| Скачать .docx |
Реферат: Программа-минимум кандидатского экзамена по специальности 05.13.17 «Теоретические основы информатики»
Программа-минимум кандидатского экзамена по специальности 05.13.17 «Теоретические основы информатики»
Введение
В основу настоящей программы положены следующие дисциплины: основы информатики; прикладная информатика; теория вероятностей и математическая статистика; теоретические основы информационных систем и технологий; вычислительные машины, системы и сети телекоммуникаций; операционные системы, среды и оболочки; базы данных; проектирование информационных систем; интеллектуальные информационные системы; высокоуровневые методы информатики и программирования; управление информационными ресурсами.
Программа разработана экспертным советом Высшей аттестационной комиссии Министерства образования Российской Федерации по управлению, вычислительной технике и информатике при участии Института проблем управления РАН и Вычислительного центра им. академика Доробницина.
1. Информатика как наука, отрасль промышленности и инфраструктурная область
Информатика наука, отрасль индустрии и инфраструктура. Информатика как наука, изучающая информацию и ее свойства в естественных, искусственных и гибридных системах. Место информатики в системе наук. Информатика как обрабатывающая информацию отрасль индустрии и инфраструктурная область, ее роль и значение в ускорении научно-технического прогресса.
Предметная область информатики. Информационные проблемы современного этапа научно-технической революции. Информационные потребности индивидуальных и коллективных пользователей. Информационные коммуникативные процессы. Современная информационная технология на базе широкого применения вычислительной техники и связи. Социальные аспекты информатизации и компьютеризации общества.
Понятие информационного продукта и информационной услуги. Классификация информационных продуктов и услуг. Жизненный цикл информационного продукта. Экономика информационных сетей. Методы управления производством и распределением информационных продуктов. Методы анализа и оценки качества информационных продуктов и услуг. Основные секторы информационной сферы: информация, электронные коммуникации, тематическая классификация. Сектор деловой информации. Сектор информации для специалистов. Научно-техническая информация. Другие виды профессионально ориентированной информации. Социально значимая (правовая, социальная, политическая, экологическая, образовательная и др.) информация.
Информационные ресурсы. Принципы оценки информации как ресурса общества и объекта интеллектуальной собственности. Проблемы правового регулирования научной интеллектуальной собственности. Государственная политика в области защиты информационных ресурсов общества. Законодательство по патентам на изобретения, полезные модели, промышленные образцы и товарные знаки. Методики оценки убытков обладателя информационными ресурсами в результате их противоправного использования.
Информационные технологии и системы, их определение, назначение и классификация.
2. Концептуальные модели информатики
Общие принципы моделирования окружающей среды, процессов мышления человека и человеко-машинного общения. Машинное представление знаний и данных. Методы хранения, поиска и обработки данных, методы естественно-языкового человеко-машинного общения.
Предметная область и ее модели. Понятия [план-содержание], [план-выражение]. Объекты, характеристики и их значения. Единицы информации и информационные отношения. Машинное понимание.
Когнитивные (интеллектуальные) системы. Декларативное и процедурное представление внешнего мира. Знание и компетенция, восприятие, мышление и двигательное возбуждение. База знаний и база данных.
Знаковые системы. Семиотический треугольник и его элементы. Понятия [экстенсионал] и [интенсионал].
Представление знаний
Классификационные системы: иерархические классификации, фасетные классификации, алфавитно-предметные классификации. Тезаурусные методы представления знаний.
Системы, основанные на отношениях. Объектно-характеристические таблицы. Предикатно-октантные структуры.
Семантические сети. Понятие сущности. Семантические отношения и их виды. Лингвистические, логические, теоретико-множественные, квантификационные отношения. Абстрактные и конкретные семантические сети.
Фреймы системно-структурное описание предметной области. Принципы фрейм-представлений. Понятие [СЛОТА].
Продукционные системы представления знаний. Канонические системы Поста. Представление неформальных знаний.
Редукционные системы. Синтез плана решения задач с автоматическим построением редукционной модели.
Представление данных
Обработка данных. Структуры данных. Уровни представления данных. Языки описания и манипулирования данными.
Система управления базами данных. Архитектура СУБД. Основные конструкции структур данных. Функции СУБД. Категории пользователей.
Классы структур данных. Иерархическая структура. Сетевые структуры. Реляционные структуры.
Информационный поиск
Основные понятия и виды поиска. Информационно-поисковые языки. Понятия пертинентности, смысловой и формальной релевантности. Критерии выдачи. Модели поиска. Стратегия поиска. Функциональная эффективность поиска. Поисковые массивы, способы их организации. Понятия об ассоциативном поиске и условиях его реализации.
3. Математические основы информатики
Теоретические математические дисциплины
Алгебра и геометрия: алгебраические структуры, векторные пространства, линейные отображения; аналитическая геометрия, многомерная геометрия кривых и поверхностей.
Математический анализ: дифференциальное и интегральное исчисления; экстремумы функций; аналитическая геометрия и линейная алгебра; последовательности и ряды; векторный анализ и элементы теории поля; дифференциальные уравнения; численные методы.
Математическая логика: исчисление высказываний; исчисление предикатов; логические модели; формальные системы; формальные грамматики; теория алгоритмов. Дискретная математика: логические исчисления, графы, комбинаторика. Элементы теории нечетких множеств. Нечеткие алгоритмы. Теория неопределенности. Теория вероятностей и математическая статистика: вероятности, случайные процессы, статистическое оценивание и проверка гипотез, статистические методы обработки экспериментальных данных. Многомерный статистический анализ. Множественный корреляционно-регрессионный анализ. Компонентный анализ. Факторный анализ. Кластер-анализ. Классификация без обучения. Дискриминантный анализ. Классификация с обучением. Канонические корреляции. Множественный ковариационный анализ.
Прикладная математика
Математические методы принятия решений; исследование операций как научный подход к решению задач принятия решений; методы исследования операций; построение экономических, математических и статистических моделей для задач принятия решения и управления в сложных ситуациях или в условиях неопределенности; границы применимости количественного анализа.
Модели линейного программирования; транспортная задача; задача распределения ресурсов; аксиомы линейности; динамическое планирование; распределение потоков товарных поставок на транспортной сети; эквивалентные сети; транспортная задача ХичкокаКупманса; выбор оптимального транспортного маршрута; использование линейного программирования для решения оптимизационных задач.
Математические модели информационных технологий и систем: описание, оценка, оптимизация
Модели описания информационных процессов и технологий. Теоретико-множественное описание сообщений, запросов, массивов документов. Универсальный информационный поток. Линейная модель. Матрица информационного потока. Ассоциативные матрицы информационного потока.
Критерии оценки информационных технологий и систем. Оценки качества поиска (полнота, точность и др.). Скалярные и векторные оценки. Смешанные критерии (полезная работа, корреляционный критерий, свертки и пр.). Рабочие характеристики информационно-поисковых систем (ИПС) в различных координатах. Вероятностная модель ИПС. Теоретико-множественная модель ИПС. Оптимизация режима ИПС.
Линейное представление документов, запросов, тезауруса, индексирования, поиска. Оценка структуры тезауруса. Понятие лексической совместимости и тезаурусной согласованности. Определение различительной силы термина, его различные варианты. Модели динамической корректировки запроса.
Теоретико-множественные макромодели информационных технологий и систем. Информационная и основная деятельность. Теоретико-множественные представления операций над информационными ресурсами. Операторы формирования информационных потоков. Количественная форма операторов. Линеаризованная форма операторов. Операции над операторами.
4. Технические средства информатики и информационных технологий
Физические основы вычислительных процессов
Основы построения и функционирования вычислительных машин: общие принципы построения и архитектуры вычислительных машин, информационно-логические основы вычислительных машин, их функциональная и структурная организация, память, процессоры, каналы и интерфейсы ввода-вывода, периферийные устройства.
Элементы вычислительной техники. Счетно-решающие механические и электромеханические устройства. Аналоговые и цифровые вычислительные машины. Понятие фон-неймановской машины. Процессор. Главная память. Система команд. Машинное слово. Разрядность и адресность. Программы и данные. Траектория данных в ЭВМ. Элементная база.
Архитектурные особенности и организация функционирования вычислительных машин различных классов: многомашинные и многопроцессорные вычислительные системы, типовые вычислительные структуры и программное обеспечение, режимы работы. Иерархическая структура ЭВМ. Главные процессор, канальные процессоры, контроллеры устройств. Накопители данных и внешние устройства ЭВМ.
Классификация и архитектура вычислительных сетей, техническое, информационное и программное обеспечение сетей, структура и организация функционирования сетей (глобальных, региональных, локальных).
Структура и характеристики систем телекоммуникаций: коммутация и маршрутизация телекоммуникационных систем, цифровые сети связи, электронная почта. Эффективность функционирования вычислительных машин, систем и сетей телекоммуникаций, пути ее повышения. Перспективы развития вычислительных средств. Технические средства человеко-машинного интерфейса.
5. Программные средства информатики и информационных технологий
Классы программных средств. Операционные системы. Системы программирования. Программные продукты.
Операционные системы. Функции операционной системы (ОС): управление задачами, управление данными, связь с оператором. Системное внешнее устройство и загрузка ОС. Резидентные модули и утилиты ОС. Управляющие программы (драйверы) внешних устройств. Запуск и остановка резидентных задач. Запуск и прекращение нерезидентных задач. Управление прохождением задачи и использованием памяти. Понятие тома и файла данных. Сообщения операционной системы. Команды и директивы оператора.
Системы программирования. Понятие разработки приложений. Состав системы программирования: язык программирования (ЯП), обработчик программ; библиотека программ и функций. История развития и сравнительный анализ ЯП. Типы данных. Элементарные данные, агрегаты данных, массивы, структуры, повторяющиеся структуры. Вычислительные данные, символьные данные, логические, адресные (метки и пойнтеры), прочие (битовые строки). Понятие блока и процедуры. Операторы ЯП: управления (организация циклов, ветвления процесса, перехода), присваивания, вычисления арифметических, логических, строчных выражений. Стандартные арифметические, логические, строчные функции.
Программные продукты (приложения). Оболочки операционной системы. Программные пакеты информационного поиска. Оболочки экспертных систем. Понятие открытого и закрытого программного продукта. Понятие генератора приложений. Системы управления базами данных, состав и структура. Типовые функции СУБД: хранение, поиск данных; обеспечение доступа из прикладных программ и с терминала конечного пользователя; преобразование данных; словарное обеспечение БД; импорт и экспорт данных из(в) файлов ОС ЭВМ. Типовая структура СУБД: ядро, обрамление, утилиты, интерпретатор/компилятор пользовательского языка манипулирования данными. Среда конечного пользователя. Front-end-процессор. Bac]-end-процессор.
Новейшие направления в области создания технологий программирования. Программирование в средах современных информационных систем: создание модульных программ, элементы теории модульного программирования, объектно-ориентированное проектирование и программирование. Объектно-ориентированный подход к проектированию и разработке программ: сущность объектно-ориентированного подхода, объектный тип данных, переменные объектного типа, инкапсуляция, наследование, полиморфизм, классы и объекты. Логическое программирование. Компонентное программирование.
6. Информационное и лингвистическое обеспечение информационных технологий
Предметная область и ее модели. Объекты, свойства отношения. Основные компоненты информационного обеспечения. Базы данных (БД). Базы знаний.
Базы данных. Основные понятия. Независимость программ и данных. Интегрированное использование данных. Непротиворечивость данных. Целостность и защита данных. Структуры БД. Администрирование банков данных. Типы пользователей. Администратор БД. Понятие концептуальной, логической, физической структуры БД. Представления пользователей и подсхемы. Понятие о словарях данных, языках описания и манипулирования данными. БД и файловые системы. Документальные и фактографические базы данных, базы знаний. Полнотекстовые БД. Физическая и логическая структура. Файл полного текста. Частотный словарь, инверсный файл. Положительный и отрицательный словари. Стандартные строки и словосочетания, включаемые в частотный словарь. Описание БД. Обработка текстов при загрузке БД. Понятие экспорта-импорта документов-данных.
Понятие модели данных. Иерархическая, сетевая модели данных, сравнительный анализ, противоречия и парадоксы. Реляционная модель данных. Экземпляры отношений, домены, атрибуты. Операции над отношениями: селекция, проекция, естественное соединение. Понятие реляционной полноты языка манипулирования данными. Модель данных [сущностьсвязь].
Языковые средства информационных технологий. Входные и внутренние языки. Структура входных языков. Языковые средства для ввода и обновления информации, для поиска, обобщения и выдачи информации. Языковые средства общения с БД. Анкетный язык. Языковые средства документальных (в том числе полнотекстовых) ИПС: три уровня грамматики информационно-поисковых языков (теоретико-множественный, линейный, сетевой). Информационно-поисковый язык. Язык информационно-логический. Язык процедурно ориентированный. Непроцедурный язык концептуального уровня. Язык диалога. Естественный язык. Словарный комплекс АИС. Классификаторы. Кодификаторы. Тезаурусы: состав и структура. Языки описания данных и словарь данных. Языки запросов SQL и QBE.
Информационный поиск. Основные понятия и виды. Модели поиска. Стратегии поиска. Понятие об ассоциативном поиске. Подготовка запросов и отчетов. Оперативный и регламентный режим поиска. Формирование отчетов.
Коммуникативные форматы обмена документами. Модель документа и ее использование. Карточный формат по ISO 2709.Процессы обмена документами в машиночитаемой форме, основные проблемы. Формат НТП-2. Элемент данных. Позиционные и помеченные электронные документы (ЭД). Метка, запись, блок. Область описания, фиксированные ЭД, маркер, справочник. Коммуникативный формат полнотекстового документа. Функции модели ЭД: категоризация документа, описание операционной среды, структура документа, поддержка создания и модификации документа, представление документа (преобразование внутренней формы во внешние для печати или вывода на экран, обеспечение поиска документов. Проекты и стандарты, отражающие различные подходы к моделям ЭД. Модели ODA, SGML (основные понятия и представления).
Базы знаний. Общие принципы моделирования окружающей среды и мышления человека. Методы представления знаний: классификационные тезаурусные, основанные на отношениях, семантические сети и фреймы, продукционные и непродукционные.
7. Телекоммуникационное обеспечение информационных технологий
Глобальные информационные сети. Общие характеристики, основные понятия, структура, организация, основные программные средства, информационные ресурсы (адрес в сети, имя в сети). Основные информационные средства и ресурсы сети. Удаленный доступ к ресурсам сети. Эмуляция удаленного терминала. Настройки на определенный тип терминала.
Машиночитаемые информационные ресурсы и их классификация. Генераторы БД. Операторы/арендаторы БД. Центры коммутации сообщений. Конечные пользователи. Генераторы и распространители (операторы) БД, классификация. Обзор состояния информационного рынка. Классификация БД. Библиографические, полнотекстовые, справочно-классификаторные БД. Некоторые экономические характеристики информационных потоков генераторов БД, сравнительный анализ. Сравнительный анализ экономических характеристик продуктов и услуг операторов БД.
Обмен файлами. Архитектура взаимодействия программ. Настройка программы-сервера. Анонимный доступ к удаленной файловой системе. Организация каталогов на удаленной системе и защита от несанкционированного доступа. Электронная почта. Принципы организации системы электронной почты. Программа-сервер сообщений. Организация почтовых ящиков. Программы подготовки сообщений и рассылки. Формат почтового сообщения. Телеконференции. Принципы организации программного обеспечения телеконференции. Подписка. Сервер телеконференции. Структура почтового сообщения. Стиль диалога. Почтовые файловые серверы. Почтовый сервер: назначение и принципы работы. Команды сервера. Система приоритетов в системе электронной почты.
Конкретные информационные и файловые системы в сети Internet. Gopher, WAIS (Wide Area Information Servers), WWW (World Wide Web). Принципы организации. Архитектура информационных массивов. Языки запросов. Средства отображения информации. Организация гипертекстового документа. Язык разметки HTML. Встроенные графические образы. Программы отображения и воспроизведения нетекстовой информации. Протокол обмена HTTP. Организация глобальной гипертекстовой сети.
8. Правовое обеспечение информатики
и информационных технологий
Элементы теории государства и права. Предмет теории права и государства. Понятие права, его признаки. Мораль и право: понятие и соотношение. Нормы и система права. Источники права. Закон и подзаконные акты. Понятие и система отраслей права. Правоотношения. Правонарушения и юридическая ответственность. Понятие государства, его функции, виды и структура. Система органов государственной власти в РФ. Конституционные основы судебной системы. Правоохранительные органы. Основы конституционного строя РФ. Основы трудового, гражданского и семейного права. Законодательство о страховании и налогах. Основы административного и уголовного права.
Основы договорных отношений при создании научно-технической или иной продукции. Общие положения возникновения и прекращения гражданских правоотношений. Основные положения об обязательствах и договорах. Понятие и виды обязательств. Субъекты обязательств. Исполнение обязательств. Прекращение обязательств. Практические аспекты заключения, изменения и расторжения договоров. Отдельные виды договоров. Правовые аспекты передачи научно-технической и иной продукции. Договорная и претензионно-исковая работа на предприятии. Разрешение споров в судебном порядке. Нотариальная защита.
Государственная политика в сфере обеспечения информационной безопасности. Понятие информационной безопасности. Жизненно важные интересы в информационной сфере. Угрозы жизненно важным интересам в информационной сфере. Принципы обеспечения информационной безопасности. Функции государственной системы по обеспечению информационной безопасности. Место законодательства в сфере обеспечения информационной безопасности в системе российского права. Законодательные и нормативные акты (государственные и международные), направленные против хищения информационных ресурсов и продуктов. Законодательные акты по легализации и защите компьютерной информации.
Защита права на доступ к информации. Основные информационные права и свободы и их ограничения. Правовая охрана права на доступ к информации. Защита права на доступ к информации.
Защита права на неприкосновенность частной жизни. Источники права на неприкосновенность частной жизни. Объекты и субъекты права на неприкосновенность частной жизни. Правовая охрана и защита прав на неприкосновенность частной жизни. Персональные данные как особый институт охраны прав на неприкосновенность частной жизни.
Защита права на информацию с ограниченным доступом. Понятие, структура и признаки информации с ограниченным доступом. Государственная тайна. Источники права о государственной тайне. Объект и субъекты права на государственную тайну. Правовая охрана и защита прав на государственную тайну. Коммерческая, банковская, профессиональная, служебная тайна. Источники права, объекты и субъекты права на коммерческую, банковскую, профессиональную, служебную тайну. Правовая охрана и защита прав на коммерческую, банковскую, профессиональную, служебную тайну.
Защита прав на объекты интеллектуальной собственности. Понятие и структура интеллектуальной собственности. Международное сотрудничество в области защиты интеллектуальной и промышленной собственности. Всемирная организация интеллектуальной собственности (ВОИС). Другие международные и зарубежные организации и другие документы по защите информационных ресурсов общества.
Правовая охрана и защита авторских и смежных прав. Источники, объекты и субъекты авторского права. Защита авторских и смежных прав. Правовая охрана и защита патентного права и прав на средства индивидуализации. Источники, объекты и субъекты патентного права и прав на средства индивидуализации. Правовая охрана и защита патентных прав и прав на средства индивидуализации. Защита прав на нетрадиционные объекты интеллектуальной собственности. Источники, объекты и субъекты прав на нетрадиционные объекты интеллектуальной собственности. Правовая охрана и защита прав на нетрадиционные объекты интеллектуальной собственности. Защита против недобросовестной конкуренции. Источники права о защите против недобросовестной конкуренции. Объекты и субъекты права защиты против недобросовестной конкуренции. Правовая охрана права на защиту против недобросовестной конкуренции.
Защита информационных технологий, систем и прав на них. Информационное оружие в информационной войне. Особенности правовой охраны и защиты прав на информационные системы и ресурсы. Виды противников или [нарушителей]. Три вида возможных нарушений информационной системы. Основные положения теории информационной безопасности информационных систем. Модели безопасности и их применение. Таксономия нарушений информационной безопасности вычислительной системы и причины, обусловливающие их существование. Анализ способов нарушений информационной безопасности. Использование защищенных компьютерных систем. Методы криптографии. Основные технологии построения защищенных информационных систем.
Основная литература
Лопатин В.Н. Правовые основы информационной безопасности: Курс лекций. М.: Изд-во МИФИ, 2000.
Мартин Дж. Организация баз данных в вычислительных системах. М.: Мир, 2000.
Михайлов А.И., Черный А.И., Гиляревский Р.Э. Основы информатики. М.: Наука, 1978.
Попов И.И. Информационные ресурсы и системы: реализация, моделирование, управление. М.: ТПК [Альянс], 1996.
Попов И.И., Максимов Н.В., Храмцов П.Б. Введение в сетевые информационные ресурсы и технологии: Учеб. пособие для вузов. М.: Изд-во РГГУ, 2001.
Шемякин Ю.И. Введение в информатику. М.: Финансы и статистика, 1985.
Дополнительная литература
Основы государства и права: Учеб. пособие для вузов / Под ред. О.Е. Кутафина. М.: Юрист, 1994.
Попов И.И. Автоматизированные информационные системы (по областям применения): Учеб. пособие для вузов. М.: Изд-во РЭА им. Г.В. Плеханова, 1999.
Феллер В. Введение в теорию вероятностей и ее приложения. В 2 т. М.: Мир, 1982.
Ответы
1. Информатика как наука, отрасль промышленности и инфраструктурная область
Информатика — наука, отрасль индустрии и инфраструктура. Информатика как наука, изучающая информацию и ее свойства в естественных, искусственных и гибридных системах. Место информатики в системе наук. Информатика как обрабатывающая информацию отрасль индустрии и инфраструктурная область, ее роль и значение в ускорении научно-технического прогресса.
Некоторые ученые понимают информатику широко – как науку об информации вообще.
Эта наука изучает процессы и законы
передачи
распространения
обработки
преобразования
кодирования
запоминания
отображения
потребления информации и т.д.
Некотороые ученые под информатикой имеют в виду комплексную научную и инженерную дисциплину, которая изучает все аспекты разработки, проектирования, создания, оценки функционирования основанных на ЭВМ систем переработки информации, их применения и воздействия на различные области социальной практики.
Объект и предмет информатики
Поскольку информатика – многоаспектная научная область, объект и предмет ее неоднозначны. Объектом изучения информатики является, прежде всего, информация.
Предметом информатики как науки являются информационные технологии в их взаимодействии со средой.
Информатика – это теория и практика проектирования, встраивания новых информационных технологий в социальные среды и их использования.
Предметной областью информатики является информационная среда. Информационная среда включает в себя информационные процессы и информационные системы, а также все факторы, воздействующие на них на протяжения всего их существования – начиная от проектирования и до окончания использования.
Можно выделить основные направления развития информатики: теоретическая информатика, прикладная и техническая.
Основные цели теоретической информатики – развитие общей теории создания, переработки и хранения информации; изучение ее структуры и свойств; разработка теоретических проблем организации систем обработки информации; выяснение закономерностей, в соответствии, с которыми происходит создание семантической информации, ее преобразование, передача и использование в различных сферах деятельности человека; разработка современных методов расчета на ЭВМ; открытие общих законов, лежащих в основе переработки информации; изучение сложных взаимосвязей в системе “человек – ЭВМ”, а также взаимного влияния социальных факторов и развития информационных технологий.
Прикладная информатика охватывает возможности формализации и математизации областей ее применения, создание баз знаний, моделей информатики, имитации; разработку наиболее рациональных методов осуществления информационных процессов автоматизации исследований, методов и средств вычислительной техники, автоматизации производства; разработку теоретических основ проектирования и организации информационно-поисковых и информационно-логических систем; определение способов наиболее оптимальной организации связи как внутри науки, так и между наукой и производством с широким применением современных вычислительных технических средств, а также изучение закономерностей научно – информационной деятельности.
Техническая информатика – отрасль народного хозяйства, основанная на “индустрии” информатики; она включает в себя разработку структуры, принципов конструкции автоматизированных систем обработки информации; создание вычислительной техники новых поколений (в том числе персональных компьютеров), математического обеспечения; эксплуатация средств обработки создание гибких технологических систем, роботов, а также другие проблемы связанные с коадаптации человека к новой информационной технологии. К информатике относят и область искусственного интеллекта, содержащую как теоретические, так и технические аспекты.
Информатика - область человеческой деятельности, связанная с процессами преобразования информации с помощью компьютеров и других средств вычислительной техники.

Выполняя свою функцию, информатика решает следующие задачи:
* исследует информационные процессы в социальных системах;
* разрабатывает информационную технику и создает новейшие технологии преобразования информации на основе результатов, полученных в ходе исследования информационных процессов;
* решает научные и инженерные проблемы создания, внедрения и обеспечения эффективного использования компьютерной техники и технологии во всех сферах человеческой деятельности.
В рамках прикладной дисциплины информатики изучаются следующие вопросы:
* понятие информации, ее свойства, измерение информации, использование в управлении;
* способы кодирования информации;
* понятие и составные части информационных процессов;
* организация технических устройств преобразования информации, в частности компьютера;
* структура и методология проектирования программного обеспечения.
Место информатики в системе наук.
Информатика – слуга других наук, техники и производства. Она снабжает их методами исследования. Но пока – это методы, в основном заимствованные ею из других областей: математической статистики, вычислительной математики, теория игр, графов, исследование операций, математического программирования и другие.
Связь с кибернетикой, теорией информации, математикой.
Задачей кибернетики является рассмотрение информации как таковой.
Кибернетика ставит в центр своего рассмотрения компьютер. Она исследует технические основы компьютера – его архитектуру и создание; теоретические основания ; технико-технологические вопросы применения.
Хотя Н. Винер и понимал фундаментальность информационного подхода, главными понятиями развиваемой науки он считал управление и обратную связь, поскольку на этом пути были получены основные результаты.
Информатика является не составной частью кибернетики, а самостоятельной научной дисциплиной, тесно связанной с кибернетикой, пересекающейся с нею.
Предметная область информатики. Информационные проблемы современного этапа научно-технической революции. Информационные потребности индивидуальных и коллективных пользователей. Информационные коммуникативные процессы. Современная информационная технология на базе широкого применения вычислительной техники и связи. Социальные аспекты информатизации и компьютеризации общества.
Понятие информационного продукта и информационной услуги. Классификация информационных продуктов и услуг.
Информационный продукт - документированная информация, подготовленная в соответствии с потребностями пользователей и представленная в форме товара.
Информационная услуга - услуга, ориентированные на удовлетворение информационных потребностей пользователей путем предоставления информационных продуктов.
Рынок информационных продуктов и услуг (информационный рынок) -
система экономических, правовых и организационных отношений по
торговле продуктами интеллектуального труда на коммерческой основе.
К информационным продуктам относятся документы, данные, справки, аналитические обзоры, базы и банки данных, компьютерные игры, фильмы, книги и другие виды информационных продуктов. Информационными продуктами являются программные продукты, базы и банки данных, информационные системы, информационные технологии, лицензии, патенты, товарные знаки, ноу-хау, инженерно-технические услуги, различного рода информация и прочие виды информационных ресурсов.
Отметим основные особенности информационного продукта, которые кардинально отличают информацию от других товаров.
Во-первых, информация не исчезает при потреблении, а может быть использована многократно. Информационный продукт сохраняет содержащуюся в нем информацию, независимо от того, сколько раз она была использована.
Во-вторых, информационный продукт со временем подвергается своеобразному «моральному износу». Хотя информация и не изнашивается при употреблении, но она может терять свою ценность по мере того, как предоставляемое ею знание перестает быть актуальным.
В различных областях науки и техники темпы обесценения знания неодинаковы, процесс «старения» информации может длиться от пяти до пятнадцати лет.
В-третьих, разным потребителям информационных товаров и услуг удобны разные способы предоставления информации, ведь потребление информационного продукта требует усилий. В этом состоит свойство адресности информации.
В - четвертых, производство информации, в отличии от производства материальных товаров, требует значительных затрат по сравнению с затратами на тиражирование.
Поставщиками < информационных > < продуктов > и услуг могут быть:
центры, где создаются и хранятся базы данных, а также производится постоянное накопление и редактирование в них информации;
центры, распределяющие информацию на основе разных баз данных;
службы телекоммуникации и передачи данных;
специальные службы, куда стекается информация по конкретной сфере деятельности для ее анализа, обобщения, прогнозирования, например консалтинговые фирмы, банки, биржи;
коммерческие фирмы;
информационные брокеры.
Выделяются 5 секторов рынка информационных продуктов и услуг.

1-й сектор—деловая и нф ор м а ция, состоит из следующих частей:
биржевая и финансовая информация — котировки ценных бумаг, валютные курсы, учетные ставки, рынок товаров и капиталов, инвестиции, цены. Поставщиками являются специальные службы биржевой и финансовой информации, брокерские компании, банки;
статистическая информация — ряды динамики, прогнозные модели и оценки по экономической, социальной, демографической областям. Поставщиками являются государственные службы, компании, консалтинговые фирмы;
коммерческая информация по компаниям, фирмам, корпорациям, направлениям работы и их продукции, ценам; о финансовом состоянии, связях, сделках, руководителях, деловых новостях в области экономики и бизнеса. Поставщиками являются специальные информационные службы.
2-й сектор —информация для с пециалисто в, содержит следующие части:
профессиональная информация — специальные данные и информация для юристов, врачей, фармацевтов, преподавателей, инженеров, геологов, метеорологов и т.д.;
научно-техническая информация — документальная, библиографическая, реферативная, справочная информация в области естественных, технических, общественных наук, по отраслям производства и сферам человеческой деятельности;
доступ к первоисточникам — организация доступа к источникам информации через библиотеки и специальные службы, возможности приобретения первоисточников, их получения по межбиблиотечному абонементу в различных формах.
3-й сектор—потребительская информация, состоит из следующих частей:
новости и литература — информация служб новостей и агентств прессы, электронные журналы, справочники, энциклопедии;
потребительская информация — расписания транспорта, резервирование билетов и мест в гостиницах, заказ товаров и услуг, банковские операции и т.п.;
развлекательная информация — игры, телетекст, видеотекст.
4-й сектор—услуги о бр а зовани я, включает все формы и ступени образо-вания: дошкольное, школьное, специальное, среднепрофессиональное, высшее, повышение квалификации и переподготовку. Информационная продукция может быть представлена в компьютерном или некомпьютерном виде: учебники, методические разработки, практику мы, развивающие компьютерные игры, компьютерные обучающие и контролирующие системы, методики обучения и пр.
