| Скачать .docx |
Курсовая работа: Исследование процессов маршрутизации
Содержание
Введение
1.Алгоритмы поиска кратчайшего пути
1.1 Исходные данные
1.2 Алгоритм Дейкстры
1.3 Алгоритм Беллмана-Форда
1.4 Расчет пути с минимальным количеством переходов
1.5 Выводы
2.Маршрутизация
2.1 Основы маршрутизации
2.2 Характеристика пртокола RIP
2.3 Построение маршрутных таблиц
Заключение
Список использованной литературы
Введение
Цель маршрутизации - доставка пакетов по назначению с максимизацией эффективности. Чаще всего эффективность выражена взвешенной суммой времен доставки сообщений при ограничении снизу на вероятность доставки. Маршрутизация сводится к определению направлений движения пакетов в маршрутизаторах. Выбор одного из возможных в маршрутизаторе направлений зависит от текущей топологии сети (она может меняться хотя бы из-за временного выхода некоторых узлов из строя), длин очередей в узлах коммутации, интенсивности входных потоков и т.п.
Целью курсового проекта является исследование процессов маршрутизации. В курсовом пректе будут рассмотрены алгоритмы поиска кратчайшего пути, произведён расчёт пути с минимальным количеством переходов. Также рассмотрим характеристики протокола RIP и построим маршрутные таблицы.
1.Краткий обзор постановки задачи и путей ее решения
Компьютерные сети, как правило, представляются в виде графов, при этом коммутаторы и маршрутизаторы сетей являются узлами графа, а линии связи представляют собой р алгоритм Беллмана- Форда), ребра графа. Ряд понятий из теории графов оказываются полезными при разработке сетей и алгоритмов маршрутизации. Для объединенной сети, такой как Интернет или интранет, представление ее в виде ориентированного графа также является приемлемым. В этом случае каждой вершине соответствует маршрутизатор. Если два маршрутизатора напрямую соединены к одной и той же локальной или глобальной сети, тогда это двусторонне соединение соответствует паре параллельных ребер, соединяющих соответствующие вершины. Если к сети напрямую присоединены более двух маршрутизаторов, тогда эта сеть представляется в виде множества пар параллельных ребер, каждая из которых соединяет два маршрутизатора. В объединенной сети для передачи IP-дейтаграммы от маршрутизатора - источника к маршрутизатору - приемнику по разным линиям через разные сети и маршрутизаторы пакетов требуется принять решение о выборе маршрута. Эта задача также эквивалентна поиску пути в графе.
Сеть с коммутацией пакетов (или сеть ретрансляции кадров, или сеть ATM) но рассматривать как ориентированный граф, в котором каждая вершина соответствует узлу коммутации пакетов, а линии связи между узлами соответствует пара параллельных ребер, по каждому из которых данные передаются в одном направлении. В такой сети для передачи пакета от узла-источника узлу - получателя по разным линиям через несколько коммутаторов пакетов требуется принять решение о выборе маршрута. Эта задача эквивалентна поиску пути в графе.
Практически во всех сетях с коммутацией пакетов и во всех объединенных сетях решение о выборе маршрута принимается на основе одной из разновидностей критерия минимальной стоимости. Если выбирается маршрут с минимальным количеством ретрансляционных участков (хопов), тогда каждому ребру, соответствующему ретрансляционному участку, назначается единичный вес. Эта задача соответствует поиску кратчайшего пути в обычном (не взвешенном) графе. Но чаще всего каждому ретрансляционному участку в соответствие ставится определенная величина, называемая стоимостью (cost) передачи. Эта величина может быть обратно пропорциональной пропускной способности линии, прямо пропорциональной текущей нагрузке на эту линию или представлять собой некую комбинацию подобных параметров. При расчете стоимости могут учитываться также такие критерии, как финансовая стоимость использования ретрансляционного участка. В любом случае, стоимости использования ретрансляционных участков являются входными данными для алгоритма поиска пути с минимальной стоимостью, который может быть сформулирован следующим образом.
Пусть имеется сеть, состоящая из узлов, соединенных двунаправленными линиями связи, и каждой линии поставлена в соответствие стоимость пересылки данных в каждом направлении. Стоимость пути между двумя узлами определяете как сумма стоимостей всех линий, входящих в данный путь. Задача состоит в том, чтобы найти путь с наименьшей стоимостью для каждой пары узлов.
Обратите внимание на то, что стоимость использования ретрансляционного участка может быть разной в разных направлениях. Например, это справедливо в случае, если стоимость использования ретрансляционного участка пропорциональна длине очереди дейтаграмм, ждущих передачи. В теории графов задаче нахождения пути с наименьшей стоимостью соответствует задача поиска пути с наименьшей длиной во взвешенном ориентированном графе.
Большинство алгоритмов поиска маршрута с наименьшей стоимостью, применяющихся в сетях с коммутацией пакетов и объединенных сетях, представляют собой вариации одного из двух общих алгоритмов, известных как алгоритм Дейкстры (Dijkstra) и алгоритм Беллмана — Форда (Bellman — Ford). В этом разделе обсуждаются оба алгоритма.
