| Скачать .docx |
Реферат: Распределенные информационные системы
Оглавление
ВВЕДЕНИЕ 4
1.ПОНЯТИЕ РАСПРЕДЕЛЕННЫХ ИС 6
1.1. Предпосылки создания распределенных ИС 6
1.2. Понятие распределенных информационных систем 8
1.3. Средства работы с распределенными данными 11
2. РАСПРЕДЕЛЕННЫЕ БАЗЫ ДАННЫХ 13
2.1. Основные принципы 13
2.2 Типы распределенных БД 15
2.3. Назначение и принцип работы распределенной БД 16
3. ПРИМЕРЫ РАСПРЕДЕЛЕННЫХ СИСТЕМ 21
ЗАКЛЮЧЕНИЕ 25
ЛИТЕРАТУРА 26
ВВЕДЕНИЕ
Актуальность данной темы реферата состоит в том, что в мировой экономике происходят процесса глобализации и информационной интеграции. Они затронули и нашу страну, которая в силу географического положения и размеров вынуждена применять распределенные информационные системы (ИС). Распределенные ИС обеспечивают работу с данными, расположенными на разных серверах, различных аппаратно-программных платформах и хранящимися в различных форматах. Они легко расширяются, основаны на открытых стандартах и протоколах, обеспечивают интеграцию своих ресурсов с другими ИС, предоставляют пользователям простые интерфейсы.
В мире существует громадное количество готовых к использованию информационно-вычислительных ресурсов. Они создавались в разное время, для их разработки использовались разные подходы. Почти всегда при разработке новой информационной системы можно найти подходящие по своим функциям уже работающие готовые компоненты. Проблема состоит в том, что при их создании не учитывались требования несовместимости. Эти компоненты не понимают один другого, они не могут работать совместно. Желательно иметь механизм или набор механизмов, которые позволят сделать такие независимо разработанные информационно-вычислительные ресурсы совместимыми.
В данной работе рассмотрены основные сведения о распределенной информационной системе: описаны предпосылки ее развития, средства работы с данными, введено понятие распределенной базы данных, а также ее типов и основных принципов. В третьей главе представлены примеры распределенных информационных систем, такие как: - Informix On-Line фирмы Informix Software;- Ingres Intelligent Database фирмы Ingres Corp;- Oracle (version 7) фирмы Oracle Corp;- Sybase System 10 фирмы Sybase Inc.
Целью исследования является изучение теоретических основ о распределенных информационных системах, а также формирование знаний о принципах ее работы.
Такое распределение данных позволяет, например, хранить в узле сети те данные, которые наиболее часто используются в этом узле. Такой подход облегчает и ускоряет работу с этими данными и оставляет возможность работать с остальными данными БД.
1.ПОНЯТИЕ РАСПРЕДЕЛЕННЫХ ИС
1.1. Предпосылки создания распределенных ИС
C самого начала развития вычислительной техники образовались два основных направления ее использования. Первое направление - применение вычислительной техники для выполнения численных расчетов, которые слишком долго или вообще невозможно производить вручную. Становление этого направления способствовало интенсификации методов численного решения сложных математических задач, развитию класса языков программирования, ориентированных на удобную запись численных алгоритмов, становлению обратной связи с разработчиками новых архитектур ЭВМ.
Второе направление - это использование средств вычислительной техники в автоматических или автоматизированных информационных системах. Обычно объемы информации, с которыми приходится иметь дело таким системам, достаточно велики, а сама информация имеет достаточно сложную структуру. Одними из естественных требований к таким системам являются средняя быстрота выполнения операций и сохранность информации.
Но поскольку информационные системы требуют сложных структур данных, эти индивидуальные дополнительные средства управления данными являлись существенной частью информационных систем и практически повторялись от одной системы к другой. Стремление выделить и обобщить общую часть информационных систем, ответственную за управление сложно структурированными данными, и явилось, судя по всему, первой побудительной причиной создания различных систем управления.
