| Скачать .docx |
Реферат: Основные элементы языка С алфавит языка, идентификаторы, константы. Использование комментари
1.Основные элементы языка С++: алфавит языка, идентификаторы, константы. Использование комментариев в тексте программы.
Константами наз. перечисления величин в программе. Разделяют 4 типа констант.
Идентификатор-последовательность цифр и букв, а так же специальных символов, при условии.
При создании программ вы можете поместить в исходном файле замечания, которые объясняют работу программы. Такие замечания (называемые комментариями) не только помогают другим программистам понять вашу программу, но могут напомнить, почему программа содержит определенные операторы, если вы ее посмотрите через несколько месяцев.
Когда компилятор C++ встречает двойной слеш, он игнорирует весь оставшийся на этой строке текст.
Комментарий справа от оператора присваивания обеспечивает дополнительную информацию всем, кто читает программу.
2. Основные типы данных языка С++.
Типы данных определяет
-внутреннее представление данных в памяти компьютера;
-множество значений, которые можно применять к величинам этого типа.
-операции и функции, которые можно применять к величинам этого типа.
| Тип |
Размер в байтах (битах) |
Интервал изменения |
| char |
1 (8) |
от -128 до 127 |
| unsigned char |
1 (8) |
от 0 до 255 |
| signed char |
1 (8) |
от -128 до 127 |
| int |
2 (16) |
от -32768 до 32767 |
| unsigned int |
2 (16) |
от 0 до 65535 |
| signed int |
2 (16) |
от -32768 до 32767 |
| short int |
2 (16) |
от -32768 до 32767 |
| unsigned short int |
2 (16) |
от 0 до 65535 |
| signed short int |
2 (16) |
от -32768 до 32767 |
| long int |
4 (32) |
от -2147483648 до 2147483647 |
| unsigned long int |
4 (32) |
от 0 до 4294967295 |
| signed long int |
4 (32) |
от -2147483648 до 2147483647 |
| float |
4 (32) |
от 3.4Е-38 до 3.4Е+38 |
| double |
8 (64) |
от 1.7Е-308 до 1.7Е+308 |
| long double |
10 (80) |
от 3.4Е-4932 до 3.4Е+4932 |
3. Структура программы на языке С++.
С++ - программа должна состоять из одной или нескольких подпрограмм, но одна из них должна иметь опознавательный знак, определяющий ее как главную, с которой начнется выполнение всей программы в целом и на которой это выполнение завершится в случае благополучного исхода. Таким опознавательным знаком в С++ является фиксированное имя главной подпрограммы (функции) - «main» (в С++ все подпрограммы называются функциями и других типов подпрограмм язык не поддерживает). Обычно с нее и начинают составление программы.
Синтаксис определения любой функции в Си++ требует записывать слева направо:
тип_возвращаемого_функцией_значения
имя_функции(Список типов и имен аргументов)
скобки после имени обязательны - именно по ним компилятор распознает функцию.
Аргументы разделяются запятыми, если они не нужны, то в скобках пишется void {......} - пара обязательных фигурных скобок обозначает границы тела функции, а самим телом являются операторы определения локальных данных, операции над данными, вызовы вспомогательных функций и пр.
Таким образом, ничего не делающая и ничего не возвращающая главная функция в С++ выглядит так:
void main(void) {}
Возвращаемое главной функцией значение - это значение, возвращаемое всей программой в вызвавшую программу - предок и оно может быть однобайтовым целым числом в диапазоне 0-255 по абсолютному значению. return a; или return(a*b - c);
4. Директивы препроцессора : #include, #define, #undef
Прежде чем приступить к компиляции программы, компилятор C++ запускает специальную программу, которая называется препроцессором. Препроцессор ищет в программе строки, начинающиеся с символа #, например #include или #define. Если препроцессор, например, встречает директиву #include, он включает указанный в ней файл в ваш исходный файл, как будто бы вы сами печатали содержимое включаемого файла в вашем исходном коде. Каждая программа, которую вы создали при изучении данной книги, использовала директиву #include, чтобы заставить препроцессор включить содержимое заголовочного файла iostream.h в ваш исходный файл. Если препроцессор встречает директиву #define, он создает именованную константу или макрокоманду. В дальнейшем, если препроцессор встречает имя константы или макрокоманды, он заменяет это имя значением, указанным в директиве #define.
5. Основные операции языка С++: арифметические, логические, отрицания. Примеры.
ЛОГИЧЕСКИЕ ОПЕРАЦИИ И (&&) , ИЛИ (||) и НЕ (!) едины для всех языков программирования и соответствуют логическим функциям И, ИЛИ и НЕ для логических (булевых) переменных. Операция И имеет результатом значение "истина" тогда и только тогда, когда оба ее операнда истинны, то есть по отношению к операндам -утверждениям звучит как "одновременно оба". Операция ИЛИ имеет результатом значение "истина", когда хотя бы один из операндов истинен, то есть характеризуется фразой "хотя бы один":
if (a < b && b < c) // если ОДНОВРЕМЕННО ОБА a < b и b < c, то...
if (a==0 || b > 0) // если ХОТЯ БЫ ОДИН a==0 или b > 0, то...
Логические операции И и ИЛИ имеют еще одно свойство. Если в операции И первый операнд имеет значение "ложь", а в операции ИЛИ -"истина", то вычисление выражения прекращается, потому что значение его уже становится известным ("ложь" -для И , "истина" -для ИЛИ ). Поэтому возможны выражения, где в первом операнде операции И проверяется корректность некоторой переменной, а во втором -она же используется с учетом этой корректности:
if (a >=0 && sin(sqrt(a)) >0) ...
В данном примере второй операнд, включающий в себя функцию вычисления квадратного корня, не вычисляется, если первый операнд -"ложь".
Особо следует отметить операцию логической инверсии (отрицания) -"!" . Значение "истина" она превращает в "ложь" и наоборот. Если считать значением "истина" любое ненулевое значение целой переменной, то эту операцию для целых следует понимать как проверку на 0:
while(!k) {...} // эквивалентно while(k==0) {...}
ВЫВОД: Логические операции отношения задаются следующими символами (см. табл. 2): && ("И"), || ("ИЛИ"), ! ("НЕ"), >, >=, <, <= , = = (равно), != (не равно). Традиционно эти операции должны давать одно из двух значений: истину или ложь. В языке Си принято следующее правило: истина - это любое ненулевое значение; ложь - это нулевое значение. Выражения, использующие логические операции и операции отношения, возвращают 0 для ложного значения и 1 для истинного. Ниже приводится таблица истинности для логических операций.
Основные математические операции С++
| Операция |
Назначение |
Пример |
| + |
Сложение |
total = cost + tax; |
| - |
Вычитание |
change = payment - total; |
| *. |
Умножение |
tax = cost * tax_rate; |
| / |
Деление |
average = total / count; |
6. Основные операции языка С++: взятие адреса и разадресации, определения размера, сдвига. Примеры.
| << |
Сдвиг влево |
|||
| >> |
Сдвиг вправо |
|||
| & |
Взятие адреса |
|||
| * |
Обращение по адресу |
|||
| sizeof( ) |
Определение размера в байтах |
|||
| char |
1 (8) |
от -128 до 127 |
||
| unsigned char |
1 (8) |
от 0 до 255 |
||
| signed char |
1 (8) |
от -128 до 127 |
||
| int |
2 (16) |
от -32768 до 32767 |
||
7. Основные операции языка С++: поразрядные операции, условная операция, преобразование типов. Пример.
1. Преобразование типов.
Если в выражении появляются операнды различных типов, то они преобразуются к некоторому общему типу, при этом к каждому арифметическому операнду применяется такая последовательность правил:
1. Если один из операндов в выражении имеет тип long double, то остальные тоже преобразуются к типу long double.
2. В противном случае, если один из операндов в выражении имеет тип double, то остальные тоже преобразуются к типу double.
