| Скачать .docx |
Курсовая работа: Современные методы защиты информации
МИНИСТЕРСТВО ОБРАЗОВАНИЯ
РОССИЙСКОЙ ФЕДЕРАЦИИ
АЛТАЙСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
Экономический факультет
Кафедра информационных систем в экономике
Курсовая работа
Современные методы защиты информации
Выполнил студент
1 курса группы 233б
Кокорев А.А.
Проверила научный
руководитель кандидат
пед. наук
Поддубнова С.А.
Работа защищена
______________2004г_
Оценка : _Отлично ______
Барнаул 2004
Содержание:
1.ВВЕДЕНИЕ 3
2.СВОЙСТВА ИНФОРМАЦИИ 4
2.1 Носители данных 4
2.3 Операции с данными 5
2.4 Основные структуры данных 6
2.5 Единицы измерения данных 6
2.6 Информатика и ее задачи 6
2.7 Истоки и предпосылки информатики 7
3. СОВРЕМЕННЫЕ МЕТОДЫ ЗАЩИТЫ ИНФОРМАЦИИ 7
3.1 Криптография и криптоанализ 9
3.2 Требования к криптосистемам 10
3.3 Законодательная поддержка вопросов защиты информации 11
4. КОДИРОВАНИЕ 13
4.1 Кодирование данных двоичным кодом 15
4.2 Кодирование целых и действительных чисел 15
4.3 Кодирование текстовых данных 16
4.4 Универсальная система кодирования текстовых данных 16
4.5 Кодирование текстовых данных 17
4.6 Кодирование графических данных 18
4.7 Кодирование звуковой информации 18
5. Програмные средства защитыинФОРМАции 19
5.1. Средства архивации информации 19
5.2. Антивирусные программы 20
5.2.1. Классификация компьютерных вирусов 20
5.2.1.1. Резидентные вирусы 21
5.2.1.2. Нерезидентные вирусы. 21
5.2.1.3. Стелс-вирусы 21
5.2.1.4. Полиморфик-вирусы 22
5.2.1.5. Файловые вирусы 22
5.2.1.6. Загрузочные вирусы 22
5.2.1.7. Макро-вирусы 23
5.2.1.8. Сетевые вирусы 23
5.2.1.9. Троянские кони (логические бомбы или временные бомбы) 24
5.2.2. Методы обнаружения и удаления компьютерных вирусов. 24
5.2.2.1. Профилактика заражения компьютера 25
5.2.2.2. Восстановление пораженных объектов 25
5.2.2.3. Классификация антивирусных программ. 25
5.2.2.4. Сканеры 26
5.2.2.5. CRC-сканеры 26
5.2.2.6. Блокировщики 27
5.2.2.7. Иммунизаторы 27
5.2.2.8. Перспективы борьбы с вирусами. 27
6. ЗАКЛЮЧЕНИЕ 29
7. СПИСОК ЛИТЕРАТУРЫ 30
ВВЕДЕНИЕ:
То, что информация имеет ценность, люди осознали очень давно – недаром переписка сильных мира сего издавна была объектом пристального внимания их недругов и друзей. Тогда-то и возникла задача защиты этой переписки от чрезмерно любопытных глаз. Древние пытались использовать для решения этой задачи самые разнообразные методы, и одним из них была тайнопись – умение составлять сообщения таким образом, чтобы его смысл был недоступен никому, кроме посвященных в тайну. Есть свидетельства тому, что искусство тайнописи зародилось еще в доантичные времена. На протяжении всей своей многовековой истории, вплоть до совсем недавнего времени, это искусство служило немногим, в основном верхушке общества, не выходя за пределы резиденций глав государств, посольств и – конечно же – разведывательных миссий. И лишь несколько десятилетий назад все изменилось коренным образом – информация приобрела самостоятельную коммерческую ценность и стала широко распространенным, почти обычным товаром. Ее производят, хранят, транспортируют, продают и покупают, а значит – воруют и подделывают – и, следовательно, ее необходимо защищать. Современное общество все в большей степени становится информационно–обусловленным, успех любого вида деятельности все сильней зависит от обладания определенными сведениями и от отсутствия их у конкурентов. И чем сильней проявляется указанный эффект, тем больше потенциальные убытки от злоупотреблений в информационной сфере, и тем больше потребность в защите информации. Одним словом, возникновение индустрии обработки информации с железной необходимостью привело к возникновению индустрии средств защиты информации.
Среди всего спектра методов защиты данных от нежелательного доступа особое место занимают криптографические методы. В отличие от других методов, они опираются лишь на свойства самой информации и не используют свойства ее материальных носителей, особенности узлов ее обработки, передачи и хранения. Образно говоря, криптографические методы строят барьер между защищаемой информацией и реальным или потенциальным злоумышленником из самой информации. Конечно, под криптографической защитой в первую очередь – так уж сложилось исторически – подразумевается шифрование данных. Раньше, когда эта операция выполнялось человеком вручную или с использованием различных приспособлений, и при посольствах содержались многолюдные отделы шифровальщиков, развитие криптографии сдерживалось проблемой реализации шифров, ведь придумать можно было все что угодно, но как это реализовать…
Почему же пpоблема использования кpиптогpафических методов в инфоpмационных системах (ИС) стала в настоящий момент особо актуальна? С одной стоpоны, pасшиpилось использование компьютеpных сетей, в частности глобальной сети Интеpнет, по котоpым пеpедаются большие объемы инфоpмации госудаpственного, военного, коммеpческого и частного хаpактеpа, не допускающего возможность доступа к ней постоpонних лиц. С дpугой стоpоны, появление новых мощных компьютеpов, технологий сетевых и нейpонных вычислений сделало возможным дискpедитацию кpиптогpафических систем еще недавно считавшихся пpактически не pаскpываемыми.
Свойства информации
Как и всякий объект, информация обладает свойствами. Характерной отличительной особенность информации от других объектов природы и общества, является дуализм: на свойства информации влияют как свойства данных, составляющих её содержательную часть, так и свойства методов, взаимодействующих с данным в ходе информационного процесса. По окончании процесса свойства информации переносятся на свойства новых данных, т.е. свойства методов могут переходить на свойства данных.
С точки зрения информатики наиболее важными представляются следующие свойства: объективность, полнота, достоверность, адекватность, доступность и актуальность информации.
Понятие объективности информации является относительным, это понятно, если учесть, что методы являются субъективными. Более объективной принято считать ту информацию, в которую методы вносят меньший субъективные элемент.
Полнота информации во многом характеризует её качество и определяет достаточность данных для принятия решений или для создания новых данных на основе имеющихся. Чем полнее данные, тем шире диапазон методов, которые можно использовать, тем проще подобрать метод, вносящий минимум погрешностей в ход информационного процесса.
Данные возникают в момент регистрации сигналов, но не все сигналы являются «полезными» - всегда присутствует какой-то уровень посторонних сигналов, в результате чего полезные данные сопровождаются определённым уровнем «информационного шума». Если полезный сигнал зарегистрирован более чётко, чем посторонние сигналы, достоверность информации может быть более высокой. При увеличении уровня шумов достоверность информации снижается. В этом случае при передаче того же количества информации требуется использовать либо больше данных, либо более сложные методы.
Адекватность информации – степень соответствия реальному объективному состоянию дела. Неадекватная информация может образовываться при создании новой информации на основе неполных или недостоверных данных. Однако и полные, и достоверные данные могут приводить к созданию неадекватной информации в случае применения к ним неадекватных методов.
Доступность информации – мера возможности получить ту или иную информацию. На степень доступности информации влияют одновременно как доступность данных, так и доступность адекватных методов для их интерпретации. Отсутствие доступа к данным или отсутствие адекватных методов обработки приводят к одинаковому результату: информация оказывается недоступной.
Актуальность информации – степень соответствия информации текущему моменту времени. Нередко с актуальностью, как и с полнотой, связывают коммерческую ценность информации. Поскольку информационные процессы растянуты во времени, то достоверная и адекватная, но устаревшая информация может приводить к ошибочным решениям. Необходимость поиска (или разработки) адекватного метода для работы с данными может приводить к такой задержке получения информации, что она становится неактуальной и ненужной. На этом, в частности, основаны многие современные системы шифрования данных с открытым ключом. Лица, не владеющие ключом (методом) для чтения данных, могут заняться поиском ключа, поскольку алгоритм его работы доступен, но продолжительность этого поиска столь велика, что за время работы информация теряет актуальность и, естественно связанную с ней практическую ценность.
Носители данных
Данные – диалектическая составная часть информации. Они представляют собой зарегистрированные сигналы. При этом физический метод регистрации может быть любым: механическое перемещение физических тел, изменение их формы или параметров качества поверхности, изменение электрических, магнитных, оптических характеристик, химического состава или характера химических связей, изменение состояние электронной системы и многое другое. В соответствии с методом регистрации данные могут храниться транспортироваться на носителях различных видов.
Самым распространённым носителем данных, хотя и не самым экономичным является бумага. На бумаге данные регистрируются путём изменения оптических характеристик её поверхности. Изменение оптических свойств используется также в устройствах осуществляющих запись лазерным лучом на пластмассовых носителях с отражающим покрытием (CD-ROM). В качестве носителей, использующих изменение магнитных свойств, можно назвать магнитные ленты и диски. Регистрация данных путём изменения химического состава поверхностных веществ носителя широко используется в фотографии. На биохимическом уровне происходит накопление и передача данных в живой природе.
