| Скачать .docx |
Реферат: Отчет по преддипломной практике 6
МОУ ВПО «Южно-Уральский профессиональный институт»
Кафедра «Информатики и вычислительной техники»
ОТЧЕТ
по преддипломной практике
специальности 230101.65 Вычислительные машины, комплексы, системы и сети
| Студент гр. ВМ-1-05, |
___________________ |
|
| факультета Управления и информационных технологий |
«___» ___________ 2009 |
|
| Руководитель |
___________________ |
О.Н.Горлова |
| «___» ___________ 2009 |
||
| Преподаватель |
___________________ |
И.Ю.Ткачук |
| «___» ___________ 2009 |
Челябинск
2009
Оглавление:
1. Ознакомление с объектом практики. 4
1.1 Общие сведения об организации. 4
1.2.1 Техническое обслуживаниe. 4
2.Технология разработки программного обеспечения. 12
2.1 Описание системы автоматизации проектирования программных продуктов на предприятии. 12
3.1 Описание архитектурных свойств и структур ЭВМ, применяемых на предприятии. 17
4. Архитектура вычислительных систем (ВС) 23
4.1 Способы организации и типы ВС на предприятии прохождения практики. 23
4.2 Уровни и способы организации параллельной обработки информации для ВС предприятия. 24
5 Информационные компьютерные сети (КС) 25
5.1 Топология КС на предприятии прохождения преддипломной практики. 25
5.2Перечень технических средств, их характеристики и параметры для КС предприятия. 26
6. Защита информации в вычислительных системах и сетях. 28
6.1 Методы защиты информации в операционной системе, установленной на предприятии. 28
6.2 Алгоритмы аутентификации пользователей ПК.. 28
7. Администрирование информационно-вычислительных сетей. 31
7.1 Описание структуры администрирования информационно вычислительной сети предприятия. 31
7.2 Список систем управления базами данных, применяемых на предприятии. 31
1. Ознакомление с объектом практики
1.1 Общие сведения об организации.
Юридический адрес 454091, г.Челябинск, ул.Механическая, дом 4 А офис 204
E-mail Ahmetshin_marat@mail.ru
Телефон: 2571317,
Индивидуальный Предприниматель МегаТрансАвто
1.2 Деятельность компании:
1. Техническое обслуживание
2. Обслуживание 1C
3. Защита информации
4. Электронный документооборот
5. Создание сайтов
6. Информационная поддержка сайтов
7. Система управления сайтом
8. Разработка ПО
1.2.1 Техническое обслуживание
Преимуществом обслуживания корпоративных сетей силами специализированной фирмы является неизменно высокое качество, стабильность, профессионализм и быстрое решение любых возникающих в процессе вашей работы технических проблем.
Грамотный специалист, имеющий большой опыт работы с оборудованием и программным обеспечением требует соответствующей его знаниям оплаты. Иметь сотрудника, в компетенции которого Вы до конца не уверены, опасно для вашего бизнеса, поскольку любой сбой в работе компьютерной системы может надолго вывести Вашу фирму из рабочего состояния.
В штате нашей компании работают специалисты с высокой квалификацией, способные решать задачи любой сложности, что подтверждается наличием государственных лицензий на данные виды работ и добрым именем нашей компании у наших клиентов.
Использование наших знаний позволит вам обеспечить бесперебойную работу оборудования, надежную антивирусную защиту компьютеров пользователей, контроль за использованием локальной сети и сети Интернет сотрудниками компании, снижение количества писем массовой рассылки электронной почты (спама), пресечение нецелевого использования сети Интернет, регулярное резервное копирование важной информации.
Уникальностью нашего предложения на рынке обслуживания являются следующие принципы работы компании:
• мы будем говорить с Вами на доступном языке, а не на малопонятном многим жаргоне компьютерщиков;
• нашим убеждением является то, что главным является качество и стабильность выполнения услуг;
• при организации обслуживания мы внедряем у вас «Процедуру обслуживания» — документ, который содержит качественные и количественные критерии оценки нашего сервиса.
В обслуживание информационных систем, проводимое нашей компанией, входит обслуживание текущих потребностей пользователей, проведение текущих регламентных работ, а также ликвидация различных отказов информационной системы.
Кроме того, на начальном этапе, в рамках обслуживания, мы проводим диагностику информационной системы Вашей организации, и, в случае выявления недостатков, мы предлагаем проведение проектных работ по реорганизации информационной системы и созданию системы защиты информации.
Ввиду того, что реализация системы защиты информации требует применения наших разработок и «ноу-хау», данные работы выполняются отдельно от общего обслуживания информационной системы.
В случае проведения нами проектных работ по реорганизации информационной системы и созданию системы защиты информации, мы снижаем стоимость обслуживания информационной системы Вашей организации.
1.2.4 Защита информации
Растущая популярность Интернета, перевод бизнес-процессов в электронный вид, в том числе и в сети общего пользования с одной стороны, и увеличивающееся количество хакеров, растущая их квалификация с другой стороны, помещают все больше и больше предприятий в группу риска. Стремительно нарастающая изощренность действий хакеров, применение нестандартных приемов взлома приводит к тому, что производители программного обеспечения просто не успевают во внедрении противодействующих мер. И система, еще вчера кажущаяся защищенной, сегодня оказывается уже уязвимой.
Поэтому лишь создание комплексной, многослойной системы защиты, включающей в себя применение как организационных, так и технических средств, позволит гарантированно обезопасить информацию, а, следовательно, и избежать финансовых потерь от нарушения безопасности информации.
Как и всякий сложный процесс, создание комплексной защиты информации наиболее эффективно проводить поэтапно. Четкая последовательность действий минимизирует вмешательство в работу существующей информационной системы, снижает непродуктивные затраты и позволит Вам как заказчику, проводить промежуточный контроль работ, а следовательно оперативно оценить эффективность вложения средств.
Привлечение сторонней фирмы для проведения диагностики защищенности имеет ряд преимуществ:
• Сотрудники специализированной фирмы имеют более высокую квалификацию.
• Сотрудники сторонней специализированной фирмы не скованы знаниями о построении системы защиты информации в организации заказчика, и могут провести максимально непредвзятую оценку защищенности.
• На результаты проверки не могут повлиять некие заинтересованные лица организации, в которой проводится анализ защищенности.
Мы рекомендуем следующие этапы создания комплексной защиты информации:
• Диагностика информационной системы
• Внедрение и сопровождение системы защиты информации
• Аттестация информационной системы.
Каждый из этих этапов может быть проведен как отдельное мероприятие по защите информации.
Диагностика информационной системы.
Задачами диагностики, как этапа создания комплексной защиты информации, в первую очередь являются:
• Анализ бизнес-процессов и информационных потоков предприятия;
• Анализ структуры информации и оценка финансовых рисков связанных с утерей информации;
• оценка технического состояния существующей информационной системы.
На этом этапе Вы как заказчик, с нашей помощью, сможете взглянуть на Вашу информацию как на материальный актив, оценить связанные с ним прибыли и возможные убытки. Диагностика информационной системы является важнейшим этапом создания комплексной защиты информации, и от ее объективности будет зависеть эффективность и стоимость будущей системы защиты информации.
Проектирование комплексной защиты информации.
Проектирование производится обязательно на основе результата диагностики информационной системы. Проектирование без диагностики — «деньги на ветер».
В этап проектирования входит:
• Оптимизация информационных потоков предприятия с точки зрения защиты информации (например, перенос информации со всех рабочих станций, в одно место, на сервер, позволит быстро и без ошибок настроить права доступа к информации, что позволит минимизировать возможность несанкционированного доступа);
• разработка организационных мер по защите информации. А именно создание комплексной политики информационной безопасности, которая представляет собой набор необходимых правил, требований и нормативных документов, необходимых для обеспечения требуемого уровня защищенности автоматизированной системы.
• тщательный подход к подбору технических средств по защите информации, с оптимальным критерием эффективность/стоимость, позволяющий создать экономически оправданную систему безопасности
Внедрение и сопровождение системы защиты информации.
На данном этапе производится реализация спроектированной системы защиты. Внедрение и сопровождение системы возможно как силами собственного технического персонала, так и силами сторонней специализированной компании, такой как компания ИТ Энигма. Наши клиенты могут по достоинству оценить выгоды от сотрудничества с компанией, располагающей необходимыми возможностями и квалификацией для качественного внедрения, дополнения, интеграции оборудования отечественных и зарубежных производителей, а также усовершенствования и адаптации технических решений в соответствии со специальными требованиями заказчика. Кроме того, наша компания имеет и собственные разработки в области защиты информационных систем, которые пока не имеют аналогов.
Аттестация информационной системы по требованиям безопасности представляет собой комплекс организационно-технических мероприятий, в результате которых подтверждается, что на аттестационном объекте выполнены требования по безопасности информации, заданные в нормативно-технической документации, утвержденные государственными органами обеспечения безопасности информации и контролируемые при аттестации.
По окончании работ, при соблюдении всех нормативных требований, заказчику выдается Аттестат соответствия, разрешающий обрабатывать информацию определенного уровня конфиденциальности.
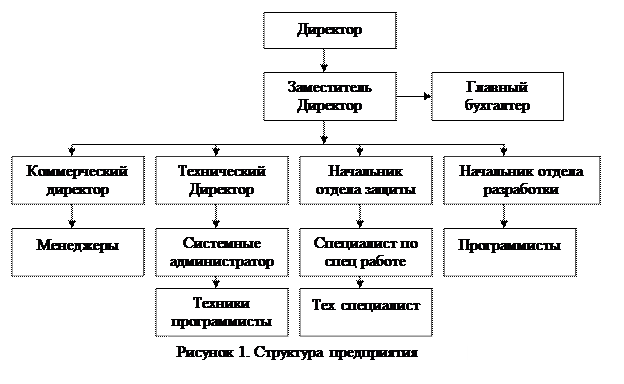
1.3 Структура предприятия:
1.4 Техника безопасности:
1. Общие положения.
1.1. Настоящая инструкция предназначена для работников ООО «ИТ-Энигма», выполняющих работы на персональном компьютере и на другой оргтехнике (принтеры, сканеры, ксероксы и т.д.).
1.2. К выполнению работ в качестве оператора компьютера и на другой оргтехнике (принтеры, сканеры, ксероксы и т.д.) допускаются лица:
1.Не моложе 16 лет;
2. Прошедшие медицинский осмотр;
3. Прошедшие вводный инструктаж по охране труда, а также инструктаж по охране труда на рабочем месте;
4. Прошедшие обучение безопасным приемам труда на рабочем месте по выполняемой работе.
1.3. Работник обязан:
1. Выполнять правила внутреннего трудового распорядка, установленные в положениях и инструкциях, утвержденных директором «ООО «ИТ-Энигма»», или его заместителями;
2.Выполнять требования настоящей инструкции;
3. Сообщать руководителю работ о неисправностях, при которых невозможно безопасное производство работ;
4. Не допускать присутствия на рабочем месте посторонних лиц;
5. Уметь оказывать первую помощь и при необходимости оказывать ее пострадавшим при несчастных случаях на производстве, по возможности сохранив обстановку на месте происшествия без изменения и сообщив о случившемся руководителю;
6. Выполнять требования противопожарной безопасности не разводить открытый огонь без специального на то разрешения руководителя работ;
7. Периодически проходить медицинский осмотр в сроки, предусмотренные для данной профессии.
1.4. Работник должен знать опасные и вредные производственные факторы, присутствующие на данном рабочем месте:
1. Возможность травмирования электрическим током при отсутствии или неисправности заземляющих устройств;
2. Вредное воздействие монитора компьютера при его неправильной установке или неисправности;
3. Возможность возникновения заболеваний при неправильном расположении монитора, клавиатуры, стула и стола;
4. Вредное воздействие паров, газов и аэрозолей выделяющихся при работе копировальной и печатающей оргтехники в непроветриваемых помещениях.
1.4. При передвижении по городу по пути на работу и с работы работник обязан соблюдать правила дорожного движения в части, касающейся пешеходов, а при доставке на работу на транспорте в части касающейся пассажиров.
1.1. Запрещается пить воду из водоразборных кранов. Вода для питья должна быть кипяченой, для чего на участках работ должно быть организовано кипячение воды, а там, где это невозможно, работник обязан приносить кипяченую воду или чай из дома.
1.2. Работник при выполнении любой работы должен обладать здоровым чувством опасности и руководствоваться здравым смыслом. При отсутствии данных качеств он к самостоятельной работе не допускается.
2. Требования охраны труда перед началом работы.
