| Скачать .docx |
Курсовая работа: Мониторинг системных вызовов создания обращения и удаления сегментов разделяемой памяти в ОС Linux
Факультет информатики и систем управления
Кафедра ПО ЭВМ и информационные технологии
Курсовая Работа
На тему: Мониторинг системных вызовов создания, обращения и удаления сегментов разделяемой памяти в ОС Linux
Содержание
1. Введение
2. Аналитическая часть
2.1. Архитектура ОС Linux
2.2. Перехват и мониторинг системных вызовов
2.3. Средства IPC. Системный вызов sys_ipc
2.4. Разделяемая память (SharedMemory)
2.5. Системные вызовы shmget, shmat, shmctl, shmdt
3. Конструкторская часть
3.1. Технические требования к системе. Перекомпиляция ядра
3.2. Написание и внедрение модуля ядра
3.3. Выбор языка программирования
3.4. Структура программного обеспечения
3.5. Структуры данных
3.6. Реализация мониторинга создания, управления и удаления сегментов разделяемой памяти
3.7. Пользовательский интерфейс
4. Заключение
Список используемой литературы
1. Введение
С развитием операционных систем и увеличением сложности программ появилась необходимость в обмене данными между процессами. Именно поэтому в операционную систему сейчас встраивается множество механизмов, которые обеспечивают так называемый Interproccess Communication (IPC), то есть межпроцессное взаимодействие.
Одной из самых распространённых операционных систем на данный момент является ОС Linux, которая представляет собой интерактивную систему с открытым кодом, разработанную для одновременной поддержки нескольких процессов и нескольких пользователей. Традиционный подход ОС семейства Unix заключается в том, чтобы позволить многопроцессорным системам запускать приложения в отдельных процессах для сокращения времени, требуемого на выполнение специфических задач. Средства IPC позволяют избежать создания огромных программ с большим количеством функций, а заменить их набором отдельных, малых приложений, способных обмениваться данными между собой.
ОС Linux относится к стандарту UnixSystemV, который поддерживает три вида IPC-объектов:
· Очереди сообщений, которые представляют собой связный список в адресном пространстве ядра. Сообщения могут посылаться в очередь по порядку и доставаться из очереди несколькими разными путями.
· Семафоры – счетчики, управляющие доступом к общим ресурсам. Чаще всего они используются как блокирующий механизм, не позволяющий одному процессу захватить ресурс, пока этим ресурсом пользуется другой.
· Разделяемая память – средство, обеспечивающее возможность наличия общей памяти у нескольких процессов.
Механизм взаимодействия, основанный на сегментах SharedMemory, является более быстрым, чем очереди сообщений и семафоры. Здесь нет никакого посредничества в виде каналов, очередей сообщений и т.п., что значительно упрощает этот механизм. Поэтому данный курсовой проект посвящён именно этому типу межпроцессного взаимодействия.
Мониторинг создания, удаления сегментов разделяемой памяти и обращения к ним позволяет проследить, какой пользователь имеет дело с объектами SharedMemory и получить информацию о том, сегмент какого размера и для каких целей запрашивается, по какому адресу он находится в виртуальной памяти и т.д.
2. Аналитическая часть
2.1 Краткий обзор архитектуры ОС Linux
Чтобы понять принцип работы программы мониторинга, для начала следует кратко рассмотреть архитектуру данной операционной системы. Linux, как операционную систему семейства UNIX, можно рассматривать в виде пирамиды, у основания которой располагается аппаратное обеспечение, состоящее из центрального процессора, памяти, дисков, терминалов и других устройств (рис. 1). Функции самой ОС заключаются в управлении аппаратным обеспечением и предоставлении всем программам интерфейса системных вызовов, позволяющего создавать процессы, файлы и прочие ресурсы и управлять ими.
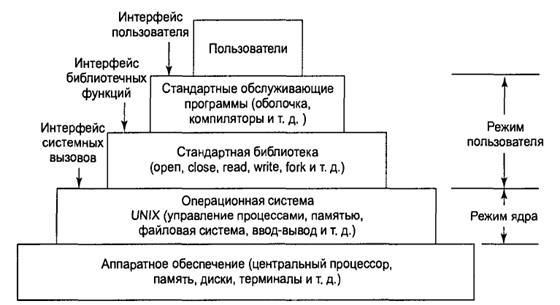
Рис. 1. Структура ОС UNIX
Программы обращаются к системным вызовам, помещая аргументы в регистры центрального процессора и выполняя команду эмулированного прерывания для переключения из пользовательского режима в режим ядра и передачи управления операционной системе. Стандарт POSIX определяет библиотечные процедуры, соответствующие системным вызовам, их параметры, что они должны делать и какой результат возвращать.