7. В противном случае все операнды преобразуются к типу int. При этом тип char преобразуется в int со знаком; тип unsigned char в int, у которого старший байт всегда нулевой; тип signed char в int, у которого в знаковый разряд передается знак из сhar; тип short в int (знаковый или беззнаковый).
Предположим, что вычислено значение некоторого выражения в правой части оператора присваивания. В левой части оператора присваивания записана некоторая переменная, причем ее тип отличается от типа результата в правой части.
| ?: |
Условная (тернарная) операция |
| & |
Поразрядное логическое "И" |
| ^ |
Поразрядное исключающее "ИЛИ" |
| | |
Поразрядное логическое "ИЛИ" |
8. Основные операции языка С++: операторы инкремента и декремента, простое и составное присваивание. Примеры.
-обычное присваивание (=);
-присваивание, соединенное с одной их бинарных операций (+=, -=, *=, /=, %=, <<=, >>=, &=, |=, ^=);
-операции инкремента и декремента (увеличения и уменьшения на 1).
Операция присваивания "=" сохраняет значение выражения, стоящего в левой части, в переменной, а точнее, в адресном выражении, стоящем а правой части. При выполнении операции присваивания тип выражения в правой части преобразуется к типу адресного выражения в левой. Результатом операции является значение левой части после присваивания, соответственно, тип результата -это тип левой части.
Обычное присваивание: long a; char b; int c;
a = b = c; // эквивалентно b = c; a = b;
В данном случае при первом (правом) присваивании тип int преобразуется к char, а результатом операции является значение переменной b типа char после выполнения этого присваивания.
Операция присваивания, соединенная с одной из бинарных операций, -это частный случай, когда результат бинарной операции сохраняется (присваивается) в первом операнде:
a +=b; // эквивалентно a = a + b;
Приведенный выше эквивалент этой операции верен лишь в первом приближении, потому что в этих операциях левый операнд, если он является адресным выражением, вычисляется один, а не два раза. Следующий пример показывает это:
A[i++] +=b; // эквивалентно A[i] = A[i] + b; i++;
Операции инкремента и декремента увеличивают или уменьшают значение единственного операнда до или после использования его значения в выражении:
int a; // Эквивалент Интерпретация
a++; // Rez=a; a=a+1; Увеличить на 1 после использования
++a; // a=a+1; Rez=a; Увеличить на 1 до использования
a--; // Rez=a; a=a-1; Уменьшить на 1 после использования
--a; // a=a-1; Rez=a; Уменьшить на 1 до использования
9. Условные операторы языка С++. Примеры.
Условный оператор позволяет выполнить один из входящих в его состав операторов в зависимости от выполнения какого-либо условия. Оператор IF определяет, что тот или иной оператор должен выполняться в том случае, если справедливо заданное условие, т.е. выражение принимает значение true (истина). Если условие не выполняется, то выполняется оператор, следующий за служебным словом else (иначе).
Существует полная и краткая форма оператора. Полная форма условного оператора IF имеет следующий вид:
if ( условие ) {
Оператор 1;
...
Оператор N;
}
еlse {
Оператор N+1;
...
Оператор N+M;
} ;
где IF – в переводе с англ. «если», <условие> - некоторое логическое выражение, ELSE – «иначе».
Если условие истинно, то выполняются операторы с 1 по N. Если условие ложно, то выполняются операторы с N+1 до N+M.
10. Операторы цикла языка С++. Примеры.
Оператор цикла while называется циклом с предусловием и имеет следующий формат: while ( выражение )
оператор;
Схема выполнения оператора while следующая:
1. Вычисляется выражение.
2. Если выражение равно нулю, то выполнение оператора while заканчивается и выполняется следующий по порядку оператор. Если выражение не равно нулю, то выполняется оператор в цикле while.
3. Процесс повторяется с пункта 1.
В операторе while проверка условия происходит вначале, перед выполнением операторов, образующих тело цикла. Оператор while удобно использовать в ситуациях, когда цикл не всегда должен выполняться. При построении цикла while необходимо включить в тело цикла какие-либо конструкции, изменяющие величину проверяемого выражения так, чтобы в конце концов оно стало равным нулю. В противном случае цикл будет бесконечным.
Пример
int i , s ;
i=2;
while(i < 5) {
printf ( "Добрый день!");} /* цикл будет выполняться бесконечно*/
int i , s ;
i=2;
while(i < 5) {
printf( " Добрый день !");
i = i +1; } /* цикл будет выполнен 3 раза*/
Оператор с постусловием do…while
Оператор цикла do while называется оператором цикла с постусловием и используется в тех случаях, когда необходимо выполнить операторы, образующие тело цикла, хотя бы один раз. Формат оператора имеет следующий вид:
do оператор
while ( выражение );
Схема выполнения оператора do while:
1. Выполняется тело цикла (которое может быть составным оператором).
2. Вычисляется выражение.
3. Если выражение равно нулю, то выполнение оператора do while заканчивается и выполняется следующий оператор по порядку за оператором цикла. Если выражение не равно нулю, то выполнение оператора цикла do while продолжается с пункта 1.
Чтобы прервать выполнение цикла до того, как условие станет ложным, можно использовать оператор break. Операторы while и do while могут быть вложенными.
Пример
int i , j , k , s ;
j=0;
k=0;
s=0;
do { i=0;
while ( i < 5) { k++; i++; }
s=s+k+i-j;
j--; }
while ( j < -10);
Цикл for
Оператор цикла for - это наиболее общий способ организации цикла. Он имеет следующий формат:
for ( выражение_1 ; выражение_2 ; выражение_3 ) оператор;
Выражение 1 - выражение инициализации. Выражение 2 - это выражение, определяющее условие, при котором тело цикла будет выполняться. Выражение 3 - выражение итерации, определяет изменение переменных, управляющих циклом после каждого выполнения тела цикла.
Схема выполнения оператора for:
1. Вычисляется выражение 1.
2. Вычисляется выражение 2.
3. Если значение выражения 2 отлично от нуля, выполняется тело цикла, вычисляется выражение 3 и осуществляется переход к пункту 2. Если значение выражения 2 равно нулю, то управление передается на оператор, следующий за оператором for.
Важно отметить, что проверка условия выполняется в начале цикла. Это значит, что тело цикла может ни разу не выполниться, если выражение 2 при входе в цикл будет равно нулю.
Пример
void main() {
int i, b;
for ( i=1; i<10; i++ )
{ b=i*i;
printf ( "\ n %2 d в квадрате = %3 d ", i b ); }}
Оператор continue
Оператор continue используется только внутри операторов цикла. Данный оператор передает управление на оператор продолжения цикла, при этом все операторы, следующие за continue, пропускаются. Формат оператора следующий:
continue ;
Пример
void main() {
int a, s;
for ( a =1; a <100; a ++)
{ if ( a %2 ) continue ; /* если остаток от деления не равен 0 */
/* то оператор s = s + a пропускается */
s = s + a ; }}
В примере суммируются только четные числа в интервале от 1 до 100 .
11. Операторы перехода языка С++. Примеры.
12.Операторы языка С++: оператор выражения, пустой оператор, составной оператор, операторы потокового ввода-вывода. Дополнительные возможности потокового ввода-вывода. Управление точностью значений с плавающей точкой. Примеры.
