| Скачать .docx |
Курсовая работа: Алгоритмы преобразования ключей
СОДЕРЖАНИЕ
ВВЕДЕНИЕ
ГЛАВА 1. АЛГОРИТМЫ ПРЕОБРАЗОВАНИЯ КЛЮЧЕЙ (РАССТАНОВКА)
ГЛАВА 2. ПРАКТИЧЕСКАЯ ЧАСТЬ
2.1 ВСТАВКА ЭЛЕМЕНТА В В-ДЕРЕВО
2.2 ОБРАБОТКА ТЕКСТОВЫХ ФАЙЛОВ
ПРИЛОЖЕНИЕ К ВЫПОЛНЕННЫМ ПРОГРАММАМ
ЗАКЛЮЧЕНИЕ
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
ВВЕДЕНИЕ
Данная курсовая работа состоит из четырёх основных разделов каждый из которых представляет собой рассмотрения отдельно взятого задания для данной курсовой работы. Для начала следует определить цель каждого задания.
1. Алгоритмы преобразования ключей (расстановка).
Хеширование - алгоритмическое преобразование ключей в адреса. В СУБД метод индексации, при котором значение ключа (идентификатора записи) служит аргументом для прямого вычисления либо локализации ассоциированной записи в файле, либо начала ее поиска.
С хешированием сталкиваются едва ли не на каждом шагу: при работе с браузером (список Web-ссылок), текстовым редактором и переводчиком (словарь), языками скриптов (Perl, Python, PHP и др.), компилятором (таблица символов). По словам Брайана Кернигана, это «одно из величайших изобретений информатики». Заглядывая в адресную книгу, энциклопедию, алфавитный указатель, мы даже не задумываемся, что упорядочение по алфавиту является не чем иным, как хешированием.
2. Написать процедуру, реализующую вставку в В-дерево.
Рассмотрим, что же такое В-дерево. Предположим, что нам придется иметь дело с множеством, которое невозможно разместить во внутренней памяти, работа с которой отличается быстрым доступом, целиком из-за его большого объема. Поэтому нам придется хранить данные во внешней памяти, обладающей относительно большим временем доступа. Значит, наша цель будет заключаться, прежде всего, в попытке уменьшить количество запросов на чтение к внешней памяти. Как мы уже видели, очень эффективным является хранение множества в виде дерева. Поэтому попробуем создать такое дерево, которое будет обеспечивать при своем обслуживании относительно небольшое количество обращений к внешней памяти.
Для этого в каждом узле дерева надо хранить как можно больше элементов (сколько позволяет объем выделенной внутренней памяти, но не настолько много, чтобы чтение столь большого блока требовало много времени) и читать каждый узел за один запрос к внешней памяти. Естественно, наше дерево должно быть упорядочено, ведь, как мы видели ранее, именно упорядоченные деревья позволяют сократить количество просматриваемых узлов. Также, чтобы гарантировать логарифмическую сложность, желательно поддерживать такое дерево сбалансированным (в том смысле, что для каждой вершины дерева высота левого поддерева должна быть равна высоте правого поддерева). Узел такого дерева назовем страницей поиска .
3. Разработать блок-схему алгоритма и составить программу обработки текстовых данных, хранящихся в произвольном файле на магнитном диске. Вид обработки данных: подсчитать количество слов, которые содержат определённое количество согласных.
4. Выполнить тестирование программы для нормальных, граничных и исключительных условий. Результаты тестирования свести в таблицу.
ГЛАВА 1. АЛГОРИТМЫ ПРЕОБРАЗОВАНИЯ КЛЮЧЕЙ
Хеширование есть разбиение множества ключей (однозначно характеризующих элементы хранения и представленных, как правило, в виде текстовых строк или чисел) на непересекающиеся подмножества (наборы элементов), обладающие определенным свойством. Это свойство описывается функцией хеширования, или хеш-функцией, и называется хеш-адресом. Решение обратной задачи возложено на хеш-структуры (хеш-таблицы): по хеш-адресу они обеспечивают быстрый доступ к нужному элементу. В идеале для задач поиска хеш-адрес должен быть уникальным, чтобы за одно обращение получить доступ к элементу, характеризуемому заданным ключом (совершенная хеш-функция). Однако на практике идеал приходится заменять компромиссом и исходить из того, что получающиеся наборы с одинаковым хеш-адресом содержат более одного элемента.
Термин «хеширование» (hashing) в печатных работах по программированию появился сравнительно недавно (1967 г. [1]), хотя сам механизм был известен и ранее. Глагол «hash» в английском языке означает «рубить, крошить», т. е. создавать этакий «винегрет». Для русского языка академиком А.П. Ершовым [2] был предложен достаточно удачный эквивалент — «расстановка», созвучный с родственными понятиями комбинаторики, такими как «подстановка» и «перестановка». Однако пока он не прижился.
Как отмечает Дональд Кнут [3], идея хеширования впервые была высказана Г.П. Ланом при создании внутреннего меморандума IBM в январе 1953 г. с предложением использовать для разрешения коллизий хеш-адресов метод цепочек. В открытой печати хеширование впервые было описано Арнольдом Думи (1956), указавшим, что в качестве хеш-адреса удобно использовать остаток от деления на простое число. Подход к хешированию, отличный от метода цепочек, был предложен А.П. Ершовым (1957), который разработал и описал метод линейной открытой адресации. Среди других исследований можно отметить работы Петерсона (1957, [4]) и Морриса (1968, [5]). В первой реализовывался класс методов с открытой адресацией при работе с большими файлами, а во второй давался обширный обзор по хешированию и вводился термин «рассеянная память» (scatter storage).
Одна из важных задач, решаемых в программировании,— это обеспечение быстрого (прямого) доступа к данным по некоему коду (индексу, адресу). Неудивительно, что решающий эту задачу массив стал одним из главных строительных блоков, превосходя по использованию списки, которые определяют последовательный доступ к элементам. В математике массиву соответствуют понятия вектор (в одномерном случае) и матрица (в двумерном).
Как известно, массив задает отображение (A) множества индексов (I) на множество элементов (E), т. е. A: I —> E. Массив позволяет по индексу быстро найти требуемый элемент. Хеширование решает в точности такую же задачу. Однако здесь уже в роли индекса выступает хеш-адрес, который определяется как значение некоей хеш-функции, применяемой к уникальному ключу. В этом смысле хеш-структуры можно рассматривать как обобщение массива.