Таким образом, взаимодействие с ядром происходит посредством стандартного интерфейса системных вызовов, который представляет собой набор услуг ядра и определяет формат запросов на услуги. Фактически, это набор функций, реализованных в ядре ОС. Процесс запрашивает услугу посредством системного вызова определенной процедуры ядра, внешне похожего на обычный вызов библиотечной функции. Ядро от имени процесса выполняет запрос и возвращает процессу необходимые данные. Любой запрос приложения пользователя в конечном итоге трансформируется в системный вызов, который выполняет запрашиваемое действие.
Прежде чем реализовать перехват какого-либо системного вызова, нужно подробнее рассмотреть механизм системных вызовов.
Точка перехода в ядре, называется system_call. Процедура, которая там находится, проверяет номер системного вызова, который сообщает ядру, какую именно услугу запрашивает процесс. Затем, она просматривает таблицу системных вызовов (sys_call_table) отыскивает адрес функции ядра, которую следует вызвать, после чего вызывается нужная функция. По окончании работы системного вызова, выполняется ряд дополнительных проверок и лишь после этого управление возвращается вызывающему процессу (или другому процессу, если вызывающий процесс исчерпал свой квант времени).
2.2 Перехват и мониторинг системных вызовов
Перехват системных вызовов можно осуществить следующими способами:
· методом прямого доступа к адресному пространству ядра
· с помощью загружаемого модуля ядра
Прямой доступ к адресному пространству ядра обеспечивает файл устройства /dev/kmem. В этом файле отображено все доступное виртуальное адресное пространство. Для работы с файлом kmem используются стандартные системные функции - open(), read(), write(). Открыв стандартным способом /dev/kmem, мы можем обратиться к любому адресу в системе, задав его как смещение в этом файле.
Обращение к системным функциям осуществляется посредством загрузки параметров функции в регистры процессора и последующим вызовом программного прерывания 0x80. Обработчик этого прерывания, функция system_call, помещает параметры вызова в стек, извлекает из таблицы sys_call_table адрес вызываемой системной функции и передает управление по этому адресу.
Имея полный доступ к адресному пространству ядра, мы можем получить все содержимое таблицы системных вызовов, т.е. адреса всех системных функций. Изменив адрес любого системного вызова, мы, тем самым, осуществим его перехват. Но для этого необходимо знать адрес таблицы, или, другими словами, смещение в файле /dev/kmem, по которому эта таблица расположена.
Для вычисления адреса функции system_call из таблицы IDT необходимо извлечь шлюз прерывания int $0x80, а из него - адрес соответствующего обработчика, т.е. адрес функции system_call. Найдя сигнатуру этой команды в файле /dev/kmem, мы найдем и адрес таблицы системных вызовов.
Но мы работает в адресном пространстве пользователя, а новый системный вызов необходимо разместить в адресном пространстве ядра. Для этого необходимо получить блок памяти в пространстве ядра и разместить в этом блоке новый системный вызов.
Выделить память в пространстве ядра можно при помощи функции kmalloc. Но вызвать напрямую функцию ядра из адресного пространства пользователя нельзя, поэтому для этого используется специальный алгоритм, в результате которого в нашем распоряжении будет блок памяти, расположенный в пространстве ядра.
Нетрудно заметить, что данный механизм довольно трудоёмок, поэтому на практике часто используется другой метод.
Перехват системных вызовов реализуется посредством механизма загружаемого модуля ядра (общепринятое сокращение LKM - LoadableKernelModule). LKMпредставляет собой программный код, выполняемый в пространстве ядра. Главной особенностью этого механизма является возможность динамической загрузки и выгрузки без необходимости перезагрузки всей системы или перекомпиляции ядра. Модули расширяют функциональные возможности. Например, одна из разновидностей модулей ядра, драйверы устройств, позволяют ядру взаимодействовать с аппаратурой компьютера. При отсутствии поддержки модулей пришлось бы писать монолитные ядра и добавлять новые возможности прямо в ядро. При этом, после добавления в ядро новых возможностей, пришлось бы перезагружать систему.
Подробнее принцип создания и загрузки модуля ядра будет описан в конструкторском разделе.
Для реализации модуля, перехватывающего системный вызов, необходимо определить алгоритм перехвата, представленный на рис. 2.

Рис.2. Алгоритм перехвата системного вызова с помощью LKM
Другими словами, в ядро загружается модуль, который
· Сохраняет указатель на оригинальный (исходный) вызов для возможности его восстановления.
· Содержит функцию, реализующую новый системный вызов.
