| Скачать .docx |
Курсовая работа: Структури даних для обробки інформації
Зміст
РОЗДІЛ І. ДИНАМІЧНІ СТРУКТУРИ ДАНИХ
РОЗДІЛ ІІ. ДЕРЕВА. БІНАРНЕ ДЕРЕВО
2.1. РЕАЛІЗАЦІЯ БІНАРНОГО ДЕРЕВА ЗА ДОПОМОГОЮ ДИНАМІЧНИХ ЗМІННИХ
СПИСОК ВИКОРИСТАНОЇ ЛІТЕРАТУРИ
Сучасні алгоритми працюють з великим обсягом інформації, і тому час пошуку у таких алгоритмах є критичним. Таким чином, актуальним є розроблення структур даних для ефективного зберігання та обробки інформації.
Однією з таких структур є бінарне дерево. Це динамічна структура даних, розмір якої обмежується тільки розміром віртуальної пам’яті комп’ютера. Бінарні дерева забезпечують пошук конкретного значення, максимуму, мінімуму, попереднього, наступного, операції вставки та видалення елемента.
Пошук у збалансованому дереві виконується за час O(log2 n), але звичайні бінарні дерева можуть вироджуватись у список, при цьому пошук вже триватиме O(n) часу.
У повсякденному житті ми дуже часто зустрічаємо приклади дерев. Наприклад, люди часто використовують генеалогічне дерево для зображення структури свого роду; як ми побачимо, багато термінів, пов'язаних з деревами, узято саме звідси.
Другий приклад - це структура великої організації; використання деревоподібної структури для представлення її "ієрархічної структури" нині широко використовується в багатьох комп'ютерних завданнях.
Третій приклад - це граматичне дерево; спочатку воно служило для граматичного аналізу комп'ютерних програм, а нині широко використовується і для граматичного аналізу літературної мови.
РОЗДІЛ І. ДИНАМІЧНІ СТРУКТУРИ ДАНИХ
Під час роботи довільної програми значення деякої статичної змінної може змінюватися, але власне кількість оголошених статичних змінних не змінюється. Це не завжди зручно. Наприклад, якщо програма призначена для введення та обробки даних про учнів класу, а для збереження цих даних використовується звичайний масив, то визначаючи розмір масиву, приходиться орієнтуватися на деяке, як здається програмісту, граничне значення учнів в класі. При цьому якщо реально учнів в класі менше цього граничного значення, то пам’ять ПК використовується неефективно. Якщо ж учнів більше – то таку програму використовувати взагалі неможна.
В таких задачах зручно використовувати структури (подібні до масивів) в яких кількість елементів може змінюватися. Такими структурами є зв’язані список. Зв’язаний список нагадує масив, в якому кількість елементів змінюється під час роботи програми.
Зв’язаний список можна побудувати використовуючи динамічні змінні. Динамічні змінні можна створювати під час роботи програми («на ходу») за допомогою так званих змінних-вказівників.
1.1 ЗМІННІ-ВКАЗІВНИКИ
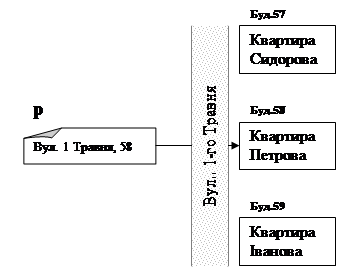
Змінну-вказівник можна уявити як звичайну статичну змінну, але таку, в якій зберігається не деяке конкретне значення (наприклад типу integer, real, …), а адрес іншої змінної.
Змінна-вказівник (р) нагадує конверт, який містить лише адресу квартири Петрова, а не її вміст. Можна сказати, що змінна-вказівник р вказує на іншу змінну, яка знаходиться за адресою вул.. 1-го Травня, 58.
Вміст змінної-вказівника р:
Вул. 1 Травня, 58
Вміст змінної за адресою «Вул. 1 Травня, 58» (ця змінна не має імені):
Квартира Петрова
Змінна, що містить значення Квартира Петрова не є звичайною статичною змінною – вона динамічна.
<Ім’я змінної-вказівника>:^тип динамічної змінної
Наприклад, a:^integer; b:^real;
Щоб змінити значення динамічній змінній, на яку вказує деяка змінна-вказівник z, необхідно виконати команду:
z^:=<значення> (z – це змінна вказівник, а z^ - динамічна змінна, на яку вказує вказівник z).
