| Скачать .docx |
Дипломная работа: Использование алгоритмов искусственного интеллекта в процессе построения UFO-моделей
Міністерство освіти і науки України
Харківський національний університет радіоелектроніки
Факультет прикладної математики та менеджменту
Кафедра соціальної інформатики
Магістерська атестаційна робота
Пояснювальна записка
2071197.ПЗ
Використання алгоритмів штучного інтелекту у процесі побудови UFO-моделей
Магістрант гр. КСмаг-05-1
Сергієнко І.М.
Науковий керівник
доц. Єльчанінов Д.Б.
Допускається до захисту
Зав. Кафедри
Соловйова К.О.
2009
Харківський національний університет радіоелектроніки
Факультет ПММ
Кафедра СІ
Спеціальність 8.000012 – "Консолідована інформація"
Завдання
на магістерську атестаційну роботу
магістрантові Сергієнко Івану Миколайовичу
1. Тема роботи Використання алгоритмів штучного інтелектуу процесі побудови UFO-моделей затверджена наказом по університету від " 12 "квітня2006 р. №556 Ст
2. Термін здачі магістрантом закінченої роботи12.06.2006
3. Вихідні дані до роботиосновні алгоритми штучного інтелекту,основні поняття UFO-аналізу
4. Зміст пояснювальної записки (перелік питань, що їх потрібно розробити) перелік умовних позначень, символів, одиниць, скорочень і термінів; вступ; огляд сучасного стану проблеми; адаптація алгоритму мурахи до процесу UFO-моделювання;використання Microsoft Excel у процесі UFO-моделювання на основі алгоритму мурахи;UFO-моделі шахтної транспортної системи;
Висновки
5. Перелік графічного матеріалу (з точним зазначенням обов’язкових креслень, плакатів)
тема роботи; актуальність дослідження; мета дослідження; постановка задачі;
адаптація алгоритму мурахи до процесу UFO-моделювання;
використання Microsoft Excel у процесі UFO-моделювання на основі алгоритму мурахи;
UFO-моделі шахтної транспортної системи; висновки; апробація результатів
6. Консультанти з роботи із зазначенням розділів роботи, що їх стосуються(п.6 заповнюється в разі необхідності)
| Найменуваннярозділу | Консультант(посада, прізвище, ім’я, по батькові) | Позначка консультанта про виконання розділу |
|
| (підпис) | (дата) | ||
7. Дата видачі завдання13.03.06
Науковий керівникдоц. Єльчанінов Дмитро Борисович
Завдання прийняв до виконанняСергієнко Іван Миколайович
Календарний план
| № | Назва етапів магістерської атестаційної роботи | Термін виконанняетапів роботи | Примітка |
| 1 | Аналіз проблемної області та постановка задачі | 03.04.06 | |
| 2 | Адаптація алгоритму мурахи до процесу UFO-моделювання | 17.04.06 | |
| 3 | Використання Microsoft Excel у процесі моделювання на основі алгоритму мурахи | 01.05.06 | |
| 4 | Розробка UFO-моделей шахтної транспортної системи | 15.05.06 | |
| 5 | Підготовка пояснювальної записки. | 29.05.06 | |
| 6 | Підготовка презентації та доповіді | 05.06.06 | |
| 7 | Попередній захист | 12.06.06 | |
| 8 | Нормоконтроль, рецензування | 14.06.06 | |
| 9 | Занесення диплома в електронний архів | 15.06.06 | |
| 10 | Допуск до захисту у зав. кафедрою | 16.06.06 |
МагістрантСергієнко Іван Миколайович
Науковий керівник Єльчанінов Д.Б.
Реферат
Пояснювальна записка: 44 рис., 1 додаток, 46 джерел.
Об’єкт дослідження – процес побудови UFO-моделей.
Мета роботи –дослідження можливості використання алгоритмів штучного інтелекту у процесі побудови UFO-моделей.
Методи дослідження –методи штучного інтелекту та сучасні комп’ютерні технології обробки табличних даних.
Результати роботи – адаптація алгоритму мурахи до процесу UFO-моделювання; використання MicrosoftExcel у процесі UFO-моделювання на основі алгоритму мурахи; UFO-моделі шахтної транспортної системи.
штучний інтелект, алгоритм мурахи, UFO-аналіз, моделювання, табличний процесор
Реферат
Пояснительная записка: 44 рис., 1 приложение, 46 источников.
Объект исследования – процесс построения UFO-моделей.
Цель работы – исследование возможности использования алгоритмов искусственного интеллекта в процессе построения UFO-моделей.
Методы исследования – методы искусственного интеллекта и современные компьютерные технологии обработки табличных данных.
Результаты работы – адаптация алгоритма муравья к процессу UFO-моделирования; использованиеMicrosoftExcel в процессе UFO-моделирования на основе алгоритма муравья; UFO-моделишахтной транспортной системы.
искусственный интеллект, Алгоритм муравья, UFO-анализ, МОДЕЛИРОВАНИЕ, табличный процессор
ABSTRACT
Explanatory note: 44 fig., 1 appendix, 46 references.
Research object – process of UFO-models construction.
Work purpose – researching of possibility of artificial intelligence methods using in process of UFO-models construction.
Researchmethods – artificial intelligence methods and modern computer technologies of tabular data processing.
Work results – ant algorithm adaptation to UFO-modeling process; Microsoft Excel using in UFO-modeling process based on ant algorithm; UFO-models of mining transport system.
artificial intelligence, ant algorithm, UFO-analysis, modeling, tabular processor
Содержание
Перечень условных обозначений, символов, единиц, сокращений и терминов
Введение
1. Обзор современного состояния проблемы
1.1 Современные технологии построения систем
1.2 Прикладные методы и технологии искусственного интеллекта
1.2.1 Нейронные сети
1.2.2 Генетические алгоритмы
1.2.3 Системы, основанные на продукционных правилах
1.2.4 Нечеткая логика
1.2.5 Умные агенты
1.2.6 Алгоритм муравья
1.3 Постановка задачи
2. Адаптация алгоритма муравья к задаче построенияUFO-модели из заданных компонентов
2.1 Начальное размещение муравья
2.2 Правила соединения UFO-компонентов
2.3 Элементарное перемещение муравья
2.3.1 Перемещение из входа контекстной диаграммы
2.3.2 Перемещение из выхода контекстной диаграммы
2.3.3 Перемещение из входа UFO-компонента
2.3.4 Перемещение из выхода UFO-компонента
2.3.5 Пример перемещений муравья
2.4. Перемещение нескольких муравьев
2.4.1 Разрешение конфликтов
2.4.2 Пример перемещений нескольких муравьев
3. Пример использования MicrosoftExcel в процессепостроения UFO-модели из заданных компонентовна основе алгоритма муравья
4. Использование алгоритма муравья в процессе UFO-моделирования шахтнойтранспортной системы
4.1 Общие сведения о подразделении "Шахта "Комсомольская""
4.2 Подготовка и вскрытие шахтного поля
4.3 UFO-модель шахтной транспортной системы
Выводы
Перечень ссылок
искусственный интеллект компьютерный муравей шахтный
Перечень условных обозначений, символов, единиц, сокращений и терминов
CASE – computer-aided system engineering;
DFD – диаграммы потоков данных;
IDEF0 – стандарт функционального моделирования;
IDEF3– стандарт документирования технологических процессов;
Муравей – программный агент, который является членом большой колонии и используется для решения какой-либо проблемы;
УФО – Узел-Функция-Объект.
Введение
В современных технологиях анализа и моделирования систем процесс построения моделей приходится осуществлять проектировщику вручную, основываясь на своем опыте и интуиции с помощью CASE-средств.
Современные прикладные методы и технологии искусственного интеллекта (нейронные сети, генетические алгоритмы, нечеткая логика, умные агенты, алгоритмы муравья и т.п.) ориентированы не столько на копирование поведения человека, сколько на достижение результатов, аналогичных человеческим результатам.
Для автоматического построения конфигурации системы целесообразно применить алгоритм муравья, который в настоящее время широко используется для поиска оптимальных путей по графу.
Таким образом, актуальной является проблема автоматического построения модели системы из заданных компонентов.
Целью данной магистерской аттестационной работы является исследование возможности использования алгоритмов искусственного интеллекта в процессе построения UFO-моделей.
Полученные результаты можно использовать в процессе UFO-анализа, а также для внедрения в CASE-инструментарии, используемые в процессе моделирования систем.
1. Обзор современного состояния проблемы
1.1 Современные технологии построения систем
Рассмотрим стандартные методы системного структурного анализа.
Стандарт IDEF0 предназначен для создания функциональной модели, отображающей структуру и функции системы, а также потоки информации и материальных объектов, связывающих эти функции [1-4].
Диаграммы потоков данных (DFD) являются основным средством моделирования функциональных требований к проектируемой системе. С их помощью эти требования разбиваются на функциональные компоненты (процессы) и представляются в виде сети, связанной потоками данных. Главная цель таких средств – продемонстрировать, как каждый процесс преобразует свои входные данные в выходные, а также выявить отношения между этими процессами [5-6].
Стандарт IDEF3 предназначен для документирования технологических процессов, происходящих на предприятии, и предоставляет инструментарий для наглядного исследования и моделирования их сценариев [7-8].
Все вышеперечисленные стандарты поддерживаются CASE-средством моделирования и документирования бизнес-процессов BPwin. Однако весь процесс построения моделей приходится осуществлять проектировщику вручную, основываясь на своем опыте и интуиции [9-10].
Более перспективной является так называемая УФО-технология анализа и моделирования систем, в которой решается задача автоматического построения многоуровневой конфигурации из заданных компонентов. Однако если конфигурацию не удается представить в виде нескольких уровней, то автоматически не получится построить конфигурацию, не привлекая опытного проектировщика. УФО-технология поддерживается CASE-средством UFO-toolkit, использующим базу знаний специальной конфигурации, включающей в себя библиотеку УФО-элементов и классификацию связей [11-14].
1.2 Прикладные методы и технологии искусственного интеллекта
Ранние разработки искусственного интеллекта были ориентированы на создание умных машин, которые копировали поведение человека, однако в настоящее время большинство исследователей и разработчиков искусственного интеллекта преследуют более практичные цели. В число прикладных алгоритмов входят [15]:
– нейронные сети;
– генетические алгоритмы;
– системы, основанные на продукционных правилах;
– нечеткая логика;
– умные агенты;
– алгоритмы муравья.
1.2.1 Нейронные сети
В отношении систем искусственного интеллекта иногда можно услышать следующие критические замечания:
– такие системы слишком "хрупкие" в том смысле, что, встретившись с ситуацией, не предусмотренной разработчиком, они либо формируют сообщения об ошибках, либо дают неправильные результаты (другими словами, эти программы довольно просто можно "поставить в тупик");
– они не способны непрерывно самообучаться, как это делает человек в процессе решения возникающих проблем.
Еще в середине 1980-х годов многие исследователи рекомендовали использовать для преодоления этих и других недостатков нейронные сети.
В самом упрощенном виде нейронную сеть можно рассматривать как способ моделирования в технических системах принципов организации и механизмов функционирования головного мозга человека. Согласно современным представлениям, кора головного мозга человека представляет собой множество взаимосвязанных простейших ячеек – нейронов, количество которых оценивается числом порядка 1010 [16]. Технические системы, в которых предпринимается попытка воспроизвести, пусть и в ограниченных масштабах, подобную структуру (аппаратно или программно), получили наименование нейронные сети.
Нейрон головного мозга получает входные сигналы от множества других нейронов, причем сигналы имеют вид электрических импульсов. Входы нейрона делятся на две категории: возбуждающие и тормозящие. Сигнал, поступивший на возбуждающий вход, повышает возбудимость нейрона, которая при достижении определенного порога приводит к формированию импульса на выходе. Сигнал, поступающий на тормозящий вход, наоборот, снижает возбудимость нейрона. Каждый нейрон характеризуется внутренним состоянием и порогом возбудимости. Если сумма сигналов на возбуждающих и тормозящих входах нейрона превышает этот порог, нейрон формирует выходной сигнал, который поступает на входы связанных с ним других нейронов, т.е. происходит распространение возбуждения по нейронной сети. Типичный нейрон может иметь до 103 связей с другими нейронами [17].
Было обнаружено, что время переключения отдельного нейрона головного мозга составляет порядка нескольких миллисекунд, т.е. процесс переключения идет достаточно медленно. Поэтому исследователи пришли к заключению, что высокую производительность обработки информации в мозге человека можно объяснить только параллельной работой множества относительно медленных нейронов и большим количеством взаимных связей между ними. Именно этим объясняется широкое распространение термина "массовый параллелизм" в литературе, касающейся нейронных сетей.