· В таблице системных вызовов sys_call_table производит замену вызовов (настраивает соответствующий указатель на новый системный вызов)
· По окончании работы (при выгрузке модуля) восстанавливает оригинальный системный вызов, используя ранее сохраненный указатель
Данный механизм позволяет создать монитор – программу, которая отслеживает вызовы конкретных системных функций, перехватывает и сохраняет информацию об их параметрах, что и было проделано в данном курсовом проекте.
2.3. Средства IPC . Системный вызов sys _ ipc
Одной из важнейших особенностей ОС семейства UNIX считается реализация механизмов IPC, или, другими словами, межпроцессного взаимодействия. Термин подразумевает различные средства обмена данными между процессами, стартовавшими в одной системе.
На высоком уровне можно разделить межпроцессное взаимодействие на следующие наиболее крупные и важные разделы:
· Сообщения: каналы (pipes) и
очередисообщений (pipes and message queues)
· Разделяемая память (Shared memory)
· Удаленный вызов процедур - RPC (remote procedure calls)
· Синхронизация: семафоры и любые виды блокирования
· Сетевое взаимодействие (API сокетов)
Из имеющихся типов IPC следующие три могут быть отнесены к
SystemVIPC, то есть к методам взаимодействия процессов, соответствующим стандарту SystemV:
·Очереди сообщений
·Семафоры
·Разделяемая память
Термин «SystemVIPC» говорит о происхождении этих средств: впервые они появились в UnixSystemV. У них много общего, например, схожи функции, с помощью которых организуется доступ к объектам, и и формы хранения информации в ядре.
Каждый объект IPC (очередь сообщений, семафор или сегмент разделяемой памяти) обладает уникальным идентификатором (Id), который позволяет ядру ОС идентифицировать этот объект. К примеру, для того, чтобы сослаться на определенный сегмент разделяемой памяти, необходимо знать уникальный идентификатор, назначенный этому сегменту. Но следует отметить, что идентификатор IPC уникален только для своего типа объектов.
Для генерации идентификатора необходим уникальный ключ. Притом пользовательские приложения должны генерировать свои собственные ключи специальной системной функцией.
Когда процесс пытается обратиться к какому-либо объекту IPC (а именно, семафору, очереди сообщений или сегменту разделяемой памяти), он совершает системный вызов sys_ipc. Под обращением здесь понимается запрос на создание, удаление объекта, управление его параметрами. При этом функции sys_ipc передаётся некий идентификатор, однозначно определяющий, что именно запрашивает процесс.
Таким образом, перехватив данный системный вызов, можно отследить процесс создания, удаления сегментов разделяемой памяти и изменения его параметров.
2.4 Разделяемая память ( Shared Memory )
Данный курсового проекта заключается в мониторинге использования только одного из средств IPC, а именно разделяемой памяти, которая может быть наилучшим образом описана как отображение участка (сегмента) памяти, который будет разделён между более чем одним процессом. SharedMemory является наиболее быстрым средством межпроцессного взаимодействия. После отображения области памяти в адресное пространство процессов, совместно её использующих, для передачи данных больше не требуется участия ядра. При использовании этого средства участки виртуального адресного пространства разных процессов отображаются на одни и те же адреса реальной памяти.
При работе с общим сегментом памяти один из процессов должен создать сегмент разделяемой (общей) памяти, указав требуемый размер сегмента, и получить его идентификатор. Этот идентификатор затем используется процессом-создателем для выполнения управляющих операций с разделяемой памятью.
Получив идентификатор разделяемого сегмента памяти (создав сегмент или получив его идентификатор от другого процесса), процесс должен "присоединить" сегмент. Операция присоединения возвращает адрес разделяемого сегмента в виртуальном адресном пространстве процесса. Виртуальный адрес одного и того же сегмента может быть разным для разных процессов. Далее процессы ведут чтение и запись данных в сегменте разделяемой памяти, используя для этого те же самые машинные команды, что и при работе с обычной памятью.
Процесс, закончивший работу с сегментом разделяемой памяти должен "отсоединить" его, а по окончании использования сегмента всеми процессами он должен быть уничтожен.
При одновременной работе процессов с общей областью памяти, возможно, требуется синхронизация их доступа к области. За обеспечение такой синхронизации полностью отвечает программист, который может использовать для этого алгоритмы, исключающие конфликты одновременного доступа или системные средства, например, семафоры.
2.5 Системные вызовы shmget , shmat , shmctl , shmdt
В ядре Linux, все вызовы, имеющие отношение к systemVIPC диспетчеризуются через функцию sys_ipc (размещенную в файле arch/i386/kernel/sys_i386.c). Для идентификации системного вызова, sys_ipcиспользует номер этого вызова.