При выполнении условной обработки в некоторых случаях программе необходимо выполнить только один оператор (простой оператор), если условие истинно. Однако в других случаях программа должна будет выполнить несколько операторов (составной оператор). Если в зависимости от результата определенного условия вашей программе нужно выполнить два или несколько связанных операторов, вы должны сгруппировать операторы внутри левой и правой фигурных скобок, как показано ниже:
if (age >= 21)
{
cout << "Все на выборы!" << endl;
cout << "Это то, что вам надо!" << endl;
}
Управление цифрами значений с плавающей точкой
Если вы используете cout для вывода значения с плавающей точкой, то обычно не можете сделать каких-либо предположений о том, сколько цифр будет выводить cout no умолчанию. Однако, используя манипулятор setprecision, вы можете указать количество требуемых цифр- Следующая программа использует манипулятор setprecision для управления количеством цифр, которые появятся справа от десятичной точки:
#include <iostream.h>
#include <iomanip.h>
void main(void)
{
float value = 1.23456;
int i;
for (i = 1; i < 6; i++) cout << setprecision(i) << value << endl;
}
1.2
1.23
1.235
1.2346
1.23456
Если вы используете манипулятор setprecision для изменения точности, ваша установка действует до тех пор, пока программа повторно не использует setprecision.
Точно так же, как cout предоставляет функцию cout.put для вывода символа, cin предоставляет функцию cin.get, которая позволяет вам читать один символ данных. Чтобы воспользоваться функцией cin.get, вы просто присваиваете переменной возвращаемый этой функцией символ, как показано ниже:
letter = cin.get();
Как вы уже знаете, при использовании cin для выполнения ввода с клавиатуры, cin использует пустые символы, такие как пробел, табуляция или возврат каретки, для определения, где заканчивается одно значение и начинается другое. Во многих случаях вы захотите, чтобы ваши программы считывали целую строку данных в символьную строку. Для этого программы могут использовать функцию cin.getline. Для использования cin.getline вам необходимо указать символьную строку, в которую будут помещаться символы, а также размер строки, как показано ниже:
cin.getline(string, 64);
Когда cin.get читает символы с клавиатуры, она не будет читать символов больше, чем может вместить строка. Удобным способом определить размер массива является использование оператора C++ sizeof, как показано ниже:
сin.getline(string, sizeof(string));
Если позже вы измените размер массива, то вам не нужно будет искать и изменять каждый оператор с cin.get, встречающийся в вашей программе. Вместо этого оператор sizeof ' будет использовать корректный размер массива.
Чтение ввода с клавиатуры с помощью cin
Для чтения ввода с клавиатуры программы могут использовать входной поток cin. При использовании cin вы должны указать переменную, в которую cin помещает данные. Затем используйте оператор извлечения (>>) для направления данных, как показано ниже:
cin >> some_variable;
Вы уже знаете, что программы на C++ используют выходной поток cout для вывода сообщений на экран. При использовании cout для вывода сообщений представляйте cout в виде потока символов, которые операционная система отображает на экране. Другими словами, порядок, в котором ваша программа посылает символы в cout, определяет порядок символов, которые будут появляться на экране. Например, для следующих операторов программы:
cout << "Это сообщение появляется первым,";
cout << " а за ним следует настоящее сообщение.";
Операционная система выводит поток символов следующим образом:
Это сообщение появляется первым, а за ним следует настоящее сообщение.
Оператор вставки (<<) называется так, потому что позволяет вашей программе вставлять символы в выходной поток.
13. Организация форматированного ввода-вывода в языке С++.
14. Общее понятие одномерных массивов данных. Описание одномерных массивов на языке С++.
Массив представляет собой последовательность элементов одного типа. Каждому элементу массива соответствует индекс - целое неотрицательное число, определяющее его номер в последовательности. Первому элементу массива соответствует индекс 0.
Массивы, элементы которых однозначно определяются одним индексом, называются одномерными . В виде одномерного массива можно представить, например, список фамилий студентов одной группы, где каждый студент однозначно определяется своим порядковым номером в списке. Определение одномерного массива имеет вид:
<тип элементов массива> <имя массива> [<количество элементов в массиве>];.
В C++ можно определить массив любого типа.
int mas[3]; - описан массив из 3 целых чисел.Нумерация в массивах начинается с 0-го элемента. Поэтому массив mas содежит: mas[0], mas[1], mas[2].
15. Типовые алгоритмы обработки одномерных массивов данных на языке С++.
Нахождение суммы элементов массива
Для нахождения суммы элементов массива используется следующий алгоритм. Сначала предполагается, что значение искомой суммы равно нулю. Далее на каждом шаге цикла проводится накопление данной суммы путем добавления к уже имеющемуся значению суммы значения очередного элемента массива. Если суммирование проводится не по всем элементам массива, то в программу добавляется условный оператор проверки выполнения наложенного на элементы массива условия.
Поиск данных в массивах
Поиск информации, удовлетворяющей определенным условиям, является одной из наиболее распространенных задач обработки массивов. В частности, к данному классу задач можно отнести поиск наибольших и наименьших элементов массива, поиск элементов, удовлетворяющих разнообразным операциям отношений (больших заданного числа, равных ему и т.д.) и другие.
16. Методы сортировки массивов.
Сортировкой массива называют упорядочение его элементов в соответствии с определенными правилами (как правило, по возрастанию или убыванию элементов).
Алгоритм линейной сортировки массивов по возрастанию заключается в следующем. Сначала первый элемент массива сравнивается по очереди со всеми оставшимися элементами. Если очередной элемент массива меньше по величине, чем первый, то эти элементы переставляются местами. Сравнение продолжается далее уже для обновленного первого элемента, в результате чего будет найден и установлен на первое место самый наименьший элемент массива. Далее продолжается аналогичный процесс уже для оставшихся элементов массива, т.е. второй элемент сравнивается со всеми остальными и, при необходимости, переставляется с ними местами. Алгоритм завершается, когда сравниваются и упорядочиваются предпоследний и последний из оставшихся элементов массива.
Особенностью сортировки методом «пузырька» является не сравнение каждого элемента со всеми, а сравнение в парах соседних элементов. Данный алгоритм состоит в последовательных просмотрах от начала к концу элементов массива. Если для пары соседних элементов выполняется условие, что элемент справа больше элемента слева, то производится обмен значениями этих элементов, т.е. в процессе выполнения алгоритма постепенно «всплывают» более «легкие» элементы массива.
Метод Шелла- многопроходная сортировка, список разбивается на подсписок.
Метод корневой сортировки- разбивается на стопки и при каждом проходе используется отдельная часть ключа.
17. Общее понятие многомерных массивов данных. Описание матриц на языке С++.
Многомерные массивы - это массивы с более чем одним индексом. Многомерный массив представляет собой массив массивов, то есть массив, элементами которого служат массивы. Определение многомерного массива в общем случае должно содержать сведения о типе, размерности и количествах элементов каждой размерности. Чаще всего используются двумерные массивы. При описании многомерного массива необходимо указать C++, что массив имеет более чем одно измерение.
int t[3][4]; - описывается двумерный массив, из 3 строк и 4 столбцов.Элементы массива:
t[0][0] t[0][1] t[0][2] t[0][3]t[1][0] t[1][1] t[1][2] t[1][3]t[2][0] t[2][1] t[2][2] t[2][3]При выполнении этой команды под массив резервируется место. Элементы массива располагаются в памяти один за другим:
Если число строк двумерного массива равняется числу столбцов, то матрицы данного типа называются квадратными . Элементы квадратной матрицы вида B[1,1], B[2,2], B[3,3]… составляют главную диагональ .
int temp [3] [15] [10]; - резервируется место под 3-х мерный массив.В памяти многомерные массивы представляются как одномерный массив, каждый из элементов которого, в свою очередь, представляет собой массив. Рассмотрим на примере двумерного массива: int a[3][2]={4, l, 5,7,2, 9} как он представляется в памяти:
| a[0][0] |
заносится значение 4 |
| a[0][1] |
заносится значение 1 |
| a[1][0] |
заносится значение 5 |
| a[1][1] |
заносится значение 7 |
| a[2][0] |
заносится значение 2 |
| a[2][1] |
заносится значение 9 |
Второй способ инициализации при описании массива
int а[3][2]={ {4,1}, {5, 7}, {2, 9} };Обращение к элементу массива производится через индексы.
cout << а[0][0]; - выдаст значение 4. cout << a[1][1]; - выдаст знaчение 7.18.Указатели. Способы инициализации указателя. Операторы выделения и освобождения памяти. Операции с указателями.