Щоб змінити значення змінної-вказівника z (направити її на іншу динамічну змінну) необхідно:
z:=<деякий вказівник нв іншу динамічну змінну>
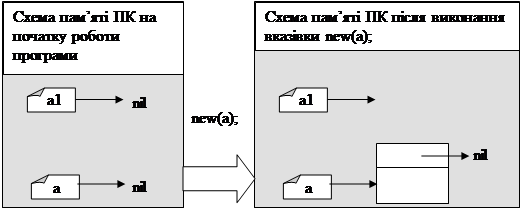
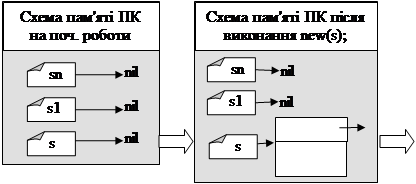
Оскільки динамічна змінна не має імені (а отже не описується в блоці var), то на початку роботи програми пам’ять під дану змінну не виділяється. А відповідна змінна-вказівник ні нащо не вказує. Коли змінна-вказівник ні нащо не вказує, то говорять, що вона вказує на nil.
Щоб виділити пам’ять, необхідно виконати процедуру new(x), де х – змінна-вказівник.
Після виконання даної процедури (new(x)) вказівник x буде вказувати на комірку пам’яті відповідного типу.
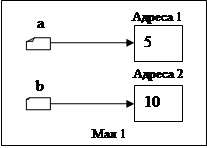
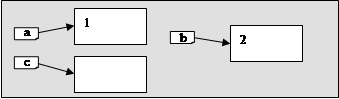
 Нехай на якомусь етапі роботи програми вказівник a
вказує на деяку динамічну змінну, що містить число 5, а b
на іншу змінну, що містить число 10 (мал.1)
Нехай на якомусь етапі роботи програми вказівник a
вказує на деяку динамічну змінну, що містить число 5, а b
на іншу змінну, що містить число 10 (мал.1)
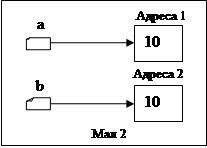
 Після виконання вказівки a
^:=10
(або a
^:=
b
^)
напрям вказівника a
не змінюється, змінюється значення динамічної змінної (в нашому випадку зміниться значення змінної за адресою 1: замість 5 там буде міститися 10)
Після виконання вказівки a
^:=10
(або a
^:=
b
^)
напрям вказівника a
не змінюється, змінюється значення динамічної змінної (в нашому випадку зміниться значення змінної за адресою 1: замість 5 там буде міститися 10)
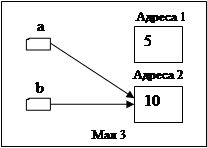
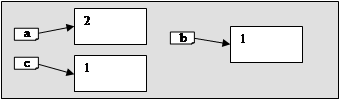
Якщо ж замість a ^:= b ^ записати a := b , то напрям вказівника a змінюється. Змінна-вказівник a буде вказувати на ту ж змінну, що і вказівник b .(мал 3). Тепер значення динамічної змінної, що знаходиться за адресою 2 можна змінити двома способами: використовуючи вказівник a та вказівник b .
Після виконання вказівок:
a:=b;
a^:=100;
b^:=15;
writeln(a^);
на екрані буде число 15 (а не 100)
Приклад .1 Демонструє зміну напрямків вказівників на дві незалежні динамічні змінні.
var a,b,c:^byte;
begin
![]()
 new(a);
new(a);
new(b);
read(a^,b^);
c:=a;

![]() a:=b;
a:=b;
b:=c;
writeln(a^,' ',b^);
end.
Результат роботи програми:
1 2
2 1
В даній програмі використовується лише дві динамічні змінні (дві комірки пам’яті)
Приклад 2 Демонструє перестановку двох динамічних змінних з використанням третьої.
var
 a,b,c:^byte;
a,b,c:^byte;
begin
![]() new(a);
new(a);
new(b);
new(с);
read(a^,b^);
![]() c^:=a^;
c^:=a^;
a^:=b^;
b^:=c^;
writeln(a^,' ',b^);
end.
Результат роботи програми:
1 2
2 1
В даній програмі використовується три динамічні змінні (три комірки пам’яті). Вона працює повністю аналогічно як у випадку із звичайними статичними змінними.
Приклад 1 ефективніший за приклад 2 , бо:
По-перше , використовується дві комірки пам’яті;
По-друге , вміст комірок пам’яті не змінюється.
1.2. ЗВ’ЯЗАНИЙ СПИСОК. СТЕК
Вказівники та динамічні змінні дозволяють створювати складні динамічні структури.
Найпростішою з них є зв’язаний список.
