| Скачать .docx |
Реферат: Компьютерная лингвистика как прикладная лингвистическая дисциплина
Тема работы: Компьютерная лингвистика как прикладная лингвистическая дисциплина
Содержание
1. Компьютерная лингвистика как прикладная лингвистическая дисциплина
2. Когнитивный инструментарий компьютерной лингвистики
3. Некоторые направления компьютерной лингвистики
4. Гипертекстовые технологии представления текста
1. Компьютерная лингвистика как прикладная лингвистическая дисциплина
Под термином "компьютерная лингвистика" (computational linguistics) обычно понимается широкая область использования компьютерных инструментов - программ, компьютерных технологий организации и обработки данных - для моделирования функционирования языка в тех или иных условиях, ситуациях, проблемных областях, а также сфера применения компьютерных моделей языка не только в лингвистике, но и в смежных с ней дисциплинах. Собственно, только в последнем случае речь идет о прикладной лингвистике в строгом смысле, поскольку компьютерное моделирование языка может рассматриваться и как сфера приложения теории программирования (computer science) в области лингвистики. Тем не менее общая практика такова, что сфера компьютерной лингвистики охватывает практически все, что связано с использованием компьютеров в языкознании: "Термин "компьютерная лингвистика" задает общую ориентацию на использование компьютеров для решения разнообразных научных и практических задач, связанных с языком, никак не ограничивая способы решения этих задач".
Институциональный аспект компьютерной лингвистики . Как особое научное направление компьютерная лингвистика оформилась в 60-е гг. Поток публикаций в этой области очень велик. Кроме тематических сборников, в США ежеквартально выходит журнал "Компьютерная лингвистика". Большую организационную и научную работу проводит Ассоциация по компьютерной лингвистике, которая имеет региональные структуры по всему миру (в частности, европейское отделение). Каждые два года проходят международные конференции по компьютерной лингвистике - КОЛИНГ. Соответствующая проблематика широко представлена также на международных конференциях по искусственному интеллекту разных уровней.
2. Когнитивный инструментарий компьютерной лингвистики
Компьютерная лингвистика как особая прикладная дисциплина выделяется прежде всего по инструменту - то есть по использованию компьютерных средств обработки языковых данных. Поскольку компьютерные программы, моделирующие те или иные аспекты функционирования языка, могут использовать самые разные средства программирования, то об общем метаязыке говорить вроде бы не приходится. Однако это не так. Существуют общие принципы компьютерного моделирования мышления, которые так или иначе реализуются в любой компьютерной модели. В основе этого языка лежит теория знаний, разработанная в искусственном интеллекте и образующая важный раздел когнитивной науки.
Основной тезис теории знаний гласит, что мышление - это процесс обработки и порождения знаний. "Знания" или "знание" считается неопределяемой категорией. В качестве "процессора", обрабатывающего знания, выступает когнитивная система человека. В эпистемологии и когнитивной науке различают два основных вида знаний - декларативные ("знание что") и процедурные ("знание как"2)). Декларативные знания представляются обычно в виде совокупности пропозиций, утверждений о чем-либо. Типичным примером декларативных знаний можно считать толкования слов в обычных толковых словарях. Например, чашка] - 'небольшой сосуд для питья округлой формы, обычно с ручкой, из фарфора, фаянса и т.п. ' [MAC]. Декларативные знания поддаются процедуре верификации в терминах "истина-ложь". Процедурные знания представляются как последовательность (список) операций, действий, которые следует выполнить. Это некоторая общая инструкция о действиях в некоторой ситуации. Характерный пример процедурных знаний - инструкции по пользованию бытовыми приборами.
В отличие от декларативных знаний, процедурные знания невозможно верифицировать как истинные или ложные. Их можно оценивать только по успешности-неуспешности алгоритма.
Большинство понятий когнитивного инструментария компьютерной лингвистики омонимично: они одновременно обозначают некоторые реальные сущности когнитивной системы человека и способы представления этих сущностей на некоторых метаязыках. Иными словами, элементы метаязыка имеют онтологический и инструментальный аспект. Онтологически разделение декларативных и процедурных знаний соответствует различным типам знаний когнитивной системы человека. Так, знания о конкретных предметах, объектах действительности преимущественно декларативны, а функциональные способности человека к хождению, бегу, вождению машины реализуются в когнитивной системе как процедурные знания. Инструментально знание (как онтологически процедурное, так и декларативное) можно представить как совокупность дескрипций, описаний и как алгоритм, инструкцию. Иными словами, онтологически декларативное знание об объекте действительности "стол" можно представить процедурно как совокупность инструкций, алгоритмов по его созданию, сборке (= креативный аспект процедурного знания) или как алгоритм его типичного использования (= функциональный аспект процедурного знания). В первом случае это может быть руководство для начинающего столяра, а во втором - описание возможностей офисного стола. Верно и обратное: онтологически процедурное знание можно представить декларативно.
