| Скачать .docx |
Реферат: Базы данных 10
БАЗЫ ДАННЫХ 2009
Данный файл содержит 1-4, 6, 10, 13, 14 лекции
Лекция 1
Введение
В начале 70-х годов для удобства работы с большими массивами данных сформулирована концепция баз данных. Ее основными положениями были:
1.Независимость прикладных программ от данных, размещенных во внешней памяти
2. Отсутствие избыточности в данных
3.Способность системы противостоять сбоям и отказам.
Для реализаций этих положений предлагалось ввести сервисную систему – посредник между пользовательскими программами и операционной системой.
Эта система была названа СУБД (система управления базами данных).

С 70 годов стали появляться различные СУБД. Наиболее известными из них были: IMS/360, TOTAL, ADABAS, ОКА, БАНК, СЕТОР, СЕДАН, ДИСОД. Эти системы разрабатывались для больших вычислительных машин. Они были мощные и интересные по своим возможностям, но достаточно сложные для понимания и освоения.
Современные СУБД во многом аналогичны по построению своим предшественникам, но имеют, как правило, более удобный интерфейс и более приспособлены для использования в вычислительных сетях.
Наиболее известными и широко используемыми в настоящее время являются
СУБДOracle, MS SQL Server иDB/2.
Тема 1. Основные положения теории баз данных
1.1 База данных и ее компоненты
БД– именованная совокупность данных, описывающая объекты реального мира и связи между ними.
Под объектом может пониматься предмет или процесс окружающего мира.
На рис. 1.1 представлен типичный состав БД и показана связь БД с пользователем.

Рис. 1.1 Взаимодействие пользователя с БД
Из рис. 1.1 видно, что в состав БД входят различные информационные объекты, но основой БД, естественно, являются данные пользователя. Именно данные пользователя определяют в своей основе сущности. Другие информационные объекты БД играют вспомогательную роль.
Индексы – это специальные элементы структуры БД, служащие для ускорения обработки запросов пользователя.
Представления – виртуальные таблицы, предоставляемые пользователям для повышения производительности и надежности системы.
Хранимые процедуры - программные модули для реализации самых разных задач, хранимые непосредственно в БД.
Триггеры – специальные программные средства для инициализации хранимых процедур в случае обновления БД.
Метаданные – данные, которые описывают данные пользователя (структуру, особенности, права пользователя и т.д.), т. е. это данные о данных. Метаданные используются самой СУБД, а не пользователями.
1.2. Использование БД
Основным инструментом пользователя при использовании БД является СУБД.
СУБД- сервисная программная система, служащая для создания и поддержки БД.
Таким образом, любая СУБД должна:
1) уметь создавать БД.
2) поддерживать БД
К функциям поддержки прежде всего относятся:
-управление внешней памятью,
-управление буферами,
- поддержка встроенного языка,
- управление транзакциями.
Все современные СУБД могут работать в двух режимах:
- в режиме диалога
- в режиме прикладных программ.
Программы, с помощью которых пользователи работают с БД, называются прикладными программами.
Как видно из рис.1.1, приложения
1) создают и передают запросы к БД на поиск или модификацию необходимых данных
2) создают и обрабатывают формы и отчеты
Отчет – это некоторая выборка данных из БД, структурированная
определенным образом.
3) выполняют логику программы, т.е. решают конкретную задачу для данной предметной области.
Принято различать следующие группы пользователей:
1 Конечные пользователи (это лица, для которых создается система с БД)
2 Разработчики приложений (программисты)
Программисты используют БД на стадии разработки системы с БД (информационной системы).
3 Администраторы баз данных АБД (они непосредственно создают БД и контролируют правильность ее использования)
Администраторы физически создают БД, задают ограничения целостности данных и определяют права конечных пользователей. Устраняют неисправности в ходе эксплуатации системы с БД и при необходимости восстанавливают БД.
АДБ, как правило, не используют приложения. Они, обычно, работают с БД средствами самой СУБД
Заметим так же, что конечные пользователи знают только свои формы и отчеты.
При этом они могут не знать, как структурированы их данные и как они хранятся во внешней памяти.
Вышеотмеченное, по сути дела, отражает основную идею концепции БД: конечный пользователь не должен знать, как структурированы данные и как они хранятся. Он должен только знать, что это за данные и какие операции можно над ними выполнять.
Лекция 2
1.3 Основные понятия реляционной модели данных
Современные СУБД в основном используют реляционную модель данных.
Реляционная модель впервые была разработана в 1969 году Коддом на основании теории отношений. Ее характерной особенностью является
представление данных пользователя в виде отношений (двумерных таблиц), широко распространенных в различных областях знаний (рис. 1.2) .
Отношение – это плоская, двумерная таблица.
Руководители (родительская таблица)
| Таб_ном_рук | № отдела | Штат | ФИО |
| 237 | 55 | 11 | Ленский РП |
| 528 | 17 | 14 | Орлов ВВ |
| 714 | 89 | 46 | Коровин НП |
![]()

![]()
![]() Внешний ключ
Внешний ключ
Сотрудники (дочерняя таблица)
| Табельный номер | ФИО | Таб_ном_рук | Должность |
| 99 | Кулибин Н.Н. | 528 | научн_сотр |
| 100 | Рогов А.Н. | 237 | лаборант |
| 101 | Иванов И. И. | 237 | инженер |
| 148 | Петров П. П. | 714 | инженер |
| 135 | Сидоров С. С. | 528 | лаборант |
Рис. 1.2 Связанные таблицы
Фактически в большинстве случаев таблица отображает сущность (Замечание: однако иногда сущность может быть представлена несколькими таблицами). Каждая строка отношения содержит описание одного объекта предметной области.
Каждое отношение характеризуется следующими понятиями:
- атрибут
- домен
- кортеж
- первичный ключ
- внешний ключ
Рис. 1.3 поясняет смысл всех характеристик отношения.

Рис. 1.3. Соотношение основных понятий реляционной модели данных
Атрибут – это именованный столбец отношения.
Атрибуты в отношении могут располагаться в любом порядке. Независимо от их переупорядочения отношение будет оставаться одним и тем же, а потому иметь тот же смысл.
Количество столбцов ограничивается конкретной СУБД. В современных СУБД количество столбцов примерно = 254.
Каждый атрибут характеризуется своим типом данных Понятие типа данных в реляционной модели данных полностью соответствует понятию типа данных в языках программирования.