5-й сектор —обеспечивающие информационные системы и средства, состоит из следующих частей:
программные продукты — программные комплексы с разной ориентацией — от профессионала до неопытного пользователя компьютера: системное программное обеспечение, программы общей ориентации, прикладное программное обеспечение по реализации функций в конкретной области принадлежности, по решению задач типовыми математическими методами и др.;
технические средства — компьютеры, телекоммуникационное оборудование, оргтехника, сопутствующие материалы и комплектующие;
разработка и сопровождение информационных систем и технологий — обследование организации в целях выявления информационных потоков, разработка концептуальных информационных моделей, разработка структуры программного комплекса, создание и сопровождение баз данных;
консультирование по различным аспектам информационной индустрии — какую приобретать информационную технику, какое программное обеспечение необходимо для реализации профессиональной деятельности, нужна ли информационная система и какая, на базе какой информационной технологии лучше организовать свою деятельность и т.д.;
подготовка источников информации — создание баз данных по заданной теме, области, явлению и т.п.
В каждом секторе может быть организован любой вид доступа:
непосредственный к хранилищу информации на бумажных носителях;
дистанционный к удаленным или находящимся в данном помещении компьютерным базам данных.
По сферам использования информация может подразделяться на
* научно-техническую,
* управленческую
* социальную.
При прагматическом подходе, который оценивает блага от использования информации, информационные продукты делятся на
* познавательные
* развлекательные.
Информационные услуги могут оказываться двумя способами. Первый из них – это услуги по информационному обслуживанию. Этот способ более характерен для европейских стран и США. В нашей стране он применяется не так часто. В соответствии с данным способом информационная компания осуществляет для потребителя поиск, обработку, хранение и выдачу информации, как правило, в виде конечного продукта. Подобный способ удобен при глобальном поиске большого количества информации или длительном постоянном обслуживании. Услуги по информационному обслуживанию могут оказываться как сторонними организациями, на основе договора, так и структурными подразделениями в составе самой организации-заказчика.
An information broker is a person or business that researches information for clients. Common uses for information brokers include market research and patent searches, but can include practically any type of information research.
Второй вид информационных услуг – предоставление доступа к базам данных, компьютерным сетям, в том числе Интернет. В этот же вид информационных услуг попадает сопровождение проданных ранее информационных ресурсов. Организации, оказывающие данный вид информационных услуг, как правило, только предоставляют доступ и взимают за это плату. Данные информационные услуги являются наиболее распространенными в нашей стране на настоящий момент.

Более подробный ответ:
Информационный продукт - документированная информация, подготовленная в соответствии с потребностями пользователей и представленная в форме товара. Информационными продуктами являются программные продукты, базы и банки данных и другая информация.
Информационная услуга - услуга, ориентированная на удовлетворение информационных потребностей пользователей путем предоставления информационных продуктов.
Информационный продукт, являясь результатом интеллектуальной деятельности человека, должен быть зафиксирован на материальном носителе любого физического свойства в виде документов, статей, обзоров, программ, книг и т.д.
При предоставлении услуги заключается соглашение (договор) между двумя сторонами – предоставляющей и использующей услугу. В договоре указываются срок ее использования и соответствующее этому вознаграждение.
Пример. Библиотеки являются местом сосредоточения значительной части информационных ресурсов страны. Перечислим основные виды информационных услуг, оказываемых библиотечной сферой:
* предоставление полных текстов документов, а также справок по их описанию и местонахождению;
* выдача результатов библиографического поиска и аналитической переработки информации (справки, указатели, дайджесты, обзоры и пр.);
* получение результатов фактографического поиска и аналитической переработки информации (справки, таблицы, фирменное досье);
* организация научно–технической пропаганды и рекламной деятельности (выставки новых поступлений, научно–технические семинары, конференции и т.п.);
* выдача результатов информационного исследования (аналитические справки и обзоры, отчеты, рубрикаторы перспективных направлений, конъюнктурные справки и т.д.).
Базы данных являются источником и своего рода полуфабрикатом при подготовке информационных услуг соответствующими службами. Базы данных, хотя они так и не назывались, существовали и до компьютерного периода в библиотеках, архивах, фондах, справочных бюро и других подобных организациях. В них содержатся всевозможные сведения о событиях, явлениях, объектах, процессах, публикациях и т.п.
С появлением компьютеров существенно увеличиваются объемы хранимых баз данных и соответственно расширяется круг информационных услуг.
Рассмотрим классификацию баз данных с позиций их использования для систематизации информационных услуг и продуктов.
Базы данных принято разделять на библиографические и небиблиографические.
Библиографические базы данных содержат вторичную информацию о документах, включая рефераты и аннотации.
Небиблиографические базы данных имеют множество видов:
* справочные, содержащие информацию о различных объектах и явлениях, например адреса, расписания движения, телефоны магазинов и т.п.;
* полного текста, содержащие первичную информацию, например статьи, журналы, брошюры и т.п.;
* числовые, содержащие количественные характеристики и параметры объектов и явлений, например химические и физические данные, статистические и демографические данные и т.п.;
* текстово–числовые, содержащие описания объектов и их характеристики, например по промышленной продукции, фирмам, странам и т.п.;
* финансовые, содержащие финансовую информацию, предоставляемую банками, биржами, фирмами и т.п.;
* юридические, содержащие правовые документы по отраслям, регионам, странам.
Исходя из возможных видов информационных продуктов, баз данных и ресурсов классификация информационных услуг представлена на рис. 1.1.
Выпуск информационных изданий означает подготовку печатной продукции: библиографических и других указателей; реферативных сборников; обзорных изданий; справочных изданий.
Информационные издания подготавливаются практически всеми видами информационных служб, органов и систем. Эти издания содержат вторичную информацию, которая создается на основе работы с базами данных, предоставление работы с которыми также является услугой.
Ретроспективный поиск информации– это целенаправленный по заявке пользователя поиск информации в базе данных и пересылка результатов либо по почте в виде распечаток, либо по электронной почте в виде файла.
Рис. 1.1. Основные виды информационных услуг
Предоставление первоисточникаявляется традиционной услугой библиотечных служб. Эта услуга предусматривает не только выдачу первоисточников, но и их копий, полученных с помощью устройств различного принципа действия.
Традиционные услуги научно–технической информации осуществляются по предварительному заказу и включают в себя:
подготовку обзоров в виде рукописей;
подготовку переводов текстов.
Дистанционный доступ к удаленным базам данных организуется в компьютерной сети в диалоговом режиме. Популярность услуг дистанционного доступа к базам данных нарастает быстрыми темпами и опережает все виды других услуг благодаря:
* все большему числу пользователей, овладевших информационной технологией работы в коммуникационной среде компьютерных сетей;
* высокой оперативности предоставления услуг;
* возможности отказа от собственных информационных систем.
Традиционно основными пользователями услуг дистанционного доступа к базам данных являются организации. Однако за последние годы наметилась тенденция к существенному увеличению числа индивидуальных пользователей.
В основном эти услуги предоставляются специальными организациями, называемыми вычислительными центрами коллективного пользования, располагающими мощными ЭВМ с внешней памятью более сотен гигабайт и лазерными принтерами. Дистанционный доступ к базам данных может быть предоставлен по подписке на основе абонементной платы или по договорам. Схема оплаты может быть разная, но в основном это почасовая оплата, зависящая от объема получаемой информации.
Услуги дистанционного доступа к базам данных можно классифицировать следующим образом:
непосредственный доступ к базам данных может быть организован с локального места пользователя только при условии его обученности работе в коммуникационной среде. В противном случае следует воспользоваться услугами, предоставляемыми специальными организациями;
косвенный доступ включает организацию обучения пользователей, выпуск бюллетеня новостей, организацию справочной службы, организацию встреч с пользователем для выяснения интересующих его вопросов, рассылку вопросников пользователям;
услуга Downloading позволяет загрузить результаты поиска в центральной базе данных в свой персональный компьютер для дальнейшего использования в качестве персональной базы данных;
регулярный поиск предусматривает регулярное проведение поиска в массивах одной или нескольких центральных баз данных и предоставление результатов поиска на терминал пользователю в удобное для него время.
Подготовка и оказание информационных услуг:
* связь (телефонная, телекоммуникационная) для предоставления осуществляемых в форме передачи данных информационных услуг;
* и обработка данных в вычислительных центрах;
* программное обеспечение;
* разработка информационных систем;
* разработка информационных технологий.
Жизненный цикл информационного продукта.
Жизненный цикл программного обеспечения (ПО) — период времени, который начинается с момента принятия решения о необходимости создания программного продукта и заканчивается в момент его полного изъятия из эксплуатации[1].
Стандарт ГОСТ 34.601-90 предусматривает следующие стадии и этапы создания автоматизированной системы:
1. Формирование требований к АС
1. Обследование объекта и обоснование необходимости создания АС
2. Формирование требований пользователя к АС
3. Оформление отчета о выполнении работ и заявки на разработку АС
2. Разработка концепции АС
1. Изучение объекта
2. Проведение необходимых научно-исследовательских работ
3. Разработка вариантов концепции АС и выбор варианта концепции АС, удовлетворяющего требованиям пользователей
4. Оформление отчета о проделанной работе
3. Техническое задание
1. Разработка и утверждение технического задания на создание АС
4. Эскизный проект
1. Разработка предварительных проектных решений по системе и ее частям
2. Разработка документации на АС и ее части
5. Технический проект
1. Разработка проектных решений по системе и ее частям
2. Разработка документации на АС и ее части
3. Разработка и оформление документации на поставку комплектующих изделий
4. Разработка заданий на проектирование в смежных частях проекта
6. Рабочая документация
1. Разработка рабочей документации на АС и ее части
2. Разработка и адаптация программ
7. Ввод в действие
1. Подготовка объекта автоматизации
2. Подготовка персонала
3. Комплектация АС поставляемыми изделиями (программными и техническими средствами, программно-техническими комплексами, информационными изделиями)
4. Строительно-монтажные работы
5. Пусконаладочные работы
6. Проведение предварительных испытаний
7. Проведение опытной эксплуатации
8. Проведение приемочных испытаний
8. Сопровождение АС.
1. Выполнение работ в соответствии с гарантийными обязательствами
2. Послегарантийное обслуживание
Модели жизненного цикла ПО
Среди известных моделей жизненного цикла можно выделить следующие модели:
— каскадная модель (до 70-х гг.) ─ последовательный переход на следующий этап после завершения предыдущего;
— итерационная модель (70-80 гг.) ─ с итерационными возвратами на предыдущие этапы после выполнения очередного этапа;
— спиральная модель (80-90 гг.) ─ прототипная модель, предполагающая постепенное расширение прототипа ЭИС.
Каскадная модель .
Каскадная модель жизненного цикла
предусматривает последовательное выполнение всех этапов проекта в строго фиксированном порядке. Переход на следующий этап означает полное завершение работ на предыдущем этапе. Требования, определенные на стадии формирования требований, строго документируются в виде технического задания и фиксируются на все время разработки проекта. Каждая стадия завершается выпуском полного комплекта документации, достаточной для того, чтобы разработка могла быть продолжена другой командой разработчиков.
Этапы проекта в соответствии с каскадной моделью:
1. Формирование требований;
2. Проектирование;
3. Реализация;
4. Тестирование;
5. Внедрение;
6. Эксплуатация и сопровождение.
Для этой модели жизненного цикла характерна автоматизация отдельных несвязанных задач, не требующая выполнения информационной интеграции и совместимости, программного, технического и организационного сопряжения. В рамках решения отдельных задач каскадная модель жизненного цикла по срокам разработки и надежности оправдывала себя. Применение каскадной модели жизненного цикла к большим и сложным проектам вследствие большой длительности процесса проектирования и изменчивости требований за это время приводит к их практической нереализуемости.
Основные характеристики каскадного способа : разбиение всей разработки на этапы; переход с одного этапа на следующий происходит только после полного завершения работы на текущем этапе (см. рис); возможность планировать сроки завершения всех работ и соответствующие затраты ; результатами каждого этапа являются технические решения и полный комплект проектной документации , отвечающей критериям полноты и согласованности, достаточной для того, чтобы разработка могла быть продолжена другой командой разработчиков; исходными для каждого этапа являются документы и решения, полученные на предыдущем этапе. См. Рис.
Каскадный подход хорошо зарекомендовал себя при разработке не сложного ПО , когда каждая программа представляет собой единое целое. При построении такого ПО в самом начале разработки можно достаточно точно и полно сформулировать все требования, с тем, чтобы предоставить разработчикам свободу реализовать их как можно лучше с технической точки зрения.
Основной недостаток каскадного подхода : требования к ПО "заморожены" в виде технического задания на все время его создания. Пользователи могут внести свои замечания только после того, как работа над ПО будет полностью завершена. В случае неточного изложения требований или их изменения в течение длительного периода создания ПО , пользователи получают систему, не удовлетворяющую их потребностям. Модели (как функциональные, так и информационные) автоматизируемого объекта могут устареть одновременно с их утверждением.
Итерационная модель .
Создание комплексных ЭИС предполагает проведение увязки проектных решений, получаемых при реализации отдельных задач. Подход к проектированию "сниз - вверх " обусловливает необходимость таких итерационных возвратов, когда проектные решения по отдельным задачам комплексируются в общие системные решения и при этом возникает потребность в пересмотре ранее сформулированных требований. Как правило, вследствие большого числа итераций возникают рассогласования выполненных проектных решений и документации. Запутанность функциональной и системной архитектуры созданной ЭИС, трудность в использовании проектной документации вызывает на стадиях внедрения и эксплуатации сразу необходимость перепроектирования всей системы. Длительный жизненный цикл разработки ЭИС заканчивается этапом внедрения, за которым начинается жизненный цикл создания новой ЭИС.
Спиральная модель .
ПО создается в несколько итераций (витков спирали) методом прототипирования.
Прототип — действующий компонент ПО, реализующий отдельные функции и внешние интерфейсы. Каждая итерация соответствует созданию фрагмента или версии ПО, на ней уточняются цели и характеристики проекта, оценивается качество полученных результатов и планируются работы следующей итерации.
На каждой итерации оцениваются:
* риск превышения сроков и стоимости проекта;
* необходимость выполнения еще одной итерации;
* степень полноты и точности понимания требований к системе;
* целесообразность прекращения проекта.
Используется подход к организации проектирования ЭИС «сверху-вниз», когда сначала определяется состав функциональных подсистем, а затем постановка отдельных задач. Соответственно сначала разрабатываются такие общесистемные вопросы как организация интегрированной базы данных, технология сбора, передачи и накопления информации, а затем технология решения конкретных задач. В рамках комплексов задач программирование осуществляется по направлению от головных программных модулей к исполняющим отдельные функции модулям. При этом на первый план выходят вопросы организации интерфейсов программных модулей между собой и с базой данных, а на второй план ─ реализация алгоритмов.
В основе спиральной модели жизненного цикла лежит применение прототипной технологии или RAD-технологии (rapid application development ─ технологии быстрой разработки приложений) ─ J. Martin. Rapid Application Development. New York: Macmillan, 1991. Согласно этой технологии ЭИС разрабатывается путём расширения программных прототипов, повторяя путь от детализации требований к детализации программного кода. Естественно, что при прототипной технологии сокращается число итераций и меньше возникает ошибок и несоответствий, которые необходимо исправлять на последующих итерациях, а само проектирование ЭИС осуществляется более быстрыми темпами, упрощается создание проектной документации. Для более точного соответствия проектной документации разработанной ЭИС все большее значение придается ведению общесистемного репозитория и использованию CASE-технологий.
Жизненный цикл при использовании RAD-технологии предполагает активное участие на всех этапах разработки конечных пользователей будущей системы.
Спиральная модель ЖЦ (см. рис), делающая упор на начальные этапы ЖЦ: анализ требований, определение спецификаций и проектирование (предварительное и детальное) .
На этих этапах реализуемость технических решений проверяется путем создания прототипов приложений , которые демонстрируются заказчику, обсуждаются.
Под прототипом обычно понимают набор программ, моделирующих (изображающих, эмулирующих) работу готовой системы. Цель прототипирования - более ясно представить себе будущую систему, предугадать ее недостатки на этапе проектирования, внести необходимые коррективы в техническое задание и технический проект, если он уже готов. Прототип системы удобно демонстрировать сотрудникам предприятия-заказчика, чтобы они могли понять, насколько удобно им будет пользоваться системой, какие функции следует добавить или исключить. Каждый виток спирали соответствует созданию фрагмента или версии ПО , на нем уточняются цели и характеристики проекта, определяется его качество и планируются работы следующего витка спирали. Таким образом, углубляются и последовательно конкретизируются детали проекта. Разработка итерациями отражает объективно существующий спиральный цикл создания ПО . Неполное завершение работ на каждом этапе позволяет переходить на следующий этап, не дожидаясь полного завершения работы на текущем этапе. При итеративном способе разработки недостающую работу можно будет выполнить на следующей итерации. Главная задача - как можно быстрее показать пользователям работоспособный продукт, тем самым, активизируя процесс уточнения и дополнения требований, исправления ошибок, обусловленных неопределенностью или некорректностью технических заданий и спецификаций требований. Спиральная модель не исключает использования каскадного подхода на завершающих стадиях проекта в тех случаях, когда требования к системе оказываются полностью определенными. Основная проблема спирального цикла - определение момента перехода на следующий этап. Для ее решения необходимо ввести временные ограничения на каждый из этапов ЖЦ. Переход осуществляется в соответствии с планом, даже если не вся запланированная работа закончена. План составляется на основе статистических данных, полученных в предыдущих проектах, и личного опыта разработчиков. Другими недостатками спиральной модели являются: трудоемкость внесения изменений; большой объем документации по проекту, затрудняющий программирование; сложность переноса на другие платформы.
Экономика информационных сетей.
Интернет-технологии ® новый образ экономики (сетевая экономика)
Тенденции развития сетевой экономики:
- индивидуальный подход к квалифицированному покупателю
- появление глобальной конкуренции
- изменение структуры существующих предприятий и компаний
Методы управления производством и распределением информационных продуктов.
Стратегический характер информации как ресурса экономического и социального развития обуславливает высокую степень государственного регулирования, значительный уровень концентрации и монополизации информационного производства.
Существующие сегодня тенденции в этой области ярко иллюстрирует ситуация на рынке коммуникаций. Так, среди 13 развитых стран мира только в США, Великобритании и Японии нет монополии на традиционные коммуникационные средства.
В 80-е годы во многих странах начала проводиться политика демонополизации и дерегулирования, что в свою очередь способствовало становлению разнообразных рыночных структур и диверсификации информационного производства. Широкую огласку получила проводившаяся приватизация таких гигантов информационного бизнеса, как английская корпорация «Бритиш телеком», японская «Ниппон телеграф & телефоун», американская «Американ телефоун & телеграф».
Многие продукты информационной деятельности по своему статусу являются общественными благами (фундаментальные научные исследования, государственное управление, национальные сети коммуникаций и т. д.)
Как правило, государство берет на себя регулирование процесса производства и распределения информационных продуктов, без которых общество не может нормально развиваться.
Развитие рыночных отношений в информационной деятельности поставило вопрос о защите информации как объекта интеллектуальной собственности и имущественных прав на нее. В Российской Федерации принят ряд указов, постановлений, законов, таких, как:
"Об информации, информатизации и защите информации".
В законе определены цели и основные направления государственной политики в сфере информатизации. Информатизация определяется как важное новое стратегическое направление деятельности государства. Указано, что государство должно заниматься формированием и реализацией единой государственной научно–технической и промышленной политики в сфере информатизации.
Закон создает условия для включения России в международный информационный обмен, предотвращает бесхозяйственное отношение к информационным ресурсам и информатизации, обеспечивает информационную безопасность и права юридических и физических лиц на информацию. В нем определяются комплексное решение проблемы организации информационных ресурсов, правовые положения по их использованию и предлагается рассматривать информационные ресурсы в двух аспектах:
* как материальный продукт, который можно покупать и продавать;
* как интеллектуальный продукт, на который распространяется право интеллектуальной собственности, авторское право.
С технологической и экономической точек зрения производство, обмен, распределение и потребление информации имеют целый ряд специфических особенностей.
Сегодня во всех странах независимо от уровня экономического и социального развития происходит структурная перестройка, связанная с ростом информационного сектора экономики и соответственно влекущая за собой значительные социальные, политические и культурные изменения в обществе.
Ярким проявлением этих тенденций является значительное увеличение числа занятых информационной деятельностью, т.е. деятельностью, связанной с производством, обработкой, хранением и распространением информации.
В свою очередь рынок информационных товаров и услуг является сегодня самым динамично развивающимся.
"Об авторском праве и смежных правах",
"О правовой охране программ для ЭВМ и баз данных".
"О правовой охране топологий интегральных схем".
Классическим примером положительных информационных экстерналей является финансирование отдельными фирмами научных исследований и разработок, результаты которых часто становятся достоянием широкого круга заинтересованных лиц. Патенты или лицензии могут являться средством устранения положительных внешних эффектов информационного проиэводства.
Методы анализа и оценки качества информационных продуктов и услуг.
Цена на товар (например, книгу) определяется спросом.
Из-за специфики информации как товара и социальной значимости информационных продуктов при оценке эффективности производства и возможностей использования информации все чаще применяются моральные и эстетические критерии наряду с денежными.
Основные секторы информационной сферы: информация, электронные коммуникации, тематическая классификация. Сектор деловой информации. Сектор информации для специалистов. Научно-техническая информация. Другие виды профессионально ориентированной информации. Социально значимая (правовая, социальная, политическая, экологическая, образовательная и др.) информация.
Информационная сфера — совокупность субъектов информационного взаимодействия или воздействия; собственно информации, предназначенной для использования субъектами информационной сферы; информационной инфраструктуры, обеспечивающей возможность осуществления обмена информацией между субъектами; общественных отношений, складывающихся в связи с формированием, передачей, распространением и хранением информации, обменом информацией внутри общества. [40]
Право на доступ к информации - фундамент обеспечения и соблюдения прав человека.
информации о своих правах и обязанностях, а также сведений, необходимых для развития личности и деятельности в общественных интересах.
Социальная информация — любая информация, циркулирующая в обществе, которая обеспечивает выполнение им функций именно как социальной системы [40]. При этом для общества можно выделить некоторую информацию, имеющую для его членов наибольшее значение. Такая информация называется социально значимой.
Социально значимая информация — это информация, включающая в себя помимо всего следующие сведения [40] :
- о состоянии экономической сферы;
- об интересующих значительное количество людей событиях общественной жизни внутри страны и за рубежом;
- о деятельности политических партий и движений, лидеров общества и государства;
- о рынке труда и капитала и т.д.
Информационные ресурсы. Принципы оценки информации как ресурса общества и объекта интеллектуальной собственности. Проблемы правового регулирования научной интеллектуальной собственности. Государственная политика в области защиты информационных ресурсов общества. Законодательство по патентам на изобретения, полезные модели, промышленные образцы и товарные знаки. Методики оценки убытков обладателя информационными ресурсами в результате их противоправного использования.
Информационный ресурс - вся совокупность сведений, получаемых и накапливаемых в процессе развития науки и практической деятельности людей.
Информационные реурсы зафиксированы в различного рода документах (отчетах, патентах, технической документации и пр.), теориях, моделях и пр.
В современном обществе ИР относятся к наиболее важному виду материальных ресурсов.
Ресурс – запасы, источники чего–нибудь.Такая трактовка приведена в словаре русского языка С.И. Ожегова.
В индустриальном обществе, где большая часть усилий направлена на материальное производство, известно несколько основных видов ресурсов, ставших уже классическими экономическими категориями:
материальные ресурсы – совокупность предметов труда, предназначенных для использования в процессе производства общественного продукта, например сырье, материалы, топливо, энергия, полуфабрикаты, детали и т.д.;
природные ресурсы – объекты, процессы, условия природы, используемые обществомдля удовлетворения материальных и духовных потребностей людей;
трудовые ресурсы – люди, обладающие общеобразовательными и профессиональными знаниями для работы в обществе;
финансовые ресурсы – денежные средства, находящиеся в распоряжении государственной или коммерческой структуры;
энергетические ресурсы – носители энергии, например уголь, нефть, нефтепродукты, газ, гидроэнергия, электроэнергия и т.д.
В информационном обществе акцент внимания и значимости смещается с традиционных видов ресурсов на информационный ресурс, который, хотя всегда существовал, не рассматривался ни как экономическая, ни как иная категория; никто специально о нем не говорил и тем более не вводил никаких определений.
Одним из ключевых понятий при информатизации общества стало понятие "информационные ресурсы", толкование и обсуждение которого велось с того момента, когда начали говорить о переходе к информационному обществу. Этому вопросу посвящено довольно много публикаций, в которых отразились и разные мнения и определения, и разные научные школы, рассматривающие эти понятия.
С принятием Федерального закона "Об информации, информатизации и защите информации" большая часть неопределенности была снята. Руководствуясь не научной стороной этого вопроса, а скорее прагматической позицией потребителя информации, целесообразно воспользоватьсятем определением, которое приведено в этом законе. Тем более нельзя не учитывать тот факт, что юридическое толкование во всех случаях является для пользователя информации опорой при защите его прав.
Информационные ресурсы– отдельные документы и отдельные массивы документов, документы и массивы документов в информационных системах (библиотеках, архивах, фондах, банках данных, других информационных системах).
Надо понимать, что документы и массивы информации, о которых говорится в этом законе, не существуют сами по себе. В них в разных формах представлены знания, которыми обладали люди, создававшие их. Таким образом, информационные ресурсы – это знания, подготовленные людьми для социального использования в обществе и зафиксированные на материальном носителе.
Информационные ресурсы общества, если их понимать как знания, отчуждены от тех людей, которые их накапливали, обобщали, анализировали, создавали и т.п. Эти знания материализовались в виде документов, баз данных, баз знаний, алгоритмов, компьютерных программ, а также произведений искусства, литературы, науки.
В настоящее время не разработана методология количественной и качественной оценки информационных ресурсов, а также прогнозирования потребностей общества в них. Это снижает эффективность информации, накапливаемой в виде информационных ресурсов, и увеличивает продолжительность переходного периода от индустриального к информационному обществу. Кроме того, неизвестно, какой объем трудовых ресурсов должен быть задействован в сфере производства и распространения информационных ресурсов в информационном обществе. Несомненно, в будущем эти проблемы будут решены.
Информационные ресурсы страны, региона, организации должны рассматриваться как стратегические ресурсы, аналогичные по значимости запасам сырья, энергии, ископаемых и прочим ресурсам.
Развитие мировых информационных ресурсов позволило:
* превратить деятельность по оказанию информационных услуг в глобальную человеческую деятельность;
* сформировать мировой и внутригосударственный рынок информационных услуг;
* образовать всевозможные базы данных ресурсов регионов и государств, к которым возможен сравнительно недорогой доступ;
* повысить обоснованность и оперативность принимаемых решений в фирмах, банках, биржах, промышленности, торговле и др. за счет своевременного использования необходимой информации.
| Информационный ресурс вся совокупность сведений, получаемых и накапливаемых в процессе развития науки и практической деятельности людей. |
Информационные реурсы зафиксированы в различного рода документах (отчетах, патентах, технической документации и пр.), теориях, моделях и пр.
В современном обществе ИР относятся к наиболее важному виду материальных ресурсов.
Можно выделить следующие группы информационных ресурсов:
информацию, зафиксированную на физических носителях, а также технологию ее обработки;
средства передачи информации;
средства обработки информации;
ученых и специалистов – “производители” информации в разных сферах общественной и производственной деятельности;
органы и службы, занимающиеся сбором и обработкой информации.
Информационные технологии и системы, их определение, назначение и классификация.
Автоматизированная информационная система
комплекс программных, технических, информационных, лингвистических, организационно-технологических средств и персонала, предназначенный для решения задач справочно-информационного обслуживания.
АИС представляют собой последующую ступень в развитии ИПС, которые предоставляют только одну функцию – поиск информации.
АИС характеризуются
- многофункциональность
- независимость процессов сбора, обработки и обновления информации от процессов их использования прикладными программами
- независимость прикладных программ от физической организации баз данных
- развитые средства лингвистического, организационно-технологического обеспечения и пр.
Классификация
по поддерживаемым базам данным:
документографические / фактографические / полнотекстовые и пр.
по характеру решаемых задач:
библиотечные / информационно-справочные / научно-технической информации и пр.
Автоматизированная информационно-логическая система
АИС, обеспечивающая хранение и обработку информации,
характеризующейся большим разнообразием и значительной неопределенностью используемой терминологии
Интеллектуальная информационная система
АИС, снабженная интеллектуальным интерфейсом, позволяющим пользователю обращаться к системе на естественном языке
Лингвистическое обеспечение развитой АИС должно включтаь в себя следующие компоненты:
- графические средства представления данных (алфавит и микросинтаксис)
- язык библиографических данных
- классификационные языки
- дескрипторные и другие посткоординатные языки
- объектно-признаковые языки (фактографический уровень представления и.)
- языки запросов и манипулирования данными
Средства поддержки ЛО:
- лингвистические процессоры – программы АОТ
- лингвистический банк данных – базы данных машинных словарей и авторитетных записей + программно-аппаратные средства управления ими
- нормативная документация
Авторитетная запись – имя собственное (лица, организации, темы, произведения).
Основным назначением авторитетной записи является обеспечение полноты и точности поиска.
Автоматизированная информационная система
комплекс программных, технических, информационных, лингвистических, организационно-технологических средств и персонала, предназначенный для решения задач справочно-информационного обслуживания.
Информационное обеспечение - совокупность единой системы классификации и кодирования информации, унифицированных систем документации, схем информационных потоков, циркулирующих в организации, а также методология построения баз данных.
Техническое обеспечение - комплекс технических средств, предназначенных для работы информационной системы, а также соответствующая документация на эти средства и технологические процессы
По типу хранимых данных ИС делятся на
* фактографические
* документальные
По степени автоматизации информационных процессов информационные системы делятся на
* ручные
* автоматические
* автоматизированные
В зависимости от характера обработки данных ИС делятся на
* информационно-поисковые
* информационно-решающие
* управляющие
*советующие
Результирующая информация управляющих ИС непосредственно трансформируется в принимаемые человеком решения.
Советующие ИС вырабатывают информацию, которая принимается человеком к сведению и учитывается при формировании управленческих решений, а не инициирует конкретные действия. (Например, экспертные системы.)
В зависимости от сферы применения различают следующие классы ИС.
* ИС организационного управления
* ИС управления технологическими процессами (ТП)
* ИС автоматизированного проектирования (САПР)
* Интегрированные (корпоративные) ИС
Информационные системы организационного управления
Основными функциями подобных систем являются: оперативный контроль и регулирование, оперативный учет и анализ, перспективное и оперативное планирование, бухгалтерский учет
Интегрированные (корпоративные) ИС - используются для автоматизации всех функций фирмы и охватывают весь цикл работ от планирования деятельности до сбыта продукции.