Требует отдельного обсуждения, всякое ли онтологически декларативное знание представимо как процедурное, а всякое онтологически процедурное - как декларативное. Исследователи сходятся в том, что всякое декларативное знание в принципе можно представить процедурно, хотя это может оказаться для когнитивной системы очень неэкономным. Обратное вряд ли справедливо. Дело в том, что декларативное знание существенно более эксплицитно, оно легче осознается человеком, чем процедурное. В противоположность декларативному знанию, процедурное знание преимущественно имплицитно. Так, языковая способность, будучи процедурным знанием, скрыта от человека, не осознается им. Попытка эксплицировать механизмы функционирования языка приводит к дисфункции. Специалистам в области лексической семантики известно, например, что длительная семантическая интроспекция, необходимая для изучения плана содержания слова, приводит к тому, что исследователь частично теряет способность к различению правильных и неправильных употреблений анализируемого слова. Можно привести и другие примеры. Известно, что с точки зрения механики тело человека является сложнейшей системой двух взаимодействующих маятников.
В теории знаний для изучения и представления знания используются различные структуры знаний - фреймы, сценарии, планы. Согласно М. Минскому, "фрейм - это структура данных, предназначенная для представления стереотипной ситуации" [Минский 1978, с.254]. Более развернуто можно сказать, что фрейм является концептуальной структурой для декларативного представления знаний о типизированной тематически единой ситуации, содержащей слоты, связанные между собой определенными семантическими отношениями. В целях наглядности фрейм часто представляют в виде таблицы, строки которой образуют слоты. Каждый слот имеет свое имя и содержание (см. табл.1).
Таблица 1
Фрагмент фрейма "стол" в табличном представлении
| Имя слота |
Содержание слота |
| количество ножек |
четыре, возможно больше, минимум три |
| материал |
дерево, пластмасса, стекло |
| поверхность |
прямоугольник, овал, круг, квадрат |
| наличие тумб |
факультативно |
| функции |
обеденный, журнальный, рабочий и пр. |
| и т.д. |
В зависимости от конкретной задачи структуризация фрейма может быть существенно более сложной; фрейм может включать вложенные подфреймы и отсылки к другим фреймам.
Вместо таблицы часто используется предикатная форма представления. В этом случае фрейм имеет форму предиката или функции с аргументами. Существуют и другие способы представления фрейма. Например, он может представляться в виде кортежа следующего вида: { (имя фрейма) (имя слота)) (значение слота,),..., (имя слотап ) (значение слотал ) }.
Обычно такой вид имеют фреймы в языках представлениях знаний.
Как и другие когнитивные категории компьютерной лингвистики, понятие фрейма омонимично. Онтологически - это часть когнитивной системы человека, и в этом смысле фрейм можно сопоставить с такими понятиями как гештальт, прототип, стереотип, схема. В когнитивной психологии эти категории рассматриваются именно с онтологической точки зрения. Так, Д. Норман различает два основных способа бытования и организации знаний в когнитивной системе человека - семантические сети и схемы. "Схемы, - пишет он, - представляют собой организованные пакеты знания, собранные для репрезентации отдельных самостоятельных единиц знания. Моя схема для Сэма может содержать информацию, описывающую его физические особенности, его активность и индивидуальные черты. Эта схема соотносится с другими схемами, которые описывают иные его стороны" [Норман 1998, с.359]. Если же брать инструментальную сторону категории фрейма, то это структура для декларативного представления знаний. В имеющихся системах ИИ фреймы могут образовывать сложные структуры знаний; системы фреймов допускают иерархию - один фрейм может быть частью другого фрейма.
По содержанию понятие фрейма очень близко категории толкования. Действительно, слот - аналог валентности, заполнение слота - аналог актанта. Основное отличие между ними заключается в том, что толкование содержит только лингвистически релевантную информацию о плане содержания слова, а фрейм, во-первых, не обязательно привязан к слову, и, во-вторых, включает всю релевантную для данной проблемной ситуации информацию, в том числе и экстралингвистическую (знания о мире) 3).
Сценарий представляет собой концептуальную структуру для процедурного представления знаний о стереотипной ситуации или стереотипном поведении. Элементами сценария являются шаги алгоритма или инструкции. Обычно говорят о "сценарии посещения ресторана", "сценарии покупки" и т.п.
Изначально фрейм также использовался для процедурного представления (ср. термин "процедурный фрейм"), однако сейчас в этом смысле чаще употребляется термин "сценарий". Сценарий можно представить не только в виде алгоритма, но и в виде сети, вершинам которой соответствуют некоторые ситуации, а дугам - связи между ситуациями. Наряду с понятием сценария, некоторые исследователи привлекают для компьютерного моделирования интеллекта категорию скрипта. По Р. Шенку, скрипт - это некоторая общепринятая, общеизвестная последовательность причинных связей [Schank 1981]. Например, понимание диалога
На улице льет как из ведра.
Все равно придется выходить в магазин: в доме есть нечего - вчера гости все подмели.
основывается на неэксплицированных семантических связях типа 'если идет дождь, на улицу выходить нежелательно, поскольку можно заболеть'. Эти связи формируют скрипт, который и используется носителями языка для понимания речевого и неречевого поведения друг друга.