Независимо от способа реализации, нейронную сеть можно рассматривать как взвешенный ориентированный граф. Узлы в этом графе соответствуют нейронам, а ребра – связям между нейронами. С каждой связью ассоциирован вес (рациональное число) который отображает оценку возбуждающего или тормозящего сигнала, передаваемого по этой связи на вход нейрона-реципиента, когда нейрон-передатчик возбуждается [18].
Поскольку нейронная сеть носит явно выраженный динамический характер, время является одним из основных факторов ее функционирования. При моделировании сети время изменяется дискретно, и состояние сети можно рассматривать как последовательность мгновенных снимков, причем каждое новое состояние зависит только от предыдущего цикла возбуждения нейронов [19].
Для выполнения обработки информации с помощью такой сети необходимо соблюдение определенных соглашений. Для того, чтобы сеть стала активной, она должна получить некоторый входной сигнал. Поэтому некоторые узлы сети играют роль "сенсоров" и их активность зависит от внешних источников информации. Затем возбуждение передается от этих входных узлов к внутренним и таким образом распространяется по сети. Это обычно выполняется посредством установки высокого уровня активности входных узлов, которая поддерживается в течение нескольких циклов возбуждения, а затем уровень активности сбрасывается.
Часть узлов сети используется в качестве выходных, и их состояние активности считывается в конце процесса вычислений. Но часто интерес представляет и состояние всей сети после того, как вычисления закончатся, либо состояние узлов с высоким уровнем активности. В некоторых случаях интерес может представлять наблюдение за процессом установки сети в стабильное состояние, а в других – запись уровня активизации определенных узлов перед тем, как процесс распространения активности завершится [20-24].
В контексте нейронных сетей изучается искусственная жизнь. Например, рассматривается развитие простых организмов в синтетической среде. Только избегая хищников и находя пищу, организмы выживают в среде. Воспроизводство агентов допускается только в том случае, если они выживают и достигают определенного уровня внутренней энергии. Это позволяет получать более здоровое и совершенное потомство. В качестве нейроконтроллеров для агентов выступают многослойные нейронные сети. Простые пищевые цепочки создаются с помощью двух различных типов организмов (хищника и травоядного) [25].
1.2.2 Генетические алгоритмы
Генетические алгоритмы предлагают модель оптимизации, которую можно применять при решении как числовых, так и символических задач. Генетическое программирование используется, например, при создании последовательности инструкций. Подобные последовательности применяются при решении математических задач [26].
Генетические алгоритмы отражают принципы естественного отбора и генетики: выживание наиболее перспективные особей, наследование и мутации. При этом человек не вмешивается в процесс поиска, но может опосредственно влиять на него заданием определенных параметров.
Как и все методы случайного поиска, генетические алгоритмы ориентированы на нахождение не оптимального решения, а на поиск лучшего, чем существующие на данный момент решения. Такой подход эффективен для сложных систем, где зачастую необходимо каким-то образом улучшить текущее решение, а задача поиска оптимального решения не ставится из-за сложности системы и, как следствие, невозможности применения традиционных методов, которые направлены на нахождение оптимальных решений.
Основные отличия генетических алгоритмов от традиционных методов заключаются в следующем [27].
Генетические алгоритмы оперируют с решениями, представленными в виде кодовой строки. И преобразования кодов производятся вне какой-либо связи с их семантикой.
Процесс поиска основан на использовании нескольких точек пространства решений одновременно. Это устраняет возможность нежелательного попадания в локальный экстремум целевой функции, не являющейся унимодальной.
В процессе поиска генетическим алгоритмом используется только информация о допустимых значениях параметров и целевой функции, что приводит к значительному повышению быстродействия.
Для синтеза новых точек генетический алгоритм использует вероятностные правила, а для перехода от одних точек к другим – детерминированные. Такое объединение правил значительно эффективнее, чем их раздельное использование.
При этом в теории генетических алгоритмов используется ряд биологических терминов [28].
Кодовая строка, описывающая возможное решение, и ее структура называются генотипом. Интерпретация кода с позиции решаемой задачи – фенотипом. Например, для предметной области САПР фенотипом будет некоторое проектное решение в виде структурной схемы вычислительного устройства [29-31]. Код также называют хромосомой.
Совокупность хромосом, одновременно используемых генетическим алгоритмом на каждом этапе поиска, называется популяцией. Размер популяции (число хромосом) обычно фиксируется и является одной из характеристик генетического алгоритма. Популяция обновляется созданием новых хромосом и уничтожением старых. Таким образом происходит смена поколений популяций.
Генерация новых хромосом основана на моделировании процесса размножения: пара родителей порождает пару потомков. За генерацию отвечает оператор скрещивания, который в общем случае применяется к каждой родительской паре с некоторой вероятностью. Значение этой вероятности наряду с размером популяции является одной из характеристик генетического алгоритма.
К хромосомам новой популяции применяется оператор мутации. Вероятность применения этого оператора к хромосоме также является параметром генетического алгоритма.
Оператор отбора осуществляет выбор родительских хромосом для порождения потомков, а оператор редукции – выбор хромосом, подлежащих уничтожению. В обоих случаях выбор делается на основании качества хромосомы, которое определяется значением целевой функции на этой хромосоме.
Генетический алгоритм прекращает свою работу в следующих случаях:
– он обработал число поколений, заданных пользователем перед началом работы алгоритма;
– качество всех хромосом превысило значение, заданное пользователем до начала работы алгоритма;
– хромосомы стали однородными до такой степени, что их улучшение от поколения к поколению происходит очень медленно.
В генетических алгоритмах часто используется стратегия элитизма, заключающаяся в переходе лучших хромосом текущей популяции в следующее поколение без изменений. Такой подход обеспечивает поддержание высокого уровня качества популяции.
Оператор мутации вносит случайные изменения в хромосомы, расширяя область пространства поиска.
Многократное применение операторов редукции, отбора, скрещивания и мутации способствует улучшению качества каждой отдельной хромосомы и, как следствие, популяции в целом, отражая основную цель генетического алгоритма – повышение качества начальной популяции. Основным результатом работы генетического алгоритма является хромосома конечной популяции, на которой целевая функция принимает экстремальное значение.
Генетические алгоритмы являются стратегическим подходом к решению проблемы, который необходимо адаптировать к конкретной предметной области путем задания параметров и определения операторов генетического алгоритма. При этом генетический алгоритм становиться сильно привязанным к рассматриваемой предметной области и может быть совершенно бесполезен для решения задач в другой предметной области [32].
От удачного выбора параметров, операторов и вида хромосом зависят устойчивость и скорость поиска – основных показателей эффективности генетического алгоритма. Скорость определяется временем, необходимым для достижения алгоритмом одного из указанных выше критериев останова. Устойчивость – это способность генетического алгоритма увеличивать качество популяции и выходить из локальных экстремумов.
Для увеличения скорости генетические алгоритмы могут подвергаться распараллеливанию как на уровне организации работы алгоритма, так и на уровне его реализации на ЭВМ.
На уровне организации работы распараллеливание осуществляется за счет структурирования популяции, которое может осуществляться двумя способами.
Первый способ называется "концепция островов" и заключается в разбиении популяции на классы (демосы), члены которых скрещиваются только между собой в пределах класса, лишь изредка обмениваясь хромосомами на основе случайной выборки. Второй способ называется "концепция скрещивания в локальной области" и заключается в задании метрического пространства на популяции, хромосомы которой подвергаются скрещиванию только с ближайшими соседями.
Что касается распараллеливания на уровне реализации, то как указанные выше процессы скрещивания пар родителей, так и процессы вычисления значений целевой функции и применения оператора мутации к хромосомам можно реализовать одновременно на нескольких параллельно работающих процессорах или системах.
Устойчивость поиска зависит от параметров операторов генетического алгоритма [33].
Для оператора скрещивания таким параметром служит степень отличия потомков от родительских хромосом: чем больше это отличие, тем устойчивей поиск, но скорость поиска меньше (лучший результат достигается за большее время).
Для оператора мутации параметром, влияющим на устойчивость поиска, служит вероятность его применения: малая вероятность обеспечивает устойчивый поиск и не приводит к ухудшению качества хромосом.
Оператор отбора связан с устойчивостью поиска следующим образом: постоянный выбор сильнейших хромосом обычно приводит к сходимости к локальному экстремуму, а выбор слабых хромосом – к ухудшению качества популяции. Аналогичное утверждение справедливо и для оператора редукции.
Что касается влияния размера популяции на устойчивость генетического алгоритма, то увеличение числа хромосом в популяции расширяет область поиска, но при этом время от времени полезно редуцировать популяцию до первоначального размера, иначе скорость генетического алгоритма резко упадет. Подобные алгоритмы называются поколенческими [34].
Развитие поколенческих алгоритмов привело к появлению адаптивных генетических алгоритмов, изменяющих свои параметры в процессе работы. Возникла концепция nGA, представляющая многоуровневые генетические алгоритмы, в которых нижний уровень улучшает популяцию, а верхний – оптимизирует параметры нижнего уровня, ориентируясь при этом на его скорость и устойчивость.
1.2.3 Системы, основанные на продукционных правилах
В системах продукций знания представляются с помощью наборов правил вида: "если А, то В". Здесь А и В могут пониматься как "ситуация-действие", "причина-следствие", "условие-заключение" и т.п. Часто правило-продукцию записывают с использованием знака логического следования: А Þ В.
В общем случае продукционная система включает следующие компоненты:
– базу продукционных правил;
– базу данных (рабочую память);
– интерпретатор.
Множество продукционных правил образует базу правил, каждое из которых представляет обособленный фрагмент знаний о решаемой проблеме. Психологи называют такие фрагменты чанками (от англ. chunk). Считается, что чанк – это объективно существующая единица знаний, выделяемая человеком в процессе познания окружающего мира.
Предпосылка правила часто рассматривается как образец. Образец – это некоторая информационная структура, определяющая обобщенную ситуацию окружающей действительности, при которой активизируется правило. Рабочая память отражает конкретные ситуации, возникающие во внешней среде. Информационная структура, представляющая конкретную ситуацию внешней среды в рабочей памяти, называется образом [35].
Интерпретатор реализует логический вывод. Процесс вывода является циклическим и называется поиском по образцу. Рассмотрим его в упрощенной форме. Текущее состояние моделируемой предметной области отражается в рабочей памяти в виде совокупности образов, каждый из которых представляется посредством фактов. Рабочая память инициализируется фактами, описывающими задачу. Затем выбираются те правила, для которых образцы, представляемые предпосылками правил, сопоставимы с образами в рабочей памяти. Данные правила образуют конфликтное множество. Все правила, входящие в конфликтное множество могут быть активизированы. В соответствии с выбранным механизмом разрешения конфликта активизируется одно из правил. Выполнение действия, содержащегося в заключении правила, приводит к изменению состояния рабочей памяти. В дальнейшем цикл управления выводом повторяется. Указанный процесс завершается, когда не окажется правил, предпосылки которых сопоставимы с образами рабочей памяти [36].