Обычно в современных реляционных базах данных допускается хранение символьных, числовых данных (точных и приблизительных), специализированных числовых данных (таких, как «деньги»), а также специальных «темпоральных» данных (дата, время, временной интервал)
Кортеж – это строка отношения.
Кортежи могут располагаться в любом порядке, при этом отношение будет оставаться тем же самым, а значит иметь тот же смысл.
Иными словами, каждый кортеж отношения является неименованным.
Кортежи номеруются самой СУБД независимо от пользователя. Замечание: некоторые СУБД имеют специальное поле- счетчик, который служит для явной нумерации строк. Однако его использование в большинстве случаев нецелесообразно.
Количество кортежей в отношении не ограничивается и определяется только размерами внешней памяти.
Домен – это набор допустимых значений для одного или нескольких атрибутов.
| Атрибут | Имя домена | Содержимое домена | Определение домена |
| ФИО | АА | Множество всех ФИО | Символьный; Размер 32 |
Таб_ном_рук Табельныйномер |
T_H | Множество допустимых номеров | Цлочисленный; Размер 4; Диапазон 1- 5000 |
Каждый атрибут отношения определяется на некотором домене. Домены могут отличаться для каждого из атрибутов (т.е. для каждого атрибута может использоваться свой домен, как например, домен АА). Однако два или более атрибута могут определяться на одном и том же домене (как это показано для атрибутов Табельныйномер и Таб_ном_рук).
Фактически задание домена означает задание типа и размера, используемых данных, а также задание ограничений целостности этих данных.
Имя атрибута не обязательно должно совпадать с именем домена.
Домен создается оператором SQLCREATEDOMAIN и используется при создании отношений в операторе CREATETABLE.
Потенциальный ключ - атрибут или совокупность атрибутов, значение которого (которых) однозначно идентифицирует каждый кортеж отношения. Например,
| Таб_ном | ФИО | Паспортные данные |
Здесь имеется два потенциальных ключа Таб_ном и Паспортные данные.
Первичный ключ - это потенциальный ключ, который выбран для однозначной идентификации кортежей отношения. (т.е. в отношении может существовать несколько атрибутов, которые могут быть использованы в качестве первичного ключа).
В таблице Сотрудник в качестве первичного ключа выступает столбец табельный номер (каждое значение этого столбца уникально: не может повторяться).
Если первичный ключ состоит из нескольких атрибутов, он называется составным .
Товар
| ПРОДАВЕЦ | ПОКУПАТЕЛЬ | ТОВАР | ЦЕНА |
| А | А1 | Т1 | 50 |
| А | А1 | Т2 | 70 |
| В | А1 | Т1 | 60 |
| С | С1 | Т3 | 80 |
Для таблицы «Товар» в качестве первичного ключа может использоваться только комбинация из трех полей ПРОДАВЕЦ ПОКУПАТЕЛЬ ТОВАР ( значения каждой комбинации является уникальными).
Внешний ключ – это атрибут (или несколько атрибутов) внутри отношения, значения которого соответствуют значениям первичного ключа другого (родительского ) отношения. (рис. 1.2).
Отношение, содержащее внешний ключ называется дочерним .
Внешние ключи используются для обеспечения логической связи между отношениями.
В таблице «Сотрудник» в качестве внешнего ключа используется табельный номер руководителя. Зная этот номер, можно найти фамилию руководителя в таблице «Руководитель».
Поле внешнего ключа дочерней таблицы («таб_ном _рук») должно совпадать по типу с полем «табельный номер» в табл. «Руководитель» (хотя вовсе не обязательно, чтобы совпадали имена.
В родительской таблице это поле («таб_ном _рук») должно бать ключевым.
Анализируя все рассмотренные выше понятия, можно отметить следующие важные свойства отношений. В любом отношении
- не должно быть одинаковых кортежей;
- не требуется упорядочение кортежей;
- не требуется упорядочение атрибутов.
Альтернативные варианты терминов в реляционной модели
| Основные термины | Альтернативные термины 1 | Альтернативные термины 2 |
| Отношение | Таблица | Файл |
| Кортеж | Строка | Запись |
| Атрибут | Столбец | Поле |
1.4 Схемы баз данных
Схема – это общее описание всей БД, включающее перечень всех таблиц и связей между ними (рис. 1.4). Схема создается администратором БД и в дальнейшем используется системой в качестве метаданных.
Одной из основных характеристик связи является тип связи .
Тип определяет возможность связи записей одной таблицы
только с одним или несколькими другой таблицы.
В первом случая говорят о типе связи 1:1(один к одному), во втором 1:М (один ко многим). Направленная связь, имеющая в обоих направлениях тип 1:М, называется связью типа М:М(многие ко многим).
Примером связи типа 1:1 является связь между таблицами
Рис. 1.4 Схема БД
“Страна” и “Столица”. Действительно, каждая страна имеет только одну столицу. И наоборот, каждая столица принадлежит только одной стране.
Примером связи типа 1:М является связь между таблицами “Служащий” и “Профсоюз”. Каждый служащий принадлежит одному профсоюзу. И наоборот, каждый профсоюз объединяет много служащих.
Примером связи типа М:М является связь между таблицами “Товар” и “Заказ”. Каждый товар может входить в несколько заказов. С другой стороны, каждый заказ может включать в себя несколько товаров.
Лекция 3
1.5. Основные области внешней памяти
Обычно внешняя память логически делится на несколько областей, представленных на рис. При этом каждой области физически соответствует один или несколько файлов операционной системы (с точки зрения операционной системы БД – это просто один или несколько файлов, содержащих какую-то неизвестную для нее информацию).
Табличная область содержит таблицы и индексы. Системная область содержит информацию о самой системе и базе данных и, в частности , описание схемы базы данных. В журнальной области хранится информация, необходимая для восстановления базы данных в случае сбоя системы. Вспомогательная область, как правило, используется для временного (промежуточного) хранения самых различных данных (рис.1.5).

Рис. 1.5 Основные области внешней памяти
Далее рассматривается только табличная область.
На логическом уровне табличная область БД представляется как набор отдельных страниц.
Страница – это минимальная совокупность данных считываемая (записываемая) из внешней памяти за одно обращение. Размер страницы, как правило, равен размеру сектора диска 512 байт или кратен 512 байт, т.е. равен кластеру.
В табличной области содержатся только таблицы и индексы, каждый из которых может занимать от одной до нескольких страниц.