Очень скоро стало понятно, что невозможно обойтись общей библиотекой программ, реализующей над стандартной базовой файловой системой более сложные методы хранения данных, например, хранение информации в нескольких файлах. Таким образом, все это способствовало созданию распределенных информационных систем.
Фактически, если информационная система поддерживает согласованное хранение информации в нескольких файлах, можно говорить о том, что она поддерживает базу данных. Если же некоторая вспомогательная система управления данными позволяет работать с несколькими файлами, обеспечивая их согласованность, можно назвать ее системой управления базами данных. Уже только требование поддержания согласованности данных в нескольких файлах не позволяет обойтись библиотекой функций: такая система должна иметь некоторые собственные данные (метаданные) и даже знания, определяющие целостность данных [1].
В мире существует громадное количество готовых к использованию информационно-вычислительных ресурсов. Они создавались в разное время, для их разработки использовались разные подходы. Почти всегда при разработке новой информационной системы можно найти подходящие по своим функциям уже работающие готовые компоненты.
1.2. Понятие распределенных информационных систем
Обычно, распределенной считают такую систему, в которой функционирует более одного сервера БД. Это применяется для уменьшения нагрузки на сервер и обеспечения работы территориально удаленных подразделений. Различная сложность создания, модификации, сопровождения, интеграции с другими системами позволяют разделить ИС на классы малых, средних и крупных распределенных систем. Малые ИС имеют небольшой жизненный цикл (ЖЦ), ориентацию на массовое использование, невысокую цену, невозможность модификации без участия разработчиков, использующие в основном настольные системы управления базами данных (СУБД) , однородное аппаратно-программное обеспечение, не имеющие средств обеспечения безопасности. Крупные корпоративные ИС, системы федерального уровня и другие имеют длительный жизненный цикл, миграцию унаследованных систем, разнообразие аппаратно-программного обеспечения, масштабность и сложность решаемых задач, пересечение множества предметных областей, аналитическую обработку данных, территориальную распределенность компонент [2].
К функциям таких ИС следует отнести, прежде всего, работу с распределенными данными, расположенными на разных физических серверах, различных аппаратно-программных платформах и хранящихся в различных внутренних форматах. В этом случае система должна предоставлять полную информацию о себе и всех своих ресурсах, легко расширяться, быть основана на открытых стандартах и протоколах, обеспечивать возможность интегрировать свои ресурсы с ресурсами других ИС. Для пользователей система должна обеспечивать различные уровни привилегий для пользователей и предоставлять простые интерфейсы доступа к информации.
Данные из разнородных систем обычно объединяются в логические группы, к которой и адресуются запросы. Абстрактная система запросов предполагает, что система оперирует не конкретным синтаксисом запросов, а его логической сутью на основе абстрактных атрибутов.
При построении распределенных ИС, как правило, используются две базовые архитектуры: Клиент/сервер и Internet Intranet.
Корпоративные ИС, построенные по архитектуре Клиент/сервер, предоставляют клиентам широкий спектр приложений и инструментов разработки, которые ориентированы на максимальное использование вычислительных возможностей клиентских рабочих мест. Ресурсы сервера используются в основном для хранения и обмена документами, а также для выхода во внешнюю среду. Данная архитектура позволяет лучше защитить серверную часть приложений, при этом, предоставляя возможность приложениям либо непосредственно адресоваться к другим серверным приложениям, либо маршрутизировать запросы к ним. Однако, частые обращения клиента к серверу снижают производительность работы сети. Приходится решать вопросы безопасной работы в сети, так как приложения и данные распределены между различными клиентами. Распределенный характер построения системы обусловливает сложность ее настройки и сопровождения
В основе ИС на базе Internet Intranet лежит принцип "открытой архитектуры". ПО ИС реализуется в виде аплетов или сервлетов (программ на языке JAVA) или в виде cgi модулей (программ на Perl или С). ИС данной архитектуры включает Web-yinh\, реализованные при помощи технологий CORBA Enterprise JavaBeans, ActiveX 1X'ОМ, многоуровневые приложения на основе Java и XML, .Net-концепция с XML, в которой обмен между различными серверами (хранилищами данных, бизнес-приложениями, серверами для мобильных клиентов и другое) производится при помощи нейтрального к любой архитектуре XML.