2.1. Перед началом работы работник обязан:
1. Получить от руководителя работ инструктаж о безопасных методах, приемах и последовательности выполнения производственного задания;
2. Привести в порядок одежду, застегнуть на все пуговицы, чтобы не было свисающих концов, уложить волосы, чтобы они не закрывали лицо и глаза;
3. Привести рабочее место в безопасное состояние;
4. Запрещается носить обувь на чрезмерно высоких каблуках;
2.2. Перед включением компьютера или другой оргтехники убедиться в исправности электрических проводов, штепсельных вилок и розеток. Вилки и розетки должны соответствовать Евростандарту. Отличительной особенностью этих вилок и розеток является наличие третьего провода, обеспечивающего заземление компьютера или другого прибора. При отсутствии третьего заземляющего провода заземление должно быть выполнено обычным способом с применением заземляющего проводника и контура заземления;
2.3. Убедиться, что корпус включаемого оборудования не поврежден, что на нем не находятся предметы, бумага и т.п. Вентиляционные отверстия в корпусе включаемого оборудования не должны быть закрыты занавесками, завалены бумагой, заклеены липкой лентой или перекрыты каким-либо другим способом.
3. Требования охраны труда во время работы.
3.1. Запрещается во время работы пить какие-либо напитки, принимать пищу;
3.2. Запрещается ставить на рабочий стол любые жидкости в любой таре (упаковке или в чашках);
3.3. Помещения для эксплуатации оргтехники должны иметь естественное и искусственное освещение, естественную вентиляцию и соответствовать требованиям действующих норм и правил. Запрещается размещать рабочие места вблизи силовых электрических кабелей и вводов трансформаторов, технологического оборудования, создающего помехи в работе оргтехники и отрицательно влияющие на здоровье операторов;
3.4. Окна в помещениях, где установлены компьютеры должны быть ориентированы на восток. Оконные проемы оборудуются регулируемыми устройствами типа жалюзи или занавесками;
3.5. Площадь на одно рабочее место пользователей компьютера должна составлять не менее 6 м2 при рядном и центральном расположении, при расположении по периметру помещения – 4 м2. При использовании компьютера без вспомогательных устройств (принтер, сканер и т.п.) с продолжительностью работы менее четырех часов в день допускается минимальная площадь на одно рабочее место 5 м2;
3.6. Полимерные материалы, используемые для внутренней отделки интерьера помещений с ПК должны подвергаться санитарно-эпидемиологической экспертизе. Поверхность пола должна обладать антистатическими свойствами, быть ровной. В помещениях ежедневно проводится влажная уборка. Запрещается использование удлинителей, фильтров, тройников и т.п., не имеющих специальных заземляющих контактов;
3.7. Экран видеомонитора должен находится от глаз оператора на расстоянии 600-700 мм, минимально допустимое расстояние 500 мм;
3.8. Продолжительность непрерывной работы с ПК должна быть не более 2 часов;
4. Требования охраны труда по окончании работы.
4.1. По окончании работы работник обязан выполнить следующее:
1. Привести в порядок рабочее место;
2. Убрать инструмент и приспособления в специально отведенные для него места хранения;
3. Обо всех замеченных неисправностях и отклонениях от нормального состояния сообщить руководителю работ;
4. Привести рабочее место в соответствие с требованиями пожарной безопасности;
5. Действие при аварии, пожаре, травме.
5.1. В случае возникновения аварии или ситуации, в которой возможно возникновение аварии немедленно прекратить работу, предпринять меры к собственной безопасности и безопасности других рабочих, сообщить о случившемся руководителю работ.
5.2. В случае возникновения пожара немедленно прекратить работу, сообщить в пожарную часть по телефону 01, своему руководителю работ и приступить к тушению огня имеющимися средствами.
5.3. В случае получения травмы обратиться в медпункт, сохранить по возможности место травмирования в том состоянии, в котором оно было на момент травмирования, доложить своему руководителю работ лично или через товарищей по работе.
6. Ответственность за нарушение инструкции.
6.1. Каждый работник ООО «ИТ-Энигма» в зависимости от тяжести последствий несет дисциплинарную, административную или уголовную ответственность за несоблюдение настоящей инструкции, а также прочих положений и инструкций, утвержденных директором ООО «ИТ-Энигма» или его заместителями.
6.2. Руководители подразделений, начальники цехов и участков, начальники отделов и служб несут ответственность за действия своих подчиненных, которые привели или могли привести к авариям и травмам согласно действующему в РФ законодательству в зависимости от тяжести последствий в дисциплинарном, административном или уголовном порядке.
6.3. Администрация ООО «ИТ-Энигма» вправе взыскать с виновных убытки, понесенные предприятием в результате ликвидации аварии, при возмещении ущерба работникам по временной или постоянной утрате трудоспособности в соответствии с действующим законодательством.
2.Технология разработки программного обеспечения
2.1 Описание системы автоматизации проектирования программных продуктов на предприятии
На предприятии используются среды проектирования программ:
1. Borland C++Builder 6 Enterprise
2. Borland Delphi 2007 for Win32
2.1.1 Borland C++Builder 6 Enterprise
Borland C++Builder 6 Enterprise расширяет возможности среды разработки приложений на C++ средствами для работы с web-службами. Кросс-платформенная библиотека компонентов Borland CLX позволяет создавать универсальные решения. С помощью новых продуктов Borland C++, которые появятся в ближайшее время, эти решения можно будет переносить на платформу Linux. Новый менеджер проектов с открытой архитектурой и средства сборки обеспечивают полный контроль над их разработкой и развертыванием.
Возможности
Интеграция B2B-приложений с помощью web-служб.
Быстрая разработка web-приложений.
Создание высокопроизводительного ПО промежуточного уровня для web-служб.
Полная поддержка стандартных протоколов SOAP, XML, WSDL и XSL.
Разработка кросс-платформенных приложений для Windows и Linux.
Высокопроизводительный 32-битный компилятор.
Поддержка баз данных IBM DB2, IBM Informix, Oracle, Sybase, MySQL, dBASE, Paradox и Borland InterBase.
Особенности
Лучшая среда быстрой разработки приложений
Инструменты Borland Two-Way-Tools для визуальной разработки приложений на C++.
Повышена степень соответствия стандарту ANSI/ISO C++ благодаря поддержке библиотеки STLPort.
Удобные средства для создания и использования объектов Windows COM, COM+, ActiveX и Automation.
BizSnup – платформа разработки приложений для электронного бизнеса с использованием web – служб
Создание клиентских приложений для работы с W3C-совместимыми web-службами в соответствии со стандартами SOAP, XML, WSDL и др.
Создание W3C-совместимых серверных компонентов web-служб в соответствии со стандартами SOAP, XML, WSDL и др.
Встроенная поддержка XML, благодаря которой радикально сокращается объем ручного программирования и появляется возможность работы с XML-документами как с объектами.
Инструменты и компоненты для преобразования структуры документов XML, позволяющие распознать незнакомые форматы XML-данных и наладить информационный обмен с деловыми партнерами.
WebSnap – полнофункциональная платформа для разработки web – приложений
Широкий выбор компонентов WebSnap для разработки web-приложений.
Создание серверных сценариев с использованием JavaScript, VBScript и ActiveScript.
DataSnap – промежуточное ПО для организации доступа к бизнес – данным
Новая, совместимая с предыдущими, версия DataSnap для разработки интерфейсов, web-приложений и web-служб.
SOAP- и XML-web-службы для работы с базами данных Oracle, Microsoft SQL Server, IBM DB2, IBM Informix, Borland InterBase и др.
Библиотека визуальных компонентов VCL
Библиотека VCL (Visual Component Library) для быстрой разработки приложений.
Компоненты ActionBands для разработки настраиваемых интерфейсов в стиле Windows 2000.
Новая библиотека компонентов CLX для Windows и Lunex
Более 165 компонентов BaseCLX, VisualCLX, DataCLX и NetCLX для разработки кросс-платформенных приложений с едиными исходными текстами.
Новый настраиваемый инструмент Tools server для управления проектами
Установка и использование в процессе разработки различных внешних инструментов и утилит (пакетных файлов, сценариев на языке Perl, компиляторов и т.д.).
Создание собственных последовательностей сборки приложений с использованием внешних инструментов.
Разработка корпоративных приложений
Мастера разработки клиентских и серверных частей CORBA-приложений для Borland VisiBroker 4.5.
Эффективные средства работы с базами данных
Локальные драйверы для Paradox, dBASE, FoxPro и Microsoft Access.
Драйверы dbExpress для InterBase и MySQL.
Драйверы dbExpress для Oracle и DB2.
Драйверы BDE SQL Links для связи с базами данных Oracle, Microsoft SQL Server, Informix, Sybase и InterBase.
Драйверы dbGo for ADO 2.5 для прямого доступа к ADO-совместимым наборам данных, созданным в самых разнообразных приложениях - от офисных программ до реляционных баз данных.
Высоко производительные Windows – приложения
Простое создание повторно используемых динамически подключаемых библиотек (.dll), компонентов COM (.ocx) и автономных приложений.
Лицензия для разработки коммерческих приложений.
Документация, примеры и оперативная справка
Подробные печатные руководства и электронная справочная система.
Требования к системе
Процессор Intel Pentium II 400 МГц или совместимый.
Операционная система Microsoft Windows 98, 2000 (SP2) или XP.
ОЗУ минимум 128 Мб, рекомендуется 256 Мб.
Жесткий диск - 750 Мб свободного пространства для полной установки.
Дисковод CD-ROM.
Монитор SVGA (800x600, 256 цветов) или с более высоким разрешением.
Манипулятор "мышь" или другое указательное устройство.
2.1.2 Borland Delphi 2007 for Win32 Enterprise R2
Borland Delphi 2007 for Win32 - мощное средство разработки приложений (RAD) с новой поддержкой Microsoft Windows Vista и AJAX.
Разработчики имеют возможность быстро и легко создавать высококачественные клиентские приложения, поддерживающие интерфейсы пользователя Microsoft Windows Vista Aero, и корпоративные веб-приложения с AJAX. Delphi 2007 for Win32 включает также новую архитектуру баз данных DBX4, которая поддерживает самые последние версии наиболее популярных сегодня RDBMS, в том числе Microsoft SQL Server, InterBase от CodeGear, MySQL и Oracle, расширяя область применения уже ставшей популярной базовой платформы.
Borland Delphi 2007 for Win32, предназначенный для независимых продавцов программных продуктов (ISV) , системных интеграторов, активных посредников (VAR), а также малых и средних предприятий, позволяет разрабатывать "родные" ультра высокопроизводительные приложения для ОС Microsoft Windows XP или Vista, которые не только поддерживают обе платформы, но и используют все преимущества Vista.
Новая библиотека VCL для Web позволяет разработчикам быстро и наглядно создавать динамические веб-приложения с высококачественными AJAX- интерфейсами пользователя.
Новые возможности Borland Delphi 2007 for Win32:
Поддержка Microsoft Windows Vista и AJAX;
Разработка приложений под ОС Microsoft Windows 2000, Windows XP или Vista и развертывание приложений под ОС Windows 2000, Windows XP и Vista;
Поддержка Microsoft MSBuild для повышения гибкости версий и поддержка приложений сторонних разработчиков;
Новая архитектура баз данных DBX 4, которая упрощает взаимодействие баз данных;
Встроенная поддержка последних версий InterBase, Microsoft SQL Server, MySQL, Oracle и других RDBMS;
Поддержка тематических приложений;
Поддержка посредством библиотеки VCL эффектов отражения Microsoft Windows Vista Aero, диалоговых окон для работы с файлами в стиле Vista и компонентов диалоговых окон выполнения задач;
Библиотека VCL для Web с поддержкой AJAX. Обратная совместимость с компонентами Developer Studio 2006 от CodeGear.
Borland Delphi 2007 for Win32 содержит несколько сотен качественных усовершенствований, которые делают Delphi и построенные на его основе приложения более надежными и отказоустойчивыми, чем когда-либо прежде. Данный продукт включает также в свой состав последние версии популярных продуктов сторонних разработчиков, например, TeeChart, Indy и Rave Reports.
Основные функции:
Borland Delphi 2007 for Win32 Enterprise R2 - версия ориентирована на корпоративные разработки, когда требуется использование технологий AJAX, возможность создания сложных веб - приложений, а также подключение к корпоративным базам данных. Enterprise включает все функции Professional и кроме того поддерживает работу с Oracle 10g, MS SQL Server 2000/2005, Informix 9x, IBM DB2 8.x, Sybase 12.5 и позволяет использовать технологию AJAX при создании Web-приложений. Enterprise также содержит улучшенные функции для платформы Together Visual Modeling Platform, среди которых - новые диаграммы (Sequence, Collaboration, Deployment, Use Case, Activity и Component), конструктор шаблонов, XMI 1.1 Import/Export, создание документации, аудит и метрики.
2.2 Описание принципов построения, структуры и технологии использования САПР ПО на предприятии.
Delphi использует язык 3-го поколения Object Pascal, обладающий полной реализаций основных признаков объектной ориентации (инкапсуляция, наследование, полиморфизм), поддержкой RTTI-RunTime Type Information и встроенной обработкой исключительных ситуаций (Exception handling). Компонентная архитектура Delphi является прямым развитием поддерживаемой объектной модели. Все компоненты являются объектными типами (классами), с возможностью неограниченного наследования. Компоненты Delphi поддерживают PME-модель (Property, Method, Events), позволяющую изменять поведение компонентов без необходимости создания новых классов.