Причем данные на странице однородны. Т.е. в пределах одной страницы могут находиться таблицы или индексы (рис.1.6).

Рис. 1.6. Размещение таблиц и индексов на страницах
1.6. Хранение таблиц
Существуют 2 способа хранения
- по строкам
- по столбцам
Наиболее распространено горизонтальное хранение. Это обеспечивает более быстрый доступ, но в БД оказывается много дублированных значений в полях, что приводит к информационной избыточности. При вертикальном хранении избыточности нет, но время доступа резко возрастает, т.к. строку приходиться собирать из различных столбцов.
В дальнейшем будем предполагать, что используется именно горизонтальное хранение данных.
Все данные на страницах однородны, т.е. на каждой странице могут размещаться данные, принадлежащие или таблицам, или индексам (рис.1.7).
Записи фиксированной длины
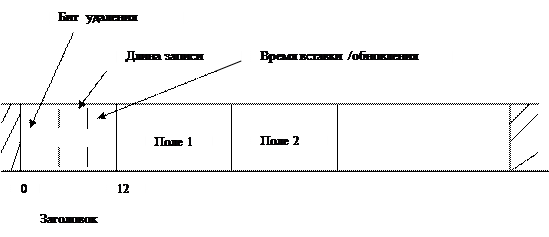
Рис. 1.7.Структура записи фиксированной длины
Заголовок записи содержит :
- бит удаления
- длину записи
- время последней вставки / обновления
-
Группирование записей фиксированной длины по страницам
 |
Рис 1.8. Хранение записей фиксированной длины на странице
Заголовок страницы может содержать:
1 cхему записи
2 таблицу размещения строк
3 таблицу размещения слотов
4 время последнего обновления страницы
Схема записи содержит количество полей типы полей и их размеры.
Таблицы размещения строк и слотов необходимы, т.к. строки (с данными) и слоты (свободные места) перемешаны между собой.
Хранение записей большого размера (типа DLOB )
 |
Рис.1.9. Распределение связанных записей по страницам
Заголовок каждого фрагмента содержит:
1 бит, указывающий, что данная порция данных является всей записью или только фрагментом.
2 биты, указывающие, что фрагмент первый, последующий или последний.
3 указатели на предыдущий и/или следующий фрагмент
4 время вставки/удаления
5 бит удаления
При организации доступа в БД диспетчер файлов и диспетчер буферов всегда работают на уровне страниц, т.е. обеспечивают чтение, удаление, добавление, обновление страниц.
Вставка строк (кортежей)
Для вставки отыскивается свободное место на любой странице (т.е. местоположение записей никак не упорядочивается.
Удаление
Физически запись со страницы никак не удаляется. Просто бит удаления в заголовке записи (или фрагмента) устанавливается в “1”.
Обновление по месту
Это самый простой случай модификации данных. При этом новая запись записывается на место старой.
Хранение мультимедийных данных
Когда в таблице содержится столбец, имеющий тип данных LОВ (largeobjects– большие объекты), тогда в каждой строке таблицы хранится лишь небольшой указатель на то место внешней памяти, где действительно хранятся данные этого типа.
Существуют различные типы LOB, служащие для хранения текстовой, графической и другой информации. Для примера отметим два из них: ВLОВ и BFILE, используемые в СУБД Oracle.
Все типы данных LOB можно разделить на две части:
- сохраняемые в базе данных ( к ним, в частности, относится BLOB)
- сохраняемые вне базы данных виде файла операционной системы( к ним, в частности, относится BFLE).
Принципы хранения данных типа LОВ и проиллюстрированы на рис. 1.10.
Рис. 1.10 показывает, что характеристики хранения полей LОВ независят от характеристик хранения базовой таблицы. Это упрощает процесс обращения к данным LОВ, занимающим обычно большие области диска. В этом примере все не-LОВ- и не-ВFILE - данные для каждой строки таблицы хранятся вместе в одной табличной области, данные столбца LОВ — в другой табличной области, а данные столбца ВFILE — в файловой системе сервера. При этом основные табличные и связанные с ними мультимедийные данные распределяются для хранения среди разных физических областей (например, дисководов), что снижает конкуренцию при доступе к диску и повышает общую производительность системы.

Рис. 1.10 Использование указателей для хранения мультимедийных
данных
Лекция 4
1.7. Управление буферами
Буфер – область оперативной памяти, используемая для кратковременного хранения данных, участвующих в процессе обмена между внешней и оперативной памятью. В процессе чтения /записи, с диска данные попадают в буфер и там некоторое время хранятся (рис. 2.6). Обычно размер буфера выбирается кратным размеру страницы.
Основное назначение буферов - синхронизация работы быстрой оперативной памяти с медленной внешней памятью. Необходимость такой синхронизации обусловлена тем, что время доступа к оперативной памяти меньше, чем к внешней.
Чем дольше данные хранятся в буфере, тем больше вероятность
того что данные, требуемые пользовательским запросом на чтение или модификацию, находятся не во внешней памяти , а в буфере. Следовательно, чем дольше данные будут храниться в буфере, тем выше будет производительность системы. Однако очень долго хранить данные в буферах нельзя. Так как если данные постоянно читаются, то затрачивается очень много оперативной памяти. А длительное хранение модифицированных данных снижает надежность системы, т.к. при отказе содержимое оперативной памяти может быть потеряно.
Поэтому число буферов и максимальное время нахождения данных в каждом буфере (время освобождения) выбирается на основе компромисса между производительностью и надежностью системы.
СУБД должна управлять буферами. Эта функция возлагается на диспетчер буферов. Диспетчер определяет, какой буфер должен заполняться, а какой освобождаться.
Каждая СУБД использует разные правила буферизации (освобождения буферов). Наиболее распространенными являются следующие 4 правила:
1. Чем реже используется буфер (т.е. страницы данных, находящиеся в буфере), тем быстрее он освобождается (правило LRU- lastrecentlyused).
2. Правило FIFO: первым пришел – первым вышел.
3. Превышение заданного порога времени. Если время хранения данных в буфере больше заданного времени, то буфер освобождается.
4. Правило принудительного сброса буферов, использованных активными транзакциями при проведении системной контрольной точки.(см. тему 4).
Рис. 1.11 поясняет процесс использования буферов прикладными программами. Когда прикладная программа обращается к СУБД с запросом записи данных (на языке SQL), то эти данные из рабочей области прикладной программы сначала попадают в буфер и некоторое время там хранятся. Затем диспетчер файлов отсылает данные буфера (в виде страницы) операционной системе, которая записывает их во внешнюю память.