В ОС Linux механизм разделяемых сегментов памяти обеспечивается четырьмя системными вызовами: shmget, shmctl, shmat, shmdt. В функции sys_ipc они имеют номера SHMGET, SHMAT, SHMCTL, SHMDT соответственно.
Функции intshmget(key_tkey, size_tsize, intflag) позволяет создать новый сегмент разделяемой памяти или подключиться к существующему. Возвращаемое числовое значение является идентификатором сегмента, который используется при дальнейших операциях с ним.
Аргумент key – уникальный ключ, необходимый для создания идентификатора. size указывает требуемый размер сегмента в байтах.
flag представляет собой комбинацию флагов доступа на чтение и запись
После создания или открытия сегмента разделяемой памяти его нужно подключить к адресному пространству процесса вызовом
void * shmat(intshmid, void *shmaddr, intflag), который возвращает адрес начала области разделяемой памяти в адресном пространстве вызвавшего процесса. Аргумент shmid – идентификатор разделяемой памяти, возвращённый shmget. Shmaddr определяет желаемый адрес «привязки» сегмента. Но в большинстве случаев система сама выбирает начальный адрес для вызвавшего процесса. По умолчанию сегмент подключается для чтения и записи, но в аргументе flag модно указать константу SHM_RDONLY, которая позволит установить доступ только на чтение.
После завершения работы с сегментом его следует отключить вызовом int shmdt(void *shmaddr), который получает в качестве аргумента адрес, возвращённый функцией shmat. Следует отдельно отметить, что эта функция не удаляет сегмент разделяемой памяти, а всего лишь снимает «привязку» к процессу.
Функция intshmctl(intshmid, intcmd, structshmid_ds *buff) позволяет выполнять различные операции с сегментом разделяемой памяти. Аргумент cmd может принимать следующие значения:
IPC_RMID – удаление сегмента с идентификатором shmid;
IPC_SET – установка значений полей структуры shmid_ds для сегмента равными значениям соответствующим полей структуры, на которую указывает buff: shm_perm.uid, shm_perm.gid, shm_perm.mode
IPC_STAT – возвращает вызывающему процессу (через аргумент buff) текущее значение структуры shmid_ds для указанного сегмента разделяемой памяти.
Разделяемые сегменты памяти в Unix/Linux (как и семафоры) не имеют внешних имен. При получении идентификатора сегмента процесс пользуется числовым ключом. Разработчики несвязанных процессов могут договориться об общем значении ключа, который они будут использовать, но у них нет гарантии в том, что это же значение ключа не будет использовано кем-то еще. Гарантированно уникальный сегмент можно создать с использованием ключа IPC_PRIVATE, но такой ключ не может быть внешним. Поэтому сегменты используются, как правило, родственными процессами, которые имеют возможность передавать друг другу их идентификаторы, например, через наследуемые ресурсы или через параметры вызова дочерней программы.
Таким образом, для создания монитора разделяемой памяти из таблицы системных вызовов следует получить адрес обработчика sys_ipc(), перехватить его, а затем, зная, какой из вышеописанных вызовов совершает система, считать соответствующие данные.
3. Конструкторская часть
3.1 Технические требования к системе. Перекомпиляция ядра
Для создания и тестирования данной программы использовалась ОС LinuxSUSE 10 (версия ядра 2.6.13-15). Но с целью предотвращения потенциальной опасности, связанной с подменой адресов системных вызовов, ядро, начиная с версии 2.5.41, не экспортирует таблицу sys_call_table, доступ к которой необходим для создания программы мониторинга системных вызовов. Поэтому, чтобы иметь возможность перехватывать системные вызовы, надо наложить следующую «заплату» и затем перекомпилировать ядро.
"Заплата" на ядро (export_sys_call_table_patch_for_linux_2.6.x)
--- kernel/kallsyms.c.orig 2003-12-30 07:07:17.000000000 +0000
+++ kernel/kallsyms.c 2003-12-30 07:43:43.000000000 +0000
@@ -184,7 +184,7 @@
iter->pos = pos;
return get_ksymbol_mod(iter);
}
-
+
/* If we're past the desired position, reset to start. */
if (pos < iter->pos)
reset_iter(iter);
@@ -291,3 +291,11 @@
EXPORT_SYMBOL(kallsyms_lookup);
EXPORT_SYMBOL(__print_symbol);
+/* START OF DIRTY HACK:
+ * Purpose: enable interception of syscalls as shown in the
+ * Linux Kernel Module Programming Guide. */
+extern void *sys_call_table;
+EXPORT_SYMBOL(sys_call_table);
+ /* see http://marc.free.net.ph/message/20030505.081945.fa640369.html
+ * for discussion why this is a BAD THING(tm) and no longer supported by 2.6.0
+ * END OF DIRTY HACK: USE AT YOUR OWN RISK */
Эта заплата протестирована с ядрами 2.6.[0123], и может накладываться или не накладываться на другие версии.
