| Скачать .docx |
Дипломная работа: Разработка методов мажоритарного декодирования с улучшенными вероятностно-временными характеристиками
Дипломная работа
«Разработка методов мажоритарного декодирования с улучшенными вероятностно-временными характеристиками»
Проблема обеспечения безошибочности (достоверности) передачи информации в сетях имеет очень важное значение. Если при передаче обычной телеграммы возникает в тексте ошибка или при разговоре по телефону слышен треск, то в большинстве случаев ошибки и искажения легко обнаруживаются по смыслу. Но при передаче данных одна ошибка (искажение одного бита) на тысячу переданных сигналов может серьезно отразиться на качестве информации.
Существует множество методов обеспечения достоверности передачи информации (методов защиты от ошибок), отличающихся по используемым для их реализации средствам, по затратам времени на их применение на передающем и приемном пунктах, по затратам дополнительного времени на передачу фиксированного объема данных (оно обусловлено изменением объема трафика пользователя при реализации данного метода), по степени обеспечения достоверности передачи информации. Практическое воплощение методов состоит из двух частей – программной и аппаратной. Соотношение между ними может быть самым различным, вплоть до почти полного отсутствия одной из частей.
Выделяют две основные причины возникновения ошибок при передаче информации в сетях:
• сбои в какой-то части оборудования сети или возникновение неблагоприятных объективных событий в сети (например, коллизий при использовании метода случайного доступа в сеть). Как правило, система передачи данных готова к такого рода проявлениям и устраняетих с помощью планово предусмотренных средств;
• помехи, вызванные внешними источниками и атмосферными явлениями. Помехи – это электрические возмущения, возникающие в самой аппаратуре или попадающие в нее извне. Наиболее распространенными являются флуктуационные (случайные) помехи. Они представляют собой последовательность импульсов, имеющих случайную амплитуду и следующих друг за другом через различные промежутки времени. Примерами таких помех могут быть атмосферные и индустриальные помехи, которые обычно проявляются в виде одиночных импульсов малой длительности и большой амплитуды. Возможны и сосредоточенные помехи в виде синусоидальных колебаний. К ним относятся сигналы от посторонних радиостанций, излучения генераторов высокой частоты. Встречаются и смешанные помехи. В приемнике помехи могут настолько ослабить информационный сигнал, что он либо вообще не будет обнаружен, либо искажен так, что «единица» может перейти в «нуль» и наоборот.
Трудности борьбы с помехами заключаются в беспорядочности, нерегулярности и в структурном сходстве помех с информационными сигналами. Поэтому защита информации от ошибок и вредного влияния помех имеет большое практическое значение и является одной из серьезных проблем современной теории и техники связи.
Среди многочисленных методов защиты от ошибок выделяются три группы методов: групповые методы, помехоустойчивое кодирование и методы защиты от ошибок в системах передачи с обратной связью.
Из групповых методов получили широкое применение мажоритарный метод, реализующий принцип Вердана, и метод передачи информационными блоками с количественной характеристикой блока.
Суть мажоритарного метода, давно и широко используемого, состоит в следующем. Каждое сообщение ограниченной длины передается несколько раз, чаще всего три раза. Принимаемые сообщения запоминаются, а потом производится их поразрядное сравнение. Суждение о правильности передачи выносится по совпадению большинства из принятой информации методом «два из трех».
Работа Хэмминга явилась катализатором цепной реакции выдвижения новых идей в области декодирования, которая началась с 1954 года. Американский ученый И.С. Рид был первым, кто использовал мажоритарное декодирование кодов Рида – Маллера. При мажоритарном декодировании для каждого информационного символа формируется нечетное число оценок путем сложения по модулю 2 определенных комбинаций символов принятого кода. Решение об истинном значении принятого символа принимается по мажоритарному принципу – если большее количество оценок равно 1, то принимается именно такое решение. В 1963 году Дж.Л. Месси [13, 25] установил общие принципы построения и декодирования подобных кодов. Достоинством мажоритарно декодируемых кодов является чрезвычайная простота и быстродействие алгоритмов декодирования. Однако класс таких кодов весьма мал, и эти коды слабее других. Значительный вклад в создание теории построения мажоритарно декодируемых кодов внесли в 1965 году советские ученые В.Д. Колесник и Е.Т. Мирончиков. [7, 35]
Использование методов передачи, основанных на применении мажоритарного декодирования двоичных последовательностей, направлено на решение ряда задач, которые можно свести к улучшению характеристик каналов передачи данных и к созданию новых методов кодирования.
1. Повышение эффективности использования каналов передачи данных (повышение вероятностно-временных характеристик декодирования)
Изложение мажоритарного метода декодирования будет неполным без рассмотрения вопросов технической реализации, анализа и синтеза алгоритмов передачи данных, а также сопоставления с известными методами по основным характеристикам, описывающим эффективность каналов передачи данных.