Таким образом, процесс вывода, основанный на поиске по образцу, состоит из четырех шагов:
– выбор образа;
– сопоставление образа с образцом и формирование конфликтного набора правил;
– разрешение конфликтов;
– выполнение правила.
Широкое применение продукционных моделей определяется следующими основными достоинствами:
– универсальностью (практически любая область знаний может быть представлена в продукционной форме);
– модульностью (каждая продукция представляет собой элемент знаний о предметной области, удаление одних и добавление других продукций выполняется независимо);
– декларативностью (продукции определяют ситуации предметной области, а не механизм управления);
– естественностью процесса вывода заключений, который во многом аналогичен процессу рассуждений эксперта;
– асинхронностью и естественным параллелизмом, который делает их весьма перспективным для реализации на параллельных ЭВМ.
Однако продукционные системы не свободны от недостатков:
– процесс вывода имеет низкую эффективность, так как при большом числе продукций значительная часть времени затрачивается на непроизводительную проверку условия применения правил;
– проверка непротиворечивости системы продукций становится весьма сложной из-за недетерминированности выбора выполняемой продукции из конфликтного множества.
В системах, основанных на правилах, часто акцент делается на системах прямого логического вывода. Например, в качестве правил и начальных фактов используется ряд примеров, что позволяет встроить систему с правилами в более крупную систему и задействовать ее для создания системы управления сенсорами, устойчивой к ошибкам [37].
1.2.4 Нечеткая логика
Ту роль, которую в классической теории множеств играет двузначная булева логика, в теории нечетких множеств играет многозначная нечеткая логика, в которой предположения о принадлежности объекта множеству, например Быстрый("Порш"), могут принимать действительные значения в интервале от 0 до 1. Возникает вопрос, а как, используя концепцию неопределенности, вычислить значение истинности сложного выражения, такого как Не(Быстрый("Шевроле")).
По аналогии с теорией вероятности, если F представляет собой нечеткий предикат, операция отрицания реализуется по формуле Не(F)=1–F.
Но аналоги операций конъюнкции и дизъюнкции в нечеткой логике не имеют никакой связи с теорией вероятностей [38]. Рассмотрим следующее выражение: ""Порш" является быстрым, представительским автомобилем".
В классической логике предположение (Быстрый("Порш")) И (Представительский ("Порш")) является истинным в том и только в том случае, если истинны оба члена конъюнкции. В нечеткой логике существует соглашение: если F и G являются нечеткими предикатами, то f(F Ù G )(X)=min(fF (X), fG (X)).
Таким образом, если Быстрый("Порш")=0,9 и Представительский("Порш")=0,7, то (Быстрый("Порш"))И(Представительский ("Порш")) = 0,7.
А теперь рассмотрим выражение (Быстрый("Порш")) И Не(Быстрый("Порш")). Вероятность истинности этого утверждения равна 0, но в нечеткой логике значение этого выражения будет равно 0,1. Какой смысл имеет это значение? Его можно считать показателем принадлежности автомобиля к нечеткому множеству среднескоростных автомобилей, которые в чем-то близки к быстрым, а в чем-то – к медленным.
Смысл выражения Быстрый("Порш")=0,9 заключается в том, что мы только на 90% уверены в принадлежности этого автомобиля к быстрым именно из-за неопределенности самого понятия "быстрый автомобиль". Вполне резонно предположить, что существует некоторая уверенность в том, что "Порш" не принадлежит к быстрым. Например, он медленнее автомобиля, принимающего участие в гонках "Формула-1".
Аналог операции дизъюнкции в нечеткой логике определяется следующим образом: f(F Ú G )(X)=max(fF (X), fG (X)).
Операторы обладают свойствами коммутативности, ассоциативности и взаимной дистрибутивности. Как к операторам в стандартной логике, к ним применим принцип композитивности, т.е. значения составных выражений вычисляются только по значениям выражений-компонентов. В этом операторы нечеткой логики составляют полную противоположность законам теории вероятностей, согласно которым при вычислении вероятностей конъюнкции и дизъюнкции величин нужно принимать во внимание условные вероятности [39].
Нечеткая логика имеет дело с ситуациями, когда и сформулированный вопрос, и знания, которыми мы располагаем, содержат нечетко очерченные понятия. Однако нечеткость формулировки понятий является не единственным источником неопределенности. Иногда мы просто не уверены в самих фактах. Если утверждается: "Возможно, Иван сейчас в Киеве", то говорить о нечеткости понятий Иван и Киев не приходится. Неопределенность заложена в самом факте, действительно ли Иван находится в Киеве.
Теория возможностей является одним из направлений в нечеткой логике, в котором рассматриваются точно сформулированные вопросы, базирующиеся на неточных знаниях.
На основе нечеткой логики часто строятся системы управления. Например, в модели зарядного устройства для батарей функции содержат не только стандартные операторы нечеткой логики, но и вспомогательные функции, которые поддерживают создание функций нечеткой логики [40].
1.2.5 Умные агенты
Агент – это аппаратная или программная сущность, способная действовать в интересах достижения целей, поставленных перед ним владельцем и/или пользователем [41].
Проблематика интеллектуальных агентов и мультиагентных систем имеет уже почти 40-летнюю историю и сформировалась на основе результатов, полученных в рамках работ по распределенному искусственному интеллекту, распределенному решению задач и параллельному искусственному интеллекту. Но, пожалуй, лишь в последнее десятилетие она выделилась в самостоятельную область исследований и приложений и все больше претендует на одну из ведущих ролей в рамках интеллектуальных информационных технологий. Спектр работ по данной тематике весьма широк, интегрирует достижения в области компьютерных сетей и открытых систем, искусственного интеллекта и информационных технологий и ряда других исследований, а результаты уже сегодня позволяют говорить о новом качестве получаемых решений.
В настоящее время множество исследовательских лабораторий, университетов, фирм и промышленных организаций работают в этой области, и список их постоянно расширяется. Он включает мало известные имена и небольшие коллективы, уже признанные исследовательские центры и организации, а также огромные транснациональные компании. Областями практического использования агентных технологий являются:
– управление информационными потоками и сетями;
– управление воздушным движением;
– информационный поиск;
– электронная коммерция;
– обучение;
– электронные библиотеки.
К построению агентно-ориентированных систем можно указать два подхода: реализация единственного автономного агента или разработка мультиагентной системы. Автономный агент взаимодействует только с пользователем и реализует весь спектр функциональных возможностей, необходимых в рамках агентно-ориентированной программы. В противовес этому мультиагентные системы являются программно-вычислительными комплексами, где взаимодействуют различные агенты для решения задач, которые трудны или недоступны в силу своей сложности для одного агента. Часто такие мультиагентные системы называют агентствами, в рамках которых агенты общаются, кооперируются и договариваются между собой для поиска решения поставленной перед ними задачи.
Агентные технологии обычно предполагают использование определенных типологий агентов и их моделей, архитектур мультиагентных систем и опираются на соответствующие агентные библиотеки и средства поддержки разработки разных типов мультиагентных систем.
Умные агенты применяются различными способами. Например, существует агент-фильтр, использующийся для фильтрации информации из сети Интернет. Параметры поиска Web-агента задаются в простом файле конфигурации. Затем агент автономно собирает новости через протокол NNTP и предоставляет их пользователю с помощью HTTP-протокола, действуя аналогично Web-серверу [42].
1.2.6 Алгоритм муравья
Алгоритмы муравья – это сравнительно новый метод, который может использоваться для поиска оптимальных путей по графу. Данные алгоритмы симулируют движение муравьев в окружающей среде и используют модель ферментов для коммуникации с другими агентами [43].
Хотя муравьи и слепы, они умеют перемещаться по сложной местности, находить пищу на большом расстоянии от муравейника и успешно возвращаться домой. Выделяя ферменты во время перемещения, муравьи изменяют окружающую среду, обеспечивают коммуникацию, а также отыскивают обратный путь в муравейник.
Самое удивительное в данном процессе – это то, что муравьи умеют находить самый оптимальный путь между муравейником и внешними точками. Чем больше муравьев используют один и тот же путь, тем выше концентрация ферментов на этом пути. Чем ближе внешняя точка к муравейнику, тем больше раз к ней перемещались муравьи. Что касается более удаленной точки, то ее муравьи достигают реже, поэтому по дороге к ней они применяют более сильные ферменты. Чем выше концентрация ферментов на пути, тем предпочтительнее он для муравьев по сравнению с другими доступными. Так муравьиная "логика" позволяет выбирать более короткий путь между конечными точками.
Алгоритмы муравья интересны, поскольку отражают ряд специфических свойств, присущих самим муравьям. Муравьи легко вступают в сотрудничество и работают вместе для достижения общей цели. Алгоритмы муравья работают так же, как муравьи. Это выражается в том, что смоделированные муравьи совместно решают проблему и помогают другим муравьям в дальнейшей оптимизации решения.
Рассмотрим пример [15]. Два муравья из муравейника должны добраться до пищи, которая находится за препятствием. Во время перемещения каждый муравей выделяет немного фермента, используя его в качестве маркера.
При прочих равных каждый муравей выберет свой путь. Пусть первый муравей выбирает путь, который в два раза длиннее, чем путь, выбранный вторым муравьем. Так как путь второго муравья в два раза короче пути первого муравья, то, когда второй муравей достигнет цели, первый муравей в этот момент пройдет только половину пути.
Когда муравей достигает пищи, он берет один из объектов и возвращается к муравейнику по тому же пути. Когда второй муравей вернется в муравейник с пищей, первый муравей еще только достиг пищи.
При перемещении каждого муравья на пути остается немного фермента. Для первого муравья за это время путь был покрыт ферментом только один раз. В то же самое время второй муравей покрыл путь ферментом дважды. Когда первый муравей вернется в муравейник, второй муравей уже успеет еще раз сходить к еде и вернуться. При этом концентрация фермента на пути второго муравья будет в два раза выше, чем на пути первого. Поэтому первый муравей в следующий раз выберет путь второго муравья, поскольку там концентрация фермента выше.
В этом и состоит базовая идея алгоритма муравья – оптимизация путем непрямой связи между автономными агентами.
1.3 Постановка задачи
Проведенный анализ современного состояния проблемы показывает, что:
– в современных технологиях построения систем процесс построения моделей приходится осуществлять проектировщику вручную, основываясь на своем опыте и интуиции с помощью CASE-средств;
– современные прикладные методы и технологии искусственного интеллекта ориентированы не столько на копирование поведения человека, сколько на достижение результатов, аналогичных человеческим результатам;
– для автоматического построения моделей систем целесообразно применить алгоритм муравья.
Целью данной магистерской аттестационной работы является исследование возможности использования алгоритмов искусственного интеллекта в процессе построения UFO-моделей.
Достижение сформулированной цели связано с решением следующих задач:
– адаптация алгоритма муравья к процессу построения UFO-модели из заданных компонентов;
– использование MicrosoftExcelв процессе построения UFO-модели из заданных компонентов;
– применение полученных результатов в процессе UFO-моделирования.
2. Адаптация алгоритма муравья к задаче построения UFO-модели из заданных компонентов
2.1 Начальное размещение муравья
Пусть задана контекстная диаграмма системы, определяющая ее множество входов и выходов (рис. 2.1).

