| Скачать .docx |
Реферат: Динамическое программирование, алгоритмы на графах
Министерство образования Республики Беларусь
Учреждение образования
«Гомельский государственный университет им. Ф. Скорины»
Математический факультет
Кафедра МПМ
Реферат
Динамическое программирование, алгоритмы на графах
Исполнитель:
Студентка Старовойтова А.Ю.
Научный руководитель:
Канд. физ-мат. наук, доцент Лебедева М.Т.
Гомель 2007
Содержание
Введение
1. Алгоритмы, использующие решение дополнительных подзадач
2. Основные определения теории графов
3. Поиск пути между парой вершин невзвешенного графа
4. Пути минимальной длины во взвешенном графе
Заключение
Литература
Введение
Существует целый класс задач по программированию, которые проще решаются, если ученик владеет определенным набором знаний, умений и навыков в области алгоритмов на графах. Это происходит потому, что такие задачи могут быть переформулированы в терминах теории графов.
Теория графов содержит огромное количество определений, теорем и алгоритмов. И поэтому данный материал не может претендовать, и не претендует, на полноту охвата материала. Однако, по мнению автора, предлагаемые сведения являются хорошим компромиссом между объемом материала и его "коэффициентом полезного действия" в практическом программировании и решении олимпиадных задач.
Иногда решение основной задачи приходится формулировать в терминах несколько модифицированных подзадач. Именно такие проблемы рассматриваются в данной работе.
1. Алгоритмы, использующие решение дополнительных подзадач
Задача 9 . Требуется подсчитать количество различных разбиений числа N на натуральные слагаемые. Два разложения считаются различными, если одно нельзя получить из другого путем перестановки слагаемых.
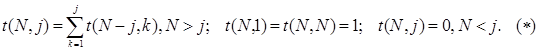
Решение. Для того чтобы подсчитать количество различных разбиений числа N на произвольные натуральные слагаемые, предварительно подсчитаем количества разбиений на следующие группы слагаемых: 1) разбиения только на единицы (очевидно, что для любого числа такое разбиение единственно); 2) разбиения на единицы и двойки такие, что хотя бы одна двойка в разбиении присутствует и т.д. Последнюю группу представляет само число N . Очевидно, что каждое разбиение числа N можно приписать только к одной из рассмотренных групп, в зависимости от значения j — максимального слагаемого в том или ином разбиении. Обозначим количество разбиений в каждой из групп t (N , j ). Тогда искомое количество разбиений равно сумме разбиений по всем возможным группам. Введение таких подзадач приводит к несложному способу подсчета числа разбиений. А именно, так как в любом из разбиений j -ой группы присутствует число j , то мы можем вычесть из N число j и сложить разбиения уже числа N – j на слагаемые, не превосходящие j . То есть мы пришли к следующему рекуррентному соотношению:
Теперь очевидно, что если мы имеем возможность завести двумерный массив размером N ´N , и будем заполнять его в порядке возрастания номеров строк, то задача будет легко решена. Однако легко заметить, что решения части подзадач никак не участвуют в формировании решения. Например, при вычислении количества разбиений числа 10 на слагаемые будут получены, но не использованы значения t (9, j ) для j = 2..9 и т. д. Для того чтобы не производить лишних вычислений, применим динамическое программирование “сверху вниз” (все предыдущие задачи решались “снизу вверх”). Для этого задачу будем решать все же рекурсивно, используя формулу (*), но ответы к уже решенным подзадачам будем запоминать в таблице. Первоначально таблица пуста (вернее заполним элементы, значение которых по формуле (*) равно 0 или 1, а остальные значения, например, числом -1). Когда в процессе вычислений подзадача встречается первый раз, ее решение заносится в таблицу. В дальнейшем решение этой подзадачи берется из таблицы. Таким образом мы получили прием улучшения рекурсивных алгоритмов, а “лишние” подзадачи теперь решаться не будут.
Приведем программу для решения этой задачи.
var i,j,k,n:byte;
sum:longint;
table:array[1..120,1..120] of longint;
function t(n,k:byte):longint;
var i,s:byte;
begin
if table[n,k]<0 then
{остальные элементы не пересчитываем}
begin
table[n,k]:=0;
for i:=1 to k do
inc(table[n,k],t(n-k,i))
end;
t:=table[n,k]
end;
begin
read(n);
fillchar(table,sizeof(table),0);
for i:=1 to n do
begin
table[i,i]:=1;
table[i,1]:=1
end;
{неопределенные элементы метим –1}
for i:=2 to n do
for j:=2 to i-1 do
table[i,j]:=-1;
sum:=0;
for i:=1 to n do
sum:=sum+t(n,i);
writeln('sum=',sum)
end.
