. Система HEARSAY-11 была создана как промышленная система. Несколько СПР были разработаны для Европейских языков, таких как KEAL и MYRTILLE-11 для Французского языка и EVAR для немецкого. Однако, эти системы не превзошли системы ARPA по эффективности или проекту. Так же была создана автоматическая система бронирования места на авиалинии, которая включает непрерывное понимание речи. Эта система, разработанная в Лабораториях Bell, отвечает на телефон, чтобы установить соответствующую бронь. Она использует метод сопоставления целового слова с шаблоном, чтобы распознать слова из словаря, насчитывающего 127 слов.
Дальнейшее Чтение
Журналы:
Artificial Intelligence
Computational Linguistics.
Journal of the Acoustical Society of America,
Journal of Phonetics
Language and Speech.
Speech Technology
Human Factors International Journal of Man-Machine Studies the International Joint Conference on Artificial Intelligence
Coling
Association of Computational Linguistics
Acoustic Society of America, International Conference on Acoustics
Speech and Signal Processing
2. Автоматический морфологический анализ. Соотношение словаря и анализа.
Автоматический морфологический анализ (АМА)- анализ отдельно взятой словоформы и всех тех сведений, которые из нее можно извлечь безотносительно к тому, относятся ли эти сведения к морфологии или нет.
АМА определяется двумя факторами:
1) тип ЕЯ, подвергаемого анализу
2) тип алгоритма авт. обработки текста
МА начинается с поиска входного слова в словаре и с членения словоформы на составляющие ее морфемы.
Общая схема морфологического анализа:
1. Общие правила (управляющий алгоритм
2. Список (таблицы) суффиксов
3. Список (таблицы) информации к суффиксам
4. Список нестандартных операций (нестандартная запись)
5. Обработка омонимичных основ
Важен тип входного словаря. Учитывая связь МА со словарем можно выделить следующие группы МА:
1. морфологический анализ со словарем словоформ: каждой словоформе приписывается определенная информация (слово отыскивается. информация извлекается)
2. морфологический анализ со словарем основ (проблемы: анализ найденных в словаре форм, как отождествить разные словоформы одного и того же слова)
сравнение словоформы на полное совпадение -> нет -> словоформа = основа + окончание. В задачу МА входит разрешение синонимии и омонимии основ
3. МА методом логического умножения (Варга)
Каждой морфеме сопоставляется информация, полученная в результате объединения информации о словоформах, в которые входит данная морфема. Информация о словоформе получается как пересечение или логическая конъюнкция (&) информации о морфемах. входящих в данную словоформу. Тем самым функция. определенная на множестве словоформ. заменяется на функцию, определенную на множестве морфем. Такой анализ производится при наличии словаря основ и применяется к флективным языкам. каждой букве соответствует булевый вектор (есть 1, нет 0). перемножая эти векторы выходят на категорию.
4. независимый МА без словаря словоформ.
Максимальное использование информации о флексиях во флективных языках. выделяются грамматические морфемы (флексии, предлоги, союзы, знаки препинания между словами - все элементы. передающие связи слов во фразе.
Группа флексий, характеризующаяся одинаковым набором грамм. отношений. которые они могут передавать, образует морфему.
флексии, входящие в одну морфему, называются алломорфами, т.е. морфемными синонимами. Задача алгоритма состоит в том, чтобы по взаимному расположению алломорфов отнести каждую флексию к ее морфеме. С этой целью строятся специальные словари: словари флексий, словари слов, не несущих грамм. инф. (наречий и т.п.). Способ имеет ограниченной применение.
Похожие рефераты:
Машины, которые говорят и слушают
Электронные словари и их применимость для традиционного машинного перевода
Теория речевых актов и ее место в современной лингвистике
Обогащение словарного запаса на уроках развития речи в младших классах вспомогательной школы
Соотношение формального и семантического аспектов предложения (на материале английского языка)
Обучение речевому этикету на уроках английского языка
Структурные и прагматические особенности директивных высказываний
Ответы на билеты по языкознанию
Дидактические подходы к тематическому принципу при обучении переводу