Рассматривая задачу повышения эффективности использования каналов передачи данных, можно выделить три важнейшие проблемы:
1. Проблему обеспечения требуемой верности Ртр , принятой и выдаваемой потребителю после декодирования информации. При этом будем понимать, что вероятность ошибки Рош в такой информации не должна превышать при работе по любому из используемых каналов наперед заданной величины Ртр . Обычно задачу обеспечения требуемой верности принятой информации определяют как «повышение верности», т.е. как снижение вероятности Рош относительно вероятности ошибки в используемом дискретном канале, описываемой вероятностью искажения символа Р0 . Для этой цели используют коды с обнаружением ошибок, с помощью которых выявляют и бракуют кодовые последовательности с ошибками, а также коды с исправлением t и менее ошибок. В случае обнаружения ошибок величина Рош определяется вероятностью того, что используемый код не бракует искаженную кодовую последовательность (не обнаруживает ошибку) при работе по данному каналу или классу каналов связи. Вопрос о гарантии требуемой величины Ртр сводится к анализу обнаруживающей способности используемого кода в рассматриваемом классе каналов связи и к методам выбора типа и параметров (синтезу) кода, обеспечивающего Ртр в любом из используемых каналов связи.
Широко используемые для исправления ошибок двоичные и q-ичные алгебраические коды с кодовым расстоянием d исправляют все векторы ошибок с весом не более t=(d-1)/2. С вероятностью ![]() , где P (i, n) – вероятность возникновений ровно i ошибок в кодовом блоке длиной п, такой код выдает потребителю информацию без ошибок. При числе ошибочных символов S>t может происходить либо отказ от декодирования, когда декодер выдает с вероятностью Рст
сигнал о необходимости стирания кодового блока, либо имеет место декодирование с ошибкой, после чего искаженная информация с числом искаженных символов S'≶S выдается потребителю с вероятностью Рош
.
, где P (i, n) – вероятность возникновений ровно i ошибок в кодовом блоке длиной п, такой код выдает потребителю информацию без ошибок. При числе ошибочных символов S>t может происходить либо отказ от декодирования, когда декодер выдает с вероятностью Рст
сигнал о необходимости стирания кодового блока, либо имеет место декодирование с ошибкой, после чего искаженная информация с числом искаженных символов S'≶S выдается потребителю с вероятностью Рош
.
Если считать, что код не исправляет ошибок кратности S>t, то Рст
+Рош
=Р2
=![]() . В этом случае проблема обеспечения требуемой верности передачи состоит из решения следующих задач:
. В этом случае проблема обеспечения требуемой верности передачи состоит из решения следующих задач:
а) определения значений вероятностей Рош и Рст для конкретного кода и различных характерных интервалов кратности ошибки от t+1 до d и выше;
б) оценки свойств дискретного канала путем описания его параметров, простейшими из которых являются значения P (i, n);
в) разработки в алгоритме декодирования надежного механизма выявления ситуации неисправляемых ошибок и выхода в отказ от декодирования.
Рисунок 1 – иллюстрирует отличие задачи обеспечения требуемой верности (кривая 1) от задачи повышения верности (кривая 2). При повышении верности обеспечивается Рош <Ртр только при Р0 <Ргр . При обеспечении требуемой верности любое качество канала (вплоть до его обрыва) не увеличивает вероятность Рош выше Ртр , сводя все случаи невозможности правильного декодирования блока к отказу от декодирования, сохраняя способность выдачи потребителю информации при улучшении состояния канала, при. котором методы приема и обеспечения требуемых вероятностно-временных характеристик обмена информации (проблема 2) приводят к успешному декодированию и выдаче информации потребителю. Для такого канала полная группа событий содержит следующие события:
· правильный прием кодового блока, который не был искажен требуемой в канале или в котором правильно исправлена ошибка с вероятностью Рп.пр ;
· произошла ошибка декодирования и кодовый блок с ошибкой выдан потребителю с вероятностью Рош ;
· произошел отказ от декодирования с вероятностью Ротк .
Отнеся число исходов каждого события к числу переданных блоков, имеем Рп.пр +Рош +Ротк =1. Учитывая, что информация выдается потребителю в первых двух случаях, вероятность приема Рпр =Рп.пр +Рош .