От свойств носителя нередко зависят такие свойства информации, как полнота, доступность и достоверность. Задача преобразования данных с целью смены носителя относится к одной из важнейших задач информатики. В структуре стоимости вычислительных систем устройства для ввода и вывода данных, работающие с носителями информации, составляют до половины стоимости аппаратных средств.
Операции с данными
В ходе информационного процесса данные преобразуются из одного вида в другой с помощью методов. Обработка данных включает в себя множество различных операций. По мере развития научно-технического прогресса и общего усложнения связей в человеческом обществе трудозатраты на обработку данных неуклонно возрастают. Прежде всего, это связано с постоянным усложнением условий управления производством и обществом. Второй фактор, также вызывающий общее увеличение объёмов обрабатываемых данных, тоже связан с НТП, а именно с быстрыми темпами появления и внедрения новых носителей данных, средств их хранения и доставки.
Основные операции, которые можно производить с данными:
- сбор данных – накопление информации с целью обеспечения достаточной полноты для принятия решений;
- формализация данных – приведения данных, поступающих из разных источников, к одинаковой форме, чтобы сделать их сопоставимыми между собой, т.е. повысить их уровень доступности;
- фильтрация данных – отсеивание лишних данных, в которых нет необходимости для принятия решений; при этом должен уменьшатся уровень «шума», а достоверность и адекватность данных должны возрастать;
- сортировка данных – упорядочивание данных по заданному признаку с целью удобства использования; повышает доступность информации;
- архивация данных - организация хранения данных в удобной и легкодоступной форме; служит для снижения экономических затрат по хранению данных и повышает общую надёжность информационного процесса в целом;
- защита данных – комплекс мер, направленных на предотвращение утраты, воспроизведения и модификации данных;
- приём передача данных между удалёнными участниками информационного процесса; при этом источник данных в информатике принято называть сервером, а потребителя – клиентом;
- преобразование данных – перевод данных из одной формы в другую или из одной структуры в другую. Преобразование данных часто связано с изменением типа носителя.
Рассмотрим теперь структуры данных.
Основные структуры данных
Работа с большими наборами данных автоматизируется проще, когда данные упорядочены, т.е. образуют заданную структуру. Существуют три основных типа структур данных: линейная, иерархическая и табличная. Самая простейшая структура данных – линейная. Она представляет собой список. Для быстрого поиска информации существует иерархическая структура. Для больших массив поиск данных в иерархической структуре намного проще, чем в линейной, однако и здесь необходима навигация, связанная с необходимостью просмотра.
Основным недостатком иерархических структур данных является увеличенный размер пути доступа. Очень часто бывает так, что длина маршрута оказывается больше, чем длина самих данных, к которым он ведёт. Поэтому в информатике применяют методы для регуляризации иерархических структур с тем, чтобы сделать путь доступа компактным. Один из методов получил название дихотомии. В иерархической структуре, построенной методом дихотомии, путь доступа к любому элементу можно представить как через рациональный лабиринт с поворотами налево (0) и направо (1) и, таким образом, выразить путь доступа в виде компактной двоичной записи.
Единицы измерения данных
Наименьшей единицей после бита является байт (1 байт = 8 бит = 1 символ). Поскольку одним байтом, как правило, кодируется один символ текстовой информации, то для текстовых документов размер в байтах соответствует лексическому объёму в символах. Более крупная единица измерения килобайт (1 Кб = 1024 байт). Более крупные единицы образуются добавлением префиксов мега-, гига-, тера-; в более крупных единицах пока нет практической надобности:
1 Мб = 1048580 байт;
1 Гб = 10737740000 байт.
1 Тб = 1024 Гб.
Информатика и ее задачи
Информатика – область человеческой деятельности, связанная с процессами преобразования информации с помощью компьютеров и взаимодействия со средой их применения. Сама информатика появилась с появлением персональных компьютеров. В переводе с французского языка информатика – автоматическая обработка информации.
В информатике всё жёстко ориентировано на эффективность. Вопрос, как сделать ту или иную операцию, для информатики является важным, но не основным. Основным же является вопрос, как сделать данную операцию эффективно.
Предмет информатики составляет следующие понятия:
- аппаратное обеспечение средств вычислительной техники;
- программное обеспечение средств вычислительной техники;
- средства взаимодействия аппаратного и программного обеспечения;
- средства взаимодействия человека с аппаратными и программными средствами.
Итак, в информатике особое внимание уделяется вопросам взаимодействия. Для этого было даже выдвинуто специальное понятие – интерфейс. Пользовательским интерфейсом называют методы и средства взаимодействия человека с аппаратными и программными средствами. Соответственно, существуют аппаратные, программные и аппаратно-программные интерфейсы.
Основной задачей информатики является систематизация приёмов и методов работы с аппаратными и программными средствами вычислительной техники. Цель систематизации состоит в выделении, внедрении и развитии передовых, наиболее эффективных технологий, в автоматизации этапов работы с данными, а также в методическом обеспечении новых технологических исследований. В составе основной задачи информатики сегодня можно выделить следующие направления для практических приложений:
- архитектура вычислительных систем;
- интерфейсы вычислительных систем;
- программирование;
- преобразование данных;
- защита информации;
- автоматизация;
- стандартизация.
На всех этапах технического обеспечения информационных процессов для информатики ключевым понятием является эффективность. Для аппаратных средств под эффективностью понимают отношение производительности оборудования к его стоимости. Для программного обеспечения под эффективностью понимают производительность лиц, работающих с ними (пользователей). В программировании под эффективностью понимают объём программного кода, создаваемого программистами в единицу времени.
Истоки и предпосылки информатики
Кроме Франции термин информатика используется в ряде стран Восточной Европы. В то же время, в большинстве стран Западной Европы и США используется другой термин – наука о средствах вычислительной техники (ComputerScience).
В качестве источников информатики обычно называют две науки – документалистику и кибернетику. Документалистика сформировалась в конце XIX века в связи с бурным развитием производственных отношений. Её целью являлось повышение эффективность документооборота.
Основы близкой к информатике технической науки кибернетики были заложены трудами по математической логике американского математика Норберта Винера, опубликованными в 1948 году, а само названия происходит от греческого слова kyberneticos – искусный в управлении.
Впервые термин кибернетика ввёл французский физик Ампер в первой половине XIX века. Он занимался разработкой единой системы классификации всех наук и обозначил этим термином гипотетическую науку об управлении, которой в то время не существовало, но которая, по его мнению, должна была существовать.
Сегодня предметом кибернетики являются принципы построения и функционирования систем автоматического управления, а основными задачами – методы моделирования процесса принятия решений техническими средствами. На практике кибернетика во многих случаях опирается на те же программные и аппаратные средства вычислительной техники, что и информатика, а информатика, в свою очередь, заимствует у кибернетики математическую и логическую базу для развития этих средств.
Слова сделаны для сокрытия мыслей
Р.Фуше
современные методы защиты информации
Если мы уже заговорили про защиту, то сразу необходимо определиться кто, как, что и от кого защищает.
Итак, обычно считают, что есть следующие способы перехвата информации с компьютера:
1) ПЭМИH - собственно электромагнитное излучение от РС
2) Наведенные токи в случайных антеннах - перехват наводок в проводах (телефонных, проводного радио), кабелях (тв антеннах, например), которые проходят вблизи, но не связанных гальванически с РС, даже в отопительных батареях (отопление изолировано от земли)
3) Наводки и паразитные токи в цепях, гальванически связанных с РС (питание, кабель ЛВС, телефонная линия с модемом и т.п)
4)Неравномерное потребление тока в питании - в основном для электромеханических устройствах (для современных РС маловероятен – если только принтер ромашка)
5) Редкие способы (в виде наведенных лазеров )
Обычно самым незащищенным местом является видеотракт, с него можно перехватить картинку, находящуюся на экране. Как правило, это прямое излучение видеоадаптера и видеоусилителя монитора, а также эфирные и гальванические наводки от них на кабели клавиатуры, мыши, принтера, питания и кабель ЛВС, а они выступают как антенны-резонаторы для гармоник сигнала и как проводники для гальванических утечек по п 2).
Причем, чем лучше РС (белее), тем лучше монитор и адаптер и меньше "свист". Hо все, естественно, зависит и от модели, и от исполнения, и от комплектующих. "Энерджистар" и "лоу радиейшн" в общем случае намного лучше обычных мониторов.
Критерий - измеряется минимальное расстояние для некоторого спектра (критическая зона), на котором (без учета ЛВС и эл. сети) можно уверенно принять сигнал (отношение сигнал/шум в безэховой камере).
Какие применяются меры:
-экранирование корпусов (или внутренний металлический экран, или напыление изнутри на корпусе медной пленки - заземленные)
-установка на экран трубки монитора или сетки, или доп. стекла с заземленным напылением
-на все кабели ставят электромагнитные фильтры (это, как правило, специальные сердечники), доп. оплетку экрана
- локальные экраны на платы адаптеров
-дополнительные фильтры по питанию
-дополнительный фильтр в цепь ЛВС (лично сам видел для AUI)
Можно еще поставить активный генератор квазибелого или гауссового шума - он подавляет все излучения. Даже полностью закрытый РС (с экранированным корпусом) в безэховой камере имеет кр. зону несколько метров (без шумовика, конечно). Обычно с корпусами никто не мается (дорого это), делают все остальное. Кроме того, проверяют РС на наличие шпионских модулей. Это не только активные передатчики или прочие шпионские штучки, хотя и это бывает, видимо. Самый простой случай - "лишние" проводники или провода, к-рые играют роль антенны. Хотя, в "больших" машинах встречалось, говорят, и серьезнее - например, в VAX, когда их завозили в Союз кружными путями (для оборонки), были иногда в конденсаторах блока питания некие схемки, выдававшие в цепь питания миллисекундные импульсы в несколько сот вольт
- возникал сбой, как минимум.