При запросе на чтение данных процесс практически аналогичен: сначала диспетчер буферов ищет необходимые данные в одном из буферов и, если не находит, то из внешней памяти считывается страница, помещается в буфер, из буфера данные поступают в рабочую область.
 |
Рис. 1.11 Использование буферов прикладными программами
Следует отметить одну важную деталь: обмен данными между буферами и внешней памятью происходит на уровне страниц, а между буферами и рабочими областями – на уровне строк. То есть пользователь отсылает строки и получает строки.
1.8. Структура встроенного языка
Все современные СУБД имеют собственные языки программирования, называемые встроенными или базовыми. Так, СУБД Oracleиспользует язык PL/SQL, СУБД MSSQL– язык Transact-SQL, СУБД Paradox– язык PAL, СУБД Access– язык MicrosoftAccessBasic (MAB) и т.д.
Главная причина, по которой разные фирмы используют для своих СУБД разные языки, в основном связана с рекламой. Оправданием обычно служит стремление использовать язык, наиболее адаптированный к особенностям конкретной СУБД. Хотя последнее очень трудно доказуемо. На рис.1.12 показана типовая структура встроенного языка.
 |
Рис.1.12. Типовая структура встроенного языка
Результаты работы генераторов запросов и отчетов, редактора форм могут использоваться и в режиме диалога, и в режиме прикладных программ. Иными словами, пользователи могут работать с создаваемыми запросами, отчетами и формами в обоих режимах.
Генераторы запросов
Генераторы запросов предназначены для облегчения создания запросов к БД. Они строятся по принципу “Querybyexample” – создание запроса по образцу. Пользователю предоставляется бланк (бланк QBE), на котором он отмечает основные реквизиты запроса (рис.1.13).

Рис. 1.13.Запрос на бланке QBE
Из рис. видно, что на бланке отмечаются поля, данные из которых подлежат выборке, и задаются условия выборки.
Отметим, что от пользователя фактически не требуются знания языка SQL. При формировании запроса генератор автоматически создает запрос на SQL на основании реквизитов заполненной формы.
Результат исполнения запроса – выходной набор представляется пользователю в виде таблицы.
Основной слабостью генераторов запросов является то, что они позволяют создавать только сравнительно несложные запросы (в которых используются несложные вычислительные операции и задаются несложные условия отбора).
Редакторы форм
Редакторы форм служат для разработки экранных форм. Формы обеспечивают:
1. Удобный ввод и вывод информации
2. Размещение управляющих элементов (кнопок, меню, переключателей и т.д.)
3. Вывод справочной информации
Источниками выводимых данных являются таблицы или запросы ( точнее, выходные наборы ранее выполненных запросов).
Генераторы отчетов
Генераторы отчетов служат для создания выходных документов по БД – отчетов. Их характерной особенностью является наличие средств управления печатью. Источниками данных для отчетов являются таблицы и запросы.
Отчеты имеют некоторые общие черты и с запросами, и с формами. По своей сути отчет – это тот же запрос на выборку данных. Однако, как правило, это достаточно простая выборка, выполненная при простых условиях отбора. Иными словами, генераторы отчетов не позволяют задавать сложные условия отбора. Именно поэтому при формировании отчета часто используют выходные наборы запросов.
Другим важным аспектом, отличающим запросы от отчетов, является группировка записей.
Группировка в запросах направлена в первую очередь на обеспечение групповых операций (нахождение для группы значений минимума, максимума, среднего, суммы и т.д).
Группировка в отчетах ориентирована в первую очередь на удобное представление данных (выделение групп строк). При этом можно задать несколько уровней группировки. Каждый уровень группировки оформляется как самостоятельный отчет со своими разделами заголовка и примечаниями (только колонтитулы, по понятным причинам, являются общим для всего отчета). На рис.1.14 представлен отчет с группировкой строк по дате выписки товара.

Рис. 1.14 Отчет с группировкой строк
С формами отчеты часто объединяет общий принцип вывода данных. Однако вывод на формах ориентирован в первую очередь на экран, а не на бумагу.
Компиляторы встроенного языка
Компиляторы встроенного языка служат для преобразования операторов этого языка в машинные коды (как и для любого другого алгоритмического языка). Компиляторы используются только программистами на стадии разработки и отладки прикладных программ. Конечные пользователи их не используют.
Лекция 6
1.10. Описание таблиц на SQL
Описание таблиц выполняется с помощью оператора CREATETABLE.
Описание включает:
1. Задание имен столбцов таблицы и указание типов данных для этих столбцов
2. Задание первичного ключа таблицы
3. Задание внешнего ключа
Пункты 1 и 3 могут отсутствовать, если соответствующие ключи не задаются.
При наличии внешнего ключа дополнительно задаются ограничения ссылочной целостности:
ON DELETE {CASCADE| NO ACTION}
Если указано ключевое слово CASCADE, то при удалении строки из главной (родительской) таблицы соответствующие строки в зависимой (дочерней) таблице тоже будут удалены. При указании ключевого слова
NOACTION в подобном случае будет выдано сообщение об ошибке.
Пример.
Создать связанные таблицы, которые позволяют внешнему ключу EMPNO в таблице ABC создать ссылки на EMPNO в таблице EMP с правилом DELETECASCADE.
CREATE TABLE EMP
(EMPNO INT NOT NULL,
LNAME VARCHAR (15),
FNAME CHAR (10),
DEPTNO SMALLINT,
HIREDATE DATE,
JOB VARCHAR (15)),
PRIMARY KEY (EMPNO));
CREATE TABLE ABC
(EMPNO INT,
SALARY DECIMAL (9,2),
REVIEW LONG VARCHAR,
FOREIGN KEY (EMPNO) REFERENCES EMP
ON DELETE CASCADE);
Здесь первый оператор CREATETABLE описывает таблицу ЕМР с полями
EMPNO, LNAME, FNAME, DEPTNO, HIREDATE, JOB. В качестве первичного ключа используется поле EMPNO (при этом указано, что оно не может содержать неопределенные значения).
Второй оператор CREATETABLE описывает таблицу АВС с полями
EMPNO, SALARY, REVIEW. Первичный ключ не определен. Внешним ключом является поле EMPNO, значения которого ссылаются на соответствующие значения в таблице ЕМР. При удалении строк из родительской таблицы ЕМР осуществляется каскадное удаление строк из таблицы АВС.