1.1 Исходные данные
· Номер варианта-6
· Матрица смежности
V1 V2 V3 V4 V5 V6
V1 0 0 5 0 1 5
V2 0 0 0 3 2 4
V3 2 0 0 6 4 0
V4 0 6 2 0 0 0
V5 1 5 5 0 0 0
V6 6 6 0 0 0 0
Рисунок 1. Взвешенный ориентированный граф, построенный по матрице смежности
V2
V1 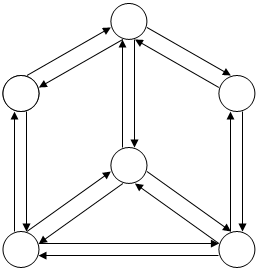 V3
V3
1.2 Алгоритм Дейкстры
Алгоритм Дейкстры может быть сформулирован следующим образом. Алгоритм находит кратчайшие пути от данной вершины-источника до всех остальных вершин, перебирая пути в порядке увеличения их длин. Работа алгоритма проходит поэтапно. К k - му шагу алгоритм находит k кратчайших (с наименьшей стоимостью) путей к k вершинам, ближайшим к вершине-источнику. Эти вершины образуют множество Т. На шаге ( k + 1) к множеству Т добавляется вершина, ближайшая к вершине- источнику среди вершин, не входящих во множество Т. При добавлении каждой новой вершины к множеству Т определяется путь к ней от источника. Формально этот алгоритм может быть определен следующим образом. Введем обозначения:
· N — множество вершин сети;
· s — вершина-источник;
· Т — множество вершин, уже обработанных алгоритмом;
· Дерево — связующее дерево для вершин, принадлежащих множеству Т, включая ребра, входящие в пути с наименьшей стоимостью от вершины s до каждой вершины множества Т ;
· w ( i , j ) — стоимость линии от вершины i до вершины j , причем w ( i , j ) = 0 или w ( i , j ) = ¥ , если две вершины не соединены напрямую, и w ( i , j ) => 0 , если две вершины соединены напрямую;
· L ( n ) — минимальная стоимость пути от вершины s до вершины п, известного на данный момент алгоритму (по завершении работы алгоритма это минимальная стоимость пути от вершины s до вершины п).
Алгоритм состоит из трех шагов. Шаги 2 и 3 повторяются до тех пор, пока множество T не совпадет с множеством N . Это значит, что шаги 2 и 3 повторяются, пока для всех вершин сети не будут найдены окончательные пути.
1. Инициализация. Т=Дерево = { s },
то есть множество исследованных вершин состоит пока что только из вершины-источника.
L(n) = w(s, п ) для п ¹ s,
то есть стоимости начальных путей к соседним вершинам представляют собой просто стоимости линий связи.
2. Получить следующую вершину.
Найти следующую вершину, не принадлежащую множеству T и имеющую путь от вершины s с минимальной стоимостью, и включить эту вершину во множество T и в Дерево. Кроме того, к дереву добавляется ребро, инцидентное этой вершине и вершине множества T , входящей в путь с минимальной стоимостью. Это может быть сформулировано следующим образом. Найти вершину x Ï Т такую, что
L ( x ) = min L ( j )
j Ï T
Добавить вершину х кмножеству T и к дереву; добавить к дереву ребро, инцидентное вершине х, составляющее компонент пути L ( x ) с минимальной стоимостью, то есть последний ретрансляционный участок пути.
3. Обновить путь с минимальной стоимостью.
L ( n ) = min [ L ( n ) , L ( x ) + w ( x , п)] для всех п Ï Т.
Если последняя величина минимальна, то с этого момента путь от вершины до вершины п представляет собой конкатенацию пути от вершины s до вершины х и пути от вершины х до вершины п.
Алгоритм завершает работу, когда все вершины добавлены к множеству Т . Таким образом, для работы алгоритма требуется |V | итераций. К моменту окончания работы алгоритма значение L ( x ) , поставленное в соответствие каждой вершине x представляет собой минимальную стоимость (длину) пути от вершины s до вершины х . Кроме того, Дерево представляет собой связующее дерево исходного ориентированного графа, определяющее пути с минимальной стоимостью от вершины s до всех остальных вершин.
На каждой итерации при выполнении шагов 2 и 3 к множеству T добавляется одна новая вершина, а также находится путь с минимальной стоимостью вершины s до этой вершины. Другими словами, на каждой итерации к множеству добавляется вершина х , а значение L ( x ) на этот момент времени представляет собой минимальную стоимость пути от вершины s до вершины х . Более того, путь с минимальной стоимостью определяется уникальным путем от вершины s , вершины х во множестве Т . Этот путь проходит только по вершинам, принадлежащим множеству Т . Чтобы понять это, рассмотрим следующую цепочку рассуждений. Вершина х, добавляемая на первой итерации, должна быть смежной с вершиной и не должно существовать другого пути к вершине х с меньшей стоимостью. Если вершина х не является смежной с вершиной s, тогда должна существовать другая вершина, смежная с вершиной s , представляющая собой первый транзитный участок пути с минимальной стоимостью к вершине х . В этом случае при выборе вершины, добавляемой к множеству Т , предпочтение будет отдано этой вершине, а не вершине х . Если вершина х является смежной с вершиной s , но путь s —х не является путем с наименьшей стоимостью от вершины s до вершины х , то это значит, что существует другая смежная с вершиной s вершина у , находящаяся на пути с минимальной стоимостью, и при выборе добавляемой к множеству Т вершины предпочтение будет отдано вершине у , а не вершине х . После выполнения k итераций во множество T войдут k вершин и будет найден путь с минимальной стоимостью от вершины s до каждой из этих вершин. Теперь рассмотрим все возможные пути от вершины s до вершин, не входящих в множество Т . Среди этих путей существу один путь с минимальной стоимостью, проходящий исключительно по вершинам, принадлежащим множеству Т , заканчивающийся линией, непосредственно связывающей некую вершину множества Т свершиной, не принадлежащей множеству Т . Эта вершина добавляется к множеству Т , а соответствующий путь считается путем с наименьшей стоимостью к данной вершине.