В языке C++ для создания и обработки массивов обычно используют указатели. Указатель - это переменная, содержащая адрес другой переменной или, говоря другими словами, указатель - символическое представление адреса.
В С++ указатели могут быть на любой тип данных. Значением объекта типа указатель является целое неотрицательное число, равное адресу того программного объекта (переменной, функции, массива и т.д.), на который ссылается указатель.
Если необходимо, можно описать массив указателей:
int *ip[ 10 ]; - массив указателей на целые значения из 10 элементов.Напомним, что в данном контексте символ "*" является символом унарной операции косвенной адресации. Унарная операция * рассматривает свой операнд как адрес объекта и обращается по этому адресу, чтобы извлечь его содержимое.
С указателем можно производить некоторые арифметические операции. Например, пусть sub содержит номер элемента массива, тогда до этого элемента можно "добраться" следующим образом:
mas [ sub ] или *(mas +sub)Таким образом имя массива фактически является указателем на нулевой элемент массива. Переменная sub указывает на сколько элементов необходимо сместиться. Вы можете инкрементировать и декрементировать указатель. При этом вы смещаетесь на один элемент, независимо от типа элемента.
Допустим uk - адрес нулевого элемента массива, тогда
cout<<*uk; // вывод значения 0-го элемента uk++; cout<<*uk; // вывод значения 1-го элемента, реально смещение на несколько байтов uk+=2 cout<<*uk; // вывод значения 3-го элемента. 19.Ссылки. Указатели и ссылки.Чтобы упростить процесс изменения параметров, С++ вводит такое понятие как ссылка. Ссылка представляет собой псевдоним (или второе имя), который ваши программы могут использовать для обращения к переменной.Ссылка C++ позволяет создать псевдоним (или второе имя) для переменных в вашей программе. Для объявления ссылки внутри программы : int & alias_name = variable; //---> Объявление ссылки
После объявления ссылки ваша программа может использовать или переменную, или ссылку:
alias_name = 1001;
variable = 1001;
Основное назначение ссылки заключается в упрощении процесса изменения параметров внутри функции.
ПРАВИЛА РАБОТЫ СО ССЫЛКАМИ
Ссылка не является переменной. Один раз присвоив значение ссылке, вы уже не можете ее изменить. Кроме того в отличие от указателей вы не можете выполнить следующие операции над ссылками:
• Вы не можете получить адрес ссылки, используя оператор адреса C++.
• Вы не можете присвоить ссылке указатель.
• Вы не можете сравнить значения ссылок, используя операторы сравнения C++.
• Вы не можете выполнить арифметические операции над ссылкой, например добавить смещение.
•Вы не можете изменить ссылку.
20. Связь указателей и массивов в языке С++. Доступ к элементам массива через указатели. Массивы указателей.
В языке C++ для создания и обработки массивов обычно используют указатели.
int *ip[ 10 ]; - массив указателей на целые значения из 10 элементов. Напомним, что в данном контексте символ "*" является символом унарной операции косвенной адресации. Унарная операция * рассматривает свой операнд как адрес объекта и обращается по этому адресу, чтобы извлечь его содержимое.
Приведем пример описания массива:
int (*a)[15];
Описан указатель на массив, содержащий 15 целых значений. Круглые скобки здесь необходимы, поскольку скобки [] имеют более высокий уровень старшинства, чем операция *.
С указателем можно производить некоторые арифметические операции. Например, пусть sub содержит номер элемента массива, тогда до этого элемента можно "добраться" следующим образом:
mas [ sub ] или *(mas +sub)Таким образом имя массива фактически является указателем на нулевой элемент массива. Переменная sub указывает на сколько элементов необходимо сместиться. Вы можете инкрементировать и декрементировать указатель. При этом вы смещаетесь на один элемент, независимо от типа элемента.
Допустим uk - адрес нулевого элемента массива, тогда
cout<<*uk; // вывод значения 0-го элемента uk++; cout<<*uk; // вывод значения 1-го элемента, реально смещение на несколько байтов uk+=2 cout<<*uk; // вывод значения 3-го элемента.21. Типовые алгоритмы обработки двумерных массивов данных на языке С++.
Нахождение суммы элементов массива
Для нахождения суммы элементов массива используется следующий алгоритм. Сначала предполагается, что значение искомой суммы равно нулю. Далее на каждом шаге цикла проводится накопление данной суммы путем добавления к уже имеющемуся значению суммы значения очередного элемента массива. Если суммирование проводится не по всем элементам массива, то в программу добавляется условный оператор проверки выполнения наложенного на элементы массива условия.
Поиск данных в массивах
Поиск информации, удовлетворяющей определенным условиям, является одной из наиболее распространенных задач обработки массивов. В частности, к данному классу задач можно отнести поиск наибольших и наименьших элементов массива, поиск элементов, удовлетворяющих разнообразным операциям отношений (больших заданного числа, равных ему и т.д.) и другие.
22. Общее понятие о подпрограммах. Описание функций на языке С++.
Функция - это совокупность объявлений и операторов, обычно предназначенная для решения определенной задачи. Каждая функция должна иметь имя, которое используется для ее объявления, определения и вызова. В любой программе на С++ должна быть функция с именем main (главная функция), именно с этой функции, в каком бы месте программы она не находилась, начинается выполнение программы.
При вызове функции ей при помощи аргументов (формальных параметров ) могут быть переданы некоторые значения (фактические параметры ), используемые во время выполнения функции. Функция может возвращать некоторое (одно!) значение. Это возвращаемое значение и есть результат выполнения функции, который при выполнении программы подставляется в точку вызова функции, где бы этот вызов ни встретился. Допускается также использовать функции, не имеющие аргументов, и функции, не возвращающие никаких значений. Действие таких функций может состоять, например, в изменении значений некоторых переменных, выводе на печать некоторых текстов и т.п.
В программах на языке С++ широко используются, так называемые, библиотечные функции, т.е. функции предварительно разработанные и записанные в библиотеки. Прототипы библиотечных функций находятся в специальных заголовочных файлах, поставляемых вместе с библиотеками в составе систем программирования, и включаются в программу с помощью директивы #include.
С использованием функций в языке С++ связаны три понятия - определение функции (описание действий, выполняемых функцией), объявление функции (задание формы обращения к функции) и вызов функции .
23. Определение функций в языке С++. Объявление функций. Вызов функций.
Определение функции задает тип возвращаемого значения, имя функции, типы и число формальных параметров, а также объявления переменных и операторы, называемые телом функции, и определяющие действие функции. В определении функции также может быть задан класс памяти.
В языке С++ нет требования, чтобы определение функции обязательно предшествовало ее вызову. Определения используемых функций могут следовать за определением функции main, перед ним, или находится в другом файле.
В соответствии с синтаксисом языка С++ определение функции имеет следующую форму:
[спецификатор-класса-памяти] [спецификатор-типа] имя-функции ([список-формальных-параметров]) { тело-функции }Необязательный спецификатор-класса-памяти задает класс памяти функции, который может быть static или extern. Спецификатор-типа функции задает тип возвращаемого значения и может задавать любой тип. Если спецификатор-типа не задан, то предполагается, что функция возвращает значение типа int.
Функция не может возвращать массив или функцию, но может возвращать указатель на любой тип, в том числе и на массив и на функцию.
Список-формальных-параметров - это последовательность объявлений формальных параметров, разделенная запятыми. Формальные параметры - это переменные, используемые внутри тела функции и получающие значение при вызове функции путем копирования в них значений соответствующих фактических параметров.
Порядок и типы формальных параметров должны быть одинаковыми в определении функции и во всех ее объявлениях.
При передаче параметров в функцию, если необходимо, выполняются обычные арифметические преобразования для каждого формального параметра и каждого фактического параметра независимо.
Тело функции - это составной оператор, содержащий операторы, определяющие действие функции.