1.11.Задание ограничений целостности: общих, доменов и семантики
Термин целостность используется для описания точности и корректности данных, хранящихся в БД. Иными словами, под целостностью подразумевается, что пользователям БД разрешается выполнять над ней некоторые действия и эти действия выполняются корректно [8].
Можно дать и другое определение: целостность означает защиту БД от некорректных действий санкционированного пользователя.
Для поддержки целостности СУБД должна содержать сведения о тех правилах, которые пользователю не следует нарушать при модификации БД (при выполнении операций UPDATE, DELETE, INSERT). Кроме того СУБД должна следить за выполнением заданных правил. Эти правила принято называть ограничениями целостности.
Кроме рассмотренных выше ограничений ссылочной целостности стандарт языка SQL поддерживает также ограничения домена, ограничения семантики и общие ограничения – «утверждения».
Домен – это набор допустимых значений для одного или нескольких атрибутов.
Каждый атрибут отношения определяется на некотором домене. Домены могут отличаться для каждого из атрибутов (т.е. для каждого атрибута может использоваться свой домен). Однако два или более атрибута могут определяться на одном и том же домене .
Фактически задание домена означает задание типа и размера, используемых данных, а также задание ограничений целостности этих данных.
Имя атрибута не обязательно должно совпадать с именем домена.
Пример домена представлен в разделе 1.3. Домен определяется оператором SQLCREATEDOMAIN.
Ограничения семантики
В основе ограничений семантики лежит проверка cемантического контекста данных. Например, если в столбце хранится процентное значение, то, очевидно, что это значение должно лежать в диапазоне от 0 до 100. Если в столбце хранится дата рождения, то эта дата не может превышать текущую дату и т.д.
Ограничения семантики для таблиц задаются с помощью предложения
CHECK (conditional-expression), вставляемого в оператор CREATETABLE (где conditional-expression определяет логическое условие, которое не может быть нарушено при модификации данных).
Пример .
CREATE TABLE EMP
(EMPNO INT NOT NULL,
LNAME VARCHAR (15),
FNAME CHAR (10),
DEPTNO SMALLINT,
HIREDATE DATE,
JOB VARCHAR (15),
PRIMARY KEY (EMPNO),
CHECK (HIREDATE <2009));
Здесь проверочное условие состоит в том, что столбец HIREDATEв таблице ЕМР (сотрудник) должен содержать значения меньшие, чем 2009 (текущий год).
Общие ограничения целостности по своей сути во многом аналогичны ограничениям семантики. Однако они предполагают наложение любых ограничений на данные. В основе таких ограничений лежит проверка логического выражения, которое возвращает значение TRUE (истина) либо значение FALSE (ложь). Если возвращается значение TRUE, то ограничение целостности выполняется и операция модификации данных разрешается. Когда же возвращается значение FALSE, то операция модификации отменяется.
Общие ограничения целостности задаются с помощью оператора CREATE ASSERTION.
Синтаксис оператора:
CREATEASSERTION имя CHECK (условное выражение);
Здесь в параметре имя задается имя правила, а в параметре условное выражение – соответствующее условие ограничения.
Пример .
CREATE ASSERTION ABC1 CHECK
(NOT EXISTS (SELECT * FROM P
WHERE NOT (P.WEIGHT>0)));
Здесь применительно к таблице Р выполняется проверка, что каждый товар имеет положительный вес.
Лекция 10
1.19. Проблема параллелизма
При одновременном исполнении нескольких транзакций (при параллельной работе) между ними могут возникать конфликты, приводящие к нарушению целостности БД.
Рассмотрим пример нарушения целостности БД двумя параллельно действующими транзакциями, представленный в табл. .
| Время | Операции транзакции А |
Операции транзакции В |
Результат |
| t1 | Читает запись i | 10 | |
| t2 | Читает запись i | 10 | |
| t3 | К записи iприбавляет число 10 | 20 |
|
| t4 | К записи iприбавляет число 15 | 25 |
В момент t1 транзакция А читает запись i, которая содержит число 10.
В момент t2 другая транзакция читает это же число. В момент t3 транзакция А модифицирует прочитанное число, прибавляя к нему число 10. В результате в БД оказывается число 20. Но в следующий момент транзакция В модифицирует прочитанное число, прибавляя к нему число 15. Таким образам, в записи i оказывается число 25. Это результат параллельной работы этих транзакций. Очевидно, что результат неправильный, т.к. две транзакции в сумме прибавили число 25. Значит, окончательным результатом должно было быть число 35, а не 25.
Фактически результат модификации, выполненной транзакцией А, пропал.
1.20. Блокирование информационных объектов базы данных
Все современные СУБД ориентированы на поддержку одновременной работы многих пользователей, а следовательно, на параллельную обработку транзакций. Для корректной обработки параллельных транзакций без возникновения конфликтных ситуаций необходимо использовать некоторыйметод управления параллелизмом. Основным методом управления параллелизмом является блокирование (альтернативными являются метод временных меток и оптимистичные технологии).
Его основная идея очень проста: в случае, когда для выполнения некоторой транзакции необходимо, чтобы некоторый объект базы данных (например, отдельный кортеж таблицы или вся таблица) не изменялся непредсказуемо и без ведома этой транзакции, такой объект блокируется. Таким образом, эффект блокирования состоит в том, чтобы "заблокировать доступ к этому объекту со стороны других транзакций", а значит, предотвратить непредсказуемое изменение этого объекта. Следовательно, первая транзакция в состоянии выполнить всю необходимую обработку с учетом того, что обрабатываемый объект остается в стабильном состоянии настолько долго, насколько это нужно.
Реально блокирование может быть выполнено посредством установки некоторого бита в соответствующем объекте, означающего, что этот объект базы данных является заблокированным. Второй подход состоит в организации списка заблокированных объектов. Существуют и другие способы реализации механизма блокирования.
Для пояснения идеи блокирования рассмотрим пример, приведенный на рис.1.18.
 |
Рис.1.18. Пример блокирования таблиц БД
В данном примере предполагается, что БД состоит из 3 таблиц (ТОВАР, ОТДЕЛЕНИЕ, ЗАКАЗ). Блокирование производится на уровне таблиц, т.е. сразу блокируется вся таблица (хотя на практике не обязательно блокируется вся таблица; в данном примере без потери общности это предположение делается для простоты рассмотрения). Кроме того предполагается, что параллельно исполняются две тразакции А и В. На рис. под названием каждой транзакции приводятся операторы SQL этой транзакции с условным обозначением времени выдачи этих операторов.
