| Скачать .docx |
Курсовая работа: Интерфейсы экспертных систем
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ
ФЕДЕРАЛЬНОЕ АГЕНТСТВО ПО ОБРАЗОВАНИЮ
Курсовая работа
по дисциплине «ИНТЕЛЛЕКТУАЛЬНЫЕ СИСТЕМЫ »
на тему: «Интерфейсы экспертных систем»
Целью индивидуальной работы является рассмотрение интерфейсов экспертных систем.
На основании изученных литературных источников, была разработана следующая структура презентации:
- Во первых рассмотрены понятие экспертной системы, требования предъявляемые к ним, области применения, важность применения ЭС, и структура ЭС (кратко описаны основные блоки, входящие в состав ЭС)
- Во вторых рассмотрена модель гибкого интерфейса в ЭС: определение гибкого интерфейса, требования, структура (построение модели диалога для ввода данных и модель объяснения результатов ЭС)
- В третьих была рассмотрен экспертные системы нового поколения, а именно описаны: определение, отличительные особенности в построении, основные преимущества предлагаемого подхода, а также рассмотрен интерфейс экспертной системы нового поколения
1. Экспертные системы. Требования и особенности экспертных систем
Экспертная система – это интеллектуальная программа, способная делать логические выводы на основании знаний в конкретной предметной области и обеспечивающая решение специфических задач. Для этого ее необходимо наделить функциями, позволяющими решать задачи, которые в отсутствие эксперта (специалиста в данной конкретной предметной области) невозможно правильно решить. Поэтому необходимым этапом в ее разработке является приобретение соответствующих знаний от эксперта.
К экспертным системам предъявляются следующие требования:
- Использование знаний, связанных с конкретной предметной областью;
- Приобретение знаний от эксперта;
- Определение реальной и достаточно сложной задачи;
- Наделение системы способностями эксперта.
Знания о предметной области, необходимые для работы ЭС, определенным образом формализованы и представлены в памяти ЭВМ в виде базы знаний, которая может изменяться и дополняться в процессе развития системы. Главное достоинство ЭС – возможность накапливать знания, сохранять их длительное время, обновлять и тем самым обеспечивать относительную независимость конкретной организации от наличия в ней квалифицированных специалистов. Накопление знаний позволяет повышать квалификацию специалистов, работающих на предприятии, используя наилучшие, проверенные решения. [1]
Важность экспертных систем состоит в следующем :
- технология экспертных систем существенно расширяет круг практически значимых задач, решаемых на компьютерах, решение которых приносит значительный экономический эффект;
- технология ЭС является важнейшим средством в решении глобальных проблем традиционного программирования: длительность и, следовательно, высокая стоимость разработки сложных приложений;
- высокая стоимость сопровождения сложных систем, которая часто в несколько раз превосходит стоимость их разработки; низкий уровень повторной используемости программ и т.п.;
- объединение технологии ЭС с технологией традиционного программирования добавляет новые качества к программным продуктам за счет: обеспечения динамичной модификации приложений пользователем, а не программистом; большей «прозрачности» приложения (например, знания хранятся на ограниченном ЕЯ, что не требует комментариев к знаниям, упрощает обучение и сопровождение); лучшей графики; интерфейса и взаимодействия.
По мнению ведущих специалистов, в недалекой перспективе ЭС найдут следующее применение:
- ЭС будут играть ведущую роль во всех фазах проектирования, разработки, производства, распределения, продажи, поддержки и оказания услуг;
- технология ЭС, получившая коммерческое распространение, обеспечит революционный прорыв в интеграции приложений из готовых интеллектуально-взаимодействующих модулей. [2]
Области применения экспертных систем:
а) Медицинская диагностика.
б) Прогнозирование.
в) Планирование.
г) Интерпретация.
д) Контроль и управление.
е) Диагностика неисправностей в механических и электрических устройствах.
ж) Обучение.