В табл. 1 показан результат применения данного алгоритма к графу, представленному на рис.1.
| № | Т | L(2) | Путь | L(3) | Путь |
L(4) | Путь | L(5) | Путь | L(6) | Путь |
| 1 | {1} | ∞ | - | 5 | 1-3 | ∞ | - | 1 | 1-5 | 5 | 1-6 |
| 2 | {1;5} | 6 | 1-5-2 | 5
|
1-3 1-5-3 |
∞ | - | 1 | 1-5 | 5 | 1-6 |
| 3 | {1;5;2} | 6 | 1-5-2 | 5
|
1-3 1-5-3 |
9 | 1-5-2-4 | 1 | 1-5 | 5
|
1-6 1-5-2-6 |
| 4 | {1;5;2;6;} |
6 |
1-6-2 1-5-2 |
5 6 18 |
1-5-3 1-6-2-5-3 |
9
|
1-5-2-4 1-6-2-4 |
1 13 |
1-6-2-5 |
5 10 |
1-5-2-6 |
| 5 | {1;5;2;6;3} | 6
14 |
1-6-2 1-3-5-2 |
5
18 |
1-5-3 1-6-2-5-3 |
9
12 11 17 24 |
1-6-2-4 1-5-3-4 1-3-4 1-3-5-2-4 1-6-2-5-3-4 |
1
|
1-5 1-3-5 1-6-2-5 |
5
17 |
1-5-2-6 1-3-5-2-6 |
| 6 | {1;5;2;6;3;4} | 6
17 18 |
1-6-2 1-3-4-2 1-5-3-4-2 |
5
|
1-4-3 1-5-2-4-3 1-6-2-4-3 |
9 |
1-5-2-4 |
1
|
1-5 1-3-4-2-5 |
1
|
1-6 1-3-4-2-6 1-5-3-4-2-6 |
Рисунок. 2
V1 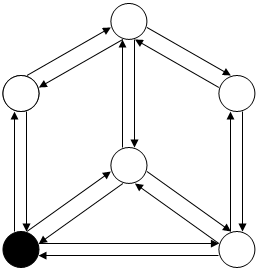 V3
V3
Рисунок.3
V1 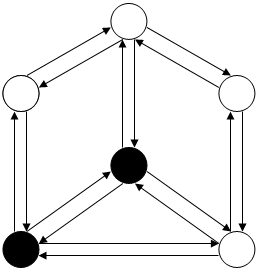 V3
V3
Рисунок.4
V1 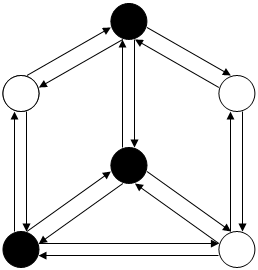 V3
V3
Рисунок.5
V1  V3
V3
Рисунок.6
V1  V3
V3
Рисунок.7
V1  V3
V3
1.3.Алгоритм Беллмана-Форда
Алгоритм Беллмана — Форда может быть сформулирован следующим образом. Требуется найти кратчайшие пути от заданной вершины при условии, что эти пути состоят максимум из одного ребра, затем найти кратчайшие пути при условии, что эти пути состоят максимум из двух ребер, и т. д. Этот алгоритм также работает поэтапно, формально он может быть определен следующим образом. Введем обозначения:
· s — вершина-источник;
· w ( i , j ) — стоимость линии от вершины i до вершины j , причем w ( i , j ) = 0 или w ( i , j ) = ¥ , если две вершины не соединены напрямую, и w ( i , j ) => 0 , если две вершины соединены напрямую;
· h — максимальное количество ребер в пути на текущем шаге алгоритма;
· Lh ( n ) — минимальная стоимость пути от вершины s до вершины п при условии, что этот путь состоит не более чем из h ребер.
Алгоритм состоит из двух шагов. Шаг 2 повторяется до тех пор, пока стоимости путей не перестанут изменяться.
1. Инициализация:
L 0 ( n ) = ¥ для всех п ¹ s ,
Lh ( s ) = 0 для всех h .
2. Обновление. Для каждого последовательного h >= 0 и для каждого п ¹ s вычислить
Lh+1 (n) - min[Lh (j) + w(j, n)].
j
Соединить вершину п с предыдущей вершиной j , для которой находится минимальное значение, и удалить любое соединение вершины п с предыдущей вершиной, образованное на более ранней итерации. Путь от вершины s до вершины п заканчивается линией связи от вершины j до вершины п .
