| Скачать .docx |
Реферат: Генетические алгоритмы и их практическое применение
Содержание:
Введение………………………………………………………………………………………… 3
I. Теоритические аспекты решения задач с помощью генетических алгоритмов. 4
1.1 Постановка задачи и функция приспособленности. 8
1.4 Отбор. 11
1.6 Мутация. 13
2.Преимущества и недостатки ГА.. 14
3. Некотoрые модели генетических алгоритмов. 15
3.1 Canonical GA (I. Holland) 15
3.3 Hybrid algorithm (L. “Dave” Davis) 16
II. Пример практической реализации генетического алгоритма. 19
1.1 Математическое обоснование принципа работы программы.. 19
1.2 Принцип работы программы.. 22
Заключение. 34
Список используемой литературы.. 35
Введение
В настоящее время все более актуальными становятся задачи оптимизации, поиска, реализации распределенных и (или) параллельных систем. Многие из них легко реализуемы простыми математическими методами, но некоторые задачи требуют к себе особого подхода. Эти задачи либо не разрешимы простыми методами, либо их решение потребует значительного времени и объема ресурсов.
В процессе изучения различных подходов к решению таких задач выдвигается гипотеза что, решение задач возможно с помощью генетических алгоритмов.[1]
Объектом изучения данной учебно-исследовательской работы являются генетические алгоритмы.
Предметом изучения – применение генетических алгоритмов для нахождения решения задачи.
Задача данной учебно-исследовательской работы состоит в изучении теоретического аспекта использования генетических алгоритмов, а так же в практической реализации задачи с использованием генетического алгоритма.
I. Теоретические аспекты решения задач с помощью генетических алгоритмов
Природа поражает своей сложностью и богатством проявлений. Среди примеров можно назвать сложные социальные системы, иммунные и нейронные системы, сложные взаимосвязи между видами. Они - всего лишь некоторые из чудес, ставшие очевидными при глубоком исследовании природы вокруг нас. Наука - это одна из систем, которая объясняет окружающее и помогает приспособиться к новой информации, получаемой из внешней среды. Многое из того, что мы видим и наблюдаем, можно объяснить теорией эволюции через наследственность, изменение и отбор.[2]
На мировоззрение людей сильно повлияла теория эволюции Чарльза Дарвина, представленная в работе "Происхождение Видов", в 1859 году. Множество областей научного знания многим обязана революции, вызванной теорией эволюции и развития. Но Дарвин, подобно многим современникам, предполагающим, что в основе развития лежит естественный отбор, не мог не ошибаться. Например, он не смог показать механизм наследования, при котором поддерживается изменчивость. Однако Дарвин обнаружил главный механизм развития: отбор в соединении с изменчивостью. Во многих случаях, специфические особенности развития через изменчивость и отбор все еще не бесспорные, однако, основные механизмы объясняют невероятно широкий спектр явлений, наблюдаемые в природе.
Поэтому не удивительно, что ученые, занимающиеся компьютерными исследованиями, в поисках вдохновения обратились к теории эволюции. Возможность того, что вычислительная система, наделенная простыми механизмами изменчивости и отбора, могла бы функционировать по аналогии с законами эволюции в естественных системах, была очень привлекательной. Эта надежда является причиной появления ряда вычислительных систем, построенных на принципах естественного отбора.[3]
История эволюционных вычислений началась с разработки ряда разных независимых моделей. Основными из них были генетические алгоритмы и классификационные системы Голанда (Holland), разработанные в начале 60-х годов. После выхода книги, ставшей классикой - "Адаптация в естественных и искусственных системах" ("Adaptation in Natural and Artifical Systems", 1975), направление получило общее признание.[4]
Главная трудность при построении вычислительных систем, основанных на принципах естественного отбора и применении этих систем в прикладных задачах, состоит в том, что естественные системы довольно хаотичные, а все наши действия, фактически, носят четкую направленность. Мы используем компьютер как инструмент для решения определенных задач, что мы сами и формулируем, и акцентируем внимание на максимально быстром выполнении при минимальных затратах. Естественные системы не имеют таких целей или ограничений, во всяком случае, нам они не известны. Выживание в природе не направлено к фиксированной цели, вместо этого эволюция делает шаг вперед в любом доступном направлении. Возможно это большое обобщение, но усилия, направленные на моделирование эволюции по аналогии с естественными системами можно разбить на две больших категории:
1. системы, смоделированные на биологических принципах. Они успешно используются для задач функциональной оптимизации и могут легко быть описаны небиологическим языком;
2. системы, которые биологически более правдоподобны, но на практике неэффективными. Они больше похожи на биологические системы, имеют сложное и интересное поведение, и, наверняка, в ближайшем будущем получат практическое применение.
Конечно, на практике нельзя разделять эти вещи так строго. Эти категории - просто два полюса, между которыми лежат разные вычислительные системы. Ближе к первому полюсу - эволюционные алгоритмы, такие как Эволюционное Программирование (Evolutionary Programming), Генетические Алгоритмы (Genetic Algorithms) и Эволюционные Стратегии (Evolution Strategies). Ближе ко второму полюсу - системы, которые могут быть классифицированы как Искусственная Жизнь (Artificial Life).[5]
Генетические алгоритмы являются частью группы методов, называемой эволюционными вычислениями, которые объединяют различные варианты использования эволюционных принципов для достижения поставленной цели.
Также в ней выделяют следующие направления:
· Эволюционные стратегии
o Метод оптимизации, основанный на идеях адаптации и эволюции. Степень мутации в данном случае меняется со временем – это приводит к, так называемой, самоадаптации.