Большинство ЭС включают знания, по содержанию которых их можно отнести одновременно к нескольким типам. Например, обучающая система может также обладать знаниями, позволяющими выполнять диагностику и планирование. Она определяет способности обучаемого по основным направлениям курса, а затем с учетом полученных данных составляет учебный план. Управляющая система может применяться для целей контроля, диагностики, прогнозирования и планирования. Система, обеспечивающая сохранность жилища, может следить за окружающей обстановкой, распознавать происходящие события (например, открылось окно), выдавать прогноз (вор-взломщик намеревается проникнуть в дом) и составлять план действий (вызвать полицию). [3]
2. Структура экспертной системы
Структура экспертной системы представлена следующими структурными элементами:
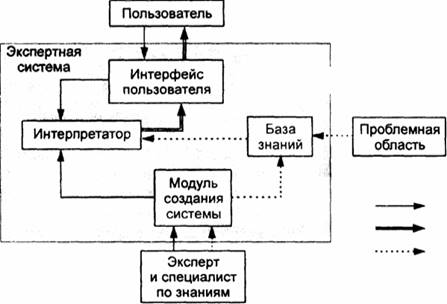
База знаний
Она содержит факты, описывающие проблемную область, а также логическую взаимосвязь этих фактов. Центральное место в базе знаний принадлежит правилам.
Правило определяет, что следует делать в данной конкретной ситуации, и состоит из двух частей: условия, которое может выполняться или нет, и действия, которое следует произвести, если условие выполняется.
Все используемые в экспертной системе правила образуют систему правил, которая даже для сравнительно простой системы может содержать несколько тысяч правил.
Все виды знаний в зависимости от специфики предметной области и квалификации проектировщика (инженера по знаниям) с той или иной степенью адекватности могут быть представлены с помощью одной либо нескольких семантических моделей.
Интерпретатор
Это часть экспертной системы, производящая в определенном порядке обработку знаний (мышление), находящихся в базе знаний. Технология работы интерпретатора сводится к последовательному рассмотрению совокупности правил (правило за правилом). Если условие, содержащееся в правиле, соблюдается, выполняется определенное действие, и пользователю предоставляется вариант решения его проблемы.
Модуль создания системы
Он служит для создания набора (иерархии) правил. Существуют два подхода, которые могут быть положены в основу модуля создания системы: использование алгоритмических языков программирования и использование оболочек экспертных систем.
Для представления базы знаний специально разработаны языки Лисп и Пролог, хотя можно использовать и любой известный алгоритмический язык.
Оболочка экспертных систем представляет собой готовую программную среду, которая может быть приспособлена к решению определенной проблемы путем создания соответствующей базы знаний. В большинстве случаев использование оболочек позволяет создавать экспертные системы быстрее и легче в сравнении с программированием.
Интерфейс пользователя
Менеджер (специалист) использует интерфейс для ввода информации и команд в экспертную систему и получения выходной информации из нее. Команды включают в себя параметры, направляющие процесс обработки знаний. Информация обычно выдается в форме значений, присваиваемых определенным переменным.
Менеджер может использовать четыре метода ввода информации: меню, команды, естественный язык и собственный интерфейс.
Технология экспертных систем предусматривает возможность получать в качестве выходной информации не только решение, но и необходимые объяснения. Различают два вида объяснений:
- объяснения, выдаваемые по запросам. Пользователь в любой момент может потребовать от экспертной системы объяснения своих действий;
- объяснения полученного решения проблемы. После получения решения пользователь может потребовать объяснений того, как оно было получено. Система должна пояснить каждый шаг своих рассуждений, ведущих к решению задачи.
Хотя технология работы с экспертной системой не является простой, пользовательский интерфейс этих систем является дружественным и обычно не вызывает трудностей при ведении диалога.
Кроме того, во многих экспертных системах вводятся дополнительные блоки: база данных, блок расчета, блок ввода и корректировки данных. Блок расчета необходим в ситуациях, связанных с принятием управленческих решений. При этом важную роль играет база данных, где содержатся плановые, физические, расчетные, отчетные и другие постоянные или оперативные показатели. Блок ввода и корректировки данных используется для оперативного и своевременного отражения текущих изменений в базе данных. [4]
3. Модель гибкого интерфейса в экспертных системах
В данной работе под интерфейсом понимается ввод исходных данных задачи и объяснение результатов работы ЭС. Гибким будем называть интерфейс, который, обеспечивая дружественное взаимодействие с пользователем ЭС, позволяет на этапе проектирования и эксплуатации ЭС учитывать, с одной стороны, изменяющиеся потребности пользователя, а с другой, изменение знаний о предметной области.
Сформулируем требования к разработке интерфейса.