При h = К для каждой вершины-получателя п алгоритм сравнивает потенциальный путь от вершины s до вершины п длиной К + 1 с путем, существовавшим к концу предыдущей итерации. Если предыдущий более короткий путь обладает меньшей стоимостью, то он сохраняется. В противном случае сохраняется новый путь от вершины s до вершины п длиной К + 1 . Этот путь состоит из пути длиной К от вершины К до некоей вершины j и прямого участка от вершины j до вершины п . В этом случае используемый путь от вершины s до вершины j представляет собой путь, состоящий из К ретрансляционных участков.
В табл. 2 показан результат применения этого алгоритма к графу, представленному на рис. 8, в котором в качестве вершины s выбираем: вершину V 1 . На каждом шаге алгоритм находит путь с минимальной стоимостью, максимальное число ретрансляционных участков в котором равно h . После последней итерации алгоритм находит путь с минимальной стоимостью к каждой вершине, а также вычисляется стоимость этого пути. Та же процедура может быть применена к вершине V 2 и т. д. Результаты работы алгоритмов Дейкстры и Беллмана - Форда совпадают.
Рисунок.8
V2
V1 V3
Таблица№2
| № | L(2) | Путь | L(3) | Путь | L(4) | Путь | L(5) | Путь | L(6) | Путь |
| 1 | ∞ | - | 5 | 1-3 | ∞ | - | 1 | 1-5 | 5 | 1-6 |
| 2 | 6 12 |
1-6-2 |
5
|
1-3 1-5-3 |
11 | 1-3-4 |
1 9 |
1-3-5 |
5 | 1-6 |
| 3 | 6
14 |
1-6-2 1-3-4-2 1-3-5-2 |
5 6 |
1-5-3 |
11 12 14 9 |
1-6-2-4 1-6-2-4 |
1 9 13 |
1-3-5 1-6-2-5 |
5 9 |
1-5-2-6 |
| 4 | 6
|
1-5-2 1-5-3-4-2 |
5
15 10 |
1-5-3 1-6-2-5-3 1-6-2-4-3 1-5-2-4-3 |
9
|
1-5-2-4 1-3-5-2-4 |
10
|
1-6-2-5 1-3-4-2-5 |
1
|
1-6 1-3-5-2-6 |
1.4.Расчет пути с минимальным количеством переходов
Преобразуем исходный граф в неориентированный невзвешенный граф.
Рисунок.9 Неориентированный, невзвешенный граф
V2
V1  V3
V3
Произведем поиск кратчайшего пути по алгоритму Дейкстры.
Таблица№3
| № | L(2) | Путь | L(3) | Путь | L(4) | Путь | L(5) | Путь | L(6) | Путь |
| 1 | ∞ | - | 5 | 1-3 | ∞ | - | 1 | 1-5 | 5 | 1-6 |
| 2 | 6 12 |
1-6-2 |
5
|
1-3 1-5-3 |
11 | 1-3-4 |
1 9 |
1-3-5 |
5 | 1-6 |
| 3 | 6
14 |
1-6-2 1-3-4-2 1-3-5-2 |
5 6 |
1-5-3 |
11 12 14 9 |
1-6-2-4 1-6-2-4 |
1 9 13 |
1-3-5 1-6-2-5 |
5 9 |
1-5-2-6 |
| 4 | 6
|
1-5-2 1-5-3-4-2 |
5
15 10 |
1-5-3 1-6-2-5-3 1-6-2-4-3 1-5-2-4-3 |
9
|
1-5-2-4 1-3-5-2-4 |
10
|
1-6-2-5 1-3-4-2-5 |
1
|
1-6 1-3-5-2-6 |
1.5 Выводы
В итоге оба алгоритма поиска кратчайшего пути привели нас к одинаковому результату. Но по алгоритму Беллмана-Форда результата мы достигли быстрее.
Достоинством алгоритма Дейсктры является то, что на каждом шаге мы находим кратчайшее расстояние еще до одной вершины, а по алгоритму Беллмана- Форда кратчайшее расстояние до любой вершины определяется только после прохождения всего алгоритма.
Расчет пути с минимальным количеством переходов привел к другим результатам, так как исходный граф был преобразован в неориентированный невзвешанный граф.
2. Маршрутизация
Цель маршрутизации - доставка пакетов по назначению с максимизацией эффективности. Чаще всего эффективность выражена взвешенной суммой времен доставки сообщений при ограничении снизу на вероятность доставки. Маршрутизация сводится к определению направлений движения пакетов в маршрутизаторах. Выбор одного из возможных в маршрутизаторе направлений зависит от текущей топологии сети (она может меняться хотя бы из-за временного выхода некоторых узлов из строя), длин очередей в узлах коммутации, интенсивности входных потоков и т.п.
2.1 Основы маршрутизации
Алгоритмы маршрутизации можно дифференцировать, основываясь на нескольких ключевых характеристиках. Во-первых, на работу результирующего протокола маршрутизации влияют конкретные задачи, которые решает разработчик алгоритма. Во-вторых, существуют различные типы алгоритмов маршрутизации, и каждый из них по-разному влияет на сеть и ресурсы маршрутизации. И наконец, алгоритмы маршрутизации используют разнообразные показатели, которые влияют на расчет оптимальных маршрутов.