Задача 10 . Плитки (Чемпионат школьников по программированию, Санкт-Петербург, 1999 г. ).
У Пети имеется неограниченный набор красных, синих и зеленых плиток размером 1´1. Он выбирает ровно N плиток и выкладывает их в полоску. Например, при N = 10 она может выглядеть следующим образом:
| К | К | К | С | З | К | К | З | К | С |
(Буквой К обозначена красная плитка, С – синяя, З – зеленая)
После этого Петя заполняет следующую таблицу, которая в данном примере выглядит так:
| Красный | Синий | Зеленый | |
| Красный | Y | Y | Y |
| Синий | Y | N | Y |
| Зеленый | Y | Y | N |
В клетке на пересечении строки, отвечающей цвету А, и столбца, отвечающего цвету Б, он записывает "Y", если в его полоске найдется место, где рядом лежат плитки цветов А и Б и "N" в противном случае. Считается, что плитки лежат рядом, если у них есть общая сторона. (Очевидно, что таблица симметрична относительно главной диагонали – если плитки цветов А и Б лежали рядом, то рядом лежали и плитки цветов Б и А.) Назовем такую таблицу диаграммой смежности данной полоски.
Так, данная таблица представляет собой диаграмму смежности приведенной выше полоски.
Помогите Пете узнать, сколько различных полосок имеет определенную диаграмму смежности (заметьте, что полоски, являющиеся отражением друг друга, но не совпадающие, считаются разными. Так, полоска
| С | К | З | К | К | З | С | К | К | К |
не совпадает с полоской, приведенной в начале условия.)
Первая строка входного файла содержит число N
. (![]() ). Следующие три строки входного файла, содержащие по три символа из набора {“Y”, “N”}, соответствуют трем строкам диаграммы смежности. Других символов, включая пробелы, во входном файле не содержится. Входные данные корректны, т.е. диаграмма смежности симметрична.
). Следующие три строки входного файла, содержащие по три символа из набора {“Y”, “N”}, соответствуют трем строкам диаграммы смежности. Других символов, включая пробелы, во входном файле не содержится. Входные данные корректны, т.е. диаграмма смежности симметрична.
Выведите в выходной файл количество полосок длины N , имеющих приведенную во входном файле диаграмму смежности. Ниже дан пример входного и выходного файлов.
| Input.txt | Output.txt |
10 YYY YNY YYN |
4596 |
Решение. Очевидно, что перебор всех возможных полосок в данной задаче невозможен, так как их количество может составить 2100 , поэтому следует попытаться найти динамическую схему решения. Понятно, что для того чтобы подсчитать количество полосок длины N , удовлетворяющих заданной диаграмме смежности, необходимо знать количество допустимых полосок длины N – 1, а также количество полосок, в диаграмме смежности которых один диагональный элемент или два симметричных недиагональных элемента равны “N” вместо “Y” в исходной диаграмме. Далее, при рассмотрении полосок длины N – 2, потребуется знать количество полосок, удовлетворяющих еще большему количеству диаграмм смежности и т. д. В результате на каком то шаге нам может понадобиться информация о количестве полосок практически со всеми возможными диаграммами. Общее количество последних составляет 26 = 64 (уникальными, то есть не повторяющимися, а, значит, определяющими количество различных диаграмм, являются только 6 элементов). Так как при увеличении длины полоски диаграмма может измениться в зависимости от сочетания цветов в последнем (новом) и предпоследнем элементах, подсчитывать полоски следует отдельно для трех различных конечных элементов. Таким образом количество хранимой информации возрастает до 64´3 = 192 значений. Столько же значений будет получено в результате пересчета. Но благодаря тому, что количество полосок длины i выражается только через количество полосок длины i – 1, хранить нужно лишь эти 2´192 = 384 значения. Несмотря на малый размер таблицы (массив total в программе) следует отметить, что ее размер экспоненциально зависит от одного из входных параметров — количества цветов k , а именно: 2´k ´2k (k +1)/2 . Например, для 8 цветов необходимо было бы хранить 240 элементов, что нереально. Этим данная задача отличается от рассмотренных ранее.