Интерфейс должен обеспечивать «удобный ввод» данных в ЭС. Под «удобным вводом» подразумевается предоставление пользователю возможности выбора варианта данных, относящихся к выполняемой задаче, простых запросов об объектах и их характеристиках, если их набор конечен, либо возможности введения необходимой информации с предоставлением синтаксической формы для этой информации. Это требование вытекает из того, что основной интерес пользователя лежит в прикладной части системы, он является непрофессионалом в области использования программных систем, не имеет необходимого опыта работы с ними.
Сочетание инициативы пользователя и ЭС в управлении диалогом по вводу данных. Большинство ЭС поддерживают машино-управляемый диалог, в котором ЭС управляет диалогом. Такой диалог имеет много ограничений. Поэтому более предпочтительно сочетание инициативы пользователя и ЭС в диалоге для ввода исходных данных. В этом случае ЭС должна предоставлять пользователю информацию о структуре и вариантах вводимых данных на основе которой пользователь может инициировать диалог, удовлетворяющий целям этого пользователя.
ЭС должна обеспечивать доступ к введенным данным и возможность их редактирования. В процессе работы с ЭС может возникнуть необходимость изменения введенных данных, либо ввода дополнительных данных; пользователь также может совершать ошибки при вводе данных, которые требуют исправления. Поэтому пользователю необходимо дать возможность просматривать введенные данные, возвращаться назад к предыдущим состояниям его диалога всякий раз, когда он сделал ошибку или хочет что-либо изменить в этих состояниях.
Обеспечение легкой модифицируемости интерфейса. При проектировании интерфейса необходимо учитывать, что не только на этапе разработки, но также и в процессе эксплуатации знания о предметной области, и, как следствие, знания об исходных данных могут изменяться. А это ведет к необходимости частой модификации интерфейса. «Легкая модифицируемость» интерфейса – понятие относящееся к так называемым «нечетким понятиям»: его невозможно точно определить или выразить количественно, но совершенно очевидно, что если модифицирование интерфейса требует внесение изменений в базу знаний или машину логического вывода, то его модифицирование представляет собой значительные трудности. Поэтому под «легкой модифицируемостью» интерфейса будем понимать модифицируемость интерфейса, не затрагивающую при этом «ядро» ЭС – базу знаний и машину логического вывода, а также внесение изменений в интерфейс, не требующих при этом модификации программ системы.
5. Объяснение в ЭС должно строиться в соответствии с потребностями пользователя. Интерфейс в ЭС должен иметь средства для построения объяснений, настраиваемых на конкретного пользователя в зависимости от его требований относительно содержания объяснения и в зависимости от этих требований формировать более или менее детальные объяснения, краткую или развернутую форму объяснения и т.д.
6. Обеспечение пользователя неинтерактивным объяснением в виде структурированного текста , в которых имеются также средства создания таблиц, отчетов и т.д. Задачей практических ЭС является получение цели: конечному пользователю необходимо получить цель и понять действия системы. Более того, при практическом использовании ЭС часто необходим протокол работы ЭС – печатный документ, отражающий результаты работы ЭС и их объяснение. При этом важно, чтобы структура и содержание такого объяснения имели вид, общепринятый в данной предметной области.
На основе сформулированных требований построим модель диалога для ввода данных и модель объяснения результатов ЭС.
Под моделью интерфейса для ввода исходных данных в ЭС будем понимать пару, состоящую из порождающей модели и регламента действий пользователя. Порождающая модель [7,8] состоит из языка формального задания исчислений этой модели (языка для записи правил исчислений) и универсального рецепта этой модели.
Любое исчисление, заданное на языке порождающей модели, определяет множество порождающих процессов. В данном случае порождающими процессами является генерация исходных данных ЭС, их просмотр и редактирование.
Когда в ходе выполнения универсального рецепта порождающей модели возникает неоднозначность, регламент действий пользователя определяет его права по ее разрешению.
Определим язык формального задания правил исчисления порождающей модели интерфейса для ввода исходных данных как тройку <N, Ts, S>, где
N={n1 ,…, nm } – множество нетерминальных символов;
Ts=TÈF – терминальный словарь, состоящий из множества предопределенных терминальных символов T={t1 ,…, tk } и множества типов возможных значений F={cтрока , дата , время , координта, [l, t] I (единица измерения), [l, t] R (единица измерения) };
SÎN – выделенный символ языка (аксиома порождающей модели).