В результате применения сценария к конкретной проблемной ситуации формируется план ). План используется для процедурного представления знаний о возможных действиях, ведущих к достижению определенной цели. План соотносит цель с последовательностью действий.
В общем случае план включает последовательность процедур, переводящих начальное состояние системы в конечное и ведущих к достижению определенной подцели и цели. В системах ИИ план возникает в результате планирования или планирующей деятельности соответствующего модуля - модуля планирования. В основе процесса планирования может лежать адаптация данных одного или нескольких сценариев, активизированных тестирующими процедурами, для разрешения проблемной ситуации. Выполнение плана производится экзекутивным модулем, управляющим когнитивными процедурами и физическими действиями системы. В элементарном случае план в интеллектуальной системе представляет собой простую последовательность операций; в более сложных версиях план связывается с конкретным субъектом, его ресурсами, возможностями, целями, с подробной информацией о проблемной ситуации и т.д. Возникновение плана происходит в процессе коммуникации между моделью мира, часть которой образуют сценарии, планирующим модулем и экзекутивным модулем.
В отличие от сценария, план связан с конкретной ситуацией, конкретным исполнителем и преследует достижение определенной цели. Выбор плана регулируется ресурсами исполнителя. Выполнимость плана - обязательное условие его порождения в когнитивной системе, а к сценарию характеристика выполнимости неприложима.
Еще одно важное понятие - модель мира. Под моделью мира обычно понимается совокупность определенным образом организованных знаний о мире, свойственных когнитивной системе или ее компьютерной модели. В несколько более общем виде о модели мира говорят как о части когнитивной системы, хранящей знания об устройстве мира, его закономерностях и пр. В другом понимании модель мира связывается с результатами понимания текста или - более широко - дискурса. В процессе понимания дискурса строится его ментальная модель, которая является результатом взаимодействия плана содержания текста и знаний о мире, свойственных данному субъекту [Джонсон-Лэрд 1988, с.237 и далее]. Первое и второе понимание часто объединяются. Это типично для исследователей-лингвистов, работающих в рамках когнитивной лингвистики и когнитивной науки.
Тесно связано с категорией фрейма понятие сцены. Категория сцены преимущественно используется в литературе как обозначение концептуальной структуры для декларативного представления актуализованных в речевом акте и выделенных языковыми средствами (лексемами, синтаксическими конструкциями, грамматическими категориями и пр) ситуаций и их частей5). Будучи связана с языковыми формами, сцена часто актуализуется определенным словом или выражением. В грамматиках сюжетов (см. ниже) сцена предстает как часть эпизода или повествования. Характерные примеры сцен - совокупность кубиков, с которыми работает система ИИ, место действия в рассказе и участники действия и т.д. В искусственном интеллекте сцены используются в системах распознавания образов, а также в программах, ориентированных на исследование (анализ, описание) проблемных ситуаций. Понятие сцены получило широкое распространение в теоретической лингвистике, а также логике, в частности в ситуационной семантике, в которой значение лексической единицы непосредственно связывается со сценой.
3. Некоторые направления компьютерной лингвистики
Обратимся к тем областям компьютерной лингвистики, которые непосредственно связаны с оптимизацией когнитивной функции языка. Ниже в качестве примера рассматриваются три сферы компьютерного моделирования, в которых используются знания о функционировании языковой системы: моделирование общения, моделирование структуры сюжета и гипертекстовые технологии представления текста.
Моделирование общения. В узком смысле проблематика компьютерной лингвистики часто связывается с моделированием общения, в частности, с обеспечением общения человека с ЭВМ на естественном или ограниченном естественном языке. Это относится к оптимизации языка как средства общения. Впрочем, компьютерные модели общения часто используются для изучения самого процесса общения. Остановимся подробнее на опыте создания и использования именно таких моделей.
Изучение уже накопившегося опыта эксплуатации компьютерных систем, требовавших обеспечения взаимодействия с ЭВМ на естественном языке, позволило исследователям по-новому взглянуть на функции и структуру естественной коммуникации. В центр внимания попали вопросы, которые ранее были на периферии теории диалога, дискурс-анализа и теории коммуникации. Что обеспечивает естественность общения? Каковы условия связности беседы? Когда общение оказывается успешным? В каких случаях возникают коммуникативные неудачи и можно ли их избежать? Какие стратегии общения используют участники коммуникативного взаимодействия при достижении своих коммуникативных целей? Это далеко не исчерпывающий список теоретических проблем, обнаружившихся в связи с функционированием компьютерных моделей общения.