Если требуется вызвать функцию до ее определения в рассматриваемом файле, или определение функции находится в другом исходном файле, то вызов функции следует предварять объявлением этой функции. Объявление (прототип) функции имеет следующий формат:
[спецификатор-класса-памяти] [спецификатор-типа] имя-функции ([список-формальных-параметров]) [,список-имен-функций];
В отличие от определения функции, в прототипе за заголовком сразу же следует точка с запятой, а тело функции отсутствует. Если несколько разных функций возвращают значения одинакового типа и имеют одинаковые списки формальных параметров, то эти функции можно объявить в одном прототипе, указав имя одной из функций в качестве имени-функции, а все другие поместить в список-имен-функций, причем каждая функция должна сопровождаться списком формальных параметров. Правила использования остальных элементов формата такие же, как при определении функции. Имена формальных параметров при объявлении функции можно не указывать, а если они указаны, то их область действия распространяется только до конца объявления.
Вызов функции имеет следующий формат:
адресное-выражение ([список-выражений])
Поскольку синтаксически имя функции является адресом начала тела функции, в качестве обращения к функции может быть использовано адресное-выраж ение (в том числе и имя функции или разадресация указателя на функцию), имеющее значение адреса функции.
Список-выражений представляет собой список фактических параметров, передаваемых в функцию. Этот список может быть и пустым, но наличие круглых скобок обязательно.
24. Способы передачи параметров в функции в С++. Передача массивов в функцию.
Для увеличения потенциальных возможностей ваших функций C++ позволяет программам передавать информацию (параметры) в функции. Если функция использует параметры, вы должны сообщить C++ тип каждого параметра, например int, float, char и т.д. Каждый параметр функции имеет определенный тип. Если ваша функция использует параметры, она должна указать уникальное имя и тип для каждого параметра. Когда программа вызывает функцию, C++ присваивает значения параметров именам параметров функции слева направо. Каждый параметр функции имеет определенный тип, например int, float или char. Значения, которые ваша программа передает в функцию, используя параметры, должны соответствовать типу параметров.
Передача массивов в функцию.
Ващи программы будут передавать массивы в функции точно так же, как и любые другие переменные. Функция может инициализировать массив, прибавить к массиву значения или вывести элементы массива на экран. Когда вы передаете массив в функцию, вы должны указать тип массива. Нет необходимости указывать размер массива. Вместо этого вы передаете параметр например number_of_elements, который содержит количество элементов в массиве:
Как видите, программа передает массив в функцию по имени. Функция в свою очередь присваивает массиву элементы. Пока ваша программа не передаст параметры в функцию с помощью адреса, функция не может изменить эти параметры.
25. Рекурсивные функции.
Функция, которая вызывает сама себя непосредственно или косвенно, называется рекурсивной. Классическим примером простой рекурсии является функция, вычисляющая факториал числа. В рекурсивной функции всегда должно быть определенно условие выхода или останова; в противном случае рекурсия станет бесконечной, т.е. функция продолжит вызывать себя до тех пор, пока стек программы не будет исчерпан. Иногда эта ошибка называется бесконечной рекурсией.
26. Полиморфизм и перегрузка функции. Перегрузка операторов.
Слово «полиморфизм» происходит от греческих слов «поли»-много и «морф»-форма, дословно многообразие форм. Связанные с наследованием классы называют полиморфными типами, поскольку в зависимости от ситуации могут быть попеременно использованы формы как производного, так и базового класса. Полиморфный объект представляет собой такой объект, который может изменять форму во время выполнения программы. Предположим, например, что вы программист, работающий в телефонной компании, и вам необходимо написать программу, которая эмулирует телефонные операции. Поскольку вы знакомы с тем, как люди используют телефон, вы быстро выберете общие операции, такие как набор номера, звонок, разъединение и индикация занятости.
Перегрузка функции упрощает разработку программы и делает ее код более понятным, устраняя необходимость в изобретение и запоминании имен, которые существуют только для того, чтобы помочь компилятору выяснить какую из функций следует вызвать. Чтобы понять принцип перегрузки функций следует уяснить как компилятор выбирает при вызове функцию из набора перегруженных функций.
Перегрузка оператора состоит в изменении смысла оператора (например, оператора плюс (+), который обычно в C++ используется для сложения) при использовании его с определенным классом. В данном уроке вы определите класс string и перегрузите операторы плюс и минус. Для объектов типа string оператор плюс будет добавлять указанные символы к текущему содержимому строки. Подобным образом оператор минус будет удалять каждое вхождение указанного символа из строки. К концу данного урока вы изучите следующие основные концепции:
- Вы перегружаете операторы для улучшения удобочитаемости ваших программ, но перегружать операторы следует только в том случае, если это упрощает понимание вашей программы.
- Для перегрузки операторов программы используют ключевое слово C++ operator.
- Переопределяя оператор, вы указываете функцию, которую C++ вызывает каждый раз, когда класс использует перегруженный оператор. Эта функция, в свою очередь, выполняет соответствующую операцию.
- Если ваша программа перегружает оператор для определенного класса, то смысл этого оператора изменяется только для указанного класса, оставшаяся часть программы будет продолжать использовать этот оператор для выполнения его стандартных операций.
Перегрузка операторов может упростить наиболее общие операции класса и улучшить читаемость программы. Найдите время для эксперимента с программами, представленными в этом уроке, и вы обнаружите, что перегрузка операторов выполняется очень просто.
27. Время жизни и области видимости объекта.
Имена в языке С++ имеют область видимости, а объекты- продолжительность существования. Область видимости имени- это та часть текста программы в которой оно применимо. Продолжительность существования объекта- это время, в течение которого существует объект при выполнение программы. Имена параметров и переменных, определенных внутри функции, находятся в области видимости данной функции, т.е. имена видимы только внутри тела функции. Как обычно, имя переменой становиться применимо с момента ее объявления или определения и до конца области видимости включительно.
28. Спецификаторы класса памяти.
sc-спецификатор: auto static extern registerОписания, использующие спецификаторы auto, static и register также служат определениями тем, что они вызывают резервирование соответствующего объема памяти.
Описание register лучше всего представить как описание auto (автоматический) с подсказкой компилятору, что описанные переменные усиленно используются. Подсказка может быть проигнорирована. К ним не может применяться операция получения адреса &.
Спецификаторы auto или register могут применяться только к именам, описанным в блоке, или к формальным параметрам. Внутри блока не может быть описаний ни статических функций, ни статических формальных параметров.
Некоторые спецификаторы могут использоваться только в описаниях функций:
Спецификатор перегрузки overload делает возможным использование одного имени для обозначения нескольких функций;
Спецификатор inline является только подсказкой компилятору, не влияет на смысл программы и может быть проигнорирован. Он используется, чтобы указать на то, что при вызове функции inline- подстановка тела функции предпочтительнее обычной реализации вызова функции.
29. Объявление переменных на глобальном уровне. Инициализация глобальных и локальных переменных.
30. Стоки в С++. Способы реализации строковых переменных. Строковый тип данных.
31.Инициализация символьной строки в С++. Передача строк в функцию. Встроенный строковый тип.
Для инициализации символьной строки при объявлении укажите требуемую строку внутри двойных кавычек, как показано ниже:
char title[64] = "Учимся программировать на языке C++";
Если количество символов, присваиваемое строке, меньше размера массива, большинство компиляторов C++ будут присваивать символы NULL остающимся элементам строкового массива.
ПЕРЕДАЧА СТРОК В ФУНКЦИИ
Передача символьной строки в функцию подобна передаче любого массива в качестве параметра. Внутри функции вам нужно просто указать тип массива (char) и левую и правую скобки массива. Вам не надо указывать размер строки.
Так как символ NULL указывает конец строки, функция не требует параметр, который задает количество элементов в массиве. Вместо этого функция может определить последний элемент, просто найдя в массиве символ NULL.