Каждое исчисление порождающей модели задается множеством записанных на этом языке порождающих правил Р вида a®b, где aÎN, а b имеет вид:
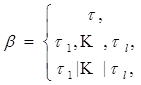
|
гдеtÎF гдеti ÎNÈT, l>1 гдеti ÎNÈT, l>1. |
При этом должны выполняться следующие условия:
– для любых a1 ,a2 ÎN, если правила a1 ®b, a2 ®b входят в P, то a1 ¹a2 ;
– для любого aÎN, если a встречается в правой части порождающего правила, то обязательно имеется правило вида a®b;
– в системе правил не существует таких правил, что aÞ*t и tÞ*a. Здесь aÞt означает, что в системе правил существует правило вида a®t1 |…|t|…|tn или правило вида a®t1 ,…,t,…,tn ; aÞ*t, если aÞm1 Þ…Þmn Þt.
Текущее состояние порождающего процесса есть пара, состоящая из дерева Di и активной вершины g в этом дереве. Корнем дерева является вершина, помеченная выделенным символом описания исходных данных S, вершины помечены нетерминальными символами языка N. Листьями этого дерева или терминальными вершинами могут быть вершины, помеченные нетерминальными символами языка N, предопределенными терминальными символами языка из множества Т и порождениями символов из множества F.
Просмотр дерева исходных данных может быть двух видов: просмотр вперед и просмотр назад (см. ниже), под редактированием понимается удаление вершины или множества вершин дерева исходных данных.
Применимое правило a®b в текущем состоянии зависит от способа его выполнения. Если способом выполнения правила является генерация, то правило a®b применимо в текущем состоянии, когда a совпадает с меткой активной вершины дерева g и является листом дерева. Если способом выполнения правила является редактирование, то правило a®b применимо в текущем состоянии, когда a совпадает с меткой активной вершины дерева g и не является листом дерева. В случае просмотра исходных данных применимое правило зависит от вида просмотра. Под просмотром вперед будем понимать переход от активной вершины к вершине – прямому потомку этой вершины в дереве исходных данных. Просмотр назад означает переход к вершине – прямому предку активной вершины. Если способом выполнения правила является просмотр вперед, метка активной вершины g есть aÎN, то правило вида a®b применимо в этом состоянии при следующих условиях.
1. bi = t1 ,…,tk , в дереве исходных данных есть множество ребер, соединяющих активную вершину g с допустимыми вершинами ni ,…,nj и среди вершин ni ,…,nj есть хотя бы одна вершина nn , имеющая метку tn ÎN.
2. bi = t1 |…|tk , в дереве исходных данных есть ребро, соединяющее активную вершину g с некоторой вершиной n с меткой ti Î{t1 ,…,tk } и ti ÎN.
Если способом выполнения правила является просмотр назад, a совпадает с меткой активной вершины дерева g и g не является корнем дерева исходных данных, то применимым является любое правило вида a‘ ®b, такое что либо b=a, либо b=t1 ., a,…,tk , либо b= t1 |…|a|…|tk , и в дереве исходных данных есть ребро, соединяющее вершину g‘ с меткой a‘ и активную вершину g с меткой a (все такие g‘ являются допустимыми вершинами в текущем состоянии).
Начальным состоянием q0 порождающего процесса является дерево, состоящее из одного корня – вершины, помеченной выделенным символом S, и активной вершины g, совпадающей с корнем этого дерева.
В результате применения некоторого правила формируется очередное состояние qi+1 на основе предыдущего состояния qi и примененного правила; qi+1 зависит также от способа выполнения правила – генерации, просмотра или редактирования.