Осталось обсудить некоторые технические приемы, позволяющие написать довольно простую программу, реализующую описанный алгоритм. Если мы поставим в соответствие каждому из уникальных мест в диаграмме смежности свою степень двойки от 20 до 25 (см. массив констант magic в программе), то каждой диаграмме может быть поставлен в соответствие номер от 0 до 63, равный сумме тех степеней двоек, которые соответствуют значениям “Y” (см. процедуру findcode). Если мы подсчитываем количество полосок для диаграммы с номером j , то совместимость добавляемого цвета k стоявшему ранее последним цвету l согласно диаграмме j можно проверить так: magic[k, l] and j <> 0. Данное условие, построенное с помощью битовой операции над целыми числами and, означает наличие в j- ой диаграмме смежности элемента “Y” на пересечении k -й строки и l -го столбца (соответствующая степень двойки массива magic содержится в двоичном представлении числа j ). Выражение j - magic[k, l] соответствует замене в диаграмме с номером j упомянутого элемента “Y” на “N” (по другому это выражение можно было бы записать как j xor magic[k, l]). Подробнее о битовых операциях над целыми числами можно прочитать в [1]. Последний прием заключается в том, что мы не будем на каждом шаге переприсваивать полученные значения элементам массива, предназначенного для хранения результатов предыдущего шага. Для этого результаты для полосок четной длины i будем помещать в половину массива total с первым индексом 0, а нечетные — с индексом 1. В любом из этих случаев значения предыдущего шага доступны по индексу [1 – i mod 2]. Кроме того, ответ на решение этой задачи при всех N , удовлетворяющих условию, требует самостоятельной организации вычислений с помощью так называемой “длинной арифметики” (см., например, [1, 3]).
Приведем программу для решения этой задачи, но использующую вместо “длинной арифметики” тип данных extended, сохраняющий максимально возможное количество значащих цифр (попробуйте модернизировать программу самостоятельно). То есть не для всех значений N ответ будет вычислен точно. Но, так как для получения результата используется только сложение целых чисел, потери точности при промежуточных вычислениях не будет, по крайней мере пока ответ не станет превышать 263 .
{$N+}
const magic: array [1..3, 1..3] of byte =
((1, 2, 4),
(2, 8, 16),
(4, 16, 32));
var n,i,j,k,l,code: longint;
can: array [1..3, 1..3] of boolean;
total: array [0..1, 1..3, 0..63] of extended;
answer: extended;
procedure readdata;
var s: string;
i, j: byte;
begin
readln(n);
fillchar(can, sizeof(can), false);
for i:= 1 to 3 do
begin
readln(s);
for j:= 1 to 3 do
if upcase(s[j]) = 'Y' then
begin
can[i, j]:= true;
can[i, j]:= true
end
end
end;
procedure findcode;
var i, j: byte;
begin
{переводим диаграмму смежности в число}
code:= 0;
for i:= 1 to 3 do
for j:= i to 3 do
if can[i, j] then
code:= code + magic[i, j]
end;
begin
assign(input, 'input.txt');
reset(input);
assign(output,'output.txt');
rewrite(output);
readdata;
findcode;
fillchar(total, sizeof(total), 0);
{количество полосок длины 1}
for i:= 1 to 3 do
total[1, i, 0]:= 1;
for i:= 2 to n do
for j:= 0 to 63 do
for k:= 1 to 3 do
{cчитаем полоски длины i,
c диаграммой смежности j
и оканчивающиеся цветом k}
begin
total[i mod 2, k, j]:= 0;
for l:= 1 to 3 do
{цикл по конечному цвету
полосок длины i - 1}
if magic[k, l] and j <> 0 then
{цвета l и k могут соседствовать
согласно диаграмме смежности j}
begin
total[i mod 2, k, j]:=
total[i mod 2, k, j] +
total[1 - i mod 2, l, j];
total[i mod 2, k, j]:=
total[i mod 2, k, j] +
total[1 - i mod 2, l, j - magic[k, l]]
end
end;
answer:= 0;
{суммируем количество полосок с диаграммой
смежности code и различными окончаниями}
for i:=1 to 3 do
answer:=answer + total[n mod 2, i, code];
writeln(answer:0:0)
end.
Похожая задача (“Симпатичные узоры”) предлагалась и на I-ой Всероссийской командной олимпиаде по программированию. Ее условие и решение можно прочитать в [2].