В момент времени 01 транзакция А обновляет таблицу ТОВАР. Таблица оказывается заблокированной.
В момент времени 03 выполняется вставка в таблицу ОТДЕЛЕНИЕ. В результате эта таблица также блокируется.
Затем делается вставка в таблицу ТОВАР. При этом таблица остается заблокированной.
В момент 09 транзакция А заканчивается выдачей оператора COMMIT и таблицы ТОВАР и ОТДЕЛЕНИЕ разблокируются.
Транзакция В в момент 02 обновляет таблицу ЗАКАЗ, вследствие чего эта таблица блокируется. В момент 04 делается попытка вставки в таблицу ОТДЕЛЕНИЕ, но ранее эта таблица заблокирована транзакцией А, поэтому транзакция В не получает к ней доступа и оказывается в состоянии ожидания . Транзакция В находится в состоянии ожидания до момента 09. когда транзакция А разблокирует таблицу ОТДЕЛЕНИЕ . Таблица разблокируется со стороны транзакции А но тут же блокируется со стороны транзакции В и транзакция В продлжает свою работу, т.е. исполняет оператор вставки. В момент 11 транзакция В завершается и разблокирует таблицы ОТДЕЛЕНИЕ и ЗАКАЗ.
Таким образом, захват таблицы одной из транзакций приводит к задержке другой (других) транзакции, если она обращается к той же таблице. Задержанная транзакция переходит в состояние ожидания. Причем она будет находиться в состоянии ожидания до тех пор, пока не будет снята блокировка, заданная другой транзакцией.
Полного параллелизма нет, однако, если транзакции работают с разными таблицами, то действительно работают в паралель. В нашем примере такая ситуация наблюдается до момента 04.
В начале данного раздела мы сделали допущение, что блокируюся все таблицы целиком. Блокируемые информационные объекты могут быть разными или, как иногда говорят, разным может быть уровень блокирования (степень дробления блокировок ):
1. блокирование всей БД.
2. блокирование отдельных таблиц БД.
3. блокирование набора кортежей ( страниц).
4. блокирование отдельных кортежей.
Теоретически могут блокироваться и отдельные поля в отдельных кортежах, однако на практике СУБД такую возможность не реализуют из-за больших накладных расходов на систему: она должна отслеживать обращения к огромному числу полей.
Очевидно, что чем меньше информационный объект по своим размерам, тем выше параллелизм в работе транзакций, так как вероятность конфликта между разными транзакциями уменьшается. Недостатком, как уже было отмечено, является рост накладных расходов системы.
Чаще всего блокирование выполняется на уровне отдельных кортежей.
Различают 2 типа блокировок:
1) блокировки без взаимного доступа ( Х-блокировки или монопольные блокировки, или блокировки записи),
2) блокировки с возможностью взаимного доступа (S-блокировки или разделяемые блокировки, или блокировки чтения).
Рассмотрим правила блокирования:
1. Если транзакция А блокирует некоторый кортеж p без возможности совместного доступа (Х-блокировка), то запрос другой транзакции В с блокировкой этого кортежа будет отменен. Т.е. транзакция В не сможет установить блокировку.
2. Если транзакция А блокирует кортеж p с возможностью взаимного доступа (S-блокировка), то возможны 2 случая:
А) запрос со стороны транзакции В на Х-блокировку этого же кортежа будет отвергнут;
Б) запрос со стороны транзакции В на S-блокировку этого же кортежа будет принят ( т.е. транзакция В сможет установить S-блокировку на кортеж p ).
В правилах указано, что в качестве "блокируемых объектов" используются кортежи, хотя еще раз подчеркнем, что могут быть и другие типы объектов.
Эти правила можно формально описать с помощью матрицы совместимости, представленной в табл. 1:
Матрица совместимости для Х- и S-блокировки Таблица 1
| X | S | - | |
| X | N | N | Y |
| S | N | Y | Y |
| - | Y | Y | Y |
Матрицу совместимости можно интерпретировать следующим образом. Рассмотрим некоторый кортеж р и предположим, что транзакция А блокирует кортеж р различными типами блокировки (это обозначено соответствующими символами S и X, а отсутствие блокировки — прочерком). Предположим также, что некоторая транзакция В запрашивает блокировку кортежа, что обозначено в первом слева столбце матрицы (для полноты картины, в таблице также приведен случай "отсутствия блокировки"). Вдругих ячейках матрицы символ N обозначает конфликтную ситуацию (запрос со стороны транзакции В не может быть удовлетворен, и сама эта транзакция переходит в состояние ожидания), aY — полную совместимость (запрос со стороны транзакции B удовлетворен).
Большинство современных СУБД устанавливает блокировки автоматически, т.е. неявным образом : например, запрос на "извлечение кортежа" является неявным запросом с S-блокировкой, а запрос на "обновление кортежа" — неявным запросом с Х-блокировкой соответствующего кортежа. При этом под термином "обновление" подразумеваются помимо самих операций обновления также операции вставки и удаления.
В большинстве случаев блокировки устанавливаются применительно к кортежам.
Но такой механизм неявного блокирования иногда может быть не удобен для пользователя и системы. Поэтому система может устанавливать блокировки и применительно к отдельным таблицам (например, в случае, когда таблица очень интенсивно используется какой то транзакцией), и применительно к отдельным страницам базы данных или ко всей базе данных.
Отметим что, наблюдается некоторый тонкий баланс между размером блокируемого информационного объекта и параллелизмом: чем мельче блокируемый информационный объект, тем выше параллелизм, чем крупнее блокируемый информационный объект, тем меньше параллелизм.
Некоторые СУБД обеспечивают возможность явного ( преднамеренного в полном смысле этого слова) задания блокировок с помощью разного рода операторов типа LOCK.
Например, оператор LOCK поддерживается системами DB2 и ORACLE. Однако следует иметь в виду, что этот оператор не является оператором языка SQL! Поэтому удобное в некотором смысле средство может быть серьезным орудием, понижающим эффективность разрабатываемой информационной системы (в случае, когда программисты злоупотребляют использованием указанного оператора).
Лекция 13
Тема 2 Интеграция данных
2.1. Хранилища данных
Концепция интеграции данных предусматривает использование содержимого двух или более баз данных с последующим конструированием одной крупной базы данных.