Компоненты Delphi
Delphi 2 Client/Server Suite включает систему контроля версий Intersolv PVCS, поддерживает работу со словарем данных (Data Dictionary) и Репозитарием объектов (Object Repository). Среда визуальной разработки Delphi позволяет единообразно работать как с предопределенными, так и с пользовательскими компонентами, которые разрабатываются на том же языке (Object Pascal), на котором создаются и конечные приложения.
Delphi 2 Client/Server Suite (GIF,12Kb)
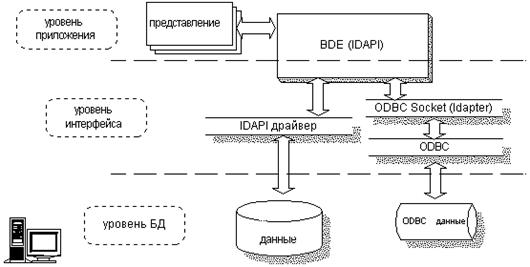
Borland Database Engine (BDE) обеспечивает единообразную работу с локальными данными (Paradox, dBase) и серверами БД (Oracle, Sybase, MS SQL Server, InterBase и т.д.), за счет применения навигационных методов доступа к серверным СУБД (двунаправленные курсоры, закладки и т.п.) и SQL - к локальным форматам (подмножество Local SQL).
|
|
| Рисунок 2. Структурная схема Borland Database Engine |
Компилятор Delphi является самым быстрым; имеет общий генератор кода с Borland C++ (Delphi 2 & BC++ 5). Компилятор Delphi (точнее, Object Pascal) является продолжением линии компиляторов Turbo Pascal / Borland Pascal.
Открытые интерфейсы Delphi - Open Tools API - обеспечивают контроль над средой разработки "из вне" и доступ к информации о проекте.
Delphi 2.01 Client/Server Suite включает CASE Expert, позволяющий импортировать данные из ведущих CASE в словарь данных Delphi, интегрировать IDE (Integrated Development Environment) с генераторами кода (например, Silver Run RDM компании CSA, WithClass 3.0 и т.п.).
"Эксперты" (программные модули, встраиваемые в IDE) позволяют использовать Delphi как "скелет" - общую среду разработки - для всего комплекса используемых инструментов.
При построении систем масштаба предприятия практически невозможно избежать неоднородности (разные ОС, СУБД, промежуточное ПО и т.п.). Встает вопрос о средствах объединения разных технологических платформ. Достаточно четко можно разбить архитектурно грамотную информационную систему на три "модуля" - клиентский, сервер приложений и БД.
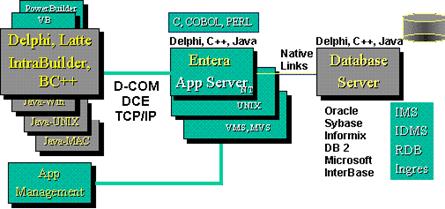
В рамках новой инициативы Golden Gate, Borland объединяет уже имеющиеся технологии с достижениями Open Environment Corporation - OEC (приобретена компанией Borland) в области средств для построения многоуровневых, распределенных систем. Продукт OEC OLEnterprise обеспечивает распределенные вычисления на базе технологий OLE automation / RPC (Remote Procedure Call) поверх D-COM и в отсутствии такового на всех платформах Windows (в том числе Win16). Полная автоматизация импорта/экспорта объектов в сети позволяет избежать необходимости изменения кода приложений для их взаимодействия на разных участках сети.
В силу того, что Delphi полностью поддерживает OLE-automation и предоставляет высокоуровневые средства работы с этими механизмами (специализированные классы, эксперты, языковые расширения), вариант совместного использования Delphi & OLEnterprise может оказать решающее воздействие на архитектуру системы => распределенные вычисления и локальные рабочие места - все в одном коде.
|
|
| Рисунок 3. Структурная схема OEC Architecture |
Так как Delphi обеспечивает создание "чистого" (native) кода посредством компиляции (например в самодостаточную - без интерпретатора - динамическую библиотеку DLL), возможна тонкая интеграция полученных программных модулей не только с 3-ми клиентскими приложениями но и с серверами приложений и баз данных на платформах Windows (в большей степени Windows NT, как следствие ее приспособленности для поддержки серверных звеньев). В качестве примера можно привести построение определяемых пользователем функций UDF для серверов БД Borland InterBase (например, для специфической обработки BLOB-полей).
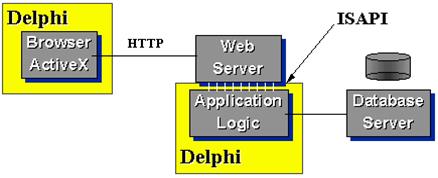
Главной целью Golden Gate является объединение лучших черт архитектуры клиент/сервер и модели intranet. И первым этапом ее реализации является добавление средств интеграции с Internet-технологиями в уже имеющиеся средства разработки. Delphi не является исключением. Выпущенная летом 1996 года обновленная версия Delphi 2.01 включает поддержку модулей сопряжения с Internet для Windows 95/NT - WinINET; возможность построения блоков расширения Microsoft Information Server через интерфейсы ISAPI & ISAPI Filter; 8 элементов ActiveX, полностью реализующих логику поддержки основных Internet-протоколов и HTML (обработка + отображение => построение броузеров) в виде повторно используемых компонентов.
|
|
| Рисунок 4. Схема взаимодействия с ActiveX |
С этих точек зрения, гибкость такого инструмента корпоративного разработчика, как Delphi становится не менее важным фактором, чем возможность стандартизации бизнес-логики и организации бизнес-процессов, но это уже тема для другого доклада.
3. Архитектура ЭВМ и МПС
3.1 Описание архитектурных свойств и структур ЭВМ, применяемых на предприятии
На предприятии установлены ЭВМ типа IBM PC ATX с архитектурой HyperTransport
Архитектура HyperTransport
Технология (архитектура) HyperTransport (HT) задумывалась как альтернатива шинно-мостовой архитектуре системных плат. Технология разработана компаниями AMD, Apple Computers, Broadcom, Cisco Systems, NVIDIA, PMC-Sierra, SGI, SiPackets, Sun Microsystems, Transmeta. Первый релиз вышел в 2001 году, в 2003-м — версия 1.10. Прежнее кодовое название — LDT (Lighting Data Transport).
Основная идея НТ — замена шинного соединения компонентов (периферийных устройств) системой двухточечных встречно направленных соединений. При этом достижима более высокая тактовая частота интерфейсов, что обеспечивает их более высокую (по сравнению с шиной) пропускную способность. Структурная схема компьютера архитектуры НТ приведена на рисунок 5. Главный мост (host bridge) обеспечивает связь НТ с ядром — процессором и памятью. Периферийные контроллеры, требующие высокой пропускной способности, реализуются в виде НТ-туннелей. В архитектуре предусматривается и мостовая связь с шиной PCI.
Архитектура НТ обеспечивает все типы транзакций процессоров и устройств PCI, PCI-X и AGP, используемые в PC. Транзакции выполняются в виде серий передач пакетов различных типов. В традиционных транзакциях целевое устройство идентифицируется адресом: чтение и запись в пространстве памяти, ввод-вывод в конфигурационном пространстве, а также считывание вектора прерывания из PIC 8259A и специальные циклы PCI (см. 14.2). Для унификации транзакций все пространства отображаются на единое 40-битное пространство адресов (объем 1 Тбайт), адрес передается в управляющих пакетах. Первые 1012 Гбайт пространства выделены для отображения обычного пространства памяти (для ОЗУ и ввода-вывода, отображенного на память). В оставшейся 12-гигабайтной области размещаются конфигурационное пространство (32 Мбайт), пространство ввода-вывода (32 Мбайт), память SMM, пространства адресов для выдачи векторов и подтверждения прерываний; 54 Мбайт остались в резерве. Транзакции НТ обеспечивают программное взаимодействие процессора с устройствами, прямой доступ к памяти и одноранговое взаимодействие устройств с адресацией в описанном комбинированном пространстве. Существует сетевое расширение спецификации, поддерживающее обмен сообщениями (как в сетях), причем возможны и широковещательные сообщения.
Транзакции выполняются расщепленным способом: инициатор посылает пакет-запрос и данные для транзакции записи, целевое устройство посылает пакет-ответ и данные для транзакций чтения. Технология НТ обеспечивает упорядоченность выполнения транзакций; есть возможность регулировать качество обслуживания (Quality of Service, QoS), что позволяет организовывать изохронные передачи.
|
|
| Рисунок 5.Архитектура HyperTransport |
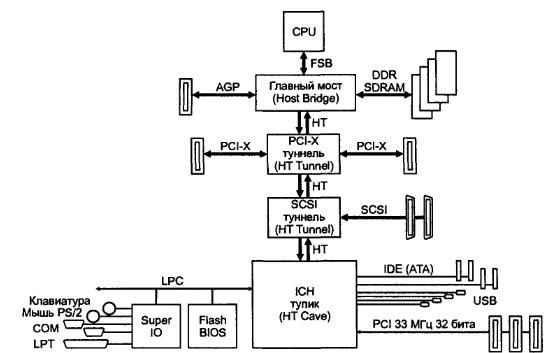
Сигнализация прерываний в НТ реализуется тоже пакетами: устройство посылает сообщение — выполняет транзакцию записи по адресу, указанному ему при конфигурировании (аналогично MSI на шине PCI). Обработчик прерывания посылает сообщение о завершении обработки прерывания (End Of Interrupt, EOI), делая запись по другому адресу, связанному с данным устройством. Такой механизм сигнализации запросов и подтверждений позволяет преодолеть неэффективность традиционого для PC механизма прерываний с помощью специальных линий IRQ.
Архитектура НТ основана на двусторонней пакетной передаче данных между парой устройств. Устройство НТ может выступать в роли инициатора или/и целевого устройства транзакций. По топологическим свойствам различают несколько типов устройств НТ:
- Туннель (tunnel) — устройство с двумя интерфейсами НТ; такие устройства могут собираться в цепочку (daisy chain), образующую логическую шину. Цепочка подключается к хосту (процессору с главным мостом), отвечающему за конфигурирование всех устройств и управляющему работой НТ.
- Мост (bridge) — устройство, соединяющее одну логически первичную шину (подключенную к хосту) с одной или несколькими логически вторичными шинами (цепочками). Мост имеет набор регистров, информация которых позволяет управлять распространением транзакций между этими шинами (аналогично мосту РС1).
- Коммутатор (switch) — устройство с несколькими интерефейсами НТ. по структуре аналогичное нескольким мостам PCI, подключенным к одной (внутренней) шине.
- Тупик, или пещера (cave) — устройство с одним интерфейсом НТ.
Хост (host) — это «хозяин шины», подключающийся к ней через главный мост и выполняющий функции конфигурирования (аналогично и совместимо с PCI). Основной вариант топологии — цепочка устройств-туннелей, подключенная верхним концом к хосту. Каждый интерфейс НТ состоит из двух независимых частей: передатчика и приемника. Каждому устройству при конфигурировании выделяются свои области в адресном пространстве. В цепочке устройства-туннели транслируют пакеты сверху вниз (нисходящий трафик) и снизу вверх (восходящий). Если в нисходящем управляющем пакете устройство обнаруживает свой адрес, оно «понимает», что обращаются к нему, и принимает соответствующую информацию (управляющие пакеты и данные). Восходящий трафик туннель транслирует «вслепую». На полученные запросы устройство отвечает посылкой пакетов вверх, включая их в транслируемый восходящий трафик. Таким образом обеспечивается программное взаимодействие процессора с устройствами. Собственные запросы на доступ к памяти устройство посылает тоже вверх, как и запросы (обращения) к другим устройствам (независимо от положения целевого устройства — выше или ниже в цепочке). Доставку пакета адресату обеспечивает главный мост: он разворачивает пакет, принятый из цепочки (адресованный не к ОЗУ), и посылает его вниз — так организуется одноранговое взаимодействие. На пакет, адресованный к ОЗУ, главный мост организует ответ от контроллера памяти, реализуя таким образом прямой доступ к памяти.
Возможны и более сложные топологии, например дерево (с мостами), позволяющее подключать больше тупиковых устройств. Возможна и цепочка с двумя хостами (на обоих концах), которая может использоваться двояко. В первом варианте обеспечиваются избыточность (дублирование функций хоста) и разде-ляемость узлов (доступность обоим хостам). При этом один главный мост становится ведущим («настоящим», разворачивающим одноранговые запросы и ответы), через него обеспечивается конфигурирование узлов. Другой мост становится ведомым — он является лишь средством связи второго хоста (процессора) с узлами. Программно при конфигурировании (инициализации НТ) роли мостов можно поменять. Во втором варианте одно из устройств разбивает шину (перестает работать туннелем), в результате получаются два хоста со своими короткими цепочками собственных (неразделяемых) устройств. С применением коммутаторов можно строить и более сложные, но беспетлевые топологии.