Схематично зв’язаний список можна зобразити так:
 |
||
a 1 – змінна-вказівник
Елемент списку a 1^ – це динамічна змінна (наприклад типу zapis=record), яка в найпростішому випадку складається з двох полів: інформаційного (наприклад, name:string) та змінної-вказівника на наступний елемент списку (next:^zapis). Тобто, динамічна змінна – елемент списку – крім деякого значення містить адресу (змінну-вказівник) наступного елемента списку.
Спробуємо описати тип динамічної змінної.
Якщо ми назвали тип динамічної змінної zapis, то, здавалося б, цей тип має виглядати так:
type
![]() zapis
=record
zapis
=record
|
![]() next:^zapis;
next:^zapis;
![]()
![]() end;
end;
Щоб вийти з цієї ситуації оголосимо спочатку «тип-вказівник» elem на тип zapis:
type
elem=^zapis;
zapis=record
name:string;
next:elem;
end;
Список, кожен елемент якого містять вказівник лише на наступний елемент називається однозв’язним.
Список, що містить два вказівники (на попередній та на наступний елементи) – двозвязний.
Формування стеку.
Формувати список можна добавляючи елементи як на початок списку (стек), як в кінець (черга), так і в довільне місце списку.
 |
|
|
|
 |
|
|
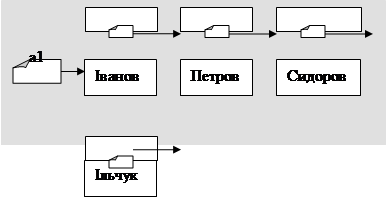
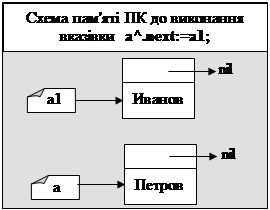
Приклад 1. Наступна програма демонструє добавляння елемента на початок списку.
type
 elem=^zapis;
elem=^zapis;
zapis=record
name:string;
next:elem;
end;
var
a1,a:elem;
begin
new(a1);
a1^.name:='Иванов';
a1^.next:=nil;
writeln(a1^.name);
{Добавимо елемент 'Петров' на початок}
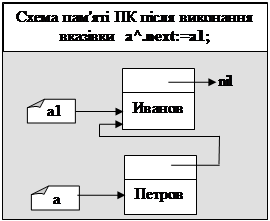 writeln('Формування стеку:');
writeln('Формування стеку:');
new(a);
a^.name:='Петров';
a^.next:=a1;
write(a^.name,' ');
a:=a^.next;
writeln(a^.name);
end.
Результат роботи програми:
Иванов
Формування стеку:
Петров Иванов
Приклад 2. Наступна програма демонструє формування безкінечного стеку.
type
elem=^zapis;
zapis=record
name:string;
next:elem;
end;
var a1,a:elem;
name:string;
begin
repeat
readln(name);
if name<>'' then
begin
new(a);
a^.name:=name;
a^.next:=a1;
a1:=a;
end;
until name='';
while a<>nil do
begin
writeln(a^.name);
a:=a^.next;
end;