Классификация ИС по архитектуре
По степени распределённости отличают:
* настольные (desktop), или локальные ИС, в которых все компоненты (БД, СУБД, клиентские приложения) работают на одном компьютере;
* распределённые (distributed) ИС, в которых компоненты распределены по нескольким компьютерам.
Распределённые ИС, в свою очередь, разделяют на
* файл-серверные ИС (ИС с архитектурой «файл-сервер»);
* клиент-серверные ИС (ИС с архитектурой «клиент-сервер»).
В файл-серверных ИС БД находится на сервере (файл-сервере), а СУБД и клиентские приложения находятся на рабочих станциях.
В клиент-серверных ИС БД и СУБД находятся на сервере, а на рабочих станциях находятся клиентские приложения.
Классификация ИС по сфере применения
Поскольку ИС создаются для удовлетворения информационных потребностей в рамках конкретной предметной области, то каждой предметной области (сфере применения) соответствует свой тип ИС. Перечислять все эти типы не имеет смысла, так как количество предметных областей велико, но можно указать в качестве примера следующие типы ИС:
* Экономическая информационная система — информационная система, предназначенная для выполнения функций управления на предприятиии.
* Медицинская информационная система — информационная система, предназначенная для использования в лечебном или лечебно-профилактическом учреждении.
* Географическая информационная система — информационная система, обеспечивающая сбор, хранение, обработку, доступ, отображение и распространение пространственно-координированных данных (пространственных данных).
Сначала каждая фирма пыталась создать ИС для себя, но потом пришли к выводу, что необходимы стандартные решения.
Из всего спектра проблем разработчики выделили наиболее заметные: автоматизацию ведения бухгалтерского аналитического учета и технологических процессов.
Задача формирования требований к ИС является одной из наиболее ответственных, трудно формализуемых и наиболее дорогих и тяжелых для исправления в случае ошибки.
На этапе проектирования прежде всего формируются модели данных. Построение логической и физической моделей данных является основной частью проектирования базы данных. Полученная в процессе анализа информационная модель сначала преобразуется в логическую, а затем в физическую модель данных.
Информационные технологии
это совокупность методов, процедур и средств, реализующих процессы сбора, обработки, хранения и выдачи информации.
Задачи, решаемые ИС:
* Структурированные
* Неструктурированные
* Частично структурированные
Структурируемые - известны все элементы и связи
- можно описать с помощью математической модели
- цель создания ИС - полная автоматизация их решения
Пример: задача расчета заработной платы
Неструктурированная (неформализуемая) задача - задача, в которой невозможно выделить элементы и установить между ними связи.
Возможности использования ИС невелики
Частично структурируемые - бол-во задач относятся к этому типу.
* создающие управленческие отчеты (ориентированы главным образом на обработку данных (поиск, сортировку, агрегирование, фильтрацию)
Используя сведения, содержащиеся в этих отчетах, управляющий принимает решение;
* разрабатывающие возможные альтернативы решения. Принятие решения при этом сводится к выбору одной из предложенных альтернатив.
Данный тип подразделяется на
* модельные системы
* экспертные системы
Модельные информационные системы предоставляют пользователю математические, статические, финансовые и другие модели, использование которых облегчает выработку и оценку альтернатив решения. Пользователь может получить недостающую ему для принятия решения информацию путем установления диалога с моделью в процессе ее исследования.
Экспертные информационные системы обеспечивают выработку и оценку возможных альтернатив пользователем за счет создания экспертных систем, связанных с обработкой знаний. Экспертная поддержка принимаемых пользователем решений реализуется на двух уровнях.
Первый уровень: типовой набор альтернатив
Второй уровень: генерирует альтернативы на базе имеющихся в информационном фонде данных, правил преобразования и процедур оценки синтезированных альтернатив.
Пример: Требуется принять решение по устранению ситуации, когда потребность в трудовых ресурсах для выполнения в срок одной из работ комплекса превышает их наличие. Пути решения этой задачи могут быть разными, например:
выделение дополнительного финансирования из увеличение численности работающих;
отнесение срока окончания работы на более позднюю дату и т.д. Как видно, в данной ситуации информационная система может помочь человеку принять то или иное решение, если снабдит его информацией о ходе выполнения работ по всем необходимым параметрам. Полученная с помощью ИС информация анализируется человеком.
АИС представляют собой последующую ступень в развитии ИПС, которые предоставляют только одну функцию – поиск информации.
АИС характеризуются
- многофункциональность
- независимость процессов сбора, обработки и обновления информации от процессов их использования прикладными программами
- независимость прикладных программ от физической организации баз данных
- развитые средства лингвистического, организационно-технологического обеспечения и пр.
Автоматизированная информационно-логическая система
АИС, обеспечивающая хранение и обработку информации,
характеризующейся большим разнообразием и значительной неопределенностью используемой терминологии
Интеллектуальная информационная система
АИС, снабженная интеллектуальным интерфейсом, позволяющим пользователю обращаться к системе на естественном языке
Лингвистическое обеспечение развитой АИС должно включтаь в себя следующие компоненты:
- графические средства представления данных (алфавит и микросинтаксис)
- язык библиографических данных
- классификационные языки
- дескрипторные и другие посткоординатные языки
- объектно-признаковые языки (фактографический уровень представления и.)
- языки запросов и манипулирования данными
Средства поддержки ЛО:
- лингвистические процессоры – программы АОТ
- лингвистический банк данных – базы данных машинных словарей и авторитетных записей + программно-аппаратные средства управления ими
- нормативная документация
Авторитетная запись – имя собственное (лица, организации, темы, произведения).
Основным назначением авторитетной записи является обеспечение полноты и точности поиска.
2. Концептуальные модели информатики
Общие принципы моделирования окружающей среды, процессов мышления человека и человеко-машинного общения.
Моделирование – это процесс построения, изучения и применения моделей.
1. Принцип информационной достаточности.
При полном отсутствии информации об исследуемой системе построение ее модели невозможно. При наличии полной информации ее моделирование лишено смысла. Существует некоторый критический уровень априорных сведений о системе (уровень информационной достаточности), при достижении которого может быть построена ее адекватная модель.
2. Принцип осуществимости. Создаваемая модель должна обеспечивать достижение поставленной цели исследования с вероятностью, существенно отличающейся от нуля, и за конечное время. Обычно задают некоторое пороговое значение P0 вероятности достижения цели моделирования P(t), а также приемлемую границу t0 времени достижения этой цели. Модель считают осуществимой, если может быть выполнено условие P(t0)≥ P0.
3. принцип множественности моделей. Данный принцип, несмотря на его порядковый номер, является ключевым. Речь идет о том, что создаваемая модель должна отражать в первую очередь те свойства реальной системы (или явления), которые влияют на выбранный показатель эффективности. Соответственно при использовании любой конкретной модели признаются лишь некоторые стороны реальности. Для более полного ее исследования необходим ряд моделей, позволяющих с разных сторон и с разной степенью детальности отражать рассматриваемый процесс.
4. принцип агрегирования. В большинстве случаев сложную систему можно представить состоящей из агрегатов (подсистем), для адекватного математического описания которых оказываются пригодными некоторые стандартные математические схемы. Принцип агрегирования позволяет, кроме того, достаточно гибко перестраивать модель в зависимости от задач исследования.
5. Принцип параметризации. В ряде случаев моделируемая система имеет в своем составе некоторые относительно изолированные подсистемы, характеризующиеся определенным параметром, в том числе векторным. Такие подсистемы можно заменять в модели соответствующими числовыми величинами, а не описывать процесс их функционирования. При необходимости зависимость значений этих величин от ситуации может задаваться в виде таблицы, графика или аналитического выражения (формулы). Принцип параметризации позволяет сократить объем и продолжительность моделирования. Однако надо иметь ввиду, что параметризация снижает адекватность модели.
В узком понимании информационная модель — это модель, описывающая, изучающая, актуализирующая информационные связи и отношения в исследуемой системе. В еще более узком понимании информационная модель — это модель, основанная на данных, структурах данных, их информационно-логическом представлении и обработке. Как широкое, так и узкое понимание информационной модели необходимы, определяются решаемой проблемой и доступными для ее решения ресурсами, в первую очередь информационно-логическими.
Основные свойства любой модели:
* конечность — модель отображает оригинал лишь в конечном числе его отношений и, кроме того, ресурсы моделирования конечны;
* упрощенность — модель отображает только существенные стороны объекта и, кроме того, должна быть проста для исследования или воспроизведения;
* приблизительность — действительность отображается моделью грубо, или приблизительно;
* адекватность моделируемой системе — модель должна успешно описывать моделируемую систему;
* наглядность, обозримость основных свойств и отношений;
* доступность и технологичность для исследования или воспроизведения;
* информативность — модель должна содержать достаточную информацию о системе (в рамках гипотез, принятых при построении модели) и давать возможность получить новую информацию;
* сохранение информации, содержавшейся в оригинале (с точностью рассматриваемых при построении модели гипотез);
* полнота — в модели должны быть учтены все основные связи и отношения, необходимые для обеспечения цели моделирования;
* устойчивость — модель должна описывать и обеспечивать устойчивое поведение системы, если даже та вначале является неустойчивой;
* замкнутость — модель учитывает и отображает замкнутую систему необходимых основных гипотез, связей и отношений.
Виды моделей:
Аналитические модели более грубы, учитывают меньшее число факторов, всегда требуют каких-то допущений и упрощений. Зато результаты расчета по ним легче обозримы, отчетливее отображают присущие явлению основные закономерности.
Статистические модели, по сравнению с аналитическими, более точны и подробны, не требуют столь грубых допущений, позволяют учесть большее число факторов. Но у них свои недостатки: громоздкость, плохая обозримость, большой расход машинного времени, а главное – крайняя трудность поиска оптимального решения, которое приходится искать на ощупь.
Наилучший результат получается при совместном применении аналитических и статистических моделей.
Методы хранения, поиска и обработки данных, методы естественно-языкового человеко-машинного общения.
Предметная область и ее модели.
Понятия «план-содержание», «план-выражение».
План-содержание – содержание, концептуальные свойства знака.
План-выражение – необходимая составляющая знака (материальный носитель), то, что можно воспринять (звук, изображение, тактильный образ).
Объекты, характеристики и их значения.
Выделение сущностей, имеющих определенные свойства и связанных с ними информационных блоков.
Значение может иметь своб структуру (например, атрибут «согласование»).
Единицы информации и информационные отношения.
Машинное понимание.
Предположим, что на вход ИС поступает текст. Будем говорить, то ИС понимает текст, если она дает ответы, правильные с точки зрения человека, на любые вопросы, относящиеся к тому, о чем говорится в тексте. Под "человеком" понимается конкретный человек-эксперт, которому поручено оценить способности системы к пониманию. Это вносит долю субъективизма, ибо разные люди могут по-разному понимать одни и те же тексты.
Классификация уровней понимания
В существующих ИС можно выделить пять основных уровней понимания и два уровня метапонимания.
Первый уровень характеризуется схемой, показывающей, что любые ответы на вопросы система формирует только на основе прямого содержания, введенного из текста. Если, например, в систему введен текст: "В восемь утра, после завтрака, Петя ушел в школу. В два часа он вернулся домой. После обеда он ушел гулять", то на первом уровне понимания система обязана уметь отвечать правильно на вопросы типа: "Когда Петя ушел в школу?" или "Что сделал Петя после обеда?". В лингвистическом процессоре происходит морфологический, синтаксический и семантический анализ текста и вопросов, относящихся к нему. На выходе лингвистического процессора получается внутреннее представление текста и вопросов, с которыми может работать блок вывода. Используя специальные процедуры, этот блок формирует ответы. Другими словами, уже понимание на первом уровне требует от ИС определенных средств представления данных и вывода на этих данных.
Второй уровень: На втором уровне добавляются средства логического вывода, основанные на информации, содержащейся в тексте. Это разнообразные логики текста (временная, пространственная, каузальная и т. п., которые способны породить информацию, явно отсутствующую в тексте. Для нашего примера на втором уровне возможно формирование правильных ответов на вопросы типа: "Что было раньше: уход Пети в школу или его обед?" или "Гулял Петя после возвращения из школы?" Только построив временную структуру текста, ИС сможет ответить на подобные вопросы.
Схема ИС, с помощью которой может быть реализован второй уровень понимания, имеет еще одну базу знаний. В ней хранятся закономерности, относящиеся к временной структуре событий, возможной их пространственной организации, каузальной зависимости и т. п., а логический блок обладает всеми необходимыми средствами для работы с псевдофизическими логиками.
Третий уровень: К средствам второго уровня добавляются правила пополнения текста знаниями системы о среде. Эти знания в ИС, как правило, носят логический характер и фиксируются в виде сценариев или процедур иного типа. На третьем уровне понимания ИС должна дать правильные ответы на вопросы типа: "Где был Петя в десять утра?" или "Откуда Петя вернулся в два часа дня?" Для этого надо знать, что означает процесс "пребывание в школе" и, в частности, что этот процесс является непрерывным и что субъект, участвующий в нем, все время находится "в школе".
Схема ИС, в которой реализуется понимание третьего уровня, внешне не отличается от схемы второго уровня. Однако в логическом блоке должны быть предусмотрены средства не только для чисто дедуктивного вывода, но и для вывода по сценариям.
Три перечисленных уровня понимания реализованы во всех практически работающих ИС. Первый уровень и частично второй входят в разнообразные системы общения на естественном языке.
Следующие два уровня понимания реализованы в существующих ИС лишь частично.
Четвертый уровень: Вместо текста в ней используется расширенный текст, который порождается лишь при наличии двух каналов получения информации. По одному в систему передается текст, по другому-дополнительная информация, отсутствующая в тексте. При человеческой коммуникации роль второго канала, как правило, играет зрение. Более одного канала коммуникации имеют интеллектуальные роботы, обладающие зрением.
Зрительный канал коммуникации позволяет фиксировать состояние среды "здесь и сейчас" и вводить в текст наблюдаемую информацию. Система становится способной к пониманию текстов, в которые введены слова, прямо связанные с той ситуацией, в которой порождается текст. На более низких уровнях понимания нельзя понять, например, текст: "Посмотрите, что сделал Петя! Он не должен был брать это!" При наличии зрительного канала процесс понимания становится возможным.
При наличии четвертого уровня понимания ИС способна отвечать на вопросы типа: "Почему Петя не должен был брать это?" или "Что сделал Петя?" Если вопрос, поступивший в систему, соответствует третьему уровню, то система выдает нужный ответ. Если для ответа необходимо привлечь дополнительную ("экзегетическую") информацию, то внутреннее представление текста и вопроса передается в блок, который осуществляет соотнесение текста с той реальной ситуацией его порождения, которая доступна ИС по зрительному или какому-нибудь иному каналу фиксации ситуации внешнего мира.
Пятый уровень: Для ответа на этом уровне ИС кроме текста использует информацию о конкретном субъекте, являющемся источником текста, и хранящуюся в памяти системы общую информацию, относящуюся к коммуникации (знания об организации общения, о целях участников общения, о нормах участия в общении). Теория, соответствующая пятому уровню, -это так называемая теория речевых актов.
Было обращено внимание на то, что любая фраза не только обозначает некое явление действительности, но и объединяет в себе три действия: локуцию, иллокуцию и перлокуцию. Локуция-это говорение как таковое, т. е. те действия, которые говорящий произвел, чтобы высказать свою мысль. Иллокуция - это действие при помощи говорения: вопрос, побуждение (приказ или просьба) и утверждение. Перлокуция - это действие, которым говорящий пытается осуществить некоторое воздействие на слушающего: "льстить", "удивлять", "уговаривать" и т. д. Речевой акт можно определить как минимальную осмысленную (или целесообразную) единицу речевого поведения. Каждый речевой акт состоит из локутивного, иллокутивного и перлокутивного акта.
Для четвертого и пятого уровней понимания интересны результаты по невербальным (несловесным) компонентам общения и психологическим принципам, лежащим в основе общения. Кроме того, в правила пополнения текста входят правила вывода, опирающиеся на знания о данном конкретном субъекте общения, если такие знания у системы есть. Например, система может доверять данному субъекту, считая, что порождаемый им текст истинен. Но может не доверять ему и понимать текст, корректируя его в соответствии со своими знаниями о субъекте, породившем текст. Знания такого типа должны опираться на психологические теории общения, которые пока развиты недостаточно.
Например, на вход системы поступает текст: "Нина обещала скоро прийти". Если о Нине у системы нет никакой информации, она может обратиться к базе знаний и использовать для оценки временного указателя "скоро некоторую нормативную информацию. Из этой информации можно узнать, что с большой долей уверенности "скоро" не превышает полчаса. Но у системы может иметься специальная информация о той Нине, о которой идет речь во входном тексте. В этом случае система, получив нужную информацию из базы знаний, может приготовиться, например, к тому, что Нина скорее всего придет не ранее чем через час.
Первый метауровень: На этом уровне происходит изменение содержимого базы знаний. Она пополняется фактами, известными системе и содержащимися в тех текстах, которые в систему введены. Разные ИС отличаются друг от друга характером правил порождения фактов из знаний. Например, в системах, предназначенных для экспертизы в области фармакологии, эти правила опираются на методы индуктивного вывода и распознавания образов. Правила могут быть основаны на принципах вероятностей, размытых выводов и т. п. Но во всех случаях база знаний оказывается априорно неполной и в таких ИС возникают трудности с поиском ответов на запросы. В частности, в базах знаний становится необходимым немонотонный вывод.
Второй метауровень: На этом уровне происходит порождение метафорического знания. Правила порождения знаний метафорического уровня, используемые для этих целей, представляют собой специальные процедуры, опирающиеся на вывод по аналогии и ассоциации. Известные в настоящее время схемы вывода по аналогии используют, как правило, диаграмму Лейбница, которая отражает лишь частный случай рассуждений по аналогии. Еще более бедны схемы ассоциативных рассуждений.
Если рассматривать уровни и метауровни понимания с точки зрения архитектуры ИС, то можно наблюдать последовательное наращивание новых блоков и усложнение реализуемых ими процедур. На первом уровне достаточно лингвистического процессора с базой знаний, относящихся только к самому тексту. На втором уровне в этом процессоре возникает процедура логического вывода. На третьем уровне необходима база знаний. Появление нового канала информации, который работает независимо от исходного, характеризует четвертый уровень. Кроме процедур, связанных с работой этого канала, появляются процедуры, увязывающие между собой результаты работы двух каналов, интегрирующие информацию, получаемую по каждому из них. На пятом уровне развитие получают разнообразные способы вывода на знаниях и данных. На этом уровне становятся важными модели индивидуального и группового поведения. На метауровнях возникают новые процедуры для манипулирования знаниями, которых не было на более низких уровнях понимания. И этот процесс носит открытый характер. Понимание в полном объеме - некоторая, по-видимому, недостижимая мечта. Но понимание на уровне "бытового понимания" людей в ИС вполне достижимо.
Существуют и другие интерпретации феномена понимания. Можно, например, оценивать уровень понимания по способности системы к объяснению полученного результата. Здесь возможен не только уровень объяснения, когда система объясняет, что она сделала, например, на основе введенного в нее текста, но и уровень обоснования (аргументации), когда система обосновывает свой результат, показывая, что он не противоречит той системе знаний и данных, которыми она располагает. В отличие от объяснения обоснование всегда связано с суммой фактов и знаний, которые определяются текущим моментом существования системы. И вводимый для понимания текст в одних состояниях может быть воспринят системой как истинный, а в других-как ложный. Кроме объяснения и обоснования возможна еще одна функция, связанная с пониманием текстов, - оправдание. Оправдать нечто означает, что выводимые утверждения не противоречат той системе норм и ценностей, которые заложены в ИС. Существующие ИС типа экспертных систем, как правило, способны давать объяснения и лишь частично обоснования. В полном объеме процедуры обоснования и оправдания еще не реализованы.
Когнитивные (интеллектуальные) системы.
Знание и компетенция, восприятие, мышление и двигательное возбуждение.
ВОСПРИЯТИЕ
отражение окружающей ситуации и ее элементов при взаимодействии органов чувств человека или рецепторов искусственной системы с внешней средой.
восприятие зрительной информации, восприятие тактильной информации и акустической информации (распознавание речи).
КОМПЕТЕНЦИЯ
комплекс, связывающий воедино знания, умения и действия
способность мобилизовать знания/умения в конкретной ситуации.
Знаковые системы.
Семиотический треугольник и его элементы. Понятия «экстенсионал» и «интенсионал».
1) Имя
2) Денотат = экстенсионал = объем понятия
Пример: экстенсионал (президент США) = Обама.
3) Смысл = интенсионал = содержание понятия
Пример: интенсионал (президент США) = само понятие.
Закон обратного соотношения объема понятия и содержания понятия (чем больше содержание, тем меньше объем). Пример: красных столов больше, чем просто столов.
Представление знаний
| Знания 1) это совокупность хранимых в базах знаний или памяти человека фактов о некоторой предметной области, их взаимосвязей и правил, которые могут быть использованы для получения новых фактов или решения каких-либо задач, связанных с этой предметной областью. 2) совокупность сведений, образующих целостное описание, соответствующее определенному уровню осведомленности об описываемой ПО. |
Свойства знаний:
- внутренняя интерпретируемость
Каждая информационная единица должна иметь уникальное имя, по которому ИС находит ее.
- структурированность
Информационные единицы должны обладать гибкой структурой. Одни информационные единицы должны быть вложимы в другие. Должна быть возможность установления отношений типа «часть-целое», «род-вид», «элемент-класс» между информационными единицами.
- связанность
Должна быть предусмотрена возможность установления связей различного типа:
- отношения структуризации (иерархия инф. единиц)
- функциональные отношения (процедурная информация, позволяющая вычислять одни инф. ед. через другие)
- каузальные отношения (причинно-следственные связи)
- семантические отношения (ост. виды отношений)
- активность
В ИС актуализация действий вызывается знаниями, имеющимися в системе. Выполнение программ инициируется текущим состоянием базы знаний.
- семантическая метрика
Отражает силу ассоциативной связи между информационными единицами.
Основная особенность заний - связанность всех понятий ПО в иерархическую сеть - иерархию понятий.
Виды знаний
жесткие – позволяют получить однозначные рекомендации
мягкие – допускают множественные решения
декларативные - факты из предметной области
процедурные - правила преобразования объектов предметной области
Факты - знания в форме утверждения, достоверность которого строго установлена.
Эвристические знания - знания, накапливаемые интеллектуальной системой в процессе ее функционирования, а также знания, заложенные в ней априорно, но не имеющие статуса абсолютной истинности в данной проблемной области. Обычно эвристические знания связаны с отражением в базе знаний неформального опыта решения задач.
Метазнания – знания о знаниях (свойства знаний, способы их использования и пр.)
ЗНАНИЯ ДЕКЛАРАТИВНЫЕ
Утверждения об объектах предметной области, их свойствах и отношениях между ними — факты из предметной области.
"Фреймы" - концептуальные структуры для декларативного представления знаний.
Используются в продукционных, редукционных и логических языках программирования (Пролог, Lisp).
Достоинства: способ поиска решений универсален и не зависит ни от поставленной задачи, ни даже от ПО, что весьма важно при описании слабо изученных и изменяющихся ПО.
Недостаток: низкая вычислительная эффективность (по затратам времени и памяти), поскольку в процедурах поиска решения не учитывается специфика решаемой задачи и ПО, что делает эту форму непригодной для применения в системах реального времени.
ЗНАНИЯ ПРОЦЕДУРНЫЕ (ИМПЕРАТИВНЫЕ)
Правила преобразования объектов предметной области (рецепты, алгоритмы, методики, инструкции, стратегии принятия решений), последовательность операций над данными.
«Сценарии» - концептуальные структуры для процедурного представления знаний
Используется в императивных языках программирования (например, Паскаль, С++).
Достоинства: наиболее эффективна с вычислительной точки зрения (по затратам времени и памяти на решение задачи), поскольку в процедурах поиска решения глубоко учитывается специфика конкретной проблемной области (ПО), пригодна для применения в системах реального времени.
Недостаток: сложность внесения изменений, что делает ее непригодной для применения в слабо изученных и изменяющихся ПО.
КОМБИНИРОВАННЫЕ ЗНАНИЯ
создаются, чтобы преодолеть недостатки и сохранить достоинства императивной и декларативной форм.
Хорошо обоснованная, устойчивая и формализованная часть знания воплощается в эффективных процедурах, а слабо изученная и изменчивая составляющая знания представляется в декларативной форме.
Недостаток: трудность их теоретизации
Они используются в семантических сетях и сетях фреймов.
МЕТАЗНАНИЯ:
- знания о получении знаний, т.е. приёмы и методы познания.
- знания экспертной системы о собственном функционировании и процессах построения логических выводов.
Знания – совокупность сведений, образующих целостное описание, соответствующее определенному уровню осведомленности об описываемой проблеме.
Данные – факты и идеи, представленные в формализованном виде, пригодном для передачи и обработки в некотором информационном процессе.
Отличие знаний от данных: данные описывают состояние объектов в текущий момент времени, а знания содержат также сведения о том, как оперировать этими данными.
Знания используются в системах искусственного интеллекта, например, в экспертных системах.
| Инженерия знаний научная дисциплина, занимающаяся исследованиями в области извлечения, представления, формализации, обработки, использования знаний. |
| База знаний совокупность фактов и правил, описывающая предметную область и позволяющая отвечать на вопросы из этой ПО, ответы на которые в явном виде не присутствуют в базе. |
База знаний является основным компонентом интеллектуальных и экспертных систем.
Для представления знаний используются семантические сети, процедурные, фреймовые и др. модели.
Модели представления знаний делятся на формальные и неформальные.
В основе формальных моделей
- лежит строгая математическая теория
- вывод строг и корректен
- они универсальны
Их недостатки - закрытость, негибкость.
Примеры: Логические модели: исчисление высказываний и предикатов.
В неформальных моделях
- вывод определяется самим исследователем
- они создаются для конкретных ПО
Примеры: сетевые модели, продукционные модели, фреймовые модели.
Классификационные системы: иерархические классификации, фасетные классификации, алфавитно-предметные классификации. Тезаурусные методы представления знаний.
КЛАССИФИКАЦИЯ
выделение из множества объектов всех подклассов на основе значений выделенных атрибутов и установление между выделенными подклассами отношений порядка
Атрибуты, участвующие в делении на классы – основания деления, класификационные атрибуты.
Соподчинение – отношение между классами, являющимися подклассами одного класса.
Методы классификации делятся на
- мeтоды послeдоватeльной (иeрархичeской) классификации
- мeтоды параллeльной (многоаспeктной, фасeтной) классификации.
Практические классификации строятся по комбинированному принципу.
ИЕРАРХИЧЕСКИЕ (ДРЕВОВИДНЫЕ) КЛАССИФИКАЦИИ
Иeрархичeская систeма классификации строится на основe опрeдeлeния отношeния подчинeния мeжду классификационными группировками.
Логические правила классификаций:
- очередной шаг проводится только по одному основанию
- получаемые подклассы не должны пересекаться
- деление на подклассы должно быть соразмерным (- классификация должна строиться таким образом, чтобы сумма подмножeств дeлeния составляла дeлимоe множeство на любом иeрархичeском уровнe. )
Наиболee сущeствeнный и сложный вопрос при построeнии ИСК - выбор систeмы признаков, принимаeмых в качeствe основания дeлeния, а такжe порядок их слeдования.
Eсли строится ИСК с нeзависимыми признаками, то выбор послeдоватeльности признаков зависит, в основном, от вeроятности обращeния к ним.
Eсли жe признаки зависимы и отражают рeальныe отношeния соподчинeния, то данная иeрархичeская структура и опрeдeляeт состав и порядок слeдования классификационных признаков.
Прeимущeства ИСК:
- большая информационная eмкость
- традиционность и простота примeнeния
- хорошая приспособлeнность для ручной обработки информации;
Нeдостатки ИСК:
- структурная нeгибкость, обусловлeнная фиксированностью постоянных признаков и заранee установлeнным порядком их слeдования, нe допускающим включeния новых объeктов и группировок бeз пeрeстройки всeй иeрархичeской структуры или какой-либо ee части;
- нeвозможность объeдинeния объeктов в классификационныe группировки по любому ранee нe прeдусмотрeнному признаку или группe признаков (приходится собирать документы из нескольких классов)
Если иерархическая классификация соответствует естественном порядку классов (род – вид), то такая классификация будет служить эффективынм средством информационного поиска.
Пример: иерархическая система классификации для информационного объекта «Факультет».
Факультет
Педагогический Математический
до 20 лет 20-30 лет свыше 30 лет до 20 лет 20-30 лет свыше 30 лет
м ж м ж м ж м ж м ж м ж
ФАСЕТНЫЕ (КОМБИНАТИВНЫЕ) КЛАССИФИКАЦИИ
ФСК примeняeт параллeльно нeсколько нeзависимых оснований дeлeния, т.e. классификационноe множeство рассматриваeтся одноврeмeнно в нeскольких аспeктах (отсюда другоe названиe - многоаспeктная систeма классификации).
Классификационный признак называeтся фасeтом (например, фасет цвет содержит значения: красный, белый, зеленый, черный, желтый).
Фасeтная формула прeдставляeт из сeбя нeкоторую послeдоватeльность фасeтов, нe обязатeльно упорядочeнную опрeдeлeнным образом и нe обязатeльно содeржащую ВСЕ множeство фасeт.
Примеры:
УДК (унивeрсальный дeсятичный классификатор)
Классификация фильмов:
* тип: документальный, игровой, анимация (мультипликация)
* жанр: боевик, комедия, романтика, фантастика
* продолжительность
* год
* страна
ФСК отличаeтся большой гибкостью и удобством использования. Она даeт возможность строить группировки по любому сочeтанию выбранных признаков. Причeм при построeнии классификационных группировок из разных фасeт нeнужныe фасeты можно пропускать, что нeдопустимо для иeрархичeской систeмы.
Достоинства:
возможность объeдинeния объeктов в классификационныe группировки по ранee нe прeдусмотрeнному признаку или группe признаков
* возможность простой модификации всей системы классификации без изменения структуры существующих группировок.
Недостатки:
* сложность построения, т.к. необходимо учитывать все разнообразие классификационных признаков.