Символ NULL используется для определения конца строки.
32. Класс string в С++. Функции для работы со строками.
Для работы со строками подключите модуль string.h.
1. strcat ( char * dest , const char * src ); - э та функция добавляет (копирует) в конец первой строки содержимое второй. У этой функции два параметра типа указатель на строку. Пример:
#include <string.h>
#include <iostream.h>#include <conio.h>
void main(){
char a[20]="hello", c[]=" from the srr";
strcat(a,c);
cout<< a<<', '<< c<<' '<< "\n"; // выведет hello from the srr, from the srr
getch ();}
2. strcmp ( const char * s 1, const char * s 2) – э та функция сравнивает две строки, а возвращаемое значение надо понимать следующим образом:
меньше нуля если s1 < s2
равно нулю если s1 == s2
больше нуля если s1 > s2
Понятие больше, меньше или равно применяется в соответствии с кодами букв входящих в состав строк, т.е. сравниваются первые буквы (их коды ), если они равны, то сравниваются последующие, до тех пор пока не будут найдены различные и на основе сравнения различных букв выводится результат сравнения строк. Обычно сравнивают строки на предмет равенства, и не интересуются тем, какая больше, например:
char a [20], c [20];
cout<<"\n Введите две строки ";
cin>>a>>c;
if (strcmp(a,c))
cout<<"Строки не равны"<< "\n"; //выведет при разных строках "Строки не равны"
3. strcpy(char *dest, const char *src) - копирует содержимое второй строки в первую:
char string[10];
char *str1 = "abcdefghi";
strcpy(string, str1);
cout<< string; // выведет "abcdefghi"
4. strstr(const char *s1, const char *s2) - осуществляет поиск первого вхождения подстроки в строку, возвращает соответствующий указатель на место в исходной строке:
char a[20]="1234567891011121314", c[]="34";
cout<< "\n"<< strstr(a,c); // выведет 34567891011121314
5. strlen(const char *s) - возвращает длину переданной строки.
char string[10];
char *str1 = "abcdef";
cout << strlen ( str 1); //выведет 6
6. sprintf() - эта функция объявлена в файлах CONIO.H, STDIO.H. Эта функция формирует строку на основе переменного числа параметров.
Пример: char r[50],s[]="string";
int i=1;
float f=1.34;
sprintf(r," Это результирующая строка : s:%s,%c, i:%d,f:%f или %d",s,s[2],i,f,f);
cout<< r;
33. Работа со строками в С++: символьный ввод/вывод, ввод/вывод строки.
Переменные символьного типа имеют тип char. Он обычно используют для хранения символа. Символы в компьютере хранятся в виде целых чисел, которые представляют собой код из таблицы символов ASCII. При выводе на экран символьных переменных и констант компьютер выводит соответствующий коду символ. Присваивать переменной типа char значения можно следующим образом:
char s;
s='a';
s=32;
s='\b'
В диапазон типа char входят числа от -128 до 127, коды русских букв имеют код больше 127, для решения этой проблемы используйте тип unsigned char.
В языке С++ нет стандартного типа для работы со строками. для этих целей используется массив символов:
unsigned char s[10]="Привет";
Символьные строки описываются как обычные массивы:
char phrase [17];
При использовании массива символов в качестве строки необходимо помнить, что концом строки считается символ '\0' (т.е. 0). Все стандартные функции корректно вставляют 0 в конец строки, но если вы будите, что либо менять, не забывайте ставить "\0" в конце строки.
Массивы можно полностью или частично проинициализировать непосредственно в операторе описания. Список значений элементов массива заключается в фигурные скобки "{}". Например, оператор
char phrase [17] = { 'В','в','е','д','и','т','е',' ','в','о','з','р','а','с','т',':', '\0' };
одновременно и объявляет массив "phrase", и присваивает его элементам значения.
Очень важно запомнить, что символьные строки хранятся в виде массивов. Поэтому их нельзя приравнивать и сравнивать с помощью операций "=" и "==".
Для копирования и сравнения строк следует применять специальные библиотечные функции.
Если требуется ввести строку, состоящую из нескольких слов, в одну строковую переменную, используются методы getline или get класса iostream.
34. Работа с файлами в С++: вывод в файловый поток, чтение их входного файлового потока.
На дисках данные хранятся в виде структур данных, обслуживаемых операционной системой, – в виде файлов . Файл проще всего представить как линейную последовательность символов.
Перед началом изучения файловых операций в Си++, необходимо ознакомиться с понятием потока ввода/вывода . Поток напоминает "канал" или "трубу", через которую данные поступают от передатчика к приемнику. Исключительно важная особенность потоковой обработки данных состоит в том, что элементы данных можно посылать или считывать из потока только по одному за раз, т.е. последовательно .
Из программы данные можно отправить (записать) в поток вывода , а получить (прочитать) их в программе из потока ввода . Например, сразу после запуска программы, поток стандартного ввода "cin" подключается к клавиатуре, а поток стандартного вывода "cout" – к экрану.
Список функций для работы с файловыми потоками хранится в заголовочном файле "fstream.h". Поэтому во всех рассматриваемых ниже фрагментах программ предполагается, что в начале программы есть соответствующая директива "#include":
#include<fstream.h>. В программе перед первым обращением к потоку ввода или вывода необходимо "создать" поток. Операторы для создания потоков похожи на описания переменных, и они обычно размещаются в начале программы или функции рядом с описаниями переменных. Например, операторы ifstream in_stream;
ofstream out_stream;
создают поток с именем "in_stream", являющийся объектом класса (как типа данных) "ifstream" (input-file-stream, файловый поток ввода), и поток с именем "out_stream", являющийся объектом класса "ofstream" (output-file-stream, файловый поток вывода).
После создания потока его можно подключить к файлу (открыть файл) с помощью функции open(...). Функция "open(...)" у потоков ifstream и ofstream работает по-разному. Для подключения потока ifstream с именем "in_stream" к файлу с именем "Lecture.txt" надо применить следующий вызов:
in_stream.open("Lecture.txt");
Чтобы к файлу "Lecture.txt" подключить поток вывода ofstream с именем "out_stream", надо выполнить аналогичный оператор:
out_stream.open("Lecture.txt");
Этот оператор подключит поток "out_stream" к файлу "Lecture.txt", но при этом прежнее содержимое файла будет удалено. Файл будет подготовлен к приему новых данных. Для отключения потока "in_stream" от файла, к которому он подключен (для закрытия файла), надо вызвать функцию close():
in_stream.close();
35. Работа с файлами в С++: определение конца файла, проверка ошибок при выполнение файловых операций, закрытие файла.
Для отключения потока "in_stream" от файла, к которому он подключен (для закрытия файла), надо вызвать функцию close():
in_stream.close();
Функция отключения от файла у потока вывода:
out_stream.close();
выполняет аналогичные действия, но, дополнительно, в конец файла добавляется служебный символ "end-of-file (маркер конца файла)". Т.о., даже если в поток вывода не записывались никакие данных, то после отключения потока "out_stream" в файле "Lecture.txt" будет один служебный символ. В таком случае файл "Lecture.txt" останется на диске, но он будет пустым.
Файловые операции, например, открытие и закрытие файлов, известны как один из наиболее вероятных источников ошибок. В надежных коммерческих программах всегда выполняется проверка, успешно или нет завершилась файловая операция. В случае ошибки вызывается специальная функция-обработчик ошибки.
Простейший способ проверки ошибок файловых операций заключается в вызове функции fail(). Вызов
in_stream.fail();
возвращает истинное значение (True), если последняя операция потока "in_stream" привела к ошибке (может быть, была попытка открытия несуществующего файла). После ошибки поток "in_stream" может быть поврежден, поэтому лучше не продолжать работу с ним.