Алгоритмы маршрутизации включают процедуры:
- измерение и оценивание параметров сети;
- принятие решения о рассылке служебной информации;
- расчет таблиц маршрутизации (ТМ);
- реализация принятых маршрутных решений.
В зависимости от того, используется ли при выборе направления информация о состоянии только данного узла или всей сети, различают алгоритмы изолированные и глобальные . Если ТМ реагирует на изменения состояния сети, то алгоритм адаптивный (динамический ) , иначе фиксированный (статический ), а при редких корректировках - квазистатический . В статических маршрутизаторах изменения в ТМ вносит администратор сети.
Простейший алгоритм - изолированный, статический. Алгоритм кратчайшей очереди в отличие от простейшего является адаптивным, пакет посылается по направлению, в котором наименьшая очередь в данном узле. Лавинный алгоритм - многопутевой, основан на рассылке копий пакета по всем направлениям, пакеты сбрасываются, если в данном узле другая копия уже проходила. Очевидно, что лавинный алгоритм обеспечивает надежную доставку, но порождает значительный трафик и потому используется только для отдельных пакетов большой ценности.
Наиболее широко используемые адаптивные протоколы (методы) маршрутизации - RIP (Routing Information Protocol) и OSPF (Open Shortest Path First). Метод RIP иначе называется методом рельефов. Он основан на алгоритме Беллмана-Форда и используется преимущественно на нижних уровнях иерархии сети. В сетях, работающих в соответствии с методом OSPF, информация о любом изменении в сети рассылается лавинообразно.
Алгоритм Беллмана-Форда относится к алгоритмам DVA (Distance Vector Algorithms). В DVA рельеф Ra(d) - это оценка кратчайшего пути от узла a к узлу d . Оценка (условно назовем ее расстоянием) может выражаться временем доставки, надежностью доставки или числом узлов коммутации (измерение в хопах) на данном маршруте. В ТМ узла а каждому из остальных узлов отводится одна строка со следующей информацией:
- узел назначения;
- длина кратчайшего пути;
- номер N ближайшего узла, соответствующего кратчайшему пути;
- список рельефов от а к d через каждый из смежных узлов.
Хотя алгоритм Беллмана-Форда сходится медленно, для сетей сравнительно небольших масштабов он вполне приемлем. В больших сетях лучше себя зарекомендовал алгоритм OSPF. Он основан на использовании в каждом маршрутизаторе информации о состоянии всей сети. В основе OSPF лежит алгоритм Дейкстры поиска кратчайшего пути в графах. При этом сеть моделируется графом, в котором узлы соответствуют маршрутизаторам, а ребра - каналам связи. Веса ребер - оценки (расстояния) между инцидентными узлами.
Находит применение еще один алгоритм маршрутизации - IGRP (Interior Gateway Routine Protocol), разработанный фирмой Cisco. Он аналогичен алгоритму RIP, но развивает его в направлениях: а) возможны различные метрики (целевые функции); б) трафик может распределяться по нескольким каналам с близкими значениями метрики.
В начале работы сети и в дальнейшем с определенной периодичностью маршрутизаторы обмениваются маршрутной информацией, на основе которой формируются таблицы маршрутизации. Информация передается волнообразно, и в больших сетях обновление таблиц может происходить медленно. Для устранения этого недостатка сеть разбивают на части (области OSPF) и обмен информацией происходит только внутри частей. При этом уменьшаются также размеры таблиц маршрутизации. Между собой части связаны через пограничные маршрутизаторы, работающие по типу мостов.
2.2 Характеристика протокола RIP
Протокол RIP является дистанционно-векторным протоколом внутренней маршрутизации. Процесс работы протокола состоит в рассылке, получении и обработке векторов расстояний до IP-сетей, находящихся в области действия протокола, то есть в данной RIP-системе. Результатом работы протокола на конкретном маршрутизаторе является таблица, где для каждой сети данной RIP-системы указано расстояние до этой сети (в хопах) и адрес следующего маршрутизатора. Информация о номере сети и адресе следующего маршрутизатора из этой таблицы вносится в таблицу маршрутов, информация о расстоянии до сети используется при обработке векторов расстояний.
Вектором расстояний называется набор пар ("Сеть", "Расстояние до этой сети"), извлеченный из таблицы маршрутов. Расстояние до сети, к которой маршрутизатор подключен непосредственно, примем равным 1.
Каждый маршрутизатор также периодически получает векторы расстояний от других маршрутизаторов. Расстояния в этих векторах увеличиваются на 1, после чего сравниваются с данными в таблице маршрутов, и, если расстояние до какой-то из сетей в полученном векторе оказывается меньше расстояния, указанного в таблице, значение из таблицы замещается новым (меньшим) значением, а адрес маршрутизатора, приславшего вектор с этим значением, записывается в поле "Следующий маршрутизатор" в этой строке таблицы. После этого вектор расстояний, рассылаемый данным маршрутизатором, соответственно изменится.
Протокол RIP (Routing Information Protocol) описанвдокументе RFC 1058. Он представляет собой один из старейших протоколов обмена маршрутной информацией между маршрутизаторами в сети, построенной на базе протокола IP. Помимо версии протокола RIP для сетей IP существует также версия этого протокола для сетей IPX/SPX компании Novell. Сообщения об обновлении таблиц маршрутизации в этом протоколе касаются только устройств, которые разделяют общую сеть. Эти устройства называются соседями. В этом протоколе все сети имеют номера. При этом способ образования номера зависит от используемого в сети протокола сетевого уровня. А все маршрутизаторы имеют свои идентификаторы.