Сценарийналоженияследуюший:
#!/bin/sh
cp export_sys_call_table_patch_for_linux_2.6.x /usr/src/linux/
cd /usr/src/linux/
patch -p0 < export_sys_call_table_patch_for_linux_2.6.x
Но такой способ эффективен только при совпадении «заплатки» с версией ядра. Если «заплата» по каким-то причинам не накладывается, нужно скопировать исходные файлы ядра в отдельную директорию, дописать в файл kernel/kallsyms.cпосле строки
EXPORT_SYMBOL(__print_symbol);
следующее:
extern void *sys_call_table;
EXPORT_SYMBOL(sys_call_table);
После этого открыть Makefile и в строке
EXTRAVERSION =
дописать новое имя ядра.
После этого следует пересобрать ядро, выполнив следующую последовательность действий:
1) Удаления временных файлов и настроек, полученных при возможной предыдущей сборке, командой
# make mrproper
1) Настройка ядра. Осуществляется одной из следущих команд:
# make xconfig
# make menuconfig
# make config
# makeoldconfig
Первый вариант (xconfig) для пользователей, у которых есть графика – запустится графическая программка для настройки, остальные – для консоли. Второй вариант (menuconfig) предлагает текстовые меню для настройки. Третий (config) задает 1000 и 1 вопрос. Четвертый (oldconfig) нужен если уже есть сформированный файл настроек .config (можно использовать файл настроек от старого ядра), при этом варианте задаются только те вопросы которые появились в этой версии ядра.
2) Сборка ядра. Выполняется командой от пользователя root
# make bzImage modules modules_install install
Перекомпиляция ядра происходит довольно долго. После установки ядра, как правило, автоматически настраивается и загрузчик. Поэтому после этого, следует перезагрузить систему уже от имени нового ядра.
3.2 Написание и внедрение модуля ядра
В программе перехват системных вызовов осуществлён механизмом загружаемого модуля ядра (LKM). В аналитической части были описаны преимущества, которые получает система при использовании данного механизма. Теперь стоит разобраться, как он реализуется.
Каждый LKM состоит минимум из двух основных функций:
· intinit_module(void) , которую вызывает insmod во время загрузки модуля
· void cleanup_module(void), которуювызывает rmmod
Функция init_module() выполняет регистрацию обработчика какого-либо события или замещает какую-либо функцию в ядре своим кодом (который, как правило, выполнив некие специфические действия, вызывает оригинальную версию функции в ядре). Вызывается при загрузке LKM в память.
Функция cleanup_module() является полной противоположностью, она производит "откат" изменений, сделанных функцией init_module(), что делает выгрузку модуля безопасной.
Любой загруженный модуль ядра заносится в список /proc/modules, поэтому при удачной загрузке можно убедиться, что модуль стал частью ядра.
В данном курсовом проекте функция init_module() изменяет соответствующий определённому системному вызову указатель в sys_call_table и сохраняет его первоначальное значение в переменной. Функция cleanup_module() восстанавливает указатель в sys_call_table, используя эту переменную.
В данном подходе кроются свои "подводные камни" из-за возможности существования двух модулей, перекрывающих один и тот же системный вызов. Например, имеется два модуля, А и B. Пусть модуль A перекрывает системный вызов open, своей функцией A_open, а модуль B -- функцией B_open. Первым загружается модуль A, он заменяет системный вызов open на A_open. Затем загружается модуль B, который заменит системный вызов A_open на B_open. Модуль B полагает, что он подменил оригинальный системный вызов, хотя на самом деле был подменен вызов A_open, если модуль B выгрузить первым, то ничего страшного не произойдет -- он просто восстановит запись в таблице sys_call_table в значение A_open, который в свою очередь вызывает оригинальную функцию sys_open. Однако, если первым будет выгружен модуль А, а затем B, то система "рухнет". Модуль А восстановит адрес в sys_call_table, указывающий на оригинальную функцию sys_open, "отсекая" таким образом модуль B от обработки действий по открытию файлов. Затем, когда будет выгружен модуль B, он восстановит адрес в sys_call_table на тот, который запомнил сам, потому что он считает его оригинальным. Т.е. вызовы будут направлены в функцию A_open, которой уже нет в памяти.