Задача 11 . Паркет (Задача VI Всероссийской олимпиады по информатике, 1994 г. )
Комнату размером N ´M единиц требуется покрыть одинаковыми паркетными плитками размером 2´1 единицу без пропусков и наложений (1 £N £ 20, 1 £M £ 8). Требуется определить количество всех возможных способов укладки паркета для конкретных значений N и M .
Решение. Пусть M — ширина комнаты, которую мы зафиксируем. Попытаемся выразить искомое количество укладок паркета для комнаты длины N , через количество укладок для комнаты длиной N – 1. Однако очевидно, что сделать это не удастся, так как существует еще множество укладок, в которых часть плиток пересекает границу между такими комнатами. Следовательно нам опять придется решать дополнительное число подзадач. А именно, введем обобщенное понятие укладки комнаты длиной N – 1: первая часть комнаты длиной N – 2 уложена плотно, а в (N – 1)-й единице измерения длины комнаты могут находиться пустоты (в N -й единице измерения паркета нет). Если наличие плитки в (N – 1)-й единице измерения обозначить 1, а ее отсутствие — 0, то количество различных окончаний подобных укладок можно пронумеровать двоичными числами от 0 до 2M – 1. Если количество укладок для каждого из окончаний нам известно (часть из них могут оказаться нереализуемыми, то есть соответствующее количество укладок будет равно 0), то мы сможем подсчитать количество различных укладок комнаты длины N . При этом придется проверять совместимость окончаний. Окончания будем считать совместимыми, если путем добавления целого числа плиток к укладе длиной N – 1 с окончанием j , таких что каждая из них увеличивает длину укладки до N , мы можем получить окончание i укладки длиной N . Если способ совмещения укладок существует, то по построению он единственен. Тогда для определения количества укладок с окончанием i длиной N необходимо просуммировать количества укладок длиной N – 1 с совместимыми окончаниями. Для комнаты нулевой длины будем считать количество укладок равным 1. Формирование динамической схемы закончено. Количество хранимых в программе значений при этом равно 2´2M =2M +1 , то есть оно экспоненциально зависит от одного из параметров задачи и существенно его увеличить не представляется возможным. В нашем случае оно равно 512, то есть применение табличного метода решения оказывается реальным. Ответ на вопрос задачи будет получен на N -м шаге алгоритма в элементе таблицы с номером 2M – 1. При максимальном по условию задачи размере комнаты для получения ответа опять потребуется “длинная арифметика”.
Схему программы для решения этой задачи, которая проще предыдущей, можно найти, например, в [3].
После рассмотрения задач 9-11 может сложиться впечатление, что к данному классу относятся лишь задачи подсчета количеств тех или иных конфигураций, в том числе комбинаторных. Конечно же это не так. Примером оптимизационной задачи, решение которой основано на аналогичных идеях, служит задача “Бизнес-классики”, предлагавшаяся на XIII Всероссийской олимпиаде по программированию (см. [4]).
Многие прикладные и олимпиадные задачи легко сформулировать в терминах такой структуры данных как граф. Для ряда подобных задач хорошо изучены эффективные (полиномиальные) алгоритмы их решения. Рассмотрим в данной лекции те из них, которые используют идеи динамического программирования. Но прежде необходимо познакомиться с некоторыми терминами, встречающимися при описании этой структуры.
2. Основные определения теории графов
Графом
называется пара ![]() , где V
– некоторое множество, которое называют множеством вершин
графа, а E
– отношение на V
(
, где V
– некоторое множество, которое называют множеством вершин
графа, а E
– отношение на V
(![]() ) - множество ребер
графа. То есть все ребра из множества E
соединяют некоторые пары точек из V
.
) - множество ребер
графа. То есть все ребра из множества E
соединяют некоторые пары точек из V
.
Если отношение E
симметричное (т.е. ![]() ), то граф называют неориентированным
, в противном случае граф называют ориентированным
. Фактически для каждого из ребер ориентированного графа указаны начало и конец, то есть пара (u
, v
) упорядочена, а в неориентированном графе (u
, v
) = (v
, u
).
), то граф называют неориентированным
, в противном случае граф называют ориентированным
. Фактически для каждого из ребер ориентированного графа указаны начало и конец, то есть пара (u
, v
) упорядочена, а в неориентированном графе (u
, v
) = (v
, u
).
Если в графе существует ребро (u , v ), то говорят, что вершина v смежна с вершиной u (в ориентированном графе отношение смежности несимметрично).