В программировании зависимость между индексом и значением записывается в виде: A = ARRAY I OF E. В роли индексирующего типа (I) обычно выбирается конкретный диапазон значений из целочисленного типа (хотя в общем случае в их роли могут выступать так называемые скалярные типы, т. е. булев тип, перечисления, множества и др.). Ну а элементы массива в зависимости от языка программирования могут быть любыми, начиная от битов, чисел и указателей (ссылок) и заканчивая составными типами произвольной глубины.
То, что массив задает функцию отображения, в языке Ада подчеркивается даже на уровне синтаксиса. Например, при появлении в тексте программы записи вида «a(i)» трудно с ходу сказать, идет ли это обращение к i-му элементу массива «a» или же просто вызывается функция «a» с параметром «i».
Выделяют два разных вида массивов: одномерные (наиболее общий случай) и многомерные (на каждом слое адресации используется массив фиксированной структуры). Во втором случае есть и особый подвид: ступенчатые массивы (jagged arrays). Они встречаются, в частности, в языке C# в том случае, когда на каждом слое адресации используется массив переменной структуры. Иначе говоря, здесь мы имеем дело с массивом разных массивов. В других языках такая конструкция легко описывается массивом разнородных указателей (каждый указывает на массив своей структуры), что фактически определяет массив списков.
Интересно, что Н. Вирт после многих лет использования в своих языках (Паскаль, Модула-2) в качестве индексирующего типа разных скалярных типов пришел к выводу, что лаконичное решение, воплощенное в языке Си (а точнее, унаследованное в Си от языков BCPL и B), носит куда более практичный характер. И в своих новых языках Оберон и Оберон-2 он отказался от идей Паскаля и ограничился заданием размера массива (количества индексируемых элементов), т. е. определением для индексов диапазона 0...n—1, где n — это размер массива: A = ARRAY 16 OF E. Связано это с эффективностью реализации и с активным использованием в программировании элементов модулярной арифметики. В Обероне предопределенная функция MOD («x MOD n»), как и в математике, соответствует остатку от целочисленного деления «x» на «n». Как показывает опыт, использование 0 в качестве начального индекса удобно в подавляющем большинстве задач. Механизмы хеширования опираются точно на ту же основу.
Вспомним некоторые определения из курса элементарной математики. Отображением (f: A —> B) множества A во множество B (функцией на A со значениями в B) называется правило, по которому каждому элементу множества A сопоставляется один или несколько элементов множества B. Отсюда следует, что отображения могут быть однозначными и многозначными в зависимости от того, имеет ли каждый прообраз в соответствии один или несколько образов. Однозначное отображение f: A—> B называется сюръективным (сюръекцией), если f(A) = B. Это так называемое отображение «на». Отображение (в общем случае неоднозначное) называется инъективным, если образы различных прообразов различны (отображение «в»). Cюръективное и инъективное отображение называется биекцией.
Вот теперь, пользуясь этими понятиями, попробуем разобраться в природе хеширования. Итак, одномерные и многомерные массивы — это яркий пример сюръекции. Поэтому их можно назвать «сюръективными» массивами. Биекцию в общем случае они не задают, поскольку разным индексам (прообразам) могут соответствовать одни и те же значения (образы). Примером «биективного» массива может служить, например, соответствующим образом заполненный массив литер: ARRAY 256 OF CHAR.
В реальных задачах нередко возникают ситуации, когда не столько важно иметь однозначное соответствие между адресом и значением, сколько гарантию того, что одно и то же значение не может быть получено по разным адресам. А это и есть инъекция, реализуемая через хеширование.
Следовательно, в случае хеширования значения хранятся в «инъективных» массивах разной структуры.
Именно здесь проходит водораздел между разными схемами и методами хеширования. Именно отсюда и проистекают проблемы поиска оптимального баланса между пространством хранения и временем доступа.
Традиционно принято выделять две схемы хеширования:
· хеширование с цепочками (со списками);
· хеширование с открытой адресацией.
В первом случае выбирается некая хеш-функция h(k) = i, где i трактуется как индекс в таблице списков t. Поскольку нельзя гарантировать, что не встретится двух разных ключей, которым соответствует один и тот же индекс i (конфликт, коллизия), такие «однородные» ключи просто помещаются в список, начинающийся в i-ячейке хеш-таблицы t (см. рисунок).
Очевидно, что процесс заполнения хеш-таблицы будет достаточно простым, но при этом доступ к элементам потребует двух операций: вычисления индекса и поиска в соответствующем списке. Операции по занесению и поиску элементов при таком виде хеширования будут вестись в незамкнутом (открытом) пространстве памяти.
Большинство задач решается с использованием методики, называемой хешированием. Ее основу составляют различные алгоритмы отображения значения ключа в значение адреса размещения элемента в таблице. Непосредственное преобразование ключа в адрес производится с помощью функций расстановки, или хэш-функций. Адреса, получаемые из ключевых слов с помощью хэш-функций, называются хэш-адресами. Таблицы, для работы с которыми используются методы хеширования, называются таблицами с вычисляемыми входами, хэш-таблицами, или таблицами с прямым доступом.
Основополагающую идею хеширования можно пояснить на следующем примере. Предположим, необходимо подсчитать, сколько раз в тексте встречаются слова, первый символ которых — одна из букв английского алфавита (или русского — это не имеет значения, можно в качестве объекта подсчета использовать любой символ из кодовой таблицы). Для этого в памяти нужно организовать таблицу, количество элементов в которой будет соответствовать количеству букв в алфавите. Далее необходимо составить программу, в которой текст будет анализироваться с помощью цепочечных команд. При этом нас интересуют разделяющие слова пробелы и первые буквы самих слов. Так как символы букв имеют определенное двоичное значение, то на его основе вычисляется адрес в таблице, по которому располагается элемент, в минимальном варианте состоящий из одного поля. В этом поле ведется подсчет количества слов в тексте, начинающихся с данной буквы. В следующей программе с клавиатуры вводится 20 слов (длиной не более 10 символов), производится подсчет английских слов, начинающихся с определенной строчной буквы, и результат подсчета выводится на экран. Хэш-функция (функция расстановки) имеет вид:
A=(C-97)*L,
где А — адрес в таблице, полученный на основе двоичного значения символа С; L — длина элемента таблицы (для нашей задачи L=l); 97 — десятичное смещение в кодовой таблице строчного символа «а» английского алфавита.
:prg02_07.asm - программа на ассемблере для подсчета количества слов, начинающихся с определенной строчной буквы:
Вход: ввод с клавиатуры 20 слов (длиной не более 10 символов).