Рисунок 2.1 – Контекстная диаграмма системы
Изначально муравей может находиться в одной из двух видов точек [44]:
– в конце любой входной стрелки In (n) (n = 1, 2, …, N);
– в начале любой выходной стрелки Out (m) (m = 1, 2, …, M).
Например, контекстная диаграмма системы может иметь два входа (In (1), In (2)) и три выхода (Out (1), Out (2), Out (3)), а муравей – находиться в конце входной стрелки In (1). Данная ситуация иллюстрируется рис. 2.2, на котором муравей условно изображен жирной точкой.

Рисунок 2.2 – Пример начального размещения муравья
2.2 Правила соединения UFO-компонентов
Пусть задана библиотека компонентов ![]() , из которых необходимо собрать систему, заданную контекстной диаграммой, изображенной на рис. 2.1. Каждый компонент
, из которых необходимо собрать систему, заданную контекстной диаграммой, изображенной на рис. 2.1. Каждый компонент ![]() библиотеки тоже характеризуется своим множеством входов
библиотеки тоже характеризуется своим множеством входов ![]() , а также – своим множеством выходов
, а также – своим множеством выходов ![]() (рис. 2.3).
(рис. 2.3).

Рисунок 2.3 – Контекстная диаграмма компонента ![]()
Входы и выходы контекстной диаграммы системы и компонентов имеют такую характеристику как тип. Существуют следующие правила соединения входов и выходов [11]. Вход In (n) контекстной диаграммы системы может быть присоединен к входу ![]() компонента
компонента ![]() , если тип In (n) совпадает с типом
, если тип In (n) совпадает с типом ![]() . Это условие совпадение типов можно записать в виде равенства
. Это условие совпадение типов можно записать в виде равенства ![]() (рис. 2.4).
(рис. 2.4).

Рисунок 2.4 – Соединение входа с входом
Выход Out (m) контекстной диаграммы системы может быть присоединен к выходу ![]() компонента
компонента ![]() , если тип Out (m) совпадает с типом
, если тип Out (m) совпадает с типом ![]() . Это условие можно записать в виде равенства
. Это условие можно записать в виде равенства ![]() (рис. 2.5).
(рис. 2.5).

Рисунок 2.5 – Соединение выхода с выходом
Выход ![]() компонента
компонента ![]() может быть присоединен к входу
может быть присоединен к входу ![]() компонента
компонента ![]() , если тип
, если тип ![]() совпадает с типом
совпадает с типом![]() . Это условие можно записать в виде равенства
. Это условие можно записать в виде равенства ![]() (рис. 2.6).
(рис. 2.6).

Рисунок 2.6 – Соединение выхода с входом
Пусть контекстная диаграмма системы имеет вход a и выход b (рис. 2.7).

Рисунок 2.7 – Пример контекстной диаграммы системы
Пусть в библиотеку компонентов входит компонент С1 с входом a и выходом c и компонент С2 с входом c и выходом b (рис. 2.8).

Рисунок 2.8 – Примеры контекстных диаграмм компонентов
Тогда вход a и выход b системы могут быть соединены с помощью компонентов С1 и С2 так, как показано на рис. 2.9.

Рисунок 2.9 – Примеры соединений компонентов
2.3 Элементарное перемещение муравья
2.3.1 Перемещение из входа контекстной диаграммы
Пусть изначально муравей находится в конце входной стрелки In (n). Он может случайным образом выбрать из библиотеки компонентов любой компонент ![]() , у которого есть вход
, у которого есть вход ![]() , который можно присоединить к входу In (n). После присоединения входа
, который можно присоединить к входу In (n). После присоединения входа ![]() компонента
компонента ![]() к входу In (n) контекстной диаграммы, муравей "переползает" по входу
к входу In (n) контекстной диаграммы, муравей "переползает" по входу ![]() на компонент
на компонент ![]() и пытается присоединять "висящие" входы компонента
и пытается присоединять "висящие" входы компонента ![]() либо к еще свободным входам контекстной диаграммы системы, либо к еще свободным выходам других компонентов. Аналогично муравей пытается присоединять "висящие" выходы компонента
либо к еще свободным входам контекстной диаграммы системы, либо к еще свободным выходам других компонентов. Аналогично муравей пытается присоединять "висящие" выходы компонента ![]() либо к еще свободным выходам контекстной диаграммы системы, либо к еще свободным входам других компонентов (рис. 2.10).
либо к еще свободным выходам контекстной диаграммы системы, либо к еще свободным входам других компонентов (рис. 2.10).