Путем
из вершины u
в вершину v
длиной k
ребер называют последовательность ребер графа ![]() . Часто тот же путь обозначают последовательностью вершин
. Часто тот же путь обозначают последовательностью вершин ![]() . Если для данных вершин u
, v
существует путь из u
в v
, то говорят, что вершина v
достижима
из u
. Путь называется простым
, если все вершины в нем различны. Циклом
называется путь, в котором начальная вершина совпадает с конечной. При этом циклы, отличающиеся лишь номером начальной точки, отождествляются.
. Если для данных вершин u
, v
существует путь из u
в v
, то говорят, что вершина v
достижима
из u
. Путь называется простым
, если все вершины в нем различны. Циклом
называется путь, в котором начальная вершина совпадает с конечной. При этом циклы, отличающиеся лишь номером начальной точки, отождествляются.
Граф называется связанным , если для любой пары его вершин существует путь из одной вершины в другую.
Если каждому ребру графа приписано какое-то число (вес ), то граф называют взвешенным .
При программировании вершины графа обычно сопоставляют числам от 1 до N
, где ![]() - количество вершин графа, и рассматривают
- количество вершин графа, и рассматривают ![]() . Ребра нумерую числами от 1 до M
, где
. Ребра нумерую числами от 1 до M
, где ![]() . Для хранения графа в программе можно применить различные методы. Самым простым является хранение матрицы смежности
, т.е. двумерного массива, скажем A
, где для невзвешенного графа
. Для хранения графа в программе можно применить различные методы. Самым простым является хранение матрицы смежности
, т.е. двумерного массива, скажем A
, где для невзвешенного графа ![]() (или 1), если
(или 1), если ![]() и
и ![]() (или 0) в противном случае. Для взвешенного графа A
[i
][j
] равно весу соответствующего ребра, а отсутствие ребра в ряде задач удобно обозначать бесконечностью. Для неориентированных графов матрица смежности всегда симметрична относительно главной диагонали (i
= j
). C помощью матрицы смежности легко проверить, существует ли в графе ребро, соединяющее вершину i
с вершиной j
. Основной же ее недостаток заключается в том, что матрица смежности требует, чтобы объем памяти памяти был достаточен для хранения N
2
значений, даже если ребер в графе существенно меньше, чем N
2
. Это не позволяет построить алгоритм со временем порядка O
(N
) для графов, имеющих O
(N
) ребер.
(или 0) в противном случае. Для взвешенного графа A
[i
][j
] равно весу соответствующего ребра, а отсутствие ребра в ряде задач удобно обозначать бесконечностью. Для неориентированных графов матрица смежности всегда симметрична относительно главной диагонали (i
= j
). C помощью матрицы смежности легко проверить, существует ли в графе ребро, соединяющее вершину i
с вершиной j
. Основной же ее недостаток заключается в том, что матрица смежности требует, чтобы объем памяти памяти был достаточен для хранения N
2
значений, даже если ребер в графе существенно меньше, чем N
2
. Это не позволяет построить алгоритм со временем порядка O
(N
) для графов, имеющих O
(N
) ребер.
Этого недостатка лишены такие способы хранения графа, как одномерный массив длины N списков или множеств вершин. В таком массиве каждый элемент соответствует одной из вершин и содержит список или множество вершин, смежных ей.
Для реализации некоторых алгоритмов более удобным является описание графа путем перечисления его ребер. В этом случае хранить его можно в одномерном массиве длиной M , каждый элемент которого содержит запись о номерах начальной и конечной вершин ребра, а также его весе в случае взвешенного графа.
Наконец, при решении задач на графах, в том числе и с помощью компьютера, часто используется его графическое представление. Вершины графа изображают на плоскости в виде точек или маленьких кружков, а ребра — в виде линий (не обязательно прямых), соединяющих соответствующие пары вершин, для неориентированного графа и стрелок – для ориентированного (если ребро направлено из u в v , то из точки, изображающей вершину u , проводят стрелку в вершину v ).
Графы широко используются в различных областях науки (в том числе в истории!!!) и техники для моделирования отношений между объектами. Объекты соответствуют вершинам графа, а ребра — отношениям между объектами). Подробнее об этой структуре данных можно прочитать в [5 - 7].