Выход: вывод результата подсчета на экран.
buf_Oahstruc
len_bufdb 11 ; длина bufjn
lenjin db 0 действительная длина введенного слова (без учета Odh) bufjn db 11 dup (20h) -.буфер для ввода (с учетом Cdh) ends 1 .data
tabdb 26 dup (0) buf buf_0ah<>
db Odh.Oah,'$' ;для вывода функцией 09h (int 21h)
.code
-.вводим слова с клавиатуры
mov ex,20
lea dx.buf
movah.Oah ml: int 21h :анализируем первую букву введенного слова - вычисляем хэш-функцию: А=С*1-97
mov Ы , buf .bufjn sub Ы. 97 inc [bx] loop ml
:выводим результат подсчета на экран push ds popes
xor al ,al
lea di ,buf
mov ex.type bufjah rep stosb ; чистимбуфер buf
mov ex.26 :синволв buf.buf_1n
lea dx.buf
mcv Ы,97 m2: push bx
mov buf .bufjn.bi :опятьвычисляемхэш-функцию:
А»С*1-97 и преобразуем "количество" в символьный вид
sub Ы. 97
mov al .[bx]
aam
or ax,03030h ;в ах длина в символьном виде
mov buf.len in.al —
mov buf.len_buf.ah ;теперь выводим:
mov ah, 09h
int 21h pop bx
inc Ы
loop m2
Таким образом, относительно сложная с первого взгляда задача очень просто реализуется с помощью методов хэширования. При этом обеспечивается высокая скорость выполнения операций доступа к элементам таблицы. Это обусловлено тем, что адреса, по которым располагаются элементы таблицы, являются результатами вычислений простых арифметических функций от содержимого соответствующих ключевых слов.
Перечислим области, где методы хэширования оказываются особенно эффективными.
· Разработка компиляторов, программ обработки текстов, пользовательских интерфейсов и т. п. В частности, компиляторы значительную часть времени обработки исходного текста программы затрачивают на работу с различными таблицами — операций, идентификаторов, констант и т. д. Правильная организация работы компилятора с информацией в этих таблицах означает значительное увеличение скорости создания объектного модуля, может быть, даже не на один порядок выше. Кстати, другие системные программы — редакторы связей и загрузчики — также активно работают со своими внутренними таблицами.
· Системы управления базами данных. Здесь особенный интерес представляют алгоритмы выполнения операций поиска по многим ключам, которые также основаны на методе хеширования.
· Разработка криптографических систем.
· Поиск по соответствию. Методы хеширования можно применять в системах распознавания образов, когда идентификация элемента в таблице осуществляется на основе анализа ряда признаков, сопровождающих объект поиска, а не полного соответствия заданному ключу. Если рассматривать эту возможность в контексте задач системного программирования, то ее можно использовать для исправления ошибок операторов при вводе информации в виде ключевых слов. Подробная информация о поиске по соответствию приведена в литературе.
Но на практике не все так гладко и оптимистично. Для эффективной и безотказной работы метода хеширования необходимо очень тщательно подходить как к изучению задачи на этапе ее постановки, так и к возможности использования конкретного алгоритма хеширования в контексте этой задачи. Так, на стадии изучения постановки задачи, в которой для доступа к табличным данным планируется использовать хеширование, требуется проводить тщательные исследования по направлениям: диапазон допустимых ключей, максимальное количество элементов в таблице, вероятность возникновения коллизий и т. д. При этом нужно знать как общие проблемы метода хеширования, так и частные проблемы конкретных алгоритмов хеширования. Одну из таких проблем рассмотрим на примере задачи.
Пусть необходимо подсчитать количество двухсимвольных английских слов в некотором тексте. В качестве хэш-функции для вычисления адреса можно предложить функцию подсчета суммы двух символов, умноженной на длину элемента таблицы: A=(Cl+C2)*L-97, где А — адрес в таблице, полученный на основе суммы двоичных значений символов С1 и С2; L — длина элемента таблицы; 97 — десятичное смещение в кодовой таблице строчного символа «а» английского алфавита. Проведем простые расчеты. Сумма двоичных значений двух символов 'а' равна 97+97=194, сумма двоичных значений двух символов 'г' равна 122+122=244. Если организовать хэш-таблицу, как в предыдущем случае, то получится, что в ней должно быть всего 50 элементов, чего явно недостаточно. Более того, для сочетаний типа ab и Ьа хэш-сумма соответствует одному числовому значению. В случае когда функция хеширования вычисляет одинаковый адрес для двух и более различных объектов, говорят, что произошла коллизия, или конфликт. Исправить положение можно введением допущений и ограничений, вплоть до замены используемой хэш-функции. Программист может либо применить один из известных алгоритмов хеширования (что, по сути, означает использование определенной хэш-функции), либо изобрести свой алгоритм, наиболее точно отображающий специфику конкретной задачи. При этом необходимо понимать, что разработка хэш-функции происходит в два этапа.
1. Выбор способа перевода ключевых слов в числовую форму.
2. Выбор алгоритма преобразования числовых значений в набор хеш-адресов.
3. Выбор способа перевода ключевых слов в числовую форму
Вся информация, вводимая в компьютер, кодируется в соответствии с одной из систем кодирования (таблиц кодировки). В большинстве таких систем символы (цифры, буквы, служебные знаки) представляются однобайтовыми двоичными числами. В последних версиях Windows (NT, 2000) используется система кодировки Unicode, в которой символы представляются в виде двухбайтовых двоичных величин. Как правило, ключевые поля элементов таблиц — строки символов, Наиболее известные алгоритмы закрытого хеширования основаны на следующих методах:
· деления;
· умножения;
· извлечения битов;
· квадрата;
· сегментации;
· перехода к новому основанию;
· алгебраического кодирования;
· вычислении значения CRC (см. соответствующую главу).
Далее мы рассмотрим только первые четыре метода. Остальные методы — сегментации, перехода к новому основанию, алгебраического кодирования — мы рассматривать не будем. Отметим лишь, что их используют либо в случае значительной длины ключевых слов, либо когда ключ состоит из нескольких слов. Информацию об этих методах можно получить в литературе.
Рассмотрение методов хеширования будет произведено на примере одной задачи. Это позволит лучше понять их особенности, преимущества, недостатки и возможные ограничения.
Необходимо разработать программу — фрагмент компилятора, которая собирает информацию об идентификаторах программы. Предположим, что в программе может встретиться не более М различных имен. Длину возможных имен ограничим восьмью символами. В качестве ключа используются символы идентификатора, какие и сколько — будем уточнять для каждого из методов. Элемент таблицы состоит из 10 байт: 1 байт признаков, 1 байт для хранения длины идентификатора и 8 байт для хранения символов самого идентификатора.