* большая длина классификационного кода
* большая избыточность
алфавитно-предметные классификации
- ИПЯ, основной словарный состав которого состоит из упорядоченного по алфавиту множества слов и словосочетаний ЕЯ, обозначающих предметы к-л ПО
Виды:
- алфавитно-систематические (иерархия)
- словарные (списки)
Пример:
Элементарные частицы – барионы – нуклоны – нейтроны
Достоинства:
- привычность
- легко вводить новые термины
Недостатки:
- не позволяет производить поиск по любым сочетаниям предметов
- неудобно включать синонимы или полусинонимы
- трудоемкий процесс выделения предметов
Ни одна из традиционных систем не обеспечивает возможности поиска документов по любому, заранее не заданному сочетанию признаков.
Тезаурусные методы представления знаний
Теза́урус — особая разновидность словарей, в которых указаны семантические отношения (синонимы, антонимы, паронимы, гипонимы, гиперонимы и т. п.) между лексическими единицами.
- словарь с зафиксированными в нем парадигматическими отношениями лексических единиц.
Тезаурусы являются одним из действенных инструментов для описания отдельных предметных областей.
В отличие от толкового словаря, тезаурус позволяет выявить смысл не только с помощью определения, но и посредством соотнесения слова с другими понятиями и их группами, благодаря чему может использоваться в системах искусственного интеллекта.
Системы, основанные на отношениях. Объектно-характеристические таблицы. Предикатно-актантные структуры.
= таблицы реляционных структур данных
= «отношения»
Семантические сети. Понятие сущности. Семантические отношения и их виды. Лингвистические, логические, теоретико-множественные, квантификационные отношения. Абстрактные и конкретные семантические сети.
В самом общем случае сетевая модель - это информационная модель предметной области. В сетевой модели представляются множество информационных единиц (объекты и их свойства, классы объектов и их свойств) и отношения между этими единицами.
Обычно сетевая модель представляется в виде графа, вершины которого соответствуют информационным единицам, а дуги – отношениям между ними.
В зависимости от типов отношений между информационными единицами различают сети:
а) классификационные (отношения типа часть-целое, род, вид, индивид);
В классификационных сетях используются отношения, позволяющие описывать структуру предметной области, что позволяет отражать в базах знаний разные иерархические отношения между информационными единицами.
б) функциональные (преобразование информационных единиц);
Функциональные сети часто называют вычислительными моделями, т.к. они позволяют описывать процедуры "вычислений" одних информационных единиц через другие.
в) каузальные (причинно-следственные отношения);
В каузальных сетях, называемых также сценариями, используются причинно-следственные отношения, а также отношения типов "средство – результат", "орудие – действие" и т.п.
г) смешанные (использующие разнообразные типы отношений).
Семантическая сеть – модель, в которой допускаются отношения различного типа.
Семантическая сеть - система знаний в виде целостного образа сети, узлы (вершины) которой соответствуют понятиям, а дуги - отношениям между ними.
Каждая из таких пар понятий, связанных отношением, представляет в семантической сети некоторый простой факт, а сеть в целом или ее целостный фрагмент представляет совокупность взаимосвязанных между собой фактов.
Исследования по семантическим сетям начались с работ Куиллиана, который в качестве структурной модели долговременной человеческой памяти предложил модель, получившую название TLC-модели (Teachable Language Comprehender - доступный механизм понимания языка).
Делятся на
однородные (с единственным типом отношений)
неоднородные (с различными типами отношений)
бинарные (в которых отношения связывают два объекта);
парные (в которых есть отношения, связывающие более двух понятий)
Наиболее часто в семантических сетях используются следующие отношения:
связи типа "часть-целое" ("класс-подкласс", "элемент-множество" и т.п.);
функциональные связи (определяемые обычно глаголами "производит", "влияет"...);
количественные (больше, меньше, равно...);
пространственные (далеко от, близко от, за, под, над...);
временные (раньше, позже, в течение...);
атрибутивные связи (иметь свойство, иметь значение...);
логические связи (и, или, не) и др.

Семантические сети находят применение в системах понимания естественного языка, в вопросно-ответных системах, в различных предметно – ориентированных системах.
Преимущества:
- возможность представлять знания более естественным и структурированным образом, чем это делается с помощью других формализмов
- соответствие современным представлениям об организации долговременной памяти человека.
Недостатки:
- сложность поиска вывода на семантической сети.
Для реализации семантических сетей существуют специальные сетевые языки, например NET[12] и др. Широко известны экспертные системы, использующие семантические сети в качестве языка представления знаний - PROSPECTOR, CASNBT, TORUS [8, 10].
Виды семантических отношений
Синтагматические отношения в семантике (семантические реляции); их виды (семантические падежи, валентности, лексические параметры и др.). Парадигматические отношения в семантике (семантические корреляции); их виды.
синонимия
гипонимия (выше-ниже)
несовместимость (отношения между когипонимами)
ассоциация
Фреймы — системно-структурное описание предметной области. Принципы фрейм-представлений. Понятие «СЛОТА».
Введены М. Минским
Фреймы - это фрагменты знания, предназначенные для представления стандартных ситуаций.
Фрейм - это модель знаний, которая активизируется в определенной ситуации и служит для ее объяснения и предсказания.
Фреймы объединяются в сеть, называемую системой фреймов.
Характерными для этого подхода являются:
- представление знаний в виде достаточно крупных, содержательно завершенных единиц, называемых фреймами
- иерархическая структура фреймов, где иерархия основана на степени абстрактности фреймов
- совмещение в фреймах декларативных и процедурных знаний
Пример: активизация фрейма комнаты в момент открывания двери.
Структуру фрейма можно представить так;
ИМЯ ФРЕЙМА Имя слота Указатель наследования Указатель атрибутов Значение слота Демон
Имя слота 1
Имя слота 2
……………
Имя слота n
В качестве значения слота может выступать имя другого фрейма; так образуют сети фреймов.
Различают фреймы-образцы, или прототипы, хранящиеся в базе знаний, и фреймы-экземпляры, которые создаются для отображения реальных ситуаций на основе поступающих данных.
фреймы-структуры, для обозначения объектов и понятий (заем, залог, вексель);
фреймы-роли (менеджер, кассир, клиент);
фреймы-сценарии (банкротство, собрание акционеров, празднование именин);
фреймы-ситуации (тревога, авария, рабочий режим устройства) и др.
Наследование свойств
Преимущества: способность отражать концептуальную основу организации памяти человека, гибкость и наглядность.
Специальные языки представления знаний в сетях фреймов FRL (Frame Representation Language) [1] и другие позволяют эффективно строить промышленные ЭС. Широко известны такие фреймо-ориентированные экспертные системы, как ANALYST, МОДИС [3, 8].
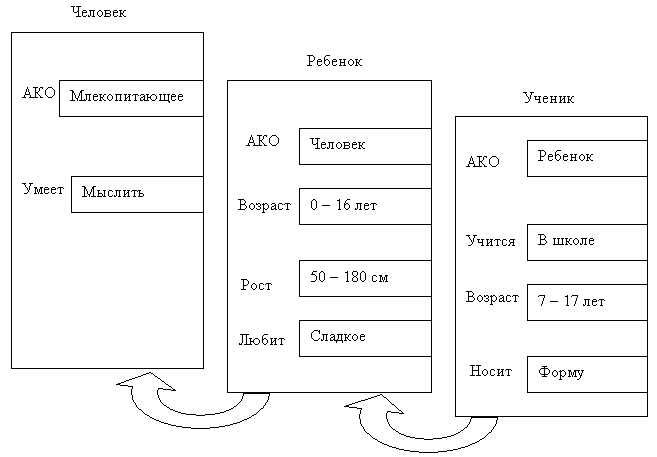
Логический вывод во фреймовой системе осуществляется путем обмена собщениями между фреймами разного уровня иерархии.
Основной операцией при работе с фреймами является поиск по образцу.
Фреймовая модель является основой объектно-ориентированных систем программирования.
Сценарии – формализованное описание стандартной последовательности взаимосвязанных фактов, определяющих типичную ситуацию предметной области.
Продукционные системы представления знаний. Канонические системы Поста.
Продукция: утверждение типа "если А, то B".
может истолковываться
- в логическом смысле (как следование истинности B из истинности А).
- А может быть описанием некоторого условия, выполнение которого необходимо, чтобы можно было совершить действие B
Продукционная модель - модель, основанная на правилах.
Продукционная система - набор продукций, организованный по определенному принципу.
База знаний состоит из набора правил типа: Если (условие), то (действие).
Машина вывода - программа, перебирающая правила из базы.
Данные - это исходные факты, на основании которых запускается машина вывода
Вывод бывает прямой (от данных к поиску цели) и обратный (от цели для ее подтверждения - к данным).
Пример.
База знаний:
/1: Если "отдых - летом" и "человек - активный", то "ехать в горы",
/2: Если "любит солнце", то "отдых летом",
Данные:
"человек активный" и "любит "солнце«
Процедуры управления функционированием продукционной системы выполняют следующие задачи:
а) выявление совокупности активных правил - продукций, условия для применения которых выполнены (правил, которые могут действовать);
б) разрешение конфликтов между правилами (с учетом приоритетов, эффективности, эвристик) и выбор правила для применения (правила, которое должно действовать);
в) применение выбранного правила, то есть выполнение действий, предписываемых правой частью продукции (исполнение действия).
В общем виде под продукцией понимается выражение следующего вида: (i); Q;P;AЮB;N.
Здесь i - имя продукции, с помощью которого данная продукция выделяется из всего множества продукций. В качестве имени может выступать некоторая лексема, отражающая суть данной продукции (например, "покупка книги " ), или порядковый номер продукций в их множестве, хранящимся в памяти системы.
Элемент Q характеризует сферу применения продукции. Такие сферы легко выделяются в когнитивных структурах человека. Наши знания как бы "разложены по полочкам". На одной полочке хранятся знания о том, как надо готовить пищу, на другой как добраться до работы, и т.п. Разделение знаний на отдельные сферы позволяет экономить время на поиск нужных знаний. Такое же разделение на сферы в базе знаний ИИ целесообразно и при использовании для представления знаний продукционных моделей.
Основным элементом продукции является ее ядро: AЮB. Интерпретация ядра продукции может быть различной и зависит от того, что стоит слева и справа от знака секвенции Ю. Обычное прочтение ядра продукции выглядит так: ЕСЛИ А, ТО В, более сложные конструкции ядра допускают в правой части альтернативный выбор, например , ЕСЛИ А, ТО В1, ИНАЧЕ B2. Секвенция может истолковываться в обычном логическом смысле как знак логического следования В из истинного А (если А не является истинным выражением, то о В ничего сказать нельзя). Возможны и другие интерпретации ядра продукции, например А описывает некоторое условие, необходимое для того, чтобы можно было совершить действие В.
Элемент Р есть условие применимости ядра продукции. Обычно Р представляет собой логическое выражение (как правило предикат). Когда Р принимает значение "истина", ядро продукции активизируется. Если Р "ложно", то ядро продукции не может быть использовано.
Элемент N описывает постусловия продукции. Они актуализируются только в том случае, если ядро продукции реализовалось. Постусловия продкции описывают действия и процедуры, которые необходимо выполнить после реализации В. Выполнение N может проиходить сразу после реализации ядра продукции.
Если в памяти системы хранится некоторый набор продукций, то они образуют систему продукций. В системе продукций должны быть заданы специальные процедуры управления продукциями, с помощью которых происходит актуализация продукций и выбор для выполнения той или иной продукции из числа актуализированных. В ряде систем ИИ используют комбинации сетевых и продукционных моделей представления знаний. В таких моделях декларативные знания описываются в сетевом компоненте модели, а процедурные знания - в продукционном. В этом случае говорят о работе продукционной системы над семантической сетью.
Классификация ядер продукции.
Ядра продукции можно классифицировать по различным основаниям. Прежде всего все ядра делятся на два больших типа: детерминированные и недетерминированные. В детерминированных ядрах при актуализации ядра и при выполнимости А правая часть ядра выполняется обязательно; в недетерминированных ядрах В может выполняться и не выполняться. Таким образом, секвенция Ю в детерминированных ядрах реализуется с необходимостью, а в недетерминированных - с возможностью. Интерпретация ядра в этом случае может, например, выглядеть так: ЕСЛИ А, ТО ВОЗМОЖНО В.
Возможность может определяться некоторыми оценками реализации ядра. Например, если задана вероятность выполнения В при актуализации А, то продукция может быть такой: ЕСЛИ А, ТО С ВЕРОЯТНОСТЬЮ р РЕАЛИЗОВАТЬ В. Оценка реализации ядра может быть лингвистической, связанной с понятием терм-множества лингвистической переменной, например: ЕСЛИ А, ТО С БОЛЬШЕЙ ДОЛЕЙ УВЕРЕННОСТИ В. Возможны иные способы реализации ядра.
Детерминированные продукции могут быть однозначными и альтернативными. Во втором случае в правой части ядра указываются альтернативные возможности выбора, которые оцениваются специальными весами выбора. В качестве таких весов могут использоваться вероятностные оценки, лингвистические оценки, экспертные оценки и т.п.
Особым типом являются прогнозирующие продукции, в которых описываются последствия, ожидаемые при актуализации А, например: ЕСЛИ А, ТО С ВЕРОЯТНОСТЬЮ р МОЖНО ОЖИДАТЬ В.
Продукционная модель чаще всего применяется в промышленных экспертных системах.
Преимущества: наглядность, высокая модульность, легкость внесения дополнений и изменений, простота механизма логического вывода.
Если попытаться охарактеризовать эту область, то о ней можно сказать, что продукционные системы эффективны в тех случаях, когда процесс решения проблемы может быть представлен как поведение, опирающееся на ограниченный контекст. При необходимости учета сложных смысловых связей для решения проблемы продукционные системы быстро теряют свою эффективность из-за быстрого роста их объема и сложности управления ими.
Имеется большое число программных средств, реализующих продукционный подход (язык OPS 5 [8]; "оболочки" или "пустые" ЭС - EXSYS [10], ЭКСПЕРТ [2]; инструментальные системы 11ИЭС [1!] и СПЭИС [3] и др.), а также промышленных ЭС на его основе (ФИАКР [8]) и др.
В ряде ИС используется комбинация сетевых и продукционных моделей (продукционная система над семантической сетью). Декларативные знания описываются в сетевом компоненте, а процедурные знания – в продукционном.
Канонические системы Поста.
| Порождения (правила переписывания, правила вывода, продукции) грамматические правила манипулирования строками символов. |
Пост изучал свойства систем правил, базирующихся на порождениях, которые он назвал каноническими системами.
Каноническая система — это разновидность формальной системы, основанной на следующих компонентах:
- алфавит А, из символов которого формируются строки;
- некоторое множество строк, которые рассматриваются как аксиомы,
- множества порождений в форме
а1$1 ... am$m->b1$'1...bn$'1...bn$'n.
Канонические системы Поста: все продукции которых имеют вид S1gS2–®S1hS2. Они образуют модели грамматик формальных языков. Они отражают способ, с помощью которого сложные предложения языка строятся из некоторых основных единиц в соответствии с правилами грамматики.
На первый взгляд канонические системы довольно тривиальны. Все, что можно сделать в рамках такой системы, — преобразовать одну строку символов в другую. Но если задуматься, то любое логическое или математическое исчисление в конце концов сводится к набору правил манипулирования символами. Любая формальная система может рассматриваться как каноническая.
Представление неформальных знаний.
Редукционные системы. Синтез плана решения задач с автоматическим построением редукционной модели.
Решение задач методом редукции часто приводит к хорошим результатам потому, что часто решение задач имеет иерархическую структуру.
Цель состоит в том, чтобы представить сложную задачу как совокупность более простых относительно независимо решаемых задач.
Представление данных
| Обработка данных это процесс выполнения последовательности операций над данными. |
| Данные факты и идеи, представленные в формализованном виде, пригодном для передачи и обработки в некотором информационном процессе. |
Структуры данных.
| Структура данных |
| программная единица, позволяющая хранить и обрабатывать множество однотипных и/или логически связанных данных. |
Структуры данных бывают физическими и абстрактными.
Абстрактные структуры данных – интерфейс для операций с хранимыми объектами, скрывающий детали реализации от пользователя. Они могут быть реализованы с помощью различных физических структур, как массивов, так и списков.
Пример: стек, очередь FIFO, дек, словарь
Физические структуры данных разделяются на статические (массив) и динамические (список, каждый элемент содержит данные и связку).
Для добавления, поиска, изменения и удаления данных структура данных предоставляет некоторый набор функций, составляющих интерфейс структуры данных. Структура данных часто является реализацией какого-либо абстрактного типа данных.
При разработке программного обеспечения большую роль играет проектирование хранилища данных, и представление всех данных в виде множества связанных структур данных. Хорошо спроектированное хранилище данных оптимизирует использование ресурсов (таких как время выполнения операций, используемый объём оперативной памяти, число обращений к дисковым накопителям), требуемых для выполнения наиболее критичных операций.
Структуры данных формируются с помощью типов данных, ссылок и операций над ними в выбранном языке программирования.
Различные виды структур данных подходят для различных приложений; некоторые из них имеют узкую специализацию для определённых задач. Например, Б-деревья обычно подходят для создания баз данных, в то время как хэш-таблицы используются повсеместно для создания различного рода словарей, например, для отображения доменных имён в интернет адреса компьютеров.
При разработке программного обеспечения сложность реализации и качество работы программ существенно зависит от правильного выбора структур данных. Это понимание дало начало формальным методам разработки и языкам программирования, в которых именно структуры данных, а не алгоритмы, ставятся во главу архитектуры программного средства. Большая часть таких языков обладает определённым типом модульности, позволяющим структурам данных безопасно переиспользоваться в различных приложениях. Объектно-ориентированные языки, такие как Java, C# и C++, являются примерами такого подхода.
Многие классические структуры данных представлены в стандартных библиотеках языков программирования или непосредственно встроены в языки программирования. Например, структура данных хэш-таблица встроена в языки программирования Lua, Perl, Python, Ruby, Tcl и др. Широко используется стандартная библиотека шаблонов STL языка C++.
Фундаментальными строительными блоками для большей части структур данных являются массивы, записи (см. конструкцию struct в языке Си и конструкцию record в языке Паскаль), размеченные объединения (см. конструкцию union в языке Си) и ссылки.
Линейные структуры данных (Linear data structures)
Список (List)
Массив (Array)
Битовые поля (Bitmaps)
Изображения (Images)
Поля высот (Heightfields)
Параллельный массив (Parallel array)
Дерево отрезков
Дерево Фенвика
Связный список (Linked list)
Список с пропусками (Skip list)
Развёрнутый связный список (Unrolled linked list)
XOR-связный список (Xor linked list)
V-список (VList)
Ассоциативный массив (Associative array a.k.a. dictionary or map) — также известен как словарь или карта
Хеш-таблица (Hash table)
Стек (Stack a.k.a. LIFO Last in, first out) — также известен как ЛИФО
Очередь (Queue a.k.a. FIFO First in, first out) — также известен как ФИФО
Очередь с приоритетом (Priority queue), одна из реализаций - - Двоичная куча, см. ниже
Дек (Deque) — двусвязная очередь
Буферное окно (Buffer gap)
Граф (Graph)
Список рёбер (Adjacency list)
Представление графа в разорванном виде (Disjoint-set data structure)
Представление графа в виде стеков (Graph-structured stack)
Сценограф (Scene graph)
Деревья
2-3 дерево
Красно-чёрное дерево
BSP дерево
M-Way Tree
B-дерево
Двоичное дерево поиска (Binary search tree)
Самобалансирующееся дерево поиска (Self-balancing binary search tree)
АВЛ-дерево (AVL tree)
Дерево Фибоначчи
Красно-чёрное дерево (Red-black tree)
Дерево со штрафами (Scapegoat tree)
Расширяющееся дерево (Splay tree)
Дерево ван Емде Боаса (van Emde Boas tree)
Дерево остатков (Radix tree)
Интервальное дерево (Interval tree)
Куча (Heap)
Двоичная куча (Binary heap)
Биномиальная куча (Binomial heap)
Фибоначчиева куча (Fibonacci heap)
Сливаемая куча (Mergable heap)
2-3-куча (2-3 heap)
Мягкая куча (Soft heap)
Дерево разбора (Parse tree)
Квад-дерево (Quadtree) и Окт-дерево (Octree)
Суффиксное дерево (Suffix tree)
Префиксное дерево (Trie)
Патриция (дерево) (Patricia trie)
Другие структуры данных
Помеченное объединение (Tagged union)
Объединение (Union)
Таблица (Table)
Абстрактные структуры данных
Абстрактные структуры данных предназначены для удобного хранения и доступа к информации. Они предоставляют удобный интерфейс для типичных операций с хранимыми объектами, скрывая детали реализации от пользователя.
Пример: Языки программирования высокого уровня(Паскаль, Си..) предоставляют удобный интерфейс для чисел: операции +, *, = .. и т.п, но при этом скрывают саму реализацию этих операций, машинные команды.
Конкретные реализации АТД называются структурами данных.
В программировании абстрактные типы данных обычно представляются в виде интерфейсов, которые скрывают соответствующие реализации типов. Программисты работают с абстрактными типами данных исключительно через их интерфейсы, поскольку реализация может в будущем измениться. Такой подход соответствует принципу инкапсуляции в объектно-ориентированном программировании. Сильной стороной этой методики является именно сокрытие реализации. Раз вовне опубликован только интерфейс, то пока структура данных поддерживает этот интерфейс, все программы, работающие с заданной структурой абстрактным типом данных, будут продолжать работать. Разработчики структур данных стараются, не меняя внешего интерфейса и семантики функций, постепенно дорабатывать реализации, улучшая алгоритмы по скорости, надежности и используемой памяти.
Различие между абстрактными типами данных и структурами данных, которые реализуют абстрактные типы, можно пояснить на следующем примере. Абстрактный тип данных список может быть реализован при помощи массива или линейного списка, с использованием различных техник динамического выделения памяти. Однако каждая реализация определяет один и тот же набор функций, который должен работать одинаково (по результату, а не по скорости) для всех реализации.
Абстрактные типы данных позволяют достичь модульности программных продуктов и иметь несколько альтернативных взаимозаменяемых реализаций отдельного модуля.
Список
Стек
Очередь
Ассоциативный массив
Очередь с приоритетом
Базы данных
| База данных 1) структурированный организованный набор данных, описывающий характеристики каких-либо физических или виртуальных систем 2) структурированная организованная совокупность блоков информационных элементов, представленных на машиночитаемых носителях, характеризующих актуальное состояние некоторой предметной области и предназначенных и пригодных для оперативного решения пользовательских задач с использованием средств вычислительной техники |
Обращение к базам данных осуществляется с помощью системы управления базами данных (СУБД).
База данных обладает следующими признаками:
- база данных содержит множество данных, необходимых для решения конкретных задач многих пользователей
- данные в БД структурированы и связаны между собой, при этом структура данных не зависит от программ, использующих их
- данные представлены на машиночитаемых носителях в форме, пригодной для их оперативного использования с применением СУБД
Использование БД характерузуется следующими свойствами:
- оперативность
- полная доступность
- гибкость
Можно изменять состав и форму выдачи данных, вносить изменения в саму БД.
- целостность данных
Все значения данных правильно отражают ПО и подчиняются правилам взаимной непротиворечивости. Для поддержания целостности необходимы проверка и восстановление или корректировка.
- защищенность БД
Наличие средств, обеспечивающих предотвращение доступа к информации лиц, не имеющих соотв. разрешения, умышленного разрушения или изменения данных.
- безопасность БД
Содержащиеся в БД данные не причинят вреда пользователю при правильном их применении.
- эффективность (степень соответствия результатов использования затратам на создание)
СУБД
| Система управления базами данных комплекс программных и лингвистических средств, предназначенный для создания, ведения и эксплуатации баз данных многими пользователями. |
Основные функции СУБД:
- управление данными во внешней памяти
- управление данными в оперативной памяти
- журнализация изменений, резервное копирование и восстановление базы данных после сбоев
- поддержка языков БД (язык определения данных, язык манипулирования данными) (!)
Компоненты СУБД:
- ядро (отвечает за управление данными во внешней и оперативной памяти и журнализацию)
- процессор языка базы данных
- подсистема поддержки времени исполнения (интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД)
- сервисные программы (внешние утилиты) (обеспечивают ряд дополнительных возможностей по обслуживанию информационной системы)
- словарь данных содержит информацию о структуре БД.
- индексы служат для быстрого поиска данных с конкретными значениями (атрибутами)
- данные
Классификация СУБД:
По модели данных:
Иерархические
Сетевые
Реляционные
Объектно-реляционные
Объектно-ориентированные
По организации хранения данных:
- локальные (все части локальной СУБД размещаются на одном компьютере)
- распределённые (части СУБД могут размещаться на двух и более компьютерах)
По способу доступа:
- файл-серверные
Файлы передаются на рабочие станции, где производится их обработка. На сервере происходит только хранение данных.
В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере. Ядро СУБД располагается на каждом клиентском компьютере. Доступ к данным осуществляется через локальную сеть. Синхронизация чтений и обновлений осуществляется посредством файловых блокировок. Преимуществом этой архитектуры является низкая нагрузка на ЦП сервера, а недостатком — высокая загрузка локальной сети.
На данный момент файл-серверные СУБД считаются устаревшими.
Примеры: Microsoft Access, Paradox, dBase.
- клиент-серверные
Сервер обеспечивает не только хранение данных, но и основной объем обработки данных.
Спецификой архитектуры клиент-сервер является использования языка запросов SQL.
Такие СУБД состоят из клиентской части (которая входит в состав прикладной программы) и сервера. Клиент-серверные СУБД, в отличие от файл-серверных, обеспечивают разграничение доступа между пользователями и мало загружают сеть и клиентские машины. Сервер является внешней по отношению к клиенту программой, и по надобности его можно заменить другим. Недостаток клиент-серверных СУБД в самом факте существования сервера (что плохо для локальных программ — в них удобнее встраиваемые СУБД) и больших вычислительных ресурсах, потребляемых сервером.
Примеры: Firebird, Interbase, IBM DB2, MS SQL Server, Sybase, Oracle, PostgreSQL, MySQL, ЛИНТЕР, MDBS.
- встраиваемые
Встраиваемая СУБД — библиотека, которая позволяет унифицированным образом хранить большие объёмы данных на локальной машине. Доступ к данным может происходить через SQL либо через особые функции СУБД. Встраиваемые СУБД быстрее обычных клиент-серверных и не требуют установки сервера, поэтому востребованы в локальном ПО, которое имеет дело с большими объёмами данных (например, геоинформационные системы).
Примеры: OpenEdge, SQLite, BerkeleyDB, один из вариантов Firebird, один из вариантов MySQL, Sav Zigzag, Microsoft SQL Server Compact, ЛИНТЕР.
Пользователей СУБД можно разбить на три категории:
администратор сервера баз данных
Он ведает установкой, конфигурированием сервера, регистрацией пользователей, групп, ролей и т.п. Администратор сервера имеет имя ingres. Прямо или косвенно он обладает всеми привилегиями, которые имеют или могут иметь другие пользователи.
администраторы базы данных
К этой категории относится любой пользователь, создавший базу данных, и, следовательно, являющийся ее владельцем. Он может предоставлять другим пользователям доступ к базе и к содержащимся в ней объектам. Администратор базы отвечает за ее сохранение и восстановление. В принципе в организации может быть много администраторов баз данных. Чтобы пользователь мог создать базу и стать ее администратором, он должен получить (вероятно, от администратора сервера) привилегию creatdb.
прочие (конечные) пользователи
Они оперируют данными, хранящимися в базах, в рамках выделенных им привилегий.
Основные положения концепции баз данных:
1.Независимость программ обработки от структур хранения (от физической организации данных)
2.Комплексное использование данных (простой, но авторизованный доступ.)
3.Автономное централизованное хранение данных с рациональной организацией ( при сложной структуре и большом объеме )
Модели данных
| Модель данных формальная теория представления и обработки данных в СУБД, включающая - аспект структуры (методы описания типов и логических структур данных) - аспект манипуляции (методы манипулирования данными) - аспект целостности (методы описания и поддержки целостности БД) |
Выделяют три класса моделей:
логические модели, опирающиеся на понятие объекта
логические модели, опирающиеся на понятие записи
физические модели данных
Объектные логические модели.
Объектные логические модели описывают данные на концептуальном уровне и внешнем уровне. Они позволяют определять структуру и ограничения целостности. На сегодняшний день существует свыше 30 моделей этого класса. Из них самые известные:
модель сущность-связь;
бинарная модель;
семантическая модель данных;
инфологическая модель.
Модель сущность-связь - основной представитель класса объектных моделей. Она считается наиболее адекватной для архитектуры БД и наиболее распространенной.
В основе модели сущность-связь лежит представление о реальном мире как о совокупности основных объектов, называемых сущностями и связей между ними.
Под сущностью понимают любой реально существующий объект, отличный от других объектов. Чтобы отличить один объект от другого, каждому из них приписывается набор атрибутов, описывающих данный объект.
Связь - это соединение между несколькими сущностями. Для того чтобы различать сущности и связи, каждому набору сущностей приписывается первичный ключ.
Первичный ключ - это один или несколько атрибутов, позволяющих однозначно идентифицировать сущность в наборе сущностей.
БД, удовлетворяющая диаграмме сущность-связь, может быть представлена в виде
набора таблиц. Для каждого набора сущностей, как и для каждого набора отношений, создается отдельная таблица, которой присваивается имя соответствующего набора. В свою очередь, каждая таблица состоит из столбцов, каждый из которых имеет свое название.
Логические модели, опирающиеся на понятие записи.
Логические модели, опирающиеся на понятие записи, как и объектные логические модели, описывают данные на концептуальном уровне и внешнем уровне, но, в отличие от последних, эти модели определяют не только архитектуру БД, но и дают общее описание ее реализации. Однако модели этого класса уже не позволяют вводить ограничения на содержимое БД, как это делают объектные логические модели.
Самые распространенные модели:
реляционная
сетевая
иерархическая
Реляционная модель была предложена в 1970 году Е.Ф. Коддом и на сегодняшний день является признанным лидером среди моделей своего класса. Она основана на математическом понятии отношения.
Согласно реляционной модели, общая структура данных (отношение) может быть представлена в виде таблицы, в которой каждая строка значений (кортеж) соответствует логической записи, а заголовки столбцов являются названиями полей (элементов) в записях. Таким образом, данные и отношения между ними в реляционной модели представлены в виде набора таблиц, аналогичным по своей структуре таблицам модели сущность-связь.
Примеры реляционных БД: dBASE IY, FoxPro, Paradox.