Под распределенной информационной базой понимается неограниченное количество баз данных, дистанционно отдаленных друг от друга и имеющих ряд общих характеристик:
- функционирующих по единым правилам, определенным централизованно для всех баз данных, входящих в распределенную информационную базу;
- обмен данными осуществляется по правилам, также определенным централизованно.
Организация распределенной базы необходима для компаний, осуществляющих различные виды деятельности, если в их повседневной работе возникает потребность решения следующих задач:
- необходимость оперативного получения информации из баз данных дистанционно отдаленных подразделений (или филиалов);
-необходимость консолидации в единой базе данных информации из баз данных юридических лиц, входящих в структуру компании, для последующего анализа данных и получения отчетности из одной базы, как по компании в целом, так и по каждому юридическому лицу в отдельности;
- необходимость введения централизованного изменения структуры и правил работы баз данных для работы всех дистанционно отдаленных подразделений (филиалов) и юридических лиц (с невозможностью изменения определенных правил непосредственно в отдаленном подразделении);
- необходимость ограничения и осуществления контроля изменения данных в дистанционно отдаленных подразделениях компании (филиалах) [3].
1.3. Средства работы с распределенными данными
При выборе распределенной ИС в первую очередь следует обратить внимание на то, какие операционные системы и сетевые протоколы она поддерживает. Однако не менее важным является и то, какие методы распределения данных в ней реализованы.
1) Фрагментация и дублирование
Один из способов распределенного хранения таблиц - это фрагментация. Таблица может быть расщеплена на части, которые будут помещены в разные узлы. Другой способ распределения данных - это дублирование (репликация). Можно создать дубли всей БД или ее частей и разместить эти дубли в узлах. Оба метода позволяют хранить данные именно в том узле, где они наиболее часто используются. Это сводит к минимуму затраты на передачу данных по сети и уменьшает использование процессоров и прочих ресурсов остальных узлов. При такой архитектуре БД приложения передача данных по сети выполняется достаточно редко.
2) Словари данных и директории
После того, как данные распределены по разным узлам сети, важно найти и использовать эти данные. Для того, чтобы найти данные и преобразовать их в нужный формат, используются глобальные словари данных и директории. В словаре хранится информация о данных, их использовании, правах доступа к данным, а также о приложениях. Директории данных используются для того, чтобы определить, где хранятся данные и как их извлечь. Словари и директории могут быть глобальными и локальными
3) Двухфазная фиксация изменений
Методы распределения данных конечно очень важны, однако сердцем современных распределенных СУБД является протокол двухфазной фиксации изменений. Этот протокол управляет выполнением транзакций, изменяющих данные нескольких узлов. Основная идея двухфазной фиксации заключается в следующем: недопустима ситуация при которой транзакция, изменяющая данные в нескольких узлах, выполняется в одних узлах и не выполняется в других узлах. Транзакция должна быть либо успешно выполнена во всех узлах, либо не выполнена ни в одном узле.
4) Обеспечение целостности
Важной характеристикой распределенной ИС является то, как она обеспечивает поддержку ссылочной целостности между данными таблицы-мастера и данными связанных с ней таблиц. Рассмотрим пример ссылочной целостности. Предположим в распределенной БД имеются три таблицы:
- таблица, содержащая информацию о детях сотрудников;
- таблица, содержащая информацию о зарплатах сотрудников за год;
- таблица, содержащая информацию о темах, выполненных сотрудником.
Все эти таблицы содержат столбец "ФИО сотрудника". Правила обеспечения ссылочной целостности требуют, чтобы при изменении значений столбца "ФИО сотрудника" в одной таблице, автоматически выполнялась корректировка значений этого столбца в других таблицах. Для обеспечения ссылочной целостности используются 2 различных метода - триггеры и декларативные ограничения целостности стандарта ANSI [4].
2. РАСПРЕДЕЛЕННЫЕ БАЗЫ ДАННЫХ
2.1. Основные принципы
Распределённые базы данных (РБД) — совокупность логически взаимосвязанных баз данных, распределённых в компьютерной сети.