Метод деления
Этот простой алгоритм закрытого хеширования основан на использовании остатка деления значения ключа К на число, равное или близкое к числу элементов таблицы М:
А(К) = К mod M
В результате деления образуется целый остаток А(К), который и принимается за индекс блока в таблице. Чтобы получить конечный адрес в памяти, нужно полученный индекс умножить на размер элемента в таблице. Для уменьшения коллизий необходимо соблюдать ряд условий:
· Значение М выбирается равным простому числу.
· Значение М не должно являться степенью основания, по которому производится перевод ключей в числовую форму. Так, для алфавита, состоящего из первых пяти английских букв и пробела {a,b,c,d,e,' '} (см. пример выше), основание системы равно 6. Исходя из этого число элементов таблицы М не должно быть степенью 6Р.
Важно отметить случай, когда число элементов таблицы М является степенью основания машинной систем счисления (для микропроцессора Intel — это 2). Тогда операция деления (достаточно медленная) заменяется на несколько операций.
Метод умножения
Для этого метода нет ограничений на длину таблицы, свойственных методу деления. Вычисление хэш-адреса происходит в два этапа:
1. Вычисление нормализованного хэш-адреса в интервале [0..1] по формуле:
хеширование адрес алгоритм обработка текстовый
F(K) = (С*К) mod 1,
где С — некоторая константа из интервала [0..1], К — результат преобразования ключа в его числовое представление, mod 1 означает, что F(K) является дробной частью произведения С*К.
2. Конечный хэш-адрес А(К) вычисляется по формуле А(К) = [M*F(K)], где М — размер хэш-таблицы, а скобки [] означают целую часть результата умножения.
Удобно рассматривать эти две формулы вместе:
А(К) = М*(С*К) mod 1.
Кнут в качестве значения С рекомендует использовать «золотое сечение» — величину, равную ((л/5)-1)/2«0,6180339887. Значение F(K) можно формировать с помощью как команд сопроцессора, так и целочисленных команд. Команды сопроцессора вам хорошо известны и трудностей с реализацией формулы (2.4) не возникает. Интерес представляет реализация вычисления А(К) с помощью целочисленных команд. Правда, в отличие от реализации сопроцессором здесь все же Удобнее ограничиться условием, когда М является степенью 2. Тогда процесс вычисления с использованием целочисленных команд выглядит так:
Выполняем произведение С*К. Для этого величину «золотого сечения» С~0,6180339887 нужно интерпретировать как целочисленное значение,
обходимо стремиться к тому, чтобы появление 0 и 1 в выделяемых позициях было как можно более равновероятным. Здесь трудно дать рекомендации, просто нужно провести анализ как можно большего количества возможных ключей, разделив составляющие их байты на тетрады. Для формирования хэш-адреса нужно будет взять биты из тех тетрад (или полностью тетрады), значения в которых изменялись равномерно.
Метод квадрата
В литературе часто упоминается метод квадрата как один из первых методов генерации последовательностей псевдослучайных чисел. При этом он непременно подвергается критике за плохое качество генерируемых последовательностей. Но, как упомянуто выше, для процесса хеширования это не является недостатком. Более того, в ряде случаев это наиболее предпочтительный алгоритм вычисления значения хэш-функции. Суть метода проста: значение ключа возводится в квадрат, после чего берется необходимое количество средних битов результата. Возможны варианты — при различной длине ключа биты берутся с разных позиций. Для принятия решения об использовании метода квадрата для вычисления хэш-функции необходимо провести статистический анализ возможных значений ключей. Если они часто содержат большое количество нулевых битов, то это означает, что распределение значений битов в средней части квадрата ключа недостаточно равномерно. В этом случае использование метода квадрата неэффективно.
На этом мы закончим знакомство с методами хеширования, так как полное обсуждение этого вопроса не является предметом книги. Информацию об остальных методах (сегментации, перехода к новому основанию, алгебраического кодирования) можно получить из различных источников.
В ходе реализации хеширования с помощью методов деления и умножения возможные коллизии мы лишь обозначали без их обработки. Настало время разобраться с этим вопросом.
Обработка коллизий
Для обработки коллизий используются две группы методов:
· закрытые — в качестве резервных используются ячейки самой хэш-таблицы;
· открытые — для хранения элементов с одинаковыми хэш-адресами используется отдельная область памяти.
Видно, что эти группы методов разрешения коллизий соответствуют классификации алгоритмов хеширования — они тоже делятся на открытые и закрытые. Яркий пример открытых методов — метод цепочек, который сам по себе является самостоятельным методом хеширования. Он несложен, и мы рассмотрим его несколько позже.
Закрытые методы разрешения коллизий более сложные. Их основная идея — при возникновении коллизии попытаться отыскать в хэш-таблице свободную ячейку. Процедуру поиска свободной ячейки называют пробитом, или рехешированием (вторичным хешированием). При возникновении коллизии к первоначальному хэш-адресу А(К) добавляется некоторое значение р, и вычисляется выражение (2.5). Если новый хэш-адрес А(К) опять вызывает коллизию, то (2.5) вычисляется при р2, и так далее:
А(К) = (A(K)+Pi)mod М (I = 0..М). (2.5)
push ds popes
lea si .buf.len_in
movcl .buf .lenjn
inccx :длину тоже нужно захватить
adddi .lenjdrepmovsb
jmpmldispl: :выводим идентификатор, вызвавший коллизию, на экран
рехэширование
;ищем место для идентификатора, вызвавшего коллизию в таблице, путем линейного рехэширования incbxmovax.bxjmpm5
Квадратичное рехеширование
Процедура квадратичного рехеширования предполагает, что процесс поиска резервных ячеек производится с использованием некоторой квадратичной функции, например такой:
Pi = а,2+Ь,+с. (2.6)
Хотя значения а, Ь, с можно задавать любыми, велика вероятность быстрого зацикливания значений р(. Поэтому в качестве рекомендации опишем один из вариантов реализации процедуры квадратичного рехеширования, позволяющий осуществить перебор всех элементов хэш-таблицы [32]. Для этого значения в формуле (2.6) положим равными: а=1,Ь = с = 0. Размер таблицы желательно задавать равным простому числу, которое определяется формулой М = 4п+3, где п — целое число. Для вычисления значений р> используют одно из соотношений:
pi = (K+i2)modM. (2.7) Pi = [M+2K-(K+i2)modM]modM. (2.8)
где i = 1, 2, ..., (M-l)/2; К — первоначально вычисленный хэш-адрес.