Технология HyperTransport предназначена для соединения компонентов компьютеров и коммуникационной аппаратуры, но только в пределах платы — слоты и карты расширения технологией НТ не рассматриваются. Для передачи информации используются два встречных однонаправленных набора высокоскоростных сигналов:
- CAD[n:0] — шина управления (control), адреса (address) и данных (data) разрядностью 2, 4, 8. 16 или 32 бита, причем во встречных направлениях может использоваться различная разрядность. У передатчика сигналы CADOUTx, у приемника — CADINx;
- CTL — сигнал-признак, позволяющий различать передачи пакетов управляющей информации и данных. У передатчика сигнал CTLOUT, у приемника — CTLIN;
- CLK — сигнал синхронизации (по фронту и спаду), для каждого байта CAD используется своя линия CLK (их может быть 1, 2 или 4). У передатчика сигналы CLKOUTx, у приемника — CLKINx.
Сигналы передаются по дифференциальным парам проводов с импедансом 100 Ом, сигналы — LVDS (низковольтные дифференциальные, уровень1,2 В). Частота синхронизации 200, 300, 400, 500, 600, 800 и даже 1000 МГц обеспечивает физическую скорость передачи 400,600,800, 1000,1200, 1600 и 2000 МТ/с (миллионов передач в секунду), что при самых больших разрядности (32 бит) и частоте обеспечивает пиковую скорость передачи данных до 8 Гбайт/с. В первой версии предельная частота была 800 МГц, что давало скорость 6,4 Гбайт/с. Поскольку пакеты могут передаваться одновременно в обоих направлениях, можно говорить о суммарной пропускной способности 12,8 или 16 Гбайт/с.
Помимо сигналов для передачи пакетов, имеются сигналы сброса и инициализации (PWR0K — признак стабильности питания и синхронизации, RESETS — сброс цепочки устройств), а также управления энергопотреблением (L0TST0PS — разрешение/запрет использования соединения при смене состояний системы, LDTREQ# — индикатор активности соединения или его запроса устройством). Эти сигналы «медленные», их формируют передатчики с открытым стоком (open-drain), все одноименные сигналы цепочки объединяются, выполняя функцию «монтажного ИЛИ». Уровни сигналов — LVTTL/CMOS (2,4 В).
По замыслу разработчиков, НТ должна стать архитектурой построения PC, однако пока что используется лишь технология НТ. В вышеприведенном примере главный мост реализует интерфейс AGP. В 64-битных процессорах AMD, в которых применяется НТ, главный мост размещается в самом процессоре. При этом у процессора оказывается два интерфейса: интерфейс памяти (пока что DDR SDRAM) и НТ в качестве системной шины. В распространенных чипсетах (от VIA, SiS) к интерфейсу НТ подключается только северный хаб, обеспечивающий лишь интерфейс подключения графического адаптера — AGP или PCI-E. Южный хаб соединяется с северным собственным интерфейсом, так что использования НТ как универсальной транспортной структуры для множества компонентов пока не наблюдается.
Северные мосты и хабы
Северный хаб (как и мост) определяет основные возможности системной платы:
- Поддерживаемые процессоры — типы, частоты системной шины, возможности мультипроцессорных или избыточных конфигураций. Типы процессо-
ров определяются протоколами системной шины, которых в настоящее время несколько:
- шина Pentium процессоров для сокета 7, Super7 (и сокета 5); частоты 50-100 МГц;
- шина Р6 процессоров для сокета 8, слотов 1 и 2, сокета-370; частоты 66-133 МГц;
- шина Pentium 4 для сокстов с 423, 478/479, 603/604 и 775 контактами; частота синхронизации 100-266 МГц при 4-кратной «накачке» обеспечивает частоту передачи данных 400-1066 МГц;
- шина EV-6 процессоров Athlon, Duron, Semptron для слота А и сокета А (462 контакта); частоты передачи данных 200-400 МГц (тактовая частота в два раза ниже);
- интерфейс HyperTransport процессоров со встроенным контроллером памяти (Athlon 64, Opteron, мобильные Turion 64 и Semptron) для сокетов с 754 и 939/940 выводами.
- Типы памяти и частота работы шины памяти1;
- DRAM (FPM, EDO, BEDO) с временем доступа 50-80 не;
- SDRAM (PC66. РС100, РС133) с частотами 66-133 МГц;
- DDR SDRAM (PC1600. РС2Ю0, РС2700, РС3200) с частотами 100-200 МГц (частота передачи в два раза выше);
- DDR2 SDRAM (РС2-3200, РС2-4300, РС2-5300, РС2-5300, РС2-6400) с частотами 200-400 МГц (частота передачи в два раза выше);
- RDRAM (РС600, РС700, РС800. РС1066) с частотами 300, 356, 400 и 533 МГц.
- Максимальный объем памяти. На него влияет ряд факторов:
- число слотов под модули памяти и поддерживаемые объемы модулей (допустимое число устанавливаемых модулей при работе на самой высокой частоте шины памяти может оказаться меньше, чем число слотов);
- максимальное количество «рядов» микросхем памяти (может ограничивать возможное число устанавливаемых двусторонних модулей).
- Число каналов памяти — пока чаще один, но для повышения пропускной способности применяются два канала. Поначалу двухканальность использовалась только для RDRAM (здесь меньше интерфейсных сигналов в канале), теперь есть двухканальные контроллеры DDR SDRAM и DDR2 SDRAM. В оба канала должны быть установлены попарно однотипные модули (как раньше пары SIMM-72 для Pentium).
- Возможность и эффективность применения разнородной памяти (например, DRAM вместе с SDRAM в старых платах, SDRAM и DDR SDRAM в более новых) и модулей с разным быстродействием (разная латентность при оди-
наковой частоте). В ряде случаев разнородная память снижает производительность всей памяти, и не всегда эта потеря окупается получаемым увеличением объема ОЗУ.
- Для старых плат с DRAM — возможность чередования банков (у современных типов памяти чередование банков внутреннее).
- Поддержка контроля достоверности памяти и исправления ошибок (ЕСС).
- Средства подключения графического акселератора (высокопроизводительное подключение), для которого уже имеется несколько вариантов:
- порт AGP и его характеристики (режим 2х/4х/8х, внеполосная адресация SBA, быстрая запись Fast Writes); для чипсетов с интегрированной графикой интересна доступность порта при отключении внутреннего графического адаптера;
- слоты PCI-E 8х или 16х для подключения графического адаптера (1 или 2 порта); слоты PCI-E 1х может обеспечивать как северный, так и южный хаб;
- графический адаптер с интерфейсом HyperTransport (пока что это теоретический вариант).
- Возможности системы управления энергопотреблением (ACPI или АРМ) — реализуемые энергосберегающие режимы процессора и памяти, управление производительностью, SMM.
Северный мост плат для сокетов 5,7 и Super7 определяет также политику записи кэша, применяемые типы и быстродействие микросхем статической памяти, возможный размер кэша и кэшируемой области основной памяти. Для современных плат без кэша все эти параметры определяются процессором, а политику обратной записи поддерживают уже все платы.
Северный мост определяет также поддерживаемые частоты и разрядность шины PCI и PCI-X, возможное количество контроллеров шины PCI (число пар сигналов арбитра PCI), способы буферизации, возможности одновременных обменов. Северный хаб на эти параметры уже не влияет, поскольку шины PCI и PCI-X подключаются к южному хабу.
Южные мосты и хабы
Южный хаб чипсета обеспечивает подключение шин PCI, PCI-X и «маломощных» портов PCI-E, ISA (но уже не всегда), АТА (2 канала), SAT A, USB, FireWire, а также «мелких» контроллеров ввода-вывода, памяти CMOS и флэш-памяти с системным модулем BIOS. В южной части располагаются таймер (8254), контроллер прерываний (совместимый с парой 8259 или APIC), контроллер DMA для шины ISA и периферии системной платы. Если в чипсет интегрирован звук, то южный хаб (мост) имеет контроллер интерфейса AC-Link или HDA Link для подключения аудиокодека, а то и сам аудиокодек. Поскольку шина ISA отправляется в отставку, для контроллеров ввода-вывода, ранее подключавшихся к шине X-BUS (это практически та же ISA), ввели новый интерфейс LPC (Low Pin Count). Он, как и следует из названия, имеет малое чис-
ло линий (6], что значительно облегчает разработку чипсета и системной платы. Флэш-память для хранения системной памяти BIOS стали помещать в специальный хаб (firmware hub), соединяемый с южным хабом отдельной шиной (аналогичной LPC). Флэш-память может подключаться и прямо к шине LPC. Для подключения энергонезависимой памяти (EEPROM) хаб может иметь дополнительный последовательный интерфейс. Для обслуживания процессоров, имеющих дополнительную сервисную шину SMBus, а также для поддержки слота CNR хаб может иметь последовательный интерфейс I2C (Inter 1С — интерфейс связи микросхем). Этот же интерфейс может использоваться для чтения идентификаторов модулей памяти (12С и SMBus — близкие родственники, несколько различающиеся набором команд). В южный хаб интегрированных чипсетов вводят и контроллер локальной сети (как правило, Ethernet).
Логически южный хаб представляется как набор виртуальных мостов и устройств, подключенных к главной шине PCI. Однако обмены данными с широкополосными устройствами (IDE, SATA, USB, FireWire, Ethernet, AC'97 или HDA) на внешнюю шину PCI все-таки не «выплескивают», иначе теряется смысл южного хаба.
Южный хаб (или мост) определяет перечисленные далее параметры системной платы:
- Параметры шины PCI (только для хабов):
- версия интерфейса и режимы (PCI, PCI-X, PCI-X 2.0);
- разрядность (32 или 64 бита);
- частота (33 или 66 МГц для PCI. до 133 МГц для PCI-X);
- допустимое количество контроллеров шины (число каналов арбитра, которое влияет на число слотов и встроенных устройств PCI).
- Число маломощных (4х) портов PCI-E.
- Параметры интерфейсов АТА:
- поддерживаемые режимы UltraDMA — ATA/33, ATA/66, ATA/100, АТА/133;
- независимость каналов — электрическое разделение каналов, возможность одновременной работы двух каналов.
- Параметры интерфейса SATA: тип контроллера (желательно AHCI), число портов, возможность одновременного использования с параллельной шиной.
- Число портов и версия шины USB.
- Наличие интерфейса AC-Link или HDA Link.
- Наличие шины ISA.
- Возможность эмуляции DMA на шине PCI (PC-PCI, DDMA).
- Возможности мониторинга состояния;
- число каналов измерения питающих напряжений;
- число каналов измерения температуры;
- число каналов измерения частоты вращения вентиляторов.
Контроллеры гибких дисков, интерфейсных портов, клавиатуры, CMOS RTC могут входить в собственно чипсет, а могут быть реализованы и на отдельных «инородных* микросхемах. От них зависят следующие параметры системной платы:
- наличие порта PS/2 Mouse (есть во всех платах АТХ);
- режимы параллельного порта (стандартный, двунаправленный, ЕСР, ЕРР, поддержка FIFO и DMA);
- режимы последовательных портов (стандартом считается совместимость с 16550А и поддержка FIFO и DMA);
- поддержка IrDA;
- типы поддерживаемых дисководов (2,88 Мбайт поддерживают теперь почти все контроллеры, но эта возможность не востребована дисководами и дискетами).
3.2 Характеристики и параметры МП, на базе которых выполнены ПК, применяемые на предприятии прохождения практик
На предприятии в основном установлены МП Intel Pentium 4
Pentium 4 1800 на ядре Willamette
В их основе лежит принципиально отличающееся от предшественников ядро — Willamette. Процессоры Pentium 4 используют новую системную шину, позволявшую передавать данные с частотой, превышавшей базовую в четыре раза (англ. quad pumped bus). Таким образом, эффективная частота системной шины первых процессоров Pentium 4 составляла 400 МГц (физическая частота — 100 МГц).
Процессоры на ядре Willamette имеют кэш данных первого уровня объёмом 8 Кбайт, кэш последовательностей микроопераций объёмом около 12 000 микроопераций, а также кэш-память второго уровня объёмом 256 Кбайт. При этом процессор содержит 42 млн транзисторов, а площадь кристалла составляла 217 мм², что объясняется устаревшей технологией производства — 180 нм КМОП с алюминиевыми соединениями Процессоры на ядре Willamette выпускались в корпусе типа FCPGA (в случае с Pentium 4 этот корпус представлял собой микросхему в корпусе OLGA, установленную на переходник PGA) и предназначались для установки в системные платы с разъёмом Socket 423, а затем — в корпусе типа FC-mPGA2 (Socket 478).
