| Скачать .docx |
Реферат: Система управления баз данных
СУБД (система управления баз данных) — программный комплекс, предназначенная для создания, введения и использования баз данных.
Классификация СУБД:
· иерархические
· сетевые
· реляционные
· объектно-ориентированные
1. Иерархические БД
Могут быть представлены как дерево, состоящее из объектов различных уровней. Верхний уровень занимает один объект, второй — объекты второго уровня и т. д.Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможна ситуация, когда объект-предок не имеет потомков или имеет их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами.
Основными информационными единицами в иерархической модели данных являются сегмент и поле. Поле данных определяется как наименьшая неделимая единица данных, доступная пользователю. Для сегмента определяются тип сегмента и экземпляр сегмента. Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента — это поименованная совокупность входящих в него типов полей данных. Как и сетевая, иерархическая модель данных базируется на графовой форме построения данных, и на концептуальном уровне она является просто частным случаем сетевой модели данных. В иерархической модели данных вершине графа соответствует тип сегмента или просто сегмент, а дугам — типы связей предок — потомок. В иерархических структуpax сегмент — потомок должен иметь в точности одного предка. Иерархическая модель представляет собой связный неориентированный гpaф древовидной структуры, объединяющий сегменты. Иерархическая БД состоит из упорядоченного набора деревьев.
В рамках иерархической модели выделяют языковые средства описания данных (ЯОД) и средства манипулирования данными (ЯМД). Каждая физическая база описывается набором операторов, обусловливающих как ее логическую структуру, так и структуру хранения БД. При этом способ доступа устанавливает способ организации взаимосвязи физических записей.
Определены следующие способы доступа:
· иерархически последовательный;
· иерархически индексно-последовательный;
· иерархически прямой;
· иерархически индексно-прямой;
· индексный.
Помимо задания имени БД и способа доступа описания должны содержать определения типов сегментов, составляющих БД, в соответствии с иерархией, начиная с корневого сегмента. Каждая физическая БД содержит только один корневой сегмент, но в системе может быть несколько физических БД.
Среди операторов манипулирования данными можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической БД невелик, но вполне достаточен.
Иерархической базой данных является Каталог папок Windows , с которым можно работать, запустив Проводник. Верхний уровень занимает папка Рабочий стол . На втором уровне находятся папки Мой компьютер, Мои документы, Сетевое окружение и Корзина , которые являются потомками папки Рабочий стол , а между собой является близнецами. В свою очередь, папка Мой компьютер является предком по отношению к папкам третьего уровня -папкам дисков (Диск 3,5(А:), (С:), (D:), (Е:), (F:) ) и системным папкам (Принтеры, Панель управления и др.)
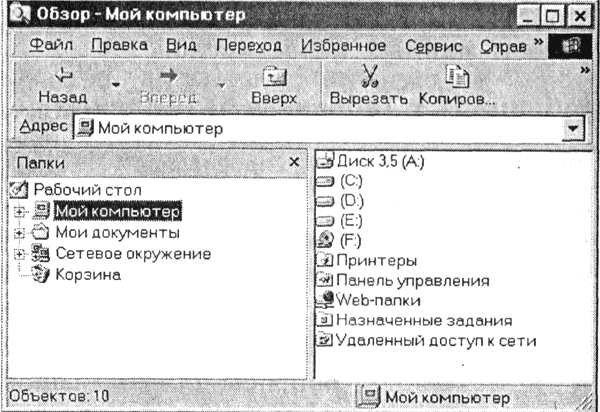 Иерархической базой данных является Реестр Windows
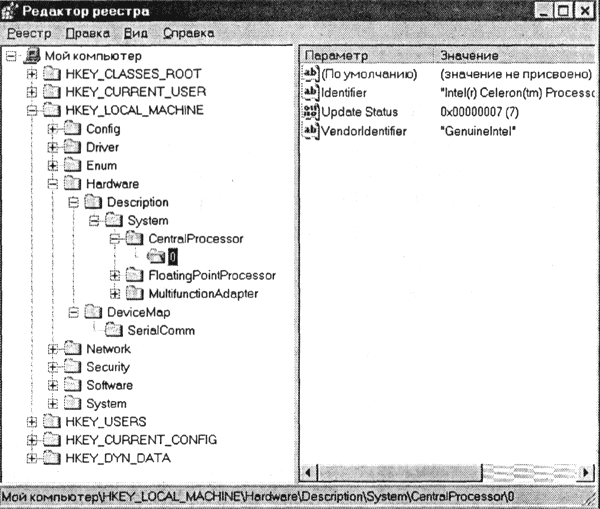
, в котором хранится вся информация, необходимая для нормального функционирования компьютерной системы (данные о конфигурации компьютера и установленных драйверах, сведения об установленных программах, настройки графического интерфейса и др.).