Адреса, формируемые с использованием формулы (2.7), покрывают половину хэш-таблицы, а адреса, формируемые с использованием формулы (2.8), — вторую половину. Практически реализовать данный метод можно следующей процедурой.
1. Задание I = -М.
2. Вычисление хэш-адреса К одним из методов хэширования.
3. Если ячейка свободна или ключ элемента в ней совпадает с искомым ключом, то завершение процесса поиска. Иначе, 1:=1+1.
4. Вычисление h := (h+|i|)modM.
5. Если I < М, то переход к шагу 3. Иначе (если I > М), таблица полностью заполнена.
Программа та же, что приведена в методе линейного рехеширования, за исключением добавления одной команды для инициализации процесса рехеширования, самого фрагмента рехеширования и небольших изменений сегмента данных. могут являться методы, основанные на деревьях поиска, и т. п. Наибольший эффект от хеширования — при поиске по заданным идентификаторам или дескрипторам, что характерно для задач баз данных, обработки документов и т. д. Для задач, в которых поиск ведется сравнением или вычислением сложных логических функций, лучше использовать традиционные методы сортировки и поиска. Для того, чтобы совершить плавный переход к рассмотрению следующей структуры данных — спискам, вернемся еще раз к одной проблеме, связанной с массивами. Упоминалось, что среди массивов можно выделить массивы специального вида, которые называют разреженными. В этих массивах большинство элементов равны нулю. Отводить место для хранения всех элементов расточительно. Естественно, возникает желание сэкономить. Что для этого можно предпринять?
Техника обработки массивов предполагает, что все элементы расположены в соседних ячейках памяти. Для ряда приложений это недопустимое ограничение.
Обобщенно можно сказать, что все перечисленные выше структуры имеют общие свойства:
· постоянство структуры данных на всем протяжении ее существования;
· память для хранения отводится сразу всем элементам структуры и все элементы находятся в смежных ячейках памяти;
· отношения между элементами просты настолько, что можно исключить потребность в средствах хранения информации об их отношениях в какой бы то ни было форме.
Исходя из этих свойств, данные структуры данных и называют статическими. Снять подобные ограничения можно, используя другой тип данных — списки. Для них подобных ограничений не существует.
Наиболее часто встречается операция поиска записи по идентифицирующему его полю - ключу . Поэтому файл, как правило, индексируется по ключевому полю. Поиск по ключу в общем виде может рассматриваться как преобразование значения ключевого поля в адрес записи в файле (или номер записи), то есть как функция вида f(key) -> m.
Очевидно, можно сформулировать обратную задачу: если некоторым образом подобрать функцию f(), то ее можно использовать для определения места в файле, куда следует поместить запись с ключом key. Основное требование к такой функции: она должна как можно более равномерно распределять записи с различными значениями ключа по файлу, то есть иметь "случайный" вид. Кроме того, необходимо каким-то образом решить проблему "коллизий", то есть попадания нескольких записей с различными ключами в один физический адрес (номер записи).
Функция f() называется распределяющей или рассеивающей функцией. Пример одной из таких функций: берется квадрат значения ключа, из него извлекаются n значащих цифр из середины, которые и дают значение номера записи в файле:
int Place1024(key) // Функция рассеивания для файла из
unsigned key; // 1024 записей и 16 разрядного
{ // ключа
unsigned long n,n1;
int m;
n = (unsigned long)key * key;
for (m=0, n1 = n; n1 !=0; m++, n1 >>= 1); // Подсчет количества значащих
if (m < 10) return(n); // битовв n
m = (m - 10) / 2; // m - количество битов по краям
return( (n >> m) & 0x3FF);
}
Известны два способа решения проблемы коллизий. В первом случае файл содержит область переполнения . Если функция f() вычисляет адрес записи в файле, а соответствующее место уже заполнено записью с другим значением ключа, то новая запись помещается в область переполнения. При этом возможны два варианта:
- записи в области переполнения не связаны между собой, и для поиска в ней используется последовательный просмотр всех записей;
- в области переполнения организуются списки записей, участвующих в коллизии: то есть запись в основной области является заголовком списка записей в области переполнения, куда попадают все записи, вступающие в коллизию.
В другом случае запись, вступившая в коллизию, помещается в некоторое свободное место файла, начиная от текущей занятой позиции. Возможные варианты поиска:
- первая свободная позиция, начиная от текущей;
- проверяются позиции, пропорциональные квадрату шага относительно текущей занятой, то есть m = ( f(key) + i * i ) mod n, где i - номер шага, n - размер таблицы. Такое размещение позволяет лучше "рассеивать" записи при коллизии.
Рассматриваемый метод обозначается терминами расстановка или хеширование (от hash - смешивать, перемалывать).
Одним из существенных недостатков метода является необходимость заранее резервировать файл для размещения записей с номерами от 0 до m - в диапазоне возможных значений функции рассеивания. Кроме того, при заполнении файла увеличивается количество коллизий и эффективность метода падает. Если же количество записей возрастает настолько, что файл необходимо расширять, то это связано с изменением функции рассеивания и перераспределением (перезаписью) уже имеющихся записей в соответствии с новой функцией.

ГЛАВА 2. ПРАКТИЧЕСКАЯ ЧАСТЬ
2.1. Вставка элемента в в-дерево
Рассмотрим структуру узла B-дерева.
В каждом узле мы будем хранить не более NumberOfItems записей. Также нам надо будет хранить текущее количество записей в узле. Для удобства возврата назад к корню дерева будем запоминать для каждого узла указатель на его узел-предок.
Type
PBTreeNode = ^TBTreeNode;
TBTreeNode = record {узелдерева}
Count: Integer;
PreviousNode: PBTreeNode;
Items: array[0..NumberOfItems+1] of record
Value: ItemType;
NextNode: PBTreeNode;
end;
end;
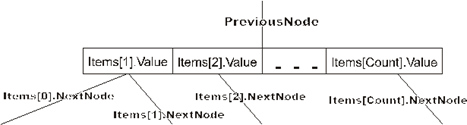
У элемента Items[0] будет использоваться только поле NextNode. Дополнительный элемент Items[NumberOfItems+1] предназначен для обработки переполнения, о чем будет рассказано ниже, где будет обсуждаться алгоритм добавления элемента в B-дерево.
Поскольку дерево упорядочено, то Items[1].Value<Items[2].Value<…< Items[Count].Value. Указатель Items[i].NextNode указывает на поддерево элементов, больших Items[i].Value и меньших Items[i+1].Value. Понятно, что указатель Items[0].NextNode будет указывать на поддерево элементов, меньших Items[1].Value, а указатель Items[Count].NextNode – на поддерево элементов, больших Items[Count].Value.