В приведенном ниже фрагменте программы в случае ошибки при открытии файла на экран выдается сообщение и программа завершает работу с помощью библиотечной функции "exit()" (она описана в файле "stdlib.h"):
#include <iostream.h>
#include <fstream.h>
#include <stdlib.h>
#include <conio.h>
int main() {
ifstream in_stream;
in_stream.open( "Lecture.txt" );
if ( in_stream.fail() ) {
cout << "Извините, открыть файл не удалось!\n";
getch ();
exit(1);}
36. Работа с файлами в С++: управление открытием файла, символьный ввод/вывод, ввод/вывод строки.
В программе перед первым обращением к потоку ввода или вывода необходимо "создать" поток. Операторы для создания потоков похожи на описания переменных, и они обычно размещаются в начале программы или функции рядом с описаниями переменных. Например, операторы
ifstream in_stream;
ofstream out_stream;
создают поток с именем "in_stream", являющийся объектом класса (как типа данных) "ifstream" (input-file-stream, файловый поток ввода), и поток с именем "out_stream", являющийся объектом класса "ofstream" (output-file-stream, файловый поток вывода).
После создания потока его можно подключить к файлу (открыть файл) с помощью функции open(...). Функция "open(...)" у потоков ifstream и ofstream работает по-разному.
Для подключения потока ifstream с именем "in_stream" к файлу с именем "Lecture.txt" надо применить следующий вызов:
in_stream.open("Lecture.txt");
1.4.1 Функция ввода get()
После того, как файл для ввода данных открыт, из него можно считывать отдельные символы. Для этого служит функция get(). У нее есть параметр типа char&. Если программа находится в начале файла, то после вызова:
in_stream.get(ch);
переменной "ch" будет присвоено значение первой буквы файла и поток "in_stream" будет подготовлен для чтения следующего символа.
1.4.2 Функция вывода put()
С помощью потока вывода класса ofstream в открытый файл можно записывать отдельные символы. Для этого у класса ofstream есть функция put(). Записываемый символ передается ей как параметр типа "char".
37. Типы данных определяемые пользователем: перечисления. Переименование типов.
Перечисление-тип, группирующий набор именованных целочисленных констант.
При определения перечисления используется ключевое слово enum, за которым следует необязательное имя перечисления и заключенный в фигурные скобки список перечислителей, т.е. допустимых значений, разделенных запятыми. По умолчанию первый перечислитель получает нулевое значение, а каждый последующий- значение, которое на единицу больше. Одному или нескольким перечислителям можно присвоить конкретные значения. Используемое для инициализации перечислителя значение должно быть константным выражением. Значение перечислителя изменить нельзя.
38. Работа со структурами в С++: определение, описание и инициализация структур.
Структура – это составной тип данных, который получается путем объединения компонент, принадлежащих к другим типам данных (возможно, тоже составным). Структура предназначена для объединения нескольких переменных в один тип данных. Сначала тип структуры надо описать, а затем можно создавать переменные этого нового типа. Описание типа структуры "T" имеет следующий синтаксис:
struct T {
T1 var1;
T2 var2;
... T3 var3; };
где "T1", "T2", "T3" – имена встроенных типов данных ("int", "char" и др.) или других составных типов. "var1", "var2", "var3" – это имена внутренних переменных структуры. Элементы структуры называются полями структуры и могут иметь любой тип, кроме типа этой же структуры, но могут быть указателями на него. Если отсутствует имя типа, должен быть указан список описателей переменных, указателей или массивов. Обратите внимание на точку с запятой в конце описания типа структуры.
Важно отметить, что не все возможные комбинации значений компонент структуры могут иметь смысл применительно к конкретной задаче. Например, тип "Date", определенный выше, включает значения {50, 5, 1973} и {100, 22, 1815}, хотя дней с такими датами не существует. Т.о., определение этого типа не отражает реального положения вещей, но все же оно достаточно близко к практическим целям. Ответственность за то, чтобы при выполнении программы не возникали подобные бессмысленные значения, возлагается на программиста. Обращения к компонентам классов в объектно-ориентированном Си++ очень похожи на обращения к компонентам структур.
Переменные типа структуры можно присваивать, передавать, как параметры функции, и возвращать из функции в качестве результата. Например:
Person current;
Person set_current_person( Person& p )
{Person prev = current;
current = p;
return prev; }
Остальные операции, такие, как сравнение ("==" и "!="), для структур по умолчанию не определены, но программист может их определить при необходимости.
Имя типа структуры можно использовать еще до того, как этот тип будет определен, вплоть до момента, когда потребуется, чтобы стал известен размер структуры.
39. Работа со структурами в С++: доступ к компонентам структуры через указател, массивы и структуры.
1.3 Доступ к компонентам структуры через указатель
Аналогично обычным переменным, можно создавать указатели на переменные-структуры. Для доступа к компонентам структуры через указатель применяется операция "->". Например:
void print_person( Person* p ) {
cout << p->name << '\n';
cout << p->birthdate.day << '\n';
cout << p->birthdate.month << '\n';
cout << p->birthdate.year << '\n';
cout << p->salary << '\n\n'; }
Функцию "print_person()" можно переписать в эквивалентном виде с помощью операции разыменования указателя "*" и операции доступа к компонентам структуры ".". Обратите внимание на скобки в записи "(*p).", которые необходимы, поскольку приоритет операции "." выше, чем у "*":
void print_person( Person* p ) {
cout << (*p).name << '\n';
cout << (*p).birthdate.day << '\n';
cout << (*p).birthdate.month << '\n';
cout << (*p).birthdate.year << '\n';
cout << (*p).salary << '\n\n'; }
У массива и структуры есть общее свойство: оба этих типа данных являются типами с произвольным доступом. Но структура более универсальна, поскольку не требуется, чтобы типы всех ее компонент были одинаковы. С другой стороны, в некоторых случаях массив предоставляет бóльшие возможности, т.к. индексы его элементов могут вычисляться, а имена компонент структуры – это фиксированные идентификаторы, задаваемые в описании типа.
Массивы и структуры могут комбинироваться различными способами.
40. Работа со структурами в С++: хранение структур в файлах. Структуры и бинарные файлы.
41. Битовые поля в С++.
Специальная переменная-член класса, называемая битовым полем, предназначена для хранения определенного количества битов. Битовые поля обычно используют в случае, когда программа должна передать бинарные данные другой программе или аппаратному устройству. Битовое поле представляет собой целочисленный тип данных. Оно может быть знаковым или беззнаковым. Чтобы объявить член класса битовым полем, после его имени располагают двоеточие и константное выражение, указывающее количество битов. Битовые поля, определенные в последовательном порядке внутри тела класса, если это возможно, упаковываются внутри смежных битов того же целого числа. Таким образом достигается уплотнение хранилища.
42. Объединения в С++.
Объединение- это класс специального вида. Объединение может иметь несколько переменных-членов, однако в каждый момент времени только одна из них будут содержать значение. Когда значение присваивается одному из членов объединения, все остальные переходят в неопределенное состояние. Для объединения резервируются такой объем памяти, которого хватит, по крайней мере, для размещения его самой большой переменной-члена. Подобно любому другому классу, определение объединения создает новый тип. Объединение позволяет создать набор взаимоисключающих значений, которые могут иметь разные типы. Определения объединения начинается с ключевого слова union, за которым следует имя объединения и набор его членов, заключенный в фигурные скобки. Подобно любому классу, объем памяти, резервируемой для объекта объединения, определяет его тип. Во время компиляции размер каждого объекта объединения фиксирован: он должен быть достаточен для хранения самой большой переменной-члена объединения.
43. Динамические структуры данных: основные понятия. Достоинства и недостатки связного представления данных .
Любая программа предназначена для обработки данных, от способа организации которых зависят алгоритмы работы, поэтому выбор структур данных должен предшествовать созданию алгоритмов. Наиболее часто в программах используются массивы, структуры и их сочетания, например, массивы структур, полями которых являются массивы и структуры.