Рисунок 2.10 – Присоединение компонента к входу системы
Если после вышеперечисленных действий муравья у компонента ![]() не осталось "висящих" входов и выходов, то муравей "выползает" из компонента
не осталось "висящих" входов и выходов, то муравей "выползает" из компонента ![]() по входу
по входу ![]() , через который он попал в этот компонент. На этом перемещения муравья прекращаются.
, через который он попал в этот компонент. На этом перемещения муравья прекращаются.
Если же у компонента ![]() остались "висящие" входы и выходы, то муравей случайным образом размещается на любом из них. Если муравей оказался в конце "висящего" входа компонента
остались "висящие" входы и выходы, то муравей случайным образом размещается на любом из них. Если муравей оказался в конце "висящего" входа компонента ![]() , то далее он должен действовать так, как описано ниже в пункте 2.3.3. Если муравей оказался в начале "висящего" выхода компонента
, то далее он должен действовать так, как описано ниже в пункте 2.3.3. Если муравей оказался в начале "висящего" выхода компонента ![]() , то далее он должен действовать так, как описано ниже в пункте 2.3.4.
, то далее он должен действовать так, как описано ниже в пункте 2.3.4.
2.3.2 Перемещение из выхода контекстной диаграммы
Пусть изначально муравей находится в начале выходной стрелки Out (m). Он может случайным образом выбрать из библиотеки компонентов любой компонент ![]() , у которого есть выход
, у которого есть выход ![]() , который можно присоединить к выходу Out (m). После присоединения выхода
, который можно присоединить к выходу Out (m). После присоединения выхода ![]() компонента
компонента ![]() к выходу Out (m) контекстной диаграммы, муравей "переползает" по выходу
к выходу Out (m) контекстной диаграммы, муравей "переползает" по выходу ![]() на компонент
на компонент ![]() и пытается присоединять "висящие" входы компонента
и пытается присоединять "висящие" входы компонента ![]() либо к еще свободным входам контекстной диаграммы системы, либо к еще свободным выходам других компонентов. Аналогично муравей пытается присоединять "висящие" выходы компонента
либо к еще свободным входам контекстной диаграммы системы, либо к еще свободным выходам других компонентов. Аналогично муравей пытается присоединять "висящие" выходы компонента ![]() либо к еще свободным выходам контекстной диаграммы системы, либо к еще свободным входам других компонентов (рис. 2.11).
либо к еще свободным выходам контекстной диаграммы системы, либо к еще свободным входам других компонентов (рис. 2.11).

Рисунок 2.11 – Присоединение компонента к выходу системы
Если после вышеперечисленных действий муравья у компонента ![]() не осталось "висящих" входов и выходов, то муравей "выползает" из компонента
не осталось "висящих" входов и выходов, то муравей "выползает" из компонента ![]() по выходу
по выходу ![]() , через который он попал в этот компонент. На этом перемещения муравья прекращаются.
, через который он попал в этот компонент. На этом перемещения муравья прекращаются.
Если же у компонента ![]() остались "висящие" входы и выходы, то муравей случайным образом размещается на любом из них. Если муравей оказался в конце "висящего" входа компонента
остались "висящие" входы и выходы, то муравей случайным образом размещается на любом из них. Если муравей оказался в конце "висящего" входа компонента ![]() , то далее он должен действовать так, как описано ниже в пункте 2.3.3. Если муравей оказался в начале "висящего" выхода компонента
, то далее он должен действовать так, как описано ниже в пункте 2.3.3. Если муравей оказался в начале "висящего" выхода компонента ![]() , то далее он должен действовать так, как описано ниже в пункте 2.3.4.
, то далее он должен действовать так, как описано ниже в пункте 2.3.4.
2.3.3 Перемещение из входа UFO-компонента
Пусть изначально муравей находится в начале входной стрелки ![]() компонента
компонента ![]() . Он может случайным образом выбрать из библиотеки компонентов любой компонент
. Он может случайным образом выбрать из библиотеки компонентов любой компонент ![]() , у которого есть выход
, у которого есть выход ![]() , который можно присоединить к входу
, который можно присоединить к входу ![]() . После присоединения выхода
. После присоединения выхода ![]() компонента
компонента ![]() к входу
к входу ![]() компонента
компонента ![]() , муравей "переползает" по выходу
, муравей "переползает" по выходу ![]() на компонент
на компонент ![]() и пытается присоединять "висящие" входы компонента
и пытается присоединять "висящие" входы компонента ![]() либо к еще свободным входам контекстной диаграммы системы, либо к еще свободным выходам других компонентов. Аналогично муравей пытается присоединять "висящие" выходы компонента
либо к еще свободным входам контекстной диаграммы системы, либо к еще свободным выходам других компонентов. Аналогично муравей пытается присоединять "висящие" выходы компонента ![]() либо к еще свободным выходам контекстной диаграммы системы, либо к еще свободным входам других компонентов (рис. 2.12).
либо к еще свободным выходам контекстной диаграммы системы, либо к еще свободным входам других компонентов (рис. 2.12).

Рисунок 2.12 – Присоединение компонента ![]() к входу компонента
к входу компонента ![]()
Если после вышеперечисленных действий муравья у компонента ![]() не осталось "висящих" входов и выходов, то муравей "переползает" из компонента
не осталось "висящих" входов и выходов, то муравей "переползает" из компонента ![]() по выходу
по выходу ![]() назад через вход
назад через вход ![]() в компонент
в компонент ![]() . Если у компонента
. Если у компонента ![]() еще остались "висящие" входы и выходы, то муравей случайным образом размещается на любом из них. Иначе – покидает компонент
еще остались "висящие" входы и выходы, то муравей случайным образом размещается на любом из них. Иначе – покидает компонент ![]() по тому пути, по которому он на него попал.
по тому пути, по которому он на него попал.
Если же у компонента ![]() остались "висящие" входы и выходы, то муравей случайным образом размещается на любом из них.
остались "висящие" входы и выходы, то муравей случайным образом размещается на любом из них.
2.3.4 Перемещение из выхода UFO-компонента
Пусть изначально муравей находится в конце выходной стрелки ![]() компонента
компонента ![]() . Он может случайным образом выбрать из библиотеки компонентов любой компонент
. Он может случайным образом выбрать из библиотеки компонентов любой компонент ![]() , у которого есть вход
, у которого есть вход ![]() , который можно присоединить к выходу
, который можно присоединить к выходу ![]() . После присоединения входа
. После присоединения входа ![]() компонента
компонента ![]() к выходу
к выходу ![]() компонента
компонента ![]() , муравей "переползает" по входу
, муравей "переползает" по входу ![]() на компонент
на компонент ![]() и пытается присоединять "висящие" входы компонента
и пытается присоединять "висящие" входы компонента ![]() либо к еще свободным входам контекстной диаграммы системы, либо к еще свободным выходам других компонентов. Аналогично муравей пытается присоединять "висящие" выходы компонента
либо к еще свободным входам контекстной диаграммы системы, либо к еще свободным выходам других компонентов. Аналогично муравей пытается присоединять "висящие" выходы компонента ![]() либо к еще свободным выходам контекстной диаграммы системы, либо к еще свободным входам других компонентов (рис. 2.13).
либо к еще свободным выходам контекстной диаграммы системы, либо к еще свободным входам других компонентов (рис. 2.13).

Рисунок 2.13 – Присоединение компонента ![]() к выходу компонента
к выходу компонента ![]()
Если после вышеперечисленных действий муравья у компонента ![]() не осталось "висящих" входов и выходов, то муравей "переползает" из компонента
не осталось "висящих" входов и выходов, то муравей "переползает" из компонента ![]() по входу
по входу ![]() назад через выход
назад через выход ![]() в компонент
в компонент ![]() . Если у компонента
. Если у компонента ![]() еще остались "висящие" входы и выходы, то муравей случайным образом размещается на любом из них. Иначе – покидает компонент
еще остались "висящие" входы и выходы, то муравей случайным образом размещается на любом из них. Иначе – покидает компонент ![]() по тому пути, по которому он на него попал.
по тому пути, по которому он на него попал.
Если же у компонента ![]() остались "висящие" входы и выходы, то муравей случайным образом размещается на любом из них.
остались "висящие" входы и выходы, то муравей случайным образом размещается на любом из них.
2.3.5 Пример перемещений муравья
Пусть контекстная диаграмма системы имеет два входа (a и b) и два выхода (c и d), а муравей находится в конце входа b (рис. 2.14).

Рисунок 2.14 – Контекстная диаграмма с двумя входами и двумя выходами
Пусть в библиотеке компонентов находятся (рис. 2.15):
– компонент С1 с входами b, e и выходом d;
– компонент С2 с входом a и выходами e, f;
– компонент С3 с входом f и выходом c.

Рисунок 2.15 – Пример библиотеки компонентов
Первое перемещение муравей делает следующим образом.
Вначале он выбирает из библиотеки компонент С1 , у которого есть вход b, который можно присоединить к входу b контекстной диаграммы.
После присоединения входа b компонента С1 к входу b контекстной диаграммы, муравей "переползает" по входу b на компонент С1 и присоединяет "висящий" выход d компонента С1 к еще свободному выходу d контекстной диаграммы системы.
У компонента С1 остался "висящий" вход e, в начале которого и размещается муравей (рис. 2.16).