Рис. 1. Сопоставление задач повышения и обеспечения требуемой верности передачи
Для любого кода, обеспечивающего требуемую верность, можно рассматривать две области: область приема и область отказа. В области приема вероятность ошибки равна нулю. Для кодов с обнаружением ошибки это случай, когда кодовый блок не искажен с вероятностью Р (0, п), а для кодов с исправлением ошибок – это возникновение не более t ошибок. При этом Рош =0; Рпр =Рп.пр ; Ротк =0. В области отказа (при кратности ошибки, превышающей t) Рп.пр =0; Рпр =Рош ; Ротк =1-Рош . Отметим что для каждой из этих областей понятие финальной вероятности ошибки Рош.ф как отношения числа блоков с ошибкой декодирования к числу принятых блоков является бессмысленным. Действительно, по определению, в области приема Рош.ф =0. В области отказа прием блока возможен только при ошибочном его декодировании, поэтому Рош.ф =1, причем для любого кода, независимо от его избыточности и того, какую часть ошибок он обнаруживает или исправляет.
2. Проблему обеспечения высоких вероятностно-временных характеристик обмена информацией или проблему помехоустойчивости. Эта проблема дополняет и делает одновременно более сложным решение первой проблемы, так как если не требовать высоких вероятностно-временных характеристик обмена, то для решений первой проблемы можно вообще ничего не принимать и стирать все принятые кодовые блоки.
В качестве вероятностно-временных характеристик (ВВХ) будем в первую очередь рассматривать две главные характеристики:
а) относительную скорость передачи информации по каналам с обратной связью R=(k/n) (1-Рст ), где п, k– параметры используемого (п, k) – кода; Рст – вероятность стирания очередного кодового блока из-за обнаружения в нем неисправляемых соответствующим кодом ошибок или из-за особенностей используемого алгоритма обратной связи;
б) вероятность доведения сообщения заданного объема V в определенных условиях за время T-Рдов (V, Т). Эта характеристика предполагает доведение сообщения с заданной вероятностью Ртр и может использоваться в первую очередь в симплексных каналах, а также в дуплексных каналах, используемых для темповой передачи информации, или передачи в реальном масштабе времени.
3. Проблему сложности реализации устройств, осуществляющих наиболее трудоемкую обработку дискретной информации, к которой можно отнести кодирование и декодирование помехоустойчивых кодов, в том числе при использовании параллельных каналов или многократной передачи одного и того же сообщения. К этой же проблеме следует отнести задачу унификации аппаратуры передачи данных, имея при этом в виду создание таких методов помехоустойчивого кодирования и передачи информации и реализующей их аппаратуры, которые могли бы путем изменения перестраиваемых параметров аппаратуры обеспечивать работу по дуплексным и симплексным каналам, с исправлением и обнаружением ошибок помехоустойчивыми кодами, использование широкого набора типов дискретных каналов с различной интенсивностью и распределением потоков ошибок. При этом очень важно, чтобы замена дискретного канала требовала минимальных сведений о его качестве и потоках ошибок в канале. В самом лучшем случае сведений о потоке ошибок не требуется вообще, а решения о годности используемого канала вырабатываются на основе критериев, заложенных в алгоритме передачи информации (алгоритме декодирования) кода и связанных с невозможностью выполнения требуемых значений приведенных выше основных ВВХ.
Рассмотрим свойства наиболее широко применяемых на практике помехоустойчивых кодов с точки зрения поставленных выше проблем.
Обнаружение ошибок с помощью блоковых (п, k) – кодов характеризуется меньшей чем исправление ошибок двоичными кодами, зависимостью вероятности необнаруженной ошибки Рош от свойств исходного дискретного канала. Такие коды, имеющие кодовое расстояние d, по определению кода обнаруживают все ошибки веса t<d с числом необнаруженных ошибок, равным числу ненулевых кодовых слов 2k -1. Для наиболее конструктивных из этого класса циклических кодов известно и широко употребляется обнаружение ошибок за счет деления полинома, отображающего кодовую последовательность, на фиксированный порождающий полином кода g(X) степени п.
То есть среди известных кодов при аппаратной реализации циклические коды с обнаружением ошибок в наибольшей степени решают первую и третью проблемы. Известны попытки использовать такие коды в симплексных каналах в режиме многократной передачи кодового блока, кодированного циклическим кодом, а также мажоритарной обработкой одноименных двоичных символов различных блоков.
Однако нельзя строго утверждать, что блоковые коды с обнаружением ошибок обеспечивают Ртр в произвольном канале. На практике для оценки вероятности необнаруженной ошибки блоковыми кодами [11, 38] пользуются двумя основными выражениями:
Рош ≈ P (≥1, n)•2-( n - k ) , (1)
Рош ≈ P (≥d, n)•2-( n - k ) (2)
Обе эти оценки приемлемы для инженерных расчетов для относительно хороших каналов и кодов с достаточно большим числом избыточных символов r= n-k, но каждая обладает недостатками, связанными с невозможностью учета свойств конкретных кодов с их спектрами весов. Формула (1) правильно отражает число векторов необнаруженной ошибки и их долю от всех 2n векторов длины п, но не учитывает того обстоятельства, что все ошибки кратности от 1 до d-1 и от п-d+1 до п такими кодами всегда обнаруживаются.
