| Скачать .docx |
Реферат: Алгоритмы планирования действий
Содержание
Введение
Алгоритмы планирования действий
1. Поведение системы
2. Принятие решений в интеллектуальных играх
3. Минимаксный алгоритм
4. Альфа – бета алгоритм
Заключение
Использованы источники
Введение
Тема реферата "Алгоритмы планирования действий" по дисциплине "Проектированиеинтеллектуальных систем".
В современном мире прогресс производительности программиста достигается в тех случаях, когда часть интеллектуальной нагрузки берут на себя компьютеры. Одним из способов достигнуть максимального прогресса в этой области, является "искусственный интеллект", когда компьютер берет на себя не только однотипные, многократно повторяющиеся операции, но и сам сможет обучаться.
Принципиальное отличие интеллектуальных систем от любых других систем автоматизации заключается в наличии базы знаний о предметной среде, в которой решается задача. Неинтеллектуальная система при отсутствии каких-либо входных данных прекращает решение задачи, интеллектуальная же система недостающие данные извлекает из базы знаний и решение выполняет.
Цель работы – рассмотреть алгоритмы планирования действий.
Алгоритмы планирования действий
1. Поведение системы
Типичным актом целенаправленного функционирования СИИ является решение задачи планирования пути достижения нужной цели из некоторой фиксированной начальной ситуации. Особое место занимают задачи, связанные с определением поведения СИИ. В психологии под поведением понимается взаимодействие живых существ с окружающей средой и другими особями, опосредованное двигательной и психической активностью. В случае СИИ некоторая деятельность будет называться поведением, если выполнены три условия: наличие цели, наличие наблюдателя и наличие оценки. Таким образом, под поведением понимается целенаправленная деятельность, а не деятельность вообще.
Второе условие вычленяет в этой деятельности еще более узкую область. В поведенческом акте должен принять участие осознаваемый наблюдатель. Его роль может выполнить сам субъект (самонаблюдение) или "мыслимый наблюдатель", который мог бы быть. Другими словами, второе условие требует возможности взгляда со стороны.
Третье условие требует, чтобы наблюдатель формировал оценку деятельности субъекта и высказывал к ней некоторое отношение. Третье условие исключает из поведения такие виды деятельности, как принятие пищи, сон, трудовую деятельность, не подверженную оценке, и т.п. Поведенческие акты органически связаны с априорными знаниями об оценках, которые субъект может ожидать после совершения действий. Умение рассуждать за наблюдателя предполагает знание о том, как он проводит свои рассуждения.
Классификация типов поведения приведена на рисунке 1.

Рисунок 1 -Классификация типов поведения
Нормативное поведение определяется набором предписаний, характерных для того общества, к которому принадлежит индивид. Ситуационное поведение определяется той реальностью, в которой оно возникает. Аналитическое поведение характеризуется осознанностью целей и плана их достижения.
2. Принятие решений в интеллектуальных играх
В интеллектуальных играх соревнование между участниками заключается в том, что они поочередно принимают решения, не зная, какое следующее решение примет противник. Классический подход, реализуемый мыслящим существом для решения этой задачи, состоит в прогнозировании последующих ходов – своих и ответных ходов противника. Таким образом, может быть построено дерево (или граф) допустимых ходов и возможных игровых позиций, пример которого приведен на рисунке2. На рисунке символами Q обозначены позиции после хода противника, символами R – позиции после хода игрока; вершины графа, у которых стрелки соединены дугой, означают И – вершину, т.е. вершину, для достижения цели в которой, необходимо достичь цели во всех вершинах нижнего уровня; вершины графа, у которых стрелки не соединены дугой, означают ИЛИ – вершину, т.е. вершину, для достижения цели в которой, необходимо достичь цель хотя бы в одной вершине нижнего уровня.
В И – ИЛИ дереве, показанном на рисунке2, вершины соответствуют позициям, а дуги – возможным ходам. Уровни позиций игрока чередуются в дереве с уровнями позиций противника. Для того, чтобы выиграть в позиции P, нужно найти ход, переводящий Р в выигранную позицию Qi . Таким образом, игрок выигрывает в позиции Р, если он выигрывает в Q1 , или в Q2, или Q3 , или … Следовательно, Р – это ИЛИ – вершина. Для любого i позиция Qi – это позиция противника, поэтому если в этой позиции выигрывает игрок, то он выигрывает и после каждого варианта хода противника. Другими словами, игрок выигрывает в Qi , если он выигрывает во всех позициях Ri1 и Ri2 и … Таким образом, все позиции противника – это И – вершины.