Одной из наиболее интересных компьютерных моделей диалога, вызвавшей оживленные теоретические дискуссии, была программа Джозефа Вейценбаума "Элиза", первый вариант которой появился в 1966 г. Изначально "Элиза" создавалась как игрушка, как учебный образец программы-имитатора, целью которой является не моделирование мышления в точном смысле, а моделирование речевого поведения. Программа поддерживала разговор с собеседником в реальном масштабе времени, однако при ее разработке были использованы ограниченные программистские ресурсы, лингвистический анализ и синтез также были сведены к минимуму. Тем не менее программа функционировала столь успешно, что фактически опровергла известный тест Тьюринга на создание искусственного интеллекта. Как известно, Тьюринг вместо софистицированного обсуждения философского вопроса о том, может ли машина мыслить, предложил игровую задачу следующего типа. Пусть есть три участника: мужчина Л, женщина В и спрашивающий С. Спрашивающий не знает, кто мужчина, а кто - женщина. Задавая вопросы участникам игры, С должен попытаться определить, кто является мужчиной, а кто - женщиной, при этом участник пытается мистифицировать спрашивающего, выдавая ему не ложную, но искаженную информацию, а участник В - наоборот, стремится помочь С. Понятно, что общение происходит не напрямую, а через телетайп или с помощью записок, отпечатанных на пишущей машинке. Что произойдет, если в качестве А будет выступать система ИИ? Будет ли спрашивающий ошибаться столь же часто? [Turing 1950, р.434]. Более простой вариант этого теста сводится к тому, что несколько участников беседуют с некоторым другим участником X. Проблема построения искусственного интеллекта решена, если большинство участников не сможет установить, с кем они беседуют - с человеком или машиной.
Программа "Элиза" была использована группой исследователей во главе с М. Макгайром для изучения структуры диалога и особенностей естественноязыковой коммуникации [McGuire 1971]. В проводившемся эксперименте с "Элизой" беседовали в течение часа 24 испытуемых. Общение происходило с помощью телетайпа. За время беседы каждый участник ввел от 10 до 65 реплик и получил на них ответы. По окончании 15 участников (62%) были уверены, что им отвечал человек, 5 испытуемых (21%) обнаружили определенные колебания и лишь четверо участников (17%) были абсолютно уверены, что общались с ЭВМ. С лингвистической точки зрения алгоритмы программы "Элиза" включают минимум лингвистической информации. Во-первых, это комплекс ключевых слов, которые актуализуют некоторые устойчивые коммуникативные формулы (шаблоны), во-вторых, способность относительно несложно трансформировать предшествующее высказывание.
Интересно, что существенная тематическая ограниченность коммуникации и значительное количество ошибок и неточностей в ответе (порядка 19% неточных или выпадающих из контекста реплик "Элизы" в упоминавшемся эксперименте М. Макгайра), не помешали испытуемым признать партнера по коммуникации человеком. Дело здесь совсем не в патологической глупости испытуемых. Это проявление важнейшей особенности коммуникации на естественном языке: естественноязыковой дискурс очень терпим по отношению к сбоям и ошибкам - он избыточен и помехоустойчив. Реплики "Элизы", выпадавшие из нормального общения, испытуемые легко объясняли обычными сбоями в понимании своей предшествующей реплики, не вполне нормальными условиями общения, шутливым настроением партнера. Устойчивость естественного дискурса объясняется также способностями человека к интерпретации речевых действий: человек, принимающий роль участника диалога, ведет себя соответствующим образом. Имея установку на общение, он стремится включать в коммуникацию все то, что по форме напоминает речевой акт, реплику. Иными словами, он склонен наделять смыслом то, что часто смысла не имеет. В этом случае испытуемые сами порождают смысл диалога, сами обеспечивают его связность, сами приписывают партнеру коммуникативные интенции.
Второй важный вывод эксперимента: испытуемые довольно быстро принимали решение о том, кто перед ними - компьютер или человек.22 участника из 24 уяснили для себя ситуацию не более, чем за пять обменов репликами, и далее не меняли своего решения. Определение ролей в коммуникации относится к метауровню общения, поскольку это составляет одну из предпосылок успешной коммуникации, предохраняющей общение от многочисленных коммуникативных неудач.
Понятно, что определение ролей участников во многом определяет выбор стратегии коммуникативного поведения. Действительно, лучше сразу определить, с кем мы разговариваем по телефону - с давним другом или чиновником налоговой инспекции. Выяснение того, кем является собеседник - машиной или человеком, также относится к метауровню общения, и испытуемые старались установить ролевые характеристики партнера как можно раньше.
Это свойство естественноязыковой коммуникации можно назвать принципом приоритета метакоммуникативных параметров ситуации общения.
Третье важное следствие из эксперимента М. Макгайра связано с существованием различных типов коммуникативного взаимодействия между людьми. Успешное взаимодействие между человеком и программой типа "Элиза" возможно только в ситуации, когда происходит так называемое "ассоциативное общение", при котором реплики диалога связаны не столько логическими отношениями типа "причина-следствие", "посылка-заключение", а ассоциациями. Ассоциативное общение не имеет конкретной направленности; само поддержание беседы может служить ее оправданием. Собеседники не преследуют цели решить какую-то проблему или выработать единую точку зрения на какой-то вопрос. В классификации Р. Якобсона для коммуникации такого типа предложен термин "фатическое общение" [Якобсон 1975]. Заметим, что беседа врача-психиатра с пациентом по форме также имеет вид фатического общения, хотя и преследует вполне определенные цели сбора данных о заболевании пациента и последующем вербальном и невербальном воздействии на его психику для достижения лечебного эффекта. "Элиза" не смогла бы успешно имитировать общение в коммуникативной ситуации, названной М. Макгайром "решение задач", поскольку она не способна понять проблемную ситуацию, то есть построить модель мира дискурса, определить альтернативы выхода из проблемы, выбрать одну из альтернатив и т.д. Одна из типичных стратегий "ухода от непонимания", реализованная в программе "Элиза" - смена темы беседы. Очевидно, что такая стратегия ведения беседы вряд ли приведет к успеху при совместном поиске решения проблемы.