Формула (2), напротив, учитывает частично последнее обстоятельство для ошибки кратности до d-1 включительно, но дает заведомо оптимистический результат, так как предполагает, что число необнаруженных ошибок менее 2k -1, что неверно. Действительно, формула (2) предполагает отбрасывание из 2n векторов ошибки тех векторов, вес которых менее d и учитывает только (2-( n - k ) ) – ю долю остальных векторов, что меньше 2k -1.
Помехоустойчивые коды для обеспечения требуемой верности передаваемой информации имеют в настоящее время весьма широкую сферу применения. Развитие и широкое использование сетей ЭВМ, информационно-вычислительных сетей (ИВС), глобальных информационных сетей требуют разработки эффективных методов передачи и защиты дискретной информации от ошибок в каналах связи. Стремление упорядочить процедуры взаимодействия абонентов в ИВС явилось причиной создания Международной организацией стандартов (МОС) так называемой эталонной модели взаимодействия открытых систем (ЭМВОС). Иерархическое разделение функций обработки передаваемой информации привело к использованию понятия уровня, выполняющего определенную логическую функцию. Совокупность правил (процедур) взаимодействующих объектов ИВС одноименных уровней называют протоколом. Рекомендованная в ЭМВОС совокупность протоколов содержит семь следующих уровней: физический, уровень канала ПД или звена данных, сетевой, транспортный, сеансовый, представительный и прикладной. Причем уровень канала ПД имеет всегда, а транспортный и прикладной уровни, как правило, средства контроля верности принимаемой информации с помощью помехоустойчивого кода, допускающего простую программную реализацию в ЭВМ.
При обмене информацией в сетях ЭВМ, использующих на ребрах сети различные по физической природе и качеству канала связи, методы защиты от ошибок должны обеспечивать требуемую верность циркулирующих данных при работе по любому из каналов связи. Подобные требования предъявляются к каналам ПД, используемым в системах телемеханики и телеуправления, в АСУ различного типа. Наиболее сложной является задача обеспечения требуемой верности при работе по каналам низкого качества, когда вероятность искажения двоичного символа P0 >10-2 , и в каналах без обратной связи при использовании кодов с исправлением ошибок.
По указанным выше причинам представляется актуальной проблема создания методов защитыот ошибок для каналов ПД и других протокольных уровней, основанных на применении кодов, обеспечивающих заданную вероятность ошибки при использовании произвольных дискретных каналовсвязи с обеспечением высоких ВВХ обмена при простой реализации алгоритмов кодирования и декодирования.
Более сильная постановка задачи состоит в построении таких каналов ПД, в которых контролируется достигаемая верность и потребителю информации предоставляется возможность оперативно менять требования по гарантированной верности, принимая сообщение с нужной верностью и отказываясь от тех сообщений, верность которых не удовлетворяет потребителя информации.
2. Помехоустойчивое кодирование информации
Кодирование в широком смысле слова можно определить как процедуру взаимно однозначного отображения сообщений в сигналы, иными словами, преобразования сообщения в код. Декодированием называется обратный процесс. Таблица соответствия между совокупностью используемых сообщений и кодовыми комбинациями, которые их отображают, называется первичным кодом. В этом случае кодовая комбинация содержит kэлементов. Кодовая комбинация избыточного кода содержит nэлементов, где n > k.
Способность кода обнаруживать и исправлять ошибки обусловлена наличием избыточных элементов в кодовой комбинации r = n– k.
В этом случае общее число возможных кодовых комбинаций будет
![]() , число разрешенных комбинаций
, число разрешенных комбинаций ![]() , а запрещенных
, а запрещенных ![]() .
.
Искажение информации в процессе передачи сводится к тому, что некоторые из переданных элементов заменяются другими – неверными. При этом для систематических кодов из ![]() случаев передачи возможно
случаев передачи возможно ![]() случаев перехода в другие разрешенные комбинации, что соответствует необнаруживаемым ошибкам, и
случаев перехода в другие разрешенные комбинации, что соответствует необнаруживаемым ошибкам, и ![]() случаев перехода в неразрешенные комбинации, которые могут быть обнаружены [5, 65]. Следовательно, часть опознанных ошибок от общего числа возможных случаев передачи составит
случаев перехода в неразрешенные комбинации, которые могут быть обнаружены [5, 65]. Следовательно, часть опознанных ошибок от общего числа возможных случаев передачи составит
![]() .
.
Например, при использовании одного избыточного элемента (r= 1) часть опознанных ошибок составляет
![]() .
.