Рисунок 2.16 – Первый ход муравья
Второе перемещение муравей делает следующим образом.
Вначале он выбирает из библиотеки компонент С2 , у которого есть выход e, который можно присоединить к входу e компонента С1 .
После присоединения выхода e компонента С2 к входу e компонента С1 , муравей "переползает" по входу e на компонент С2 и присоединяет "висящий" вход a компонента С2 к еще свободному входу a контекстной диаграммы системы.
У компонента С2 остался "висящий" выход f, в конце которого и размещается муравей (рис. 2.17).

Рисунок 2.17 – Второй ход муравья
Третье перемещение муравей делает следующим образом.
Вначале он выбирает из библиотеки компонент С3 , у которого есть вход f, который можно присоединить к выходу f компонента С2 . После присоединения входа f компонента С3 к выходу f компонента С2 , муравей "переползает" по выходу f на компонент С3 и присоединяет "висящий" выход c компонента С3 к еще свободному выходу c контекстной диаграммы системы (рис. 2.18).

Рисунок 2.18 – Третий ход муравья
У компонента С3 не осталось "висящих" входов и выходов. Поэтому муравей "переползает" обратно по связи f на компонент С2 . У компонента С2 тоже не осталось "висящих" входов и выходов. Поэтому муравей "переползает" обратно по связи e на компонент С1 . У компонента С1 тоже не осталось "висящих" входов и выходов. Поэтому муравей "переползает" обратно по связи b на вход b контекстной диаграммы системы.
Муравей вернулся в начальное положение, поэтому его перемещения на этом прекращаются.
Присоединяя "висящие" входы или выходы компонента, муравей в первую очередь должен пытаться их присоединять к еще свободным входам или выходам контекстной диаграммы системы, а уже потом – к "висящим" входам или выходам других компонентов.
Наконец, из библиотеки компонентов муравью, вероятно, следует выбирать для присоединения тот компонент, у которого в результате окажется меньше "висящих" входов и выходов. Хотя такая локальная оптимальность вовсе не гарантирует того, что процесс построения системы из заданных компонентов закончится быстрее.
2.4 Перемещение нескольких муравьев
Естественно, что сборка системы из заданных компонентов будет производиться гораздо быстрее, если ее будет осуществлять не один муравей, но несколько. Количество муравьев может задаваться произвольным образом. Например, их можно разместить по одному в конце каждого входа и в начале каждого выхода контекстной диаграммы системы. Однако при этом возникает проблема разрешения конфликтов при попытке разных муравьев присоединить, например, к одному свободному выходу контекстной диаграммы, "висящие" выходы своих компонентов (рис. 2.19).
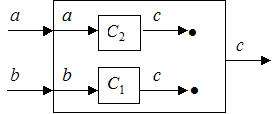
Рисунок 2.19 – Конфликт двух муравьев
2.4.1 Разрешение конфликтов
Можно предложить несколько способов разрешения конфликтов муравьев при доступе к одним ресурсам.
Например, можно назначить муравьям приоритеты – целые числа от 1 до V, где V – количество муравьев. Чем меньше число, тем выше приоритет. Таким образом, самый высокий приоритет имеет муравей, которому сопоставлено число 1, а самый низкий – муравей, которому сопоставлено число V. Если два муравья конфликтуют, то предпочтение отдается тому, у которого выше приоритет. Например, если у муравьев, изображенных выше на рис. 2.19, приоритеты назначены так, что муравей, находящийся на выходе c компонента C1 , имеет приоритет 7, а муравей, находящийся на выходе c компонента C2 , имеет приоритет 9, то их конфликт за выход c контекстной диаграммы системы разрешиться в пользу муравья, находящегося на выходе c компонента C1 , который имеет более высокий приоритет по сравнению с муравьем, находящимся на выходе c компонента C2 . Результат разрешения конфликта этих двух муравьев показан на рис. 2.20.
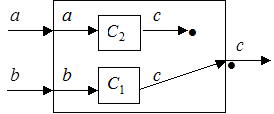
Рисунок 2.20 – Разрешение конфликта двух муравьев
Другим способом может быть разрешение конфликта, основанное на присоединении к свободной связи любой случайным образом выбранной "висящей" связи.
Наконец, предпочтение можно отдавать муравью, у которого больше "висящих" связей.
2.4.2 Пример перемещений нескольких муравьев
Пусть контекстная диаграмма системы имеет два входа (a и b) и два выхода (c и d), а муравей 1 находится в конце входа b, и муравей 2 – в начале выхода c, рис. 2.21).

Рисунок 2.21 – Размещение муравьев на контекстной диаграмме
Пусть в библиотеке компонентов находятся (рис. 2.22):
– компонент С1 с входами b, e и выходом g;
– компонент С2 с входом a и выходами e, f;
– компонент С3 с входами f, h и выходом c;
– компонент С4 с входом g и выходами h, d.

Рисунок 2.22 – Библиотека из четырех компонентов
Первое перемещение муравей 1 делает следующим образом.
Вначале он выбирает из библиотеки компонент С1 , у которого есть вход b, который можно присоединить к входу b контекстной диаграммы.
После присоединения входа b компонента С1 к входу b контекстной диаграммы, муравей "переползает" по входу b на компонент С1 . У компонента С1 остался "висящий" вход e и "висящий" выход g, в конце которого и размещается муравей 1 (рис. 2.23).

Рисунок 2.23 – Первый ход муравья 1
Первое перемещение муравей 2 делает следующим образом. Вначале он выбирает из библиотеки компонент С3 , у которого есть выход c, который можно присоединить к выходу c контекстной диаграммы. После присоединения выхода c компонента С3 к выходу c контекстной диаграммы, муравей "переползает" по выходу c на компонент С3 . У компонента С3 остались "висящие" входы h и f, в начале которого и размещается муравей 2 (рис. 2.24).

Рисунок 2.24 – Первый ход муравья 2
Второе перемещение муравей 1 делает следующим образом.
Вначале он выбирает из библиотеки компонент С4 , у которого есть вход g, который можно присоединить к выходу g компонента С1 .
После присоединения входа g компонента С4 к выходу g компонента С1 , муравей "переползает" по входу g на компонент С4 , выход h которого он соединяет с входом h компонента С3 , а выход d – c выходом d контекстной диаграммы системы (рис. 2.25).

Рисунок 2.25 – Второй ход муравья 1
Второе перемещение муравей 2 делает следующим образом. Вначале он выбирает из библиотеки компонент С2 , у которого есть выход f, который можно присоединить к входу f компонента С3 . После присоединения выхода f компонента С2 к входу f компонента С3 , муравей "переползает" по входу f на компонент С2 , выход e которого он соединяет с входом e компонента С1 , а вход a – c входом a контекстной диаграммы системы (рис. 2.26).

Рисунок 2.26 – Второй ход муравья 2
3. Пример использования MicrosoftExcel в процессе построения UFO-модели из заданных компонентов на основе алгоритма муравья
Пусть контекстная диаграмма системы имеет такой вид, как на рис. 3.1, и все муравьи расположены у входов в диаграмму.

Рисунок 3.1 – Начальное размещение трех муравьев
Пусть библиотека компонентов содержит шесть подсистем, таких, как показано на рис. 3.2.

Рисунок 3.2 – Библиотека из шести компонентов
В MicrosoftExcel данную библиотеку компонентов можно представить так, как показано на рис. 3.3, на листе "Библиотека компонентов".

Рисунок 3.3 – Представление библиотеки в MicrosoftExcel
Текущее положение муравьев в MicrosoftExcel можно представить так, как показано на рис. 3.4, на листе "Муравьи".

Рисунок 3.4 – Представление текущего положения муравьев в MicrosoftExcel
Для поиска в библиотеке компонентов того компонента, который может быть подключен муравьем к той "висящей" стрелке, на которой он сейчас находится, можно воспользоваться функцией ПРОСМОТР [45].
Функция ПРОСМОТР имеет две синтаксические формы: вектор и массив. Вектор – это диапазон, который содержит только одну строку или один столбец. Векторная форма функции ПРОСМОТР просматривает диапазон, в который входят значения только одной строки или одного столбца (так называемый вектор) в поисках определенного значения и возвращает значение из другого столбца или строки. Эта форма функции ПРОСМОТР используется, когда требуется указать интервал, в котором находятся искомые значения. Другая форма функции ПРОСМОТР автоматически использует для этой цели первую строку или первый столбец.
Синтаксис векторной формы функции ПРОСМОТР имеет следующий вид: ПРОСМОТР (Иск_знач; Просматриваемый_вектор; Вектор_результатов).
Иск_знач – это искомое значение, которое ПРОСМОТР ищет в первом векторе. Искомое значение может быть числом, текстом, логическим значением, именем или ссылкой, ссылающимися на значение. Просматриваемый_вектор – это интервал, содержащий только одну строку или один столбец. Значения в аргументе просматриваемый вектор могут быть текстами, числами или логическими значениями. Следует отметить, что значения в аргументе просматриваемый вектор должны быть расположены в порядке возрастания, в противном случае функция ПРОСМОТР может вернуть неверный результат. Тексты в нижнем и верхнем регистре считаются эквивалентными. Вектор_результатов – это интервал, содержащий только одну строку или один столбец. Он должен быть того же размера, что и просматриваемый вектор. Для поиска в библиотеке компонентов того компонента, который может быть подключен муравьем 1 к "висящей" стрелке a, на которой он сейчас находится, в ячейку Е3 введем формулу
=ПРОСМОТР(C3;'Библиотека компонентов'!$A$2:$A$7;
'Библиотека компонентов'!$B$2:$B$7),
которую затем распространим с помощью маркера заполнения в ячейки Е4 и Е5. Результат показан на рис. 3.5.