Исторически протокол RIP имеет близкую связь с семейством сетевых протоколов фирмы Xerox. Протокол известен довольно давно, Впервые он появился в 1982 году как часть стека протокола TCP/IP в версии UNIX, разработанной организацией BerkleySoftwareDistribution. При использовании протокола RIP работает эвристический алгоритм динамического программирования Беллмана — Форда. Решение, найденное с его помощью, является близким к оптимальному. Преимуществом протокола RIP является его вычислительная простота. Недостатком — увеличение трафика при периодической рассылке широковещательных сообщений.
Базовый алгоритм обновления маршрута в RIP
 |

![]()
![]()
![]() нет
нет
да
![]()
|
![]()
![]()
![]()
![]()


![]()
![]()
![]()
 нет
нет
![]() нет
нет
![]() да
да
нет
![]()
|
![]()
![]()
![]()
|
|
![]()
![]()
|
2.3. Построение маршрутных таблиц
За исходный примем граф изображенный на рисунке 10.
Таблица№4- Начальное состояние
| R | Сеть назначения | Следующий переход | Дистанция |
| R1 | 10 35 45 |
- - - |
1 1 1 |
| R2 | 15 20 25 |
- - - |
1 1 1 |
| R3 | 30 40 45 50 |
- - - - |
1 1 1 1 |
| R4 | 20 30 |
- - |
1 1 |
| R5 | 25 35 40 |
- - - |
1 1 1 |
| R6 | 10 15 |
- - |
1 1 |
Рассылка маршрутных таблиц начинается с 1-го маршрутизатора и далее последовательно по циклу.
Таблица №5. R1=>R3R5R6
| R | Сеть назначения | Следующий переход | Дистанция |
R3 |
30 40 45 50 10 35
|
- - - - R1 R1 R1 |
1 1 1 1 2 2 2 |
| R5 | 25 35 40 10 35 45 |
- - - R1 R1 R1 |
1 1 2 2 2 |
| R6 | 10 15 10 35 45 |
- - R1 R1 R1 |
1 2 2 2 |
Таблица №6. R2=>R4R5R6
| R | Сеть назначения | Следующий переход | Дистанция |
| R4 | 20 30 15 20 25 |
- - R2 R2 R2 |
1 2 2 2 |
| R5 | 25 35 40 10 45 15 20 25 |
- - - R1 R1 R2 R2 R2 |
1 1 2 2 2 2 2 |
| R6 | 10 15 35 45 15 20 25 |
- - R1 R1 R2 R2 R2 |
1 2 2 2 2 2 |
Таблица №7. R3=>R1R4R5
| R | Сеть назначения | Следующий переход | Дистанция |
| R1 | 10 35 45 30 40 45 50 10 35 |
- - - R3 R3 R3 R3 R3 R3 |
1 1 2 2 2 2 3 3 |
| R4 | 20 30 15 25 30 40 45 50 10 35 |
- - R2 R2 R3 R3 R3 R3 R3 R3 |
1 2 2 2 2 2 2 3 3 |
| R5 | 25 35 40 10 45 15 20 30 40 45 50 10 35 |
- - - R1 R1 R2 R2 R3 R3 R3 R3 R3 R3 |
1 1 2 2 2 2 2 2 2 2 3 3 |
Таблица №8. R4=>R2R3
| R | Сеть назначения | Следующий переход | Дистанция |
| R2 | 15 20 25 20 30 15 25 40 45 50 10 35 |
- - - R4 R4 R4 R4 R4 R4 R4 R4 R4 |
1 1 2 2 3 3 3 3 3 4 4 |
| R3 | 30 40 45 50 10 35 20 30 15 25 40 45 |
- - - - R1 R1 R4 R4 R4 R4 R4 R4 |
1 1 1 2 2 2 2 3 3 3 3 |
Таблица №9. R5=>R1,R2R3.
| R | Сеть назначения | Следующий переход | Дистанция |
| R1 | 10 35 45 30 40 50 25 35 40 10 45 15 20 30 50 |
- - - R3 R3 R3 R5 R5 R5 R5 R5 R5 R5 R5 R5 |
1 1 2 2 2 2 2 2 3 3 3 3 3 3 |
R2 |
15 20 25 30 40 45 50 10 35 25 35 40 10 45 15 20 30 50 |
- - - R4 R4 R4 R4 R4 R4 R5 R5 R5 R5 R5 R5 R5 R5 R5 |
1 1 2 3 3 3 4 4 2 2 2 3 3 3 3 3 3 |
| R3 | 30 40 45 50 10 35 20 15 25 25 35 40 10 45 15 20
|
- - - - R1 R1 R4 R4 R4 R5 R5 R5 R5 R5 R5 R5 R5 R5 |
1 1 1 2 2 2 3 3 2 2 2 3 3 3 3 3 3 |
Таблица №10. R6=>R1R2.
|
Таблица №11. R1=>R3R5R6.