· Генетическое программирование
o Применение эволюционного подхода к популяции программ.
· Эволюционное программирование
o Было впервые предложено Л.Дж. Фогелем в 1960 году для моделирования эволюции как процесса обучения с целью создания искусственного интеллекта. Он использовал конечные автоматы, предсказывающие символы в цифровых последовательностях, которые, эволюционируя, становились более приспособленными к решению поставленной задачи.[6]
Генетические алгоритмы применяются для решения следующих задач:
· Оптимизация функций
· Оптимизация запросов в базах данных
· Разнообразные задачи на графах (задача коммивояжера, раскраска, нахождение паросочетаний)
· Настройка и обучение искусственной нейронной сети
· Задачи компоновки
· Составление расписаний
· Игровые стратегии
· Аппроксимация функций
· Искусственная жизнь
· Биоинформатика [7]
1. Классический ГА
1.1 Постановка задачи и функция приспособленности
Пусть перед нами стоит задача оптимизации, например:
· Задача наилучшего приближения
o Если рассматривать систему n линейных уравнений с m неизвестными
Ax = b
в случае, когда она переопределена (n > m ), то иногда оказывается естественной задача о нахождении вектора x , который "удовлетворяет этой системе наилучшим образом", т. е. из всех "не решений" является лучшим.
· Задача о рационе.
o Пусть имеется n различных пищевых продуктов, содержащих m различных питательных веществ. Обозначим через aij содержание (долю) j -го питательного вещества в i -ом продукте, через bj — суточную потребность организма в j -ом питательном веществе, через ci — стоимость единицы i -го продукта. Требуется составить суточный рацион питания минимальной стоимости, удовлетворяющий потребность во всех питательных веществах
o Эта задача — классическая задача линейного программирования. К ней сводятся многие оптимизационные задачи. Формулируется она так. На m складах находится груз, который нужно развезти n потребителям. Пусть ai (i = 1, ..., n ) — количество груза на i -ом складе, а bj (j = 1, ..., m ) — потребность в грузе j -го потребителя, cij — стоимость перевозки единицы груза с i -го склада j -му потребителю. Требуется минимизировать стоимость перевозок.
· Задачи о распределении ресурсов.
o Общий смысл таких задач — распределить ограниченный ресурс между потребителями оптимальным образом. Рассмотрим простейший пример — задачу о режиме работы энергосистемы. Пусть m электростанций питают одну нагрузку мощности p . Обозначим через xj активную мощность, генерируемую j -ой электростанцией. Техническими условиями определяются возможный минимум mj и максимум Mj вырабатываемой j -ой электростанцией мощности. Допустим затраты на генерацию мощности x на j -ой электростанции равны ej (x ). Требуется сгенерировать требуемую мощность p при минимальных затратах.[8]
Переформулируем задачу оптимизации как задачу нахождения максимума некоторой функции f(x1 , x2 , …, xn ), называемой функцией приспособленности (fitness function). Она должна принимать неотрицательные значения на ограниченной области определения (для того, чтобы мы могли для каждой особи считать её приспособленность, которая не может быть отрицательной), при этом совершенно не требуются непрерывность и дифференцируемость.
Каждый параметр функции приспособленности кодируется строкой битов.
Особью будет называться строка, являющаяся конкатенацией строк упорядоченного набора параметров (рис1):
1010 10110 101 … 10101
| x1 | x2 | x3 | … | xn |
Рис 1. Ионкатенационная строка упорядоченного набора параметров
Универсальность ГА заключается в том, что от конкретной задачи зависят только такие параметры, как функция приспособленности и кодирование решений. Остальные шаги для всех задач производятся одинаково.[9]
Генетические алгоритмы оперируют совокупностью особей (популяцией), которые представляют собой строки, кодирующие одно из решений задачи. Этим ГА отличается от большинства других алгоритмов оптимизации, которые оперируют лишь с одним решением, улучшая его.[10]
С помощью функции приспособленности среди всех особей популяции выделяют:
· наиболее приспособленные (более подходящие решения), которые получают возможность скрещиваться и давать потомство
· наихудшие (плохие решения), которые удаляются из популяции и не дают потомства
Таким образом, приспособленность нового поколения в среднем выше предыдущего.[11]
В классическом ГА:
· начальная популяция формируется случайным образом
· размер популяции (количество особей N) фиксируется и не изменяется в течение работы всего алгоритма
· каждая особь генерируется как случайная L-битная строка, где L — длина кодировки особи
· длина кодировки для всех особей одинакова[12]
1.3 Алгоритм работы
На рисунке 2 изображена схема работы любого генетического алгоритма:
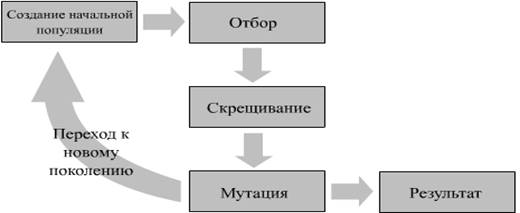
Рис 2. Схема работы любого генетического алгоритма.
Шаг алгоритма состоит из трех стадий:
1. генерация промежуточной популяции (intermediate generation ) путем отбора (selection ) текущего поколения
2. скрещивание (recombination ) особей промежуточной популяции путем кроссовера (crossover ), что приводит к формированию нового поколения
3. мутация нового поколения [13]
Промежуточная популяция — это набор особей, получивших право размножаться. Наиболее приспособленные особи могут быть записаны туда несколько раз, наименее приспособленные с большой вероятностью туда вообще не попадут.[14]
В классическом ГА вероятность каждой особи попасть в промежуточную популяцию пропорциональна ее приспособленности, т.е. работает пропорциональный отбор (proportional selection ).