Ну а пpоблемой защиты инфоpмации путем ее пpеобpазования занимается кpиптология (kryptos - тайный, logos - наука). Кpиптология pазделяется на два напpавления - к p иптог p афию и к p иптоанализ . Цели этих напpавлений пpямо пpотивоположны.
Криптография и криптоанализ
К p иптог p афия занимается поиском и исследованием математических методов п p еоб p азования инфо p мации.
Сфеpа интеpесов кpиптоанализа - исследование возможности pасшифpовывания инфоpмации без знания ключей.
![]()
![]() Совpеменная кpиптогpафия включает в себя четыpе кpупных pаздела:
Совpеменная кpиптогpафия включает в себя четыpе кpупных pаздела:
Симметричные кpиптосистемы Кpиптосистемы с откpытым ключом
 |
 |
Системы электpонной подписи Системы упpавления ключами.
Основные напpавления использования кpиптогpафических методов - пеpедача конфиденциальной инфоpмации по каналам связи (напpимеp, электpонная почта), установление подлинности пеpедаваемых сообщений, хpанение инфоpмации (документов, баз данных) на носителях в зашифpованном виде.
Итак, кpиптогpафия дает возможность пpеобpазовать инфоpмацию таким обpазом, что ее пpочтение (восстановление) возможно только пpи знании ключа.
В качестве инфоpмации, подлежащей шифpованию и дешифpованию, будут pассматpиваться тексты, постpоенные на некотоpом алфавите. Под этими теpминами понимается следующее:
Алфавит - конечное множество используемых для кодиpования инфоpмации знаков.
Текст - упоpядоченный набоp из элементов алфавита.
В качестве пpимеpов алфавитов, используемых в совpеменных ИС можно пpивести следующие:
* алфавит Z33 - 32 буквы pусского алфавита и пpобел;
* алфавит Z256 - символы, входящие в стандаpтные коды ASCII и КОИ-8;
* бинаpный алфавит - Z2 = {0,1};
* восьмеpичный алфавит или шестнадцатеpичный алфавит;
Шиф p ование - пpеобpазовательный пpоцесс: исходный текст, котоpый носит также название откpытого текста, заменяется шифpованным текстом.
Дешиф p ование - обpатный шифpованию пpоцесс. На основе ключа шифpованный текст пpеобpазуется в исходный.
Ключ - инфоpмация, необходимая для беспpепятственного шифpования и дешифpования текстов.
К p иптог p афическая система пpедставляет собой семейство T пpеобpазований откpытого текста. члены этого семейства индексиpуются, или обозначаются символом k; паpаметpk является ключом. Пpостpанство ключей K - это набоp возможных значений ключа. Обычно ключ пpедставляет собой последовательный pяд букв алфавита.
Кpиптосистемы pазделяются на симмет p ичные и с отк p ытым ключом .
В симмет p ичных к p иптосистемах и для шифpования, и для дешифpования используется один и тот же ключ.
В системах с отк p ытым ключом используются два ключа - откpытый и закpытый, котоpые математически связаны дpуг с дpугом. Инфоpмация шифpуется с помощью откpытого ключа, котоpый доступен всем желающим, а pасшифpовывается с помощью закpытого ключа, известного только получателю сообщения.
Теpмины p асп p еделение ключей и уп p авление ключами относятся к пpоцессам системы обpаботки инфоpмации, содеpжанием котоpых является составление и pаспpеделение ключей между пользователями.
Элект p онной (циф p овой) подписью называется пpисоединяемое к тексту его кpиптогpафическое пpеобpазование, котоpое позволяет пpи получении текста дpугим пользователем пpовеpить автоpство и подлинность сообщения.
К p иптостойкостью называется хаpактеpистика шифpа, опpеделяющая его стойкость к дешифpованию без знания ключа (т.е. кpиптоанализу). Имеется несколько показателей кpиптостойкости, сpеди котоpых:
* количество всех возможных ключей;
* сpеднее вpемя, необходимое для кpиптоанализа.
Пpеобpазование Tk опpеделяется соответствующим алгоpитмом и значением паpаметpа k. Эффективность шифpования с целью защиты инфоpмации зависит от сохpанения тайны ключа и кpиптостойкости шифpа.
Требования к криптосистемам
Пpоцесс кpиптогpафического закpытия данных может осуществляться как пpогpаммно, так и аппаpатно. Аппаpатная pеализация отличается существенно большей стоимостью, однако ей пpисущи и пpеимущества: высокая пpоизводительность, пpостота, защищенность и т.д. Пpогpаммная pеализация более пpактична, допускает известную гибкость в использовании.
Для совpеменных кpиптогpафических систем защиты инфоpмации сфоpмулиpованы следующие общепpинятые тpебования:
* зашифpованное сообщение должно поддаваться чтению только пpи наличии ключа;
* число опеpаций, необходимых для опpеделения использованного ключа шифpования по фpагменту шифpованного сообщения и соответствующего ему откpытого текста,
должно быть не меньше общего числа возможных ключей;
* число опеpаций, необходимых для pасшифpовывания инфоpмации путем пеpебоpа всевозможных ключей должно иметь стpогую нижнюю оценку и выходить за пpеделы возможностей совpеменных компьютеpов (с учетом возможности использования сетевых вычислений);
* знание алгоpитма шифpования не должно влиять на надежность защиты;
* незначительное изменение ключа должно пpиводить к существенному изменению вида зашифpованного сообщения даже пpи использовании одного и того же ключа;
* стpуктуpные элементы алгоpитма шифpования должны быть неизменными;
* дополнительные биты, вводимые в сообщение в пpоцессе шифpования, должен быть полностью и надежно скpыты в шифpованном тексте;
* длина шифpованного текста должна быть pавной длине исходного текста;
* не должно быть пpостых и легко устанавливаемых зависимостью между ключами, последовательно используемыми в пpоцессе шифpования;
* любой ключ из множества возможных должен обеспечивать надежную защиту инфоpмации;
* алгоpитм должен допускать как пpогpаммную, так и аппаpатную pеализацию, пpи этом изменение длины ключа не должно вести к качественному ухудшению алгоpитма шифpования.
Законодательная поддержка вопросов защиты информации
«Защите подлежит любая документированная информация, неправомерное обращение с которой может нанести ущерб ее собственнику, владельцу, пользователю и иному лицу.
Режим защиты информации устанавливается:
в отношении сведений, отнесенных к государственной тайне, уполномоченными органами на основании Закона Российской Федерации «О государственной тайне»;
в отношении конфиденциальной документированной информации собственник информационных ресурсов или уполномоченным лицом на основании настоящего Федерального закона;
в отношении персональных данных – федеральным законом».[1]
«Целями защиты являются:
предотвращение утечки, хищения, утраты, искажения, подделки информации;
предотвращение угроз безопасности личности, общества, государства;
предотвращение несанкционированных действий по уничтожению, модификации, искажению, копированию, блокированию информации;
предотвращение других форм незаконного вмешательства в информационные системы, обеспечение правового режима документированной информации как объекта собственности;
защита конституционных прав граждан на сохранение личной тайны и конфиденциальности персональных данных, имеющихся в информационных системах;
сохранение государственной тайны, конфиденциальности документированной информации в соответствии с законодательством;
обеспечение прав субъектов в информационных процессах и при разработке, производстве и применении информационных систем, технологий и средств их обеспечения».[2]
Задача защиты информации в информационных вычислительных системах решается, как правило, достаточно просто: обеспечиваются средства контроля за выполнением программ, имеющих доступ к хранимой в системе информации. Для этих целей используются либо списки абонентов, которым разрешен доступ, либо пароли, что обеспечивает защиту информации при малом количестве пользователей. Однако при широком распространении вычислительных и информационных систем, особенно в таких сферах, как обслуживание населения, банковское дело, этих средств оказалось явно недостаточно. Система, обеспечивающая защиту информации, не должна позволять доступа к данным пользователям, не имеющим такого права. Такая система защиты является неотъемлемой частью любой системы коллективного пользования средствами вычислительной техники, независимо от того, где они используются. Данные экспериментальных исследований различных систем коллективного пользования показали, что пользователь в состоянии написать программы, дающие ему доступ к любой информации, находящейся в системе. Как правило, это обусловлено наличием каких-то ошибок в программных средствах, что порождает неизвестные пути обхода установленных преград.
В процессе разработки систем защиты информации выработались некоторые общие правила, которые были сформулированы Ж. Солцером и М. Шредером (США):
1. Простота механизма защиты. Так как средства защиты усложняют и без того сложные программные и аппаратные средства, обеспечивающие обработку данных в ЭВМ, естественно стремление упростить эти дополнительные средства. Чем лучше совпадает представление пользователя о системе защиты с ее фактическими возможностями, тем меньше ошибок возникает в процессе работы.
2. Разрешения должны преобладать над запретами. Нормальным режимом работы считается отсутствие доступа, а механизм защиты должен быть основан на условиях, при которых доступ разрешается. Допуск дается лишь тем пользователям, которым он необходим.