end.
Результат роботи програми:
елемент1
елемент2
елемент3
елемент4
елемент5
елемент6
елемент6
елемент5
елемент4
елемент3
елемент2
елемент1
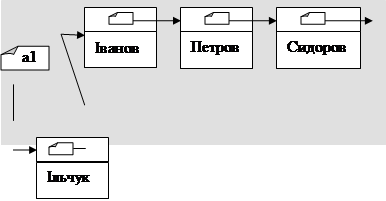
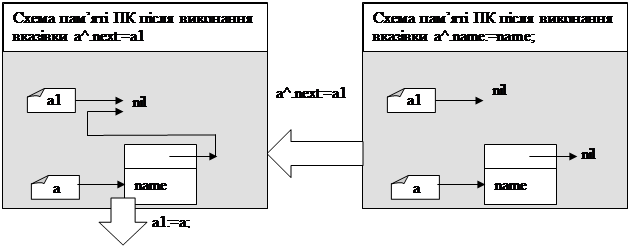
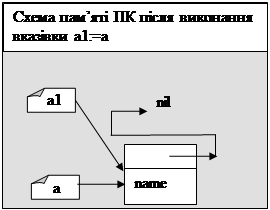
Розглянемо докладніше як працює з попереднього прикладу структура:
new(a);
a^.name:=name;
a^.next:=a1;
a1:=a;
 |
||||
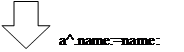 |
||||
 |
||||
 |
||||
При повторному виконанні вказівок:
new(a);
a^.name:=name;
a^.next:=a1;
a1:=a;
в пам’яті ПК відбудуться наступні перетворення:
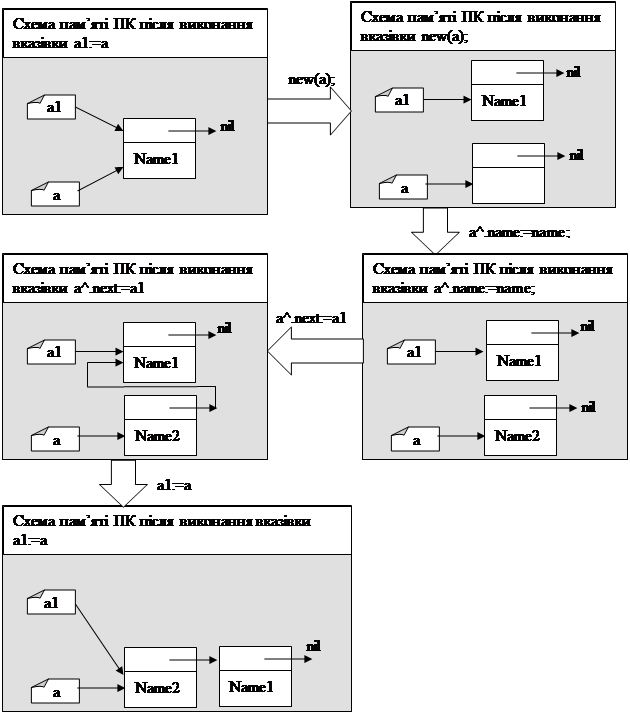
Бачимо, що кожен наступний елемент (Name2) встановлюється на початок списку. Останній елемент, який увійде у стек – перший з нього виходить (він буде на першому місці, тобто при читанні стеку, буде першим).
1 .3. ЗВ’ЯЗАНИЙ СПИСОК. ЧЕРГА.
Формування черги (вставка елементів в кінець списку).
 |
||||
|
||||
 |
||||
 |
||||
|
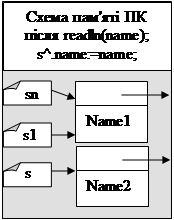
||||
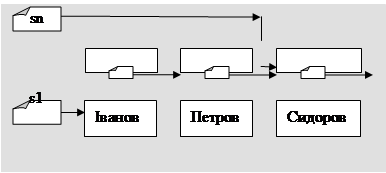
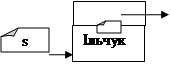
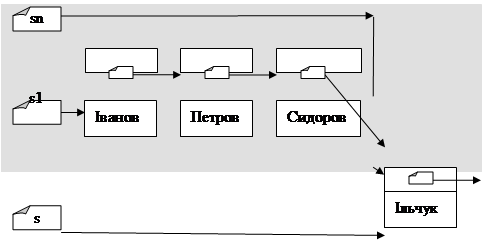
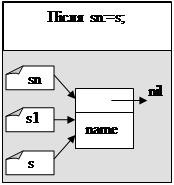
Після створення динамічної змінної s^,поміщаємо в неї «Ільчук». Потім необхідно на цей елемент «напрямити» вказівник елемента sn^ (динамічна змінна sn^ містить вказівник next . А отже, sn^.next:=s;). Після цього елемент «Ільчук» добавиться в кінець списку. Але вказівник sn ще вказує на попередньо останній елемент (тобто на «Сидоров»). Напрямимо його на «Ільчук» (на «Ільчук вказує s. Отже, sn:=s).
Розглянемо схематично дію програмного коду вставки елемента в чергу.
 |
 |
![]() type
type
elem=^zapis;
![]()
 zapis=record
zapis=record
name:string;
next:elem;
end;
var
s1, s, sn:elem;
begin
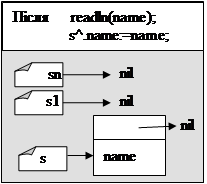
new(s);
readln(name);
s^.name:=name;
s^.next:=nil;
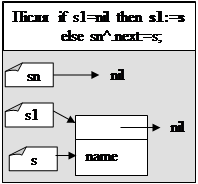
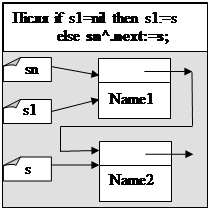
if s1=nil then s1:=s
else sn^.next:=s;
sn:=s;
end.
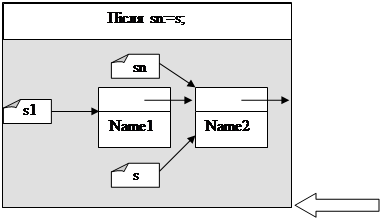
В результаті роботи такої програми три вказівника будуть вказувати на перший елемент черги.