Существует несколько способов реализации данного отбора:
- stochastic sampling . Пусть особи располагаются на колесе рулетки так, что размер сектора каждой особи пропорционален ее приспособленности. N раз запуская рулетку, выбираем требуемое количество особей для записи в промежуточную популяцию.
- remainder stochastic sampling . Для каждой особи вычисляется отношение ее приспособленности к средней приспособленности популяции. Целая часть этого отношения указывает, сколько раз нужно записать особь в промежуточную популяцию, а дробная показывает её вероятность попасть туда ещё раз. Реализовать такой способ отбора удобно следующим образом: расположим особи на рулетке так же, как было описано. Теперь пусть у рулетки не одна стрелка, а N , причем они отсекают одинаковые сектора. Тогда один запуск рулетки выберет сразу все N особей, которые нужно записать в промежуточную популяцию.[15] Такой способ иллюстрируется рисунком 3:

Рис 3. Способ remainder stochastic sampling в реализации отбора
Особи промежуточной популяции случайным образом разбиваются на пары, потом с некоторой вероятностью скрещиваются, в результате чего получаются два потомка, которые записываются в новое поколение, или не скрещиваются, тогда в новое поколение записывается сама пара.
В классическом ГА применяется одноточечный оператор кроссовера (1-point crossover ): для родительских строк случайным образом выбирается точка раздела, потомки получаются путём обмена отсечёнными частями [16] (рис.4).
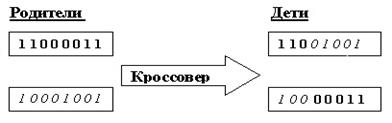 Рис 4. Одноточечный оператор кроссовера
Рис 4. Одноточечный оператор кроссовера
1.6 Мутация
К полученному в результате отбора и скрещивания новому поколению применяется оператор мутации, необходимый для "выбивания" популяции из локального экстремума и способствующий защите от преждевременной сходимости.
Каждый бит каждой особи популяции с некоторой вероятностью инвертируется. Эта вероятность обычно очень мала, менее 1% (рис 5).
1011001100 101101 -> 1011001101 101101Рис 5. МутацияМожно выбирать некоторое количество точек в хромосоме для инверсии, причем их число также может быть случайным. Также можно инвертировать сразу некоторую группу подряд идущих точек.[17]
Такой процесс эволюции, вообще говоря, может продолжаться до бесконечности, пока не будет выполнен критерий остановки алгоритма. Таким критерием может быть:
1. нахождение глобального, либо субоптимального решения;
2. исчерпание числа поколений, отпущенных на эволюцию;
3. исчерпание времени, отпущенного на эволюцию. Генетические алгоритмы служат, главным образом, для поиска решений в очень больших, сложных пространствах поиска.[18]
2 . Преимущества и недостатки ГА
2.1 Преимущества
Эксперименты, описанные в литературе, показывают, что генетические алгоритмы очень эффективны в поиске глобальных минимумов адаптивных рельефов, так как в них исследуются большие области допустимых значений параметров нейронных сетей. (Градиентные алгоритмы дают возможность находить только локальные минимумы.) Другая причина того, что генетические алгоритмы не застревают в локальных минимумах — случайные мутации, которые аналогичны температурным флуктуациям метода имитации отжига.
В литературе есть указания на достаточно высокую скорость обучения при использовании генетических алгоритмов. Хотя скорость сходимости градиентных алгоритмов в среднем выше, чем генетических алгоритмов.
Генетические алгоритмы дают возможность оперировать дискретными значениями параметров нейронных сетей. Это упрощает разработку цифровых аппаратных реализаций нейронных сетей. При обучении на компьютере нейронных сетей, не ориентированных на аппаратную реализацию, возможность использования дискретных значений параметров в некоторых случаях может приводить к сокращению общего времени обучения.[19]
2.2 Недостатки
Генетические алгоритмы обучения сложны для понимания и программной реализации. Есть такие случаи, где не только не желательно, но и проблематично использовать ГА: в случае когда необходимо найти точный глобальный оптимум; время исполнения функции оценки велико; необходимо найти все решения задачи, а не одно из них; конфигурация является не простой (кодирование решения); поверхность ответа имеет слабоизменяющийся рельеф.[20]
3. Некоторые модели генетических алгоритмов
3.1 Canonical GA ( J . Holland )
Данная модель алгоритма является классической. Она была предложена Джоном Холландом в его знаменитой работе "Адаптация в природных и исусственных средах" (1975). Часто можно встретить описание простого ГА (Simple GA, D. Goldberg), он отличается от канонического тем, что использует либо рулеточный, либо турнирный отбор. Модель канонического ГА имеет следующие характеристики:
- Фиксированный размер популяции.
- Фиксированная разрядность генов.
- Пропорциональный отбор.
- Особи для скрещивания выбираются случайным образом.
- Одноточечный кроссовер и одноточечная мутация.