Наконец, четвертый вывод можно сформулировать как неуниверсальность правил коммуникативного взаимодействия. Он касается самих закономерностей общения на естественном языке. Каждый тип коммуникации обслуживается своим набором относительно простых правил, обеспечивающих связность дискурса, его осмысленность для участников. Типология видов общения задается соответствующими наборами правил. Из экспериментов М. Макгайра с программой "Элиза" следует, что кроме ассоциативного (= фатического) способа общения, выделяется еще "решение задач", "задавание вопросов" и "уточнение понимания". С лингвистической точки зрения эти типы, скорее всего, неоднородны, пересекаются и даже находятся на разных уровнях дискурса. Так, "уточнение понимания" относится к метауровню коммуникации, "задавание вопросов" может быть частью стратегии "решение задач" и "уточнения понимания" и т.д. Существенно, что компьютерный эксперимент с программой, моделирующей поведение участника коммуникации, позволяет экспериментально подтвердить или опровергнуть многие положения теории диалога, разработанные как в лингвистике, так и в смежных дисциплинах - в дискурс-анализе, теории коммуникации, психологии и социологии общения.
Моделирование структуры сюжета . Изучение структуры сюжета относится к проблематике структурного литературоведения (в широком смысле), психологии творчества и культурологии. Имеющиеся компьютерные программы моделирования сюжета основываются на трех базовых формализмах представления сюжета - морфологическом и синтаксическом направлениях представления сюжета, а также на когнитивном подходе.
"Морфология" сюжета . Идеи о морфологическом устройстве структуры сюжета восходят к известным работам В.Я. Проппа о русской волшебной сказке [Пропп 1928; Пропп 1986]. Пропп заметил, что при обилии персонажей и событий волшебной сказки количество функций персонажей ограничено: "Постоянными, устойчивыми элементами сказки служат функции действующих лиц, независимо от того, кем и как они выполняются. Они образуют основные составные части сказки" [Пропп 1928, с.31]. К числу базовых относятся, например, следующие функции:
отлучение персонажа сказки из дома;
запрет герою на действие;
нарушение запрета;
получение вредителем информации о жертве;
обман жертвы вредителем;
невольное пособничество жертвы вредителю и т.д.
Идеи Проппа легли в основу компьютерной программы TALE, моделирующей порождение сюжета сказки. В основу алгоритма программы TALE положена последовательность функций персонажей сказки. Фактически функции Проппа задавали множество типизированных ситуаций, упорядоченных на основе анализа эмпирического материала. Возможности сцепления различных ситуаций в правилах порождения определялись типичной последовательностью функций - в том виде, в котором это удается установить из текстов сказок. В программе типичные последовательности функций описывались как типовые сценарии встреч персонажей.
В дальнейшем система была усложнена за счет введения модели мира сказки, география которого состоит из обычного мира, промежуточного (среднего) мира и иного мира [Гаазе-Рапопорт, Поспелов, Семенова 1984]. Каждый мир состоит из локусов, связанных между собой определенными отношениями. Отношения связывают не только локусы внутри каждого мира, но и локусы различных миров. Обычный мир состоит из следующих локусов: место проживания героя (локус 1), место получения задания (локус Г), место дарения волшебных предметов, помогающих выполнить задание. Первый локус и локус штрих часто совпадают (ср. сказки о Падчерице и злой Мачехе). К обычному миру относятся также локусы 3 (их может быть много), в которых преодолеваются препятствия с помощью волшебных предметов. Количество препятствий, как правило, совпадает с количеством волшебных предметов. После преодоления препятствий герой оказывается в промежуточном мире, стражем которого является Баба-Яга. Средний мир отделяет мир героев от мира антигероев. Функции Бабы-Яги различаются - она может выступать как дарительница информации или очередного волшебного средства, а может выступать на стороне антигероев (например, при акценте на людоедском поведении Бабы-Яги). Иной мир включает место обитания антигероя (локус 5), место битвы между героем и антигероем (локус 6) и, наконец, локус 7 - место награды или цели, которой добивается герой. Локусы связаны отношениями перехода, которые представляют возможные последовательности развертывания сюжета.
Модифицированная версия программы TALE имеет следующую блок-схему [Гаазе-Рапопорт, Поспелов, Семенова 1984, с.52]:
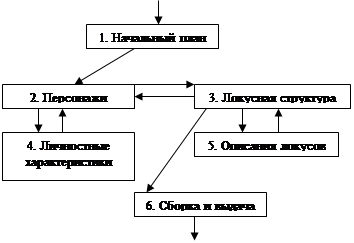
Блок-схема программы TALE
Работа программы начинается с первого блока, в котором выбирается тип сюжета сказки и ее персонажи. Здесь же формируется экспозиция сказки (setting). Во втором блоке хранятся описания, связанные с персонажами, а в четвертом - постоянные характеристики персонажей. Описания даются во фреймоподобных структурах представления знаний. С помощью второго и третьего блоков формируются мотивы и поступки персонажей. Третий блок задает последовательность движения персонажей по локусам. В последнем (шестом) блоке происходит сборка порожденных фрагментов сказки.