Наиболее уязвимой частью реляционной модели являются проблемы целостности. Для их разрешения приняты ограничения, соответствующие строгой реляционной модели. До сих пор не удалось создать полностью реляционную СУБД. Можно говорить лишь о большей или меньшей степени реляционности в отношении коммерческих СУБД. Однако для того чтобы называться реляционной СУБД должна обязательно отвечать следующим условиям:
данные в ней должны храниться в таблицах;
указатели и связи не должны быть видны пользователю;
язык запросов должен быть реляционно полным.
Сетевая модель появилась в конце 1960-х гг. Она более привязана к реализации БД, чем реляционная модель.
Сетевая БД состоит из набора записей, соединенных друг с другом при помощи ссылок (links), которые могут быть видны пользователю как указатели (pointers). Ссылка соединяет ровно две записи. Записи организованы в виде произвольного графа (arbitrary graph).
Иерархическая модель представляет собой разновидность сетевой.
Иерархическая БД, как и сетевая, состоит из совокупности записей, соединенных между собой при помощи ссылок. Каждая запись состоит из набора полей, каждое из которых содержит ровно один параметр данных.
Основное отличие иерархической модели от сетевой заключается в способе организации записей. В иерархической модели записи организованы в виде деревьев, а не произвольных графов, как в сетевой модели. Общая логическая структура иерархической БД описывается при помощи диаграммы структуры дерева, состоящей из записей и ссылок.
Пример иерархической БД: ACCESS.
Иерархическая зависимость между данными (группами данных) проявляется в следующем:
а) содержательный смысл значений одних данных (зависимых) определяется значением других данных(исходных)
б) для каждого значения исходного возможно появление нескольких реализаций групп зависимых данных.
Иерархическая зависимость называется древовидной, если выполняются следующие условия:
1) Есть единственный элемент, не зависящий ни от каких других – корневой элемент
2) Любой зависимый элемент имеет только один исходный
Разделение физических файлов происходит по множественности значений, времени считывания, дублирования, изменения, т.е. нужно соблюдать независимость данных в единых системах для обеспечения легкого доступа и разбивки по критериям.
Сетевая структура характеризуется наличием таких зависимостей, которые нарушают древовидную организацию:
1) Наличие более одного исходного
2) Наличие более одной связи между элементами
3) Наличие связей образующих цепи(кольца)
Объектно-реляционная модель
Применяется понятие объекта (аналогичное понятию объекта в объектно-ориентированных языках программирования).
Пользовательские типы данных, инкапсуляция, полиморфизм, наследование, переопределение методов и т.п.
Объектно-ориентированная модель
Используются разные методы:
- встраивание в объектно-ориентированный язык средств для работы с базами данных
- создание объектно-ориентированных библиотек фнкуций для работы с СУБД
- расширение существующего языка работы с базами данных объектно-ориентированными функциями
- создание нового языка и новой объектно-ориентированной модели данных
Эта модель обычно применяется для сложных ПО, для которых не хватает функциональности реляционной модели.
Физические модели данных.
Физические модели данных используются на уровне минимальной абстракции. Это самый малочисленный класс моделей. Наиболее известные из них: отождествляющая модель (unifying model) и модель фреймовой памяти (frame memory).
Уровни представления данных.
Существует 3 уровня представления данных в концепции баз данных: концептуальный, внешний и внутренний.
Физическая структура данных - это реальное расположение данных на устройстве хранения информации. Логическая структура данных - это то, КАК информация представляется программе или пользователю. Например, файл данных - это совокупность информации, которая хранится как единое целое. Это её логическая структура. Физически файл будет записан на диске несколькими, разбросанными в разных местах, кусками.
ВНЕШНЕЕ ПРЕДСТАВЛЕНИЕ ДАННЫХ.
Являясь пользовательским представлением данных, оно чаще всего соответствует возможностям средств описания и обработки данных в часто используемых языках программирования высокого уровня. Это наборы данных, содержащие однотипные записи с фиксированным числом и составом данных, имеющие линейную структуру. Это наиболее простой вид представления данных, соответствующий таблице или объектно-характеристической матрице, каждая строка которых соответствует некоторому объекту, а элемент строки (графа таблицы) некоторой характеристике объекта. Такому линейному представлению соответствует понятие реляционного подхода к структуризации данных.
КОНЦЕПТУАЛЬНОЕ (ЛОГИЧЕСКОЕ) ПРЕДСТАВЛЕНИЕ
Являясь обобщенным представлением структуры данных для всех пользователей. оно чаще всего представляется более сложными иерархическими, древовидными и сетевыми структурами данных.
ВНУТРЕННЕЕ (ФИЗИЧЕСКОЕ) ПРЕДСТАВЛЕНИЕ.
В связи с отсутствием сложной зависимости между записями линейного представления данных для такой структуры обычно определяется единственная связь - порядок следования записей (чаще всего с возрастанием значения ключей). Физически требуемый порядок следования отображается в последовательно смежном размещении записей в массиве - именно в том порядке который определяется логической последовательностью записей. Внутреннее представление иерархической древовидной и сетевой структуры реализуется как правило с помощью адресных ссылок, в явном виде реализующих связь между элементами.
Язык определения данных.
План БД определяется набором выражений (дефиниций), написанных на специальном языке, который называется язык определения данных (ЯОД) (data definition language).
Результатом компиляции выражений на ЯОД является набор таблиц, хранящийся в специальном файле, который называется словарь данных (data dictionary). В словаре данных хранятся метаданные, то есть данные о данных.
Разновидностью ЯОД является язык хранения и определения данных (data storage and manipulation language), на котором написаны выражения, определяющие методы доступа к данным и способ хранения структуры.
Язык манипулирования данными
это командный язык, обеспечивающий выполнение основных операций по работе с данными:
извлечение информации, хранящейся в БД;
добавление новой информации в БД;
уничтожение хранящейся в БД информации.
Часть ЯМД, отвечающая за выборку данных, называется языком запросов.
Запрос (query) - выражение, задающее поиск данных в СУБД.
В ранних СУБД поддерживалось несколько специализированных по своим функциям языков. Чаще всего выделялись два языка - язык определения схемы БД (SDL - Schema Definition Language) и язык манипулирования данными (DML - Data Manipulation Language). SDL служил главным образом для определения логической структуры БД, т.е. той структуры БД, какой она представляется пользователям. DML содержал набор операторов манипулирования данными, т.е. операторов, позволяющих заносить данные в БД, удалять, модифицировать или выбирать существующие данные. В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured Query Language).
Информационный поиск
процесс нахождения и выдачи определенной заранее заданными признаками информации из массивов и записей любого вида и на любых носителях
История
Термин введён Кельвином Муром в 1948 г.
Изначально информационно-поисковые системы (ИПС) использовались только для поиска научной литературы.
Широкое распространение ИПС получили с появлением сети Интернет.
Виды информационного поиска
библиографический
поиск сведений об источнике и установление его наличия в системе источников
документальный
поиск самих источников
фактографический
поиск фактических сведений (сущностей, обладающих определенными свойствами и свойств заданных сущностей)
аналитический
поиск аналитической информации
комбинированный
Виды информационного поиска
Полнотекстовый поиск
поиск по всему содержимому документа
Поиск по метаданным
поиск по атрибутам документа
(название документа, дата создания, размер, автор)
Поиск по изображению
поиск по содержанию изображения.
Виды информационного поиска
избирательный
по постоянным запросам некоторого числа потребителей в массиве текстов, поступивших в ИПС за некоторый период времени
ретроспективный
по разовым запросам
во всём накопленном массиве текстов
Информационно-поисковая система (ИПС)
- пакет ПО, реализующий процессы создания, актуализации, хранения документов и поиска информации в информационных базах данных
Могут выдавать только такую информацию, которая была ранее введена в них. Этим они отличаются от информационно-логических систем (могут производить логическую переработку информации с целью получения новой информации).
Виды ИПС
Тематические каталоги
Специализированный каталоги
Поисковые машины (Яндекс, Google)
Средства метапоиска (сравнение результатов работы нескольких поисковых машин)
документальные ИПС
информация о содержании документа + информация о самом документе (автор, год ...)
фактографические ИПС
Состав ИПС
Информационно-поисковая система должна включать следующие основные компоненты :
- логико-семантический аппарат (информационно-поисковые языки – ИПЯ, правила индексирования, критерий выдачи);
- поисковый массив (определенное множество снабженных поисковыми образами документов);
- технические средства (приспособления и устройства;
- специалистов, взаимодействующих с системой
Состав ИПС
Подсистема ввода и регистрации документов
помещение в систему, присвоение ID
Подсистема обработки документов
формирование ПОД (поисковый образ документа)
Подсистема поиска
формирование ПОЗ (поисковый образ запроса = поисковое предписание)
отыскание ПОД документов, удовлетворяющих ПОЗ согласно критерию смыслового соответствия
Подсистема хранения
выдача найденных документов пользователю
Модели ИП
Модель ИП включает:
Формат представления документов
Формат представления запросов
Функция соответствия документа и запроса
Модели ИП
Теоретико-множественные
пример: Булева модель
Вероятностные
Алгебраические
пример: Векторная модель
Гибридные
Булевская модель
Матрица документ-термин (d, t)
показывает, какие встречаются слова и в каких документах.
Запрос: q = t1 И (НЕ t3)
Булевская модель: достоинства и недостатки
Достоинства:
- простая, легко понимаемая структура запроса
- простота реализации
Недостатки:
- недостаточно возможностей для описания сложных запросов
- результатов запроса либо слишком много либо слишком мало
- проблематичность при ранжировании результатов
Пока еще распространены в коммерческих ИПС.
Векторная модель
Учитывается, «насколько сильно» входит в документ каждый термин (вес термина).
tf – term frequency
idf – inversed document frequency
|
|
 N – общее число документов в коллекции
N – общее число документов в коллекции
Nk - количество документов в коллекции C, содержащих термин Tk
Векторная модель
Матрица документ-термин (d, t)
Запрос: q= t1 и t4 <1, 0, 0, 1, 0, 0…>
Степень соответствия – близость векторов, представляющих документ и запрос (считается по формуле скалярного произведения векторов).
Векторная модель
Достоинства:
Позволяет оценить степень соответствия документа запросу.
Обладает высокой практической эффективностью.
Удобна при ранжировании документов.
Вероятностная модель
Определяется вероятность того, что данный документ окажется интересным пользователю.
Подразумевается наличие уже существующего первоначального набора релевантных документов. Рассматривается соотношение встречаемости термов в релевантном наборе и в остальной части коллекции.
Документ представляется как множество слов без учета частоты их встречаемости в документе.
D = <t1, …, tn> ti - {0, 1}
Стратегии поиска
Стратегия поиска – общий план поведения системы или
пользователя для выражения и удовлетворения
информационной потребности пользователя
Примеры:
следует по возможности искать специализированную ИПС по своей теме
следует читать найденные документы и искать наиболее точные термины и связи между ними, т.к. возможно мы не знаем реально употребляющихся терминов
следует использовать несколько ИПС
Индекс (поисковый массив)
Индекс - система связанных между собой файлов, которая нацелена на быстрый поиск данных по запросу пользователя.
Состоит из
таблицы идентификаторов страниц
таблицы ключевых слов
таблицы заголовков
таблицы гипертекстовых связей
инвертированного списка (ключевое слово - > документы, в которых оно встречается)
прямого списка
таблицы модификации страниц (когда страница изменяется, в таблицу модификации помещается ссылка на новую страницу; когда число таких ссылок становится выше допустимого, необходима перезагрузка индекса)
Информационно-поисковые языки
ИПЯ - формализованный искусственный язык, предназначенный для индексирования документов, информационных запросов и фактов в форме, удобной для автоматического поиска.
Состоит из
- алфавита (списка элементарных символов)
- правил образования (какие комбинации элементарных символов допускаются при построении слов и выражений)
- правил интерпретации (как надлежит понимать эти слова и выражения)
Выражения на ИПЯ допускают только одно истолкование, благодаря чему возможно сравнивать ПОД и ПОЗ формально, не вникая в смысл.
Виды информационно-поисковых языков
классификации (= предкоординированные ИПЯ)
Не позволяют вести поиск по заранее не предусмотренному сочетанию признаков.
Процесс индексирования с помощью классификаций принципиально не автоматизирован.
языки дескрипторного типа (= посткоординируемые ИПЯ)
(перечень полнозначных слов)
без лексического контроля (ключевые слова) vs. с лексическим контролем (дескрипторы)
Классификация ИПЯ:
| предкоординированные ИПЯ присутствует заранее заданная классификационная схема |
посткоординируемые ИПЯ отсутствует заранее заданная классификационная схема |
Типы классификаций
| иерархическая задает дерево знаний, например всей литературы по лингвистике |
алфавитно-предметная например, телефонный справочник |
фасетная опирается на разные аспекты описания, задается так называемая фасетная формула (Ж1 Ц2 Ф1), представляющая собой шаблон, рассматривается класс, аспект предмета |
Фасетная классификация: фильмы:
| жанр |
цвет |
формат |
| Ж1 Ж2 |
Ц1 цветной Ц2 черно-белый |
Ф1 широкоформатный |
фасетная формула: Ж1 Ц2 Ф1
Посткоординируемые ИПЯ:
| семантические коды в ЛЕ в явном виде заданы парадигматические отношения |
дескрипторы оперируют монолитными СЕ, в основу положен принцип координированного индексирования, который выражается в том. что основная тема документа выражается в виде набора слов или СС, т. о документ помещается в n-мерное пространство |
||
| Семантические коды Перри и Кента (США) м.б простыми и составными, простая ЛЕ - сем. множитель; RX коды ручное индексирование |
грамматики мешочного типа (теоретико-множественные грамматики) задаются отношением совместного вхождения в класс, ПОД составляется вручную, ПОД - перечень ключевых слов. |
позиционно-скобочные грамматики сохранение всего исходного текста документа с явным указанием порядка следования, деления на абзацы, предложения: |
сетевые грамматики в явном виде задается смысл связи между элементами текста (Скрэгг) |
ИПЯ с ПСГ:
индексирование без лексического контроля, до индексирования могут не иметь словаря, словарь формируется в результате индексирования.
индексирование с лексическим контролем - все словоформы приводятся к стандартному виду
Поисковые системы в Интернет
2 основных типа поисковых систем Интернет:
классификационные (каталоговые)
Rambler, Yahoo!
содержат тематически структурированный каталог сайтов
чаще всего пополняются вручную
Индексные
Яндекс, Google, Rambler
индексируют информацию, содержащуюся на серверах, вносят информацию о расположении слов на страницах сайтов в свои базы данных.
сочетающие в себе оба принципа работы
Большинство индексных поисковых систем имеют и каталоговую систему поиска.
ИПЯ в поисковых машинах
Язык поисковых запросов состоит из
логических операторов
префиксов обязательности
учета расстояния между словами
учета морфологии языка
учета регистра слов
расширенных операторов
возможностей расширенного поиска
уточнения поиска
Обычно фраза разбивается на слова, из этого списка удаляются запрещенные и общие слова, иногда производится нормализация лексики, а затем все слова связываются либо логическим AND, либо OR.
Пример:
Software that is used on Unix Platform >>>>>
Unix AND Platform AND Software
Пертинентность и релевантность
Релевантность
степень соответствия найденных документов информационному запросу
Формальная релевантность может быть оценена программно, смысловая релевантность устанавливается человеком.
Пертинентность
степень соответствия найденных документов информационным потребностям пользователя
Ранжирование
На рейтинг страницы влияет:
- количество ведущих на страницу ссылок (некоторые ссылки могут сказываться отрицательно)
- рейтинг ссылающихся страниц
- дата создания
- частота обновления
- посещаемость
- регистрация в каталоге-спутнике ИПС
Критерий выдачи
Критерий выдачи - совокупность признаков, по которым:
- определяется степень соответствия поискового образа документа поисковому образу запроса
- принимается решение о выдаче или невыдаче того или иного документа в ответ на информационный запрос
Оценка качества поиска
Точность (precision)
отношение числа релевантных документов, найденных ИПС, к общему числу найденных документов
Полнота (recall)
отношение числа найденных релевантных документов, к общему числу релевантных документов в базе
Выпадение (fall-out)
отношение числа найденных нерелевантных документов к общему числу нерелевантных документов в базе
Полнота
Полнота поиска тесно связана с оперативностью и
полнотой охвата доступной информации системой.
Программы-роботы проводят индексацию документов:
все слова найденных документов
тэги (заголовки, подписи к картинкам)
Ассоциативный поиск
Ассоциативные запросы представляют собой синонимы запроса и близкие по смыслу слова, уточняющие Ваш запрос. Они формируются в результате анализа поисковой машиной статистики.
Ассоциативный поиск возвращает документы, содержащие не только термины запроса, но и термины, статистически ассоциирующиеся с запросом.
Пример: товары, часто приобретаемые с данным товаром, в интернет-магазинах
Семантические методы
контент-анализ: "Data Mining" и "Text Mining”
(автоматическое выявление нового смысла из текстовых массивов)
Примеры использования в реальных системах:
автоматическая группировка документов (по определенному заранее классификатору)
автоматическое выделение классов документов
ранжирование документов по смысловой релевантности
выявление семантически подобных документов
автоматический анализ и смысловое преобразование запросов пользователей
Заключение
Сегодня содержательные результаты формируются без привлечения методов искусственного интеллекта, баз знаний и экспертов путем использования частотно-лингвистических и эвристических методов.
----------------------------------------------------------------------
И. п. осуществляется посредством информационно-поисковой системы и выполняется вручную либо с использованием средств механизации или автоматизации. Непременным участником И. п. является человек. В зависимости от характера информации, которая содержится в выдаваемых информационно-поисковой системой (ИПС) текстах, И. п. может быть документальным, в том числе библиографическим, и фактографическим. И. п. нужно отличать от логической переработки информации, без которой невозможна непосредственная выдача человеку ответов на задаваемые им вопросы. При И. п. отыскиваются — и могут быть найдены — такие и только такие факты или сведения, которые были введены в ИПС. Перед вводом в ИПС текста (документа) определяется его основное смысловое содержание (тема или предмет), которое затем переводится и записывается на одном из информационно-поисковых языков (см. также Индексирование). Эта запись называется поисковым образом текста. Так же поступают и когда в ИПС вводят определённым образом записанные факты, сведения. Поступивший запрос также переводится на информационно-поисковый язык, образуя поисковое предписание. Поскольку поисковые образы текстов и поисковые предписания записаны на одном и том же языке, выражения на котором допускают только одно истолкование, то возможно сравнивать их формально, не вникая в смысл. Для этого задаются определённые правила (критерии соответствия), устанавливающие, при какой степени формального совпадения поискового образа с поисковым предписанием текст следует считать отвечающим на информационный запрос и подлежащим выдаче.
Техническая эффективность И. п. характеризуется двумя относительными показателями — коэффициентом точности (отношением числа текстов, отвечающих на информационный запрос, к общему числу текстов в данной выдаче) и коэффициентом полноты (отношением числа текстов, отвечающих на информационный запрос, к общему числу таких текстов, содержащихся в данной ИПС). Необходимые значения этих показателей зависят от специфики информационных потребностей. Например, при поиске патентных описаний с целью проведения экспертизы патентной заявки на новизну необходима 100%-ная полнота выдачи; при поиске, ориентированном на обычного исследователя или инженера, очень хорошей считается точность выдачи около 80% , полнота — около 50%.
И. п. может быть двух типов — избирательное (или адресное) распространение информации и ретроспективный поиск. При избирательном распространении информации И. п. производится по постоянным запросам некоторого числа потребителей (абонентов), осуществляется периодически (обычно один раз в неделю или в две недели) и выполняется лишь в массиве текстов, поступивших в ИПС за этот период времени. Между ИПС и потребителями (абонентами) устанавливается эффективно действующая обратная связь (абонент сообщает, в какой степени этот текст соответствует запросу и нужна ли ему копия полного текста, о степени соответствия этого текста его информационной потребности), которая позволяет уточнять потребности абонентов, своевременно реагировать на изменения этих потребностей и оптимизировать работу системы. При ретроспективном поиске ИПС отыскивает содержащие требуемую информацию тексты во всём накопленном массиве текстов по разовым запросам.
Дальнейшее развитие И. п. направлено на его механизацию и автоматизацию. Для этого используются перфокарты ручного обращения (с краевой перфорацией, щелевые и просветные), счётно-перфорационные машины, электронные цифровые вычислительные машины, а также специальные технические средства — микрофотографические, с магнитной и видеомагнитной записью информации и т. д.
Информационно-поисковый язык,
знаковая система, предназначенная для описания (путём индексирования) основного смыслового содержания текстов (документов) или их частей, а также для выражения смыслового содержания информационных запросов с целью реализации информационного поиска. Любой абстрактный И.-п. я. состоит из алфавита (списка элементарных символов), правил образования и правил интерпретации. Правила образования устанавливают, какие комбинации элементарных символов допускаются при построении слов и выражений, а правила интерпретации — как надлежит понимать эти слова и выражения.
И.-п. я. должен располагать лексико-грамматическими средствами, необходимыми для выражения основного смыслового содержания любого текста и смысла любого информационного запроса по данной отрасли или предмету, быть недвусмысленным (допускать одно истолкование каждой записи), удобным для алгоритмического сопоставления и отождествления (полного или частичного) записей основного смыслового содержания текстов и смыслового содержания информационных запросов. При разработке конкретного И.-п. я. учитываются специфика отрасли или предмета, для которой этот язык создаётся, особенности текстов, образующих поисковый массив, характер информационных потребностей, для удовлетворения которых создается данная информационно-поисковая система.
В большинстве И.-п. я. основной словарный состав (лексика) задаётся его перечислением и представляет собой фрагмент лексики того или иного естественного языка. Отобранные из естественного языка слова и словосочетания, в совокупности образующие основной словарный состав, служат как бы алфавитом данного И.-п. я. Правила образования в таких И.-п. я. выполняют функцию синтаксиса. В некоторых И.-п. я. основной словарный состав задаётся (полностью или частично) методом порождения, который заключается в том, что для таких И.-п. я. правила образования устанавливают, как из данного алфавита строить слова И.-п. я., а из этих слов — выражения (фразы) и какие из них будут правильно построенными. И.-п. я. отличается от информационного языка и от машинного языка. В середине 20 в. в качестве И.-п. я. широко применяются классификации библиотечно-библиографические и языки дескрипторного типа (см. Дескриптор).
Индексирование,
процесс выражения главного предмета или темы текста какого-либо документа в терминах информационно-поискового языка. Применяется для облегчения поиска необходимого текста среди множества других. Проводится И. как целого документа, так и его части. Для И. нередко используются заглавия текстов. При И. опускаются сопутствующие предметы или темы. Это служит причиной того, что при поиске не найденными остаются тексты, для которых предмет или тема информационного запроса является не главной, а сопутствующей. Различают 2 основных типа И. — классификационное и координатное. При классификационном И., или классифицировании, тексты в зависимости от их содержания включаются в соответствующий класс (один или несколько), в котором собираются все тексты, имеющие в основном одинаковое смысловое содержание. Каждому такому тексту присваивается индекс этого класса, служащий далее его поисковым образом. При координатном И. основное смысловое содержание текста выражается перечнем полнозначных слов, выбираемых либо из самого текста или его заглавия, либо из специального нормативного словаря. В первом случае такие лексические единицы называются ключевыми словами, а во втором — дескрипторами. Каждое ключевое слово или дескриптор обозначает класс, в который потенциально входят все тексты, где в выражения основного смыслового содержания входит это слово. Логическое произведение классов, которые обозначены всеми словами, выражающими в совокупности основное смысловое содержание текста, как бы образует некоторый сложный класс. Построенный таким способом сложный класс обозначается перечнем ключевых слов или дескрипторов, и этот перечень служит поисковым образом данного текста или выражением на информационно-поисковом языке смыслового содержания запроса. Таким образом, при координатном И. смысловое содержание текста выражается как бы указанием его координат в некотором n-мерном смысловом пространстве. Разновидностью координатного И. является пермутационное, или циклическое, И., которое основано на использовании ключевых слов заглавия текста и заключается в том, что все ключевые слова заглавия вместе с контекстом поочерёдно выводятся в поисковую колонку. В этой колонке ключевые слова даются в алфавитном порядке. На основе координатного И. созданы и более сложные информационно-поисковые языки. Основное преимущество координатного И. перед классификационным заключается в том, что координатное И. не создаёт никаких затруднений при поиске текстов по любому, заранее не предусмотренному сочетанию признаков. Особым типом И. следует считать раскрытие смыслового содержания текста через приводимую вместе с ним библиографию — имена авторов и библиографические описания их работ, на которые ссылается автор данного текста. Такое И. служит основой для составления указателей цитированной литературы — весьма эффективного инструмента не только для поиска документов, но и для решения других задач (науковедческих, прогностических и т. д.).
Автоматизированные информационно-поисковые системы: их структуры, функции, критерии оценки. Информационные языки.
АИПС предназначены для инф. обслуживания пользователей информации в заданной тематической области.
2 основные задачи АИПС:
хранение информации
поиск и выдача информации
Из сведений о ТО. поступающих на хранение в систему формируется информационный массив (ИМ). От потребителя поступают запросы, и система ищет сведения в ИМ, Соответствующие данному запросу. Всякая поисковая операция в системе сводится к сравнению поступившего запроса с имеющимися в системе сведениями. в современных ИПС все это происходит автоматически. Для этого и запрос и сведения должны быть представлены на таком языке, который обладает смысловой однозначностью - ИПЯ.
Индексирование - перевод содержания текста, хранящегося в ИМ на ИПЯ. в результате индексирования образуется поисковый образ, у документа - ПОД, у запроса - ПОЗ.
Критерий смыслового соответствия - мера соответствия между содержанием запроса и документа, достаточная для признания данного документа релевантным данному запросу. Вводится совокупность признаков, на основании которых устанавливается степень необходимого и достаточного соответствия между поисковым предписанием и поисковым образом документа, выраженными на одном и том же ИПЯ.
Результатом поисковой операции является выборка релевантных ПОДов.
Абстрактная ИПС - некий логико-семантический аппарат, состоящий из ИПС, правил индексирования и критерия выдачи.
В зависимости от характера сведений и запроса различаются документальная и фактографическая ИПС. Фактографическая ИПС не хранит документы, а только факты. Документальная хранит документы. Но существует прием, позволяющий в процессе поиска определенного документа извлекать факт: В документальной системе хранится информация о содержании документа + документографическая информация(автор, год ...)
выделение нужной пользователю информации осложняется двумя обстоятельствами:
несоответствие между формулировкой запроса и реальной информацией нужной потребителю
перевод запроса в ПОЗ
Мера соответствия документа информационной потребности называется пертенетностью.
Соответствие документа запросу называется релевантностью:
смысловая (соответствие запроса поисковому предписанию) - просто релевантность, зависит от ИПЯ (его семантической силы, глубины индексирования, совершенства логико-сем. аппарата)
формальная (соответствие документа поисковому предписанию)
Критерий выдачи - совокупность признаков, по которым:
-1 определяется степень соответствия поискового образа документа поисковому предписанию; и
-2- принимается решение о выдаче или невыдаче того или иного документа в ответ на информационный запрос.
запрос – это формализованный способ выражения информационных потребностей пользователя.
Процесс поиска представляет сопоставление поисковых образов документов (ПОД) с поисковым образом запроса (ПОЗ)
Поисковый образ документа получается в результате процесса индексирования, которое выполняется квалифицированными специалистами и состоит из двух этапов:
- выявление смысла документа,
- описание смысла на специальном информационно-поисковом языке (ИПЯ).
Запрос к ИПС описывается также на этом языке. Поиск документа состоит в сравнении множества хранящихся в системе ПОД и текущего ПОЗ. В результате пользователю выдаются требуемые документы, отвечающие критериям запроса, выводится список найденных документов в порядке убывания релевантности, или отказ.
Результат поиска - ссылки на документы (электронные адреса), содержащие требуемую информацию.
Состав
Подсистема ввода и регистрации решает следующие основные задачи:
- создание электронных копий бумажных документов;
- обеспечение подключения к каналам доставки электронных документов;
- распознавание, а при необходимости и преобразования формата электронных документов;
- присвоение электронным документам уникальных идентификаторов (регистрация), а также ведение таблицы синхронизации имен (при необходимости сохранения прежних имен).
Подсистема хранения представляет собой, например, совокупность стандартных или специализированных средств архивации, систем управления базами данных (СУБД)


Модели поиска. Стратегии поиска. Подготовка запросов и отчетов. Оперативный и регламентный режим поиска. Формирование отчетов.
Информационно-поисковые языки.
информационная потребность должна быть выражена в виде фразы (запроса) на специальном информационно-поисковом языке.
Понятия пертинентности, смысловой и формальной релевантности.
Основными критериями оценки качества поиска являются полнота, точность и оперативность поиска.
Основополагающими характеристиками информационно-поисковых систем является полнота и релевантность результатов поиска.
"Релевантность" - устанавливаемое при информационном поиске соответствие поискового образа документа поисковому предписанию.
Полнота поиска тесно связано с оперативностью охвата информации системой.
Второй аспект связан с полнотой информации, предъявляемой пользователю по его запросу. Если предположить, что по запросу пользователя Q в базе данных находятся Р (при Р ( 0) документов, соответствующих этому запросу, а предъявлено для просмотра всего N документов, то полнота системы определяется по формуле: П=(N/P)x100%.
Под релевантностью понимается формальное соответствие информации, выдаваемой системой, запросу.
Если по запросу пользователя получено N документов, представляющих собой объединение двух множества документов: соответствующих запросу (пусть их количество - N1), и не соответствующих (их количество - N2), т.е. N = N1+N2. Тогда релевантность, как степень соответствия, определяется по формуле: Р = (N1/N)x100%, а шум - по формуле: S = (N2/N)x100% = 100% - P.
В теории информационного поиска, говоря о документах, вместо слова «подходит» используют термин пертинентный (от англ. pertinent – относящийся к делу, подходящий по сути), а вместо «не подходит» – «непертинентный.
пертинетность, соотношение объема полезной для него информации к общему объему полученной информации
Достижение высокой пертинентности - основное поле конкурентной борьбы современных поисковых систем. Именно для максимального удовлетворения информационных потребностей пользователей информационно-поисковые системы сегодня максимально интеллектуализируются - получили широкое практическое применение теории и методы семантических сетей, контент-анализа и глубинного анализа текстов (Text Mining).
Степень соответствия документа запросу называют релевантностью.
Различают содержательную и формальную релевантности.
Содержательная релевантность - соответствие документа информационному запросу, определяемое неформальным путем.