На первый взгляд, проблему можно решить, проверкой -- совпадает ли адрес в sys_call_table с адресом нашей функции open и если не совпадает, то не восстанавливать значение этого вызова (таким образом B не будет "восстанавливать" системный вызов), но это порождает другую проблему. Когда выгружается модуль А, он "видит", что системный вызов был изменен на B_open и "отказывается" от восстановления указателя на sys_open. Теперь, функция B_open будет по прежнему пытаться вызывать A_open, которой больше не существует в памяти, так что система "рухнет" еще раньше -- до удаления модуля B.
Подобные проблемы делают такую "подмену" системных вызовов неприменимой для широкого распространения. С целью предотвращения потенциальной опасности, связанной с подменой адресов системных вызовов, ядро более не экспортирует sys_call_table. Но всё же получить доступ к таблице системных вызовов можно, поставив соответствующую «заплату», что было описано в предыдущем параграфе.
3.3 Выбор языка программирования
Программа написана на языке С с использованием встроенного в
ОС Linux компилятора GCC. Выбор языка основан на том, что исходный код ядра, предоставляемый системой, написан на С, и использование другого языка программирования в данном случае было бы нецелесообразным. К тому же он является мощным средством для разработки практически любого приложения.
3.4 Структура программного обеспечения
Программа состоит из следующих объектов
1) Загружаемый модуль ядра Monitor.с
2) Модуль Start.с, который осуществляет подготовку к загружению модуля Monitor.с
3) Модуль Save.с, предназначенный для сохранения полученных данных и вывода их на экран.
4) Модуль Test.с, содержащий эмулятор системных вызовов для тестирования программного обеспечения.
Monitor.с представляет собой загружаемый модуль ядра (LKM), написание и принцип загрузки которого были описаны выше.
Помимо двух основных функций программа содержит новый обработчик системного вызова sys_ipc- функцию new_sys_ipc, которая, в зависимости от принимаемых данных вызывает функции:
my_shmget;
my_shmat;
my_shmctl;
my_shmdt;
представляющие собой обработчики системных вызовов
shmget(), shmat(), shmctl(), shmdt() соответственно.
Также в модуле находятся функции, отображающие полученные данные в системном файле /var/log/messages:
print_shmget_info();
print_shmat_info();
print_shmctl_info();
print_shmdt_info();
Модуль Test.c представляет собой программу, позволяющую пользователю
· Создать сегмент разделяемой памяти
· Записать в него данные
· Считать данные
· Узнать режим доступа сегмента
· Удалить сегмент
Для этого предназначены процедуры:
· void writeshm();
· void readshm();
· void removeshm();
· void seeuid();
Модуль создан для тестирования программы мониторинга.
Модули Start.c и Save.cпредназначены для отображения данных, полученных в результате выполнения программы мониторинга обращений к сегментам разделяемой памяти, на экран и для сохранения их в файл.
3.5 Структуры данных
Для каждого сегмента разделяемой памяти ядро хранит нижеследующую структуру, определённую в заголовочном файле <sys/shm.h>. Данный программный проект позволяет отследить процесс изменения содержимого полей этих структур при вызове системной функции sys_ctl.
struct shmid_ds
{
struct ipc_perm shm_perm;
int shm_segsz;
time_t shm_atime;
time_t shm_dtime;
time_t shm_ctime;
unsigned short shm_cpid;
unsigned short shm_lpid;
shortshm_nattch;
};
Значения полей структуры:
shm_perm – права на выполнение операции (структура определена в
файле <sys/ipc.h>)
shm_segsz – реальный размер сегмента (в байтах)
shm_atime – время последнего подключения
shm_dtime – время последнего отключения
shm_ctime – время последнего изменения
shm_cpid – идентификатор процесса создателя
shm_lpid – идентификатор процесса подключавшегося последним
shm_nattch – количество текущих подключений сегмента
struct ipc_perm
{
key_t key;
ushort uid;
ushort gid;
ushort cuid;
ushort cgid;
ushort mode;
ushort seq;
};
Со значением полей
key– уникальный ключ IPC
uid– идентификатор пользователя владельца
gid– идентификатор группы владельца
cuid– идентификатор пользователя создателя
cgid– идентификатор владельца создателя
mode– разрешения чтения/записи
seq– последовательный номер канала
Сохраняемая отдельно вместе с ключом IPC-объекта информация содержит данные о владельце и создателе этого объекта (они могут различаться) и режимы восьмеричного доступа.