РБД состоит из набора узлов, связанных коммуникационной сетью, в которой:
а)каждый узел — это полноценная СУБД сама по себе;
б)узлы взаимодействуют между собой таким образом, что пользователь любого из них может получить доступ к любым данным в сети так, как будто они находятся на его собственном узле [5].
Каждый узел сам по себе является системой базы данных. Любой пользователь может выполнить операции над данными на своём локальном узле точно так же, как если бы этот узел вовсе не входил в распределённую систему. Распределённую систему баз данных можно рассматривать как партнёрство между отдельными локальными СУБД на отдельных локальных узлах.
Фундаментальный принцип создания распределённых баз данных («правило 0»): Для пользователя распределённая система должна выглядеть так же, как нераспределённая система.
Фундаментальный принцип имеет следствием определённые дополнительные правила или цели. Таких целей всего двенадцать:
1.Локальная независимость. Узлы в распределённой системе должны быть независимы, или автономны. Локальная независимость означает, что все операции на узле контролируются этим узлом.
2.Отсутствие опоры на центральный узел. Локальная независимость предполагает, что все узлы в распределённой системе должны рассматриваться как равные. Поэтому не должно быть никаких обращений к «центральному» или «главному» узлу с целью получения некоторого централизованного сервиса.
3.Непрерывное функционирование. Распределённые системы должны предоставлять более высокую степень надёжности и доступности.
4.Независимость от расположения. Пользователи не должны знать, где именно данные хранятся физически и должны поступать так, как если бы все данные хранились на их собственном локальном узле.
5.Независимость от фрагментации. Система поддерживает независимость от фрагментации, если данная переменная-отношение может быть разделена на части или фрагменты при организации её физического хранения. В этом случае данные могут храниться в том месте, где они чаще всего используются, что позволяет достичь локализации большинства операций и уменьшения сетевого трафика.
6.Независимость от репликации. Система поддерживает репликацию данных, если данная хранимая переменная-отношение — или в общем случае данный фрагмент данной хранимой переменной-отношения — может быть представлена несколькими отдельными копиями или репликами, которые хранятся на нескольких отдельных узлах.
7.Обработка распределённых запросов. Суть в том, что для запроса может потребоваться обращение к нескольким узлам. В такой системе может быть много возможных способов пересылки данных, позволяющих выполнить рассматриваемый запрос.
8.Управление распределёнными транзакциями. Существует 2 главных аспекта управления транзакциями: управление восстановлением и управление параллельностью обработки. Что касается управления восстановлением, то чтобы обеспечить атомарность транзакции в распределённой среде, система должна гарантировать, что все множество относящихся к данной транзакции агентов (агент — процесс, который выполняется для данной транзакции на отдельном узле) или зафиксировало свои результаты, или выполнило откат. Что касается управления параллельностью, то оно в большинстве распределённых систем базируется на механизме блокирования, точно так, как и в нераспределённых системах.
9.Аппаратная независимость. Желательно иметь возможность запускать одну и ту же СУБД на различных аппаратных платформах и, более того, добиться, чтобы различные машины участвовали в работе распределённой системы как равноправные партнёры.
10.Независимость от операционной системы. Возможность функционирования СУБД под различными операционными системами.
11.Независимость от сети. Возможность поддерживать много принципиально различных узлов, отличающихся оборудованием и операционными системами, а также ряд типов различных коммуникационных сетей.
12.Независимость от типа СУБД. Необходимо, чтобы экземпляры СУБД на различных узлах все вместе поддерживали один и тот же интерфейс, и совсем необязательно, чтобы это были копии одной и той же версии СУБД [6].
Основная задача систем управления распределенными базами данных состоит в обеспечении средства интеграции локальных баз данных, располагающихся в некоторых узлах вычислительной сети, с тем, чтобы пользователь, работающий в любом узле сети, имел доступ ко всем этим базам данных как к единой базе данных.