Иерархической базой данных является Реестр Windows
, в котором хранится вся информация, необходимая для нормального функционирования компьютерной системы (данные о конфигурации компьютера и установленных драйверах, сведения об установленных программах, настройки графического интерфейса и др.).
Содержание реестра автоматически обновляется при установке нового оборудования, инсталляции программ и т. п. Для просмотра и редактирования реестра Windows в ручном режиме можно использовать специальную программу rege-dit.exe, которая хранится в папке Windows. Однако редактирование реестра можно проводить только в случае крайней необходимости и при условии понимания выполняемых действий. Неквалифицированное редактирование реестра может привести компьютер в неработоспособное состояние.
Еще одним примером иерархической базы данных является база данных Доменная система имен подключенных к Интернету компьютеров. На верхнем уровне находится табличная база данных, содержащая перечень доменов верхнего уровня (всего 264 домена), из которых 7 - административные, а остальные 257 - географические. Наиболее крупным доменом (данные на январь 2002 года) является домен net (около 48 миллионов серверов), а в некоторых доменах (например, в домене zr) до сих пор не зарегистрировано ни одного сервера.
На втором уровне находятся табличные базы данных, содержащие перечень доменов второго уровня для каждого домена первого уровня.
На третьем уровне могут находиться табличные базы данных, содержащие перечень доменов третьего уровня для каждого домена второго уровня, и таблицы, содержащие IP-адреса компьютеров, находящихся в домене второго уровня.
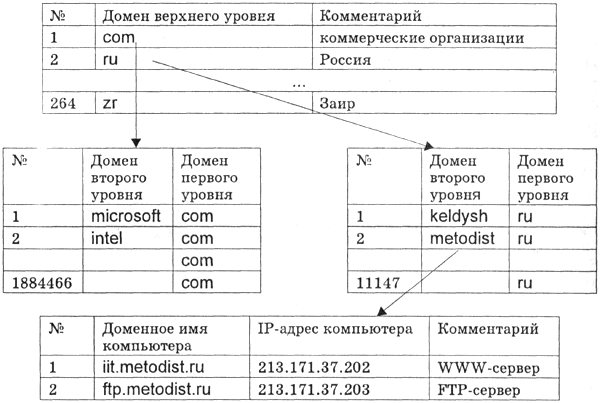
База данных Доменная система имен должна содержать записи обо всех компьютерах, подключенных к Интернету, то есть более 150 миллионов записей. Размещение такой огромной базы данных на одном компьютере сделало бы поиск информации очень медленным и неэффективным. Решение этой проблемы было найдено путем размещения отдельных составных частей базы данных на различных DNS-серверах. Таким образом, иерархическая база данных Доменная система имен является распределенной базой данных .
Поиск информации в такой иерархической распределенной базе данных ведется следующим образом. Например, мы хотим ознакомиться с содержанием WWW-сервера фирмы Microsoft.
Сначала наш запрос, содержащий доменное имя сервера www.microsoft..com, будет оправлен на DNS-сервер нашего провайдера, который переадресует его на DNS-сервер самого верхнего уровня базы данных. В таблице первого уровня будет найден интересующий нас домен com и запрос будет адресован на DNS-сервер второго уровня, который содержит перечень доменов второго уровня, зарегистрированных в домене com.