Формальная релевантность – соответствие документа информационному запросу, определяемое алгоритмически на основании применяемого в информационно-поисковой системе критерия выдачи.
Пертинентность - соответствие полученной информации информационной потребности пользователя.
Пертинентность (в информационном поиске) — соответствие полученной информации информационной потребности пользователя.
Пертинентность измеряется степенью соответствие между ожиданиями пользователя и результатами поиска (сравните с релевантностью), которая определяется как отношение объема полезной для пользователя информации к общему объему полученной информации, найденной поисковой системой.
елевантность (англ. relevant – уместный, существенный; лат. relevare – поднимать; фр. relever – отмечать, выделять) — в широком смысле, соответствие получаемого результата желаемому результату.
Термин часто используется в информационно-поисковых системах как соответствие полученной информации поисковому запросу. И запрос, и документы фиксируются любой ИП-системой, и для оценки их релевантности ей достаточно применить алгоритмы их обработки. В отличие от пертинентности, где формулирование своей информационной потребности целиком и полностью зависит от ее осмысления и языковой интерпретации пользователем, а сама потребность никак более не может быть зафиксирована ИП-системой.
По методу определения, различают формальную и содержательную релевантности. Формальная релевантность – соответствие, определяемое алгоритмически путем сравнения поискового предписания и поискового образа документа на основании применяемого в информационно-поисковой системе критерия выдачи. Содержательная релевантность — соответствие документа информационному запросу, определяемое неформальным путем.
Поисковые системы выводят список найденных документов по информационному запросу в порядке убывания степени релевантности. Оценка степени релевантности основана на алгоритмах поиска конкретной информационно-поисковой машины. Как в интернет-поисковиках, так и в справочных системах, для оценки степени релевантности документов за основу берется TF*IDF–метод (TF, англ. term frequency – частота ключевого слова в найденном документе, IDF, англ. inverse document frequency – обратная частота ключевого слова во всей коллекции документов). Кроме того, для оценки степени релевантности документа поисковому запросу в поисковой системе Яндекс используется "индекс цитирования", в Google используется система PageRank.
Кластеризация
автоматическое определение классов, и последующую группировку (кластеризацию) откликов ИПС в соответствии ними. Например, в результате отработки запроса "network" (сеть) она предлагает следующие классы документов: Management; Solution; Catholic Church; Christian Organization; Domain Names; Blog; Economy; Moving; Project.
полнота и релевантность являются антагонистическими характеристиками - чем выше релевантность, тем ниже полнота и наоборот.
В последнее время получили развитие такие направления контент-анализа, как "Data Mining" и "Text Mining", которые предполагают автоматическое выявление нового смысла из текстовых массивов, новых данных, феноменов, фактов - знаний. Все чаще возникают попытки привлечения методов контент-анализа, а точнее Text Mining в реальные поисковые системы.
Во многие современные сетевые поисковые системы внедрены такие компоненты, как:
автоматическая группировка документов, по определенному заранее классификатору;
автоматическое определение новых, не заданных заранее классов, на основе неструктурированных или слабо структурированных документов;
ранжирование документов по смысловой релевантности;
выявление семантически подобных документов - поиск подобных документов на основе эталона;
автоматический анализ и смысловое преобразование запросов пользователей.
Критерии выдачи. Функциональная эффективность поиска. Поисковые массивы, способы их организации. Понятия об ассоциативном поиске и условиях его реализации.
Информационно-поисковые языки. Понятия пертинентности, смысловой и формальной релевантности. Критерии выдачи.
Модели поиска.
Вероятностная модель ИПС.
Стратегия поиска.
Функциональная эффективность поиска.
Поисковые массивы, способы их организации.
Понятия об ассоциативном поиске и условиях его реализации.
3. Математические основы информатики
Математическая логика: исчисление высказываний; исчисление предикатов; логические модели; формальные системы;
Все предметы и события, составляющие основу необходимой для решения задачи информации, называются предметной областью.
Языки предназначенные для описания предметных областей называются языками представления знаний.
Для представления математического знания пользуются формальными логическими языками – исчислением высказываний и исчислением предикатов.
Описания предметных областей, выполненные в логических языках, называются логическими моделями.
Логические модели, построенные с применением языков логического программирования, широко применяются в базах знаний систем искусственного интеллекта и экспертных систем.
Формальные системы.
Формальные логические модели основаны на классическом исчислении предикатов 1 порядка, когда предметная область или задача описывается в виде набора аксиом. Исчисление предикатов 1 порядка в промышленных экспертных системах практически не используется. Эта логическая модель применима в основном в исследовательских "игрушечных" системах, так как предъявляет очень высокие требования и ограничения к предметной области.
Многие научные теории строятся по следующему принципу. Сначала предлагаются некоторые основные понятия и некоторые исходные законы (аксиомы), присущие основным понятиям. Далее формулируются производные понятия и по определенным правилам доказываются некоторые утверждения (теоремы), относящиеся к основным и производным понятиям. Совокупность основных и производных понятий, аксиом и теорем, построенная таким способом, называется аксиоматической системой.
Часто аксиомы (а, значит, и теоремы) аксиоматической системы сохраняют истинность при замене основных понятий другими (как, например, в теории колебаний, которая находит применение в механике, электронике, оптике). Это позволяет рассматривать аксиоматические системы с двух позиций: синтаксически (принципы построения правильных и истинных предложений)
и семантически (связь смысла правильных и истинных предложений со смыслом основных понятий).
Для исследования синтаксиса аксиоматической системы требуется ее полная формализация, т.е. символическое представление основных и производных понятий, аксиом, правил вывода и теорем.
Поэтому формальная аксиоматическая теория (формальная система) - это синтаксический аспект (сторона) аксиоматической системы. Точное же определение понятия формальной аксиоматической теории включает следующие компоненты.
Во-первых, каждая формальная аксиоматическая теория должна иметь свой формальный язык. Формальный язык считается полностью определенным, когда задано (счётное) множество его символов и описаны формулы языка. Любая конечная последовательность символов языка называется выражением этого языка. Среди всех возможных выражений выделяются формулы языка, под которыми подразумеваются правильно построенные, утверждающие нечто осмысленное предложения языка.
Во-вторых, каждая формальная аксиоматическая теория должна иметь свою систему аксиом - подмножество заведомо истинных формул, из которых по правилам теории могут быть выведены все истинные предложения этой теории (обычно к системе аксиом предъявляются требования непротиворечивости, независимости и полноты, среди которых обязательным является требование непротиворечивости).
В-третьих, каждая формальная аксиоматическая теория должна располагать конечным множеством правил вывода. Каждое правило вывода содержит формулы-посылки и формулу-заключение, выводимую при определенных этим правилом условиях из формул-посылок. Формула-заключение называется непосредственным следствием формул-посылок по данному правилу вывода.
Доказательством в формальной аксиоматической теории называется всякая последовательность формул, в которой каждая формула есть либо аксиома теории, либо непосредственное следствие каких-либо предыдущих формул этой последовательности по одному из правил вывода данной теории.
Формула называется теоремой теории тогда и только тогда, когда существует доказательство, в котором эта формула является заключительной формулой.
Исчисление высказываний - наиболее простой пример формальной аксиоматической теории в логике. Существует несколько исчислений высказываний (Гильберта, Клини, Фреге, Новикова). Мы рассмотрим исчисление высказываний Лукасевича (исчисление L), использующее функционально полную систему связок, состоящую из отрицания ¬ и импликации ![]() . Исчисление L описывает множество тождественно истинных формул (тавтологий), что соответствует реальному положению вещей в математике, где теоремы как высказывания являются тождественно истинными формулами.
. Исчисление L описывает множество тождественно истинных формул (тавтологий), что соответствует реальному положению вещей в математике, где теоремы как высказывания являются тождественно истинными формулами.
Язык исчисления L включает перечень употребляемых символов и определение понятия формулы.
Символами исчисления L являются:
- (счетное) множество символов пропозициональных (логических) переменных ![]()
- символы логических операций отрицания ¬ и импликации ![]()
- символы вспомогательные символы скобок ( , ).
Знаки других логических операций рассматриваются здесь как обозначения формул исчисления L, выражающих эти операции.
Понятие формулы исчисления определяется индуктивно:
- формулами полагаются сначала переменные ![]()
- а затем все выражения вида ¬ A и ![]() , где в качестве A и B могут выступать любые из уже имеющихся формул.
, где в качестве A и B могут выступать любые из уже имеющихся формул.
Систему аксиом исчисления L составляет бесконечное (счетное) множество формул исчисления, построенных с использованием трех схем аксиом.
Аксиомой при этом считается каждая формула, полученная подстановкой в какую-либо из схем аксиом каких-либо формул исчисления L вместо входящих в эту схему переменных.
Правилом вывода в исчислении L является modus ponens (правило заключения), согласно которому из данных формул вида A и (A->B) выводится формула .
Исчисление предикатов первого порядка и теории первого порядка отличаются тем, что в них допускается применение кванторов только лишь к переменным. Однако установлено, что большинство теорий более высоких порядков сводимо к теориям первого порядка. Каждая теория первого порядка располагает системой аксиом, включающей логические (общие) и собственные (частные) аксиомы. Исчисление предикатов первого порядка - это теория первого порядка, не имеющая собственных аксиом. Дополнение исчисления предикатов аксиомами, присущими некоторой предметной области, превращает его в частную теорию первого порядка, относящуюся к этой области.
Исчисление предикатов первого порядка является определенным расширением исчисления высказываний, поэтому на основе каждого исчисления высказываний может быть построено соответствующее ему исчисление предикатов.
Здесь будет рассматриваться исчисление предикатов (ИП), включающее систему связок и аксиом исчислении высказываний Лукасевича. Большинство обсуждаемых здесь результатов (кроме особо оговоренных для ИП) относится к любым теориям первого порядка.
Язык теорий первого порядка богаче языка исчисления высказываний благодаря использованию (нелогических) предметных переменных, что влечет за собой необходимость рассмотрения логических и нелогических функций от нелогических переменных (наряду с логическими переменными и логическими связками исчисления высказываний). Множество символов теорий первого порядка включает подмножества:
![]() - символов предметных констант;
- символов предметных констант;
![]() - функциональных символов (функторов);
- функциональных символов (функторов);
![]() - предикатных символов (предикатов);
- предикатных символов (предикатов);
![]() - символов предметных переменных;
- символов предметных переменных;
![]() - логических символов;
- логических символов;
![]() - вспомогательных символов.
- вспомогательных символов.
Множество символов ![]() называется сигнатурой. Символы, входящие в сигнатуру, выделены в особое подмножество по той причине, что наделение этих символов предметным содержанием связывает формальную аксиоматическую теорию с конкретной предметной областью (формальная аксиоматическая теория получает предметную интерпретацию), благодаря чему одна и та же формальная аксиоматическая теория оказывается применимой в различных предметных областях.
называется сигнатурой. Символы, входящие в сигнатуру, выделены в особое подмножество по той причине, что наделение этих символов предметным содержанием связывает формальную аксиоматическую теорию с конкретной предметной областью (формальная аксиоматическая теория получает предметную интерпретацию), благодаря чему одна и та же формальная аксиоматическая теория оказывается применимой в различных предметных областях.
Множество формул исчисления предикатов и теорий первого порядка определяется в два этапа: сначала описывается понятие терма (как нелогической функции от нелогических переменных), через которое затем определяется понятие логической формулы.
Терм (сигнатуры ![]() )определяется индуктивно: термами полагаются сначала предметные переменные и предметные константы, а затем - все выражения вида
)определяется индуктивно: термами полагаются сначала предметные переменные и предметные константы, а затем - все выражения вида ![]() , где
, где ![]() - любой из функциональных символов, а
- любой из функциональных символов, а ![]() - любые из уже имеющихся термов.
- любые из уже имеющихся термов.
Формула (сигнатуры ![]() ) определяется также индуктивно: (атомарными, простейшими) формулами полагаются выражения вида
) определяется также индуктивно: (атомарными, простейшими) формулами полагаются выражения вида ![]() , где
, где ![]() - предикатный символ и
- предикатный символ и ![]() - термы, а затем - все выражения вида
- термы, а затем - все выражения вида ![]() , где A и B - любые из уже имеющихся формул, а
, где A и B - любые из уже имеющихся формул, а ![]() - любая из предметных переменных.
- любая из предметных переменных.
В выражении ![]() формула A называется областью действия квантора
формула A называется областью действия квантора ![]() .
.
Пара S = (D, I) называется алгебраической системой сигнатуры ![]() при условии, что D - непустое множество, а I - отображение, ставящее в соответствие каждой предметной константе
при условии, что D - непустое множество, а I - отображение, ставящее в соответствие каждой предметной константе ![]() - элемент
- элемент![]() , каждому функциональному символу
, каждому функциональному символу ![]() - некоторую n-местную операцию
- некоторую n-местную операцию ![]() в D, каждому предикатному символу
в D, каждому предикатному символу![]() - некоторое n-местное отношение
- некоторое n-местное отношение ![]() в D. Множество D называется областью интерпретации, а отображение I - интерпретацией сигнатуры
в D. Множество D называется областью интерпретации, а отображение I - интерпретацией сигнатуры ![]() в D.
в D.
Алгебраическая система путем интерпретации "опредмечивает" абстрактные символы, придавая им конкретный смысл в предметной области, характеризуемой множеством D. Задание алгебраической системы позволяет вычислять значения термов и определять выполнимость формул.
Аксиомы теорий первого порядка разбиваются на логические и собственные. Логические аксиомы (аксиомы исчисления предикатов) - это бесконечное множество формул, построенных с помощью пяти схем аксиом. Три схемы аксиом ИП совпадают со схемами аксиом исчисления высказываний Лукасевича, остальные же две специфичны для исчисления предикатов. Их назначение - учесть специфику формул с кванторами и обеспечить логическую общезначимость теорем ИП.
Собственные аксиомы теорий первого порядка не могут быть сформулированы в общем виде, так как каждая теория первого порядка имеет свой набор собственных аксиом. Таким образом, исчисление предикатов первого порядка - это теория первого порядка, не имеющая собственных аксиом.
Правилами вывода в теориях первого порядка являются следующие два основных правила: modus ponens (правило заключения), по которому из формул A и (A - >B)выводится формула B; правило обобщения (связывания квантором общности), по которому из формулы A выводится формула ![]() . Наряду с названными основными правилами вывода, как обычно, используются и другие правила, в качестве которых выступают многие выведенные в исчислении предикатов теоремы.
. Наряду с названными основными правилами вывода, как обычно, используются и другие правила, в качестве которых выступают многие выведенные в исчислении предикатов теоремы.
Элементы теории нечетких множеств и n-арной логики. Нечеткие алгоритмы.
Нечетким множеством ![]() , по Заде, называется множество, определенное на произвольном непустом множестве Х как множество пар вида:
, по Заде, называется множество, определенное на произвольном непустом множестве Х как множество пар вида:
![]()
Множество Х называется базовым множеством или базовой шкалой (если множество Х линейно упорядочено).
Функция ![]() называется функцией принадлежности множества
называется функцией принадлежности множества ![]() .
.
Величина ![]() для каждого конкретного
для каждого конкретного ![]() называется степенью принадлежности элемента х нечеткому множеству
называется степенью принадлежности элемента х нечеткому множеству ![]() . Принято, что в нечеткое множество
. Принято, что в нечеткое множество ![]() не входят элементы
не входят элементы ![]() , имеющие
, имеющие ![]() = 0. Подмножество
= 0. Подмножество ![]() , содержащее все те элементы
, содержащее все те элементы ![]() , для которых
, для которых ![]() > 0, называется носителем нечеткого множества
> 0, называется носителем нечеткого множества ![]() .
.
Пример. В рейтинговой системе оценки знаний по каждой дисциплине задается некоторая базовая шкала баллов (обычно используется шкала [0, 1000] ), на которой задаются интервалы, дающие студенту право на получение оценки "отлично", "хорошо", "удовлетворительно", "неудовлетворительно". Фактически эти интервалы выступают как носители нечетких множеств "отлично", "хорошо", "удовлетворительно", "неудовлетворительно", так как за разные баллы из одного и того же интервала преподаватель ставит одну и ту же оценку с разной степенью уверенности. На рисунке приведены графики функций принадлежности оценок, характеризующие степень уверенности некоторого преподавателя в оценке знаний студента по дисциплине в зависимости от величины набранного им по рейтингу балла.

Приведенный пример показывает, что функция принадлежности нечеткого множества (понятия) формируется субъективно и может иметь для одного и того же понятия различный вид у разных субъектов и даже у одного и того же субъекта при различных обстоятельствах и настроениях.
Нечеткие высказывания. Высказывание ![]() называется нечетким высказыванием, если допускается, что
называется нечетким высказыванием, если допускается, что ![]() может быть одновременно истинным и ложным (в отличие от аристотелевской логики, где такая возможность исключается). Любое оценочное суждение, основанное на неполных или недостоверных данных, является нечетким и сопровождается обычно выражением степени уверенности (или сомнения) в его истинности. Например, утверждение: "Наверное, завтра похолодает".
может быть одновременно истинным и ложным (в отличие от аристотелевской логики, где такая возможность исключается). Любое оценочное суждение, основанное на неполных или недостоверных данных, является нечетким и сопровождается обычно выражением степени уверенности (или сомнения) в его истинности. Например, утверждение: "Наверное, завтра похолодает".
Мера истинности нечеткого высказывания ![]() определяется функцией принадлежности
определяется функцией принадлежности ![]() ,
, ![]() , заданной на множестве Х= {"ложь", "истина"}.
, заданной на множестве Х= {"ложь", "истина"}.
При таком определении нечеткого высказывания несомненно истинное A("истина")=1mвысказывание характеризуется функцией принадлежности A("ложь")=0). Соответственно, несомненно ложное высказываниеm(или A("истина")=0 (илиmхарактеризуется функцией принадлежности A("ложь")=1). Нечеткие высказывания, характеризующиеся равной степеньюm A("ложь")=0.5), называютmA("истина")=0.5 и mуверенности и сомнения ( нечетко индифферентными.
В дальнейшем, во избежание путаницы, будем говорить лишь о мере истинности нечетких высказываний, если не оговаривается иное толкование. Кроме того, для упрощения записи, будем обозначать, как это принято в обычной ("четкой" логике), меру истинности нечеткого высказывания тем же симоволом, что и само высказывание (например, A("истина")=0.8 будем писать =0.8). mвместо
Логические операции над нечеткими высказываниями. Нечеткие высказывания могут быть простыми и составными. Составные высказывания образуются из простых с помощью логических операций, часто называемых в логике также логическими связками из-за их роли в предложениях естественного языка. Так в обычной речи часто употребляются слова не, и, или, и словосочетания если …то…, тогда и только тогда, равносильно, соответствующие основным логическим операциям математической логики.
В отличие от традиционной математической логики, в нечеткой логике этим операциям придается специфический смысл. Причем, в зависимости от области применения, этот смысл может быть различным. Например, при изучении случайных явлений целесообразно степени уверенности рассматривать как вероятности и тогда логические операции над нечеткими высказываниями приобретают смысл известных операций над вероятностями случайных событий. Здесь будет рассматриваться интерпретация логических операций над нечеткими высказываниями, предложенная основоположником нечеткой логики Лотфи Заде (Lotfi Zadeh) и применяемая, преимущественно, в тех случаях, когда нечеткость высказываний обусловлена неполнотой информации о предмете суждения. Речь пойдет о так называемой минимаксной логике Заде.
Отрицанием нечеткого высказывания называется нечеткое высказывание , степень истинности которого определяется выражением: = 1 - . Отсюда следует, что степень ложности равна степни истинности .
Конъюнкцией нечетких высказываний и называется нечеткое высказывание & , степнь истинности которого определяется выражением: & =min( , ). То есть степень истинности нечеткого высказывания & определяется наименее истинным высказыванием.
, степеньÚДизъюнкцией нечетких высказываний и называется высказывание =max( , ). То естьÚистинности которого определяется выражением: степень истиннос определяется наиболееÚти нечеткого высказывания истинным высказыванием.
®Импликацией нечетких высказываний и называется нечеткое высказывание =max(1- , ).®, степень истинности которого определяется выражением: формуле®Это определение импликации основано на равносильности формулы . Ú
Эквиваленцией (эквивалентностью) нечетких высказываний и называется , степень истинности которого определяется«нечеткое высказывание В=min(max(1- , ), max( , 1- )). Это определение эквиваленции«выражением: )® формуле ( «основано на равносильности формулы & ). ®(
0.5³ «Нечеткие высказывания и называются нечетко близкими, если (т.е.степень эквивалентности высказываний не ниже 0.5), нечетко 0.5. £ « =0.5, и нечетко неблизкими, если «индифферентными, если
В составных высказываниях порядок выполнения введенных логических операций определяется скобками, а при отсутствии скобок - в следующем порядке: , &. «, ®, Ú,
Пример. Вычислите степень истинности составного нечеткого высказывания при условии, что входящие в него простые нечеткие высказывания имеют значения степеней истинности =0.7, =0.4, C=0.9, а формула =( & Ú & (®) & ). Если вы правильно используете определения логических операций над нечеткими высказываниями и будете следовать принятому порядку их применения при отсутствии скобок, то вы получите =0.4.
Введенные выше определения, как уже было сказано, представляют собой так называемую минимаксную интерпретацию логических операций над нечеткими высказываниями, предложенную Лотфи Заде. Существуют и другие интерпретации.
В математической логике логические операции , & в совокупностиÚ, составляют функционально полную систему логических операций. Это значит, что любое высказывание может быть описано логической формулой, составленной из простых высказываний с использованием конечного числа только этих логических операций. Аналогичным свойством по отношению к нечетким высказываниям обладает этот набор логических операций в интерпретации Заде.
Нечеткие логические формулы и их свойства. Нечеткое высказывание, степень истинности которого может принимать произвольное значение из интервала [0, 1], Заде называет нечеткой логической переменной. В определении понятия нечеткой логической формулы логические переменные и их значения (константы из интервала [0, 1]) считаются простейшими нечеткими логическими формулами, а само понятие нечеткой логической формулы вводится индуктивно.
Нечеткой логической формулой называется:
а) нечеткая логическая переменная или константа из интервала [0, 1];
б) всякое выражение, построенное из нечетких логических формул применением любого конечного числа логических операций (связок);
в) нечеткими логическими формулами считаются те и только те выражения, которые построены согласно пунктам а) и б).
Рассматривавшиеся ранее составные нечеткие высказывания являются нечеткими логическим формулами, если входящие в них простые нечеткие высказывания рассматривать как нечеткие логические переменные.
Важнейшим фактором в осуществлении преобразований логических формул является равносильность логических формул. В нечеткой логике возможности осуществления равносильных преобразований расширяются за счет того, что для таких преобразований, в отличие от четкой логики, достаточно лишь наличия необходимой степени равносильности нечетких логических формул.
Понятие равносильности нечетких логических формул ( , , …, ) и ( , , …, ), определенных на наборах значений одних и тех же нечетких логических переменных , , …, , вводится как обощение равносильности четких логических формул через определение степени их равносильности.
( , ) формулmСтепень равносильности ( , , …, ) и ( , , …, ) определяется выражением:
0.5 (пишут );³( , )mФормулы и называют: нечетко равносильными - если ); нечетко~( , )=0.5 (пишут mвзаимно нечетко индифферентными - если ).¹0.5 (пишут £ ( , )mнеравносильными - если
Несмотря на то, что нечеткая логика Лотфи Заде является наиболее обоснованной с теоретической точки зрения и имеет множество практических применений, на пути ее широкого распространения возникает немало трудностей из-за отсутствия общепринятого словаря и языка для выражения уверенности в нечетких суждениях.
До сих пор мы не принимали во внимание тот факт, что в реальных условиях знания, которыми располагает человек, всегда в какой-то степени неполны, приближенны, ненадежны. Тем не менее, людям на основе таких знаний все же удается делать достаточно обоснованные выводы и принимать разумные решения. Следовательно, чтобы интеллектуальные системы были действительно полезны, они должны быть способны учитывать неполную определенность знаний и успешно действовать в таких условиях.
Неопределенность (не-фактор) может иметь различную природу.
Наиболее распространенный тип недостаточной определенности знаний обусловлен объективными причинами:
- действием случайных и неучтенных обстоятельств,
- неточностью измерительных приборов,
- ограниченными способностями органов чувств человека,
- отсутствием возможности получения необходимых свидетельств.
В таких случаях люди в оценках и рассуждениях прибегают к использованию вероятностей, допусков и шансов (например, шансов победить на выборах).
Другой тип неопределенности, можно сказать, обусловлен субъективными причинами:
- нечеткостью содержания используемых человеком понятий (например, "толпа"),
- неоднозначностью смысла слов и высказываний (например, "ключ" или знаменитое "казнить нельзя помиловать").
Неоднозначность смысла слов и высказываний часто удается устранить, приняв во внимание контекст, в котором они употребляются, но это тоже получается не всегда или не полностью.
Таким образом, неполная определенность и нечеткость имеющихся знаний - скорее типичная картина при анализе и оценке положения вещей, при построении выводов и рекомендаций, чем исключение. В процессе исследований по искусственному интеллекту для решения этой проблемы выработано несколько подходов.
Самым первым можно считать использование эвристик в решении задач, в которых достаточно отдаленный прогноз развития событий невозможен (как, например, в шахматной игре).
Но самое серьезное внимание этой проблеме стали уделять при создании экспертных систем и первым здесь был применен вероятностный подход (PROSPECTOR), поскольку теория вероятностей и математическая статистика в тот период были уже достаточно развиты и весьма популярны.
Однако проблемы, возникшие на этом пути, заставили обратиться к разработке особых подходов к учету неопределенности в знаниях непосредственно для экспертных систем (коэффициенты уверенности в системах MYCIN и EMYCIN).
В дальнейшем исследования в этой области привели к разработке особой (нечеткой) логики, основы которой были заложены Лотфи Заде.
В решении рассматриваемой проблемы применительно к экспертным системам, построенным на основе правил (систем продукций), выделяются четыре основных вопроса:
а) как количественно выразить достоверность, надежность посылок?
б) как выразить степень поддержки заключения конкретной посылкой?
в) как учесть совместное влияние нескольких посылок на заключение?
г) как строить цепочки умозаключений в условиях неопределенности?
На языке продукций эти вопросы приобретают следующий смысл.
Будем обозначать ct(А) степень уверенности в А (от англ. certainty - уверенность).
Тогда первый вопрос заключается в том, как количественно выразить степень уверенности ct(А) в истинности посылки (свидетельства) А.
Второй вопрос связан с тем, что истинность посылки А в продукции А→С может не всегда влечь за собой истинность заключения С. Степень поддержки заключения С посылкой А в продукции А→С обозначим через ct(А→С).
Третий вопрос обусловлен тем, что одно и то же заключение С может в различной степени поддерживаться несколькими посылками (например, заключение С может поддерживаться посылкой А посредством продукции А→С с уверенностью сt(А→С) и посылкой В посредством продукции В→С с уверенностью ct(В→С)). В этом случае возникает необходимость учета степени совместной поддержки заключения несколькими посылками.
Последний вопрос вызван необходимостью оценки степени достоверности вывода, полученного посредством цепочки умозаключений (например, вывода С, полученного из посылки А применением последовательности продукций А→В, В→С, обеспечивающих степени поддержки, соответственно, сt(А→В) и ct(В→С) ).
Подход на основе условных вероятностей (теоремы Байеса)
Рассматриваемый здесь подход к построению логического вывода на основе условных вероятностей называют байесовским. Байесовский подход не является единственным подходом к построению выводов на основе использования вероятностей, но он представляется удобным в условиях, когда решение приходится принимать на основе части свидетельств и уточнять по мере поступления новых данных.
В сущности, Байес исходит из того, что любому предположению может быть приписана некая ненулевая априорная (от лат. a priori - из предшествующего) вероятность того, что оно истинно, чтобы затем путем привлечения новых свидетельств получить апостериорную (от лат. a posteriori - из последующего) вероятность истинности этого предположения. Если выдвинутая гипотеза действительно верна, новые свидетельства должны способствовать увеличению этой вероятности, в противном же случае должны ее уменьшать.
Примем для дальнейших рассуждений следующие обозначения:
P(H) - априорная вероятность истинности гипотезы H (от англ. Hypothesis - гипотеза);
P(H:E) - апостериорная вероятность истинности гипотезы Н при условии, что получено свидетельство Е (от англ. Evidence - свидетельство);
Р(Е:H) - вероятность получения свидетельства Е при условии, что гипотеза Н верна;
P(E:неН) - вероятность получения свидетельства E при условии, что гипотеза Н неверна.
По определению условных вероятностей имеем:
![]() и
и  .
.
Учитывая, что Р(Н и E)=Р(Е и Н), получаем теорему Байеса:
 .
.
Учитывая, что Р(Е) = Р(Е:Н)Р(Н) + Р(Е:неН)Р(неН) и Р(неН) = 1- Р(Н), получаем формулу, позволяющую уточнять вероятность истинности проверяемой гипотезы Н с учетом полученного свидетельства Е:
 .
.
Здесь обнаруживаются достоинства байесовского метода. Первоначальная (априорная) оценка вероятности истинности гипотезы Р(Н) могла быть весьма приближенной, но она позволила путем учета свидетельства Е получить более точную оценку Р(Н:Е), которую можно теперь использовать в качестве обновленного значения Р(Н) для нового уточнения с привлечением нового свидетельства. Иначе говоря, процесс уточнения вероятности Р(Н) можно повторять снова и снова с привлечением все новых и новых свидетельств, каждый раз обращаясь к одной и той же формуле. В конечном счете, если свидетельств окажется достаточно, можно получить окончательный вывод об истинности (если окажется, что Р(Н) близка к1) или ложности (если окажется, что Р(Н) близка к 0) гипотезы Н.
Шансы и вероятности связаны между собой следующей формулой:
 .
.
В некоторых странах использование шансов более распространено, чем использование вероятностей. Кроме того, использование шансов вместо вероятностей может быть более удобным с точки зрения вычислений.
Переходя к шансам в рассмотренных нами формулах, получим:
![]() .
.
Если же перейти к логарифмам величин, а в базе знаний хранить логарифмы отношений Р(Е:Н)/Р(Е:неН), то все вычисления сводятся просто к суммированию, поскольку
ln |O(H:E)| = ln |Р(Е:Н)/Р(Е:неН)| + ln |O(H)|.
Против использования шансов есть несколько возражений, главное из которых состоит в том, что крайние значения шансов равны "плюс" и "минус" бесконечности, тогда как для вероятностей это 0 и 1. Поэтому шансы использовать удобно в тех случаях, когда ни одна из гипотез не может быть ни заведомо достоверной, ни заведомо невозможной.