При повторному виконанні вказівок
new(s);
readln(name);
s^.name:=name;
s^.next:=nil;
if s1=nil then s1:=s
else sn^.next:=s;
sn:=s;
новий елемент s^ буде добавлено в кінець списку. При цьому s1 буде вказувати на перший елемент списку, а s та sn – на добавлений елемент списку (останній елемент).
Розглянемо на схемі повторну дію згаданих вище вказівок:
 |
 |
||||||
ТЕКСТ ПРОГРАМИ ФОРМУВАННЯ ЧЕРГИ:
type
elem=^zapis;
zapis=record
name:string;
next:elem;
end;
var s1, s, sn:elem;
name:string;
BEGIN
s1:=nil; s:=nil;
repeat
new(s);
readln(name);
if name<>’’ then begin
s^.name:=name;
s^.next:=nil;
if s1=nil then s1:=s;
else sn^.next:=s;
sn:=s;
end;
until name=’’;
while s1<>nil do begin
writeln('--',s1^.name);
s1:=s1^.next;
end;
END .
ФОРМУВАННЯ ВПОРЯДКОВАНОГО СПИСКУ.
S1 – вказівник на перший елемент списку
S_new – вказівник на новий елемент списку
S_p – вказівник на елемент, після якого необхідно здійснити вставку нового елемента
Buf – деякий допоміжний вказівник на елемент, який проглядається в процесі пошуку місця для вставки нового елемента.
type
elem=^spisok;
spisok=record
name:string;
next:elem;
end;
var
s1,s_new,buf,s_p:elem;
BEGIN
s1:=nil;s_new:=nil;buf:=nil;
repeat
new(s_new);
readln(s_new^.name);
s_p:=nil;
buf:=s1;
if s_new^.name<>'' then
begin
while (buf^.name<s_new^.name)and(buf<>nil) do
begin
s_p:=buf;
buf:=buf^.next;
if s_p=nil then
begin
s_new^.next:=s1;
s1:=s_new;
end
else
begin
s_new^.next:=s_p^.next;
_p^.next:=s_new;
end;
end;
until s_new^.name='';
while s1<>nil do
begin
writeln('--',s1^.name);
s1:=s1^.next;
end;
END.
ВИДАЛЕННЯ ЕЛЕМЕНТА ЗІ СПИСКУ
Якщо у деякому сформованому списку вказівник s_1 вказує на перший елемент списка, то програмний код знищення елементів, що вводяться з клавіатури (якщо він присутній у списку, то нехай buf – це вказівник на елемент, що знаходиться перед ним) , може мати наступний вигляд:
{Формування списку}
repeat
writeln('Введите элемент, который хотите уничтожить со списка:’);
readln(name);
if name<>'' then
begin
if s1^.name=name then s1:=s1^.next
else
begin
buf:=s1;
while (buf^.next^.name<>name)and(buf^.next<>nil) do buf:=buf^.next;
if buf^.next^.name=name then buf^.next:=buf^.next^.next;
end;
end;
until name='';
ОБЕРНЕННЯ ЕЛЕМЕНТІВ СПИСКУ (ЗМІНЕННЯ НАПРЯМКІВ УСІХ ВКАЗІВНИКІВ НА ПРОТИЛЕЖНИЙ)
1 спосіб (шляхом «переміщення» кожного елемента списку, починаючи з другого, на його початок)
Зауваження! Під переміщенням елемента розуміємо не фізичне переміщення його на початок списку. На початок списку «направляємо» лише вказівник елемента, який з даного списка видаляється.
S_1 – вказівник на перший елемент списку
S – вказівник на поточний елемент списку
Buf – вказівник на наступний за поточним елементом (на елемент що переміщається на початок списку
s:=s_1;
buf:=s_1;
while s^.next<>nil do
begin
buf:=s^.next;
s^.next:=s^.next^.next;
buf^.next:=s_1;
s_1:=buf;
end;
2 спосіб (шляхом зміни напрямків вказівників на протилежний)
S_1 – вказівник на перший елемент списку
S – вказівник на поточний елемент списку
Left – вказівник на елемент, що знаходиться лівіше від поточного
Right – вказівник на елемент, що знаходиться правіше від поточного
right:=s_1;
s:=nil;
repeat
left:=s;
s:=right;
right:=right^.next;
s^.next:=left;
until right=nil;
РОЗДІЛ ІІ . ДЕРЕВА. БІНАРНЕ ДЕРЕВО
Деревом називається динамічна структура, у якій кожен вузол містить не один, а декілька вказівників на декілька інших вузлів.