Блок-схема модифицированного варианта программы TALE показывает, что чисто "морфологического" подхода к структуре сюжета сказки явно недостаточно. "Морфемы" сказочного сюжета должны не только определенным образом сочетаться между собой, но и иметь специфические ограничения на сочетаемость. Фиксация одного типичного порядка следования функций персонажей волшебной сказки существенно ограничивает имеющиеся возможности сочетаемости. Более адекватное решение этой проблемы дает синтаксический подход к структуре сюжета.
"Синтаксис" сюжета . Теоретическую основу синтаксического подхода к сюжету текста составили "сюжетные грамматики" (story grammars). Сюжетные грамматики появились в середине 70-х гг. в результате переноса идей порождающей грамматики Н. Хомского на описание макроструктуры текста. Если важнейшими составляющими синтаксической структуры в порождающей грамматике были глагольные и именные группы, то в большинстве сюжетных грамматик в качестве базовых выделялись экспозиция (setting), событие и эпизод. В теории сюжетных грамматик широко обсуждались условия минимальности: ограничения, определявшие статус последовательности из элементов сюжета как нормальный сюжет. Оказалось, однако, что чисто лингвистическими методами это сделать невозможно. Многие ограничения носят социокультурный характер. Сюжетные грамматики, существенно различаясь набором категорий в дереве порождения, допускали весьма ограниченный набор правил модификации нарративной структуры. В подавляющем большинстве случаев эти правила заимствованы из той же порождающей грамматики. Потенциал варьирования структуры сюжета обеспечивается в первую очередь трансформациями передвижения и опущения. Например, текст признания преступника, фиксирующий реальную последовательность развертывания событий в преступлении, можно с помощью перестановок и опущений преобразовать в детективный сюжет: {преступник → замысел → орудие убийства → место → убийство → обнаружение трупа → поиски преступника} → {обнаружение трупа → обнаружение орудия убийства → поиски преступника}.
Использование сюжетных грамматик в компьютерном моделировании оказалось не вполне удачным. Синтактический компонент сюжета, описываемый грамматиками, отражает чисто внешние особенности текста. Не удается обнаружить операциональные критерии выделения различных составляющих сюжета.
Основной вывод дискуссии о недостатках сюжетных грамматик свелся к необходимости описания сюжета в рамках структуры целесообразной деятельности, то есть с привлечением категорий "цель", "проблема", "план" и т.д. Иными словами, метаязыка, учитывающего только внешние особенности сюжета, явно недостаточно. Необходимо обращение к когнитивным состояниям персонажей.
Когнитивный подход к сюжету. В начале 80-х гг. одной из учениц Р. Шенка - В. Ленерт - в рамках работ по созданию компьютерного генератора сюжетов был предложен оригинальный формализм аффективных сюжетных единиц (АСЕ - Affective Plot Units), оказавшийся мощным средством представления структуры сюжета [Lehnert 1982]. При том, что он был изначально разработан для системы ИИ, этот формализм использовался в чисто теоретических исследованиях. Сущность подхода Ленерт заключалась в том, что сюжет описывался как последовательная смена когнитивно-эмоциональных (аффективных) состояний персонажей. Тем самым в центре внимания формализма Ленерт стоят не внешние компоненты сюжета - экспозиция, событие, эпизод, мораль - а его содержательные характеристики. В этом отношении формализм Ленерт отчасти оказывается возвращением к идеям Проппа.
Каждая аффективная сюжетная единица представляет собой бинарное отношение, связывающее некоторые события, оцениваемые персонажами положительно (+) или отрицательно (-), и когнитивно-эмоциональные состояния персонажей (в различных комбинациях - событие & состояние; событие & событие и т.д.). Бинарное отношение не однородно. Всего выделяется пять типов бинарных отношений, специфицируемых в каждой аффективной сюжетной единице. Бинарное отношение может быть мотивацией (обозначение - т), актуализацией (а), прекращением одного действия другим (t), эквивалентностью (е), а также аффективной каузальной связью между персонажами. Каждая аффективная сюжетная единица получает название, например, УСПЕХ, НЕУДАЧА, УПОРСТВО, ПРОБЛЕМА и т.д.
4. Гипертекстовые технологии представления текста
Феномен гипертекста можно обсуждать с нескольких точек зрения. С одной стороны, это особый способ представления, организации текста, с другой - новый вид текста, противопоставленный по многим своим свойствам обычному тексту, сформированному в гутенберговской традиции книгопечатания. И, наконец, это новый способ, инструмент и новая технология понимания текста.