2.2. Типы распределенных БД
Возможны однородные и неоднородные распределенные базы данных. В однородном случае каждая локальная база данных управляется одной и той же СУБД. В неоднородной системе локальные базы данных могут относиться даже к разным моделям данных.
Помимо вышеназванных типов распределенных баз данных можно выделить следующие:
1) Распределённые Базы Данных
2) Мультибазы данных с глобальной схемой. Система Мультибаз данных - это распределённая система, которая служит внешним интерфейсом для доступа ко множеству локальных СУБД или структурируется, как глобальный уровень над локальными СУБД.
3) Федеративные базы данных. В отличие от мультибаз не располагают глобальной схемой, к которой обращаются все приложения. Вместо этого поддерживается локальная схема импорта-экспорта данных. На каждом узле поддерживается частичная глобальная схема, описывающая информацию тех удалённых источников, данные с которых необходимы для функционирования.
4) Мультибазы с общим языком доступа - распределённые среды управления с технологией "клиент-сервер"
5) Интероперабельные системы - это системы, в которых сами приложения, выполняемые в среде той или иной СУБД, ответственны за интерфейсы между различными средами приложения, независимо от того, являются они однородными или неоднородными. Системы ориентированы главным образом на обмен данными. Дальнейшее развитие этих систем является объектно-ориентированные БД [7].
2.3. Назначение и принцип работы распределенной БД
Когда у предприятия есть удаленные филиалы, возникает необходимость в синхронизации данных между ними и главным офисом. Естественно, что в основной базе предприятия должны отображаться любые изменения касательно филиалов. Такую синхронизацию можно осуществлять при помощи механизмов распределенной базы данных.
В главном офисе создаются начальные образы базы (для каждого филиала - свой образ) и передаются в филиалы, где их загружают. При этом задаются настройки обмена, по которым будет происходить синхронизация между каждой из периферийных (подчиненных) баз и главной базой.
Структура предприятия может быть такова, что у филиалов, подчиненных главному офису, могут быть свои удаленные подразделения. Тогда для них производят процедуру аналогичную той, что была совершена при настройке филиалов, подчиненных напрямую главной базе [8].
Таким образом, можно подытожить, что в распределенной базе формируются древообразные связи. Например, на предприятии главному офису подчинено два филиала, причем у первого филиала есть два удаленных подразделения, а у второго - три подразделения. Получается, что основной базе подчинено две периферийных базы. Первой периферийной базе, в свою очередь, подчинено еще две базы, а второй периферийной - три. Связи в такой распределенной базе представлены на рис. 2.1.
![]()
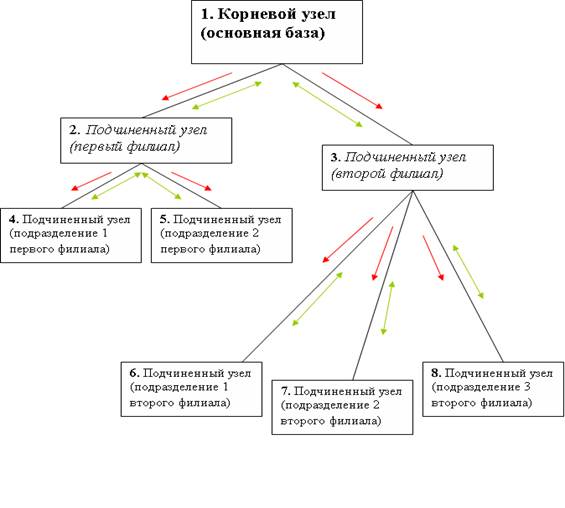 Рис.2.1. Принцип работы БД
Рис.2.1. Принцип работы БД
Узел 1 является корневым для всей распределенной базы и главным узлом для подчиненных ему второму и третьему. Второй узел является главным узлом для подчиненных ему четвертому и пятому. Третий узел будет главным для подчиненных ему шестому, седьмому и восьмому.
Любой узел распределенной базы данных (УРБД) "видит" только узлы, напрямую связанные с ним. С такими узлами он и осуществляет обмен данными.