Процессоры работают на тактовой частоте 1,3—2 ГГц с частотой системной шины 400 МГц, напряжение ядра составляло 1,7—1,75 В в зависимости от модели, а максимальное тепловыделение — 100 Вт на частоте 2 ГГц.
Intel Pentium 4 1800 на ядре Northwood
Представлявшем собой ядро Willamette с увеличенным до ½ Мбайт объёмом кэш-памяти второго уровня. Процессоры на ядре Northwood содержат 55 млн транзисторов и производились по новой 130 нм КМОП-технологии с медными соединениями. За счёт использования новой технологии производства удалось значительно сократить площадь кристалла: кристалл процессоров на ядре Northwood ревизии B0 имел площадь 146 мм², а в последующих ревизиях площадь кристалла уменьшилась до 131 мм².
Тактовая частота процессоров Pentium 4 на ядре Northwood составляла 1,6—3,4 ГГц, частота системной шины — 400, 533 или 800 МГц в зависимости от модели. Все процессоры на ядре Northwood выпускались корпусе типа FC-mPGA2 и предназначались для установки в системные платы с разъёмом Socket 478, напряжение ядра этих процессоров составляло 1,475—1,55 В в зависимости от модели, а максимальное тепловыделение — 134 Вт на частоте 3,4 ГГц.
Pentium 4 3066 МГц, поддерживающий технологию виртуальной многоядерности — Hyper-threading. Этот процессор оказался единственным процессором на ядре Northwood с частотой системной шины 533 МГц, обладавшим поддержкой технологии Hyper-threading. В дальнейшем эту технологию поддерживали все процессоры с частотой системной шины 800 МГц (2,4—3,4 ГГц).
Pentium 4 на ядре Prescott. Впервые с момента своего появления архитектура NetBurst претерпела значительные изменения.
Основным отличием ядра Prescott от предшественников являлся удлинённый с 20 до 31 стадии конвейер. Это позволило увеличить частотный потенциал процессоров Pentium 4, однако могло приводить к более серьёзным потерям производительности при ошибке предсказания переходов. В связи с этим ядро Prescott получило усовершенствованный блок предсказания переходов, позволивший значительно сократить количество ошибок предсказания. Кроме того, было модернизировано АЛУ, в частности, был добавлен блок целочисленного умножения, отсутствовавший в процессорах на ядрах Willamette и Northwood. Кэш данных первого уровня был увеличен с 8 до 16 Кбайт, а кэш второго уровня — с ½ до 1 Мбайт.
Процессоры Pentium 4 на ядре Prescott получили поддержку нового дополнительного набора команд — SSE3, а также поддержку технологии EM64T (в ранних процессорах поддержка 64-битных расширений была отключена). Кроме того, была оптимизирована технология Hyper-threading (в частности, в набор SSE3 вошли инструкции, предназначенные для синхронизации потоков).
В результате изменений, внесённых в архитектуру NetBurst, производительность процессоров на ядре Prescott изменилась по сравнению с процессорами на ядре Northwood, имеющими равную частоту, следующим образом: в однопоточных приложениях, использующих инструкции x87, MMX, SSE и SSE2, процессоры на ядре Prescott оказывались медленнее, чем предшественники, а в приложениях, использующих многопоточность или чувствительных к объёму кэш-памяти второго уровня, опережали их
Тактовая частота процессоров Pentium 4 на ядре Prescott составляла 2,4—3,8 ГГц, частота системной шины — 533 или 800 МГц в зависимости от модели. При этом в настольных процессорах с тактовой частотой ниже 2,8 ГГц была отключена поддержка технологии Hyper-threading. Изначально процессоры на ядре Prescott выпускались в корпусе типа FC-mPGA2 (Socket 478), а затем — в корпусе типа FC-LGA4 (LGA775). Процессоры содержали 125 млн транзисторов, производились по 90 нм технологии КМОП с использованием растянутого кремния (англ. strained silicon), площадь кристалла составляла 112 мм², напряжение ядра — 1,4—1,425 В в зависимости от модели.
Несмотря на то, что процессоры на ядре Prescott производились по новой 90 нм технологии, добиться снижения тепловыделения не удалось: так, например, Pentium 4 3000 на ядре Northwood имел типичное тепловыделение 81,9 Вт, а Pentium 4 3000E на ядре Prescott в корпусе типа FC-mPGA2 — 89 Вт. Максимальное тепловыделение процессоров Pentium 4 на ядре Prescott составляло 151,13 Вт на частоте 3,8 ГГц.
Pentium 4 на модернизированном ядре Prescott. Это ядро отличалось от предшественника лишь увеличенным до 2 Мбайт объёмом кэш-памяти второго уровня, поэтому получило наименование Prescott 2M. Количество транзисторов в процессорах на новом ядре увеличилось до 188 млн, площадь кристалла — до 135 мм², а напряжение ядра не изменилось по сравнению с процессорами на ядре Prescott.
Все процессоры на ядре Prescott 2M выпускались в корпусе типа FC-LGA4, имели частоту системной шины 800 МГц, поддерживали технологии Hyper-threading и EM64T. Тактовая частота процессоров Pentium 4 на ядре Prescott 2M составляла 3—3,8 ГГц.
Pentium 4 641 на ядре Cedar Mill
Процессоры на ядре Cedar Mill были представлены компанией Intel 16 января 2006 года. Cedar Mill стало последним ядром, использовавшимся в процессорах Pentium 4. Оно представляло собой ядро Prescott 2M, выпускаемое по новой технологии — 65 нм. Применение 65 нм технологии позволило уменьшить площадь кристалла до 81 мм².
Существовало четыре модели процессоров Pentium 4 на ядре Cedar Mill: 631 (3 ГГц), 641 (3,2 ГГц), 651 (3,4 ГГц), 661 (3,6 ГГц). Все они работали с частотой системной шины 800 МГц, предназначались для установки в системные платы с разъёмом LGA775, а также поддерживали технологии Hyper-threading и EM64T. Напряжение питания этих процессоров составляло 1,2—1,3375 В, максимальное тепловыделение — 116,75 Вт.
Процессоры Pentium 4 на ядре Cedar Mill выпускались до 8 августа 2007 года, когда компания Intel объявила о снятии с производства всех процессоров архитектуры NetBurst.
3.3 Структура МПС
Микроархитектура процессора Pentium 4
На первый взгляд Pentium 4 кажется вполне традиционной CISC-машиной с большим и громоздким набором команд, поддерживающим 8-, 16- и 32-разрядные целочисленные операции, а также 32- и 64-разрядные операции с плавающей точкой. В нем всего 8 доступных регистров, причем ни один из них не повторяет другие. Допустимая длина команд составляет 1-17 байт.
На самом же деле процессор Pentium 4 основан на современном надежном RISC-ядре с развитой конвейеризацией. Его тактовая частота уже очень высока, а в последующие годы, скорее всего, вырастет еще больше. Удивительно, как инженерам Intel на основе архаичной архитектуры удалось построить процессор, отвечающий всем современным требованиям.
Обзор микроархитектуры NetBurst
Микроархитектура Pentium 4. называемая NetBurst. ознаменовала собой решительный отход от принципов микроархитсктуры Р6. использовавшейся в процессорах Pentium Pro, Pentium II и Pentium III. Она дает определенное представление о том, на какой базе продукция Intel будет разрабатываться в течение нескольких ближайших лет. Примерная схема микроархитектуры Pentium 4 изображена на рисунке6.
|
|
| Рисунок 6. Микроархитектура Pentium 4 |
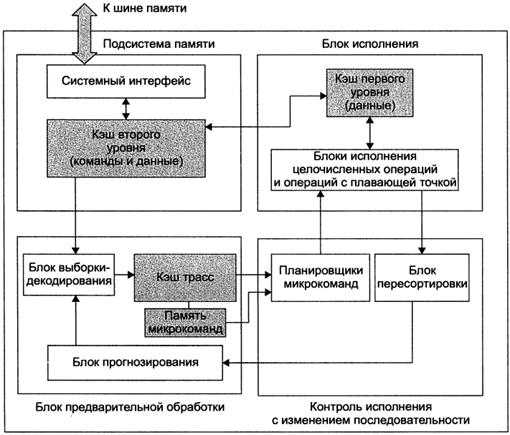
Pentium 4 состоит из четырех основных блоков: подсистемы памети, блока предварительной обработки, блока контроля исполнения с изменением последовательности и блока исполнения. Рассмотрим эти блоки по порядку, начиная с верхнего левого и продвигаясь против часовой стрелки.
В состав подсистемы памяти входит объединенный кэш второго уровня (L2), а также логика доступа к внешнему ОЗУ по шине памяти. В первом поколении Pentium 4 объем L2 составлял 256 Кбайт; во втором — 512 Кбайт; в третьем — 1 Мбайт. L2 представляет собой 8-входовую ассоциативную кэш-память с 128-байтным строками. Если запрос к кэшу второго уровня не приносит результата, организуются две 64-байтных передачи в основную намять, посте чего из нес выбираются необходимые блоки. Данный кэш L2 относится к категории КЭШей с отложенной записью. Иными словами, новые данные в измененной строке записываются обратно в память лишь после сброса.
С кэшем тесно связан блок предварительной выборки (он не показан на рисунке), который пытается перенести данные из основной памяти в L2 еще до того, как эти данные запрошены. Из L2 данные могут на высокой скорости передаваться в другие блоки кэш-памяти. За один цикл может быть выполнена одна операция выборки из L2; так, на тактовой частоте 3 ГГц из L2 в другие кэши теоретически можно передать до 1,5 млрд 64-байтных блоков в секунду - таким образом, пропускная способность становится равной 96 Гбайт/с
Под изображенной на рисунке 5 подсистемой памяти находится блок предварительной обработки, который выбирает команды на L2 и декодирует их в порядке выполнения команд программы. Каждая команда на уровне ISA разбивается на последовательность RISC-подобных микроопераций. Для упрощения команд блок выборки-декодирования определяет, какие микрооперации необходимы для решения внутренних задач. В более сложных случаях производится поиск последовательности микроопераций в памяти микрокоманд. В любом случае команда уровня ISA процессора Pentium 4 преобразуется в последовательность микроопераций, подлежащих исполнению RISC-ядром микросхемы. Этот механизм позволяет «навести мосты» между устаревшим набором CISC-команд и современным трактом данных RISC.
Декодированные микрооперации отправляются в кэш трасс (trace cache), в роли которого выступает кэш команд первого уровня. Поскольку кэшируются на исходные команды, а декодированные микрооперации, необходимость в повторном декодировании при извлечении команды из кэша трасс отпадает. В этом заключается одно из наиболее существенных расхождений между микроархитектурами NetBurst и Р6 (в последней команды Pentium удерживались в кэше команд первого уровня). Здесь же выполняется прогнозирование ветвлений.
Команды перелаются из кэша трасс планировщику команд в порядке, определяемом программой, но при их выполнении возможно отступление от этого порядка. При обнаружении микрооперации, которую нельзя выполнить, планировщик команд удерживает ее, одновременно продолжая обрабатывать поток команд - запускаются все последующие команды, которые не предусматривают обращение к занятым ресурсам (регистрам, функциональным блокам и т. д.). Здесь же выполняется подмена регистров, благодаря чему WAR- и WAW-взаимозависемы команды могут выполняться без задержки.
Как уже отмечалось, очередность запуска команд может не соответствовать предусмотренной в программе. В то же время требование архитектуры Pentium, касающееся точных прерываний, говорит о том, что ISA-команды должны возвращать результаты без отступления от заданной программой последовательности. За реализацию этого требования отвечает блок пересортировки.
В верхней правой части рисунка изображен блок исполнения, объединяющий специализированные блоки исполнения, которые непосредственно осуществляют целочисленные операции, операции с плавающей точкой и специализированные команды. Существует несколько блоков исполнения, работающих параллельно. Данные они получают из регистрового файла и кэша данных первого уровня.
Конвейер NetBurst
На рисунке6 приводится более подробная схема микроархитектуры NetBurst, в том числе ее конвейер. В верхней части схемы изображен блок предварительной обработки, ответственный за выборку команд из памяти и их подготовку к выполнению. Этот блок получает новые инструкции Pentium из кэша второго уровня порциями по 64 бит. Они декодируются в микрооперации и помешаются в кэш трасс. Емкость кэша трасс составляет 12 000 микроопераций, и по своей производительности он сопоставим с традиционным кэшем первого уровня на 8 или 16 Кбайт.
|
|
| Рисунок 7 . Упрощенная схема тракта данных Pentium 4. |
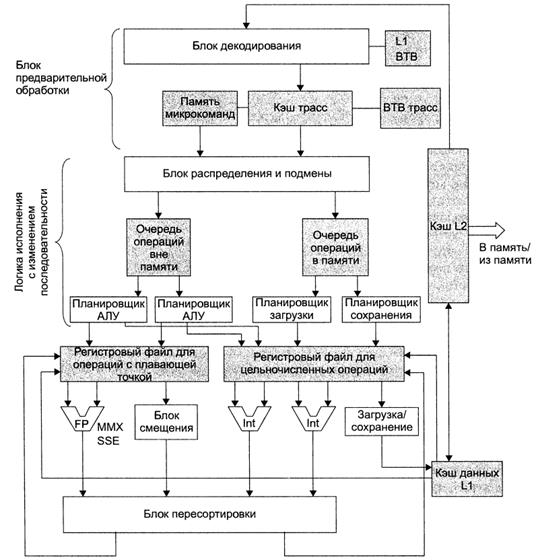
В кэше тpacc каждые шесть микроопераций объединяются в группу, занимающую одну строку Микрооперации из одной строки выполняются без нарушение последовательности, хотя они могут быть образованы из ISA команд Penium, отстоящих друг от друга на тысячи байтов. Для формирования более протяженных последовательностей микроопераций практикуется объединение трассируемых строк.