Само дерево можно задать просто указанием корневой вершины. Естественно, что у такой вершины PreviousNode будет равен nil.
Type
TBTree = TBTreeNode;
Прежде чем рассматривать алгоритмы, соберем воедино все требования к B-дереву :
1. каждый узел имеет не более NumberOfItems сыновей;
2. каждый узел, кроме корня, имеет не менее NumberOfItems/2 сыновей;
3. корень, если он не лист, имеет не менее 2-х сыновей;
4. все листья расположены на одном уровне (дерево сбалансировано);
5. нелистовой узел с k сыновьями содержит не менее k-1 ключ.
Из всего вышесказанного можно сразу сформулировать алгоритм поиска элемента в B-дереве.
Поиск элемента в B-дереве
Поиск будем начинать с корневого узла. Если искомый элемент присутствует в загруженной странице поиска, то завершаем поиск с положительным ответом, иначе загружаем следующую страницу поиска, и так до тех пор, когда либо найдем искомый элемент, либо не окажется «следующей страницы поиска» (пришли в лист B-дерева).
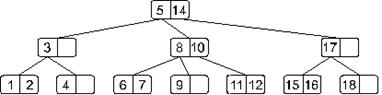
Посмотрим на примере, как это будет работать. Пусть мы имеем такое дерево (в наших примерах мы будем разбирать небольшие деревья, хотя в реальности B-деревья применяются при работе с большими массивами информации):

Будем искать элемент 11. Сначала загрузим корневой узел. Эта страница поиска содержит элементы 5 и 13. Наш искомый элемент больше 5, но меньше 13. Значит, идем по ссылке, идущей от элемента 5. Загружаем следующую страницу поиска (с элементами 8 и 10). Эта страница тоже не содержит искомого элемента. Замечаем, что 11 больше 10 – следовательно, двигаемся по ссылке, идущей от элемента 10. Загружаем соответствующую страницу поиска (с элементами 11 и 12), в которой и находим искомый элемент. Итак, в этом примере, чтобы найти элемент, нам понадобилось три раза обратиться к внешней памяти для чтения очередной страницы.
Если бы в нашем примере мы искали, допустим, элемент 18, то, просмотрев 3 страницы поиска (последней была бы страница с элементом 17), мы бы обнаружили, что от элемента 17 нет ссылки на поддерево с элементами большими 17, и пришли бы к выводу, что элемента 18 в дереве нет.
Теперь точно сформулируем алгоритм поиска элемента Item в B-дереве, предположив, что дерево хранится в переменной BTree, а функция LookFor возвращает номер первого большего или равного элемента узла (фактически производит поиск в узле).
function BTree.Exist(Item: ItemType): Boolean;
Var
CurrentNode: PBTreeNode;
Position: Integer;
begin
Exist := False;
CurrentNode := @BTree;
Repeat
Position := LookFor(CurrentNode, Item);
if (CurrentNode.Count>=Position)and
(CurrentNode.Items[Position].Value=Item) then
begin
Exist := True;
Exit;
end;
if CurrentNode.Items[Position-1].NextNode=nil then
Break
else
CurrentNode := CurrentNode.Items[Position-1].NextNode;
until False;
end;
Здесь мы пользуемся тем, что, если ключ лежит между Items[i].Value и Items[i+1].Value, то во внутреннюю память надо подкачать страницу поиска, на которую указывает Items[i].NextNode.
Заметим, что для ускорения поиска ключа внутри страницы поиска (функция LookFor), можно воспользоваться дихотомическим поиском, который описан ранее в главе, где разбирались способы хранения множества элементов в последовательном массиве.
Учитывая то, что время обработки страницы поиска есть величина постоянная, пропорциональная размеру страницы, сложность алгоритма поиска в B-дереве будет T(h), где h – глубина дерева.
Добавление элемента в B-дерево
Для того чтобы наше дерево можно было считать эффективной структурой данных для хранения множества значений, необходимо, чтобы каждый узел заполнился хотя бы наполовину. Дерево строится снизу. Это означает, что любой новый элемент добавляется в листовой узел. Если при этом произойдет переполнение (на этот случай в каждом узле зарезервирован лишний элемент), то есть число элементов в узле превысит NumberOfItems, то надо будет разделить узел на два узла, и вынести средний элемент на верхний уровень. Может случиться, что при этой операции на верхнем уровне тоже получится переполнение, что вызовет еще одно деление. В худшем случае эта волна докатится до корня дерева.
В общем виде алгоритм добавления элемента Item в B-дерево можно описать следующей последовательностью действий:
1. Поиск листового узла Node, в который следует произвести добавление элемента Item.
2. Добавление элемента Item в узел Node.
3. Если Node содержит больше, чем NumberOfItems элементов (произошло переполнение), то
o делим Node на две части, не включая в них средний элемент;
o Item=средний элемент Node;
o Node=Node.PreviousNode;
o Переходим к пункту 2.
Заметим, что при обработке переполнения надо отдельно обработать случай, когда Node – корень, так как в этом случае Node.PreviousNode=nil.
Посмотрим, как это будет работать, на примере.
Возьмем нарисованное ниже дерево и добавим в него элемент 13.
Двигаясь от корня, найдем узел, в который следует добавить искомый элемент. Таким узлом в нашем случае окажется узел, содержащий элементы 11 и 12. Добавим. В результате наше дерево примет такой вид:
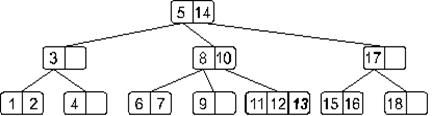
Понятно, что мы получили переполнение. При его обработке узел, содержащий элементы 11, 12 и 13 разделится на две части: узел с элементом 11 и узел с элементом 13, – а средний элемент 12 будет вынесен на верхний уровень. Дерево примет такой вид:

Мы опять получили переполнение, при обработке которого узел, содержащий элементы 8, 10 и 12 разделится на два узла: узел с элементом 8 и узел с элементом 12, – а средний элемент 10 будет вынесен на верхний уровень. И теперь дерево примет такой вид:

Теперь мы получили переполнение в корне дерева. Как мы оговаривали ранее этот случай надо обработать отдельно. Это связано с тем, что здесь мы должны будем создать новый корень, в который во время деления будет вынесен средний элемент:

Теперь полученное дерево не имеет переполнения.