Если способом выполнения правила является генерация, применимое правило имеет вид a®b, где bÎF, то в очередном состоянии порождающего процесса образуется дерево исходных данных Di+1 путем добавления к дереву Di ребра, связывающего вершину, помеченную символом a с новой вершиной n, имеющей в качестве метки порождение символа t. После этого a становится нетерминальной вершиной дерева Di+1 , а n – новой терминальной вершиной этого дерева, активной вершиной g становится вершина n с меткой t. При этом порождение значений в дереве исходных данных зависит от b. Так, если b=строка , то порождается конечная последовательность символов некоторого алфавита, если b=дата, то порождается значение типа дата и т.д.Если применяется правило a®b, где b=t1 ,…,tn , tк ÎNÈT для всех к=1,…, n, то дерево исходных данных Di+1 образуется путем добавления к дереву Di ребер, связывающих вершину с меткой a с любым непустым множеством вершин nf ,…, nj . Вершины nf ,…, nj имеют метки tf .,tj соответственно, причем {tf ,…,tj } Í {t1 ,…,tn }, где 1£f<j£n. После этого вершина с меткой a становится нетерминальной вершиной дерева Di+1 , nf ,…,nj – новыми терминальными вершинами дерева с метками tf .,tj , активной вершиной g становится вершина ns с меткой ts , f<=s<=j. Если среди правил языка выбрано правило a®b, где b=t1 |…|tn , tк ÎNÈT для всех к=1,…, n, то дерево исходных данных Di+1 образуется путем добавления к дереву Di ребра, связывающего вершину с меткой a с новой вершиной n, имеющей метку tj , при этом метка tj - некоторая метка из множества меток t1 ,…,tn , т.е. tj Î{t1 ,…,tn }, где 1<=i<=n. После этого вершина с меткой a становится нетерминальной вершиной дерева Di+1 , n – новой терминальной вершиной дерева с меткой tj , активной вершиной g становится вершина n с меткой tj .
Если видом просмотра является просмотр вперед, применимое правило имеет вид a®b, где b=t1 ,…,tk , то при применении этого правила активной вершиной очередного состояния становится такая вершина nn Î{ni ,…,nj }, что метка tn вершины nn является нетерминальным символом языка, т.е. tn ÎN. Если применимое правило имеет вид a®b, где b=t1 |…|tk , то при применении этого правила активной вершиной в очередном состоянии становится вершина n. Областью видимости в каждом состоянии при просмотре вперед являются активная вершина с меткой a и ее прямые потомки в дереве исходных данных. Если в качестве действия просмотра выбран просмотр назад, то при использовании применимого правила активной в следующем состоянии становится вершина g‘ с меткой a‘ . Областью видимости при просмотре назад являются активная вершина с меткой a и его прямые предки в дереве исходных данных.
Если способом выполнения правила является редактирование, метка активной вершины g есть aÎN, и применяемое правило имеет вид a®b, где b= t или bi = t1 |…|tk , то в этом случае под удалением будем понимать удаление вершины n, являющейся прямым потомком активной вершины g, ребра, соединяющего g и n, а также всего поддерева, корнем которого является n. Формирование очередного состояния процесса редактирования (удаления) происходит следующим образом: из дерева исходных данных удаляется поддерево с корнем n и ребро, соединяющее вершину n с предком этой вершины – вершиной g. В этом случае активная вершина g становится листом дерева. Если в текущем состоянии метка активной вершины g есть aÎN и применимое правило имеет вид a®b, где b= t1 ,…,tk ,то под удалением будем понимать удаление всех вершин nf ,…,nj , являющихся прямыми потомками активной вершины g. Формирование очередного состояния процесса редактирования происходит следующим образом: из дерева исходных данных удаляется множество всех поддеревьев, с корнями nf ,…,nj и множество ребер, соединяющих вершины nf ,…,nj с предком этих вершин – вершиной g. Активная вершина g становится листом дерева.
Порождающий процесс может быть завершен только в том случае, если он достиг терминального состояния.
В модели диалога пользователь может выбрать способ выполнения правила – генерацию, просмотр или редактирование.
Так, если способом выполнения правила является генерация исходных данных, то задача пользователя в диалоге состоит в разрешении всех неоднозначностей. Неоднозначности в процессе порождения исходных данных могут состоять в следующем.
1. Каждый шаг порождающего процесса характеризуется множеством применимых на данном шаге правил порождения очередного состояния, которое может содержать более одного применимого правила. Пользователь имеет возможность выбрать любое правило для получения очередного состояния процесса порождения среди множества применимых в данном состоянии правил.
2. Если в некотором состоянии применяется правило вида a®b, aÎN, где b=t1 |…|tn , причем tj ÎNÈTÈF, то в этом случае неоднозначно определяется посылка ti Î{t1 ,…,tn }, где 1<=i<=n. Пользователь в процессе порождения имеет возможность выбрать любую посылку в пределах указанных ограничений.
3. Если в некотором состоянии применяется правило вида a®b, aÎN, где b=t1 ,…,tn , причем tj ÎNÈTÈF, то в этом случае неоднозначно определяется посылка, являющаяся подмножеством {ti ,…,tj } Í {t1 ,…,tn }, где i<>j, 1<=i<=n, 1<=j<=n. Пользователь в процессе порождения имеет возможность выбрать любую посылку в пределах указанных ограничений, а также активную вершину.