В таблице второго уровня будет найден домен microsoft и запрос будет переадресован на DNS-сервер третьего уровня. В таблице третьего уровня будет найдена запись, соответствующая доменному имени, содержавшемуся в запросе. Поиск информации в базе данных Доменная система имен будет завершен и начнется поиск компьютера в сети по его IP-адресу.
2. Сетевые БД
Сетевая СУБД - система управления базами данных, поддерживающая сетевую организацию: любая запись, называемая записью старшего уровня, может содержать данные, которые относятся к набору других записей, называемых записями подчиненного уровня.
Типичным представителем является Integrated Database Management System появилась в 70-х годах. Сетевой подход к организации данных является расширением иерархического. Сетевая БД состоит из набора записей и набора связей между этими записями. На формирование связи особых ограничений не накладывается. В иерархических структурах запись-потомок должна иметь в точности одного предка; в сетевой структуре данных потомок может иметь любое число предков. Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности. В сравнении с иерархической моделью сетевая модель предоставляет большие возможности в смысле допустимости образования произвольных связей. В рамках сетевых СУБД легко реализуются и иерархические даталогические модели. Сетевые СУБД поддерживают сложные соотношения между типами данных, что делает их пригодными во многих различных приложениях. Однако пользователи таких СУБД ограничены связями, определенными для них разработчиками БД-приложений. Более того, подобно иерархическим сетевые СУБД предполагают разработку БД приложений опытными программистами и системными аналитиками.
Недостатком сетевой модели данных является высокая сложность и жесткость схемы БД, построенной на ее основе, а также сложность для понимания и выполнения обработки информации в БД обычным пользователем. Кроме того, в сетевой модели данных ослаблен контроль целостности связей вследствие допустимости установления произвольных связей между записями.
Просматривая, к примеру, в сетевой СУБД записи объекта «Лицо» и выбрав запись «Иванов» (т. е. поместив табличный курсор на соответствующую запись), можно через активизацию поля «Работает» вызвать на экран поля связанной записи в объекте «Организация» и просмотреть соответствующие данные, а далее, при необходимости, через активизацию поля «Адрес» в записи по объекту «Организация» вызвать и просмотреть данные по дислокации места работы сотрудника «Иванов» и т. д.
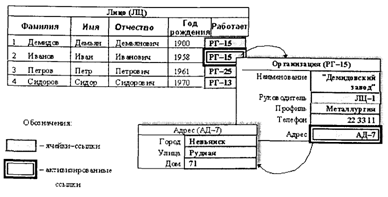
Данный пример показывает, что навигационные возможности сетевых СУБД позволяют пользователю реализовывать свои информационные потребности («беседовать» с базой данных) более естественным интерактивным способом, шаг за шагом уточняя свои потребности, и тем самым более глубоко и наглядно анализировать (изучать) данные.
3. Реляционные БД
К.Дейт в своей классической книге "Введение в системы баз данных" дает следующее определение реляционной системы управления базами данных:
1. Данные воспринимаются пользователем как таблицы (и никак иначе).
2. В распоряжении пользователя имеются операторы, которые генерируют новые таблицы из старых.
Одна из непосредственных задач СУБД (здесь и далее речь идет о реляционных СУБД, поэтому слово "реляционный" опускается) - осуществлять контроль целостности данных. Под целостностью данных подразумевается логическая непротиворечивость данных. Различают три понятия целостности:
1. Целостность в отношении конкретной базы - такие данные, как возраст, рост, вес не могут быть отрицательными. IP-адрес имеет строго заданный формат - это четыре числа в диапазоне от 0 до 255, разделенных точкой, плюс дополнительные ограничения на использование 0, 255 и спецадресов. Большинство СУБД не предоставляют механизмов, в полной мере позволяющих контролировать данный тип целостности.
2. Целостность сущностей - в таблице, где хранятся записи об объектах, не может быть двух одинаковых объектов, а также не может быть неопределенных объектов, т.е. записей с неопределенным значением (NULL-значением) первичного ключа. СУБД не должна допускать записей с повторяющимися значениями первичного ключа или NULL-значением одного из компонентов первичного ключа. Данный тип целостности поддерживают все СУБД. Более подробно мы поговорим об этом понятии целостности ниже, при описании первичных ключей.