Рисунок 3.5 – Поиск компонентов в MicrosoftExcel
Заметим, что для муравья 3 результат поиска оказался неверным. Это связано с тем, что компоненты в библиотеке (рис. 3.3) упорядочены по возрастанию по системам, но не по входам, как это требует функция ПРОСМОТР. Поэтому функция ПРОСМОТР вернула неверный результат. Чтобы в дальнейшем получать правильные результаты, необходимо изменить представление библиотеки компонентов так, как показано на рис. 3.6.

Рисунок 3.6 – Измененная библиотека компонентов
Теперь MicrosoftExcel дает правильный результат (рис. 3.7).

Рисунок 3.7 – Верный результат поиска компонентов в MicrosoftExcel
Итак, MicrosoftExcel рекомендует (рис. 3.7):
– муравью 1 подключить к выходу a компонент С1 ;
– муравью 2 подключить к выходу b компонент С2 ;
– муравью 3 подключить к выходу c компонент С4 .
Сделаем это (рис. 3.8):

Рисунок 3.8 – Первые перемещения муравьев
Заметим, что муравей 1 закончил свои перемещения, а муравей 2 перешел на стрелку g, и муравей 3 – на стрелку h.
Посмотрим, что теперь предложит MicrosoftExcel муравьям 2 и 3 (рис. 3.9).

Рисунок 3.9 – Вторая итерация поиска компонентов в MicrosoftExcel
Итак, MicrosoftExcel рекомендует (рис. 3.9):
– муравью 2 подключить к выходу g компонент С3 ;
– муравью 3 подключить к выходу h компонент С5 .
Сделаем это (рис. 3.10):

Рисунок 3.10 – Вторые перемещения муравьев
Заметим, что муравей 2 также закончил свои перемещения, а муравей 3 перешел на стрелку i.
Посмотрим, что теперь предложит MicrosoftExcel муравь. 3 (рис. 3.11).

Рисунок 3.11 – Третья итерация поиска компонентов в MicrosoftExcel
Сделаем это и посмотрим на окончательный результат (рис. 3.12):
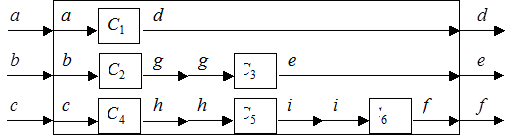
Рисунок 3.12 – Окончательный результат
4. Использование алгоритма муравья в процессе UFO-моделирования шахтной транспортной системы
Все результаты, представленные в этом разделе, получены в ходе исследовательской практики в отдельном подразделении "Шахта "Комсомольская"" государственного предприятия "Антрацит" Министерства угольной промышленности Украины (г. Антрацит, Луганская область).
4.1 Общие сведения о подразделении "Шахта "Комсомольская""
Подразделение создано для осуществления производственной, хозяйственной, коммерческой и других видов деятельности с целью содействия всестороннему развитию государственного предприятия "Антрацит", повышению его инвестиционной привлекательности, получения прибыли.
Подразделение работает по единой производственно-технологической программе с государственным предприятием "Антрацит" и отчитывается перед ним о результатах финансово-хозяйственной деятельности.
Основными видами деятельности, которые осуществляет подразделение, являются, в частности:
– добыча угольной продукции;
– переработка (обогащение) угольного сырья;
– переработка, использование и реализация отходов производства, вторичного сырья;
– разработка и внедрение проектов по применению новой техники, передовой технологии, современных методов организации производства, а также использование прогрессивных материалов, изделий и конструкций;
– развитие производственно-хозяйственного комплекса подразделения, повышение производительности труда и эффективности добычи угля, максимальное использование внутренних резервов, интенсификация производственных процессов;
– обеспечение экономического анализа производственной и финансово-хозяйственной деятельности с целью выявления резервов повышения эффективности производства, улучшения использования материальных, трудовых и финансовых ресурсов;
– научно-техническая деятельность.
Для достижения цели создания подразделения и учитывая необходимость обеспечения подразделением выполнения планов добычи угля, эффективного освоения производственных мощностей и наибольшего использования внутренних резервов при соблюдении безопасных условий труда и наименьших затратах трудовых, материальных и денежных ресурсов, а также повышения социально-экономического уровня трудового коллектива и удовлетворения социальных потребностей работников, подразделение осуществляет, в частности, следующие производственно-хозяйственные функции:
– самостоятельно планирует свою деятельность, исходя из основных показателей, которое доводит государственное предприятие "Антрацит";
– на основе перспективной программы развития и задания, которое устанавливается государственным предприятием "Антрацит" на добычу угля, разрабатывает планы производства, доводит их до участков и цехов;
– разрабатывает проекты отработки очистных забоев и анализирует эффективность использования используемого оборудования при обеспечении соблюдения безопасных условий труда;
– осуществляет выбор системы разработки угольных месторождений и его элементов, способов подготовки участков для выема, способов механизации основных процессов очистных и подготовительных работ, способов управления горным давлением в очистных и подготовительных выработках;
– принимает участие в рассмотрении проектов отработки шахтных полей и технологических процессов;
– внедряет в производство достижения отечественной и зарубежной науки и техники.
4.2 Подготовка и вскрытие шахтного поля
Подземный транспорт шахт и рудников горнодобывающей промышленности является составным звеном общешахтной транспортной системы. Он представляет собой многозвенную систему, состоящую из разнотипных транспортных установок цикличного и непрерывного действия, с взаимосвязанными параметрами, функционирующую в сложных горно-геологических условиях [46].
Характерные черты подземного транспорта:
– сравнительно небольшие расстояния транспортирования в подземных условиях при значительных объёмах перевозки;
– неравномерность грузопотоков;
– широкая разветвлённость транспортных магистралей;
– наличие в одной магистрали нескольких видов транспорта и необходимость перегрузок в местах сопряжения;
– многозвенность транспорта, работающего в горизонтальных и наклонных выработках в стеснённых условиях при значительной запылённости, влажности и загазованности окружающей среды.
Основные виды подземного транспорта: конвейерный и локомотивный.
Конвейерный транспорт характеризуется:
– высокой производительностью, связанной с поточностью;
– низкой трудоёмкостью обслуживания;
– высокой надёжностью;
– низким уровнем травматизма обслуживающего персонала;
– способностью транспортировать груз, как по горизонтальным, так и по наклонным выработкам;
– удобством сопряжения с очистными забоями.
Недостатки конвейерного транспорта:
– относительно высокие капитальные и эксплуатационные затраты;
– неприспособленность к транспортированию крупнокусковых и абразивных грузов;
– низкая технологическая гибкость.
Локомотивный транспорт характеризуется
– многофункциональностью;
– практически неограниченной производительностью;
– высокой экономичностью;
– маневренностью;
– высоким коэффициентом готовности.
Недостатки локомотивного транспорта:
– цикличность
– зависимость производительности от уровня организации
– ограниченность применения по углам наклона
– наличие сложного аккумуляторного хозяйства при использовании аккумуляторных электровозов.
Существуют различные системы подготовки и вскрытия шахтного поля. Одной из них является панельная система подготовки с отработкой длинными столбами по простиранию.
При панельной системе подготовки применяется следующая схема транспорта. Отбитый уголь по призабойному скребковому конвейеру через перегружатель доставляется на ярусный штрек. В зависимости от мощности забоя, могут быть применены 2 последовательно соединённые конвейера 2ЛТ80 и 2Л80 или один 1ЛТ100 на всю длину ярусного штрека. Далее уголь подаётся на панельный конвейерный уклон, где, в зависимости от нагрузки, могут быть применены уклонные ленточные конвейеры 1ЛУ100, 2ЛУ100 или 2ЛУ120В. В месте сопряжения уклона и главного полевого транспортного штрека оборудуется горный бункер ёмкостью 100-150 т. По главному штреку транспортирование осуществляется локомотивной откаткой. Для доставки материалов и оборудования к очистному забою по ярусным штрекам предусматривается установка грузо-людской монорельсовой дороги ДМКМ. Для обслуживания конвейера на конвейерном уклоне устанавливается монорельсовая дорога.
4.3 UFO-модель шахтной транспортной системы
Контекстная модель шахтной транспортной системы показана на рис. 4.1.

Рисунок 4.1 – Контекстная модель шахтной транспортной системы
В процессе построения декомпозиции контекстной модели шахтной транспортной системы муравей может пользоваться библиотекой компонентов, основные элементы которой представлены на рис. 4.2.

Рисунок 4.2 – Основные элементы библиотеки компонентов
Первоначально муравей находится в добывающем забое. Если муравей выбрал для транспортировки отбитого угля компонент "Конвейер 1ЛТ100", то диаграмма декомпозиции контекстной модели шахтной транспортной системы примет следующий вид (рис. 4.3).
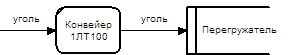
Рисунок 4.3 – Первый шаг муравья
Далее муравей может выбрать уклонный ленточный конвейер 1ЛУ100. В этом случае диаграмма декомпозиции контекстной модели шахтной транспортной системы примет такой вид, как показано на рис. 4.4.
![]()
Рисунок 4.4 – Второй шаг муравья
На последнем шаге муравей выбирает локомотивную откатку. В результате получается такая диаграмма декомпозиции контекстной модели шахтной транспортной системы, как показано на рис. 4.5.
![]()
Рисунок 4.5 – Третий шаг муравья
Если бы на первом шаге муравей выбрал вместо конвейера 1ЛТ100 конвейер 2ЛТ80, а вместо конвейера 1ЛУ100 конвейер 2ЛУ120В, то в результате получилась бы диаграмма декомпозиции контекстной модели шахтной транспортной системы, показанная на рис. 4.6.