Внесение изменений в данные информационной базы возможно в любом узле УРБД, причем изменения данных передаются между любыми связанными узлами. На схеме направления, по которым передаются изменения данных, обозначены зелеными стрелочками (по ним из любого узла УРБД за определенное количество шагов можно попасть в любой другой узел, отсюда следует, что при внесении изменений в данные любого узла эти изменения постепенно перенесутся во все остальные).
Внесение изменений в конфигурацию информационной базы возможно только в одном (корневом) узле УРБД, причем изменения конфигурации передаются от главного узла к подчиненным. На схеме направления, по которым передаются изменения конфигурации, обозначены красными стрелочками [9].
Теперь рассмотрим, каким образом осуществляется обмен данными между узлами УРБД. При внесении изменений в данные информационной базы программа запоминает, что было изменено и каким образом. Для любого узла раз в определенный промежуток времени запускается обработка (вручную либо автоматически), которая формирует специальные сообщения, в каких в формате XML отображена информация о том, были ли изменения (если были, то какие), и отправляет их в определенные каталоги по локальной сети либо по FTP, или же на определенные адреса электронной почты. Также обработка проверяет, появились ли в этом каталоге либо электронном ящике аналогичные сообщения от других узлов, связанных напрямую с этим узлом, адресованные ему. Если появились, то загрузит сообщения, а следовательно и изменения в данных. Инфраструктура сообщений поддерживает нумерацию сообщений, и позволяет получать подтверждения от узла-получателя о приеме сообщений. Такое подтверждение содержится в каждом сообщении, приходящем от узла-получателя в виде номера последнего принятого сообщения.
Если узел-приемник еще не успел загрузить сообщение из каталога обмена , узел-источник не будет выкладывать, а тем более формировать файл сообщений в каталог обмена по этому узлу. Подразумевается, что после успешной загрузки, файл удаляется из каталога обмена. Это позволяет не осуществлять лишние операции при обмене и не загружать канал лишний раз.
При изменении конфигурации базы информация об изменениях распространяется в сообщениях обмена вместе с изменениями данных.
Обмен данными между базами производится следующим образом:
1)В базе-источнике система определяет список изменённых объектов за время, прошедшее с предыдущего сеанса выгрузки данных.
2)По данному списку система формирует XML-пакет, который передается в базу-приемник.
Для того чтобы сформировать пакет система обращается к измененным объектам базы данных. При обращении система блокирует данные объекты.
3) XML-пакет передается в базу-приемник.
В базе-приемнике XML-пакет разворачивается и изменения, содержащиеся в нем, вносятся в базу.
Все изменения записываются в рамках одной транзакции, при этом все измененные объекты блокируются.
3. ПРИМЕРЫ РАСПРЕДЕЛЕННЫХ СИСТЕМ
Сегодня практически все крупнейшие производители систем управления базами данных предлагают решения в области управления распределенными ресурсами. Однако все эти решения поддерживают ограниченные функции построения неоднородных распределенных систем.
Среди многочисленных прототипов и научно-исследовательских систем следует упомянуть систему SDD-1 , созданную в конце 70-х -- начале 80-х годов в научно-исследовательском отделении фирмы Computer Corporation of America; систему R* , которая является распределенной версией системы System R и создана в начале 80-х годов фирмой IBM; а также систему Distributed INGRES , которая является распределенной версией системы INGRES и создана также в начале 80-х годов в Калифорнийском университете в Беркли.
Что касается коммерческих продуктов, то в настоящее время в большинстве реляционных систем предусмотрены разные виды поддержки использования распределенных баз данных с разной степенью функциональности. Среди таких систем наиболее известны система INGRES/STAR отделения Ingres Division фирмы The ASK Group Inc., система ORACLE фирмы Oracle Corporation, а также модуль распределенной работы системы DB2 фирмы IBM.
Сегодня многие фирмы - разработчики СУБД заявляют о том, что они поддерживают работу с распределенными БД, однако при ближайшем рассмотрении в большинстве случаев эти заявления оказываются несколько преувеличенными. Специалисты в области СУБД считают, что только несколько пакетов СУБД позволяют в некоторой степени реализовать распределенную базу данных.