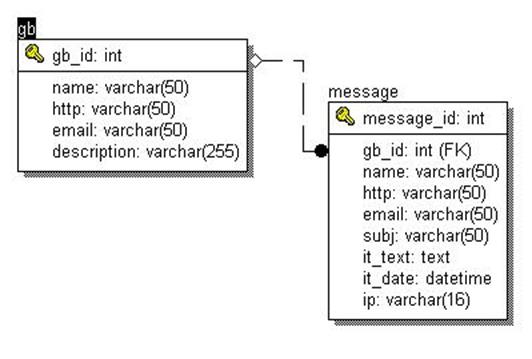
3. Ссылочная целостность - одной записи в таблице гостевых книг может соответствовать несколько записей в таблице сообщений. Таблицы могут находиться во взаимосвязях один к одному, один ко многим и многие ко многим. Связи между таблицами осуществляются на основании внешних ключей. В таблице сообщений не может быть сообщения, принадлежащего к несуществующей гостевой книге, иначе говоря, любой записи в таблице сообщений должна найтись запись в таблице гостевых книг. СУБД должна предоставлять механизмы для контроля операций и соблюдения ссылочной целостности при выполнении операций INSERT, UPDATE и DELETE. К сожалению, не все СУБД имеют такие механизмы.
Помимо невысокой эффективности, к недостаткам традиционных реляционных СУБД можно отнести факт того, что в качестве основного и, часто, единственного механизма, обеспечивающего быстрый поиск и выборку отдельных строк таблице (или в связанных через внешние ключи таблицах), обычно используются различные модификации индексов, основанных на B-деревьях. Такое решение оказывается эффективным только при обработке небольших групп записей и высокой интенсивности модификации данных в базах данных.
Рассмотрим более детально все три понятия целостности данных по порядку. К первому типу целостности относятся такие механизмы СУБД, как ограничение на диапазон допустимых значений, триггеры и транзакции. К сожалению, пока ни один из этих механизмов не поддерживается СУБД MySQL, поэтому, если ваши сайты будут базироваться на данной СУБД, то вам придется обождать до появления данных возможностей. Ограничения на значения должны появится уже в четвертой версии MySQL. При помощи ограничений на значения можно задать ограничение на формат адреса электронной почты.
email varchar(32) CHECK (email LIKE '%@%'),
Тем самым, запретив значения, которые не содержат знака '@'. Большинство же информационных систем применительно к веб-сайтам, будь то конференции, чаты, списки рассылки, имеют довольно простую структуру базы данных, обычно не превышающую 5-7 таблиц. В таких системах целостность данных не имеет критического значения. В случае ввода неправильного адреса электронной почты ничего катастрофического не произойдет, поэтому контроль за целостностью данных можно переложить на приложения, т.е. CGI-программы.
Механизм триггеров позволяет СУБД контролировать операции INSERT, UPDATE и DELETE на предмет допустимости этих операций. Например, таким образом, вы можете ограничить число публикуемых сообщений в день от одного пользователя или запретить вводить сообщения, длиной более 255 символов, лицам, незаполнившим поля email и http.
И наконец, последний механизм транзакций, о котором вам необходимо иметь представление, позволяет контролировать выполнение блоков SQL-запросов. Транзакция представляет собой набор SQL-запросов, и СУБД гарантирует, что либо все эти запросы будут выполнены, либо же ни один из них не будет выполнен. Транзакции могут применятся при вставке, изменении и удалении данных в нескольких таблицах. Например, вам необходимо в системе гостевых книг объединить две гостевые книги в одну. Для этого необходимо изменить идентификатор гостевой книги gb_id в таблице сообщений, удалить одну запись из таблицы гостевых книг и, возможно, модифицировать запись о первой гостевой книге. И мы должны быть полностью уверены в том, что либо эти операции пройдут успешно, либо же не будет выполнена ни одна из них.
Далее мы рассмотрим целостность сущностей. Как уже было сказано выше, целостность сущностей базируется на первичном ключе. Мы дадим определение первичного ключа и рассмотрим ряд примеров таблицы и методов выбора первичных ключей.