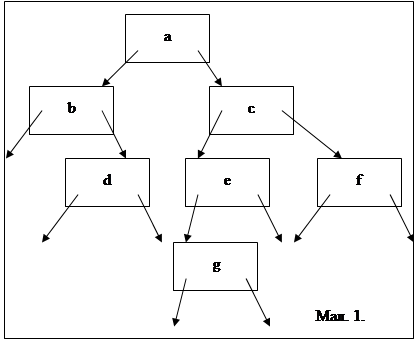 Кореневий вузол (корінь дерева) – це самий верхній вузол (вузол a – кореневий) . Якщо з деякого вузла (наприклад, вузла а) вказівники вказують на інші вузли (в нашому випадку на вузли b та c), то такий вузол називають предком. Вузли ж на які вказують вказівники від предка називаються потомками.
Кореневий вузол (корінь дерева) – це самий верхній вузол (вузол a – кореневий) . Якщо з деякого вузла (наприклад, вузла а) вказівники вказують на інші вузли (в нашому випадку на вузли b та c), то такий вузол називають предком. Вузли ж на які вказують вказівники від предка називаються потомками.
Все сказане вище ілюструє малюнок 1, якщо його розглянути то можна зробити висновки про те, що:
· Лівий потомок вузла а – вузол b
· Правий потомок – вузол c.
· Вузли b та c мають спільного предка – вузол а
Якщо вузол не має потомків, то такий вузол називають листком дерева, тому згідно малюнка вершини d, g та f – є листками.
Дерево, кожен вузол якого не може мати більше двох потомків називається бінарним.
2.1. РЕАЛІЗАЦІЯ БІНАРНОГО ДЕРЕВА ЗА ДОПОМОГОЮ ДИНАМІЧНИХ ЗМІННИХ
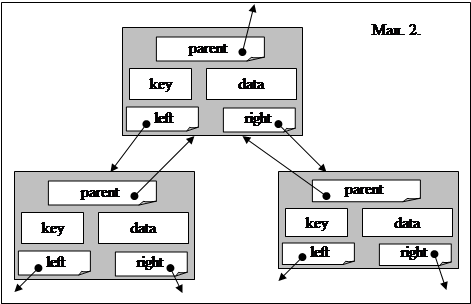
Розглянемо динамічну змінну b, що має таку структуру, як показано на малюнку 2. А саме, змінна b є записам з 5 полів:
Parent –вказівник на предка
Left – вказівник на лівого потомка
Right – вказівник на правого потомка
Data – поле даних (наприклад, прізвище)
Key – ключ (цілочисельне значення), по якому ідентифікується елемент.
Тип такої динамічної змінної виглядає наступнич чином:
type
BinarTree=^node;
node=record
key:integer;
data:string;
left,right,
parent:BinarTree;
end;
Сформуємо дерево керуючись таким принципом: ключ кожного лівого потомка менший за ключ предка, а ключ правого потомка – більший або рівний ключа предка.
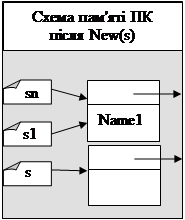
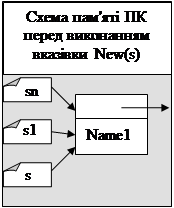
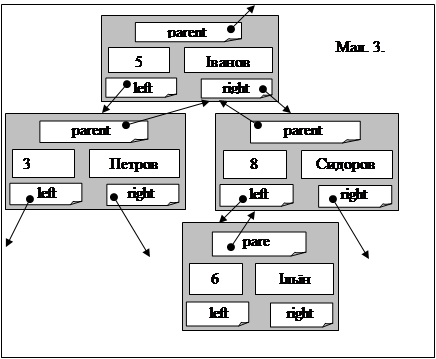 Наприклад, бінарне дерево з трьох вузлів (Іванов (ключ=5), Петров (ключ=3) та Сидоров (ключ=8)) має вигляд як показано на мал.3. Добавимо в дерево елемент Ільїн з ключем 6. Цей елемент буде лівим потомком елемента Сидоров (так як 6>5 та 6<8). Якби ключ елемента Ільїн був рівний 4, то він був би правим потомком елемента Петров (бо 4<5 та 4>3)
Наприклад, бінарне дерево з трьох вузлів (Іванов (ключ=5), Петров (ключ=3) та Сидоров (ключ=8)) має вигляд як показано на мал.3. Добавимо в дерево елемент Ільїн з ключем 6. Цей елемент буде лівим потомком елемента Сидоров (так як 6>5 та 6<8). Якби ключ елемента Ільїн був рівний 4, то він був би правим потомком елемента Петров (бо 4<5 та 4>3)
При вставці кожного наступного елемента (нехай вказівник b_new вказує на цей елемент) в дерево (b вказує на корінь цього дерева), ми повинні спочатку знайти листок (нехай на нього вказує вказівник b_parent), який буде предком елемента що вставляєть.