- Следующее поколение формируется из потомков текущего поколения без "элитизма". Потомки занимают места своих родителей. [21]
3 . 2 Genitor (D. Whitley)
В данной модели используется специфичная стратегия отбора. Вначале, как и полагается, популяция инициализируется, и её особи оцениваются. Затем выбираются случайным образом две особи, скрещиваются, причем получается только один потомок, который оценивается и занимает место наименее приспособленной особи. После этого снова случайным образом выбираются 2 особи, и их потомок занимает место особи с самой низкой приспособленностью. Таким образом, на каждом шаге в популяции обновляется только одна особь. Подводя итоги можно выделить следующие характерные особенности:
- Фиксированный размер популяции.
- Фиксированная разрядность генов.
- Особи для скрещивания выбираются случайным образом.
- Ограничений на тип кроссовера и мутации нет.
- В результате скрещивания особей получается один потомок, который занимает место наименее приспособленной особи.[22]
3.3 Hybrid algorithm (L. "Dave" Davis)
Использование гибридного алгоритма позволяет объединить преимущества ГА с преимуществами классических методов. Дело в том, что ГА являются робастными алгоритмами, т.е. они позволяют находить хорошее решение, но нахождение оптимального решения зачастую оказывается намного более трудной задачей в силу стохастичности принципов работы алгоритма. Поэтому возникла идея использовать ГА на начальном этапе для эффективного сужения пространства поиска вокруг глобального экстремума, а затем, взяв лучшую особь, применить один из "классических" методов оптимизации. Характеристики алгоритма:
- Фиксированный размер популяции.
- Фиксированная разрядность генов.
- Любые комбинации стратегий отбора и формирования следующего поколения
- Ограничений на тип кроссовера и мутации нет.
- ГА применяется на начальном этапе, а затем в работу включается классический метод оптимизации.[23]
3.4 Island Model GA
Представим себе следующую ситуацию. В некотором океане есть группа близкорасположенных островов, на которых живут популяции особей одного вида. Эти популяции развиваются независимо, и только изредка происходит обмен представителями между популяциями. Островная модель ГА использует описанный принцип для поиска решения. Вариант, безусловно, интересный и является одной из разновидностей параллельных ГА. Данная модель генетического алгоритма обладает следующими свойствами:
- Наличие нескольких популяций, как правило, одинакового фиксированного размера.
- Фиксированная разрядность генов.
- Любые комбинации стратегий отбора и формирования следующего поколения в каждой популяции. Можно сделать так, что в разных популяциях будут использоваться разные комбинации стратегий, хотя даже один вариант дает разнообразные решения на различных "островах".
- Ограничений на тип кроссовера и мутации нет.
- Случайный обмен особями между "островами". Если миграция будет слишком активной, то особенности островной модели будут сглажены, и она будет не очень сильно отличаться от моделей ГА без параллелизма.[24]
3 . 5 CHC (Eshelman)
CHC расшифровываетсякак Cross-population selection, Heterogenous recombination and Cataclysmic mutation. Данный алгоритм довольно быстро сходится из-за того, что в нем нет мутаций, используются популяции небольшого размера, и отбор особей в следующее поколение ведется и между родительскими особями, и между их потомками. В силу этого после нахождения некоторого решения алгоритм перезапускается, причем лучшая особь копируется в новую популяцию, а оставшиеся особи подвергаются сильной мутации (мутирует примерно треть битов в хромосоме) существующих и поиск повторяется. Еще одной специфичной чертой является стратегия скрещивания: все особи разбиваются на пары, причем скрещиваются только те пары, в которых хромосомы особей существенно различны (хэммингово расстояние больше некоторого порогового плюс возможны ограничения на минимальное расстояние между крайними различающимися битами). При скрещивании используется так называемый HUX-оператор (Half Uniform Crossover) - это разновидность однородного кроссовера, но в нем к каждому потомку попадает ровно половина битов хромосомы от каждого родителя. Таким образом, модель обладает следующими свойствами:
- Фиксированный размер популяции.
- Фиксированная разрядность генов.
- Перезапуск алгоритма после нахождения решения.
- Небольшая популяция.
- Особи для скрещивания разбиваются на пары и скрещиваются при условии существенных отличий.
- Отбор в следующее поколение проводится между родительскими особями и потомками.
- Используется половинный однородный кроссовер (HUX).
- Макромутация при перезапуске.[25]
II. Практическая часть реализации генетических алгоритмов
В данной учебно-исследовательской работе приведен пример программы использующей генетический алгоритм. Программа создана посредством среды программирования С++. Алгоритм компонента представляет собой применение методов, известных в теории эволюции, для эвристического поиска решений переборных задач.
1. Математическое обоснование принципа работы программы
Проверим эффективность работы генетических алгоритмов на примере нахождения значений коэффициентов неизвестных в Диофа́нтовом уравнении.
Диофа́нтово уравнение или уравнение в целых числах — это уравнение с целыми коэффициентами и неизвестными, которые могут принимать только целые значения. Названы в честь древнегреческого математика Диофанта.[26]
Рассмотрим диофантово уравнение: a+2b+3c+4d=30, где a, b, c и d - некоторые положительные целые. Применение ГА за очень короткое время находит искомое решение (a, b, c, d).
Архитектура ГА-систем позволяет найти решение быстрее за счет более 'осмысленного' перебора. Мы не перебираем все подряд, но приближаемся от случайно выбранных решений к лучшим.