В этом случае, как и при поиске, время обработки страницы поиска есть величина постоянная, пропорциональная размеру страницы, а значит, сложность алгоритма добавления в B-дерево будет также T(h), где h – глубина дерева.
Итак, как мы заметили с самого начала, у B-деревьев есть своя сфера применения: хранение настолько больших массивов информации, что их невозможно целиком разместить в выделяемой оперативной памяти, но требуется обеспечить быстрый доступ к ним.
В таких случаях B-деревья являются хорошим средством программно ускорить доступ к данным.
Ярким примером практического применения B-деревьев является файловая система NTFS, где B-деревья применяются для ускорения поиска имен в каталогах. Если сравнить скорость поиска в этой файловой системе и в обычной FAT на примере поиска на жестком диске большого объема или в каталоге, содержащем очень много файлов, то можно будет констатировать превосходство NTFS. А ведь поиск файла в каталоге всегда предшествует запуску программы или открытию документа.
B-деревья обладают прекрасным качеством: во всех трех операциях над данными (поиск/удаление/добавление) они обеспечивают сложность порядка T(h), где h – глубина дерева. Это значит, что чем больше узлов в дереве и чем сильнее дерево ветвится, тем меньшую часть узлов надо будет просмотреть, чтобы найти нужный элемент. Попробуем оценить T(h).
Число элементов в узле есть величина вероятностная с постоянным математическим ожиданием MK . Математическое ожидание числа узлов равно:
![]() ,
,
где n – число элементов, хранимых в B-дереве. Это дает сложность T(h)=T(log(n)), а это очень хороший результат.
Поскольку узлы могут заполняться не полностью (иметь менее NumberOfItems элементов), то можно говорить о коэффициенте использования памяти. Эндрю Яо доказал, что среднее число узлов после случайных вставок при больших n и NumberOfItems составит N/(m*ln(2))+F(n/m2), так что память будет использоваться в среднем на ln(2)*100%.
В отличие от сбалансированных деревьев B-деревья растут не вниз, а вверх. Поэтому (и из-за разной структуры узлов) алгоритмы включения/удаления принципиально различны, хотя цель их в обоих случаях одна – поддерживать сбалансированность дерева.
Идея внешнего поиска с использованием техники B-деревьев была предложена в 1970 году Р.Бэйером и Э.Мак-Крэйтом и независимо от них примерно в то же время М.Кауфманом. Естественно, что за это время было предложено ряд усовершенствований B-деревьев, связанных с увеличением коэффициента использования памяти и уменьшением общего количества расщеплений.
Одно из таких усовершенствований было предложено Р.Бэйером и Э.Мак-Крэйтом и заключалось в следующем. Если узел дерева переполнен, то прежде чем расщеплять этот узел, следует посмотреть, нельзя ли «перелить» часть элементов соседям слева и справа. При использовании такой методики уменьшается общее количество расщеплений и увеличивается коэффициент использования памяти.
program PTree; {$APPTYPE CONSOLE} type TInfo = Byte; PItem = ^Item; Item = record Key: TInfo; Left, Right: PItem; end; TTree = class private Root: PItem; public constructor Create; procedure Add(Key: TInfo); procedure Del(Key: TInfo); procedure View; procedure Exist(Key: TInfo); destructor Destroy; override; end; //--------------------------------------------------------- constructor TTree.Create; begin Root := nil; end; //--------------------------------------------------------- procedure TTree.Add(Key: TInfo); procedure IniTree(var P: PItem; X: TInfo); //созданиекорнядерева begin New(P); P^.Key :=X; P^.Left := nil; P^.Right := nil; end; procedure InLeft (var P: PItem; X : TInfo); //добавлениеузласлева var R : PItem; begin New(R); R^.Key := X; R^.Left := nil; R^.Right := nil; P^.Left := R; end; procedure InRight (var P: PItem; X : TInfo); //добавитьузелсправа var R : PItem; begin New(R); R^.Key := X; R^.Left := nil; R^.Right := nil; P^.Right := R; end; procedure Tree_Add (P: PItem; X : TInfo); var OK: Boolean; begin OK := false; while not OK do begin if X > P^.Key then //посмотретьнаправо if P^.Right <> nil //правыйузелне nil then P := P^.Right //обходсправа else begin //правый узел - лист и надо добавить к нему элемент InRight (P, X); //иконец OK := true; end else //посмотреть налево if P^.Left <> nil //левый узел не nil then P := P^.Left //обход слева else begin //левый узел -лист и надо добавить к нему элемент InLeft(P, X); //иконец OK := true end; end; //цикла while end; begin if Root = nil then IniTree(Root, Key) else Tree_Add(Root, Key); end; //------------------------------------------------------------- procedure TTree.Del(Key: TInfo); procedure Delete (var P: PItem; X: TInfo); var Q: PItem; procedure Del(var R: PItem); //процедура удаляет узел имеющий двух потомков, заменяя его на самый правый //узел левого поддерева begin if R^.Right <> nil then //обойти дерево справа Del(R^.Right) elsebegin //дошли до самого правого узла //заменить этим узлом удаляемыйQ^.Key := R^.Key; Q := R; R := R^.Left; end; end; //Del begin //Delete if P <> nil then //искатьудаляемыйузел if X < P^.Key then Delete(P^.Left, X) else if X > P^.Key then Delete(P^.Right, X) |
//искать в правом поддереве else begin //узел найден, надо его удалить //сохранить ссылку на удаленный узел Q := P; if Q^.Right = nil then //справа nil //и ссылку на узел надо заменить ссылкой на этого потомка P := Q^.Left else if Q^.Left = nil then //слева nil //и ссылку на узел надо заменить ссылкой на этого потомка P := P^.Right else //узел имеет двух потомков Del(Q^.Left); Dispose(Q); end else WriteLn('Такого элемента в дереве нет'); end; begin Delete(Root, Key); end; //------------------------------------------------------------- procedure TTree.View; procedure PrintTree(R: PItem; L: Byte); var i: Byte; begin if R <> nil then begin PrintTree(R^.Right, L + 3); for i := 1 to L do Write(' '); WriteLn(R^.Key); PrintTree(R^.Left, L + 3); end; end; begin PrintTree (Root, 1); end; //------------------------------------------------------------- procedure TTree.Exist(Key: TInfo); procedure Search(var P: PItem; X: TInfo); begin if P = nil then begin WriteLn('Такого элемента нет'); end else if X > P^. Key then //ищется в правом поддереве Search (P^. Right, X) else if X < P^. Key then Search (P^. Left, X) else WriteLn('Есть такой элемент'); end; begin Search(Root, Key); end; //------------------------------------------------------------- destructor TTree.Destroy; procedure Node_Dispose(P: PItem); //Удаление узла и всех его потомков в дереве begin if P <> nil then begin if P^.Left <> nil then Node_Dispose (P^.Left); if P^.Right <> nil then Node_Dispose (P^.Right); Dispose(P); end; end; begin Node_Dispose(Root); end; //------------------------------------------------------------- procedure InputKey(S: String; var Key: TInfo); begin WriteLn(S); ReadLn(Key); end; var Tree: TTree; N: Byte; Key: TInfo; begin Tree := TTree.Create; repeat WriteLn('1-Добавить элемент в дерево'); WriteLn('2-Вывести узлы дерева'); WriteLn('3-Проверить существование узла'); WriteLn('4-Выход'); ReadLn(n); with Tree do begin case N of 1: begin InputKey('Введите значение добавляемого элемента', Key); Add(Key); end; 2: View; 3: begin InputKey('Введите элемент, существование которого вы хотите проверить', Key); Exist(Key); end; end; end; until N=4; Tree.Destroy; end. |
2.2 ОБРАБОТКА ТЕКСТОВЫХ ФАЙЛОВ
Разработать блок-схему алгоритма и составить программу обработки текстовых данных, хранящихся в произвольном файле на магнитном диске. Вид обработки данных: подсчитать количество слов, которые содержат определённое количество согласных.