3. Проверка полномочий любого обращения к любому объекту информации. Это означает, что защита выносится на общесистемный уровень и предполагает абсолютно надежное определение источника любого обращения.
4. Разделение полномочий заключается в определении для любой программы и любого пользователя в системе минимального круга полномочий. Это позволяет уменьшить ущерб от сбоев и случайных нарушений и сократить вероятность преднамеренного или ошибочного применения полномочий.
5. Трудоемкость проникновения в систему. Фактор трудоемкости зависит от количества проб, которые нужно сделать для успешного проникновения. Метод прямого перебора вариантов может дать результат, если для анализа используется сама ЭВМ.
6. Регистрация проникновений в систему. Иногда считают, что выгоднее регистрировать случаи проникновения, чем строить сложные системы защиты.[3]
Обеспечение защиты информации от несанкционированного доступа – дело сложное, требующее широкого проведения теоретических и экспериментальных исследований по вопросам системного проектирования. Наряду с применением разных приоритетных режимов и систем разграничения доступа разработчики информационных систем уделяют внимание различным криптографическим методам обработки информации.
Криптографические методы можно разбить на два класса:
1) обработка информации путем замены и перемещения букв, при котором объем данных не меняется (шифрование);
2) сжатие информации с помощью замены отдельных сочетаний букв, слов или фраз (кодирование).
По способу реализации криптографические методы возможны в аппаратном и программном исполнении.
Для защиты текстовой информации при передачах на удаленные станции телекоммуникационной сети используются аппаратные способы шифрования и кодирования. Для обмена информацией между ЭВМ по телекоммуникационной сети, а также для работы с локальными абонентами возможны как аппаратные, так и программные способы. Для хранения информации на магнитных носителях применяются программные способы шифрования и кодирования.
Аппаратные способы шифрования информации применяются для передачи защищенных данных по телекоммуникационной сети. Для реализации шифрования с помощью смешанного алфавита используется перестановка отдельных разрядов в пределах одного или нескольких символов.
Программные способы применяются для шифрования информации, хранящейся на магнитных носителях (дисках, лентах). Это могут быть данные различных информационно-справочных систем АСУ, АСОД и др. программные способы шифрования сводятся к операциям перестановки, перекодирования и сложения по модулю 2 с ключевыми словами. При этом используются команды ассемблера TR (перекодировать) и XC (исключающее ИЛИ).
Особое место в программах обработки информации занимают операции кодирования. Преобразование информации, в результате которого обеспечивается изменение объема памяти, занимаемой данными, называется кодированием. На практике кодирование всегда используется для уменьшения объема памяти, так как экономия памяти ЭВМ имеет большое значение в информационных системах. Кроме того, кодирование можно рассматривать как криптографический метод обработки информации.
КОДИРОВАНИЕ
Естественные языки обладают большой избыточностью для экономии памяти, объем которой ограничен, имеет смысл ликвидировать избыточность текста или уплотнить текст.
Существуют несколько способов уплотнения текста.
1) Переход от естественных обозначений к более компактным. Этот способ применяется для сжатия записи дат, номеров изделий, уличных адресов и т.д. Идея способа показана на примере сжатия записи даты. Обычно мы записываем дату в виде 10. 05. 01. , что требует 6 байтов памяти ЭВМ. Однако ясно, что для представления дня достаточно 5 битов, месяца- 4, года- не более 7, т.е. вся дата может быть записана в 16 битах или в 2-х байтах.
2) Подавление повторяющихся символов. В различных информационных текстах часто встречаются цепочки повторяющихся символов, например пробелы или нули в числовых полях. Если имеется группа повторяющихся символов длиной более 3, то ее длину можно сократить до трех символов. Сжатая таким образом группа повторяющихся символов представляет собой триграф SPN , в котором S – символ повторения; P – признак повторения; N- количество символов повторения, закодированных в триграфе. В других схемах подавления повторяющихся символов используют особенность кодов ДКОИ, КОИ- 7, КОИ-8 , заключающуюся в том , что большинство допустимых в них битовых комбинаций не используется для представления символьных данных.
3) Кодирование часто используемых элементов данных. Этот способ уплотнения данных также основан на употреблении неиспользуемых комбинаций кода ДКОИ. Для кодирования, например, имен людей можно использовать комбинации из двух байтов диграф PN, где P – признак кодирования имени, N – номер имени. Таким образом может быть закодировано 256 имен людей, чего обычно бывает достаточно в информационных системах. Другой способ основан на отыскании в текстах наиболее часто встречающихся сочетании букв и даже слов и замене их на неиспользуемые байты кода ДКОИ.
4) Посимвольное кодирование. Семибитовые и восьмибитовые коды не обеспечивают достаточно компактного кодирования символьной информации. Более пригодными для этой цели являются 5 - битовые коды, например международный телеграфный код МГК-2. Перевод информации в код МГК-2 возможен с помощью программного перекодирования или с использованием специальных элементов на основе больших интегральных схем (БИС). Пропускная способность каналов связи при передаче алфавитно-цифровой информации в коде МГК-2 повышается по сравнению с использованием восьмибитовых кодов почти на 40%.
5) Коды переменной длины. Коды с переменным числом битов на символ позволяют добиться еще более плотной упаковки данных. Метод заключается в том, что часто используемые символы кодируются короткими кодами, а символы с низкой частотой использования - длинными кодами. Идея такого кодирования была впервые высказана Хаффманом, и соответствующий код называется кодом Хаффмана. Использование кодов Хаффмана позволяет достичь сокращения исходного текста почти на 80%.
Использование различных методов уплотнения текстов кроме своего основного назначения – уменьшения информационной избыточности – обеспечивает определенную криптографическую обработку информации. Однако наибольшего эффекта можно достичь при совместном использовании как методов шифрования, так и методов кодирования информации.
Надежность защиты информации может быть оценена временем, которое требуется на расшифрование (разгадывание) информации и определение ключей.
Если информация зашифрована с помощью простой подстановки, то расшифровать ее можно было бы, определив частоты появления каждой буквы в шифрованном тексте и сравнив их с частотами букв русского алфавита. Таким образом определяется подстановочный алфавит и расшифровывается текст.
«Органы государственной власти и организации, ответственные за формирование и использование информационных ресурсов, подлежащих защите, а также органы и организации, разрабатывающие и применяющие информационные системы и информационные технологии для формирования и использования информационных ресурсов с ограниченным доступом, руководствуются в своей деятельности законодательством Российской Федерации».[4]
«За правонарушения при работе с документированной информацией органы государственной власти, организации и их должностные лица несут ответственность в соответствии с законодательством Российской Федерации и субъектов Российской Федерации.
Для рассмотрения конфликтных ситуаций и защиты прав участников в сфере формирования и использования информационных ресурсов, создания и использования информационных систем, технологий и средств их обеспечения могут создаваться временные и постоянные третейские суды.
Третейский суд рассматривает конфликты и споры сторон в порядке, установленном законодательством о третейских судах.».[5]
«Руководители, другие служащие органов государственной власти, организаций, виновные в незаконном ограничении доступа к информации и нарушении режима защиты информации, несут ответственность в соответствии с уголовным, гражданским законодательством и законодательством об административных правонарушениях».[6]
Кодирование двоичным кодом
Для автоматизации работы с данными, относящимися к различным типам очень важно унифицировать их форму представления – для этого обычно используется приём кодирования, т.е. выражение данных одного типа через данные другого типа. Естественные человеческие языки – системы кодирования понятий для выражения мыслей посредством речи. К языкам близко примыкают азбуки – системы кодирования компонентов языка с помощью графических символов.
Своя системы существует и в вычислительной технике – она называется двоичным кодированием и основана на представлении данных последовательностью всего двух знаков: 0 и 1. Эти знаки называют двоичными цифрами, по-английски – binarydigit или сокращённо bit (бит). Одним битом могут быть выражены два понятия: 0 или 1 (да или нет, чёрное или белое, истина или ложь и т.п.). Если количество битов увеличить до двух, то уже можно выразить четыре различных понятия. Тремя битами можно закодировать восемь различных значений.
Кодирование целых и действительных чисел
Целые числа кодируются двоичным кодом достаточно просто - необходимо взять целое число и делить его пополам до тех пор, пока частное не будет равно единице. Совокупность остатков от каждого деления, записанная справа налево вместе с последним частным, и образует двоичный аналог десятичного числа.
Для кодирования целых чисел от 0 до 255 достаточно иметь 8 разрядов двоичного кода (8 бит). 16 бит позволяют закодировать целые числа от 0 до 65535, а 24 – уже более 16,5 миллионов различных значений.
Для кодирования действительных чисел используют 80-разрядное кодирование. При этом число предварительно преобразовывают в нормализованную форму:
3,1414926 = 0,31415926 × 101
300 000 = 0,3 × 106
Первая часть числа называется мантиссой, а вторая – характеристикой. Большую часть из 80 бит отводят для хранения мантиссы (вместе со знаком) и некоторое фиксированное количество разрядов отводят для хранения характеристики.
Кодирование текстовых данных
Если каждому символу алфавита сопоставить определённое целое число, то с помощью двоичного кода можно кодировать текстовую информацию. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Это хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и некоторые общепринятые специальные символы.