Модуль Monitor.cсодержит следующие структуры данных для хранения информации о сегменте разделяемой памяти, полученной в результате выполнения программы
struct shmget_info
{
int cur_uid;
int key;
int shm_id;
int size;
int flag;
};
struct shmat_info
{
int cur_uid;
int shm_id;
unsigned long address;
};
struct shmctl_info
{
int cur_uid;
int shm_id;
int cmd;
struct shmid_ds *main;
int result;
};
struct shmdt_info
{
int cur_uid;
char *address;
intresult;
};
key – уникальный ключ для определения сегмента
shm_id – идентификатор сегмента
size – запрашиваемый размер сегмента
flag – флаг, определяющий, с какой целью был совершён системный
вызов sys_get:
· процесс создаёт новый сегмент разделяемой
памяти (flag = 0)
· процесс обращается к уже созданному сегменту
разделяемой памяти (flag !=0)
address – адрес начала сегмента в адресном пространстве пользователя
cmd – номер команды, указывающей на то, для каких действий был
произведён системный вызов sys_ctl:
· получить значения полей структуры shmid_ds (IPC_STAT)
· изменить значения полей в структуре shmid_ds (IPC_SET)
· удалить сегмент (IPC_RMID)
main – полученная копия структуры shmid_ds
result – результат выполнения системного вызова (success или failed)
3.6 Реализация мониторинга создания, управления и удаления сегментов разделяемой памяти
Как уже было отмечено, отследить обращения к сегментам разделяемой памяти можно, перехватив системный вызов sys_ipc, который помимо прочих аргумантов принимает параметр call, определяющий какую из системных функций sys_get, sys_shmat, sys_ctl, sys_dt следует вызвать.
Для перехвата выхова sys_ipc, надо сделать следующее:
· В функции init_module() сохранить указатель на оригинальный (исходный) вызов – orig_sys_ipc – и в таблице системных вызовов sys_call_table настроить соответствующий указатель на новый системный вызов.
· Создать функцию, реализующую новый системный вызов – new_sys_ipc.
· В функции cleanup_module() восстанавить оригинальный системный вызов, используя ранее сохраненный указатель.
В созданном обработчике системного вызова, в зависимости от аргумента call, вызывать функции обработки вызовов sys_get, sys_shmat, sys_ctl, sys_dt, которые сохраняют полученные данные в соответствующие структуры данных, затем отображаются в ядро и выводятся в системном файле /var/log/messages.
Компиляция созданного модуля ядра осуществляется с помощью команды
# make
Несмотря на все свои достоинства, утилита make ничего не знает о проекте, поэтому необходимо создать простой текстовый файл, который будет содержать все необходимые инструкции по сборке. Файл с инструкциями по сборке проекта называется Makefile.
В данном случае, когда модуль состоит из одного файла, Makefile имеет вид, представленный на рис.3
obj-m += monitor.o all: make -C /lib/modules/$(shell uname -r)/build M=$(PWD)modules clean: make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean |
Рис.3. Makefile
Загрузка модуля в ядро осуществляется командой
insmod ./<имя модуля>.ko
Выгрузка – командой
rmmod <имя модуля>
Проверить, загружен ли модуль в ядро, можно командой
# lsmod,
которая выдаёт список всех загруженных модулей. lsmod в свою очередь обращается за необходимыми сведениями к файлу /proc/modules.
3.7 Пользовательский интерфейс
Пользовательский интерфейс является полностью консольным. Во-первых, потому что при минимуме входных данных нецелесообразно создавать графическое приложение. Во-вторых, концепция ОС Linuxпредполагает широкое использование возможностей командной строки Shell.
Для того чтобы запустить программу, необходимо выполнить следующую последовательность действий:
· Запустить приложение start.o
· Загрузить модуль ядра
· Запустить тестовую программу (или любое приложение ОС)
· Выгрузить модуль ядра
· Запустить приложение save.o
Тестирующее приложение предоставляет пользователю меню, позволяющее производить выбор действий над сегментом разделяемой памяти (рис.4).