Первичный ключ
- это столбец или группа столбцов в одной таблице таких, что не может существовать двух записей с одинаковым значением этого столбца или группы столбцов, причем для случая группы столбцов никакое подмножество столбцов не является уникальным.
Можно выделить принципиально различающиеся три случая:
1. в таблице отсутствует первичный ключ;
2. простой первичный ключ, т.е. состоящий из одного столбца;
3. составной первичный ключ, т.е. состоящий из нескольких столбцов.
Рассмотрим первый случай, когда в таблице может и не быть первичного ключа, как, например, в таблице hit в системе анализа посетителей веб-сайта. В этой таблице просто нет столбцов, которые могли бы образовать первичный ключ. В таблице, чисто теоретически, с очень малой долей вероятности могут быть полностью одинаковые строки. Один пользователь может запустить на своем компьютере два броузера и открыть в них страницу нашего сайта. Из-за того, что ни операционная система, ни протокол TCP\IP не работают в реальном времени, и в них имеются задержки по времени, есть вероятность того, что открытие в этих броузерах нашей страницы произойдет одновременно. Соответственно, поскольку броузеры одни и те же, работают на одном компьютере, то программа counter внесет в таблицу hit две одинаковые строчки. Также небольшое пояснение, что CGI-программа counter может быть запущена одновременно несколько раз, и что сервер тоже работает не в реальном времени, поэтому и есть вероятность появления одинаковых строк.
В таблице hit нет необходимости различать записи, т.е. иметь первичный ключ. Если бы такая необходимость была, то можно было бы добавить в таблицу счетчик записей. В СУБД MYSQL это делается следующим образом:
CREATE TABLE hit(
hit_id int(10) unsigned NOT NULL auto_increment,
...
)
При вставке новой записи hit_id будет увеличиваться на единицу, тем самым мы получим возможность различать записи внутри таблицы. В системе гостевых книг первичными ключами являются поля gb_id в таблице гостевых книг и message_id в таблице сообщений. На практике чаще всего встречается именно такой способ назначения и использования первичных ключей. В таблицах системы гостевых книг первичные ключи служат для идентификации записей и установления отношения один ко многим. В классической теории для соблюдения целостности сущностей необходимо назначать первичным ключом столбец или группу столбцов, которые однозначно идентифицируют объект. Но в реальности, зачастую, таких столбцов может и не быть. Ни в таблице сообщений, ни в таблице гостевых книг нет осмысленной группы столбцов, которую бы можно было назначить первичным ключом. В данном случае, первичным ключом можно только сделать все столбцы таблицы сообщений, но, в этом случае, мы осложняем себе жизнь при выборе конкретного сообщения. В запросе SELECT * FROM message WHERE name='name' AND email='email' AND... придется перечислить совпадение для каждого столбца. Такая выборка будет происходить медленно, т.к. нужно затратить время, чтобы выполнить сравнение для каждого столбца. Гораздо удобнее ввести счетчик, тогда запрос будет выглядеть значительно проще: SELECT * FROM message WHERE id='id'.
Если же у вас в таблице имеется все же столбец или несколько столбцов, однозначно идентифицирующих объект, то их бесспорно стоит назначить первичным ключом. Например, у вас база данных по автомобилям, в этом случае, первичным ключом будет номер автомобиля. Не стоит пугаться того, что номер автомобиля представляется символьной строкой. Когда вы назначаете столбец или группу столбцов первичным ключом, по ним автоматически создается индекс. Индекс представляет собой хеш-таблицу, т.е. таблицу из двух колонок: в первой колонке в отсортированном порядке идут значения первичного ключа, а во второй колонке - указатель на то место, где лежит полная запись таблицы. Поскольку первая колонка отсортирована, то операции поиска по такой таблице происходят на порядок быстрее, чем если бы индекса не было. Для всех полей таблицы, которые участвуют в предложении WHERE SQL-запросов, надо обязательно создавать индексы. Однако, учтите, что индекс ускоряет поиск только в случае, если его значения слабо повторяются. Одним словом, если вы сделаете индекс по полю "пол", то никакого ускорения не получится, т.к. половина хеш-таблицы будет состоять из одних записей, а половина из других. В MySQL индекссоздаетсяследующейкомандой:
CREATE [UNIQUE] INDEX index_name ON tablename (column1, column2, ...)