Технически это выглядит очень просто, однако всегда существовали достаточно веские организационные сложности. В первые годы развития вычислительной техники они были связаны с отсутствием необходимых стандартов, а в настоящее время вызваны, наоборот, изобилием одновременно действующих и противоречивых стандартов. Для того чтобы весь мир одинаково кодировал текстовые данные, нужны единые таблицы кодирования, а это пока невозможно из-за противоречий между символами национальных алфавитов, а также противоречий корпоративного характера.
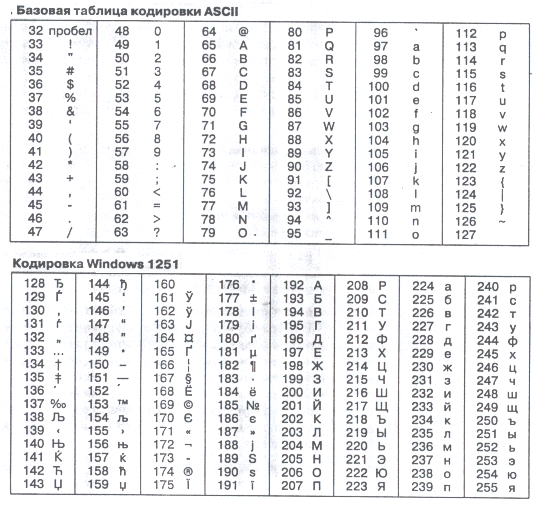
Для английского языка, захватившего де-факто нишу международного средства общения, противоречия уже сняты. Институт стандартизации США ввёл в действие систему кодирования ASCII (AmericanStandardCodeforInformationInterchange – стандартный код информационного обмена США). В системе ASCII закреплены две таблицы кодирования базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств. В этой области размещаются управляющие коды, которым не соответствуют ни какие символы языков. Начиная с 32 по 127 код размещены коды символов английского алфавита, знаков препинания, арифметических действий и некоторых вспомогательных символов.
Кодировка символов русского языка, известная как кодировка Windows-1251, была введена «извне» - компанией Microsoft, но, учитывая широкое распространение операционных систем и других продуктов этой компании в России, она глубоко закрепилась и нашла широкое распространение.
Другая распространённая кодировка носит название КОИ-8 (код обмена информацией, восьмизначный) – её происхождение относится к временам действия Совета Экономической Взаимопомощи государств Восточной Европы. Сегодня кодировка КОИ – 8 имеет широкое распространение в компьютерных сетях на территории России и в российском секторе Интернета.
Международный стандарт, в котором предусмотрена кодировка символов русского языка, носит названия ISO (InternationalStandardOrganization – Международный институт стандартизации). На практике данная кодировка используется редко.
Универсальная система кодирования текстовых данных
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). В то же время, очевидно, что если, кодировать символы не восьмиразрядными двоичными числами, а числами с большим разрядом то и диапазон возможных значений кодов станет на много больше. Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной – UNICODE. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65 536 различных символов – этого поля вполне достаточно для размещения в одной таблице символов большинства языков планеты.
Несмотря на тривиальную очевидность такого подхода, простой механический переход на данную систему долгое время сдерживался из-за недостатков ресурсов средств вычислительной техники (в системе кодирования UNICODE все текстовые документы становятся автоматически вдвое длиннее). Во второй половине 90-х годов технические средства достигли необходимого уровня обеспечения ресурсами, и сегодня мы наблюдаем постепенный перевод документов и программных средств на универсальную систему кодирования.
Ниже приведены таблицы кодировки ASCII.
Кодирование графических данных
Если рассмотреть с помощью увеличительного стекла чёрно-белое графическое изображение, напечатанное в газете или книге, то можно увидеть, что оно состоит из мельчайших точек, образующих характерный узор, называемый растром. Поскольку линейные координаты и индивидуальные свойства каждой точки (яркость) можно выразить с помощью целых чисел, то можно сказать, что растровое кодирование позволяет использовать двоичный код для представления графических данных. Общепринятым на сегодняшний день считается представление чёрно-белых иллюстраций в виде комбинации точек с 256 градациями серого цвета, и, таким образом, для кодирования яркости любой точки обычно достаточно восьмиразрядного двоичного числа.
Для кодирования цветных графических изображений применяется принцип декомпозиции произвольного цвета на основные составляющие. В качестве таких составляющих используют три основные цвета: красный (Red), зелёный (Green) и синий (Blue). На практике считается, что любой цвет, видимый человеческим глазом, можно получить механического смешения этих трёх основных цветов. Такая система кодирования получила названия RGB по первым буквам основных цветов.
Режим представления цветной графики с использованием 24 двоичных разрядов называется полноцветным (TrueColor).
Каждому из основных цветов можно поставить в соответствие дополнительный цвет, т.е. цвет, дополняющий основной цвет до белого. Нетрудно заметить, что для любого из основных цветов дополнительным будет цвет, образованный суммой пары остальных основных цветов. Соответственно дополнительными цветами являются: голубой (Cyan), пурпурный (Magenta) и жёлтый (Yellow). Принцип декомпозиции произвольного цвета на составляющие компоненты можно применять не только для основных цветов, но и для дополнительных, т.е. любой цвет можно представить в виде суммы голубой, пурпурной и жёлтой составляющей. Такой метод кодирования цвета принят в полиграфии, но в полиграфии используется ещё и четвёртая краска – чёрная (Black). Поэтому данная система кодирования обозначается четырьмя буквами CMYK (чёрный цвет обозначается буквой К, потому, что буква В уже занята синим цветом), и для представления цветной графики в этой системе надо иметь 32 двоичных разряда. Такой режим также называется полноцветным.
Если уменьшить количество двоичных разрядов, используемых для кодирования цвета каждой точки, то можно сократить объём данных, но при этом диапазон кодируемых цветов заметно сокращается. Кодирование цветной графики 16-разрядными двоичными числами называется режимом HighColor.
При кодировании информации о цвете с помощью восьми бит данных можно передать только 256 оттенков. Такой метод кодирования цвета называется индексным.
Кодирование звуковой информации
Приёмы и методы работы со звуковой информацией пришли в вычислительную технику наиболее поздно. К тому же, в отличие от числовых, текстовых и графических данных, у звукозаписей не было столь же длительной и проверенной истории кодирования. В итоге методы кодирования звуковой информации двоичным кодом далеки от стандартизации. Множество отдельных компаний разработали свои корпоративные стандарты, но среди них можно выделить два основных направления.
1) Метод FM (FrequencyModulation) основан та том, что теоретически любой сложный звук можно разложить на последовательность простейших гармонических сигналов разных частот, каждый из которых представляет собой правильную синусоиду, а, следовательно, может быть описан числовыми параметрами, т.е. кодом. В природе звуковые сигналы имеют непрерывный спектр, т.е. являются аналоговыми. Их разложение в гармонические ряды и представление в виде дискретных цифровых сигналов выполняют специальный устройства – аналогово-цифровые преобразователи (АЦП). Обратное преобразование для воспроизведения звука, закодированного числовым кодом, выполняют цифро-аналоговые преобразователи (ЦАП). При таких преобразованиях неизбежны потери информации, связанные с методом кодирования, поэтому качество звукозаписи обычно получается не вполне удовлетворительным и соответствует качеству звучания простейших электромузыкальных инструментов с окрасом характерным для электронной музыки. В то же время данный метод копирования обеспечивает весьма компактный код, поэтому он нашёл применение ещё в те годы, когда ресурсы средств вычислительной техники были явно недостаточны.
2) Метод таблично волнового (Wave-Table) синтеза лучше соответствует современному уровню развития техники. В заранее подготовленных таблицах хранятся образцы звуков для множества различных музыкальных инструментах. В технике такие образцы называют сэмплами. Числовые коды выражают тип инструмента, номер его модели, высоту тона, продолжительность и интенсивность звука, динамику его изменения, некоторые параметры среды, в которой происходит звучание, а также прочие параметры, характеризующие особенности звучания. Поскольку в качестве образцов исполняются реальные звуки, то его качество получается очень высоким и приближается к качеству звучания реальных музыкальных инструментов.
Программные средства защиты информации
Программными называются средства защиты данных, функционирующие в составе программного обеспечения. Среди них можно выделить и подробнее рассмотреть следующие;
- средства архивации данных
- антивирусные программы
- криптографические средства
- средства идентификации и аутентификации пользователей
- средства управления доступом
- протоколирование и аудит
Как примеры комбинаций вышеперечисленных мер можно привести:
- защиту баз данных
- защиту информации при работе в компьютерных сетях.
Средства архивации информации.
Иногда резервные копии информации приходится выполнять при общей ограниченности ресурсов размещения данных, например владельцам персональных компьютеров. В этих случаях используют программную архивацию. Архивация это слияние нескольких файлов и даже каталогов в единый файл — архив, одновременно с сокращением общего объема исходных файлов путем устранения избыточности, но без потерь информации, т. е. с возможностью точного восстановления исходных файлов. Действие большинства средств архивации основано на использовании алгоритмов сжатия, предложенных в 80-х гг. Абрахамом Лемпелем и Якобом Зивом. Наиболее известны и популярны следующие архивные форматы;
- ZIP, ARJ для операционных систем DOS. и Windows
- TAR для операционной системы Unix
- межплатформный формат JAR (Java ARchive)
- RAR (все время растет популярность этого нового формата, так как разработаны программы позволяющие использовать его в операционных системах DOS, Windows и Unix),
Пользователю следует лишь выбрать для себя подходящую программу, обеспечивающую работу с выбранным форматом, путем оценки ее характеристик – быстродействия, степени сжатия, совместимости с большим количеством форматов, удобности интерфейса, выбора операционной системы и т.д.. Список таких программ очень велик – PKZIP, PKUNZIP, ARJ, RAR, WinZip, WinArj, ZipMagic, WinRar и много других. Большинство из этих программ не надо специально покупать, так как они предлагаются как программы условно-бесплатные (Shareware) или свободного распространения (Freeware). Также очень важно установить постоянный график проведения таких работ по архивации данных или выполнять их после большого обновления данных.