В работе [3] дано следующее определение распределенной БД: "Распределенная БД - это множество физических баз данных, которые выглядят для пользователя как одна логическая БД". К сожалению, на сегодняшний день ни одна СУБД полностью не реализует это определение. Наиболее близко к его реализации подошли следующие СУБД:
- Informix On-Line фирмы Informix Software;
- Ingres Intelligent Database фирмы Ingres Corp;
- Oracle (version 7) фирмы Oracle Corp;
- Sybase System 10 фирмы Sybase Inc.
Хотя ни одна из этих 4 СУБД полностью не реализует все функции распределенной СУБД, однако каждая из них реализует или в скором времени будет реализовывать поддержку работы с распределенной БД.
Наиболее полно функции распределенной СУБД реализованы в СУБД Ingres и Oracle. Коротко рассмотрим возможности этих пакетов.
СУБД Ingres работает на множестве UNIX-платформ, на платформах DEC VMS, Hewlett-Packard MPE, DOS, Microsoft Windows 3.1, OS/2, Macintosh. Она также работает со многими сетевыми протоколами, включая Open System Interconnection Transport Class 4. Ingres имеет средства для доступа к данным СУБД DB2, Rdb, Allbase. Основные функции распределенной СУБД обеспечиваются дополнительной компонентой Ingres/Star. Она поддерживает оптимизацию распределенных запросов, позволяет читать и обновлять в рамках одной транзакции данные разных узлов, обеспечивает возможность удалять записи одновременно в нескольких узлах.
СУБД Informix-Online разработана для среды UNIX, но может также работать под Novell. Informix-Online имеет оптимизатор запросов и реализует те же функции работы с распределенной БД, что и Ingres, однако у Informix более жесткие требования к ресурсам компьютера, в частности ему требуется больше оперативной памяти.
СУБД System 10 фирмы Sybase в настоящее время находится в состоянии разработки. Она должна работать на UNIX-платформах, на платформах OS/2, Window NT, NetWare. System 10 будет работать с несколькими сетевыми протоколами и поддерживать связь с СУБД DB2, Oracle 7, Informix-Online, Rdb. System 10 будет иметь оптимизатор распределенных запросов, она позволит читать и обновлять данные нескольких узлов. Функции работы с распределенной БД будут реализованы с помощью дополнительной компоненты Replication Server.
В 7 версии СУБД Oracle реализовано множество функций для работы с распределенной БД. Среди них следует выделить оптимизатор распределенных запросов и средство чтения и обновления данных нескольких узлов в рамках одной транзакции. Oracle v 7 работает на более чем 80 вычислительных платформах, поддерживает большинство существующих коммерческих сетевых протоколов и может обмениваться данными с СУБД DB2, SQL/DS, Tandem Computers, NonStop SQL, Rdb, HP TurboImage. Разрабатываются шлюзы еще к 18 СУБД.
В Oracle словарь данных хранится также, как остальные данные, поэтому его таблицы могут быть распределены по узлам сети. Все операции с распределенной БД "прозрачны" для пользователей и разработчиков. В области обновления распределенной БД Oracle обогнал всех своих конкурентов. Пользователи Oracle могут с помощью компоненты SQL*Net "прозрачно" работать с данными (не обязательно данными Oracle), размещающимися на различных типах компьютеров и в различных узлах сети. Высокопроизводительное средство "прозрачного" обновления распределенной БД реализовано на основе оригинально выполненного двухфазного протокола фиксации изменений.
Все 4 рассмотренные СУБД поддерживают локальную автономию узлов. Это означает, что администратор БД может рассматривать локальную БД конкретного узла как самостоятельную БД. Все СУБД поддерживают ANSI стандарт языка SQL - ANSI SQL-89 и расширение этого стандарта. Запросы к БД формулируются на языке SQL. Дополнительно к непроцедурному языку SQL Oracle поддерживает свой собственный процедурный язык PL/SQL, а Sybase поддерживает свой язык Transact-SQL.