Если для выполнения ISA-команды Pentium требуется более четырех микроопераций, она не декодируется и не помещается в кэш трасс. Вместо этого она снабжается специальным маркером, заставляющим систему провести поиск микроопераций в памяти микрокоманд. Таким образом, логика исполнения с изменением последовательности получает микрооперации путем извлечения из кэша трасс ранее декодированных ISA-команд или оперативного поиска сложных ISA-команд (например, команды смешения строки) в памяти микрокоманд.
Встретившись с командой безусловного перехода, блок декодирования ищет предсказанный объект перехода в буфере объектов перехода (Branch Target Buffer, ВТВ) первого уровня и продолжает декодирование с соответствующего адреса. В кэше буфера объектов перехода первого уровня сохраняются 4000 последних переходов. Если необходимая команда перехода отсутствует в таблице, применяется статическое прогнозирование. При этом подразумевается, что обратный переход, во-первых, является частью цикла, во-вторых, не занят. Точность статического прогноза в этом случае очень высока. Прямой переход считается незанятым и входящим в структуру оператора if. Точность статического прогноза в случае прямых переходов значительно ниже, чем и случае обратных. Для прогнозирования микрооперации перехода применяется буфер трасс объектов перехода, или ВТВ трасс.
Второй компонент конвейера — логика исполнения с изменением последовательности — получает данные из кэша трасс емкостью 12 000 микрооперации. При поступлении из блока предварительной обработки каждой последующей микрооперации (а за цикл их поступает три) блок распределения и подмены регистрирует се в таблице, состоящей из 128 записей и называемой буфером переупорядовачивания команд (ReOrder Buffer, ROB). В этом буфере хранятся данные о состоянии микрооперации, вплоть до пересортировки ее результатов. Затем блок распределения и подмены проводит проверку на предмет доступности ресурсов, необходимых для выполнения микрооперации. Если ресурсы свободны, микрооперация устанавливается в одну из очередей на выполнение. Для микроопераций, исполняемых в памяти и вне памяти, предусмотрены отдельные очереди. Если выполнение микрооперации в данный момент невозможно, она откладывается, однако обработка последующих микроопераций продолжается; таким образом, микрооперации часто выполняются вне их исходной последовательности. Этот принцип позволяет поддерживать загрузку всех функциональных блоков на максимально высоком уровне. В каждый отдельно взятый момент могут одновременно обрабатываться до 126 команд, причем 48 из них могут загружаться из памяти, а 24 - сохраняться в памяти.
Иногда микрооперации простаивают. Это происходит в тех случаях, когда к одному и тому же регистру для чтения или записи пытаются обратиться несколько микроопераций; соответственно, одной из них это удается, а остальным
нет. Такие конфликты, как мы уже выяснили, называются WAR- и WAW-взаи-мозависимостями. Подмена целевого регистра позволяет записать результаты выполнения микрооперации в один из 120 временных (регистров, а значит, выполнить эту микрооперацию немедленно. Если же все временные регистры недоступны или микрооперация попадает в ситуацию RAW-взаимозависимости (обойти которую нельзя), планировщик указывает характер возникшей проблемы в виде записи в буфере ROB. Впоследствии, после освобождения всех необходимых ресурсов, микрооперация устанавливается в одну из очередей на выполнение.
Блок распределения и подмены помещает готовые к выполнению операции в одну из двух очередей. Четыре планировщика ответственны за извлечение микрокоманд из очередей. Каждый планировщик регламентирует обращения к тем или иным ресурсам:
1. Планировщик 1 - АЛУ 1 и блок смещения операций с плавающей точкой.
2. Планировщик 2 - АЛУ 2 и блок исполнения операций с плавающей точкой.
3. Планировщик 3 - команды загрузки.
4. Планировщик 4 - команды сохранения.
Поскольку планировщики и АЛУ работают на скорости, вдвое превышающей номинальную тактовую частоту, первые два планировщика могут передавать но две микрооперации за цикл. Учитывая то, что два целочисленных АЛУ тоже работают на удвоенной скорости, процессор Pentium 4 с тактовой частотой 3 ГГц способен выполнять 12 млрд целочисленных операций в секунду. В силу столь высокой скорости блок контроля исполнения с изменением последовательности испытывает некоторые трудности с загрузкой АЛУ. Команды загрузки и сохранения проходят через один блок исполнения, работающий на удвоенной частоте, который в течение одного цикла может вызывать по одной команде обоих типов. Таким образом, в лучшем случае (при отсутствии операций с плавающей точкой) за цикл может' быть вызвано 6 целочисленных микроопераций.
Два целочисленных АЛУ неодинаковы. АЛУ 1 выполняет любые арифметические и логические операции и переходы. АЛУ 2 способно выполнять только команды сложения, вычитания, сдвига и циклического сдвига. Не идентичны и два блока исполнения операций с плавающей точкой. Первый из них выполняет только сдвиги и SSE-команды. Второй поддерживает арифметические операции с плавающей точкой, а также ММХ- и SSE-команды.
АЛУ и блоки исполнения операций с плавающей точкой получают данные от двух регистровых файлов емкостью по 128 записей. Один из этих файлов отводится для целых чисел, другой — для чисел с плавающей точкой. В них содержатся все опранды, необходимые для исполнения команд; кроме того, они играют роль хранилища результатов. В силу подмены регистров восемь из них содержат регистры, доступные на уровне архитектуры команд (ЕАХ. ЕВХ. ЕСХ. EDX и т. д.), однако расположение «реальных» значений в каждом конкретном случае зависит от изменений в отображении, происходящих в ходе выполнения.
Кэш данных первого уровня является одним из компонентов высокоскоростной (2х) схемы. При емкости 8 Кбайт в нем хранятся целые числа, числа с плавающей точкой и другие типы данных. В отличие от кэша трасс, эти данные никоим образом не декодируются. Функция кэша данных сводится к хранению копий байтов, находящихся в памяти. Что касается его характеристик, то кэш данных первого уровня представляет собой 4-входовую ассоциативную кэш-память с емкостью строки 64 байт. Он поддерживает сквозную запись; иными словами, при изменении строки кэша она незамедлительно копируется обратно в кэш второго уровня. В течение никла кэш данных первого уровня обрабатывает по одной операции чтения и записи. Пели затребованное слово не удается обнаружить в кэше первого уровня, отправляется запрос в кэш второго уровня; по* следний в такой ситуации может ответить либо сразу, либо после выборки соответствующей строки из памяти. В любой момент и состоянии исполнения могут находиться до четырех запросов, направленных из кэша первого уровня в кэшвторого уровня.
Так как микрооперации выполняются вне исходной последовательности, сохранение в кэше первого уровня возможно только после пересортировки результатов всех команд, предшествующих команде сохранения. Такую пересортировку результатов с их трассировкой (отслеживанием того, где они находятся) выполняет блок пересортировки В случае прерывания прекращается обработка всех команд, еще не прошедших пересортировку результатов; таким образом, обеспечивается соблюдение требования, согласно которому при прерывании
Команды процессора Pentium 4
Команды Pentium 4 представляют собой причудливую смесь 32-разрядных команд, а также команд, появившихся еще в процессоре 8088. В таблице1 приведены наиболее распространенные целочисленные команды, при этом используются следующие обозначения:
SRC - источник данных;
DST - приемник данных:
#-количество битов, из которое происходит сдвиг;
LV - количество локальных переменных.
Перечень далеко не полный, поскольку в него не вошли команды с плавающей точкой, команды управления, а также некоторые нечасто встречающиеся целочисленные команды (например, использование 8-разрядного байта для выполнения поиска по таблице). Тем не менее таблица дает представление о том, какие действия может выполнять Pentium 4.
Многие команды Pentium 4 обращаются к одному или к двум операндам, которые находятся в регистрах или памяти. Например, бинарная команда ADD складывает два операнда, а унарная команда INC увеличивает значение одного операнда на 1. Некоторые команды имеют несколько похожих вариантов. Например, команды сдвига могут сдвигать слово либо вправо, либо влево, с учетом знакового бита или без учета. Большинство команд имеют несколько различных колировок в зависимости от природы операндов.
Таблица 1.
| Команда |
Описание |
| Команды перемещения |
|
| MOV DST. SRC |
Перемещение из SRC в DST |
| PUSH SRC |
Помещение из SRC в стек |
| POP DST |
Выталкивание слова из стека и помещение его в DST |
| XCHG DS1.DS2 |
Смена мест DS1 и DS2 |
| LEA DST. SRC |
Загрузка действительного адреса SRC в DST |
| CMOV DST. SRC |
Условное перемещение |
| Арифметические команды |
|
| ADD DST, SRC |
Сложение SRC и DST |
| SUB DST. SRC |
Вычитание SRC из DST |
| MUL SRC |
Умножение ЕАХ на SRC (без учета знака) |
| IMUL SRC |
Умножение ЕАХ на SRC (с учетом знака) |
| DJV SRC |
Деление EDX:EAX на SRC (без учета знака) |
| IDV SRC |
Деление EDX:EAX на SRC (с учетом знака) |
| ADC DST. SRC |
Сложение SRC с DST и прибавление бита переноса |
| S88 DST. SRC |
Вычитание DST и перенос из SRC |
| INC DST |
Инкремент (прибавление 1) DST |
| DEC DST |
Декремент (вычитание 1) DST |
| NEG DST |
Отрицание DST (вычитание DST из 0) |
| Двоично-десятичные команды |
|
| DAA |
Десятичная коррекция |
| AAA |
Коррекция ASCII-кода для сложения |
| AAS |
Коррекция ASCII-кода для вычитания |
| AAM |
Коррекция ASCII-кода для умножения |
| AAD |
Коррекция ASCII-кода для деления |
| Логические команды |
|
| AND DST, SRC |
Логическая операция И над SRC и DST |
| OR DST. SRC |
Логическая операция ИЛИ над SRC и DST |
| XOR DST. SRC |
Логическая операция ИСКЛЮЧАЮЩЕЕ ИЛИ над SRC и DST |
| NOT DST |
Замещение DST дополнением до 1 |
| Команды обычного и цикличесхого сдвига |
|
| SAL/SAR DST. # |
Сдвиг DST влево/вправо на * бит |
| SHL/SHR DST. # |
Логический сдвиг OST влево/вправо на я бит |
| ROL/ROR OST, * |
Циклический сдвиг DST влево/вправо на # бит |
| ROL/ROR OST. ш |
Циклический сдвиг OST по переносу на * бит |
| Команды тестирования и сравнения |
|
| TSTSRC1.SRC2 |
Операнды логической операции И. установка флагов |
| CMP SRC1.SRC2 |
Установка флагов на основе разности SRC1 - SRC2 |
| Команды передачи управления |
|
| JMP ADDR |
Переход к адресу |
| Jxx ADDR |
Условные перекоды на основе флагов |
| CALL ADDR |
Вызов процедуры по адресу |
| RET |
Выход из процедуры |
| IRET |
Выход из прерывания |
| LOOPkx |
продолжение цикла до выполнения определенного условия |
| INT ADDR |
Программное прерывание |
| INTO |
Прерывание, если установлен бит переполнения |
| Команды обработки стокрок |
|
| LOOS |
Загрузка строки |
| STOS |
Сохранение строки |
| MOVS |
Перемещение строки |
| CMPS |
Сравнение двух строк |
| SCAS |
Сканирование строки |
| Команды для работы с /содами условий |
|
| STC |
Установка бита переноса в регистре EFLAGS |
| CLC |
Сброс бита переноса в регистре EFLAGS |
| CMC |
Дополнение бита переноса в регистре EFLAGS |
| STD |
Установка бита направления в регистре EFLAGS |
| CLO |
Сброс бита направления в регистре EFLAGS |
| STN |
Установка бита прерывания в регистре EFLAGS |
| CLI |
Сброс бита прерывания в регистре EFLAGS |
| PUSHFD |
Помещение значения из регистра EFLAGS в стек |
| POPFD |
Выталкивание значения из стека в регистр EFLAGS |
| LAHF |
Загрузка АН из регистра EFLAGS |
| SAHF |
Сохранение АН в регистре EFLAGS |
| Прочие команды |
|
| SWAP DST |
Изменение порядка следования байтов в DST |
| CWQ |
Расширение ЕАХ до EDX:EAX для деления |
| SWDE |
Расширение 16-разрядного числа в АХ до ЕАХ |
| ENTER SIZE. LV |
Создание стекового фрейма с байтами размера |
| LEAVE |
Удаление стекового фрейма, созданного командой ENTER |
| NOP |
Пустая операция |
| HLT |
Останов |
| IN AL, PORT |
Перенос байта из порта в АЛУ |
| OUT PORT, AL |
Перенос байта из АЛУ в порт |
| WAIT |
Ожидание прерывания |
При выполнении команд источники данных (SRC) не изменяются, а приемники (DST) обычно изменяются. Существуют определенные правила, определяющие, что может быть источником, а что приемником, но здесь мы не будем о них говорить. Многие команды имеют три варианта: для 8-, 16- и 32-разрядных операндов соответственно. Они различаются по коду операции и/или по одному биту в команде. В таблице1. приведены в основном 32-разрядные команды.