Для того чтобы искаженная кодовая комбинация была опознана с наименьшей ошибкой, необходимо чтобы остальные ![]() запрещенных комбинаций были разбиты на
запрещенных комбинаций были разбиты на ![]() непересекающихся множеств
непересекающихся множеств ![]() , причем
, причем ![]() кодовые комбинации, принадлежащие
кодовые комбинации, принадлежащие ![]() , должны в наибольшей степени быть похожими на i-ю разрешенную комбинацию и должны быть приписаны ей.
, должны в наибольшей степени быть похожими на i-ю разрешенную комбинацию и должны быть приписаны ей.
Процедура опознания искаженной кодовой комбинации в этом случае будет состоять в ее сравнении со всеми ![]() кодовыми комбинациями. Когда произойдет совпадение с одной из комбинаций, принадлежащих
кодовыми комбинациями. Когда произойдет совпадение с одной из комбинаций, принадлежащих ![]() , осуществится отождествление искаженной комбинации с i-й разрешенной, т.е. исправление ошибки. Ошибка будет исправлена в
, осуществится отождествление искаженной комбинации с i-й разрешенной, т.е. исправление ошибки. Ошибка будет исправлена в ![]() случаях из всех возможных. Отношение числа исправляемых кодом ошибочных кодовых комбинаций к числу обнаруживаемых ошибочных комбинаций равно [5, 67]:
случаях из всех возможных. Отношение числа исправляемых кодом ошибочных кодовых комбинаций к числу обнаруживаемых ошибочных комбинаций равно [5, 67]:
![]() .
.
Степень отличия любых двух кодовых комбинаций характеризуется расстоянием между ними в смысле Хэмминга, называемым кодовым расстоянием. Оно выражается числом элементов, в которых комбинации отличаются одна от другой, и обозначается через d. Минимальное количество элементов, в которых все комбинации кода отличаются друг от друга, называется минимальным кодовым расстоянием d0
. Минимальное кодовое расстояние – параметр, определяющий помехоустойчивость избыточного кода. В общем случае для обнаружения всех ошибок до ![]() -кратных включительно минимальное кодовое расстояние
-кратных включительно минимальное кодовое расстояние
![]() . (3)
. (3)
Минимальное кодовое расстояние, необходимое для одновременного обнаружения и исправления ошибок:
![]() , (4)
, (4)
где t– число исправляемых ошибок.
Для кодов, только исправляющих ошибки:
![]() (5)
(5)
Соотношения (3), (4) и (5) определяют лишь кратность гарантийно обнаруживаемых и исправляемых ошибок. Обычно коды обнаруживают и исправляют часть ошибок и более высокой кратности.
К наиболее употребляемым избыточным кодам можно отнести блоковые и непрерывные коды.
Блоковые коды характеризуются тем, что исходная непрерывная информационная последовательность разделяется на отдельные части, каждая из которых кодируется отдельно и независимо от других частей, образуя раз решенные слова избыточного кода.
Равномерные блоковые коды характеризуются одинаковой длиной разрешенных кодовых слов, в отличие от неравномерных кодов.
В непрерывных кодах исходная информационная последовательность не разделяется на части, а кодируется непрерывно, причем избыточные элементы формируются на определенных позициях между информационными. Равномерные блоковые коды подразделяются на линейные и нелинейные.
Линейные коды образуют наиболее обширный подкласс кодов и определяются тем, что сумма по модулю для двух и более разрешенных комбинаций кода дает комбинацию этого же кода.
Нелинейные коды не обладают этим свойством. Примером нелинейных кодов является код с постоянным весом, применяемый в телеграфии. В некоторых случаях линейные коды называют групповыми, что обусловлено математическим описанием подмножества разрешенных кодовых слов длины nкак подгруппы в группе всех слов длины n. Линейный код, в котором информационные и проверочные элементы разделены и расположены на строго определенных позициях, называется систематическим, в отличие от несистематических кодов, в которых нельзя в явном виде выделить информационные и проверочные элементы. Систематические коды получили наибольшее распространение. Систематические коды, как правило, обозначаются (n, k) – кодами и включают: коды с проверкой на четность, коды Хэмминга, циклические коды, коды с повторением, итеративные коды, каскадные, коды Рида–Малера, дециклические коды и много других [3, 32].
В информационных системах для передачи коротких команд управления нашли наибольшее применение циклические коды; для обнаружения ошибок при встроенном контроле аппаратуры обработки – коды с одной проверкой на четность; при хранении информации – коды с повторением; при непрерывной передаче больших массивов измерительных данных – сверточные коды. Для повышения эффективности обработки избыточных кодов развиваются различные квазиоптимальные методы декодирования, использующие дополнительную информацию о ненадежных элементах передаваемых данных.