3. Поиск пути между парой вершин невзвешенного графа
Пусть мы имеем произвольный граф, ориентированный или неориентированный. Если в невзвешенном графе существует путь, то назовем длиной пути количество ребер в нем. Если пути нет вообще, то расстояние считается бесконечным. Путь минимальной длины при этом называется кратчайшим путем в графе. Легко показать, что любые части кратчайшего пути также являются кратчайшими путями между соответствующими вершинами. Ведь если это не так, то есть существует отрезок кратчайшего пути, между концами которого можно построить более короткий путь, то мы можем заменить этот отрезок кратчайшего пути между вершинами u и v на более короткий, тем самым уменьшив и длину кратчайшего пути между u и v , что невозможно. Это свойство кратчайших путей позволяет решать задачу их нахождения методом динамического программирования. Покажем сначала как можно записать “волновой алгоритм” так, что задача поиска кратчайшего пути между двумя вершинами графа будет решаться за O (N 2 ) действий.
Задача 12 . Для линий метрополитена некоторого города известно, между какими парами линий есть пересадочная станция. Необходимо определить, за сколько пересадок можно добраться с линии m на линию n или сообщить, что сделать это невозможно.
Решение. Такой метрополитен удобно описывать с помощью графа, вершины которого есть линии метрополитена (а не станции!!!), а наличие ребра между вершинами i и j графа соответствует наличию пересадочной станции между линиями с номерами i и j . Представим этот граф с помощь массива множеств (переменная ss в программе), в i -м элементе этого массива содержится множество всех линий, на которые можно попасть с линии i за одну пересадку. Результат будем получать с помощью множества s, на каждом шаге алгоритма содержащего номера всех линий, на которые можно попасть с исходной линии m за k пересадок. Заметим, что если вершина n нашего графа достижима из вершины m (говорят, что они находятся в одной компоненте связности ), то искомое число пересадок меньше общего количества линий nn . Так как даже если после каждой из первых nn – 1 пересадок мы попадали на новую линию, то после следующей пересадки мы обязательно окажемся на какой-то из линий повторно, ведь их всего nn . Поэтому, если наш алгоритм не завершился за nn – 1 шаг, то граф не связан и дальнейший поиск пути бесполезен (заметим, что наличие пути между двумя конкретными вершинами не доказывает его связность, а исследовать все пары вершин с помощью предложенного алгоритма для анализа связности неэффективно).
Программа для решения задачи представлена ниже.
const nn=200;{число линий}
type myset = set of 0..nn;var i,m,n,k:byte; ss:array[1..nn] of myset; s,s1:myset;begin
…{считываем входные данные}
s:=[m]; k:=0; while not (n in s) and(k<nn-1) do begin k:=k+1;
s1:=s; s:=[]; for i:=1 to nn do if i in s1 then
{добавляем к s вершины,
достижимые из i} s:=s+ss[i] end; if n in s then writeln(k) else
writeln('it is impossible')
end.
Заметим, что предложенный при решении задачи 12 алгоритм можно модифицировать так, чтобы он находил длину кратчайшего пути от исходной вершины до всех других вершин графа, причем асимптотическое время его работы не изменится. Несмотря на хорошие временные характеристики, область применения алгоритма ограничена размером типа “множество” в Паскале. Избежать этого ограничения можно, используя такой способ представления графа как массив списков вершин, смежных с данной. О способах реализации динамических структур данных, и в частности списков, см., например, [8].
Пусть теперь требуется определить наличие пути сразу для всех пар вершин графа. Такая задача для невзвешенного графа называется транзитивным замыканием . Рассмотрим ее решение на примере следующей проблемы.
Задача 13. Пусть для некоторых пар переменных известно, что значение одной из них не больше значения другой. Выписать остальные пары из упомянутых переменных, для которых, используя транзитивность операции “£”, можно также сказать, значение одной из них не превосходит значение другой.
Решение . Обозначим данными переменными вершины графа, а знание о наличии между двумя переменными отношения “£” — ориентированными ребрами. Для некоторой пары вершин справедливо, что значение одной £ значения другое, если в построенном ориентированном графе существует путь из первой из упомянутых вершин во вторую. Тогда для решения задачи можно воспользоваться следующим алгоритмом Уоршолла [5, 6]. Пусть A — матрица, изначально равная матрице смежности графа, записанной с помощью логических констант true и false . На k -м шаге алгоритма значение true в элементе матрицы A [i , j ] будет означать, что из вершины i в вершину j cуществует путь, который проходит через некоторые вершины с номерами, не превосходящими k – 1. Если же через упомянутые вершины пути нет(A [i , j ] = false ), но существует путь из вершины i в вершину k и путь из вершины k в вершину j то значение данного элемента матрицы становится true . Покажем как написать фрагмент программы, реализующий этот алгоритм без использования условных операторов:
c:=a;{запоминаем матрицу смежности}
for k:=1 to nn do
for i:=1 to nn do
for j:=1 to nn do
a[i,j]:=a[i,j] or a[i,k] and a[k,j];
Краткость говорит здесь сама за себя. В результате выполнения трех вложенных циклов (то есть мы имеем алгоритм, работающий за N 3 операций), порядок которых очень важен, в матрице a мы фактически получим ответ на вопрос задачи. Распечатать его можно так:
for i:=1 to nn do
for j:=1 to nn do
if a[i,j] xor c[i,j] then writeln(i,’ ’,j);
Если же требуется найти длины кратчайших путей для всех пар вершин, то, если каждому ребру графа приписать вес, равный единице, решение задачи будет полностью совпадать с решением той же задачи для взвешенного графа (см. далее). Поэтому отдельно мы рассматривать его не будем.