Составной первичный ключ может быть в таблице по персоналиям, где серия и номер паспорта представлены в отдельных колонках. В этом случае эти две колонки будут образовывать составной первичный ключ.
Внешний ключ
- это столбец или группа столбцов в одной таблице R1, совпадающих по типу данных с первичным ключом в таблице R2, и каждому значению этого столбца или группы столбцов в таблице R1 обязательно должно найтись совпадающее с ним значение в таблице R2.
Далее мы рассмотрим типы отношений между таблицами:
- Отношение один ко многим
- Отношение многие ко многим
- Отношение один к одному
Отношение один ко многим мы уже детально рассмотрели на примере системы гостевых книг. Данного типа отношения реализуются при помощи внешнего ключа в одной таблице, который ссылается на первичный ключ другой таблицы.
Рассмотрим пример базы данных системы конференций. На конференцию авторами докладов подаются статьи. У каждой статьи может быть несколько авторов. У каждого автора может быть несколько статей. Подобного рода отношения называются многие ко многим и реализуются при помощи дополнительной таблицы с двумя внешними ключами, которые образуют первичный ключ.
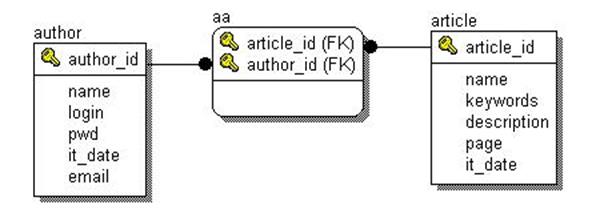
Мы видим таблицу авторов, которая относится к таблице aa (сокращение от authorarticle), как один ко многим. Это означает, что для одной записи в таблице авторов может быть несколько записей в таблице aa. Аналогичным образом и таблица статей относится к таблице aa, как один ко многим. А между таблицами авторов и статей реализуется отношение многие ко многим.
4. Объектно-ориентированные БД
В наиболее общей и классической постановке объектно-ориентированный подход базируется на концепциях:
1. объекта и идентификатора объекта;
2. атрибутов и методов;
3. классов;
4. иерархии и наследования классов.
Непосредственным предшественником объектно-ориентированных СУБД являются системы, поддерживающие организацию сложных объектов. Эти постреляционные системы большей частью появились по причине несоответствия возможностей реляционных СУБД потребностям нетрадиционных приложений (автоматизация проектирования, инженерия и т.д.). По сути дела, в таких системах частично поддерживается структурная часть ООБД (без возможностей наследования). Многие объектно-ориентированные СУБД (в частности, ORION) разрабатывались на базе предыдущих работ со сложными объектами.
Другой основой объектно-ориентированных СУБД являются так называемые расширяемые системы. Основная идея таких систем состоит в поддержании набора модулей с четко оговоренными интерфейсами, на базе которого можно быстро построить СУБД, опирающуюся на конкретную модель данных или предназначенную для конкретной области применений. В частности, как показывает опыт системы EXODUS, средства расширяемых систем хорошо пригодны и для построения объектно-ориентированной СУБД.
Наибольшую функциональную нагрузку несет компонент управления объектами. В число функций этой подсистемы входит:
- управление сложными объектами, включая создание и уничтожение объектов, выборку объектов по именам, поддержку предопределенных методов, поддержку объектов со внутренней структурой-множеством, списком и кортежем;
- управление передачей сообщений между объектами;
- управление транзакциями;
- управление коммуникационной средой (на базе транспортных протоколов TCP/IP в локальной сети Ethernet);
- отслеживание долговременно хранимых объектов (напомним, что в O2 объект хранится во внешней памяти до тех пор, пока достижим из какого-либо долговременно хранимого объекта);
- управление буферами оперативной памяти (аналогично ORION, представление объекта в оперативной памяти отличается от его представления на диске);
- управление кластеризацией объектов во внешней памяти;
- управление индексами.