3. Циклические коды
3.1 Задание циклических кодов
Наиболее распространенным подклассом линейных кодов являются циклические коды. Это обусловлено относительно простым построением кодера и декодера, обнаруживающего ошибки, при достаточно высоких корректирующих способностях кода. Эти коды позволяют преодолеть некоторые трудности, связанные с технической реализацией, свойственные линейным кодам. В информационной системе циклические коды предпочтительны для передачи сообщений небольшой длины, например, команд управления объектами.
Алгебраическая структура циклических кодов впервые была исследована Боузом, Чоудхури и Хоквингемом, поэтому они известны как БЧХ-коды. Эти коды характеризуются следующими свойствами [7, 110]: длиной кодовых последовательностей
![]() (6)
(6)
где т = 1,2,3,…;
числом проверочных элементов, не превышающим величины ![]() , т.е.
, т.е.
![]() (7)
(7)
способностью обнаруживать все пакеты ошибок длины
![]() (8)
(8)
циклическим сдвигом разрешенной комбинации кода, приводящим к образованию разрешенной комбинации; этого же кода.
Возможно задание циклических БЧХ-кодов при помощи порождающих или проверочных матриц аналогично общим правилам, построения линейных кодов. Однако воспользуемся более простыми инженерными методиками, базирующимися на алгебраических понятиях. В этом случае более удобной является запись кодовых комбинаций в виде полинома переменной х:
![]()
Коэффициенты ai представляют собой цифры данной системы счисления. В двоичной системе счисления коэффициенты могут принимать одно из двух значений 0 или 1. Так, двоичное четырехразрядное число 1001 может быть записано в виде полинома
![]()
Это выражение устанавливает однозначное соответствие между двумя формами записи кодовых комбинаций.
Циклические коды образуются умножением каждой комбинации – элементного безызбыточного кода, выраженной в виде многочлена G (х), на образующий полином Р (х) степени (п – k). При этом умножение производится по обычным правилам с приведением подобных членов по модулю два [6, 98]. Следовательно, в случае отсутствия ошибок любая разрешенная кодовая комбинация циклического кода должна разделиться на образующий полином Р (х) без остатка. Появление остатка от деления указывает на наличие ошибок в кодовой комбинации. При этом гарантийно обнаруживаются ошибки, определяемые выражениями (7) и (8).
Кроме того, обнаруживается большая часты ![]() ошибок более высокой кратности.
ошибок более высокой кратности.
Широкое применение нашел другой метод, который в отношении степени избыточности и помехоустойчивости приводит к построению эквивалентного циклического кода. В соответствии с этим методом каждая кодовая комбинация первичного кода G (х) умножается на одночлен Xn - k . Это эквивалентно приписыванию справа к комбинации G (х), записанной в двоичной форме, (п – k) нулей. Произведение G(х) xn - k делится на образующий полином Р (х) степени (п – k):
![]() (9)
(9)
где Q (х) – частное от деления такой же степени, как и G(х); R (х) – остаток.
Так как частное Q (х) имеет такую же степень, как и кодовая комбинация G (х), то, следовательно, Q (х) является кодовой комбинацией этого же простого k-элементного кода.
Умножая обе части равенства на Р (х) получим:
![]() (10)
(10)
Здесь знак минус заменен знаком плюс, так как сложение и вычитание по модулю два – операции эквивалентные.
Из полученного равенства видно, что кодовая комбинация циклического кода может быть получена двумя эквивалентными методами, причем второй метод приводит к построению систематического циклического кода, в котором информационные и проверочные элементы разделены. А так как информационные элементы непосредственно принимаются из канала связи, то эффект размножения ошибок в информационной части кодовой комбинации будет отсутствовать.
3.2 Коды с постоянной четностью единиц
Наименьшей избыточностью обладают циклические (k+ 1, k) – коды, имеющие один проверочный элемент и получившие название кодов с постоянной четностью единиц. Построение этих кодов осуществляется при помощи образующего полинома
![]()
методами, изложенными в п. 4.1. При этом разрешенные кодовые слова циклического (k+ 1, k) – кода во всех случаях содержат четное число единиц. Докажем это свойство, используя метод построения циклических кодов, основанный на умножении комбинаций G(х) на образующий полином
Р (х) = х + 1.
Так как образующий полином Р (х) является двучленом, то произведение G(х) Р (х) независимо от числа членов первого сомножителя
G(х) всегда будет содержать четное число членов.
Доказанное свойство определяет метод построения кодов с постоянной четностью единиц, наиболее пригодный для технической реализации и приводящий к получению кодовых комбинаций систематического кода.
Коды с постоянной четностью единиц позволяют обнаружить любые ошибки нечетной кратности, т.е. для этих; кодов ![]() = 1,3,5,…, l, где l = kдля нечетных значений kи l = k + 1 для четных значений k.