Для начала выберем 5 случайных решений: 1 =< a,b,c,d =< 30. Вообще говоря, мы можем использовать меньшее ограничение для b,c,d, но для упрощения пусть будет 30.
| Хромосома | (a,b,c,d) |
| 1 | (1,28,15,3) |
| 2 | (14,9,2,4) |
| 3 | (13,5,7,3) |
| 4 | (23,8,16,19) |
| 5 | (9,13,5,2) |
Таблица 1 : 1-е поколение хромосом и их содержимое
Чтобы вычислить коэффициенты выживаемости (fitness), подставим каждое решение в выражение a+2b+3c+4d. Расстояние от полученного значения до 30 и будет нужным значением.
| Хромосома | Коэффициент выживаемости |
| 1 | |114-30|=84 |
| 2 | |54-30|=24 |
| 3 | |56-30|=26 |
| 4 | |163-30|=133 |
| 5 | |58-30|=28 |
Таблица 2 : Коэффициенты выживаемости первого поколения хромосом (набора решений)
Так как меньшие значения ближе к 30, то они более желательны. В нашем случае большие численные значения коэффициентов выживаемости подходят, увы, меньше. Чтобы создать систему, где хромосомы с более подходящими значениями имеют большие шансы оказаться родителями, мы должны вычислить, с какой вероятностью (в %) может быть выбрана каждая. Одно решение заключается в том, чтобы взять сумму обратных значений коэффициентов, и исходя из этого вычислять проценты. (Заметим, что все решения были сгенерированы Генератором Случайных Чисел - ГСЧ)
| Хромосома | Подходящесть |
| 1 | (1/84)/0.135266 = 8.80% |
| 2 | (1/24)/0.135266 = 30.8% |
| 3 | (1/26)/0.135266 = 28.4% |
| 4 | (1/133)/0.135266 = 5.56% |
| 5 | (1/28)/0.135266 = 26.4% |
Таблица 3 : Вероятность оказаться родителем
Для выбора 5-и пар родителей (каждая из которых будет иметь 1 потомка, всего - 5 новых решений), представим, что у нас есть 10000-стонняя игральная кость, на 880 сторонах отмечена хромосома 1, на 3080 - хромосома 2, на 2640 сторонах - хромосома 3, на 556 - хромосома 4 и на 2640 сторонах отмечена хромосома 5. Чтобы выбрать первую пару кидаем кость два раза и выбираем выпавшие хромосомы. Таким же образом выбирая остальных, получаем:
| Хромосома отца | Хромосома матери |
| 3 | 1 |
| 5 | 2 |
| 3 | 5 |
| 2 | 5 |
| 5 | 3 |
Таблица 4 : Симуляция выбора родителей
Каждый потомок содержит информацию о генах и отца и от матери. Вообще говоря, это можно обеспечить различными способами, однако в нашем случае можно использовать т.н. "кроссовер" (cross-over). Пусть мать содержит следующий набор решений: a1,b1,c1,d1, а отец - a2,b2,c2,d2, тогда возможно 6 различных кроссоверов (| = разделительная линия):
| Хромосома-отец | Хромосома-мать | Хромосома-потомок |
| a1 | b1 ,c1 ,d1 | a2 | b2 ,c2 ,d2 | a1 ,b2 ,c2 ,d2 or a2 ,b1 ,c1 ,d1 |
| a1 ,b1 | c1 ,d1 | a2 ,b2 | c2 ,d2 | a1 ,b1 ,c2 ,d2 or a2 ,b2 ,c1 ,d1 |
| a1 ,b1 ,c1 | d1 | a2 ,b2 ,c2 | d2 | a1 ,b1 ,c1 ,d2 or a2 ,b2 ,c2 ,d1 |
Таблица 5 : Кроссоверы между родителями
Есть достаточно много путей передачи информации потомку, и кроссовер - только один из них. Расположение разделителя может быть абсолютно произвольным, как и то, отец или мать будут слева от черты.
А теперь попробуем проделать это с нашими потомками
| Хромосома-отец | Хромосома-мать | Хромосома-потомок |
| (13 | 5,7,3) | (1 | 28,15,3) | (13,28,15,3) |
| (9,13 | 5,2) | (14,9 | 2,4) | (9,13,2,4) |
| (13,5,7 | 3) | (9,13,5 | 2) | (13,5,7,2) |
| (14 | 9,2,4) | (9 | 13,5,2) | (14,13,5,2) |
| (13,5 | 7, 3) | (9,13 | 5, 2) | (13,5,5,2) |
Таблица 6 : Симуляция кросс-оверов хромосом родителей
Теперь мы можем вычислить коэффициенты выживаемости (fitness) потомков.
| Хромосома-потомок | Коэффициент выживаемости |
| (13,28,15,3) | |126-30|=96 |
| (9,13,2,4) | |57-30|=27 |
| (13,5,7,2) | |57-30|=22 |
| (14,13,5,2) | |63-30|=33 |
| (13,5,5,2) | |46-30|=16 |
Таблица 7 : Коэффициенты выживаемости потомков (fitness)
Средняя приспособленность (fitness) потомков оказалась 38.8, в то время как у родителей этот коэффициент равнялся 59.4. Следующее поколение может мутировать. Например, мы можем заменить одно из значений какой-нибудь хромосомы на случайное целое от 1 до 30.
Продолжая таким образом, одна хромосома в конце концов достигнет коэффициента выживаемости 0, то есть станет решением.