Actions with Shared Memory Segment w <text> - write text data into Segment r - read data from Segment d - delete Segment u - getUID |
Рис.4. Меню тестирующей программы
Результат отображается на экране и сохраняется в файле. Структура файла отображена на рис.5
Jun 2 02:33:53 terma kernel: Jun 2 02:33:53 terma kernel: ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Jun 2 02:33:53 terma kernel: Monitoring of Shared Memory Segments. Jun 2 02:33:53 terma kernel: Jun 2 02:34:16 terma kernel: SHMGET is called by UID: 0 Jun 2 02:34:16 terma kernel: key = 1392733089 Jun 2 02:34:16 terma kernel: shmID = 2588675 Jun 2 02:34:16 terma kernel: size = 88 byte Jun 2 02:34:16 terma kernel: flag = 1968 Jun 2 02:34:16 terma kernel: [creating of new segment] Jun 2 02:34:16 terma kernel: Jun 2 02:34:16 terma kernel: SHMAT is called by UID: 0 Jun 2 02:34:16 terma kernel: shmID = 2588675 Jun 2 02:34:16 terma kernel: shmaddr = 40018000 Jun 2 02:34:16 terma kernel: Jun 2 02:34:23 terma kernel: SHMGET is called by UID: 0 Jun 2 02:34:23 terma kernel: key = 1392733089 Jun 2 02:34:23 terma kernel: shmID = 2588675 Jun 2 02:34:23 terma kernel: size = 88 byte Jun 2 02:34:23 terma kernel: flag = 0 Jun 2 02:34:23 terma kernel: [using segment as client] Jun 2 02:34:23 terma kernel: Jun 2 02:34:23 terma kernel: SHMAT is called by UID: 0 Jun 2 02:34:23 terma kernel: shmID = 2588675 Jun 2 02:34:23 terma kernel: shmaddr = 40018000 Jun 2 02:34:23 terma kernel: Jun 2 02:34:23 terma kernel: SHMCTL is called by UID: 0 Jun 2 02:34:23 terma kernel: shmID = 2588675 Jun 2 02:34:23 terma kernel: cmd = IPC_STAT (2) Jun 2 02:34:23 terma kernel: [getting current information about segment] Jun 2 02:34:23 terma kernel: size of segment = 88 byte Jun 2 02:34:23 terma kernel: key = 1392733089 Jun 2 02:34:23 terma kernel: uid = 0 Jun 2 02:34:23 terma kernel: gid = 0 Jun 2 02:34:23 terma kernel: cuid = 0 Jun 2 02:34:23 terma kernel: cgid = 0 Jun 2 02:34:23 terma kernel: mode = 0 Jun 2 02:34:23 terma kernel: [successfully] Jun 2 02:34:23 terma kernel: Jun 2 02:34:26 terma kernel: SHMGET is called by UID: 0 Jun 2 02:34:26 terma kernel: key = 1392733089 Jun 2 02:34:26 terma kernel: shmID = 2588675 Jun 2 02:34:26 terma kernel: size = 88 byte Jun 2 02:34:26 terma kernel: flag = 0 Jun 2 02:34:26 terma kernel: [using segment as client] Jun 2 02:34:26 terma kernel: Jun 2 02:34:26 terma kernel: SHMAT is called by UID: 0 Jun 2 02:34:26 terma kernel: shmID = 2588675 Jun 2 02:34:26 terma kernel: shmaddr = 40018000 Jun 2 02:34:26 terma kernel: Jun 2 02:34:26 terma kernel: SHMCTL is called by UID: 0 Jun 2 02:34:26 terma kernel: shmID = 2588675 Jun 2 02:34:26 terma kernel: cmd = IPC_RMID (0) Jun 2 02:34:26 terma kernel: [segment marked for deletion] Jun 2 02:34:26 terma kernel: [successfully] Jun 2 02:34:26 terma kernel: Jun 2 02:34:26 terma kernel: SHMDT is called by UID: 0 Jun 2 02:34:26 terma kernel: shmaddr: 40018000 Jun 2 02:34:26 terma kernel: [segment was deleted successfully] Jun 2 02:34:26 terma kernel: Jun 2 02:34:55 terma kernel: Jun 2 02:34:55 terma kernel: The end. Jun 2 02:34:55 terma kernel: ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ |
Рис.5 Файл Result
Заключение
В результате выполнения данной курсовой работы был изучен механизм межпроцессного взаимодействия (IPC) на основе сегментов разделяемой памяти. Реализован мониторинг системных вызовов, обращающихся к объектам SharedMemory, а именно создания, удаления сегментов разделяемой памяти и обращения к ним в ОС Linux. В результате чего были получены данные о сегментах разделяемой памяти, такие как идентификаторы пользователя и группы владельца, запрашиваемый и реальный размеры сегмента, адрес привязки сегмента в адресном пространстве пользователя и другие.
Список используемой литературы
1) «Linux Programmer’s Guide», Sven Goldt, Sven van der Meer, Skott Burkett, Matt Welsh
2) «The Linux Kernel Module Programming Guide», А Peter Jay Salzman, Michael Burian, Ori Pomerantz
3) «Перехват системных вызовов», статья из журнала «Системный администратор», В. Мешков
4) «Современные операционные системы» , Э. Таненбаум