= 1,3,5,…, l, где l = kдля нечетных значений kи l = k + 1 для четных значений k.
3.3 Помехоустойчивость циклических кодов
Циклические коды можно использовать в следующих режимах: для исправления ошибок; для обнаружения ошибок; для исправления и обнаружения ошибок.
Достоверность передаваемой информации. Наиболее предпочтительным является использование циклических кодов в режиме обнаружения ошибок, так как при этом достигается наибольшая достоверность передаваемой информации, определяемая вероятностью необнаруженных ошибок:
![]() (11)
(11)
где ![]() – вероятность ошибок кратности, большей чем
– вероятность ошибок кратности, большей чем ![]() ;
; ![]() – кратность гарантийно обнаруживаемых циклическим кодом ошибок;
– кратность гарантийно обнаруживаемых циклическим кодом ошибок;![]() - коэффициент, учитывающий долю необнаруживаемых ошибок более высокой кратности, чем
- коэффициент, учитывающий долю необнаруживаемых ошибок более высокой кратности, чем ![]() .
.
C учетом выражения (11) получим
![]() (12)
(12)
При пР0
![]() 1, ограничиваясь первым членом суммы, получим приближенное выражение, пригодное для инженерных расчетов:
1, ограничиваясь первым членом суммы, получим приближенное выражение, пригодное для инженерных расчетов:
![]() (13)
(13)
При передаче информации в канале связи с группирующимися ошибками, определяя ![]() , и подставляя в (11), получим приближенное выражение
, и подставляя в (11), получим приближенное выражение
 (14)
(14)
Для точных расчетов вероятность ![]() должна определяться из выражения (3).
должна определяться из выражения (3).
Использование циклических кодов для исправления ошибок приводит к снижению достоверности передаваемой информации, которая может быть определена по формулам (12), (13) и (14), если исключить коэффициент ![]() и вместо параметра
и вместо параметра ![]() подставить параметр t, который определяет кратность гарантийно исправляемых циклическим кодом ошибок и связан с
подставить параметр t, который определяет кратность гарантийно исправляемых циклическим кодом ошибок и связан с ![]() соотношением
соотношением
![]() . (15)
. (15)
Режим одновременного исправления и обнаружения ошибок по достигаемой достоверности занимает промежуточное положение между рассмотренными режимами. Вероятность необнаружения ошибок в этом случае может быть вычислена по формулам (11) – (13), если параметр ![]() уменьшить на величину t.
уменьшить на величину t.
В режиме исправления ошибок достоверность снижается по сравнению с режимом обнаружения ошибок. Это позволяет сделать вывод, что наиболее рациональными следует считать такие системы передачи дискретной информации, в которых циклические коды используются для обнаружения ошибок.
В некоторых случаях, когда используются каналы связи достаточно низкого качества, находит применение режим одновременного исправления и обнаружения ошибок. Это позволяет уменьшить потери информации и увеличить относительную скорость передачи.
Потери информации. Потери информации имеют место в том случае, когда возникает ошибка, необнаруживаемая циклическим кодом, поэтому для режима обнаружения ошибок можно записать, что
![]() (16)
(16)
где Рош – вероятность появления любой ошибки в кодовой комбинации. Так как в реальных системах Рн.о. <Рош, то можно положить, что
![]() (17)
(17)
В режиме одновременного исправления и обнаружения ошибок исправляются ошибки до t– кратных включительно. Поэтому потери будут обусловлены абсолютным большинством ошибок, кратность которых превышает t, т.е.
![]() , (18)
, (18)
где![]() – вероятность появления i-кратных ошибок.
– вероятность появления i-кратных ошибок.
4. Мажоритарное декодирование циклических кодов
Декодирование циклических мажоритарных кодов с повторением. При декодировании циклических кодов, допускающих мажоритарную обработку, процесс декодирования может быть осуществлен только после приема всей комбинации циклического (п, k) – кода. Для кодов с повторением мажоритарная обработка заканчивается после приема всех повторений комбинации. Использование для помехоустойчивого кодирования сообщений одновременно циклических мажоритарных кодов и метода многократных повторений позволяет обеспечить требуемые характеристики по достоверности и надежности передачи информации при использовании каналов связи низкого качества.
На рис. 2 изображена функциональная схема декодирующего устройства для циклических мажоритарных кодов с повторением. Устройство содержит регистр сдвига 1, сумматоры по модулю два 2, распределитель 3, счетчики мажоритарных проверок 4 – 1, 4–2,…, 4 – k, блок запоминания 5, блок, сравнения 6 и дешифратор 7.
Регистр сдвига установлен для записи п элементов одной кодовой комбинации циклического (п, k) – кода и перезаписи комбинации по цепи обратной связи при формировании результатов мажоритарных проверок.