Для удобства команды разделены на несколько групп. Первая группа содержит команды, которые перемещают данные между компонентами машины: регистрами, памятью и стеком. Вторая группа содержит арифметические команды для операций со знаком и без знака. При умножении и делении 64-разрядное произведение или делимое хранится в двух регистрах: ЕАХ (младшие биты) и EDX (старшие биты).
Третья группа включает двоично-десятичную арифметику. Здесь каждый байт рассматривается как два 4-разрядных полубайта. Каждый полубайт содержит 1 десятичный разряд (от 0 до 9). Комбинации битов от 1010 до 1111 не используются. Таким образом, 16-разрядное целое число может содержать десятичное число от 0 до 9999. Хотя такая форма хранения неэффективна, она устраняет необходимость преобразования десятичных входных данных в двоичные, а затем обратно в десятичные для вывода. Эти команды служат для выполнения арифметических действий нал двоично-десятичными числами. Они широко используются в программах на языке COBOL
Логические команды и команды сдвига манипулируют битами в слове или байте. Существует несколько комбинаций.
Следующие две группы связаны с проверкой, сравнением и осуществлением перехода в зависимости от полученного результата. Результаты проверки и сравнения хранятся в различных битах регистра EFLAGS. Символами Jхх обозначена группа команд, выполняющих условный переход в зависимости от результатов предыдущего сравнения (то есть в зависимости от битов в регистре EFLAGS).
В Pentium 4 есть несколько команд для загрузки, сохранения, перемещения, сравнения и сканирования символьных строк или слов. Перед этими командами может стоять специальный префиксный байт REP (repetition — повторение), который заставляет команду повторяться до тех пор. пока не будет выполнено определенное условие (например, пока регистр ЕСХ. значение которого уменьшается на 1 после каждого повторения, не станет равным 0). Таким образом. различные действия (перемещение, сравнение и г.д.) могут производиться над произвольными блоками данных. Следующая группа команд управляет кодами условий.
В последнюю группу входят команды, которые не вошли ни в одну из предыдущих групп. Это команды перекодирования, управления, ввода-вывода и остановки процессора.
Команды Pentium 4 имеют ряд префиксов. Один из них (REP) мы уже упомянули. Префикс - это специальный байт, который может ставиться практически перед любой командой (подобно WIDE в IJVM). Как уже отмечалось, префикс REP заставляет команду, идущую за ним, повторяться до тех пор, пока регистр ЕСХ не примет значение 0. Префиксы REP2 и REPHZ заставляют команду выполняться
снова и снова, пока код выполнения условия Z не примет значение 1 или 0 соответственно. Префикс LOCK резервирует шину для всей команды, чтобы можно было осуществлять межпроцессорную синхронизацию. Другие префиксы используются для того, чтобы команда работала и 16 или 32 разрядном формате При этом меняется не только длима операндов, но и полностью переопределяются режимы адресации. Наконец, в Pentium 4 реализована сложная схема сегментации, в которой задействованы код, данные, стек и дополнительные сегменты (наследие 8088). Префиксы позволяют регламентировать применение тех или иных сегментов при обращении к памяти.
4. Архитектура вычислительных систем (ВС)
4.1 Способы организации и типы ВС на предприятии прохождения практики
На рабочих местах установлены компьютеры с одним МП или с одним МП и 2 ядрами
То есть SISD (англ. Single Instruction, Single Data) — архитектура компьютера, в которой один процессор выполняет один поток команд, оперируя одним потоком данных. Относится к фон-Неймановской архитектуре.
SISD компьютеры это обычные, "традиционные" последовательные компьютеры, в которых в каждый момент времени выполняется лишь одна операция над одним элементом данных (числовым или каким-либо другим значением). Большинство современных персональных ЭВМ, например, попадает именно в эту категорию. Иногда сюда относят и некоторые типы векторных компьютеров, это зависит от того, что понимать под потоком данных, но обсуждать эти детали здесь мы не будем. А вот двух ядерные процессоры уже относятся к MIMD
На серверах установлены двух или четырёх процессорные системы они относятся к MIMD
MIMD компьютер имеет N процессоров, независимо исполняющих N потоков команд и обрабатывающих N потоков данных. Каждый процессор функционирует под управлением собственного потока команд, то есть MIMD компьютер может параллельно выполнять совершенно разные программы.
|
|
| Рисунок 8. MIMD архитектура. |
MIMD архитектуры далее классифицируются в зависимости от физической организации памяти, то есть имеет ли процессор свою собственную локальную память и обращается к другим блокам памяти, используя коммутирующую сеть, или коммутирующая сеть подсоединяет все процессоры к общедоступной памяти. Исходя из организации памяти, различают следующие типы параллельных архитектур:
Компьютеры с распределенной памятью (Distributed memory)
Процессор может обращаться к локальной памяти, может посылать и получать сообщения, передаваемые по сети, соединяющей процессоры. Сообщения используются для осуществления связи между процессорами или, что эквивалентно, для чтения и записи удаленных блоков памяти. В идеализированной сети стоимость посылки сообщения между двумя узлами сети не зависит как от расположения обоих узлов, так и от трафика сети, но зависит от длины сообщения.
|
|
| Рисунок 9. |
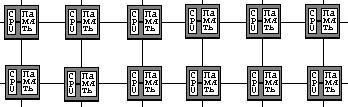
Компьютеры с общей (разделяемой) памятью (True shared memory)
Все процессоры совместно обращаются к общей памяти, обычно, через шину или иерархию шин. В идеализированной PRAM (Parallel Random Access Machine - параллельная машина с произвольным доступом) модели, часто используемой в теоретических исследованиях параллельных алгоритмов, любой процессор может обращаться к любой ячейке памяти за одно и то же время. На практике масштабируемость этой архитектуры обычно приводит к некоторой форме иерархии памяти. Частота обращений к общей памяти может быть уменьшена за счет сохранения копий часто используемых данных в кэш-памяти, связанной с каждым процессором. Доступ к этому кэш-памяти намного быстрее, чем непосредственно доступ к общей памяти.
|
|
| Рисунок 10. |
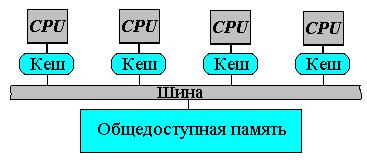
Компьютеры с виртуальной общей (разделяемой) памятью (Virtual shared memory)
Общая память как таковая отсутствует. Каждый процессор имеет собственную локальную память и может обращаться к локальной памяти других процессоров, используя "глобальный адрес". Если "глобальный адрес" указывает не на локальную память, то доступ к памяти реализуется с помощью сообщений, пересылаемых по коммуникационной сети.
4.2 Уровни и способы организации параллельной обработки информации для ВС предприятия
Информация баз данных выполняется на сервера с архитектурой MIMD дополнительно каких либо способов ускорения и распараллеливания не применено т.к. существующая система справляется с нагрузкой.
5 Информационные компьютерные сети (КС)
5.1 Топология КС на предприятии прохождения преддипломной практики
На предприятии применена топология иерархическая звезда на базе технология Fast Ethernet 10/100MBit/s
|
|
| Рисунок 11. Топология КС |
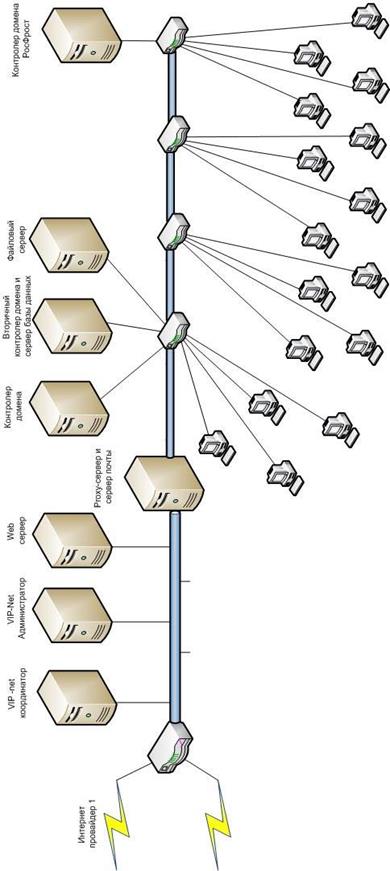
5.2Перечень технических средств, их характеристики и параметры для КС предприятия
Интернет от двух провайдеров приходит в межсетевой экран-маршрутизатор DFL-860 а за ним идет DMZ (демиталиризованная зона) с серверами VIP-net и WEB, далее идет прокси сервер а за ним вся сеть построена на не управляемых коммутаторах DES-1024D
DFL-860
Характеристики:
Интерфейсы
2 порта 10/100Base-TX WAN
1 порт 10/100Base-TX DMZ2
7 портов 10/100Base-TX LAN
Производительность3
Производительность межсетевого экрана 150 Мбит/с
Производительность VPN 60 Мбит/с
Количество параллельных сессий 25 000
Политики 1 000
Функции межсетевого экрана
Прозрачный режим NAT, PAT
Протокол динамической маршрутизации OSPF H.323 NAT Traversal
Политики по расписанию
Application Layer Gateway (ALG)
Активная сетевая безопасность ZoneDefense
Сетевые функции DHCP клиент/север DHCP relay
Маршрутизация на основе политик
IEEE 802.1Q VLAN: до 16
IP Multicast: IGMP v1-v3, IGMP Snooping
Виртуальные частные сети (VPN)
Шифрование (DES/3DES/Twofish/Blowfish/CAST-128)
300 выделенных VPN-туннелей
Сервер PPTP/L2TP
Hub and Spoke
IPSec NAT Traversal
Балансировка нагрузки
Балансировка исходящего трафика1
Балансировка нагрузки серверов
Алгоритм балансировки нагрузки серверов: 3 типа
Перенаправление трафика при обрыве канала (Fail-over)
Управление полосой пропускания
Traffic Shaping на основе политик
Гарантированная полоса пропускания
Максимальная полоса пропускания
Полоса пропускания на основе приоритета
Динамическое распределение полосы пропускания
Отказоустойчивость
Резервирование канала WAN (WAN Fail-over)
Intrusion Prevention (IPS)
Автоматическое обновление шаблонов
Защита от атак DoS, DDoS
Предупреждение об атаках по электронной почте
Расширенная подписка IDP/IPS
Чёрный список по IP
Фильтрация содержимого
Тип HTTP6: URL, ключевые слова
Тип скриптов: Java Cookie, ActiveX, VB
Тип e-mail5: «Черный» список, ключевые слова
Внешняя база данных фильтрации содержимого
Антивирусная защита
Антивирусное сканирование в реальном времени
Неограниченный размер файла
Антивирусная защита внутри VPN-туннелей
Поддержка сжатых файлов
Поставщик сигнатур: Kaspersky
Автоматическое обновление шаблонов
Сертификаты безопасности UL LVD (EN60950-1)
DES-1024D
Характеристики:
Поддержка полного/полудуплекса на каждом порту
Контроль за трафиком для предотвращения потери данных на каждом порту
Автоопределение сетевой конфигурации
Безопасная схема коммутации store-and-forward
Коррекция полярности подключения RX на каждом порту
Компактный настольный размер
IEEE 802.3 10BASE-T Ethernet
IEEE 802.3u 100BASE-TX Fast Ethernet
ANSI/IEEE 802.3 NWay режим автоопределения
Протокол CSMA/CD
Скорость передачи данных
Ethernet: 10Mbps (полудуплекс) или 20Mbps (полный дуплекс)
Fast Ethernet: 100Mbps (полудуплекс) или 200Mbps (полный дуплекс)
Количество Портов
24 Порта 10/100Mbps
Обмен среды интерфейса автоопределение MDI/MDIX на каждом порту
Таблица MAC-адресов 8K на устройство
Автоматическое Обновление таблицы MAC–адресов
Фильтрация пакетов/Скорость передачи (полудуплекс)
10BASE-T: 14,880 pps на порт
100BASE-TX: 148,810 pps на порт
Физические параметры
Буфер ОЗУ 2.5M
Питание: 100 - 240 Вольт, 50/60 Гц 0.3A
Электромагнитное излучение
(EMI) FCC Class A, CE Class A, C-Tick, VCCI Class A
Безопасность CUL, CB
6. Защита информации в вычислительных системах и сетях
6.1 Методы защиты информации в операционной системе, установленной на предприятии
Для обеспечения безопасности на предприятии организованная DMZ (демилитаризованная зона) — технология обеспечения защиты информационного периметра, при которой серверы, отвечающие на запросы из внешней сети, или направляющие туда запросы, находятся в особом сегменте сети (который и называется DMZ) и ограничены в доступе к основным сегментам с помощью межсетевого экрана (МСЭ). При этом не существует прямых соединений между внутренней сетью и внешней - любые соединения возможны только с серверами в DMZ, которые (возможно) обрабатывают запросы и формируют свои, возвращая ответ получателю уже от своего имени.