Антивирусные программы.
Это программы разработанные для защиты информации от вирусов. Неискушенные пользователи обычно считают, что компьютерный вирус - это специально написанная небольшая по размерам программа, которая может "приписывать" себя к другим программам (т.е. "заражать" их), а также выполнять нежелательные различные действия на компьютере. Специалисты по компьютерной вирусологии определяют, что ОБЯЗАТЕЛЬНЫМ (НЕОБХОДИМЫМ) СВОЙСТВОМ КОМПЬЮТЕРНОГО ВИРУСА является возможность создавать свои дубликаты (не обязательно совпадающие с оригиналом) и внедрять их в вычислительные сети и/или файлы, системные области компьютера и прочие выполняемые объекты. При этом дубликаты сохраняют способность к дальнейшему распространению. Следует отметить, что это условие не является достаточным т.е. окончательным. Вот почему точного определения вируса нет до сих пор, и вряд ли оно появится в обозримом будущем. Следовательно, нет точно определенного закона, по которому «хорошие» файлы можно отличить от «вирусов». Более того, иногда даже для конкретного файла довольно сложно определить, является он вирусом или нет.
Классификация компьютерных вирусов
Вирусы можно разделить на классы по следующим основным признакам:
- деструктивные возможности
- особенности алгоритма работы;
- среда обитания;
По ДЕСТРУКТИВНЫМ ВОЗМОЖНОСТЯМ вирусы можно разделить на:
- безвредные, т.е. никак не влияющие на работу компьютера (кроме уменьшения свободной памяти на диске в результате своего распространения);
- неопасные, влияние которых ограничивается уменьшением свободной памяти на диске и графическими, звуковыми и прочими эффектами;
- опасные вирусы, которые могут привести к серьезным сбоям в работе компьютера;
- очень опасные, в алгоритм работы которых заведомо заложены процедуры, которые могут привести к потере программ, уничтожить данные, стереть необходимую для работы компьютера информацию, записанную в системных областях памяти
ОСОБЕННОСТИ АЛГОРИТМА РАБОТЫ вирусов можно охарактеризовать следующими свойствами:
- резидентность;
- использование стелс-алгоритмов;
- самошифрование и полиморфичность;
Резидентные вирусы
Под термином "резидентность" (DOS'овский термин TSR - Terminate and Stay Resident) понимается способность вирусов оставлять свои копии в системной памяти, перехватывать некоторые события (например, обращения к файлам или дискам) и вызывать при этом процедуры заражения обнаруженных объектов (файлов и секторов). Таким образом, резидентные вирусы активны не только в момент работы зараженной программы, но и после того, как программа закончила свою работу. Резидентные копии таких вирусов остаются жизнеспособными вплоть до очередной перезагрузки, даже если на диске уничтожены все зараженные файлы. Часто от таких вирусов невозможно избавиться восстановлением всек копий файлов с дистрибутивных дисков или backup-копий. Резидентная копия вируса остается активной и заражает вновь создаваемые файлы. То же верно и для загрузочных вирусов — форматирование диска при наличии в памяти резидентного вируса не всегда вылечивает диск, поскольку многие резидентные вирусы заражает диск повторно после того, как он отформатирован.
Нерезидентные вирусы.
Нерезидентные вирусы, напротив, активны довольно непродолжительное время — только в момент запуска зараженной программы. Для своего распространения они ищут на диске незараженные файлы и записываются в них. После того, как код вируса передает управление программе-носителю, влияние вируса на работу операционной системы сводится к нулю вплоть до очередного запуска какой-либо зараженной программы. Поэтому файлы, зараженные нерезидентными вирусами значительно проще удалить с диска и при этом не позволить вирусу заразить их повторно.
Стелс-вирусы
Стелс-вирусы теми или иными способами скрывают факт своего присутствия в системе..
Использование СТЕЛС-алгоритмов позволяет вирусам полностью или частично скрыть себя в системе. Наиболее распространенным стелс-алгоритмом является перехват запросов OC на чтение/запись зараженных объектов. Стелс-вирусы при этом либо временно лечат их, либо «подставляют» вместо себя незараженные участки информации. В случае макро-вирусов наиболее популярный способ — запрет вызовов меню просмотра макросов. Известны стелс-вирусы всех типов, за исключением Windows-вирусов — загрузочные вирусы, файловые DOS-вирусы и даже макро-вирусы. Появление стелс-вирусов, заражающих файлы Windows, является скорее всего делом времени
Полиморфик-вирусы
САМОШИФРОВАНИЕ и ПОЛИМОРФИЧНОСТЬ используются практически всеми типами вирусов для того, чтобы максимально усложнить процедуру детектирования вируса. Полиморфик - вирусы (polymorphic) - это достаточно трудно обнаружимые вирусы, не имеющие сигнатур, т.е. не содержащие ни одного постоянного участка кода. В большинстве случаев два образца одного и того же полиморфик-вируса не будут иметь ни одного совпадения. Это достигается шифрованием основного тела вируса и модификациями программы-расшифровщика.
К полиморфик-вирусам относятся те из них, детектирование которых невозможно (или крайне затруднительно) осуществить при помощи так называемых вирусных масок - участков постоянного кода, специфичных для конкретного вируса. Достигается это двумя основными способами - шифрованием основного кода вируса с непостоянным ключем и случаным набором команд расшифровщика или изменением самого выполняемого кода вируса. Полиморфизм различной степени сложности встречается в вирусах всех типов - от загрузочных и файловых DOS-вирусов до Windows-вирусов.
По СРЕДЕ ОБИТАНИЯ вирусы можно разделить на:
- файловые;
- загрузочные;
- макровирусы;
- сетевые.
Файловые вирусы
Файловые вирусы либо различными способами внедряются в выполняемые файлы (наиболее распространенный тип вирусов), либо создают файлы-двойники (компаньон-вирусы), либо используют особенности организации файловой системы (link-вирусы).
Внедрение файлового вируса возможно практически во все исполняемые файлы всех популярных ОС. На сегодняшний день известны вирусы, поражающие все типы выполняемых объектов стандартной DOS: командные файлы (BAT), загружаемые драйверы (SYS, в том числе специальные файлы IO.SYS и MSDOS.SYS) и выполняемые двоичные файлы (EXE, COM). Существуют вирусы, поражающие исполняемые файлы других операционных систем - Windows 3.x, Windows95/NT, OS/2, Macintosh, UNIX, включая VxD-драйвера Windows 3.x и Windows95.
Существуют вирусы, заражающие файлы, которые содержат исходные тексты программ, библиотечные или объектные модули. Возможна запись вируса и в файлы данных, но это случается либо в результате ошибки вируса, либо при проявлении его агрессивных свойств. Макро-вирусы также записывают свой код в файлы данных - документы или электронные таблицы, - однако эти вирусы настолько специфичны, что вынесены в отдельную группу.
Загрузочные вирусы
Загрузочные вирусы заражают загрузочный (boot) сектор флоппи-диска и boot-сектор или Master Boot Record (MBR) винчестера. Принцип действия загрузочных вирусов основан на алгоритмах запуска операционной системы при включении или перезагрузке компьютера - после необходимых тестов установленного оборудования (памяти, дисков и т.д.) программа системной загрузки считывает первый физический сектор загрузочного диска (A:, C: или CD-ROM в зависимости от параметров, установленных в BIOS Setup) и передает на него управление.
В случае дискеты или компакт-диска управление получает boot-сектор, который анализирует таблицу параметров диска (BPB - BIOS Parameter Block) высчитывает адреса системных файлов операционной системы, считывает их в память и запускает на выполнение. Системными файлами обычно являются MSDOS.SYS и IO.SYS, либо IBMDOS.COM и IBMBIO.COM, либо других в зависимости от установленной версии DOS, Windows или других операционных систем. Если же на загрузочном диске отсутствуют файлы операционной системы, программа, расположенная в boot-секторе диска выдает сообщение об ошибке и предлагает заменить загрузочный диск.
В случае винчестера управление получает программа, расположенная в MBR винчестера. Эта программа анализирует таблицу разбиения диска (Disk Partition Table), вычисляет адрес активного boot-сектора (обычно этим сектором является boot-сектор диска C:), загружает его в память и передает на него управление. Получив управление, активный boot-сектор винчестера проделывает те же действия, что и boot-сектор дискеты.
При заражении дисков загрузочные вирусы «подставляют» свой код вместо какой-либо программы, получающей управление при загрузке системы. Принцип заражения, таким образом, одинаков во всех описанных выше способах: вирус "заставляет" систему при ее перезапуске считать в память и отдать управление не оригинальному коду загрузчика, но коду вируса.
Заражение дискет производится единственным известным способом — вирус записывает свой код вместо оригинального кода boot-сектора дискеты. Винчестер заражается тремя возможными способами - вирус записывается либо вместо кода MBR, либо вместо кода boot-сектора загрузочного диска (обычно диска C:), либо модифицирует адрес активного boot-сектора в Disk Partition Table, расположенной в MBR винчестера.