Рисунок 4.6 – Диаграмма декомпозиции контекстной модели
Выводы
В процессе выполнения магистерской аттестационной работы получены следующие результаты:
– проанализированы современные технологии построения систем;
– проанализированы прикладные методы и технологии искусственного интеллекта:
1) нейронные сети;
2) генетические алгоритмы;
3) системы, основанные на продукционных правилах;
4) нечеткая логика;
5) умные агенты;
6) алгоритм муравья.
– осуществлена адаптация алгоритма муравья к задаче построения UFO-модели из заданных компонентов:
1) начальное размещение муравья;
2) правила соединения муравьем UFO-компонентов;
3) перемещение муравья из входа и выхода контекстной диаграммы;
4) перемещение муравья из входа и выхода UFO-компонента;
5) разрешение конфликтов при перемещении нескольких муравьев.
– разработан пример использованияMicrosoftExcel в процессе построенияUFO-модели из заданных компонентов на основе алгоритма муравья;
– полученные результаты применены в процессе UFO-моделирования шахтной транспортной системы.
Полученные результаты можно использовать в процессе UFO-анализа.
Среди возможных направлений развития следует отметить перспективность исследования возможности применения других алгоритмов искусственного интеллекта в процессе UFO-анализа. Также направлением развития может быть внедрение полученных результатов в CASE-инструментарии, используемые в процессе моделирования систем.
Результаты работы апробированы на IV-м Международном научно-практическом форуме "Информационные технологии и кибернетика 2006", который проходил в Днепропетровске 27-28 апреля 2006 г., и опубликованы в сборнике докладов и тезисов этого форума [44].
Перечень ссылок
1. Лямец В.И., Тевяшев А.Д. Системный анализ. Вводный курс. – Харьков: ХТУРЭ, 1998. – 252 с.
2. Давыдов А.Н., Судов Е.В., Якунина О.В. Применение расширенной идеологии IDEF для анализа и реинжиниринга бизнес-процессов в производственных и организационных системах // Проблемы продвижения продукций и технологий на внешний рынок. Специальный выпуск, 1997. – С. 23-27.
3. Информационные технологии организационного управления сложными социотехническими системами / О.Е. Федорович, Н.В. Нечипорук, Е.А. Дружинин, А.В. Прохоров. – Харьков: Нац. аэрокосм. ун-т "Харьк. авиац. ин-т", 2004. – 295 с.
4. Емельянов В.В., Урусов А.В. IDEF-RDO: имитационный анализ функциональной структуры сложных систем // Программные продукты и системы. – 1997. – № 3. – С. 13-18.
5. Калянов Г.Н. Консалтинг при автоматизации предприятий. – М.: Синтег, 1997. – 316 с.
6. Вендров А.М. CASE-технологии. Современные методы и средства проектирования информационных систем. – М.: Финансы и статистика, 1998. – 176 с.
7. Бондаренко М.Ф., Маторин С.И., Ельчанинов Д.Б. Системная технология моделирования информационных и организационных систем: Учебное пособие. – Харьков: ХНУРЭ, 2005. – 116 с.
8. Емельянов В.В., Попов Э.В. Интеллектуальное имитационное моделирование в реинжиниринге бизнес-процессов // Программные продукты и системы. – 1998. – № 3. – С. 3-10.
9. Маклаков С.В. Моделирование бизнес процессов с BPwin 4.0. – М.: Диалог-МИФИ, 2002. – 224 с.
10. Маклаков С.В. BPwin, ERwin. CASE-средства разработки информационных систем. – М.: Диалог-Мифи, 1999. – 295 с.
11. Маторин С.И. Анализ и моделирование бизнес-систем: системологическая объектно-ориентированная технология. – Харьков: ХНУРЭ, 2002. – 322 с.
12. Бондаренко М.Ф., Соловьева Е.А., Маторин С.И., Ельчанинов Д.Б. Системологическая технология моделирования информационных и организационных систем: Учебное пособие. – Харьков: ХНУРЭ, 2005. – 136 с.
13. Маторин В.С., Маторин С.И., Полунин Р.А., Попов А.С. Знаниеориентированный CASE-инструментарий автоматизации UFO-анализа // Проблемы программирования. – 2002. – №1-2. – С. 469-476.
14. Маторин С.И., Ельчанинов Д.Б. Применение теории паттернов для формализации системологического УФО-анализа // Научно-техническая информация. Серия 2. – 2002. – №11. – С. 1-8.
15. Джонс М.Т. Программирование искусственного интеллекта в приложениях. – М.: ДМК Пресс, 2004. – 312 с.
16. Хьюбел Д. Глаз, мозг, зрение. – М.: Мир, 1990. – 239 с.
17. Pulsed neural networks / by W. Maas and C.M. Bishop eds. – MIT Press. – 1999. – 408 p.
18. Lin C.T. Neural fuzzy systems: a neuro-fuzzy synergism to intelligent systems. – Upper Saddle Rever, New Jersey: Prentice Hall PTR, 1997. – 786 p.
19. Цыпкин Я.З. Основы теории обучающихся систем. – М.: Наука, 1970. – 252 с.
20. Hertz J. Introduction to the theory of neural computation. – Redwood City: Addison-Wesley Publishing Company, 1996. – 327 p.
21. Kohonen T. Self-organizing Maps. – Berlin: Springer-Verlag, 1995. –363 p.
22. Приобретение знаний / Под ред. С. Осуги, Ю. Саэки; Пер. с япон. – М.: Мир, 1990. – 304 с.
23. Огнев И.В. Интеллектуальные системы ассоциативной памяти. – М.: Радио и связь, 1996. – 176 с.
24. Kung S.Y. Digital Neural Networks. – Engewood Cliffs, New Jersey: PTR Prentice Hall, 1994. – 418 p.
25. Корнеев В.В., Гареев А.Ф., Васютин С.В., Райх В.В. Базы данных. Интеллектуальная обработка информации. – М.: "Нолидж". 2000. – 352 с.
26. Люгер Д.Ф. Искусственный интеллект: стратегии и методы решения сложных проблем. – М.: "Вильямс", 2003. – 864 с.
27. Goldberg D.E. Genetic algorithms in search, optimization and machine learning. – Adison Wesley, Reading, MA, 1989. – 308 p.
28. Эволюционные вычисления и генетические алгоритмы. Обозрение прикладной и промышленной математики. Выпуск 5.– М.: "ТВП".– Т.3.– 1996.– 204 с.
29. Ельчанинов Д.Б., Кривуля Г.Ф., Лобода В.Г., Механа Сами Применение генетических алгоритмов и многоуровневых сетей Петри при проектировании компьютерной техники // Радиоэлектроника и информатика, 2002. – № 1. – С. 89-97.
30. Петросов Д.А. Лобода В.Г., Ельчанинов Д.Б. Представление генетических алгоритмов сетями Петри в задачах проектирования компьютерной техники // Материалы научно-практической конференции "Информационные технологии – в науку и образование". Харьков: ХНУРЭ, 2005. – С. 48-51.
31. Ельчанинов Д.Б., Петросов Д.А., Механа Сами Применение генетических алгоритмов при проектировании компьютерной техники // Вестник Херсонского государственного университета. № 2 (18). 2003. – С. 35-38.
32. Григорьев А.В. Представление генетических алгоритмов сетями Петри в задаче размещения. Автореф. дис. канд. техн. наук. – Казань, 2002. – 20 c.
33. Генетические алгоритмы, искусственные нейронные сети и проблемы виртуальной реальности / Г.К. Вороновский, К.В. Махотило, С.Н. Петрашев, С.А. Сергеев. – Х.: ОСНОВА, 1997. – 112 с.
34. De Jong K.A. Genetic Algorithms: A 10 Year Perspective // In: Procs of the First Int. Conf. onGeneticAlgorithms, 1985. – P. 167-177.
35. Искусственный интеллект [В 3-х кн.]. – Кн. 2. Модели и методы: Справочник / Под. ред. Д.А. Поспелова. – М.: Радио и связь, 1990. – 304 с.
36. Бакаев А.А., Гриценко В.И., Козлов Д.Н. Экспертные системы и логическое программирование. – Киев: Наук. думка, 1992. – 220 с.
37. Бондарев В.Н., Аде Ф.Г. Искусственный интеллект. – Севастополь: Изд-во СевНТУ, 2002. – 615 с.
38. Обработка нечеткой информации в системах принятия решений / А.Н. Борисов, А.В. Алексеев, Г.В. Меркурьев. – М.: Радио и связь, 1989. – 304 с.
39. Поспелов Д.А. Ситуационное управление: теория и практика. – М.: Наука, 1986. – 288 с.
40. Джексон П. Введение в экспертные системы. – М.: "Вильямс", 2001. – 624 с.
41. Sycara P.K. Multiagent Systems // AI MAGAZINE. – 1998. – V. 19. – № 2. – P. 79-93.
42. Гаврилова Т.А., Хорошевский В.Ф. Базы знаний интеллектуальных систем. – СПб: Питер, 2000. – 384 с.
43. Marco Dorigo, Vittorio Maniezzo, Alberto Colorni. The Ant System: Optimization by a colony of cooperating agents. // IEEE Transactions on Systems, Man and Cybernetics – Part B, Vol. 26, No.1, 1996. – P. 1-13.
44. Сергиенко И.Н. Алгоритмы искусственного интеллекта в процессе организационного моделирования // Информационные технологии и кибернетика 2006: Сборник докладов и тезисов IV-го Международного научно-практического форума (Днепропетровск, 27-28 апреля 2006 г.). – Днепропетровск: ИТМ, 2006. – С. 62-63.
45. Петров В.Н. Информационные системы. – СПб.: Питер, 2002. – 688 с.
46. Подземный транспорт шахт и рудников: Справочник / Под общей редакцией Г.Я. Пейсаховича, И.П. Ремизова. – М.: Недра, 1985. – 304 с.