4. Пути минимальной длины во взвешенном графе
Длиной пути между двумя вершинами во взвешенном графе называется сумма весов ребер, составляющих этот путь. В отличие от невзвешенного графа наличие ребра между двумя вершинами не гарантирует, что кратчайший путь между ними состоит из этого ребра. Зачастую суммарный вес пути, состоящего из двух, трех и более ребер может оказаться меньше веса одного ребра, поэтому даже для полного графа (то есть графа, между каждой из пар вершин которого существует ребро, а в случае ориентированного графа — два ребра, направленных в противоположные стороны) задача поиска кратчайших путей имеет смысл. Понятие кратчайшего пути пока будем рассматривать только для графов, все ребра которых имеют неотрицательный вес.
Наиболее просто найти кратчайший путь между каждой из пар вершин можно с помощью алгоритма Флойда [5 – 7], основанного на той же идее, что и алгоритм Уоршолла. Пусть в элементе матрицы A [i , j ] хранится длина кратчайший пути из вершины i в вершину j , который проходит через некоторые вершины с номерами, не превосходящими k – 1. Если же длины пути из вершины i в вершину k и пути из вершины k в вершину j то таковы, что их сумма меньше, чем значение данного элемента матрицы, то его следует переопределить. То есть в реализации алгоритма Уоршолла следует заменить операцию and на “+”, а or — на нахождение минимума из двух величин. Для реализации алгоритма массив a первоначально следует заполнить элементами матрицы смежности, обозначая отсутствие ребра между двумя вершинами “бесконечностью” — числом, заведомо превосходящим длину любого пути в рассматриваемом графе, но меньшим, чем максимальное значение используемого типа данных, чтобы было возможно выполнять с ним арифметические операции. В этом случае можно избежать дополнительных проверок.
Если же нам требуется найти сам кратчайший путь, а не его длину, то при каждом улучшении пути между двумя вершинами мы в соответствующем элементе вспомогательного массива (в программе — w) будем запоминать номер той вершины, через которую кратчайший путь проходит, а затем с помощью элегантной рекурсивной процедуры будем его печатать. Идея рекурсии заключается в том, что если мы знаем, что кратчайший путь от вершины i до вершины j проходит через вершину k , то мы можем обратиться к той же самой процедуре с частями пути от i до k и от k до j . Рекурсивный спуск заканчивается, когда на кратчайшем пути между двумя вершинами не окажется промежуточных вершин.
Приведем фрагмент программы, реализующий алгоритм Флойда и печатающий кратчайшие пути между всеми парами вершин графа.
procedure way(i,j:integer);
{печатает путь между вершинами i и j}
begin
if w[i,j]=0 then write(' ',j)
{печатаем только вершину j,
чтобы избежать повторов}
else
begin
way(i,w[i,j]); way(w[i,j],j)
end
end;
begin
…{заполняем матрицу смежности}
for k:=1 to nn do
for i:=1 to nn do
for j:=1 to nn do
if a[i,k]+a[k,j]<a[i,j] then
begin
a[i,j]:=a[i,k]+a[k,j];
w[i,j]:=k
end;
for i:=1 to nn do
for j:=1 to nn do
begin
write(i);
if i<>j then way(i,j);
writeln
end
end.
Алгоритм Флойда хорош всем, кроме одного: он требует хранить матрицу смежности, а это не всегда возможно. Кроме того, для определения длины кратчайшего пути между двумя конкретными вершинами, его упростить невозможно (то есть все равно придется считать пути между всеми парами вершин). Если вес любого ребра в графе вычисляется по некоторой формуле (например, как расстояние между двумя точками на плоскости, если таковыми являются вершины нашего графа), то матрицу смежности можно не создавать вообще, а в процессе выполнения программы обращаться к функции вычисления веса ребра, соединяющего вершины i и j : a (i , j ).