4. Если в некотором состоянии применяется правило вида a®b, aÎN, bÎF, то пользователь в процессе порождения выбирает возможное значение, которое принадлежит типу b.
При просмотре исходных данных пользователь может проводить следующие действия.
1. Выбирать вид просмотра, т.е. определять в каком направлении просматривать дерево исходных данных. В зависимости от своих потребностей и условий применимости правил в данном состоянии пользователь может выбрать просмотр вперед или просмотр назад.
2. Определять в каком состоянии завершить просмотр исходных данных.
3. Разрешать неоднозначность процесса просмотра исходных данных. Неоднозначность процесса просмотра исходных данных состоит в том, что каждый шаг процесса просмотра характеризуется множеством вершин, допустимых в текущем состоянии в качестве активных в следующем состоянии. Данную неоднозначность порождающего процесса пользователь разрешает путем выбора активной вершины следующего состояния из множества вершин, допустимых в текущем состоянии.
Рассмотрим вторую составляющую интерфейса – объяснение результатов ЭС. Под моделью объяснения будем понимать вычислительную модель[7], универсальный рецепт которой на основе формального задания объяснения и результатов ЭС формирует текст объяснения.
Будем считать, что текст объяснения T состоит из последовательности элементов объяснения t1 ,…, tn , а результаты ЭС x представлены в виде конечной совокупности отношений, причем каждое отношение P – это конечное множество кортежей P = {<a1 ,…, an >}, где a1 ,…, an – элементы кортежей. Будем также считать, что формальное задание объяснения W – есть составной оператор. Под составным оператором будем понимать последовательность элементов описания объяснения w1 ,…, wn . Каждый элемент описания wi – текстовая конструкция, которая определяет содержание текста объяснения в зависимости от результатов работы ЭС. Текстовыми конструкциями в модели объяснения являются конструкции строка, выводимое множество, цикл и альтернатива. Конструкции цикл и альтернатива в свою очередь содержат составной оператор в качестве компоненты.
Каждой конструкция wi составного оператора может быть присвоен свой позиционный номер i. Позиционные номера определяют лексикографический порядок конструкций в формальном задании объяснения.
Cледует отметить, что, с одной стороны, одно и то же формальное задание объяснения W может соответствовать различным результатам ЭС – x, но с другой стороны, формальное задание W должно быть согласовано с результатами ЭС x. Текст объяснения T, создаваемый на основе W получается различным, в зависимости от x.
Рассмотрим текстовые конструкции формального задания объяснения и дадим их содержательную трактовку.
Текстовая конструкция строка – это последовательность символов заданного алфавита. Как правило, текст объяснения содержит фиксированные (не зависящие от результатов ЭС) фразы, принятые в данной предметной области. Это могут быть заголовки, пояснения каких-либо заключений ЭС, вводные фразы и др. Текстовая конструкция строка в формальном задании объяснения предназначена для представления таких фиксированных фраз. Примером таких текстовых конструкций могут быть: «Фамилия, имя, отчество», «диагноз при поступлении», «лечащий врач» и т.д.
Прежде, чем перейти к рассмотрению других конструкций языка, введем вспомогательную конструкцию описание переменной. Конструкция описание переменной необходима для того, чтобы задать имя переменной и связать его с именем отношения P из x и номером j его аргумента. Описание переменной имеет вид: P(c1 ,…, cj *, …, cn ), где P – имя отношения, представляющего результаты ЭС, c1 ,… сj-1 , cj+1 ,…, cn - имена вспомогательных переменных, cj * - имя описываемой переменной. Под значением cj * переменнной будем понимать множество всех j-ых элементов кортежей отношения P из x. Значениями вспомогательных переменных c1 ,… сj-1 , cj+1 ,…, cn является множество кортежей с номерами 1,…, j-1, j+1,… n соответственно.
Текстовая конструкция выводимое множество указывает, что в тексте объяснения необходимо перечислить в определенном (в соответствии с условием) порядке все значения некоторой переменной. Данная конструкция имеет вид <g:усл >, где g – описание переменной, усл – условие, которое накладывается на ее значения (условие может отсутствовать). Условие определяет, в каком порядке значения переменной должны быть помещены в текст объяснения, – либо алфавитном порядке, либо в порядке, который определен в этом условии.