Системы с большей популяцией (например, 50 вместо 5-и сходятся к желаемому уровню (0) более быстро и стабильно.[27]
1. 1 Принцип работы программы
Oбранимся к теоретическим пояснениям в практической реализации данной задачи в среде программирования С++ :
Первым делом посмотрим на заголовок класса:
#include <stdlib.h>
#include <time.h>
#define MAXPOP 25
struct gene {
int alleles[4];
int fitness;
float likelihood;
// Test for equality.
operator==(gene gn) {
for (int i=0;i<4;i++) {
if (gn.alleles[i] != alleles[i]) return false;
}
return true;
}
};
class CDiophantine {
public:
CDiophantine(int, int, int, int, int);
int Solve();
// Returns a given gene.
gene GetGene(int i) { return population[i];}
protected:
int ca,cb,cc,cd;
int result;
gene population[MAXPOP];
int Fitness(gene &);
void GenerateLikelihoods();
float MultInv();inverse.
int CreateFitnesses();
void CreateNewPopulation();
int GetIndex(float val);
gene Breed(int p1, int p2);
};
Существуют две структуры: gene и класс CDiophantine. gene используется для слежения за различными наборами решений. Создаваямая популяция - популяция ген. Эта генетическая структура отслеживает свои коэффициенты выживаемости и вероятность оказаться родителем. Также есть небольшая функция проверки на равенство.
Теперь по функциям:
Fitness function
Вычисляет коэффициент выживаемости (приспособленности - fitness) каждого гена. В нашем случае это - модуль разности между желаемым результатом и полученным значением. Этот класс использует две функции: первая вычисляет все коэффициенты, а вторая – поменьше - вычисляет коэффициент для какого-то одного гена.
int CDiophantine::Fitness(gene &gn) {
int total = ca * gn.alleles[0] + cb * gn.alleles[1]
+ cc * gn.alleles[2] + cd * gn.alleles[3];
return gn.fitness = abs(total - result);
}
int CDiophantine::CreateFitnesses() {
float avgfit = 0;
int fitness = 0;
for(int i=0;i<MAXPOP;i++) {
fitness = Fitness(population[i]);
avgfit += fitness;
if (fitness == 0) {
return i;
}
}
return 0;
}
Заметим, что если fitness = 0, то найдено решение - возврат. После вычисления приспособленности (fitness) нам нужно вычислить вероятность выбора этого гена в качестве родительского.
Likelihood functions
Как и было объяснено, вероятность вычисляется как сумма обращенных коэффициентов, деленная на величину, обратную к коэффициенту данному значению. Вероятности кумулятивны (складываются), что делает очень легким вычисления с родителями. Например:
| Хромосома | Вероятность |
| 1 | (1/84)/0.135266 = 8.80% |
| 2 | (1/24)/0.135266 = 30.8% |
| 3 | (1/26)/0.135266 = 28.4% |
| 4 | (1/133)/0.135266 = 5.56% |
| 5 | (1/28)/0.135266 = 26.4% |
В программе, при одинаковых начальных значениях, вероятности сложатся: представьте их в виде кусков пирога. Первый ген - от 0 до 8.80%, следующий идет до 39.6% (так как он начинает 8.8). Таблица вероятностей будет выглядеть приблизительно так:
| Хромосома | Вероятность (smi = 0.135266) |
| 1 | (1/84)/smi = 8.80% |
| 2 | (1/24)/smi = 39.6% (30.6+8.8) |
| 3 | (1/26)/smi = 68% (28.4+39.6) |
| 4 | (1/133)/smi = 73.56% (5.56+68) |
| 5 | (1/28)/smi = 99.96% (26.4+73.56) |
Последнее значение всегда будет 100. Имея в нашем арсенале теорию, посмотрим на код. Он очень прост: преобразование к float необходимо для того, чтобы избегать целочисленного деления. Есть две функции: одна вычисляет smi, а другая генерирует вероятности оказаться родителем.
float CDiophantine::MultInv() {
float sum = 0;
for(int i=0;i<MAXPOP;i++) {
sum += 1/((float)population[i].fitness);
}
return sum;
}
void CDiophantine::GenerateLikelihoods() {
float multinv = MultInv();
float last = 0;
for(int i=0;i<MAXPOP;i++) {
population[i].likelihood = last
= last + ((1/((float)population[i].fitness) / multinv) * 100);
}
}
Итак, у нас есть и коэффициенты выживаемости (fitness) и необходимые вероятности (likelihood). Можно переходить к размножению (breeding).
Breeding Functions
Функции размножения состоят из трех: получить индекс гена, отвечающего случайному числу от 1 до 100, непосредственно вычислить кроссовер двух генов и главной функции генерации нового поколения. Рассмотрим все эти функции одновременно и то, как они друг друга вызывают. Вот главная функция размножения:
void CDiophantine::CreateNewPopulation() {
gene temppop[MAXPOP];
for(int i=0;i<MAXPOP;i++) {
int parent1 = 0, parent2 = 0, iterations = 0;
while(parent1 == parent2 || population[parent1]
== population[parent2]) {
parent1 = GetIndex((float)(rand() % 101));
parent2 = GetIndex((float)(rand() % 101));
if (++iterations > (MAXPOP * MAXPOP)) break;
}
temppop[i] = Breed(parent1, parent2); // Create a child.