Привожу исходный текст программы:
Program file;
uses crt;
label
fin;
Constmn=['б','в','д','ж','з','к','л','м','н','п','р','с','т','ф','х','ц','ч','ш','щ'];
Var f3:text;
i,j,ch,sl:integer;
name:string;
s:char;
wrd :string;
dbase:string;
Begin
clrScr;
writeln('vvedite imya faila');
readln(name);
assign(f3,name);
reset(f3);
s:=' ';
sl:=0;
ch:=0;
while not eof(f3) do
begin
readln(f3,wrd);
i:=1;
While i<=length(wrd) do
begin
if wrd[i]<>' ' then sl:=sl+1;
while (wrd[i]<>' ') and (i<=length(wrd)) do inc(i);
inc(i)
end;
end;
close(f3);
reset(f3);
while not eof(f3) do
begin
while not eoln(f3) do
begin read(f3,s);
if (s in mn) then ch:=ch+1;
end;
end;
wrd:='c:\den.txt';
assign(f3,wrd);
{$I-}
append(f3);
{$I+}
if IOResult <> 0
then begin
{$I-}
rewrite(f3);
{$I+}
if IOResult <> 0
then
begin
writeln('ERROR!');
goto fin;
end;
end;
write(f3,' kol-vo slov --',sl,' kol-vo soglasnih --',ch,'');
writeln('chislo slov: ',sl,' chiso soglasnih: ',ch);
close(f3);
fin:
readkey;
End.
Приложение к выполненным программам
1. Обработка текстовых файлов
¦ Ввод данных ¦
¦ Запись в файл ¦
¦ Считывание файла ¦
¦ Обработка данных ¦
¦ Вывод результата ¦
+------ Выход ------+
Ввод данных:
Я хочу есть и спать, ещё я бы поиграл в комп.
Запись в файл
TEXT.pas
Вывод результата:
chisloslov: 11 chisosoglasnih: 17
Содержание выходного файла DEN.txt:
kol-vo slov --11 kol-vo soglasnih --17
2. Вставка элемента в В-дерево
1-Dobavitelementvderevo
2-Vivesti uzli dereva
3-Provtrit sushestvovanie uzla
4-vihod
1
Vvedite znacgenie dobavlayemogo elementa
33
1-Dobavit element v derevo
2-Vivesti uzli dereva
3-Provtrit sushestvovanie uzla
4-vihod
1
Vvedite znacgenie dobavlayemogo elementa
22
1-Dobavit element v derevo
2-Vivesti uzli dereva
3-Provtrit sushestvovanie uzla
4-vihod
1
Vvedite znacgenie dobavlayemogo elementa
44
1-Dobavit element v derevo
2-Vivesti uzli dereva
3-Provtrit sushestvovanie uzla
4-vihod
1
Vvedite znacgenie dobavlayemogo elementa
11
1-Dobavit element v derevo
2-Vivesti uzli dereva
3-Provtrit sushestvovanie uzla
4-vihod
2
44
33
22
11
1-Dobavit element v derevo
2-Vivesti uzli dereva
3-Provtrit sushestvovanie uzla
4-vihod
ЗАКЛЮЧЕНИЕ
Была выполнена курсовая работа по предмету «Структуры и алгоритмы компьютерной обработки данных» на тему «Алгоритмы преобразования ключей (расстановка)». В данной курсовой работе рассмотрены теоретические вопросы и выполнены практические задания, которые соответствуют выданному заданию.
В данной курсовой работе можно выделить 3 основных части, которые соответствуют следующим статусам:
1. Теоретическая часть;
2. Теоретическая + практическая часть;
3. Практическая часть;
В курсовой представлена вся необходимая информация по данной курсовой, использована как научная литература, так и возможности всемирной сети Internet. Выполнены практические задания, и использованием знаний и умений программировать на алгоритмических языках высокого уровня TurboPascal, BorlandDelphi.
СПИСОКИСПОЛЬЗОВАННОЙЛИТЕРАТУРЫ
1. Hellerman H. Digital Computer System Principles. McGraw-Hill, 1967.
2. Ершов А.П. Избранные труды. Новосибирск: ВО «Наука», 1994.
3. Кнут Д. Искусство программирования, т.3. М.: Вильямс, 2000.
4. Peterson W.W. Addressing for Random-Access Storage // IBM Journal of Research and Development. 1957. V.1, N2. Р.130—146.
5. Morris R. Scatter Storage Techniques // Communications of the ACM, 1968. V.11, N1. Р.38—44.
6. Ахо А., Хопкрофт Дж., Ульман Дж. Структуры данных и алгоритмы. М.: Вильямс, 2000.
7. Чмора А. Современная прикладная криптография. М.: Гелиос АРВ, 2001.
8. Кормен Т., Лейзерсон Ч., Ривест Р. Алгоритмы: построение и анализ. М.: МЦНМО, 2001.
9. Вирт Н. Алгоритмы + структуры данных = программы. М.: Мир, 1985.
10. Керниган Б., Пайк Р. Практика программирования. СПб.: Невский диалект, 2001.
11. Шень А. Программирование: теоремы и задачи. М.: МЦНМО, 1995.