Часто текст объяснения должен содержать повторяющиеся части, и при каждом повторении эти части несколько отличаются друг от друга, причем эти отличия должны определяться результатами ЭС. Текстовая конструкция цикл служит для представления таких повторяющихся частей и имеет вид: <s:усл ,a>. Здесь s – описание переменной, усл – условие, которое накладывается на ее значения (условие может отсутствовать), a – тело цикла. Описание переменной необходимо для того, чтобы задать условия выполнения тела цикла: количество повторений тела цикла в объяснении, а также содержание изменяемых частей в теле цикла. Тело цикла – составной оператор. Содержание изменяемой информации при каждом выполнении тела цикла зависит от значений параметра цикла и вспомогательных переменных. При каждом выполнении тела цикла параметру цикла соответствует некоторое новое значение из множества ее значений, определяемое результатами ЭС и условием усл , которое накладывается на значения переменной. Каждому значению переменной соответствуют подмножества значений вспомогательных переменных.
Текстовая конструкция альтернатива имеет вид: <b, {W1 ,…,Wm }>. Здесь b-описание переменной, {W1 ,…,Wm } – описания альтернатив. Описание каждой альтернативы состоит из двух частей – множества условий выбора dk и варианта yk , т.е. Wk =<dk ,yk >, 1<=k<=m. Множество условий выбора dk задает либо некоторое число, обозначающее возможное число значений переменной, либо значение (или множество значений), которое может получить переменная по результатам работы ЭС, либо некоторую метку. Вариант yk – это составной оператор, который будет выполняться, если значения переменной удовлетворяют условию выбора dk . Переменная из описания b удовлетворяет условию выбора dk , если число ее значений совпадает с числом в условии выбора, либо значение переменной (или подмножество ее значений) совпадает со значением (или подмножеством значений) в условии выбора. Выполнение определенной альтернативы состоит в выполнении варианта (составного оператора) первого по порядку описания альтернативы, для которого переменная из описания b удовлетворяет условию выбора. Если переменная из описания b не удовлетворяет ни одному из условий выбора, то выполняется альтернатива, условием выбора которой является метка.
Процесс построения текста объяснения по его описанию заключается в последовательном выполнении элементов составного оператора формального задания объяснения, начиная с первого, при этом формируется очередное состояние вычислительного процесса, которое зависит от выполняемого элемента описания wi и состояния вычислительного процесса.
Состояние вычислительного процесса хранит информацию о позиционном номере выполняемого элемента объяснения, значениях основных и вспомогательных переменных, отношениях, с которыми они связаны, некоторую дополнительную информацию о состоянии выполнения цикла и альтернативы, а также сформированный на данном шаге текст объяснения. Информация об основных компонентах состояния (за исключением текста объяснения) заносится при выполнении конструкций цикл и альтернатива и необходима для выполнения всех конструкций формального задания объяснения, за исключением строки. Например, если конструкция выводимое множество является составляющей тела цикла, то по описанию переменной в выводимом множестве и информации о значениях основных и вспомогательных переменных будут определены ее значения и помещены в текст объяснения. По окончании выполнения элементов формального задания объяснения состояние вычислительного процесса содержит сформированный текст объяснения. [5]
В индивидуальном задании передо мной была поставлена цель изучения интерфейсов экспертных систем.
Мною были рассмотрены следующие темы:
1. Структура ЭС, области применения ЭС, требования предъявляемые к ЭС, важность ЭС
2. Модель гибкого интерфейса (рассмотрены: определение гибкого интерфейса, требования к интерфейсу, состав)
3. ЭС нового поколения (определение, особенности в построении ЭС нового поколения, основные преимущества предлагаемого подхода, а также рассмотрен интерфейс экспертной системы нового поколения)
Перспективы развития данной тематики очень обнадеживают, так как появляются ЭС нового поколения, а значит и новая область для изучения.
1. Долин Г. Что такое ЭС // Компьютер Пресс. – 1992. – №2
2. Экспертные системы http://korotenko.ru/learn_es.htm
3. Область применения экспертных систем.
http://expsys.narod.ru/glava.htm#
4. Технология и основные этапы построения интегрированных (корпоративных) и экспертных информационных систем http://expert-sistem.narod.ru/es1.html
5. В.В. Грибова, А.С. Клещев Модель гибкого интерфейса в ЭС // статья, Proc. 6thInternationalconference«knowledge-dialogue – solution -97», Yalta, 1997, Vol. II, pp. 225–233.