}
for(i=0;i<MAXPOP;i++) population[i] = temppop[i];
}
Итак, первым делом мы создаем случайную популяцию генов. Затем делаем цикл по всем генам. Выбирая гены, мы не хотим, чтобы они оказались одинаковы (ни к чему скрещиваться с самим собой, и вообще - нам не нужны одинаковые гены (operator = в gene). При выборе родителя, генерируем случайное число, а затем вызываем GetIndex. GetIndex использует идею кумулятивности вероятностей (likelihoods), она просто делает итерации по всем генам, пока не найден ген, содержащий число:
int CDiophantine::GetIndex(float val) {
float last = 0;
for(int i=0;i<MAXPOP;i++) {
if (last <= val && val <= population[i].likelihood) return i;
else last = population[i].likelihood;
}
return 4;
}
Возвращаясь к функции CreateNewPopulation(): если число итераций превосходит MAXPOP2, она выберет любых родителей. После того, как родители выбраны, они скрещиваются: их индексы передаются вверх на функцию размножения (Breed). Breed function возвращает ген, который помещается во временную популяцию. Вот код:
gene CDiophantine::Breed(int p1, int p2) {
int crossover = rand() % 3+1;
int first = rand() % 100;
gene child = population[p1];
int initial = 0, final = 3;
if (first < 50) initial = crossover;
else final = crossover+1;
for(int i=initial;i<final;i++) {
child.alleles[i] = population[p2].alleles[i];
if (rand() % 101 < 5) child.alleles[i] = rand() % (result + 1);
}
return child;
}
В конце концов мы определим точку кроссовера. Заметим, что мы не хотим, чтобы кроссовер состоял из копирования только одного родителя. Сгенерируем случайное число, которое определит наш кроссовер. Остальное понятно и очевидно. Добавлена маленькая мутация, влияющая на скрещивание. 5% - вероятность появления нового числа.
Теперь уже можно взглянуть на функцию Solve(),которая возвратит аллель, содержащую решение. Она всего лишь итеративно вызывает вышеописанные функции. Заметим, что мы присутствует проверка: удалось ли функции получить результат, используя начальную популяцию. Это маловероятно, однако лучше проверить.
int CDiophantine::Solve() {
int fitness = -1;
// Generate initial population.
srand((unsigned)time(NULL));
for(int i=0;i<MAXPOP;i++) {
for (int j=0;j<4;j++) {
population[i].alleles[j] = rand() % (result + 1);
}
}
if (fitness = CreateFitnesses()) {
return fitness;
}
int iterations = 0;
while (fitness != 0 || iterations < 50) {
GenerateLikelihoods();
CreateNewPopulation();
if (fitness = CreateFitnesses()) {
return fitness;
}
iterations++;
}
return -1;
}
Описаниезавершено.
2. Листинг программы
#include <stdlib.h>
#include <time.h>
#include <iostream.h>
#define MAXPOP 25
struct gene {
int alleles[4];
int fitness;
float likelihood;
// Test for equality.
operator==(gene gn) {
for (int i=0;i<4;i++) {
if (gn.alleles[i] != alleles[i] }
return false;
}
return true;
}
};
class CDiophantine {
public:
CDiophantine(int, int, int, int, int); // Constructor with coefficients for a,b,c,d.
int Solve(); // Solve the equation.
// Returns a given gene.
gene GetGene(int i) { return population[i];}
protected:
int ca,cb,cc,cd; // The coefficients.
int result;
gene population[MAXPOP]; // Population.
int Fitness(gene &); // Fitness function.
void GenerateLikelihoods(); // Generate likelihoods.
float MultInv(); // Creates the multiplicative inverse.
int CreateFitnesses();
void CreateNewPopulation();
int GetIndex(float val);
gene Breed(int p1, int p2);
};
CDiophantine::CDiophantine(int a, int b, int c, int d, int res) : ca(a), cb(b), cc(c), cd(d), result(res) {}
int CDiophantine::Solve() {
int fitness = -1;
// Generate initial population.
srand((unsigned)time(NULL));
for(int i=0;i<MAXPOP;i++) { // Fill the population with numbers between
for (int j=0;j<4;j++) { // 0 and the result.
population[i].alleles[j] = rand() % (result + 1);
}
}
if (fitness = CreateFitnesses()) {
return fitness;
}
int iterations = 0; // Keep record of the iterations.
while (fitness != 0 || iterations < 50) {// Repeat until solution found, or over 50 iterations.
GenerateLikelihoods(); // Create the likelihoods.
CreateNewPopulation();
if (fitness = CreateFitnesses()) {
return fitness;
}
iterations++;
}
return -1;
}
int CDiophantine::Fitness(gene &gn) {
int total = ca * gn.alleles[0] + cb * gn.alleles[1] + cc * gn.alleles[2] + cd * gn.alleles[3];
return gn.fitness = abs(total - result);
}
int CDiophantine::CreateFitnesses() {
float avgfit = 0;
int fitness = 0;
for(int i=0;i<MAXPOP;i++) {
fitness = Fitness(population[i]);
avgfit += fitness;
if (fitness == 0) {
return i;
}
}
return 0;
}
float CDiophantine::MultInv() {
float sum = 0;
for(int i=0;i<MAXPOP;i++) {
sum += 1/((float)population[i].fitness);
}
return sum;
}
void CDiophantine::GenerateLikelihoods() {
float multinv = MultInv();
float last = 0;
for(int i=0;i<MAXPOP;i++) {
population[i].likelihood = last = last + ((1/((float)population[i].fitness) / multinv) * 100);
}
}
int CDiophantine::GetIndex(float val) {
float last = 0;
for(int i=0;i<MAXPOP;i++) {
if (last <= val && val <= population[i].likelihood) return i;
else last = population[i].likelihood;
}
return 4;
}
gene CDiophantine::Breed(int p1, int p2) {
int crossover = rand() % 3+1; // Create the crossover point (not first).
int first = rand() % 100; // Which parent comes first?
gene child = population[p1]; // Child is all first parent initially.
int initial = 0, final = 3; // The crossover boundaries.
if (first < 50) initial = crossover; // If first parent first. start from crossover.
else final = crossover+1; // Else end at crossover.
for(int i=initial;i<final;i++) { // Crossover!
child.alleles[i] = population[p2].alleles[i];
if (rand() % 101 < 5) child.alleles[i] = rand() % (result + 1);
}
return child; // Return the kid...