Теоретические основания гипертекста . Многие исследователи рассматривают создание гипертекста как начало новой информационной эпохи, противопоставленной эре книгопечатания. Линейность письма, внешне отражающая линейность речи, оказывается фундаментальной категорией, ограничивающей мышление человека и понимание текста. Мир смысла нелинеен, поэтому сжатие смысловой информации в линейном речевом отрезке требует использования специальных "коммуникативных упаковок" - членение на тему и рему, разделение плана содержания высказывания на эксплицитные (утверждение, пропозиция, фокус) и имплицитные (пресуппозиция, следствие, импликатура дискурса) слои. Отказ от линейности текста и в процессе его представления читателю (чтения и понимания), и в процессе синтеза, по мнению теоретиков, способствовал бы "освобождению" мышления и даже возникновению его новых форм.
Прототипический текст - это монолог. Между тем многие лингвисты (и среди них М. Бахтин и Л. Якубинский) указывали на вторичность монолога по сравнению с диалогом. Гипертекст с этой точки зрения позволяет устранить искусственную монологичность текста.
Обычный текст, как правило, имеет автора. Гипертекст автора в традиционном понимании не имеет - у него множество авторов, причем для постоянно изменяющегося гипертекста авторский коллектив также постоянно меняется. Изменение статуса автора меняет и статус читателя: в гипертекстовой системе понимание часто сопровождается изменением компонентов гипертекста или, как минимум, выбором пути просмотра, что опять-таки акт творческий, авторский.
Множественность авторства имеет и еще одно следствие: в гипертексте представлено много точек зрения на проблему, а в обычном тексте - только одна. Именно поэтому гипертекст более объективен и более толерантен к читателю, чем классический текст.
Гипертекстовые технологии позволяют легко сочетать различные виды информации - обычный текст, рисунок, график, таблицу, схему, звук и движущееся изображение. Как традиционный текст, так и гипертекст - феномены, порожденные новыми технологиями. В первом случае технология позволила легко тиражировать и распространять знания самых различных типов, а во втором - компьютерные технологии дали возможность изменить сам внешний вид текста и его структуру. Разнородность гипертекста - это первое технологическое свойство гипертекста, технологическое в том смысле, что оно непосредственно следует из используемой компьютерной технологии. Второе технологическое свойство гипертекста - его нелинейность. Гипертекст не имеет стандартной, обычной последовательности чтения. Прочие свойства гипертекста в той или иной степени являются следствиями из этих двух технологических свойств.
Суммировать различия текста и гипертекста можно следующим образом:
конечность, законченность традиционного текста vs. бесконечность, незаконченность, открытость гипертекста;
линейность текста vs. нелинейность гипертекста;
точное авторство текста vs. отсутствие авторства (в традиционном понимании) у гипертекста;
снятие противопоставления между автором и читателем;
субъективность, односторонность обычного текста vs. объективность, многосторонность гипертекста;
однородность обычного текста vs. неоднородность гипертекста.
Компоненты гипертекста. Структурно гипертекст может быть представлен как граф, в узлах которого находятся традиционные тексты или их фрагменты, изображения, таблицы, видеоролики и т.д. Узлы связаны разнообразными отношениями, типы которых задаются разработчиками программного обеспечения гипертекста или самим читателем. Отношения задают потенциальные возможности передвижения или навигации по гипертексту. Отношения могут быть однонаправленными или двунаправленными. Соответственно, двунаправленные стрелки позволяют двигаться пользователю в обе стороны, а однонаправленные - только в одну. Цепочка узлов, через которые проходит читатель при просмотре компонентов текста, образует путь или маршрут.
Элементы типологии гипертекста. Первое противопоставление относится к структуре гипертекста. Гипертекст может быть иерархическим или сетевым. Иерархическое - древовидное - строение гипертекста существенно ограничивает возможности перехода между его компонентами. В таком гипертексте отношения между компонентами напоминают структуру тезауруса, основанного на родо-видовых связях. Иерархический гипертекст не реализует всех возможностей технологии гипертекста. В среде разработчиков гипертекстовых систем он не пользуется популярностью (хотя и довольно часто реализуется в работающих системах).
Второе противопоставление характеризует не саму структуру гипертекста, а возможности программного обеспечения. Здесь различаются простые и сложные гипертексты. Примером простого программного обеспечения гипертекста может служить электронное оглавление документа, которое позволяет перейти к любой части оглавления, минуя этап просмотра всего текста. К простому гипертексту относится и система, которая дает возможность просматривать отсылки к литературе, содержащиеся в тексте, не обращаясь непосредственно к списку литературы. Сложные гипертексты обладают богатой системой переходов между компонентами гипертекста, в них отсутствует представление о базовом тексте, с которым связаны второстепенные по значимости тексты. В некотором смысле нормальный, обычный гипертекст и является сложным гипертекстом.
По способу существования гипертекста выделяются статические и динамические гипертексты. Статический гипертекст не меняется в процессе эксплуатации; в нем пользователь может фиксировать свои комментарии, однако они не меняют существо дела. Для динамического гипертекста изменение является нормальной формой существования. Обычно динамические гипертексты функционируют там, где необходимо постоянно анализировать поток информации, то есть в информационных службах различного рода. Гипертекстовой является, например, Аризонская информационная система (AAIS), которая ежемесячно пополняется на 300-500 рефератов в месяц.
