| Скачать .docx |
Реферат: Побудова украиномовнои онтологии засобами СУБД
Глибовець М. М., Марченко О. О., Никоненко А. О.
ПОБУДОВА УКРАЇНОМОВНОЇ
ОНТОЛОГІЇ ЗАСОБАМИ СУБД
2. Формати онтологій
Для спрощення роботи з онтологіями ство¬
рено ряд мов опису онтологій. Метою таких
мов є надання можливості задавати додаткову
машинно-інтерпретовану семантику ресурсам,
зробити машинне представлення даних більш
наближеним до реального світу, підвищити мож¬
ливості концептуального моделювання слабко
структурованих Web-даних. Такий підхід поши¬
рився й на різноманітні мови опису онтології та
на інструментальні засоби, призначені для робо¬
ти з ними. Сьогодні виділяють три основні класи
мов опису онтологій:
- традиційні мови специфікації онтологій: Ontolingua,
CycL та мови, засновані на дескриптивних
логіках (такі як LOOM), також мови,
засновані на фреймах (OKBC, OCML, Flogic);
- більш пізні мови, засновані на Web-стандартах
(XOL, SHOE, UPML);
- спеціальні мови для обміну онтологіями че¬
рез Web: RDF(S), DAML, OIL, OWL [2].
Коротко охарактеризуємо найбільш пошире¬
ні та часто вживані мови опису онтологій.
Мова RDF. У рамках проекту семантичної
інтерпретації інформаційних ресурсів Інтернету
(Semantic Web) був запропонований стандарт
опису метаданих документа Resource Description
Framework, що використовує Xml-синтаксис.
RDF використовує базову модель даних
≪об'єкт - атрибут - значення≫ іздатний відігра¬
ти роль універсальної мови опису семантики ре¬
сурсів та взаємозв'язків між ними. Ресурси опи¬
суються у вигляді орієнтованого розміченого
графа. Кожен ресурс може мати властивості, які
у свою чергу також можуть бути ресурсами або
їхніми колекціями. Усі словники RDF викорис¬
товують базову структуру, яка описує класи ре¬
сурсів і типи зв'язків між ними. Це дозволяє ви¬
користовувати різнорідні децентралізовані слов¬
ники, створені для машинної обробки за різними
принципами й методами. Важливою особливіс¬
тю стандарту є розширюваність: можна задати
структуру опису джерела, використовуючи й
розширюючи такі вбудовані поняття RDF-схем,
як класи, властивості, типи, колекції. Модель
схеми RDF включає наслідування класів і влас¬
тивостей [3].
DAML+OIL - семантична мова розмітки
Web-ресурсів, що розширює стандарти RDF і
RDF Schema за рахунок більш повних примітивів
моделювання. Остання версія DAML+OIL забез¬
печує багатий набір конструкцій для створення
онтології й розмітки інформації таким чином,
щоб їх могла читати й розуміти машина [4].
OWL (Web Ontology Language) - мова подан¬
ня онтологій, що розширює можливості XML,
RDF, RDF Schema і DAML+OIL. Цей проект пе¬
редбачає створення потужного механізму семан¬
тичного аналізу. Планується, що в ньому буде
усунено обмеження конструкцій DAML+OIL.
Онтології OWL - це послідовності аксіом і
фактів, а також посилань на інші онтології. Вони
містять компонент для запису авторства та іншої
докладної інформації, є документами Web, на
них можна посилатися через URI [5].
KIF (Knowledge Interchange Format, або формат
обміну знаннями) - заснований на S-виразах
синтаксис для логіки. KIF - це спеціальна мова,
призначена для використання при обміні зна¬
ннями між різними комп'ютерними системами.
Мова не призначена для внутрішнього представ¬
лення знань усередині комп'ютерних систем або
всередині тісно зв'язаних наборів комп'ютерних
систем (хоча може бути використана й для цієї
мети). Мова була розроблена для опису загаль¬
ного формату представлення знань, незалежного
від конкретних систем [6].
CycL (мова опису онтології Cyc) - це гібрид¬
на мова, що поєднує в собі властивості фреймів
і логіку предикатів. CycL розрізняє такі сутності,
як екземпляри, класи, предикати й функції. Син¬
таксис мови CycL схожий на синтаксис мови
Lisp. Словник CycL складається з термів. Мно¬
жину термів можна розділити на константи, тер¬
ми (що не є атомами) і змінні. Крім цього, зустрі¬
чаються деякі інші типи об'єктів. Терми вико¬
ристовуються для складання значущих виразів
CycL, які використовуються для формування су¬
джень, з яких складається база знань [7].
Зважаючи на сказане вище, зрозуміло, що
сьогодні не існує ні єдиної, формалізованої та
стандартизованої мови для опису онтологій, ні
єдиного загальновживаного формату збережен¬
ня даних в онтологіях. Тому кожен розробник
системи для обробки природномовних текстів
вимушений розробляти свою онтологію з ≪нуля
≫, починаючи з формату збереження даних і
закінчуючи самим наповненням бази. З'явилися
навіть спеціалізовані онтології, які дістали назву
≪організаційні≫. Звичайно, така ситуація не є
прийнятною й дуже ускладнює, сповільнює та
робить більш дорогою розробку нових лінгвіс¬
тичних систем [8].
Наша розробка - перший крок у напрямі усу¬
нення ситуацій, коли для кожного проекту по¬
трібно розробляти нову онтологію. Найближчим
часом ми плануємо закінчити проект щодо ство¬
рення єдиної онтологічної бази для програмних
систем, що працюють з українською мовою, а в
перспективі - і для російської, англійської та де¬
яких інших європейських мов. Принципи орга¬
нізації онтологічної бази української мови та її
структура й будуть описані далі у статті.
Частина бази даних, що відповідає за _роботу з онтологією:
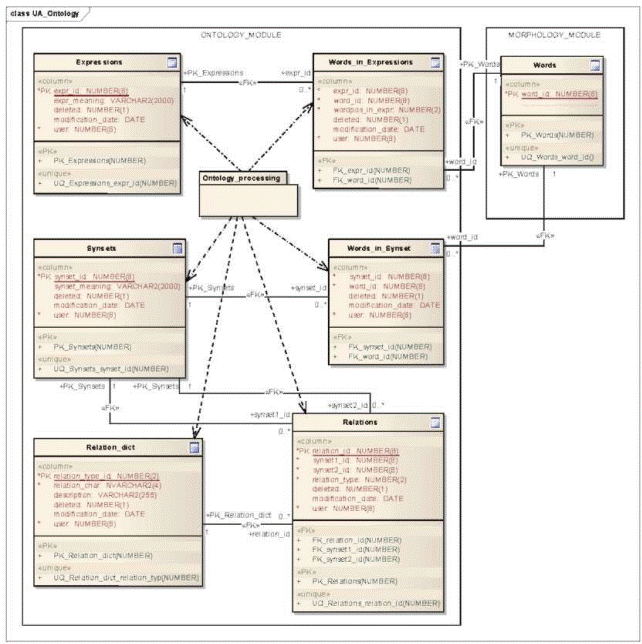
Рис. 2. Діаграма класів для даних про семантику
http://www.library.ukma.kiev.ua/e-lib/NZ/NZV86_2008_computer/08_glybovets_mm.PDF