В зависимости от требований к безопасности, DMZ может организовываться одним, двумя или тремя межсетевыми экранами (МСЭ).
Внутренняя защита организована на основе Windows AD пользователи и компьютеры проходят на сервере аутентификацию и авторизацию по протоколу Kerberos. Также разграничен доступ к внутренним ресурсам на основе политик безопасности, настроенных на контролере домена, все компьютеры сети при загрузке получают конфигурационную информацию с контролера домена.
6.2 Алгоритмы аутентификации пользователей ПК
Пользователи аутентифицируются на котроллере домена по протоколу Kerberos
Kerberos - это компьютерный сетевой протокол аутентификации, позволяющий отдельным личностям общаться через незащищённые сети для безопасной идентификации. Так же является набором бесплатного ПО от Массачусетского Технологического Института (Massachusetts Institute of Technology (MIT)), разработавшего этот протокол. Ее организация направлена в первую очередь на клиент-серверную модель и обеспечивает взаимную аутентификацию - оба пользователя через сервер подтверждают личности друг друга. Сообщения, отправляемые через протокол Kerberos, защищены от прослушивания и атак.
Kerberos основан на симметричной криптосистеме и требует третье доверенное лицо (сервер). Расширение Kerberos позволяет использовать открытые ключи в процессе аутентификации.
Протокол
Безопасность протокола в значительной мере основывается на том, что системные часы участников более-менее синхронны и на временных утверждениях подлинности, называемых билетами Kerberos.
Ниже приведено упрощенное описание протокола. Следующие аббревиатуры будут использованы:
AS = Сервер аутентификации
TGS = Сервер предоставления билетов
SS = Ресурс, предоставляющий некий сервис, к которому требуется получить доступ
TGT = Билет для получения билета
В двух словах клиент авторизируется на AS, используя свой долгосрочный секретный ключ, и получает билет от AS. Позже клиент может использовать этот билет для получения дополнительных билетов на доступ к ресурсам SS без необходимости прибегать к использованию своего секретного ключа.
Более детально:
Шаги входа пользователя в систему:
Пользователь вводит имя и пароль на клиентской машине.
Клиентская машина выполняет над паролем одностороннюю функцию (обычно хэш), и результат становится секретным ключом клиента/пользователя.
Шаги аутентификации клиента:
Клиент посылает простым текстом сообщение серверу AS, запрашивая сервисы от имени пользователя. Например так: «Пользователь АБВ хочет запросить сервисы». Обратите внимание, что ни секретный ключ, ни пароль не посылаются на AS.
AS проверяет, есть ли такой клиент в базе. Если есть, то назад AS отправляет следующие два сообщения:
Сообщение A: Сессионный Ключ Client/TGS зашифрованный секретным ключом клиента/пользователя.
Сообщение B: TGT (который включает ID клиента, сетевой адрес клиента, период действия билета, и Сессионный Ключ Сlient/TGS) зашифрованный секретным ключом TGS.
Как только клиент получает сообщения A и B, он расшифровывает сообщение A, чтобы получить Сессионный Ключ Client/TGS. Этот сессионный ключ используется для дальнейшего обмена с сервером TGS. (Важно: Клиент не может расшифровать сообщение B, так как оно зашифровано секретным ключом TGS.) В этот момент у пользователя достаточно данных, чтобы авторизироваться на TGS.
Шаги авторизации клиента для получения сервиса:
При запросе сервисов клиент отправляет следующие два сообщения на TGS:
Сообщение C: Содержит TGT, полученный в сообщении B и ID требуемого сервиса.
Сообщение D: Аутентикатор (составленный из ID клиента и временного штампа), зашифрованный на Сессионном Ключе Client/TGS.
После получения сообщений C и D, TGS извлекает сообщение B из сообщения C и расшифровывает его используя секретный ключ TGS. Это дает ему Сессионный Ключ Client/TGS. Используя его TGS расшифровывает сообщение D и посылает следующие два сообщения клиенту:
Сообщение E: Client-to-server ticket (который содержит ID клиента, сетевой адрес клиента, время действия билета и Сессионный Ключ Client/server) зашифрованный секретным ключом сервиса.
Сообщение F: Сессионный ключ Client/server, зашифрованный на Сессионном Ключе Client/TGS.
Шаги клиента при запросе сервиса:
При получении сообщений E и F от TGS, у клиента достаточно информации для авторизации на SS. Клиент соединяется с SS и посылает следующие два сообщения:
Сообщение E из предыдущего шага (client-to-server ticket, зашифрованный секретным ключом сервиса).
Сообщение G: новый аутентикатор, который включающий ID клиента, временной штамп и зашифрованный на client/server session key.
SS расшифровывает билет используя свой секретный ключ для получения Сессионного Ключа Client/Server. Используя сессионный ключ, SS расшифровывает аутентикатор и посылает клиенту следующее сообщение для подтверждения готовности обслужить клиента и показать, что сервер действительно является тем, за кого себя выдает:
Сообщение H: Временной штамп, указанный клиентом + 1, зашифрованный на Сессионном Ключе Client/Server.
Клиент расшифровывает подтверждение, используя Сессионный Ключ Client/Server и проверяет, действительно ли временной штамп корректно обновлен. Если это так, то клиент может доверять серверу и может начать посылать запросы на сервер.
Сервер предоставляет клиенту требуемый сервис.
7. Администрирование информационно-вычислительных сетей
7.1 Описание структуры администрирования информационно вычислительной сети предприятия
Администрирование сводится к у правлению всеми Windows станциями через контролер домена Windows 2003 server с ролью Active Directory, в ней задаются все настройки безопасности. На прокси сервере администратор сам настраивает все без какой либо централизации и автоматизаци. Конролер домена и прокси сервер никак не взаимосвязаны и работают независемо.
Active Directory — LDAP-совместимая реализация интеллектуальной службы каталогов корпорации Microsoft для операционных систем семейства Windows NT. Active Directory позволяет администраторам использовать групповые политики (GPO) для обеспечения единообразия настройки пользовательской рабочей среды, развёртывать ПО на множестве компьютеров (через групповые политики или посредством Microsoft Systems Management Server 2003 (или System Center Configuration Manager)), устанавливать обновления ОС, прикладного и серверного ПО на всех компьютерах в сети (с использованием Windows Server Update Services (WSUS); Software Update Services (SUS) ранее). Active Directory хранит данные и настройки среды в централизованной базе данных. Сети Active Directory могут быть различного размера: от нескольких сотен до нескольких миллионов объектов.
Представление Active Directory состоялось в 1996 году, продукт был впервые выпущен с Windows 2000 Server, а затем был модифицирован и улучшен при выпуске сначала Windows Server 2003, затем Windows Server 2003 R2.
В отличие от версий Windows до Windows 2000, которые использовали в основном протокол NetBIOS для сетевого взаимодействия, служба Active Directory интегрирована с DNS и TCP/IP. DNS-сервер, обслуживающий Active Directory, должен быть совместим c BIND версии 8.1.2 или более поздней, сервер должен поддерживать записи типа SRV (RFC 2052) и протокол динамических обновлений (RFC 2136).
7.2 Список систем управления базами данных, применяемых на предприятии.
На файловом сервере поднят сервер базы данных 1С на основе My SQL 2005 обслуживающий систему регистрации заявок ITIL, и бухгалтерский компьютер на котором 1С бухгалтерия.
Microsoft SQL Server — система управления реляционными базами данных (СУБД), разработанная корпорацией Microsoft. Основной используемый язык запросов — Transact-SQL, создан совместно Microsoft и Sybase. Transact-SQL является реализацией стандарта ANSI/ISO по структурированному языку запросов (SQL) с расширениями. Используется для небольших и средних по размеру баз данных, и в последние 5 лет — для крупных баз данных масштаба предприятия, конкурирует с другими СУБД в этом сегменте рынка.
Microsoft SQL Server в качестве языка запросов использует версию SQL, получившую название Transact-SQL (сокращённо T-SQL), являющуюся реализацией SQL-92 (стандарт ISO для SQL) с множественными расширениями. T-SQL позволяет использовать дополнительный синтаксис для хранимых процедур и обеспечивает поддержку транзакций (взаимодействие базы данных с управляющим приложением). Microsoft SQL Server и Sybase ASE для взаимодействия с сетью используют протокол уровня приложения под названием Tabular Data Stream (TDS, протокол передачи табличных данных). Протокол TDS также был реализован в проекте FreeTDS с целью обеспечить различным приложениям возможность взаимодействия с базами данных Microsoft SQL Server и Sybase.
Microsoft SQL Server также поддерживает Open Database Connectivity (ODBC) — интерфейс взаимодействия приложений с СУБД. Последняя версия (SQL Server 2005) обеспечивает возможность подключения пользователей через веб-сервисы, использующие протокол SOAP. Это позволяет клиентским программам, не предназначенным для Windows, кроссплатформенно соединяться с SQL Server. Microsoft также выпустила сертифицированный драйвер JDBC, позволяющий приложениям под управлением Java (таким как BEA и IBM WebSphere) соединяться с Microsoft SQL Server 2000 и 2005.
SQL Server поддерживает зеркалирование и кластеризацию баз данных. Кластер сервера SQL — это совокупность одинаково конфигурированных серверов; такая схема помогает распределить рабочую нагрузку между несколькими серверами. Все сервера имеют одно виртуальное имя, и данные распределяются по IP адресам машин кластера в течение рабочего цикла. Также в случае отказа или сбоя на одном из серверов кластера доступен автоматический перенос нагрузки на другой сервер.
SQL Server поддерживает избыточное дублирование данных по трем сценариям:
Снимок: Производится «снимок» базы данных, который сервер отправляет получателям.
История изменений: Все изменения базы данных непрерывно передаются пользователям.
Синхронизация с другими серверами: Базы данных нескольких серверов синхронизируются между собой. Изменения всех баз данных происходят независимо друг от друга на каждом сервере, а при синхронизации происходит сверка данных. Данный тип дублирования предусматривает возможность разрешения противоречий между БД.
В SQL Server 2005 встроена поддержка .NET Framework. Благодаря этому, хранимые процедуры БД могут быть написаны на любом языке платформы .NET, используя полный набор библиотек, доступных для .NET Framework, включая Common Type System (система обращения с типами данных в Microsoft .NET Framework). Однако, в отличие от других процессов, .NET Framework, будучи базисной системой для SQL Server 2005, выделяет дополнительную память и выстраивает средства управления SQL Server вместо того, чтобы использовать встроенные средства Windows. Это повышает производительность в сравнении с общими алгоритмами Windows, так как алгоритмы распределения ресурсов специально настроены для использования в структурах SQL Server.
В ходе практической деятельности мне удалось изучить проектно-технологическую документацию, выполнить технико-экономическое обоснование выполняемой разработки, реализацию некоторых из возможных путей решения поставленной в техническом задании задачи. Принимал участие в фазах проектирования, разработки, изготовления и сопровождения объектов профессиональной деятельности, при этом использовал современные методы, средства и технологии разработки. В ходе работы работал в коллективе специалистов высокого класса, взаимодействовал со специалистами смежного профиля.
9. Литература
1 Таненбаум Э. Современные операционные системы. 2-е изд.- СПб.: Питер,2002г.
2 Гордеев А.В. Операционные системы. 2-е изд.- СПб.: Питер,2004г.
3 Сташин В.В., Урусов Ф.В. Мологонцева О.Ф. Проектирование цифровых устройств на однокристальных микроконтроллерах. – М., Энергоатомиздат, 1990 г.
4 Ремизевич Т.В. Микроконтроллеры для встраиваемых приложений. Додека, - М., 2000.
5 Таненбаум Э.Компьютерные сети. 2-е изд.- СПб.: Питер,2002г.
6 Таненбаум Э.С. -Архитектура компьютера. 5-е изд. -СПб.: Питер,2007г
7 www.wikipedia.org
8 www.it-enigma.ru