Отношения между элементами гипертекста могут изначально фиксироваться создателями, а могут порождаться всякий раз, когда происходит обращение пользователя к гипертексту. В первом случае речь идет о гипертекстах жесткой структуры, а во втором - о гипертекстах мягкой структуры. Жесткая структура технологически вполне понятна. Технология организации мягкой структуры должна основываться на семантическом анализе близости документов (или других источников информации) друг к другу. Это нетривиальная задача компьютерной лингвистики. В настоящее время широко распространено использование технологий мягкой структуры на ключевых словах. Переход от одного узла к другому в сети гипертекста осуществляется в результате поиска ключевых слов. Поскольку набор ключевых слов каждый раз может различаться, каждый раз меняется и структура гипертекста. Жесткость или мягкость архитектуры гипертекста зависит и от количества информации, которая в нем содержится. Если узлов в сети гипертекста порядка одной-трех тысяч, то чаще всего используется жесткая архитектура, если же количество узлов достигает нескольких десятков тысяч или даже миллионов единиц, то мягкая структура оказывается более предпочтительной, поскольку кодировка жестких связей отнимает слишком много времени. Заметим, что структура Интернета часто функционирует как гипертекст мягкой архитектуры.
Технология построения гипертекстовых систем не делает различий между текстовой и нетекстовой информацией. Между тем включение визуальной и звуковой информации (видеороликов, картин, фотографий, звукозаписей и т.п.) требует существенного изменения интерфейса с пользователем и более мощной программной и компьютерной поддержки. Такие системы получили название гипермедиа или мультимедиа. Наглядность мультимедийных систем предопределила их широкое использование в обучении, в создании компьютерных вариантов энциклопедий. Известны, например, прекрасно выполненные CD-ромы с мультимедийными системами по детским энциклопедиям издательства "Дорлинг Киндерсли".
Некоторые гипертекстовые системы. Технологически в основе гипертекста лежат компьютерные программы, которые поддерживают следующие базовые функции:
обеспечение быстрого просмотра информационного массива (браузинг);
обработка ссылочных отношений (обращение и вызов фрагмента текста или другой информации, на которую производится отсылка);
навигация по гипертексту, запоминание маршрута движения; представление пути движения в легко воспринимаемой форме;
возможность формирования обычного линейного текста как результата движения по гипертексту;
дополнение гипертекста новой информацией;
введение новых отношений в структуру гипертекста (для систем с жесткой структурой).
Программные оболочки гипертекста, как правило, универсальны. Они могут использоваться в различных областях для создания тематически разных гипертекстов. Таковы, например, оболочка ZOG и разработанная на ее основе промышленная гипертекстовая система KMS (университет Карнеги-Меллон, США). Сферы применения этих гипертекстовых систем необычайно разнообразны - от работы с документацией и поддержки электронной почты до гипертекстов, предназначенных для экспертов, работающих над бюджетом. Имеются и специализированные системы. Так, система NoteCards (продукт компании "Xerox PARC") предназначена для аналитической работы, а система WE, моделирующая особенности получения нового знания - для помощи в авторской работе. Наиболее популярны в настоящее время программные пакеты HyperCard компании "Apple". Они относительно просты в использовании. Гипертекст в оболочке HyperCard представляется в виде каталожных карточек. Пользователь с помощью довольно простого интерфейса организует структуру карточки и устанавливает связи между карточками. Пакеты HyperCard позволяют сочетать различные типы информации, в частности карточки могут включать графическую, звуковую и др. информацию. Следует отметить, что современные базы данных также включают поля для визуальной и звуковой формы данных (ср., например, базу данных ACCESS 7, работающую в среде Windows). Близка к HyperCard по своим свойствам и программа SuperCard фирмы "Silicon Beach". Некоторые системы гипертекста содержат специальные средства ориентации пользователя в гиперпространстве - карты или закладки, отмечающие наиболее посещаемые узлы гипертекста. Комплексом средств ориентации обладает система Hypergate Writer фирмы "Eastgate Systems Inc".
Литература
1. Баранов А.Н. Категории искусственного интеллекта в лингвистической семантике. Фреймы и сценарии. М., 1987.
2. Городецкий Б.Ю. Компьютерная лингвистика: моделирование языкового общения // Новое в зарубежной лингвистике. Вып. XXIV. Компьютерная лингвистика. М., 1989. С.5-31.
3. Войскунский А.Е. Моделирование мышления // Речевое общение: проблемы и перспективы. М., 1983. С.16-60.
4. Олкер X.Р. Волшебные сказки, трагедии и способы изложение мировой истории // Язык и моделирование социального взаимодействия. М., 1987. С.408-440.
5. Поспелов Д.А. Ситуационное управление. Теория и практика. М., 1986. С.71-83; 99-106.
6. Субботин М.М. Гипертекст. Новая форма письменной коммуникации // ВИНИТИ. Сер. Информатика. Т.18. М., 1994.