| R | Сеть назначения | Следующий переход | Дистанция |
| R3 | 30 40 45 50 10 35 20 15 25 10 35 45 30 40 50 25 15 20 |
- - - - R1 R1 R4 R4 R5 R1 R1 R1 R1 R1 R1 R1 R1 R1 |
1 1 1 1 2 2 2 3 2 2 2 2 3 3 4 3 3 3 |
| R5 | 25 35 40 10 45 15 20 30 50 10 35 45 30 40 50 25 15 20 |
- - - R1 R1 R2 R2 R3 R3 R1 R1 R1 R1 R1 R1 R1 R1 R1 |
1 1 1 2 2 2 2 2 2 2 2 2 3 3 3 3 4 4 |
| R6 | 10 15 35 45 20 25 10 35 45 30 40 50 25 15 20 |
- - R1 R1 R2 R2 R1 R1 R1 R1 R1 R1 R1 R1 R1 |
1 1 2 2 2 2 2 2 2 3 3 3 3 4 4 |
Дальнейшее рассмотрение построения маршрутных таблиц не имеет смысла так как сходимость достигнута.
Итоговая таблица маршрутизации будет иметь вид:
Таблица №12.
| R | Сеть назначения | Следующий переход | Дистанция |
| R1 | 10 35 45 30 40 50 25 15 20 |
- - - R3 R3 R3 R5 R5 R5 |
1 1 1 2 2 2 2 3 3 |
| R2 | 15 20 25 30 40 45 50 10 35 |
- - - R4 R4 R4 R4 R4 R4 |
1 1 1 2 3 3 3 4 4 |
| R3 | 30 40 45 50 10 35 20 15 25 |
- - - - R1 R1 R4 R4 R4 |
1 1 1 1 2 2 2 3 3 |
| R4 | 20 30 15 25 40 45 50 10 35 |
- - R2 R2 R3 R3 R3 R3 R3 |
1 1 2 2 2 2 2 3 3 |
| R5 | 25 35 40 10 45 15 20 30 50 |
- - - R1 R1 R2 R2 R3 R3 |
1 1 2 2 2 2 2 3 3 |
| R6 | 10 15 35 45 20 25 30 40 50 |
- - R1 R1 R2 R2 R1 R1 R1 |
1 1 2 2 2 2 3 3 3 |
2.4 Отключение канала
Рассмотрим процессы, происходящие в маршрутизаторах при отключении 30 сети.
Таблица №13.
| R | Сеть назначения | Следующий переход | Дистанция |
| R3 | 30 40 45 50 10 35 20 15 25 |
- - - - R1 R1 R4 R4 R4 |
1 1 1 1 2 2 2 3 3 |
| R4 | 20 30 15 25 40 45 50 10 35 |
- - R2 R2 R3 R3 R3 R3 R3 |
1 1 2 2 2 2 2 3 3 |
Таблица №14.R3=>R1R5.
| R | Сеть назначения | Следующий переход | Дистанция |
| R1 | 10 35 45 30 40 50 25 15 20 30 40 45 50 10 35 20 15 25 |
- - - R3 R3 R3 R5 R5 R5 R3 R3 R3 R3 R3 R3 R3 R3 R3 |
1 1 1 2 2 2 2 3 3 10 2 2 2 3 3 3 4 4 |
| R5 | 25 35 40 10 45 15 20 30 50 30 40 45 50 10 35 20 15 25 |
- - - R1 R1 R2 R2 R3 R3 R3 R3 R3 R3
|
1 1 2 2 2 2 2 3 3 10 2 2 2 3 3 3 4 4 |
Таблица №15. R4=>R2.
| R | Сеть назначения | Следующий переход | Дистанция |
| R2 | 15 20 25 30 40 45 50 10 35 20 30 15 25 40 45 50 10 35 |
- - - R4 R4 R4 R4 R4 R4 R4 R4 R4 R4 R4 R4 R4 R4 R4 |
1 1 1 2 3 3 3 4 4 2 10 3 3 3 3 3 4 4 |
Таблица №16. R6=>R1,R2.
| R | Сеть назначения | Следующий переход | Дистанция |
| R1 | 10 35 45 30 40 50 25 15 20 10 15 35 45 20 25 30 40 50 |
- - - R3 R3 R3 R5 R5 R5 R6 R6 R6 R6 R6 R6 R6 R6 R6 |
1 1 1 10 2 2 2 3 3 2 2 3 3 3 3 4 4 4 |
| R2 | 15 20 25 30 40 45 50 10 35 10 15 35 45 20 25 30 40 50 |
- - - R4 R4 R4 R4 R4 R4 R6 R6 R6 R6 R6 R6 R6 R6 R6 |
1 1 1 10 3 3 3 4 4 2 2 3 3 3 3 4 4 4 |
Таблица №17. R1=>R3,R5,R6.
| R | Сеть назначения | Следующий переход | Дистанция |
| R3 | 30 40 45 50 10 35 20 15 25 10 35 45 30 40 50 25 15 20 |
- - - - R1 R1 R4 R4 R4
|
10 1 1 1 2 2 2 3 3 2 2 2 5 3 3 3 4 4 |
| R5 | 25 35 40 10 45 15 20 30 50 10 35 45 30 40 50 25 15 20 |
- - - R1 R1 R2 R2 R3 R3
R1
R1 |
1 1 2 2 2 2 2 10 3
3
4 |
| R6 | 10 15 35 45 20 25 30 40 50 10 35 45 30 40 50 25 15 20 |
- - R1 R1 R2 R2 R1 R1 R1 R1 R1 R1 R1 R1 R1 R1 R1 R1 |
1 1 2 2 2 2 3 3 3 2 2 2 5 3 3 3 4 4 |
Таблица №18. R5=>R1,R2,R3.