}
void CDiophantine::CreateNewPopulation() {
gene temppop[MAXPOP];
for(int i=0;i<MAXPOP;i++) {
int parent1 = 0, parent2 = 0, iterations = 0;
while(parent1 == parent2 || population[parent1] == population[parent2]) {
parent1 = GetIndex((float)(rand() % 101));
parent2 = GetIndex((float)(rand() % 101));
if (++iterations > 25) break;
}
temppop[i] = Breed(parent1, parent2); // Create a child.
}
for(i=0;i<MAXPOP;i++) population[i] = temppop[i];
}
void main() {
CDiophantine dp(1,2,3,4,30);
int ans;
ans = dp.Solve();
if (ans == -1) {
cout << "No solution found." << endl;
} else {
gene gn = dp.GetGene(ans);
cout << "The solution set to a+2b+3c+4d=30 is:\n";
cout << "a = " << gn.alleles[0] << "." << endl;
cout << "b = " << gn.alleles[1] << "." << endl;
cout << "c = " << gn.alleles[2] << "." << endl;
cout << "d = " << gn.alleles[3] << "." << endl;
}
}
Заключение
Мы с вами проделали большой путь, открывая для себя генетические алгоритмы, их, казалось бы, тривиальную и одновременно с этим гениальную идею, взятую из природы. По окончанию работы можно сделать выводы о том, что: во-первых, генетические алгоритмы являются универсальным методом оптимизации многопараметрических функций, что позволяет решать широкий спектр задач; во-вторых, они имеют множество модификаций и сильно зависят от параметров. Зачастую небольшое изменение одного из них может привести к неожиданному улучшению результата. Но следует помнить, что применение ГА полезно лишь в тех случаях, когда для данной задачи нет подходящего специального алгоритма решения.
Несмотря на небольшое количество задач в данной научно-исследовательской работе, которое мы с вами рассмотрели: решение Диофантова уравнения и задачу коммивояжера, мы полностью подтверждаем гипотезу. Задачи оптимизации успешно решаются при помощи генетических алгоритмов.
Список используемой литературы
1. http://www.basegroup.ru/download/genebase.htm
2. http://www.basegroup.ru/genetic/math.htm
3. http://saisa.chat.ru/ga.html
4. http://algolist.manual.ru/ai/ga/ga1.php
5. http://www.ai.tsi.lv/ru/ga/ga_intro.html
6. http://port33.ru/users/acp/articles/Genetic_algorithms/index.html
7. http://paklin.newmail.ru/mater/gene_net.html
8. http://www.iki.rssi.ru/ehips/genetic.htm
9. http://fdmhi.mega.ru/ru/senn_ga.htm
10. http://www.vspu.ru/public_html/cterra/20.html
11. http://www.chat.ru/~saisa
12. http://www.xakep.ru/post/18589/default.asp
13. http://g-u-t.chat.ru/ga/oper.htm
14. http://iissvit.narod.ru/rass/vip4.htm
15. http://www.nestor.minsk.by/kg/index.html
16. http://algo.ekaboka.com/algo-rus/index.htm
17. http://www.neuroproject.ru
18. http://math.nsc.ru/AP/benchmarks/UFLP/uflp_ga.html
19. http://www.interface.ru/home.asp?artId=8109
20. http://algolist.ru/ai/ga/dioph.php
21. http://ru.wikipedia.org/wiki/Диофантово_уравнение
[1] http://paklin.newmail.ru/mater/gene_net.html
[2] http://www.ai.tsi.lv/ru/ga/ga_intro.html
[3] http://iissvit.narod.ru/rass/vip4.htm
[4] http://algo.ekaboka.com/algo-rus/index.htm
[5] http://www.neuroproject.ru
[6] http://www.interface.ru/home.asp?artId=8109
[7] http://math.nsc.ru/AP/benchmarks/UFLP/uflp_ga.html
[8] http://www.basegroup.ru/genetic/math.htm
[9] http://www.basegroup.ru/download/genebase.htm
[10] http://www.nestor.minsk.by/kg/index.html
[11] http://www.iki.rssi.ru/ehips/genetic.htm
[12] http://fdmhi.mega.ru/ru/senn_ga.htm
[13] http://chat.ru/ga.html
[14] http://www.chat.ru/~saia
[15] http://www.xakep.ru/post/18589/default.asp
[16] http://port33.ru/users/acp/articles/Genetic_algorithms/index.html
[17] http://paklin.newmail.ru/mater/gene_net.html
[18] http://www.vspu.ru/public_html/cterra/20.html
[19] http://algolist.manual.ru/ai/ga/ga1.php
[20] http://cmc.cs.msu.su/labs/lvk/materials/tez_sapr99_1.html
[21] http://algo.ekaboka.com/algo-rus/index.htm
[22] http://algolist.ru/ai/ga/dioph.php
[23] http://g-u-t.chat.ru/ga/oper.htm
[24] http://g-u-t.chat.ru/ga/oper.htm
[25] http://chat.ru/ga.html
[26] http://ru.wikipedia.org/wiki/Диофантово_уравнение
[27] http://algolist.ru/ai/ga/dioph.php