Для пошуку такого листка використаємо деякий проміжний вказівник b_buf, який спочатку буде вказувати на корінь дерева b, а потім крок за кроком приймати значення b_buf^.left або b_buf^.right в залежності від значенні ключа елемента що вставляється (b_new) до тих пір, поки не дойде до листка дерева.
Програмний код пошуку елемента b_parent.
b_buf:=b;
while b_buf<>nil do
begin
b_parent:=b_buf;
if b_new^.key<b_parent^.key
then b_buf:=b_buf^.left
else b_buf:=b_buf^.right;
end;
Наступний крок – направити вказівник b_new^.parent на знайдений елемент b_parent та вказівники left або right знайденого елемента b_parent на елемент, що вставляється b_new:
Програмний код виставлення лівого та правого вказівників знайденого елемента-предка (b_parent^.left та b_parent^.right) на новий елемент (b_new) та вказівника нового елемента-потомка (b_new^.parent) на знайдений елемент-предок (b_parent):
b_new^.parent:=b_parent;if b_new^.key<b_parent^.key then b_parent^.left:=b_new
else b_parent^.right:=b_new
ВИВЕДЕННЯ НА ЕКРАН ЛИСТКІВ БІНАРНОГО ДЕРЕВА.
Процедура виведення листів бінарного дерева є рекурсивною. Адже листками деякого дерева Х є листи його лівого та правого потомків (якщо ці потомки не nil). Назвемо процедуру виведення листка дерева write_tree(x:BinarTree). Якщо лівий та правий вказівники деякого елемента вказують на nil значить цей елемент є листом, а отже його треба вивести на екран. Інакше шукаємо листки лівого потомка (якщо він не рівний nil), а потім – правого потомка (якщо він також не рівний nil).
procedure write_tree(x:BinarTree);
begin
if (x^.left=nil) and (x^.right=nil) then write(x^.data,' ')
else
begin
if x^.left<>nil then write_tree(x^.left);
if x^.right<>nil then write_tree(x^.right);
end;
end;
ТЕКСТ ПРОГРАМИ ФОРМУВАННЯ БІНАРНОГО ДЕРЕВА
ТА ВИВЕДЕННЯ НА ЕКРАН ЙОГО ЛИСТІВ
uses crt;
type
BinarTree=^node;
node=record
key:integer;
data:string;
left,right,parent:BinarTree;
end;
var
b,b_parent,b_new,b_buf:BinarTree;
name:string;
k:integer;
procedure write_tree(x:BinarTree);
begin
if (x^.left=nil) and (x^.right=nil) then write(x^.data,' ')
else
begin
if x^.left<>nil then write_tree(x^.left);
if x^.right<>nil then write_tree(x^.right);
end;
end;
begin
clrscr;
repeat
write('Фамилия -> ');
readln(name);
if name<>'' then
begin
write('Ключ -> ');
readln(k);
new(b_new);
with b_new^ do
begin
parent:=nil;
left:=nil;right:=nil;
data:=name;
key:=k;
end;
if b=nil then b:=b_new
else
begin
b_buf:=b;
while b_buf<>nil do
begin
b_parent:=b_buf;
if b_new^.key<b_parent^.key then b_buf:=b_buf^.left
else b_buf:=b_buf^.right;
end;
b_new^.parent:=b_parent;
if b_new^.key<b_parent^.key then b_parent^.left:=b_new
else b_parent^.right:=b_new
end;
end;
until name='';
write('Листы дерева: ');
write_tree(b);
writeln;
end.
Результат роботи програми:
Имя -> Иванов
Ключ -> 5
Имя -> Петров
Ключ -> 3
Имя -> Сидоров
Ключ -> 8
Имя -> Ильин
Ключ -> 6
Имя ->
Листі дерева: Петров Ильин
ВИВЕДЕННЯ НА ЕКРАН УСІХ ВУЗЛІВ БІНАРНОГО ДЕРЕВА
 Видозмінимо процедуру виведення листів бінарного дерева в процедуру виведення усіх його вузлів: лівий потомок - правий потомок – предок - … - кореневий вузол:
Видозмінимо процедуру виведення листів бінарного дерева в процедуру виведення усіх його вузлів: лівий потомок - правий потомок – предок - … - кореневий вузол:
procedure write_tree(x:BinarTree);
begin
if (x^.left<>nil) or (x^.right<>nil) then
begin
if x^.left<>nil then write_tree(x^.left);
if x^.right<>nil then write_tree(x^.right);
end;
write(x^.data,' ');
end;
Тут виведення вузлів здійснюється як результат зворотньої дії рекурсивної процедури (вказівка write(x^.data,' ') – вкінці процедури). При такій організації вузли розпочнуть виводитись на екран після досягнення крайнього лівого листка.