| R | Сеть назначения | Следующий переход | Дистанция |
| R1 | 10 35 45 30 40 50 25 15 20 25 35 40 10 45 15 20 50 30 |
- - - R3 R3 R3 R5 R5 R5 R5 R5 R5 R5 R5 R5 R5 R5 R5 |
1 1 1 2 2 2 2 3 3 2 2 3 3 3 3 3 4 4 |
| R2 | 15 20 25 30 40 45 50 10 35 25 35 40 10 45 15 20 50 30 |
- - - R4 R4 R4 R4 R4 R4
R5
R5 |
1 1 1 2 3 3 3 4 4
3
4 |
| R3 | 30 40 45 50 10 35 20 15 25 25 35 40 10 45 15 20 50 30 |
- - - - R1 R1 R4 R4 R4 R5 R5 R5 R5 R5 R5 R5 R5 R5 |
10 1 1 1 2 2 2 3 3
3
4 |
Таблица №19. R2=>R4,R5,R6.
| R | Сеть назначения | Следующий переход | Дистанция |
| R4 | 20 30 15 25 40 45 50 10 35 15 20 25 30 40 45 50 10 35 |
- - R2 R2 R3 R3 R3 R3 R3 R2 R2 R2 R2 R2 R2 R2 R2 R2 |
1 1 2 2 2 2 2 3 3 2 2 2 3 4 4 4 5 5 |
| R5 | 25 35 40 10 45 15 20 30 50 15 20 25 30 40 45 50 10 35 |
- - - R1 R1 R2 R2 R3 R3 R2 R2 R2 R2 R2 R2 R2 R2 R2 |
1 1 2 2 2 2 2 10 3 2 2 2 3 4 4 4 5 5 |
| R6 | 10 15 35 45 20 25 40 50 30 15 20 25 30 40 45 50 10 35 |
- - R1 R1 R2 R2 R1 R1 R1 R2 R2 R2 R2 R2 R2 R2 R2 R2 |
1 1 2 2 2 2 3 3 5 2 2 2 3 4 4 4 5 5 |
Таблица №20. R3=>R1R5.
| R | Сеть назначения | Следующий переход | Дистанция |
| R1 | 10 35 45 30 40 50 25 15 20 30 40 45 50 10 35 20 15 25 |
- - - R3 R3 R3 R5 R5 R5 R3 R3 R3 R3 R3 R3 R3 R3 R3 |
1 1 1 2 2 2 2 3 3 10 1 1 1 2 2 2 3 3 |
| R5 | 25 35 40 10 45 15 20 30 50 30 40 45 50 10 35 20 15 25 |
- - - R1 R1 R2 R2 R3 R3 R3 R3 R3 R3 R3 R3 R3 R3 R3 |
1 1 2 2 2 2 2 10 3 10 1 1 1 2 2 2 3 3 |
Итоговая таблица маршрутизации будет иметь вид:
Таблица №21.
| R | Сеть назначения | Следующий переход | Дистанция |
| R1 | 10 35 45 30 40 50 25 15 20 |
- - - R3 R3 R3 R5 R5 R5 |
1 1 1 2 2 2 2 3 3 |
| R2 | 15 20 25 30 40 45 50 10 35 |
- - - R4 R4 R4 R4 R4 R4 |
1 1 1 2 3 3 3 4 4 |
| R3 | 30 40 45 50 10 35 20 15 25 |
- - - - R1 R1 R4 R4 R4 |
10 1 1 1 2 2 2 3 3 |
| R4 | 20 30 15 25 40 45 50 10 35 |
- - R2 R2 R3 R3 R3 R3 R3 |
1 1 2 2 2 2 2 3 3 |
| R5 | 25 35 40 10 45 15 20 30 50 |
- - - R1 R1 R2 R2 R3 R3 |
1 1 2 2 2 2 2 10 3 |
| R6 | 10 15 35 45 20 25 40 50 30 |
- - R1 R1 R2 R2 R1 R1 R1 |
1 1 2 2 2 2 3 3 5 |
Заключение
При выполнении курсового проекта мною были рассмотрены алгоритмы поиска кратчайшего пути (алгоритм Дейкстры и алгоритм Беллмана- Форда), по алгоритму Беллмана- Форда результат достигается за меньшее количесво шагов. Также в курсовом проекте был произведён расчёт пути с минимальным количеством переходов, где исходный граф был преобразован в неориентированный, невзвешенный граф. Результаты при этом расчёте оказались другими. Были описаны основы маршрутизации (алгоритмы, адаптивные протоколы), приведено построение маршрутных таблиц.
Список использованной литературы
1 Кульгин М. В. Коммутация и маршрутизация IР/IРХ-трафика
2. Столлингс В. Современные компьютерные сети. – 2003. (Глава 14. Теория графов и поиск путей с минимальной стоимостью)