Все 4 СУБД обеспечивают "прозрачный" механизм запроса, обновления и просмотра данных, размещенных в нескольких узлах. Уже отмечалось, что все 4 СУБД могут обмениваться данными с другими СУБД. Однако только двухфазный протокол фиксации Oracle 7 позволяет выполнять распределенные обновления данных в разных СУБД. Проблема заключается в том, что двухфазные протоколы фиксации изменений разных СУБД плохо совместимы между собой [10].
Все 4 пакета обеспечивают выполнение локальной и глобальной блокировки данных. Однако они реализуют эту блокировку на различных уровнях. Так Oracle по умолчанию реализует блокировку на уровне записи, а остальные СУБД - на уровне страницы или таблицы. Механизм блокировок позволяет предотвратить изменение данных, которые в это время контролируются другими пользователями. Тем самым обеспечивается целостность и непротиворечивость данных. Блокировка на уровне записи позволяет одновременно обновлять соседние записи одной и той же таблицы. Это резко снижает время ожидания, ускоряет обработку данных и уменьшает вероятность возникновения взаимоблокировок.
Все фирмы-разработчики распределенных СУБД намерены в будущем поддерживать архитектуру распределенной базы данных фирмы IBM (Distributed Relational Database Architecture). Правда хотя IBM уже давно объявила о начале работ по реализации этой архитектуры, она до сих пор не закончена. Это очевидно связано с очень высокой сложностью реализации объявленной архитектуры.
ЗАКЛЮЧЕНИЕ
Организация распределенной базы необходима для компаний, осуществляющих различные виды деятельности, если в их повседневной работе возникает потребность решения следующих задач:
- необходимость оперативного получения информации из баз данных дистанционно отдаленных подразделений (или филиалов);
- необходимость консолидации в единой базе данных информации из баз данных юридических лиц, входящих в структуру компании, для последующего анализа данных и получения отчетности из одной базы, как по компании в целом, так и по каждому юридическому лицу в отдельности;
- необходимость введения централизованного изменения структуры и правил работы баз данных для работы всех дистанционно отдаленных подразделений (филиалов) и юридических лиц (с невозможностью изменения определенных правил непосредственно в отдаленном подразделении);
- необходимость ограничения и осуществления контроля изменения данных в дистанционно отдаленных подразделениях компании (филиалах).
Основная задача систем управления распределенными базами данных состоит в обеспечении средства интеграции локальных баз данных, располагающихся в некоторых узлах вычислительной сети, с тем, чтобы пользователь, работающий в любом узле сети, имел доступ ко всем этим базам данных как к единой базе данных.
Таким образом, распределенные информационные системы являются неотъемлемой частью современной информационной системы. При этом должны обеспечиваться: простота использования системы; возможности автономного функционирования при нарушениях связности сети или при административных потребностях; высокая степень эффективности.
ЛИТЕРАТУРА
1. Как организовать распределенную информационную базу?
http://www.intelis-it.ru/services/automation_act/information-systems.html
2. Распределенные базы данных. Википедия.
http://ru.wikipedia.org/wiki/распереленные_бд
3. Бойко В.В., Савинков В.М. Проектирование баз данных информационных систем. – 2-е изд. – М.: Финансы и статистика, 1989. – 350 с.
4. Дейт К. Дж. Введение в системы баз данных.: Пер. с англ. – 6-е изд. – Киев: Диалектика, 1998. – 784 с.
5. Распределенные информационные системы и базы данных. Глеб Ладыженский
http://articles.org.ru/cfaq/index.php?qid=1306&catid=54
6. . Глобально распределенные информационные системы
http://www.ci.ru/inform4_97/astr1.htm
7. Проектирование структуры распределенной базы данных.
http://www.integro.ru/projects/gis/quest_1.htm
8. Коннолли, Т., Бегг, К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика. 3-е издание.: Пер. с англ. — М.: Издательский дом «Вильяме», 2003. – 433 с.
9. Лекция 20. Распределенные БД
http://www.lcard.ru/~nail/database/osbd/glava_~3.htm
10. Технологии распределенных баз данных
http://rema.44.ru//resurs/study/dblab/dblab.html.