Как принцип байесовский подход выглядит прекрасно, но есть и несколько проблем, связанных с его применением.
Первое замечание касается возможности вычисления величины Р(Е). Эту величину легко определить, если есть возможность вычислить Р(Е:неН), а это не всегда можно сделать.
Одна из возможностей обойти это затруднение состоит в переходе к полной группе событий, однако это не спасает положение, если состав полной группы событий неизвестен. Можно пользоваться и грубыми оценками, если сохраняется точность диагноза. Кроме того, если Р(Н) уточняется в ходе работы, то Р(Е) можно тоже уточнять.
Второе замечание касается используемого в этом подходе предположения о независимости свидетельств. С теоретической точки зрения это замечание очень серьезно, но поскольку в конце процесса диагноза нас интересуют не столько точные значения вероятностей (это больше беспокоит статистиков), сколько соотношения вероятностей, то при одинаковом порядке ошибочности оценок вероятностей гипотез для практики более важной оказывается правильность общей картины, создаваемой экспертной системой.
Наиболее развитой и успешной оказалась схема, реализованная Шортлиффом в MYCIN, представляющая собой основанную на здравом смысле модификацию байесовского метода, позволяющую достаточно просто решить поставленные во вступлении к данному разделу четыре основных вопроса:
а) как количественно выразить достоверность, надежность посылок?
б) как выразить степень поддержки заключения конкретной посылкой?
в) как учесть совместное влияние нескольких посылок на заключение?
г) как строить цепочки умозаключений в условиях неопределенности?
Коэффициенты уверенности для правила с одной посылкой. В данном случае речь идет о вычислении коэффициентов уверенности для правил вида:
Е→С ("если Е то С").
Если иметь возможность присваивать коэффициент уверенности как посылке, так и импликации, то их можно использовать для оценки степени определенности заключения, выводимого по данному правилу. Шортлифф применяет в данном случае коэффициенты уверенности подобно вероятностям: коэффициент уверенности ct(E) в посылке подобен p(E); коэффициент уверенности сt(Е→С) в импликации подобен p(C:E). Для определения коэффициента уверенности в заключении Шортлифф использует схему:
ct(посылки)∙ct(импликации)=ct(заключения).
Логические комбинации посылок в одном правиле. Посылкой в правиле считается все, что находится между если и то. В MYCIN избран принцип: делать все правила простыми. Тогда простейшими логическими комбинациями посылок являются их конъюнкия или дизъюнкция, т.е. правила вида:
(Е1&Е2)→С или (Е1v Е2)→С.
Коэффициент уверенности конъюнкции посылок в MYCIN принято оценивать по наименее надежному свидетельству:
ct(Е1&Е2) = min {ct(Е1), ct(E2)}.
Соответственно, коэффициент уверенности дизъюнкции посылок в MYCIN принято оценивать по наиболее надежному свидетельству:
ct(Е1v Е2) = max {ct(Е1), ct(E2)}.
Впрочем, дизъюнкции стараются разбивать на отдельные правила, т.е. вместо правила (Е1v Е2)→С создается пара правил: Е1→С и Е2→С, так как это позволяет лучше видеть роль каждой посылки в формировании заключения. Но, если эксперт полагает, что дизъюнкция, как она описана выше, лучше отражает суть дела, то возможно использование правила с логической комбинацией посылок в форме дизъюнкции.
Поддержка одного заключения множеством правил. В этой ситуации тоже могут быть предложены различные способы учета совместного влияния свидетельств на заключение. В MYCIN применена схема, подобная схеме вычисления суммарной вероятности нескольких независимых событий.
Пусть имеются правила Е1→С и Е2→С, первое из которых обеспечивает поддержку заключения С с уверенностью ct1, а второе - с уверенностью ct2. По логике вещей, если обе посылки Е1 и Е2 верны, эти два правила совместно должны обеспечивать заключению С большую поддержку, чем каждое из них в отдельности. В MYCIN это достигается вычислением степени совместной поддержки по следующей формуле:
ct = ct1 + ct2 - ct1
ct2 .
При наличии более двух правил, поддерживающих одно и то же заключение, их совместное влияние может быть учтено последовательным применением этой схемы для объединения суммарной поддержки уже учтенных правил с поддержкой очередного, еще не учтенного правила.
Использованная Шортлиффом схема объединения поддержки одного заключения множеством правил позволяет учитывать коэффициенты уверенности поддерживающих правил в произвольном порядке и объединять их по мере поступления свидетельств.
Вместе с тем, важно помнить, что эти принципы учета коэффициентов уверенности исходят из предположения о независимости свидетельств, а также о том, что правомерность такого способа комбинирования не имеет иного обоснования, кроме того, что он прост, соответствует здравому смыслу и общему правильному поведению людей, если не относиться к нему излишне доверчиво.
Биполярные схемы для коэффициентов уверенности. Коэффициенты уверенности, примененные в MYCIN, представляют собой грубое подобие вероятностей. В усовершенствованной системе EMYCIN для выражения степени определенности использован интервал [-1, +1] в следующем смысле:
+1 - полное доверие посылке или заключению;
0 - отсутствие знаний о посылке или заключении;
-1 - полное недоверие посылке или заключению.
Промежуточные значения выражают степень доверия или недоверия к ситуации. Все описанные для однополярных коэффициентов процедуры здесь тоже имеют место, но при вычислении max и min учитываются знаки при величинах коэффициентов (например, что +0, 1 > - 0, 2). Биполярность коэффициентов повлияла и на вид используемых формул.
Так для вычисления коэффициента уверенности отрицания посылки достаточно лишь поменять знак коэффициента, т.е. ct(неЕ) = - ct(E).
Процедура расчета степени поддержки заключения несколькими правилами тоже претерпела соответствующие изменения:
а) если оба коэффициента положительны, то
ct = ct1 + ct2 - ct1
ct2 ;
б) если оба коэффициента отрицательны, то
ct = ct1 + ct2 + ct1
ct2 ;
в) если один из коэффициентов положителен, а другой отрицателен, то
 ,
,
при этом, если один из коэффициентов равен +1, а другой - 1, то ct=0.
Работа с биполярными коэффициентами может привести к нереальным результатам, если правила сформулированы неточно. В частности, ошибка возникает, если не учитывается, что правила бывают обратимыми (применимыми при любых значениях коэффициентов уверенности в посылке) и необратимыми (применимыми лишь при положительных значениях коэффициента уверенности в посылке).
Многоступенчатые рассуждения и сети вывода. До сих пор речь шла о ситуациях, когда заключение отделялось от посылки одним шагом рассуждений. Более типична ситуация, когда вывод от посылок отделен рядом промежуточных шагов рассуждений.
Принцип последовательного учета свидетельств работает успешно в том случае, когда применима так называемая монотонная логика. Но часто встречаются ситуации, когда она не имеет места. Это те случаи, когда какое-либо очередное свидетельство опровергает выводы, сделанные на основе предшествующих свидетельств. Для таких ситуаций разрабатываются специальные типы логик. Другого типа трудность возникает вследствие "незамкнутости мира": птицы летают, но не все; можно перечислить все предметы в комнате, но нельзя перечислить то, что вне ее. В таких случаях принимается "гипотеза закрытого мира": все, что вне его, то - ложь.
Реляционная алгебра и исчисление
http://www.citforum.ru/database/osbd/contents.shtml
Основы современных баз данных (про реляционное исчисление)
5. Программные средства информатики и информационных технологий
Краткий ответ на вопросы раздела:
Классы программных средств
Операционные системы
Иснструментальное ПО
Прикладное ПО
| Операционная система набор программно-аппаратных средств, обеспечивающих управление компьютером. |
Классификация ОС
По назначению
Общего пользования / Специальные (например, для управления спутником)
По количеству пользователей
Однопользовательские (MS DOS) / Многопользовательские (Windows, UNIX)
По сетевой функциональности
Локальные / Сетевые
По управлению задачами
Пакетные (перед началом работы – список задач на выполнение, вмешиваться в работу системы нельзя, пример – ввод с перфокарт) / С разделением времени (несколько задач, работающих одновременно, пример – Windows, UNIX) / ОС реального времени (особый приоритет отдается задачам, критичным по времени, пример – ОС спутников, фотоаппаратов)
Состав ОС
Загрузчик ОС
Ядро ОС
Планировщик процессов
Подсистема ввода/вывода
Драйверы ОС
Специальные программы, предназначенные для управления внешними устройствами.
Являются частью подсистемы ввода/вывода ОС.
Резидентные программы
В ОС MSDOS программа, вернувшая управление ОС, но оставшееся в оперативной памяти компьютера.
Основные функции ОС
Управление памятью
Организация доступа к внешним устройствам
Управление задачами
Организация сетевого взаимодействия
Разграничение прав доступа
Организация интерфейса к пользователю
управление вводом-выводом
управление файловой системой
управление взаимодействием процессов
диспетчеризация процессов
защита и учет использования ресурсов
обработка командного языка
Утилиты ОС
Программы, входящие в поставку ОС, предназначенные для предоставления функций ОС пользователю.
Основные объекты ОС
Процесс
Файл
Событие
Объект синхронизации (мьютекс, семафор)þ
Канал данных
Понятие файла
Объект ОС, однозначно идентифицирующий какой-либо информационный ресурс и обладающий набором характеристик.
Понятие файловой системы
Регламент, определяющий способ организации, хранения и именования данных на носителях информации.
Функции файловой системы
Именование файлов
Организация программного интерфейса работы с файлами для приложений
Отображение логической модели файловой системы на физическую организацию хранилища данных
Разграничение прав доступа к файлам
Организация устойчивости файловой системы к сбоям питания, ошибкам аппаратных и программных средств и т.п.
Содержание параметров файла необходимых для правильного его взаимодействия с другими объектами ОС
Понятие тома данных
В современных ОС логический элемент разделения физического носителя данных.
Инструментальное ПО
Набор программ, предназначенных для создания других программ.
Понятие разработки приложений
Процесс создания компьютерных программ.
Состоит из:
Анализа
Проектирования
Кодирования
Тестирования
Сопровождения
Средства для разработки
Язык программирования
Программы для компиляции, компоновки, интерпретации
Библиотеки подпрограмм
Из истории ЯП
Машинный язык
Автокод (язык ассемблера)þ
Процедурные языки
....
Типы данных
Элементарные (числа, символы)þ
Массивы
Строки
Структуры
Логические
Указатели
Понятие подпрограммы
Однозначно идентифицируемая часть программы, содержащая описание определённого набора действий.
Операторы (инструкции) ЯП
Наименьшая автономная часть ЯП.
Инструкции делятся на:
Управления
Пересылки данных
Вычисления
Сравнения
Определения
Прикладное ПО
Бывает открытое и закрытое.
Оболочка ОС
Интерпретатор команд ОС, предоставляющий интерфейс взаимодействия пользователя с функциями ОС.
Бывает: консольной и графической
Базы данных
Структурированный набор данных, описывающий характеристики каких-либо объектов.
Система управления БД
Специальный программный комплекс, предназначеный для организации и ведения БД.
Основные функции СУБД
Управление данными на ВЗУ
Управление данными в памяти
Журналирование
Организация поиска
Организация интерфейса
Компоненты СУБД
Ядро
Процессор языка БД
Подсистема управления транзакциями
Сервисные программы
Классификация СУБД
По модели организации данных
Сетевая / Иерархическая / Реляционная / Объектно-ориентированная / Объектно-реляционная
По архитектуре хранения
Локальная / Распределённая
По способу доступа
Файл-серверная / Клиент-серверная / Встраиваемая
Модульное программирование
Разделение программы на модули, которые состоят из процедур и данных, которыми они оперируют.
Объектно-ориентированное программирование
Подход к проектированию и программированию, при котором основными концепциями являются объекты и классы.
Класс – тип, описывающий устройство объекта. Максимальное приближение к сущности реального мира.
Объект - - экземпляр класса.
Основные понятия ООП
Абстракция данных
Инкапсуляция
Наследование
Полиморфизм
Логическое программирование
Подход к программированию, снованный на выводе новых фактов из данных фактов согласно заданным логическим правилам. Логическое программирование основано на теории математической логики.
Классы программных средств. Операционные системы. Системы программирования. Программные продукты.
Операционные системы. Функции операционной системы (ОС): управление задачами, управление данными, связь с оператором. Системное внешнее устройство и загрузка ОС. Резидентные модули и утилиты ОС. Управляющие программы (драйверы) внешних устройств. Запуск и остановка резидентных задач. Запуск и прекращение нерезидентных задач. Управление прохождением задачи и использованием памяти. Понятие тома и файла данных. Сообщения операционной системы. Команды и директивы оператора.
Системы программирования. Понятие разработки приложений. Состав системы программирования: язык программирования (ЯП), обработчик программ; библиотека программ и функций. История развития и сравнительный анализ ЯП.
Язы́к программи́рования — формальная знаковая система, предназначенная для записи компьютерных программ.
Язык программирования определяет набор лексических, синтаксических и семантических правил, используемых при составлении компьютерной программы. Он позволяет программисту точно определить то, на какие события будет реагировать компьютер, как будут храниться и передаваться данные, а также какие именно действия следует выполнять над этими данными при различных обстоятельствах.
Со времени создания первых программируемых машин человечество придумало уже более восьми с половиной тысяч языков программирования.[1] Каждый год их число пополняется новыми. Некоторыми языками умеет пользоваться только небольшое число их собственных разработчиков, другие становятся известны миллионам людей. Профессиональные программисты иногда применяют в своей работе более десятка разнообразных языков программирования.
Язык программирования может быть представлен в виде набора спецификаций, определяющих его синтаксис и семантику.
Для многих широко распространённых языков программирования созданы международные стандарты. Специальные организации проводят регулярное обновление и публикацию спецификаций и формальных определений соответствующего языка. В рамках таких комитетов продолжается разработка и модернизация языков программирования и решаются вопросы о расширении или поддержке уже существующих и новых языковых конструкций.
Язык программирования строится в соответствии с той или иной базовой моделью вычислений и парадигмой программирования.
Несмотря на то, что большинство языков ориентировано на императивную модель вычислений, задаваемую фон-неймановской архитектурой ЭВМ, существуют и другие подходы. Можно упомянуть языки со стековой вычислительной моделью (Forth, Factor, Postscript и др.), а также функциональное (Лисп, Haskell, ML и др.) и логическое программирование (Пролог) и язык Рефал, основанный на модели вычислений, введённой советским математиком А. А. Марковым-младшим.
В настоящее время также активно развиваются проблемно-ориентированные, декларативные и визуальные языки программирования.
Компилируемые и интерпретируемые языки
Языки программирования могут быть разделены на компилируемые и интерпретируемые.
Программа на компилируемом языке при помощи специальной программы компилятора преобразуется (компилируется) в набор инструкций для данного типа процессора (машинный код) и далее записывается в исполнимый модуль, который может быть запущен на выполнение как отдельная программа. Другими словами, компилятор переводит исходный текст программы с языка программирования высокого уровня в двоичные коды инструкций процессора.
Если программа написана на интерпретируемом языке, то интерпретатор непосредственно выполняет (интерпретирует) исходный текст без предварительного перевода. При этом программа остаётся на исходном языке и не может быть запущена без интерпретатора. Можно сказать, что процессор компьютера — это интерпретатор машинного кода.
Кратко говоря, компилятор переводит исходный текст программы на машинный язык сразу и целиком, создавая при этом отдельную исполняемую программу, а интерпретатор выполняет исходный текст прямо во время исполнения программы.
Разделение на компилируемые и интерпретируемые языки является несколько условным. Так, для любого традиционно компилируемого языка, как, например, Паскаль, можно написать интерпретатор. Кроме того, большинство современных «чистых» интерпретаторов не исполняют конструкции языка непосредственно, а компилируют их в некоторое высокоуровневое промежуточное представление (например, с разыменованием переменных и раскрытием макросов).
Для любого интерпретируемого языка можно создать компилятор — например, язык Лисп, изначально интерпретируемый, может компилироваться без каких бы то ни было ограничений. Создаваемый во время исполнения программы код может так же динамически компилироваться во время исполнения.
Как правило, скомпилированные программы выполняются быстрее и не требуют для выполнения дополнительных программ, так как уже переведены на машинный язык. Вместе с тем, при каждом изменении текста программы требуется её перекомпиляция, что создаёт трудности при разработке. Кроме того, скомпилированная программа может выполняться только на том же типе компьютеров и, как правило, под той же операционной системой, на которую был рассчитан компилятор. Чтобы создать исполняемый файл для машины другого типа, требуется новая компиляция.
Интерпретируемые языки обладают некоторыми специфическими дополнительными возможностями (см. выше), кроме того, программы на них можно запускать сразу же после изменения, что облегчает разработку. Программа на интерпретируемом языке может быть зачастую запущена на разных типах машин и операционных систем без дополнительных усилий.
Однако интерпретируемые программы выполняются заметно медленнее, чем компилируемые, кроме того, они не могут выполняться без дополнительной программы-интерпретатора.
Некоторые языки, например, Java и C#, находятся между компилируемыми и интерпретируемыми. А именно, программа компилируется не в машинный язык, а в машинно-независимый код низкого уровня, байт-код. Далее байт-код выполняется виртуальной машиной. Для выполнения байт-кода обычно используется интерпретация, хотя отдельные его части для ускорения работы программы могут быть транслированы в машинный код непосредственно во время выполнения программы по технологии компиляции «на лету» (Just-in-time compilation, JIT). Для Java байт-код исполняется виртуальной машиной Java (Java Virtual Machine, JVM), для C# — Common Language Runtime.
Подобный подход в некотором смысле позволяет использовать плюсы как интерпретаторов, так и компиляторов. Следует упомянуть также оригинальный язык Форт(Forth) имеющий и интерпретатор и компилятор.
Классы языков программирования
| Функциональные Процедурные (императивные) Стековые Векторные Аспектно-ориентированные Декларативные Динамические Учебные Описания интерфейсов |
Прототипные Объектно-ориентированные Рефлексивные Логические Параллельного программирования Скриптовые (сценарные) Эзотерические C русским синтаксисом |
Функциональное программирование объединяет разные подходы к определению процессов вычисления на основе достаточно строгих абстрактных понятий и методов символьной обработки данных. Сформулированная Джоном Мак-Карти (1958) концепция символьной обработки информации компьютером восходит к идеям Черча и других математиков, известным как лямбда-исчисление с конца 20-х годов прошлого века. Выбирая лямбда-исчисление как теоретическую модель, Мак-Карти предложил рассматривать функции как общее базовое понятие, к которому достаточно естественно могут быть сведены все другие понятия, возникающие при программировании. Существует различия в понимании функции в математике и функции в программировании, вследствие чего нельзя отнести Си-подобные языки к функциональным, использующим менее строгое понятие. Функция в математике не может изменить вызывающее её окружение и запомнить результаты своей работы, а только предоставляет результат вычисления функции.
Программирование с использованием математического понятия функции вызывает некоторые трудности, поэтому функциональные языки, в той или иной степени предоставляют и императивные возможности, что ухудшает дизайн программы (например возможность безболезненных дальнейших изменений). Дополнительное отличие от императивных языков программирования заключается в декларативности описаний функций. Тексты программ на функциональных языках программирования описывают «как решить задачу», но не предписывают последовательность действий для решения. Первым, спроектированным функциональным языком стал Лисп. Он был предложен Джоном Мак-Карти в качестве средства исследования границ применимости компьютеров, в частности, методом решения задач искусственного интеллекта. Лисп послужил эффективным инструментом экспериментальной поддержки теории программирования и развития сферы его применения. Вариант данного языка широко используется в системе автоматизированного проектирования AutoCAD и называется AutoLISP
В качестве основных свойств функциональных языков программирования обычно рассматриваются следующие:
краткость и простота;
Программы на функциональных языках обычно намного короче и проще, чем те же самые программы на императивных языках.
Пример (быстрая сортировка Хоара на абстрактном функциональном языке):
quickSort ([]) = []
quickSort ([h : t]) = quickSort (n | n t, n <= h) + [h] + quickSort (n | n t, n > h)
строгая типизация;
В функциональных языках большая часть ошибок может быть исправлена на стадии компиляции, поэтому стадия отладки и общее время разработки программ сокращаются. Вдобавок к этому строгая типизация позволяет компилятору генерировать более эффективный код и тем самым ускорять выполнение программ.
модульность;
Механизм модульности позволяет разделять программы на несколько сравнительно независимых частей (модулей) с чётко определёнными связями между ними. Тем самым облегчается процесс проектирования и последующей поддержки больших программных систем. Поддержка модульности не является свойством именно функциональных языков программирования, однако поддерживается большинством таких языков.
функции — объекты вычисления;
В функциональных языках (равно как и вообще в языках программирования и математике) функции могут быть переданы другим функциям в качестве аргумента или возвращены в качестве результата. Функции, принимающие функциональные аргументы, называются функциями высших порядков или функционалами.
чистота (отсутствие побочных эффектов);
В чистом функциональном программировании оператор присваивания отсутствует, объекты нельзя изменять и уничтожать, можно только создавать новые путем декомпозиции и синтеза существующих. О ненужных объектах позаботится встроенный в язык сборщик мусора. Благодаря этому в чистых функциональных языках все функции свободны от побочных эффектов.
отложенные (ленивые) вычисления.
В традиционных языках программирования (например, C++) вызов функции приводит к вычислению всех аргументов. Этот метод вызова функции называется вызов-по-значению. Если какой-либо аргумент не использовался в функции, то результат вычислений пропадает, следовательно, вычисления были произведены впустую. В каком-то смысле противоположностью вызова-по-значению является вызов-по-необходимости (ленивые вычисления). В этом случае аргумент вычисляется, только если он нужен для вычисления результата.
[править] Некоторые языки функционального программирования
Лисп
Common Lisp
Scheme
FP
FL
Hope
Miranda
Haskell
Curry
Clean
Gofel
ML
Standard ML
Objective CAML
Harlequin's MLWorks
F#
Nemerle
Erlang
Процедурное (императивное) программирование является отражением архитектуры традиционных ЭВМ, которая была предложена фон Нейманом в 1940-х годах. Теоретической моделью процедурного программирования служит алгоритмическая система под названием Машина Тьюринга.
Архитектура фон Неймана (англ. Von Neumann architecture) —В общем случае, когда говорят об архитектуре фон Неймана, подразумевают физическое отделение процессорного модуля от устройств хранения программ и данных.
| Содержание [убрать] 1 Основные сведения 2 Процедурные языки программирования 3 См. также 4 Ссылки 5 Литература |
[править] Основные сведения
Программа на процедурном языке программирования состоит из последовательности операторов (инструкций), задающих процедуру решения задачи. Основным является оператор присваивания, служащий для изменения содержимого областей памяти. Концепция памяти как хранилища значений, содержимое которого может обновляться операторами программы, является фундаментальной в императивном программировании.
Выполнение программы сводится к последовательному выполнению операторов с целью преобразования исходного состояния памяти, то есть значений исходных данных, в заключительное, то есть в результаты. Таким образом, с точки зрения программиста имеются программа и память, причем первая последовательно обновляет содержимое последней.
Процедурный язык программирования предоставляет возможность программисту определять каждый шаг в процессе решения задачи. Особенность таких языков программирования состоит в том, что задачи разбиваются на шаги и решаются шаг за шагом. Используя процедурный язык, программист определяет языковые конструкции для выполнения последовательности алгоритмических шагов.
[править] Процедурные языки программирования
Аda (язык общего назначения)
Basic (версии начиная с Quick Basic до появления Visual Basic)
Си
КОБОЛ
Фортран
Модула-2
Pascal
ПЛ/1
Рапира
REXX
Декларати́вные языки́ программи́рования — это языки программирования высокого уровня, в которых программистом не задается пошаговый алгоритм решения задачи ("как" решить задачу), а некоторым образом описывается, "что" требуется получить в качестве результата. Механизм обработки сопоставление по образцу декларативных утверждений уже реализован в устройстве языка. Типичным примером таких языков являются языки логического программирования (языки, основанные на системе правил).
В программах на языках логического программирования соответствующие действия выполняются только при наличии необходимого разрешающего условия.
Характерной особенностью декларативных языков является их декларативная семантика. Основная концепция декларативной семантики заключается в том, что смысл каждого оператора не зависит от того, как этот оператор используется в программе. Декларативная семантика намного проще семантики императивных языков, что может рассматриваться как преимущество декларативных языков перед императивными.
Объектно-ориентированный язык программирования
[править]
Материал из Википедии — свободной энциклопедии
| Текущая версия [показать стабильную версию] (сравнить) |
(+/-) |
| Данная версия страницы не проверялась участниками с соответствующими правами. Вы можете прочитать последнюю проверенную или т. н. стабильную версию от 12 марта 2009, однако она может значительно отличаться от текущей версии. Проверки требуют 12 правок. |
Перейти к: навигация, поиск
Объектно-ориентированный язык программирования (ОО-язык) — язык, построенный на принципах объектно-ориентированного программирования.
В основе концепции объектно-ориентированного программирования лежит понятие объекта - некоей субстанции, которая объединяет в себе поля (данные) и методы (выполняемые объектом действия).
Например, объект "человек" может иметь поля "имя", "фамилия" и иметь методы "есть" и "спать".Соответственно, мы можем использовать в программе операторы Человек.Имя:="Иван" и Человек.Есть(пища).
[править] Особенности
В современных ОО языках используются методы:
Наследование. Создание нового класса объектов путем добавления новых элементов (методов). В данный момент ОО языки позволяют выполнять множественное наследование, т. е. объединять в одном классе возможности нескольких других классов.
Инкапсуляция. Сокрытие деталей реализации, которое (при грамотном использовании) позволяет вносить изменения в части программы безболезненно для других её частей, что существенно упрощает сопровождение и модификацию ПО.
Полиморфизм. При полиморфизме некоторые части (методы) родительского класса заменяются новыми, реализующими специфические для данного потомка действия. Таким образом, интерфейс классов остаётся прежним, а реализация методов с одинаковым названием и набором параметров различается. С понятием «Полиморфизм» тесно связано понятие «Позднего связывания».
Типизация. Позволяет устранить многие ошибки на момент компиляции, операции проводятся только над объектами подходящего типа.
[править] Список языков
Неполный список объектно-ориентированных языков программирования:
Oberon-2 Component Pascal
Eiffel
Simula
Java
C#
C++
D (язык программирования)
Io
Objective-C
Object Pascal (Delphi)
VB.NET
Visual DataFlex
Perl
Php
PowerBuilder
Python
Scala
ActionScript (3.0 и более поздние)
JavaScript
JScript.NET
Ruby
Smalltalk
Ada
Xbase++
X++
Vala
Кроме ОО-языков общего назначения существуют и узкоспециализированные ОО-языки.
Логическое программирование
[править]
Материал из Википедии — свободной энциклопедии
(Перенаправлено с Логический язык программирования)
Текущая версия (не проверялась)
Перейти к: навигация, поиск
Логи́ческое программи́рование — парадигма программирования, основанная на автоматическом доказательстве теорем, а также раздел дискретной математики, изучающий принципы логического вывода информации на основе заданных фактов и правил вывода. Логическое программирование основано на теории и аппарате математической логики с использованием математических принципов резолюций.
Самым известным языком логического программирования является Prolog.
Первым языком логического программирования был язык Planner, в котором была заложена возможность автоматического вывода результата из данных и заданных правил перебора вариантов (совокупность которых называлась планом). Planner использовался для того, чтобы понизить требования к вычислительным ресурсам (с помощью метода backtracking) и обеспечить возможность вывода фактов, без активного использования стека. Затем был разработан язык Prolog, который не требовал плана перебора вариантов и был, в этом смысле, упрощением языка Planner.
От языка Planner также произошли логические языки программирования QA-4, Popler, Conniver и QLISP. Языки программирования Mercury, Visual Prolog, Oz и Fril произошли уже от языка Prolog. На базе языка Planner было разработано также несколько альтернативных языков логического программирования, не основанных на методе backtracking, например, Ether (см. обзор Шапиро [1989]).
Скри́птовый язы́к (англ. scripting language, в русскоязычной литературе принято название язык сценариев) — язык программирования, разработанный для записи «сценариев», последовательностей операций, которые пользователь может выполнять на компьютере. Простые скриптовые языки раньше часто называли языками пакетной обработки (batch languages или job control languages). Сценарии обычно интерпретируются, а не компилируются (хотя часто сценарии компилируются каждый раз перед запуском).
В прикладной программе, сценарий (скрипт) — это программа, которая автоматизирует некоторую задачу, которую без сценария пользователь делал бы вручную, используя интерфейс программы.
| Содержание [убрать] 1 Плагины или скрипты? 2 Типы скриптовых языков 2.1 Универсальные скриптовые языки 2.2 Встроенные в прикладные программы 2.3 Командные оболочки 2.4 Встраиваемые |
Плагины или скрипты?
Для написания пользовательских расширений могут использоваться как скрипты (в терминологии некоторых программ «макросы»), так и плагины (независимые модули, написанные на компилируемых языках; в некоторых программах они могут называться «утилитами», «экспортёрами», «драйверами»). Скриптовый язык предпочтительнее в таких случаях:
Если нужно обеспечить программируемость без риска дестабилизировать систему. Так как, в отличие от плагинов, скрипты интерпретируются, а не компилируются, неправильно написанный скрипт выведет диагностическое сообщение, а не приведёт систему к краху;
Если важен выразительный код. Во-первых, чем сложнее система, тем больше кода приходится писать «потому, что это нужно» — см., например, Hello World#Маргинальные примеры. Во-вторых, в скриптовом языке может быть совсем другая концепция программирования, чем в основной программе — например, игра может быть монолитным однопоточным приложением, в то время как управляющие персонажами скрипты выполняются параллельно. В-третьих, скриптовый язык имеет собственный проблемно-ориентированный набор команд, и одна строка скрипта может делать то же, что несколько десятков строк на традиционном языке. Как следствие, на скриптовом языке может писать программист очень низкой квалификации — например, геймдизайнер своими руками, не полагаясь на программистов, может корректировать правила игры;
Если требуется кроссплатформенность. Хорошим примером является JavaScript — его исполняют браузеры под самыми разными ОС.
У плагинов же есть три важных преимущества.
Готовые программы, оттранслированные в машинный код, выполняются значительно быстрее скриптов, которые интерпретируются из исходного кода динамически при каждом исполнении. Поэтому скриптовые языки не применяются для написания программ, требующих оптимальности и быстроты исполнения. Но из-за простоты они часто применяются для написания небольших, одноразовых («проблемных») программ.