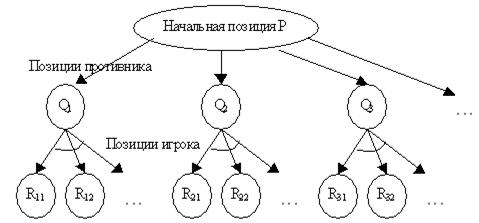
Рисунок 2 - Пример дерева при поиске хода
Целевые вершины – это позиции, выигранные согласно правилам игры, например позиции, в которых король противника получает мат. Позициям проигранным соответствуют задачи, которые не имеют решения. Для того, чтобы решить игровую задачу, необходимо построить решающее дерево, гарантирующее победу игрока независимо от ответов противника. Такое дерево задает полную стратегию достижения выигрыша: для каждого возможного продолжения, выбранного противником, в дереве стратегии есть ответный ход, приводящий к победе. Например, для игры в "тик-так-ту" может быть построено полное дерево ходов, которое показано на рисунке3. Из-за симметрии игрового поля только два ответных хода белых являются различными.
Если необходимо найти какое-нибудь решение задачи, то организуется простейший поиск в И – ИЛИ дереве, который заключается в систематическом и полном просмотре дерева, не руководствуясь при этом какими – либо эвристиками. Для сложных задач подобные процедуры неэффективны из–за большой комбинаторной сложности пространства поиска. Например, для игры в шахматы пространство поиска оценивается в 10120 позиций! Поэтому необходимы эвристические алгоритмы управления поиском. Основная идея этих алгоритмов – просмотр только части дерева ходов.
3. Минимаксный алгоритм
Существует стандартный метод поиска, используемый в игровых программах, основанный на минимаксном принципе. Дерево ходов просматривается по одной из ветвей до максимальной глубины (обычно несколько ходов) и оценивается позиция. Очень многое зависит от оценочной функции, которая для большинства игр, является приближенной эвристической оценкой шансов на выигрыш одного из участников игры. Поскольку один из участников игры стремится к высоким оценкам, а другой - к низким, то им даются имена МАКС и МИН соответственно. МАКС всегда выбирает ход с максимальной оценкой; в противоположность ему МИН всегда выбирает ход с минимальной оценкой. Пользуясь этим минимаксным принципом и зная значения оценок для всех вершин подножия дерева поиска, можно определить оценки всех вышерасположенных вершин дерева. Оценки вершин подножия дерева делаются с помощью некоторой оценочной функции и называются статическими. Затем, двигаясь по дереву снизу – вверх, определяется оценка (динамическая) внутренних вершин.
На рисунке4 показан принцип оценивания вершин и выделен жирными линиями основной вариант игры.
Основной вариант показывает, какова "минимакснооптимальная" игра для обоих участников. Необходимо отметить, что оценки всех позиций, входящих в основной вариант, одинаковы.
Минимаксный принцип позволяет просматривать не полное дерево, а лишь ограниченное число уровней в глубину. Однако, поиск в ширину не сокращается.

Рисунок 3 - Полное дерево ходов в игре "тик-так-ту"

Рисунок 4 - Статические и минимаксные оценки вершин
4. Альфа – бета алгоритм
Минимаксный алгоритм оценки может быть сделан более экономным. Для этого может быть использована следующая идея. Предположим, что есть два варианта хода. Как только стало известно, что один ход явно хуже другого, то можно принять правильное решение, не выясняя, насколько в точности он хуже. Этот принцип может быть использован для сокращения дерева поиска. Для дерева, представленного на рисунке4, может быть выполнена следующая последовательность действий по поиску хода:
- начальная позиция "а";
- переход к "b";
- переход к "d";
- выбор максимальной из оценок преемников позиции "d", получено V(d)=4;
- возврат к "b" и переход к "e";
- рассмотрение первого преемника позиции "e" с оценкой 5. В этот момент МАКС обнаруживает, что ему гарантирована в позиции "e" оценка, не меньшая, чем 5, независимо от оценок других (возможно, более предпочтительных) вариантов хода. Этого вполне достаточно для того, чтобы МИН, даже не зная точной оценки позиции "e", понял, что в позиции "b" ход в "е" хуже, чем ход в "d".