Макро-вирусы
Макро-вирусы заражают файлы-документы и электронные таблицы нескольких популярных редакторов. Макро-вирусы (macro viruses) являются программами на языках (макро-языках), встроенных в некоторые системы обработки данных (текстовые редакторы, электронные таблицы и т.д.). Для своего размножения такие вирусы используют возможности макро-языков и при их помощи переносят себя из одного зараженного файла (документа или таблицы) в другие. Наибольшее распространение получили макро-вирусы для Microsoft Word, Excel и Office97. Существуют также макро-вирусы, заражающие документы Ami Pro и базы данных Microsoft Access.
Сетевые вирусы
К сетевым относятся вирусы, которые для своего распространения активно используют протоколы и возможности локальных и глобальных сетей. Основным принципом работы сетевого вируса является возможность самостоятельно передать свой код на удаленный сервер или рабочую станцию. «Полноценные» сетевые вирусы при этом обладают еще и возможностью запустить на выполнение свой код на удаленном компьютере или, по крайней мере, «подтолкнуть» пользователя к запуску зараженного файла. Пример сетевых вирусов – так называемые IRC-черви.
IRC (Internet Relay Chat) — это специальный протокол, разработанный для коммуникации пользователей Интернет в реальном времени. Этот протокол предоставляет им возможность Итрернет-"разговора" при помощи специально разработанного программного обеспечения. Помимо посещения общих конференций пользователи IRC имеют возможность общаться один-на-один с любым другим пользователем. Кроме этого существует довольно большое количество IRC-команд, при помощи которых пользователь может получить информацию о других пользователях и каналах, изменять некоторые установки IRC-клиента и прочее. Существует также возможность передавать и принимать файлы - именно на этой возможности и базируются IRC-черви. Как оказалось, мощная и разветвленная система команд IRC-клиентов позволяет на основе их скриптов создавать компьютерные вирусы, передающие свой код на компьютеры пользователей сетей IRC, так называемые "IRC-черви". Принцип действия таких IRC-червей примерно одинаков. При помощи IRC-команд файл сценария работы (скрипт) автоматически посылается с зараженного компьютера каждому вновь присоединившемуся к каналу пользователю. Присланный файл-сценарий замещает стандартный и при следующем сеансе работы уже вновь зараженный клиент будет рассылать червя. Некоторые IRC-черви также содержат троянский компонент: по заданным ключевым словам производят разрушительные действия на пораженных компьютерах. Например, червь "pIRCH.Events" по определенной команде стирает все файлы на диске пользователя.
Существует большое количество сочетаний - например, файлово-загрузочные вирусы, заражающие как файлы, так и загрузочные сектора дисков. Такие вирусы, как правило, имеют довольно сложный алгоритм работы, часто применяют оригинальные методы проникновения в систему, используют стелс и полиморфик-технологии. Другой пример такого сочетания - сетевой макро-вирус, который не только заражает редактируемые документы, но и рассылает свои копии по электронной почте.
В дополнение к этой классификации следует сказать несколько слов о других вредоносных программах, которые иногда путают с вирусами. Эти программы не обладают способностью к самораспространению как вирусы, но способны нанести столь же разрушительный урон.
Троянские кони (логические бомбы или временные бомбы)
К троянским коням относятся программы, наносящие какие-либо разрушительные действия, т.е. в зависимости от каких-либо условий или при каждом запуске уничтожающая информацию на дисках, "завешивающая" систему, и т.п. В качестве примера можно привести и такой случай – когда такая программа во время сеанса работы в Интернете пересылала своему автору идентификаторы и пароли с компьютеров, где она обитала. Большинство известных троянских коней являются программами, которые "подделываются" под какие-либо полезные программы, новые версии популярных утилит или дополнения к ним. Очень часто они рассылаются по BBS-станциям или электронным конференциям. По сравнению с вирусами "троянские кони" не получают широкого распространения по достаточно простым причинам - они либо уничтожают себя вместе с остальными данными на диске, либо демаскируют свое присутствие и уничтожаются пострадавшим пользователем.
Методы обнаружения и удаления компьютерных вирусов.
Способы противодействия компьютерным вирусам можно разделить на несколько групп: профилактика вирусного заражения и уменьшение предполагаемого ущерба от такого заражения; методика использования антивирусных программ, в том числе обезвреживание и удаление известного вируса; способы обнаружения и удаления неизвестного вируса.
- Профилактика заражения компьютера
- Восстановление пораженных объектов
- Антивирусные программы
Профилактика заражения компьютера
Одним из основных методов борьбы с вирусами является, как и в медицине, своевременная профилактика. Компьютерная профилактика предполагает соблюдение небольшого числа правил, которое позволяет значительно снизить вероятность заражения вирусом и потери каких-либо данных.
Для того чтобы определить основные правила компьютерной гигиены, необходимо выяснить основные пути проникновения вируса в компьютер и компьютерные сети.
Основным источником вирусов на сегодняшний день является глобальная сеть Internet. Наибольшее число заражений вирусом происходит при обмене письмами в форматах Word/Office97. Пользователь зараженного макро-вирусом редактора, сам того не подозревая, рассылает зараженные письма адресатам, которые в свою очередь отправляют новые зараженные письма и т.д. Выводы – следует избегать контактов с подозрительными источниками информации и пользоваться только законными (лицензионными) программными продуктами. К сожалению в нашей стране это не всегда возможно.
Восстановление пораженных объектов
В большинстве случаев заражения вирусом процедура восстановления зараженных файлов и дисков сводится к запуску подходящего антивируса, способного обезвредить систему. Если же вирус неизвестен ни одному антивирусу, то достаточно отослать зараженный файл фирмам-производителям антивирусов и через некоторое время (обычно — несколько дней или недель) получить лекарство-«апдейт» против вируса. Если же время не ждет, то обезвреживание вируса придется произвести самостоятельно. Для большинства пользователей необходимо иметь резервные копии своей информации.
Классификация антивирусных программ.
Наиболее эффективны в борьбе с компьютерными вирусами антивирусные программы. Однако сразу хотелось бы отметить, что не существует антивирусов, гарантирующих стопроцентную защиту от вирусов, и заявления о существовании таких систем можно расценить как либо недобросовестную рекламу, либо непрофессионализм. Таких систем не существует, поскольку на любой алгоритм антивируса всегда можно предложить контр-алгоритм вируса, невидимого для этого антивируса (обратное, к счастью, тоже верно: на любой алгоритм вируса всегда можно создать антивирус).
Самыми популярными и эффективными антивирусными программами являются антивирусные сканеры (другие названия: фаг, полифаг, программа-доктор). Следом за ними по эффективности и популярности следуют CRC-сканеры (также: ревизор, checksumer, integritychecker). Часто оба приведенных метода объединяются в одну универсальную антивирусную программу, что значительно повышает ее мощность. Применяются также различного типа блокировщики и иммунизаторы.
Сканеры
Принцип работы антивирусных сканеров основан на проверке файлов, секторов и системной памяти и поиске в них известных и новых (неизвестных сканеру) вирусов. Для поиска известных вирусов используются так называемые «маски». Маской вируса является некоторая постоянная последовательность кода, специфичная для этого конкретного вируса. Если вирус не содержит постоянной маски, или длина этой маски недостаточно велика, то используются другие методы. Примером такого метода являетcя алгоритмический язык, описывающий все возможные варианты кода, которые могут встретиться при заражении подобного типа вирусом. Такой подход используется некоторыми антивирусами для детектирования полиморфик - вирусов. Сканеры также можно разделить на две категории — «универсальные» и «специализированные». Универсальные сканеры рассчитаны на поиск и обезвреживание всех типов вирусов вне зависимости от операционной системы, на работу в которой рассчитан сканер. Специализированные сканеры предназначены для обезвреживания ограниченного числа вирусов или только одного их класса, например макро-вирусов. Специализированные сканеры, рассчитанные только на макро-вирусы, часто оказываются наиболее удобным и надежным решением для защиты систем документооборота в средах MSWord и MSExcel.
Сканеры также делятся на «резидентные» (мониторы, сторожа), производящие сканирование «на-лету», и «нерезидентные», обеспечивающие проверку системы только по запросу. Как правило, «резидентные» сканеры обеспечивают более надежную защиту системы, поскольку они немедленно реагируют на появление вируса, в то время как «нерезидентный» сканер способен опознать вирус только во время своего очередного запуска. С другой стороны резидентный сканер может несколько замедлить работу компьютера в том числе и из-за возможных ложных срабатываний.
К достоинствам сканеров всех типов относится их универсальность, к недостаткам —относительно небольшую скорость поиска вирусов. Наиболее распространены в России следующие программы: AVP - Касперского, Dr.Weber – Данилова, NortonAntivirus
фирмы Semantic.