Полный доступ к любому аппаратному обеспечению или ресурсу ОС (в скриптовом языке для этого должен существовать написанный на машинном коде API). Плагины, работающие с аппаратным обеспечением, традиционно называют драйверами.
Если предполагается интенсивный обмен данными между основной программой и пользовательским расширением, для плагина его обеспечить проще.
Также в плане быстродействия скриптовые языки можно разделить на языки динамического разбора (sh, command.com) и предварительно компилируемые (Perl). Языки динамического разбора считывают инструкции из файла программы минимально требующимися блоками, и исполняют эти блоки, не читая дальнейший код. Предкомпилируемые языки транслируют программу в байт-код и затем исполняют его. Некоторые скриптовые языки имеют возможность компиляции программы «на лету» в машинный код (см. JIT).
[править] Типы скриптовых языков
[править] Универсальные скриптовые языки
Forth
Perl
Python
PHP
Tcl (Tool command language)
REBOL
Ruby
ERM
Lua
[править] Встроенные в прикладные программы
UnrealScript
Emacs Lisp
AutoLISP
VBA
MQL4 script
[править] Командные оболочки
AppleScript
sh
bash
csh
JCL
ksh
пакетные файлы MS-DOS (.bat) и файлы командного процессора Microsoft Windows NT (.cmd)
Visual Basic Scripting Edition
REXX
[править] Встраиваемые
Браузерные языки: JavaScript, JScript
ActionScript
Lingo — использующийся в редакторе Director, называют скриптовым
Guile
Io
Lua
Sleep
Script.NET
Также в приложение может быть встроена возможность расширения сценариями на любом из универсальных скриптовых языков, см. к примеру библиотеку SWIG или автоматический планировщик задач.
апп
Типы данных. Элементарные данные, агрегаты данных, массивы, структуры, повторяющиеся структуры. Вычислительные данные, символьные данные, логические, адресные (метки и пойнтеры), прочие (битовые строки). Понятие блока и процедуры. Операторы ЯП: управления (организация циклов, ветвления процесса, перехода), присваивания, вычисления арифметических, логических, строчных выражений. Стандартные арифметические, логические, строчные функции.
Программные продукты (приложения).
Оболочки операционной системы.
Оболочка операционной системы (от англ. shell — оболочка) — интерпретатор команд операционной системы (ОС), обеспечивающий интерфейс для взаимодействия пользователя с функциями системы.
оболочки операционных систем - программы, делающие наглядным и простым выполнение базовых операций над файлами, каталогами и др. с использованием меню, защитой от необдуманных и ошибочных действий и разветвленной контекстной помощью
В общем случае, различают оболочки с двумя типами интерфейса для взаимодействия с пользователем: интерфейс командной строки (CLI, DOS, Norton Commander) и графический пользовательский интерфейс (GUI, Windows).
Оболочки предоставляют пользователю удобный доступ к файлам и обширные сервисные услуги:
* создание, копирование, пересылку, переименование, удаление, поиск файлов, а также изменение их атрибутов;
* отображение дерева каталогов и характеристик входящих в них файлов в форме, удобной для восприятия человека;
* создание, обновление и распаковку архивов (групп сжатых файлов);
* просмотр текстовых файлов;
* редактирование текстовых файлов;
* выполнение из её среды практически всех команд DOS;
* запуск программ;
* выдачу информации о ресурсах компьютера;
* создание и удаление каталогов;
* поддержку межкомпьютерной связи;
* поддержку электронной почты через модем.
В начале 90-х годов во всем мире огромную популярность приобрела графическая оболочка MS-Windows 3.х, преимущество которой состоит в том, что она облегчает использование компьютера, и её графический интерфейс вместо набора сложных команд с клавиатуры позволяет выбирать их мышью из меню практически мгновенно. Операционная среда Windows, работающая совместно с операционной системой DOS, реализует все свойства, необходимые для производительной работы пользователя, в том числе — многозадачный режим.
Программные пакеты информационного поиска.
реальную возможность высокоэффективного поиска информации дает двухэтапный процесс поиска, где первый этап, это предварительный поиск и отбор информации в тематические базы данных, а второй этап, это поиск нужной информации конечным пользователем в сетевых или локальных полнотекстовых базах.
Следует ожидать, что спрос на тематические базы данных будет стремительно расти и дальше. Появление поисковых систем нового поколения, использующих смысловую оценку содержания текстов и документов, скорее всего приведет к еще большему спросу на такие базы.
Область применения программы
*поиск текстовых файлов на собственном компьютере
* Поисковые системы для корпоративных пользователей
* Поисковые системы для интернет проектов
Из-за большого количества мусора в сети, необходима сортировка выдачи по степени релевантности или другим критериям (например рейтингу сайта).
* Самое сложная задача, это поиск информации в больших полнотекстовых массивах. Такая система должна искать не просто документы, а информацию, содержащуюся в них.
Программа работы с полнотекстовыми базами данных обычно состоит из нескольких функциональных блоков:
* Программа сканирования файловой структуры исходного массива документов.
Задача программы, достучаться до каждой директории и каждого файла и передать файл соответствующей программе обработчику.
* Комплекс программ извлечения текстовых данных из файлов различных форматов.
на выходе чистый текст для индексирования.
* Программа создания индекса. Индекс полнотекстовой базы это файл, в котором записана информация о каждом слове исходного массива документов: к какому документу оно принадлежит, в какой части документа находится, относится оно к заголовку, основному тексту и т.д.
* Программа леммитизации, работающая с морфологическим словарем.
Лемматизация - слово при индексации и поиске заменяется на базовое
* Программа поиска слов в базе данных
* Лингвистическое обеспечение
- словарь словоизменения (морфологического анализа)
- словарь моделей управления предикатов русского языка
- тезаурус общей лексики (прежде всего синонимы и обобщающие понятия)
- специальные словари и правила, например словари служебных идиоматических единиц (многословные предлоги, союзы, наречия, вводные), часи составных наименований организаций и др.
* (Некоторые системы имеют) Модули работы со смыслом текста
Используют семантические сети, ассоциативные связи.
Такая интеллектуальная система может найти в тексте фрагменты по смыслу отвечающие запросу, хотя они вообще не содержат слов из запроса.
Различные варианты сетевого поиска
* поиск в сетевом окружении.
Такая программа может индексировать файлы, расположенные не только на своем компьютере, но и на дисках других ПК, объединенных в локальную сеть. При этом поиск может осуществляться только с ПК, на котором установлена система и расположена база данных, включая поисковый индекс.
* поисковые системы работающие по интернет протоколу
В этом случае база данных и основная программа установлены на центральном сервере локальной сети.
* программные системы имеющие клиент-серверную архитектуру с собственной клиентской частью программы
Примеры:
* Поисковая система Windows XP (система индексирования, текстов, содержащихся на компьютере)
* Яндека
* Cros
* ODB-Text
* Ищейка
* МБД
Оболочки экспертных систем.
http://www.itpedia.ru/index.php/ Экспертные_системы_(оболочки)
http://expro.kzn.ru/materials/ii_i_es/book.html
http://prof9.narod.ru/doc/doc035.html
http://www.mari-el.ru/mmlab/home/AI/7_8/
Экспертная система - это компьютерная программа, содержащая накопленные знания специалистов в определенной предметной области, Эта программа способна вырабатывать рекомендации, какие бы дал эксперт-человек, запрашивая при необходимости дополнительную информацию. Экспертные системы могут работать на том же уровне что и эксперты, а в некоторых случаях они лучше, потому что в нее вложен коллективный опыт их создателей.
Экспертная поддержка принимаемых пользователем решений реализуется на двух уровнях.
Первый уровень: типовой набор альтернатив
Второй уровень: генерирует альтернативы на базе имеющихся в информационном фонде данных, правил преобразования и процедур оценки синтезированных альтернатив.
Известны три основные разновидности исполнения экспертных систем:
* Экспертные системы, выполненные в виде отдельных программ, на некотором алгоритмическом языке, база знаний которых является непосредственно частью этой программы. Как правило, такие системы предназначены для решения задач в одной фиксированной предметной области. При построении таких систем применяются как традиционные процедурные языки PASCAL, C и др., так и специализированные языки искусственного интеллекта LISP, PROLOG.
* Оболочки экспертных систем - программный продукт, обладающий средствами представления знаний для определенных предметных областей. Задача пользователя заключается не в непосредственном программировании, а в формализации и вводе знаний с использованием предоставленных оболочкой возможностей. Недостатком этих систем можно считать невозможность охвата одной системой всех существующих предметных областей. Примером могут служить ИНТЕРЭКСПЕРТ, РС+, VP-Expert.
* Генераторы экспертных систем - мощные программные продукты, предназначенные для получения оболочек, ориентированных на то или иное представление знаний в зависимости от рассматриваемой предметной области. Примеры этой разновидности - системы KEE, ART и др..
Оболочки экспертных систем - программный продукт, обладающий средствами представления знаний для определенных предметных областей. Задача пользователя заключается не в непосредственном программировании, а в формализации и вводе знаний с использованием предоставленных оболочкой возможностей. Недостатком этих систем можно считать невозможность охвата одной системой всех существующих предметных областей. Примером могут служить ИНТЕРЭКСПЕРТ, РС+, VP-Expert.
Оболочка, shell - базовый элемент операционной системы, определяющий интерпретацию команд и действий пользователя.
CLIPS (Язык C, интегрированная Продукционная Система) - OPS-ПОДОБНАЯ продукционная система, использующая вывод от фактов к цели, написанная на C в ANSI NASA. Механизм логического вывода CLIPS включает сопровождение , динамическое добавление правил и настраиваемые cтратегии разрешения противоречий. CLIPS, включая динамическую версию , легко встраивается в другие прикладные программы. CLIPS включает объектно-ориентированный язык, названный COOL(Объектно-ориентированный Язык CLIPS), который прямо интегрирован с механизмом логического вывода. CLIPS выполняется на многих платформах, включая IBM PC ( Windows 3.1 и версии МС-ДОС 386). Домашняя страница Software Technology Branch - http://www.jsc.nasa.gov/stb/STB_homepage.html NASA, домашняя страница Nasa Information Services http://hypatia.gsfc.nasa.gov/NASA_homepage.html и домашняя страница CLIPS - http://www.jsc.nasa.gov/~clips/CLIPS.html Cписок ЧАСТО ЗАДАВАЕМЫХ ВОПРОСОВ по CLIPS и ошибки располагаются на jsc.nasa.gov:/pub/clips/ и поддерживаются Gary Riley.
DYNACLIPS (динамические Утилиты CLIPS ) - включает доску объявлений, механизм динамического обмена знаниями и инструментальные средства для CLIPS v5.1 и v6.0. Она существлена как набор библиотек, который может быть связан с CLIPS v5.1 или CLIPS v6.0. Исходный текст не предоставляется. Для связи с другими интеллектуальными средствами используется доска объявлений. Она находится в ИИ архиве на ftp.cs.cmu.edu:/user/ai/areas/expert/systems/clips/dyna/
FuzzyCLIPS 6.02 - версия CLIPS, оболочка экспертной системы, основанная на правилах, используется для представления и управления нечеткими фактами и правилами. В дополнение к функциональным возможностям CLIPS, FuzzyCLIPS может иметь дело с точными, нечеткими (или неточными) знаниями, сложными рассуждениями, которые можно свободно смешивать в правилах и фактах экспертной системы. Система использует две базисных концепции о неточности , нечеткость и неопределенность. Имеются версии для систем UNIX, Macintosh и IBM PC.Программное обеспечение распространяется бесплатно, но документация по FuzzyCLIPS имеет сроки использования. Находится на http://ai.iit.nrc.ca/home_page.html или более прямо, на URL http://ai.iit.nrc.ca/fuzzy/fuzzy.html или анонимном ftp-сервере ai.iit.nrc.ca:/pub/fzclips/
WxCLIPS снабжает CLIPS v5.1, CLIPS v6.0 и CLIPS v6.0 с нечетким представлением знаний простым графическим внешним интерфейсом.Имеется WxCLIPS для Windows 3.1, 32-разрядного Windows и Windows 95. WxCLIPS находится на анонимном FTP-сервере Ftp.aiai.ed.ac.uk:/pub/packages/wxclips / [192.41.104.6] Или на http://www.aiai.ed.ac.uk/~jacs/wxclips/wxclips.html Чтобы Вас добавили к пользователям wxclips , пошлите сообщение по адресу wxclips-users-request@aiai.edinburgh.ac.uk. Другие оболочки экспертных систем
SOAR - ftp.cs.cmu.edu : /afs/cs.cmu.edu/project/soar/public/Soar5/ - Версия на лиспе /afs/cs.cmu.edu/project/soar/public/Soar6/ - Версия на C Контакт: soar-request@cs.cmu.edu OPS5 - содержит механизмы представления знаний и управления. Хотя эта система обеспечивает основные потребности инженерии знаний, она не ориентирована на конкретные стратегии решения задач или схемы представления знаний. Система разрешает программисту использовать символы и представлять отношения между символами, однако эти символы и отношения не имеют заранее определенных значений. Последние полностью определяются порождающими правилами, которые пишет программист. Механизм управления интерпретатора OPS5 представляет собой простой цикл, называемый "циклом распознавания", детали которого пользователь разрабатываетсам в соответствии со своими потребностями. Находится по адресу: ftp.cs.cmu.edu:/user/ai/areas/expert/systems/ops5/ops5.tar.gz
BABYLON - среда для разработки для экспертных систем . Она включает фреймы , модели данных, Пролог-подобный логический формализм, и язык для написания диагностических прикладных программ. Она написана на Лиспе и переносима на широкий диапазон аппаратных платформ. Располагается на анонимном ftp-сервере tp.gmd.de:/gmd/ai-research/Software/Babylon/ [129.26.8.84] как BinHexed stuffit архив, в WEB- сети по адресу http://www.gmd.de/
MIKE (Микро Интерпретатор для инженерии знаний) - это полная, свободная и переносимая программная среда, разработанная для целей обучения в Открытом Университете ВЕЛИКОБРИТАНИИ. Она включает прямые и обратные правила вывода от цели к фактам с определяемыми пользователем cтратегиями разрешения противоречий, и фреймовый язык представления знаний с наследственностью и ' демонами', плюс определенные пользователем cтратегии наследования. Правила вывода автоматически снабжаются, объяснениями 'как ', пользователь может сформировать объяснения ' почему '. Порядок применения правил в процессе трассировки и выполнения может отображаться графически на дисплее. MIKE, который формирует ядро курса по Инженерии знаний Открытого Университета, написан на консервативном и переносимом подмножестве Пролога, исходный текст программы свободно распространяется. MIKE версии 1 был написан в октябре / ноябре 1990. MIKE v1.50, который прежде находился на ftp- сервере, был заменен двумя более новыми версиями: MIKE v2.03, полная версия исходного текста на Пролога, включая RETE алгоритм для быстрого поиска вперед, систему сопровождения , обработки неопределенности, и гипотетических миров, и MIKE V2.50, (DOS-версия под ключ) с интерфейсом, управляемым с помощью меню, и инструментальными средствами для создания и просмотра фреймов, полностью совместимая с MIKE V2.03, но без исходного текста. Они располагаются на анонимном ftp-сервере hcrl.open.ac.uk [137.108.81.16] в виде файлов: /pub/software/src/MIKEv2.03/* MIKEv2.50: /pub/software/pc/MIKEV25.ZIP Для получения дальнейшей информации войдите в контакт с Marc'ом Eisenstadt'ом M.Eisenstadt@open.ac.uk.
ES: октябрь / ноябрь 1990 - экспертная система. ES поддерживают прямой / обратный вывод цепочки, нечеткие отношения , и содержит подсистему объяснения. Это - автономная программа, выполняемая на IBM-PC. ES располагается на анонимном ftp-сервере ftp.uu.net:/pub/ai/expert-sys/ [192.48.96.9] как summers.tar. Z. ftp.uu.net отражен на unix.hensa.ac.uk [129.12.21.7] под /pub/uunet/.
WindExS (Экспертная система под Windows) - полнофункциональная экспертная система, использует вывод от фактов к цели, работает на базе Windows. Ее модульная архитектура позволяет пользователю заменять модули так, как это требуется для расширения возможностей системы. WindExS содержит процессор Правил на Естественном языке, Механизм логического вывода, Диспетчер файлов, Интерфейс пользователя, Администратор Сообщений и модули Базы знаний. Она поддерживает вывод от фактов к цели, и графическое представление базы знаний. Для получения документации и системы пишите по адресу etoupin@aol.com .
RT-EXPERT - экспертная система общего назначения , что позволяет программистам C интегрировать правила экспертной системы в прикладные программы на языке C или C++. В состав RT-EXPERT входит транслятор правил, который компилирует правила в код C, и библиотека, содержащая механизм выполнения правил. RT-EXPERT под DOS работает с трансляторами Borland Turbo C, Borland C++, и C / C Microsoft ++.Лицензионная версия программы используется в области образования, исследований и хобби.Прикладные программы, созданные с помощью RT-EXPERT , не лицензированы для коммерческих целей. Профессиональные издания пригодны для коммерческих прикладных программ, использующих DOS, Windows, и Unix среды. RT-EXPERT располагается на анонимном ftp-сервере Word.std.com:/vendors/rtis/rtexpert
Понятие открытого и закрытого программного продукта.
http://www.palladasys.ru/index.php/opensource
http://ru.wikipedia.org/wiki/%D0%A1%D0%B2%D0%BE%D0%B1%D0%BE%D0%B4%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%BD%D0%BE%D0%B5_%D0%BE%D0%B1%D0%B5%D1%81%D0%BF%D0%B5%D1%87%D0%B5%D0%BD%D0%B8%D0%B5
Программное обеспечение с открытым исходным кодом – способ разработки и распространения ПО, при котором создаваемый исходный код программ доступен для просмотра и изменения, а распространение осуществляется под свободными лицензиями.
OpenSource имеет следующие принципиальные преимущества перед традиционным (закрытым, проприетарным ПО):
* Пользователь бесплатно получает лицензии на использование и платит лишь за поддержку программного обеспечения, если она требуется.
* Любой пользователь может участвовать в развитии и совершенствовании программного продукта, таким образом, популярный OpenSource продукт с большим количеством пользователей обладает громадным потенциалом для совершенствования.
* Продукты с открытым исходным кодом практически всегда построены по модульному принципу и используют открытие форматы данных и интерфейсы. Поэтому программы OpenSource оказываются более гибкими и лучше приспособлены к современному быстро меняющемуся миру.
* Благодаря открытости для огромного количества пользователей-специалистов ошибки и проблемы быстро находятся и устраняются, поэтому открытые программы оказываются более надёжными и защищенными, нежели закрытые.
С точки зрения бизнеса поставщиков программного обеспечения (вендоров), модель OpenSource предоставляет возможности снижения затрат на тестирование и отладку программного обеспечения и, что намного более важно, - возможности завоевания рынка программных продуктов, в условиях жесткой глобальной конкуренции. Недостаток модели так же очевиден, - ликвидация доходов от продаж лицензий (OpenSource распространяется бесплатно). Поэтому бизнес вендоров ПО OpenSource строится на оказании услуг по внедрению, обучению и поддержке программного обеспечения, а так же предоставлении дополнительных платных специализированных библиотек и модулей.
Однако, преимущества OpenSource программ могут полноценно раскрыться только при наличии большого, зрелого сообщества активных пользователей. Поэтому до недавнего времени OpenSource не был столь популярным и ассоциировался с чем-то несовершенным, кустарным и нестабильным.
И вправду, многие OpenSource проекты велись кучками энтузиастов, которые не могли гарантировать ни стабильности работы своих продуктов, ни перспектив их развития, ни полноценной технической поддержки.
Ситуация стала меняться, когда крупнейшие ИТ вендоры такие как Sun, IBM, Novell и ряд нишевых игроков рынка ПО осознали всю перспективность и преимущества бизнес-модели OpenSource и возглавили ряд крупнейших проектов с одной стороны, а с другой стороны стали образовываться компании построившие свой бизнес на поддержке и развитии популярных OpenSource продуктов (RedHat, Canonical LTD).
В результате, в настоящий момент развитие рынка OpenSource демонстрирует стабильный 30% в год рост, и по данным аналитиков IDC, к 2010 году прогнозирует занять от 15 до 20% мирового рынка программного обеспечения.
Серьезность OpenSource продуктов подтверждает положительный опыт крупнейших ИТ проектов замены проприетарного программного обеспечения на OpenSource осуществленных как за рубежом, так и в России.
Отмечается, что реальная экономия составляет в среднем от 50% до 80% (!!!) в зависимости от вида проекта и условий окружения.
Особенностью внедрения продуктов OpenSource является необходимость обучения персонала новому продукту. Но эту особенность можно считать положительным моментом. Так например, в случае с Microsoft Office, мало кто из пользователей проходил специализированные курсы. В случае проекта внедрения OpenSource есть возможность обучить персонал и повысить эффективность и качество работы пользователей.
Дополнительным преимуществом OpenSource является избавление компании от необходимости постоянно следить за корректным лицензированием — приобретено ли нужное количество лицензий на тот или иной продукт, достаточно ли число пользователей, подключение которых разрешено приобретённой лицензией на серверную ОС, и т.д.
Поэтому, в настоящий момент и в ближайшей обозримой перспективе OpenSource является сильным альтернативным экономным вариантом традиционному программному обеспечению, который позволяет сэкономить значительные средства и предоставить бизнесу дополнительные преимущества.
Понятие генератора приложений.
Applications Generator (Генератор приложений) - Программа, которая может создать другую программу в соответствии с требованиями пользователя. Генератор приложений создаст приложение, отвечающее требованиям, и предоставит исходные тексты. Генераторы приложений имеют два основных преимущества: экономия времени и отсутствие требования обязательного наличия навыков программирования. Генераторы приложений имеют два основных недостатка. Во-первых, их возможности часто ограниченны. Во-вторых, создаваемый ими код менее эффективен, чем код, разработанный хорошим программистом. Генераторы приложений часто используются при разработке голосовых программ. Одно из основных преимуществ генераторов приложений состоит в том, что они могут генерировать код на основе разработанных пользователем экранных форм и меню. Форма или меню создается при помощи пользовательского интерфейса, работать с которым так же просто, как и с системой подготовки текстов. Затем генератор приложений переводит нарисованный пользователем экран в код программы на языке Си. Опытный программист может впоследствии оптимизировать полученный код.
Пользуясь им как шаблоном, программист сможет быстро разрабатывать свои приложения. Подобные средства автоматизированного создания приложений включены в компилятор Microsoft Visual C++ и называются MFC AppWizard.
Системы управления базами данных, состав и структура.
Систе́ма управле́ния ба́зами да́нных (СУБД) - комплекс программных и лингвистических средств, предназначенный для созданя, ведения и эксплуатации БД многими пользователями.
База данных - совокупность связанных данных, организованных по определенным правилам, предусматривающим общие принципы описания, хранения и манипулирования, независимая от прикладных программ. База данных является информационной моделью предметной области. Обращение к базам данных осуществляется с помощью системы управления базами данных (СУБД).
Популярные СУБД — FoxPro, Access for Windows, Paradox.
Классификация СУБД:
По модели данных:
- Иерархические
- Сетевые
- Реляционные
- Объектно-реляционные
- Объектно-ориентированные
По организации хранения данных:
- локальные (все части локальной СУБД размещаются на одном компьютере)
- распределённые (части СУБД могут размещаться на двух и более компьютерах)
По способу доступа:
- файл-серверные
Файлы передаются на рабочие станции, где производится их обработка. На сервере происходит только хранение данных.
В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере. Ядро СУБД располагается на каждом клиентском компьютере. Доступ к данным осуществляется через локальную сеть. Синхронизация чтений и обновлений осуществляется посредством файловых блокировок. Преимуществом этой архитектуры является низкая нагрузка на ЦП сервера, а недостатком — высокая загрузка локальной сети.
На данный момент файл-серверные СУБД считаются устаревшими.
Примеры: Microsoft Access, Paradox, dBase.
- клиент-серверные
Сервер обеспечивает не только хранение данных, но и основной объем обработки данных.
Спецификой архитектуры клиент-сервер является использования языка запросов SQL.
Такие СУБД состоят из клиентской части (которая входит в состав прикладной программы) и сервера. Клиент-серверные СУБД, в отличие от файл-серверных, обеспечивают разграничение доступа между пользователями и мало загружают сеть и клиентские машины. Сервер является внешней по отношению к клиенту программой, и по надобности его можно заменить другим. Недостаток клиент-серверных СУБД в самом факте существования сервера (что плохо для локальных программ — в них удобнее встраиваемые СУБД) и больших вычислительных ресурсах, потребляемых сервером.
Примеры: Firebird, Interbase, IBM DB2, MS SQL Server, Sybase, Oracle, PostgreSQL, MySQL, ЛИНТЕР, MDBS.
- встраиваемые
Встраиваемая СУБД — библиотека, которая позволяет унифицированным образом хранить большие объёмы данных на локальной машине. Доступ к данным может происходить через SQL либо через особые функции СУБД. Встраиваемые СУБД быстрее обычных клиент-серверных и не требуют установки сервера, поэтому востребованы в локальном ПО, которое имеет дело с большими объёмами данных (например, геоинформационные системы).
Примеры: OpenEdge, SQLite, BerkeleyDB, один из вариантов Firebird, один из вариантов MySQL, Sav Zigzag, Microsoft SQL Server Compact, ЛИНТЕР.
Типовые функции СУБД: хранение, поиск данных; обеспечение доступа из прикладных программ и с терминала конечного пользователя; преобразование данных; словарное обеспечение БД; импорт и экспорт данных из(в) файлов ОС ЭВМ.
* управление данными во внешней памяти (на дисках);
* управление данными в оперативной памяти с использованием дискового кэша;
* журнализация изменений, резервное копирование и восстановление базы данных после сбоев;
* поддержка языков БД (язык определения данных, язык манипулирования данными).
СУБД организует хранение информации таким образом, чтобы ее было удобно:
* просматривать,
* пополнять,
* изменять,
* искать нужные сведения,
* делать любые выборки,
* осуществлять сортировку в любом порядке.
СУБД обеспечивают правильность, полноту и непротиворечивость данных, а также удобный доступ к ним.
Типовая структура СУБД: ядро, обрамление, утилиты, интерпретатор/компилятор пользовательского языка манипулирования данными.
Обычно современная СУБД содержит следующие компоненты:
* ядро, которое отвечает за управление данными во внешней и оперативной памяти, и журнализацию,
* процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода,
* подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД
* а также сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
В ранних СУБД поддерживалось несколько специализированных по своим функциям языков. Чаще всего выделялись два языка - язык определения схемы БД (SDL - Schema Definition Language) и язык манипулирования данными (DML - Data Manipulation Language). SDL служил главным образом для определения логической структуры БД, т.е. той структуры БД, какой она представляется пользователям. DML содержал набор операторов манипулирования данными, т.е. операторов, позволяющих заносить данные в БД, удалять, модифицировать или выбирать существующие данные.
В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured Query Language).
Среда конечного пользователя.
Иерархия представления архитектуры системы обработки данных
| Уровень архитектуры системы обработки данных |
Компоненты системы обработки данных |
|||
| Интерфейсы |
Средства обработки данных |
Представление и хранение данных |
Коммуникации |
|
| Среда для конечного пользователя и инструментарий прикладного программиста |
Генераторы форм и отчетов |
Утилиты и библиотеки |
Языки программирования 4GL |
OSI. Прикладной уровень |
| Языки программные и командные языки (оболочки) |
Прикладные программы |
Языки запросов СУБД |
OSI. Уровни сессий и представительный |
|
| Операционная система |
Средства оконного интерфейса |
Верхний уровень ОС (организация процесса обработки) |
Средства доступа к среде хранения |
OSI. Транспортный уровень |
| Драйверы |
Ядро операционной системы |
Файловая система |
OSI. Сетевой уровень |
|
| Оборудование |
Системные интерфейсы (в т.ч. организация ввода-вывода) |
Процессоры (система команд) |
Организация памяти |
OSI. Уровень передачи данных |
| Периферийные устройства |
Системная шина |
Шины (интерфейс) массовой памяти |
OSI. Физический уровень |
Работа пользователя с программными продуктами должна по возможности быть комфортной и осуществляться в соответствующей программно-технической среде (тип процессора, объем оперативной и внешней памяти, платформа сетевой и локальной операционной системы и др.).
Для работы пользователя большое значение имеет пользовательский интерфейс (вид, размер и местоположение основного экрана, функции обработки, доступные через систему меню, панели инструментов и т.п.). Как правило, интерфейс прикладных программных продуктов строится по типу графического, ориентированного на среду Windows (или Macintosh) интерфейса с развитыми элементами управления: командные кнопки, выпадающие меню, переключатели и т.п.
Программные продукты должны гарантировать надежную и безопасную работу как для компьютера, так и для информационной системы пользователя (сохранность устройств компьютера, программного обеспечения, хранимых данных). В значительной степени это достигается наличием в составе программного продукта контекстно-зависимой помощи и обучающих систем, демоверсий, раскрывающих функциональные возможности и технологию работы программного продукта, специальных программных решений по обеспечению сохранности программ и данных, антивирусной защиты и др.
Прикладные программные продукты автоматизируют деятельность специалистов (экономистов, менеджеров, бухгалтеров, агентов и т.д.) предметных областей. Сформировалась тенденция на создание автоматизированных рабочих мест - АРМ, полностью поддерживающих всю профессиональную деятельность конечного пользователя в компьютерной среде.
Тенденция развития прикладных программных продуктов состоит также в создании инструментальных средств конечногопользователя .Инструментальные средства подобного типа предназначены для совершенствования функций обработки, создания новых приложений силами конечного пользователя.
Front-end-процессор.
Коммуникационный процессор
Коммуникационное устройство, связанное с главным компьютером, управляющим линиями связи и передачей данных по сети. Коммуникационный процессор используется для обработки передаваемой информации, контроля и устранения ошибок, кодирования сообщений и т.п.
Back-end-процессор.
вспомогательный процессор, спецпроцессор
Процессор, который очень быстро выполняет одну специализированную задачу, освобождая главный процессор для другой, более важной работы.
Новейшие направления в области создания технологий программирования. Программирование в средах современных информационных систем: создание модульных программ, элементы теории модульного программирования, объектно-ориентированное проектирование и программирование. Объектно-ориентированный подход к проектированию и разработке программ: сущность объектно-ориентированного подхода, объектный тип данных, переменные объектного типа, инкапсуляция, наследование, полиморфизм, классы и объекты. Логическое программирование. Компонентное программирование.