Исходная концепция интеграции данных была предложена специалистами фирмы IВМ в виде "информационного хранилища" и первоначально представлена ими как решение, обеспечивающее доступ к данным, накопленным в нереляционных системах. Предполагалось, что такое информационное хранилище позволит организациям использовать их архивы данных для эффективного решения производственных задач. Однако из-за чрезвычайной сложности и невысокой производительности подобных систем, созданных на начальных этапах, первые попытки создания информационных хранилищ в основном были отвергнуты. С тех пор к концепции хранилищ информации возвращались вновь и вновь, но только в последние годы потенциал технологии хранилищ данных стал рассматриваться как достаточно ценное и жизнеспособное решение.
Наиболее упорным и удачливым сторонником технологии хранилищ данных оказался Билл Инмон, который за активное продвижение этой концепции был удостоен почетного титула "отца — основателя хранилищ данных".
Хранилище - это предметно - ориентированный, интегрированный, привязанный ко времени и неизменяемый набор данных, предназначенный для поддержки принятия решений.
В приведенном выше определении Инмона указанные характеристики данных понимаются следующим образом.
• Предметная ориентированность. Хранилище данных организовано в виде специфических разделов, описывающих основные предметы (или субъекты) организации (например, клиенты, товары и продажи), а не прикладные области деятельности (выписка счета клиенту, контроль товарных запасов и продажа товаров).
Это свойство отражает необходимость хранения данных, предназначенных для поддержки принятия решений, а не обычных оперативно-прикладных данных.
• Интегрированность. Смысл этой характеристики состоит в том, что оперативно-прикладные данные обычно поступают из разных источников, которые часто имеют несогласованное представление одних и тех же данных, например, используют разный формат. Для предоставления пользователю единого обобщенного представления данных необходимо создать интегрированный источник, обеспечивающий согласованность хранимой информации.
• Привязка ко времени. Данные в хранилище точны и корректны только в том случае, когда они привязаны к некоторому моменту или промежутку времени,
Привязанность хранилища данных ко времени следует из большой длительности того периода, за который была накоплена сохраняемая в нем информация,
В отличие от операционных данных, привязанных к текущим транзакциям, хранилище данных представляет собой поток данных во времени.
Например, когда в хранилище данных обновляется информация об объеме продаж за предыдущую неделю, то обновляются еженедельные, ежемесячные, ежегодные и другие зависящие от времени агрегатные данные по продуктам, клиентам, магазинам и другим переменным.
После того как данные записаны в хранилище (т.е. выполнена операция вставки) они никогда из него не удаляются, оно постоянно растет. Кроме того эти данные не модифицируются (т.е. не выполняются операции типа Update).
Интегрирующая архитектура хранилища данных предусматривает извлечение (выгрузку) информации из нескольких источников и сочетание ее в рамках глобальной схемы хранилища, которое воспринимается пользователем как традиционная база данных.
На рис. 2.1 представлен пример интеграции данных на основе двух источников.

Рис.2.1 Организация хранилища данных
Компонент извлечения данных представляет собой программное средство самой разной сложности, созданное на любом алгоритмическом языке (в частном случае и на языке SQL) и предназначенное для извлечения данных из конкретного источника данных.
Компонент трансляции/загрузки данных – программное средство, обеспечивающее:
1) объединение (интеграцию) данных, извлеченных из разных источников,
2) преобразование форматов извлеченных данных в форматы, используемые хранилищем,
3) загрузку извлеченных интегрированных данных в хранилище в соответствии со схемой данного хранилища.
Способы трансляции и сочетания информации из первичных источников в общем случае могут быть самыми разными.
Как только информация загружена в хранилище данных, ее можно считывать совершенно так же, как и содержимое любых баз данных.
Существует три основных способа сбора информации в хранилище данных.
1.Содержимое хранилища периодически (скажем, еженощно) реконструируется на основе текущей информации источников — наиболее общий подход, основной недостаток которого зачастую связан с необходимостью "отключения" системы от внешнего мира на время выполнения процедуры трансляции/загрузки, нередко весьма продолжительной. Другой изъян заключается в том, что данные в хранилище быстро теряют актуальность.
2. В хранилище периодически заносятся данные из источников, претерпевшие изменения с момента осуществления последней загрузки.
Количество переносимых данных в этом случае, как правило, существенно ниже, что весьма важно, если время, отводимое на обновление информации, ограниченно и/или объем хранилища велик (обычной практикой является создание и поддержка хранилищ, размер которых исчисляется многими гигабайтами или даже терабайтами).
Недостаток подхода состоит в сложности процедуры инкрементного обновления в сравнении с прямолинейным алгоритмом полной загрузки данных.
3. Информация в хранилище обновляется непосредственно в ответ на операцию (или группу операций) модификации содержимого одного или нескольких источников.
Использование подобной стратегии предполагает интенсивный обмен данными и может оказаться оправданным, вероятно, только в тех ситуациях, когда размер хранилища невелик и частота операций изменения источников низка.
2.2. Медиаторы
Медиатор обеспечивает поддержку набора виртуальных таблиц, отображающих интегрированные данные из различных источников, — во многом так же, как хранилище данных, представляет материализованные отношения с обобщенной информацией из аналогичных источников. Однако медиатор сам по себе не сохраняет данные, поэтому механизм его действия существенно отличается от механизма хранилищ данных.
На рис.2.2 изображена схема интеграции информации двух источников средствами медиатора (как и в случае хранилищ данных, количество источников, разумеется, может быть произвольным).

Рис. 2.2 Организация медиатора
В ответ на запрос пользователя медиатор, не "владеющий" данными непосредственно, обязан получить информацию из подходящих источников, сформировать адекватный результат и передать его пользователю.
Как видно из рис.2.2, медиатор посылает запросы каждой из оболочек, а те в свою очередь адресуют их соответствующим источникам. (В определенных случаях медиатор способен направлять какой-либо оболочке целую серию запросов, а к некоторым другим оболочкам не обращаться вовсе.) Оболочка передает медиатору полученный ею итог обработки запроса, а медиатор, осуществляя объединение и трансляцию данных, возвращенных оболочками, формирует окончательный результат и отсылает его пользователю
Лекция 14
ТЕМА 3. К лиент-серверные системы
3.1. Основные понятия
Ранее мы отмечали, что с БД одновременно может работать много пользователей. Это достигается использованием технологии "клиент/сервер".