На основании приведенного выше рассуждения можно пренебречь другими преемниками позиции "е" и приписать ей приближенную оценку 5. Приближенный характер этой оценки не окажет никакого влияния на оценку позиции "b", а следовательно и позиции "а".
На этой идее основан альфа – бета алгоритм, предназначенный для эффективной реализации минимаксного принципа. На рис показан результат применения альфа – бета алгоритма к дереву, представленного на рисунке 5.

Рисунок 5 - Результат применения альфа – бета алгоритма
Ключевая идея альфа – бета отсечения состоит в том, чтобы найти ход не обязательно лучший, но "достаточно хороший" для того, чтобы принять правильное решение. Эту идею можно формализовать, введя два граничных значения, обычно обозначаемых Альфа и Бета ,между которыми должна находиться рабочая оценка позиции. Альфа – это самое маленькое значение оценки, которое к настоящему моменту уже гарантировано для игрока МАКС; Бета – это самое большое значение оценки, но которое МАКС пока еще может надеяться. Таким образом, действительное значение оценки всегда лежит между Альфа и Бета . Если же стало известно, что оценка некоторой позиции лежит вне интервала Альфа – Бета, то этого достаточно для того, чтобы сделать вывод: данная позиция не входит в основной вариант. При этом точное значение оценки такой позиции знать не обязательно, его надо знать только тогда, когда оценка лежит между Альфа и Бета .
"Достаточно хорошую" рабочую оценку V(P, Альфа, Бета) позиции Р можно определить как любое значение, удовлетворяющее следующим ограничениям:
- не более Альфа, если оценка позиции Р меньше либо равна Альфа;
- не менее Бета, если оценка позиции Р больше или равна Бета;
- точно равна оценке V(P), если оценка позиции Р находится между значениями Альфа и Бета.
Эффективность альфа – бета процедуры зависит от порядка, в котором просматриваются позиции. Всегда лучше рассматривать самые сильные ходы с каждой из сторон. В наихудшем случае альфа – бета процедура выполняет полный перебор вершин дерева.
Заключение
Минимаксный принцип и альфа – бета алгоритм лежат в основе многих удачных игровых программ, чаще всего шахматных. Общая схема подобной программы такова: произвести альфа – бета поиск из текущей позиции вплоть до некоторого предела по глубине (диктуемого временными ограничениями турнирных правил). Для оценки терминальных поисковых позиций использовать подобранную специально для данной игры оценочную функцию. Затем выполнить наилучший ход, найденный альфа – бета алгоритмом, принять ответный ход противника и запустить тот же цикл с начала.
Многое зависит от оценочной функции. Если была бы известна абсолютно точная оценочная функция, то можно было бы ограничить поиск рассмотрением только непосредственных преемников текущей позиции, фактически исключив перебор. В общем случае такая функция является эвристической.
Использованы источники
1. Уоссермен Ф., Нейрокомпьютерная техника, - М.,Мир, 1992.
2. Горбань А.Н. Обучение нейронных сетей. - М.: ПараГраф, 1990
3. Горбань А.Н., Россиев Д.А. Нейронные сети на персональном компьютере. - Новосибирск: Наука, 1996
4. Gilev S.E., Gorban A.N., Mirkes E.M. Several methods for accelerating the training process of neural networks in pattern recognition // Adv. Modelling & Analysis, A. AMSE Press. – 1992. – Vol.12, N4. – P.29-53
5. С. Короткий. Нейронные сети: алгоритм обратного распространения.
6. С. Короткий, Нейронные сети: обучение без учителя. Artificial Neural Networks: Concepts and Theory, IEEE Computer Society Press, 1992.
7. Заенцев И. В. Нейронные сети: основные модели./Учебное пособие к курсу "Нейронные сети" для студентов 5 курса магистратуры к. электроники физического ф-та Воронежского Государственного университета – e-mail: ivz@ivz.vrn.ru
8. Лорьер Ж.Л. Системы искусственного интеллекта. – М.: Мир, 1991. – 568 с.