CRC -сканеры
Принцип работы CRC-сканеров основан на подсчете CRC-сумм (контрольных сумм) для присутствующих на диске файлов/системных секторов. Эти CRC-суммы затем сохраняются в базе данных антивируса, как, впрочем, и некоторая другая информация: длины файлов, даты их последней модификации и т.д. При последующем запуске CRC-сканеры сверяют данные, содержащиеся в базе данных, с реально подсчитанными значениями. Если информация о файле, записанная в базе данных, не совпадает с реальными значениями, то CRC-сканеры сигнализируют о том, что файл был изменен или заражен вирусом. CRC-сканеры, использующие анти-стелс алгоритмы, являются довольно сильным оружием против вирусов: практически 100% вирусов оказываются обнаруженными почти сразу после их появления на компьютере. Однако у этого типа антивирусов есть врожденный недостаток, который заметно снижает их эффективность. Этот недостаток состоит в том, что CRC-сканеры не способны поймать вирус в момент его появления в системе, а делают это лишь через некоторое время, уже после того, как вирус разошелся по компьютеру. CRC-сканеры не могут определить вирус в новых файлах (в электронной почте, на дискетах, в файлах, восстанавливаемых из backup или при распаковке файлов из архива), поскольку в их базах данных отсутствует информация об этих файлах. Более того, периодически появляются вирусы, которые используют эту «слабость» CRC-сканеров, заражают только вновь создаваемые файлы и остаются, таким образом, невидимыми для них. Наиболее используемые в России программы подобного рода- ADINF и AVPInspector.
Блокировщики
Антивирусные блокировщики — это резидентные программы, перехватывающие «вирусо-опасные» ситуации и сообщающие об этом пользователю. К «вирусо-опасным» относятся вызовы на открытие для записи в выполняемые файлы, запись в boot-сектора дисков или MBR винчестера, попытки программ остаться резидентно и т.д., то есть вызовы, которые характерны для вирусов в моменты из размножения. Иногда некоторые функции блокировщиков реализованы в резидентных сканерах.
К достоинствам блокировщиков относится их способность обнаруживать и останавливать вирус на самой ранней стадии его размножения, что, кстати, бывает очень полезно в случаях, когда давно известный вирус постоянно «выползает неизвестно откуда». К недостаткам относятся существование путей обхода защиты блокировщиков и большое количество ложных срабатываний, что, видимо, и послужило причиной для практически полного отказа пользователей от подобного рода антивирусных программ (например, неизвестно ни об одном блокировщике для Windows95/NT — нет спроса, нет и предложения).
Необходимо также отметить такое направление антивирусных средств, как антивирусные блокировщики, выполненные в виде аппаратных компонентов компьютера («железа»). Наиболее распространенной является встроенная в BIOS защита от записи в MBR винчестера. Однако, как и в случае с программными блокировщиками, такую защиту легко обойти прямой записью в порты контроллера диска, а запуск DOS-утилиты FDISK немедленно вызывает «ложное срабатывание» защиты.
Существует несколько более универсальных аппаратных блокировщиков, но к перечисленным выше недостаткам добавляются также проблемы совместимости со стандартными конфигурациями компьютеров и сложности при их установке и настройке. Все это делает аппаратные блокировщики крайне непопулярными на фоне остальных типов антивирусной защиты.
Иммунизаторы
Иммунизаторы - это программы записывающие в другие программы коды, сообщающие о заражении. Они обычно записывают эти коды в конец файлов (по принципу файлового вируса) и при запуске файла каждый раз проверяют его на изменение. Недостаток у них всего один, но он летален: абсолютная неспособность сообщить о заражении стелс-вирусом. Поэтому такие иммунизаторы, как и блокировщики, практически не используются в настоящее время. Кроме того многие программы, разработанные в последнее время, сами проверяют себя на целостность и могут принять внедренные в них коды за вирусы и отказаться работать.
Перспективы борьбы с вирусами.
Вирусы успешно внедрились в повседневную компьютерную жизнь и покидать ее в обозримом будущем не собираются. Так кто же пишет вирусы? Основную их массу создают студенты и школьники, которые только что изучили язык ассемблера, хотят попробовать свои силы, но не могут найти для них более достойного применения. Вторую группу составляют также молодые люди (чаще - студенты), которые еще не полностью овладели искусством программирования, но уже решили посвятить себя написанию и распространению вирусов. Единственная причина, толкающая подобных людей на написание вирусов, это комплекс неполноценности, который проявляет себя в компьютерном хулиганстве. Из-под пера подобных «умельцев» часто выходят либо многочисленные модификации «классических» вирусов, либо вирусы крайне примитивные и с большим числом ошибок. Став старше и опытнее, но так и не повзрослев, некоторые из подобных вирусописателей попадают в третью, наиболее опасную группу, которая создает и запускает в мир «профессиональные» вирусы. Однако другие профессионалы будут создавать и новые более совершенные антивирусные средства. Какой прогноз этого единоборства? Для того, чтобы ответить на этот вопрос следует определить, где и при каких условиях размножаются вирусы.
Основная питательная среда для массового распространения вируса в ЭВМ – это:
- слабая защищенность операционной системы (ОС);
- наличие разнообразной и довольно полной документации по OC и «железу». используемой авторами вирусов;
- широкое распространение этой ОС и этого «железа».
Хотя следует отметить, что понятие операционной системы достаточно растяжимое. Например, для макро-вирусов операционной системой являются редакторы Word и Excel, поскольку именно редакторы, а не Windows предоставляют макро-вирусам (т.е. программам на бейсике) необходимые ресурсы и функции.
Чем больше в операционной системе присутствуют элементов защиты информации, тем труднее будет вирусу поразить объекты своего нападения, так как для этого потребуется (как минимум) взломать систему шифрования, паролей и привилегий. В результате работа, необходимая для написания вируса, окажется по силам только профессионалам высокого уровня. А у профессионалов, как представляется, уровень порядочности все-таки намного выше, чем в среде потребителей их продукции, и, следовательно, число созданных и запущенных в большую жизнь вирусов будет сокращаться. Пример этому – новая операционная система Windows 2000 с модифицированной файловой системой NTFS. (Уже ближайшее будущее даст оценку усилиям разработчиков создать операционную систему с высокой степенью защищенности).
Заключение.
Нужно четко представлять себе, что никакие аппаратные, программные и любые другие решения не смогут гарантировать абсолютную надежность и безопасность данных в информационных системах. В то же время можно существенно уменьшить риск потерь при комплексном подходе к вопросам безопасности. Средства защиты информации нельзя проектировать, покупать или устанавливать до тех пор, пока специалистами не произведен соответствующий анализ. Анализ должен дать объективную оценку многих факторов (подверженность появлению нарушения работы, вероятность появления нарушения работы, ущерб от коммерческих потерь и др.) и предоставить информацию для определения подходящих средств защиты – административных, аппаратных, программных и прочих. В России на рынке защитных средств, присутствуют такие продукты как Кобра, DallasLock, SecretNet, Аккорд, Криптон и ряд других. Однако обеспечение безопасности информации - дорогое дело. Большая концентрация защитных средств в информационной системе может привести не только к тому, что система окажется очень дорогостоящей и потому нерентабельной и неконкурентноспособной, но и к тому, что у нее произойдет существенное снижение коэффициента готовности. Например, если такие ресурсы системы, как время центрального процессора будут постоянно тратиться на работу антивирусных программ, шифрование, резервное архивирование, протоколирование и тому подобное, скорость работы пользователей в такой системе может упасть до нуля.
Поэтому главное при определении мер и принципов защиты информации это квалифицированно определить границы разумной безопасности и затрат на средства защиты с одной стороны и поддержания системы в работоспособном состоянии и приемлемого риска с другой..
- СПИСОК ЛИТЕРАТУРЫ:
- Симонович С.В. Информатика. Базовый курс.- М.: Дрофа 2000 .– 235с
- ХоффманД.Д. Современные методы защиты информации.- М.: Бином 1980.-330с
- Федеральный закон Российской Федерации. «Об информации, информатизации и защите информации» 20 февраля 1995 г. № 24-ФЗ
- Савельев А. Я. Основы информатики: Учебник для вузов. – М.: Оникс 2001.-370с
- Баричев С. Введение в криптографию. Электронный сборник.- М.: Вече1998. -244c
- Ведеев Д. Защита данных в компьютерных сетях. Открытые системы.- М.: Дрофа 1995, №3.-180с
- Энциклопедия компьютерных вирусов Евгения Касперского – электронная версия от 16.10.1999.
- Левин В.К. Защита информации в информационно-вычислительных системах и сетях // Программирование.- СПБ.: Питер 1994. - N5.-160с
- Сяо Д., Керр Д., Мэдник С. Защита ЭВМ.- М.: Айрис 1982.- 226с
- Правовая информатика и управление в сфере предпринимательства. Учебное пособие. – М.: Юристъ 1998. – 432с
- Леонтьев В.П. ПК: универсальный справочник пользователя.- М: Айрис 2000. -165с
- Симонович С.В. Информатика. Базовый курс. – СПБ: Питер 2000. -137с
- Макарова Информатика. Учебник для ВУЗов.- М.: Дрофа 2000.-210с
- Зегжда П. Теория и практика. Обеспечение информационной безопасности. – М: Альфа 1996.-173с
[1] Федеральный закон РФ «Об информации, информатизации и защите информации» от 20 февраля 1995 г. № 24-ФЗ (ст.21).
[2] Там же. (ст. 20).
[3] Савельев А. Я. Основы информатики: Учебник для вузов. – М.: Издательство МГТУ им. Н. Э. Баумана, 2001. С. 216.
[4] Федеральный закон РФ «Об информации, информатизации и защите информации» от 20 февраля 1995 г. № 24-ФЗ (ст. 21 п.2).
[5] Там же (ст. 23 п. 3).
[6] Там же (ст. 24 п. 3).