Архитектура клиент-сервер – это общее понятие вычислительной системы состоящей из 3-х частей: клиента, сервера и коммутационных средств.
Клиент- это часть системы требующая для своей работы предоставление некоторых сервисов (услуг).
Сервер – это часть системы, обслуживающая клиента, т.е. предоставляющая сервисы по запросам клиентов.
Коммутационные средства – программные и технические средства, обеспечивающие взаимодействие сервера с клиентами.
Основной принцип архитектуры клиент-сервер применительно к технологии баз данных заключается в разделении функций стандартного пользовательского приложения на 5 групп:
1 функции ввода-вывода и отображения данных
2 функции реализации прикладной задачи
3 функции обработки данных внутри прикладной задачи
4 функции управления базой данных
5 служебные функции
Состав типового приложения, работающего с БД, представлен на рис.3.1.
![]()
Рис.3.1. Состав типового приложения
1. Ввод-вывод и отображение предусматривает:
- формирование экранных изображений
- чтение и запись информации в экранные формы
- обработка движений мыши и нажатий клавиш и пр.
Для этого используются различные графические интерфейсы, например,
GUI, который поддерживается в разных операционных системах Windows,
OS/2 и др.
2. Реализация прикладной задачи означает реализацию алгоритма пользователя. Например, алгоритма банковской или инженерной задачи.
Обычно для такой реализации используются базовые или другие алгоритмические языки (Cи++, VisualBasic и др.).
3. Обработка данных внутри прикладной задачи предполагает использование запросов к БД на выборку или модификацию требуемых данных. Для этого используются операторы языка SQL.
4. Функции управления БД – это функции самой СУБД.
5. Служебные функции выполняют роль связок между первыми четырьмя функциями. Эти функции обеспечиваются промежуточным программным обеспечением (ППО).
Распределение указанных 5-ти функций между клиентами и сервером является основной задачей проектирования клиент-серверных систем.
В настоящее время нет какой-либо методики такого распределения.
Как правило, распределить 5 функций строго не удается: отдельные части какой-либо функции могут присутствовать и на клиенте и на сервере.
Далее будут рассмотрены наиболее распространенные модели реализации архитектуры “клиент-сервер”.
3.2 Модели клиент –сервер в архитектуре баз данных
Модель удаленного доступа к данным
![]() Клиент Сервер
Клиент Сервер
Рис.3.2. Модель удаленного доступа
Частично на сервере может присутствовать компонент обработки данных в виде хранимых процедур и триггеров, осуществляющих контроль данных.
Основное достоинство – унификация интерфейса: общение между клиентом и сервером основывается на языке SQL.
Недостаток: Разные клиенты могут выполнять одинаковые операции. Следовательно, с одной стороны, дублируется код клиентов, а с другой – сервер выполняет одинаковые операции.
Модель активного сервера БД
В модели активного сервера функции реализации прикладной задачи и обработки данных выполняются на сервере в виде хранимых процедур и в прикладной программе клиента .
Обработка данных выполняется операторами встроенного SQL.
В основном хранимыми процедурами реализуются общие задачи многих пользователей по контролю данных (рис. 3.3)..
Клиент Сервер
![]()
Рис.3.3. Модель активного сервера БД
К достоинству модели следует отнести то, что хранимые процедуры могут быть использованы разными клиентами. Это существенно уменьшает дублирование отдельных фрагментов прикладной программы.
Недостатком модели является большая загрузка сервера.
Модель сервера приложений
Данная трехзвенная модель находит В настоящее время все большее число поклонников находит трехзвенная модель сервера приложений (рис.3.4). Это обусловлено ее гибкостью
Клиент Сервер приложений Сервер БД
![]()
Рис.3.4. Модель сервера приложений
Общие части многих приложений различных пользователей (прежде всего это относится к задачам проверки целостности данных) реализуются на сервере приложений в виде хранимых процедур. Причем реализация общих задач может быть выполнена на любых алгоритмических языках.
К недостаткам модели следует отнести большие затраты на ее реализацию, обусловленные большей сложностью.
Кроме того эта модель менее надежная по сравнению с двухзвенной.
3.3. Промежуточное программное обеспечение
Клиенты и серверы в принципе могут располагаться на одном ПК.
Но более типично использование нескольких ПК, связанных сетью.
Для работы с сетью используются специальные промежуточные программные средства (иногда называемые коммуникационным программным обеспечением).
На рис.3.5 показано взаимодействие между компонентами ППО.
![]()
Рис.3.5. Взаимодействие между компонентами ППО
Клиент выдает запрос на SQL. ППО передает этот запрос в виде сообщения сетевым протоколам. При этом ППО форматирует это сообщение в соответствии с требованиями соответствующего протокола. На приемном конце ППО преобразует сообщение в запрос, понятный серверу.
Таким образом, ППО обычно включает в себя 3 компонента, показанные на рис.3.6:
-программныйинтерфейсприложения (Application Programming Interfase, API),
- транслятор запросов,
- сетевой транслятор.
![]()
Рис. 3.6. Компоненты ППО
Эти компоненты (или их функции) в основном распределяются по нескольким уровням программного обеспечения.
Программный интерфейс приложения (АР1) открыт для клиентского приложения. Программист взаимодействует с ППО через АРI, поставляемый вместе с ППО. API ППО позволяет программисту писать стандартный код SQL вместо кода, специфичного для данного сервера БД. Иначе говоря, АР1 обеспечивает независимость клиентского процесса от сервера БД. Такая независимость означает, что сервер можно заменить без необходимости переписывать клиентское приложение.
Транслятор запросов транслирует SQL-запросы в специфичный синтаксис сервера - БД. На уровне транслятора БД SQL-запрос отображается на SQL-протоколБД. Поскольку сервер базы данных может иметь какие-то специальные функциональные возможности, транслятор запросов к БД может оптимально транслировать основной SQL-запрос в специфичный формат, используемый на сервере БД. ЕслиSQL-запрос использует данные от двух различных серверов БД, то транслятор запросов берет на себя заботу о связи с каждым сервером и об извлечении данных в формате, подходящем для клиентского приложения.
Сетевой транслятор управляет сетевыми коммуникационными протоколами.
Напомним, что сервер может использовать любые сетевые протоколы. Поэтому если клиентское приложение подключается к двум базам данных, в одной из которых используется протокол TCP/IP, а в другой IPX/SPX , то сетевой транслятор обрабатывает все детали связи каждой базы данных прозрачно для клиентского приложения.