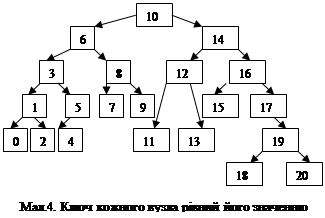
При введенні бінарного дерева, зображеного на малюнку 4, результат роботи описаної процедури буде наступним:
Все узлы дерева: 0 2 1 4 5 3 7 9 8 6 11 13 12 15 18 20 19 17 16 14 10
Якщо вказівку write(x^.data,' ') розмістити не в кінці, а на початку процедури, то виведення вузлів буде здійснюватися як результат прямої дії рекурсії. Тобто, спочатку виведуться усі ліві потомки кореня дерева, потім правий потомок предка крайнього лівого листка і всі його ліві потомки і т.д. аж до крайнього правого лиска дерева.
В цьому випадку при введенні того ж дерева (мал.4) результат роботи такої процедури наступний:
Все узлы дерева: 10 6 3 1 0 2 5 4 8 7 9 14 12 11 13 16 15 17 19 18 20
ВИЗНАЧЕННЯ КІЛЬКОСТІ РІВНІВ БІНАРНОГО ДЕРЕВА (ВИСОТИ ДЕРЕВА)
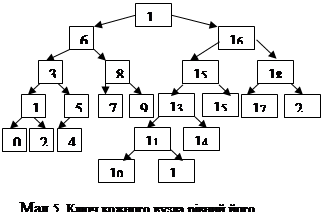
На малюнку 5 зображено шести-рівневе бінарне дерево. Лівий потомок (6) – 4-х рівневе дерево. Правий потомок (16) 5-ти рівневе дерево. Бачимо, що для того, щоб визначити висоту дерева необхідно до висоти «вищого» потомка додати 1. Виходячи з таких міркування функція визначення висоти дерева (Function height_tree(x:BinarTree):integer) має рекурсивний характер.
Нехай i – висота лівого потомка, а j – висота правого потомка. Тоді:
 Function height_tree(x:BinarTree):integer;
Function height_tree(x:BinarTree):integer;
var
i,j:integer;
begin
if x=nil then height_tree:=0
else
begin
i:=height_tree(x^.left);
j:=height_tree(x^.right);
if i>j then height_tree:=i+1
else height_tree:=j+1;
end;
end;
При введенні дерева, зображеного на мал.5, результат роботи функції height_tree наступний:
Висота дерева: 6
В ИСНОВКИ
У виконаній роботі було розглянуто процеси пошуку інформацій та розроблено структури даних для ефективного зберігання та обробки інформації. Як приклад розглянуто бінарне дерево. Це динамічна структура даних, розмір якої обмежується тільки розміром віртуальної пам’яті комп’ютера. Бінарні дерева забезпечують пошук конкретного значення, максимуму, мінімуму, попереднього, наступного, операції вставки та видалення елемента.
Розглянуті у роботі бінарні структури широко використовуються у житті, наприклад це різноманітні "ієрархічні структури", які нині широко використовуються в багатьох комп'ютерних завданнях. На даний час також розвивається граматичний аналіз, в основі якого і знаходяться принципи бінарних дерев. Граматичний аналіз на даний час широко використовується у сучасних пошукових алгоритмах.
Тому вивчення бінарних дерев та їх функціонування має важливе значення.
СПИСОК ВИКОРИСТАНОЇ ЛІТЕРАТУРИ.
1. Никита Культин «Программирование в Turbo Pascal и Delphi» — СПб.: БХВ — Санкт-Петербург, 1999.
2. С.А.Немнюгин «Turbo Pascal: практикум» — СПб.: Питер, 2001.
3. Е.А.Зуев «Программирование на языке Turbo Pascal 6.0., 7.0. — Москва: Веста, Радио и связь, 1993.
4. Аляев Ю.А., Козлов О.А. Программирование. Pascal, C++, Visual Basic. М.: Финансы и статистика, 2004.
5. Гуденко Д., Петроченко Д. Сборник задач по программированию. – Спб.: Питер, 2003.