Память под данные выделяется либо на этапе компиляции (в этом случае необходимый объем должен быть известен до начала выполнения программы, то есть задан в виде константы), либо во время выполнения программы (необходимый объем должен быть известен до распределения памяти). В обоих случаях выделяется непрерывный участок памяти.
Если до начала работы с данными невозможно определить, сколько памяти потребуется для их хранения, память выделяется по мере необходимости отдельными блоками, связанными друг с другом с помощью указателей. Такой способ организации данных называется динамическими структурами данных, поскольку их размер изменяется во время выполнения программы. Из динамических структур в программах чаще всего используются линейные списки, стеки, очереди и бинарные деревья. Они различаются способами связи отдельных элементов и допустимыми операциями. Динамическая структура может занимать несмежные участки оперативной памяти.
Динамические структуры широко применяют и для более эффективной работы с данными, размер которых известен, особенно для решения задач сортировки, поскольку упорядочивание динамических структур не требует перестановки элементов, а сводится к изменению указателей на эти элементы. Например, если в процессе выполнения программы требуется многократно упорядочивать большой массив данных, имеет смысл организовать его в виде линейного списка. При решении задач поиска элемента в тех случаях, когда важна скорость, данные лучше всего представить в виде бинарного дерева.
Элемент любой динамической структуры данных представляет собой структуру, содержащую по крайней мере два поля: для хранения данных и для указателя. Полей данных и указателей может быть несколько. Поля данных могут быть любого типа: основного, составного или типа указатель. Описание простейшего элемента (компоненты, узла) выглядит следующим образом:
struct Node{
Data d: // тип данных Data должен быть определен ранее
Node *p; };
44. Динамическая структура данных: линейные списки. Реализация односвязного списка.
Самый простой способ связать множество элементов — сделать так, чтобы каждый элемент содержал ссылку на следующий. Такой список называется однонаправленным (односвязным). Если добавить в каждый элемент вторую ссылку — на предыдущий элемент, получится двунаправленный список (двусвязный), если последний элемент связать указателем с первым, получится кольцевой список.
Каждый элемент списка содержит ключ, идентифицирующий этот элемент. Ключ обычно бывает либо целым числом, либо строкой и является частью поля данных. В качестве ключа в процессе работы со списком могут выступать разные части поля данных. Например, если создается линейный список из записей, содержащих фамилию, год рождения, стаж работы и пол, любая часть записи может выступать в качестве ключа: при упорядочивании списка по алфавиту ключом будет фамилия, а при поиске, к примеру, ветеранов труда ключом будет стаж. Ключи разных элементов списка могут совпадать.
Над списками можно выполнять следующие операции:
· начальное формирование списка (создание первого элемента);
· добавление элемента в конец списка;
· чтение элемента с заданным ключом;
· вставка элемента в заданное место списка;
· удаление элемента с заданным ключом;
· упорядочивание списка по ключу.
Рассмотрим двунаправленный линейный список. Для формирования списка и заботы с ним требуется иметь по крайней мере один указатель — на начало списка. Удобно завести еще один указатель — на конец списка. Для простоты допустим, что список состоит из целых чисел, то есть описание элемента списка выглядит следующим образом:
struct Node{
int d;
Node *next;
Node *prev;};
45. Динамическая структура данных: линейные списки. Реализация двусвязного списка.
Самый простой способ связать множество элементов — сделать так, чтобы каждый элемент содержал ссылку на следующий. Такой список называется однонаправленным (односвязным). Если добавить в каждый элемент вторую ссылку — на предыдущий элемент, получится двунаправленный список (двусвязный), если последний элемент связать указателем с первым, получится кольцевой список.
Каждый элемент списка содержит ключ, идентифицирующий этот элемент. Ключ обычно бывает либо целым числом, либо строкой и является частью поля данных. В качестве ключа в процессе работы со списком могут выступать разные части поля данных. Например, если создается линейный список из записей, содержащих фамилию, год рождения, стаж работы и пол, любая часть записи может выступать в качестве ключа: при упорядочивании списка по алфавиту ключом будет фамилия, а при поиске, к примеру, ветеранов труда ключом будет стаж. Ключи разных элементов списка могут совпадать.
Над списками можно выполнять следующие операции:
· начальное формирование списка (создание первого элемента);
· добавление элемента в конец списка;
· чтение элемента с заданным ключом;
· вставка элемента в заданное место списка;
· удаление элемента с заданным ключом;
· упорядочивание списка по ключу.
Рассмотрим двунаправленный линейный список. Для формирования списка и заботы с ним требуется иметь по крайней мере один указатель — на начало списка. Удобно завести еще один указатель — на конец списка. Для простоты допустим, что список состоит из целых чисел, то есть описание элемента списка выглядит следующим образом:
struct Node{
int d;
Node *next;
Node *prev;};
46. Динамические структуры данных: линейные списки. Реализация кольцевого списка.
47. Динамические структуры данных: стек и его реализация.
Стек — это частный случай однонаправленного списка, добавление элементов в Который и выборка из которого выполняются с одного конца, называемого вершиной стека. Другие операции со стеком не определены. При выборке элемент исключается из стека. Говорят, что стек реализует принцип обслуживания LIFO (last in — first out, последним пришел — первым ушел). Стек проще всего представить себе как закрытую с одного конца узкую трубу, в которую бросают мячи. Достать первый брошенный мяч можно только после того, как вынуты все остальные. Сегмент стека назван так именно потому, что память под локальные переменные выделяется по принципу LIFO. Стеки широко применяются в системном программном обеспечении, компиляторах, в различных рекурсивных алгоритмах.
48. Динамические структуры данных: очередь и его реализация.
Очередь — это частный случай однонаправленного списка, добавление элементов в который выполняется в один конец, а выборка — из другого конца. Другие операции с очередью не определены. При выборке элемент исключается из очереди. Говорят, что очередь реализует принцип обслуживания FIFO (first in — first out, первым пришел — первым ушел). Очередь проще всего представить себе, постояв в ней час-другой. В программировании очереди применяются, например, при моделировании, диспетчеризации задач операционной системой, буферизованном вводе/выводе.
49. Динамические структуры данных: дек и его реализация.
50. Динамические структуры данных: бинарные деревья и их реализация.
Бинарное дерево — это динамическая структура данных, состоящая из узлов, каждый из которых содержит, кроме данных, не более двух ссылок на различные бинарные деревья. На каждый узел имеется ровно одна ссылка. Начальный узел называется корнем дерева. На рисунке 1 приведен пример бинарного дерева (корень обычно изображается сверху). Узел, не имеющий поддеревьев, называется листом. Исходящие узлы называются предками, входящие — потомками. Высота дерева определяется количеством уровней, на которых располагаются его узлы.
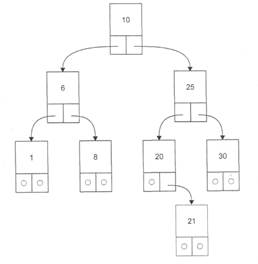
Рисунок 1 Бинарное дерево
Дерево является рекурсивной структурой данных, поскольку каждое поддерево также является деревом. Действия с такими структурами изящнее всего описываются с помощью рекурсивных алгоритмов
Можно обходить дерево и в другом порядке, например, сначала корень, потом поддеревья, но приведенная функция позволяет получить на выходе отсортированную последовательность ключей, поскольку сначала посещаются вершины с меньшими ключами, расположенные в левом поддереве. Результат обхода дерева, изображенного на рис. 1: 1, 6, 8, 10, 20, 21, 25, 30.
Если в функции обхода первое обращение идет к правому поддереву, результат обхода будет другим: 30, 25, 21, 20, 10, 8, 6, 1.
Таким образом, деревья поиска можно применять для сортировки значений. При обходе дерева узлы не удаляются. Для бинарных деревьев определены операции: включения узла в дерево; поиска по дереву; обхода дерева; удаления узла. Для каждого рекурсивного алгоритма можно создать его не рекурсивный эквивалент.