В этом случае для определение кратчайшего пути между вершинами s и t используют алгоритм Дейкстры [5 – 7]. Все вершины в процессе работы этого алгоритма разбиты на два множества: те, до которых кратчайший путь из вершины s уже известен (в программе они помечены значениями true одномерного булевского массива b) и все остальные. Cначала в первом множестве находится только вершина s . На каждом шаге к нему добавляется одна из вершин, текущее известное расстояние до которой минимально среди всех вершин из второго множества, обозначим ее p . Первоначально текущие расстояния (в программе они хранятся в одномерном массиве l) от s до остальных вершин равны ¥, а расстояние до s равно 0, p также равна s . На очередном же шаге мы пытаемся улучшить длину пути до каждой из вершин второго множества, сравнивая выражения l[p]+a(p,i) и l[i]. Нужно показать, почему минимальное из значений l, рассматриваемых на текущем шаге, является длиной кратчайшего пути до соответствующей вершины, а, следовательно, этот путь содержит только вершины из первого множества. Если это не так, то есть кратчайший путь до этой вершины содержит и вершины из второго множества, то минимальной оказалась бы длина пути от s до одной из этих вершин. Значит кратчайший путь до вершины p проходит только через вершины первого множества и больше его пересчитывать не нужно.
Приведем схему программы, реализующей этот алгоритм (функцию a(i, j) и значение “бесконечности” определять не будем):
for i:=1 to nn do
begin
l[i]= ¥;
b[i]:=false
end;
p:=s; l[s]:=0;
b[s]:=true;
f:=true;{cтоит ли искать дальше}
while (p<>t) and f do
begin
f:=false;
for i:=1 to nn do
if not b[i] then
if l[p]+a(p,i)<l[i] then l[i]:=l[p]+a(p,i);
min:=t;{важно, что b[t]=false}
for i:=1 to n do
if (not b[i])and(l[i]<l[min]) then min:=i;
if l[min]< ¥ then
begin
p:=min; b[p]:=true; f:=true
end
end;
Несложно подсчитать, что трудоемкость алгоритма составляет O (N 2 ), что окупает некоторые сложности в его реализации. Как и в случае применения “волнового” алгоритма в невзвешенном графе, асимптотическая оценка не изменится если нам потребуется подсчитать длину пути от s до каждой из вершин графа. Поэтому, как и в алгоритме Флойда, длины кратчайших путей между всеми парами вершин могут быть рассчитаны за O (N 3 ) операций.
Заключение
Итак, неформально, граф можно определить как набор вершин (города, перекрестки, компьютеры, буквы, цифры кости домино, микросхемы, люди) и связей между ними: дороги между городами; улицы между перекрестками; проводные линии связи между компьютерами; слова, начинающиеся на одну букву и закачивающиеся на другую или эту же букву; проводники, соединяющие микросхемы; родственные отношения, например, Алексей - сын Петра. Двунаправленные связи, например, дороги с двусторонним движением, принято называть ребрами графа; а однонаправленные связи, например, дороги с односторонним движением, принято называть дугами графа. Граф, в котором вершины соединяются ребрами, принято называть неориентированным графом, а граф, в котором хотя бы некоторые вершины соединяются дугами, принято называть ориентированным графом.
Литература
1. Андреева Е., Фалина И. Системы счисления и компьютерная арифметика. М.: Лаборатория базовых знаний, 2000.
2. Станкевич А .С. Решение задач I Всероссийской командной олимпиады по программированию. “Информатика”, №12, 2001.
3. Окулов С.М. 100 задач по информатике. Киров: изд-во ВГПУ, 2000.
4. Андреева Е.В. Решение задач XIII Всероссийской олимпиады по информатике. “Информатика”, №19, 2001.
5. Ахо А.А., Хопкрофт Д.Э., Ульман Д.Д. Структуры данных и алгоритмы. М.: “Вильямс”, 2000.
6. Кормен Т., Лейзерсон Ч., Ривест Р. Алгоритмы. Построение и анализ. М.: МЦНМО, 2000.
7. Липский В. Комбинаторика для программистов. М.: “Мир”, 1988.
8. Вирт Н. Алгоритмы и структуры данных. Санкт-Петербург: “Невский диалект”, 2001.