Сумматоры по модулю два 2 предназначены для вычисления мажоритарных проверок путем суммирования импульсов с различных ячеек регистра сдвига 1 с целью получения серии импульсов, из которых затем по большинству определяется значение информационного элемента. Входы сумматоров подключены к ячейкам регистра сдвига в соответствии с системой мажоритарных проверок для конкретного циклического кода.
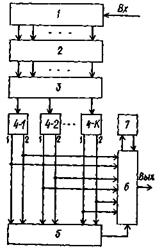
Рис. 2
Распределитель 3 служит для направления результатов мажоритарных проверок с выходов сумматоров в счетчик того информационного элемента, которому соответствуют эти проверки.
Счетчики мажоритарных проверок 4–1, 4–2,…. 4-k используются для подсчета результатов мажоритарных проверок. Они выполнены по схеме с несколькими порогами срабатывания. Каждый порог определяется числом принятых кодовых комбинаций, по результатам мажоритарных проверок которых вычисляются информационные элементы. В общем случае число счетчиков равняется числу информационных элементов k в исходной кодовой комбинации. Если l– число мажоритарных проверок для одного информационного элемента за одно повторение, то минимальный порог определится величиной 0,5l(l – четное) или 0,5 (l+ 1). где l – нечетное. За m повторений порог определится величиной 0,5 lm или 0,5 (1m + 1). За все N повторений порог определится величиной 0,5 lm или 0,5 (lm + 1). Так, для циклического (7,3) – кода с трехкратным повторением l = 4, минимальный порог за одно повторение равен двум, порог за два повторения равен четырем и порог за все повторения равен 6.

Рис. 3
При этом счетчик мажоритарных проверок для одного информационного элемента (рис. 3) будет состоять из трех двоичных разрядов и значение информационного элемента для минимального порога определится состоянием второго разряда счетчика после обработки первого повторения, для второго порога – состоянием третьего разряда счетчика после обработки двух повторений и для третьего порога за все повторения – состоянием второго и третьего разрядов счетчика после обработки трех повторений.
В частном случае порогов срабатывания может быть два: первый порог за одно или часть повторений определяет первый этап обработки, второй порог за все повторения определяет второй этап обработки.
Счетчики мажоритарных проверок 4–1, 4–2,…, 4-t выполнены по схеме с двумя порогами и соответственно имеют по два выхода.
Блок запоминания 5 служит для поочередного запоминания результатов мажоритарной обработки, соответствующих реализованным порогам срабатывания счетчиков 4–1, 4–2,…, 4-к.
Блок сравнения 6 первый результат мажоритарной обработки выдает для исполнения, сравнивает каждый последующий результат с предыдущим и при их несовпадении выдает сигнал на прекращение исполнения предыдущего решения и выдает для исполнения последующее решение.
Дешифратор 7 анализирует результаты мажоритарных обработок и при выявлении запрещенной комбинации блокирует ее выдачу до окончания приема всех повторений. К запрещенным комбинациям могут быть отнесены сообщения, исполнение которых приводит к необратимым процессам у получателя и которые не могут быть скорректированы последующими результатами мажоритарных проверок. В частном случае для систем, в которых отсутствуют запрещенные комбинации, дешифратор 7 будет отсутствовать. Работа устройства происходит следующим образом. Принимаемая n-разрядная кодовая комбинация вводится в регистр сдвига 1. Далее, в течение к тактов при помощи регистра сдвига 1 и сумматоров 2 формируются результаты мажоритарных проверок для каждого из к информационных элементов, которые через распределитель 3 вводятся в соответствующий счетчик мажоритарных проверок 4–1, 4–2,…, 4-k. Вся процедура декодирования осуществляется за время ![]() , где V– скорость модуляции для принимаемой кодовой комбинации. Аналогично обрабатывается каждое повторение циклического кода. После приема и обработки т повторений, определяющих первый порог срабатывания, информационные элементы с первых выходов счетчиков мажоритарных проверок поступают одновременно в блок запоминания 5 и блок сравнения 6. Из блока сравнения 6 декодированная комбинация поступает в дешифратор 7, который анализирует и не препятствует выдаче для исполнения разрешенной комбинации, или подачей сигнала в блок сравнения 6 блокирует выдачу запрещенной комбинации.
, где V– скорость модуляции для принимаемой кодовой комбинации. Аналогично обрабатывается каждое повторение циклического кода. После приема и обработки т повторений, определяющих первый порог срабатывания, информационные элементы с первых выходов счетчиков мажоритарных проверок поступают одновременно в блок запоминания 5 и блок сравнения 6. Из блока сравнения 6 декодированная комбинация поступает в дешифратор 7, который анализирует и не препятствует выдаче для исполнения разрешенной комбинации, или подачей сигнала в блок сравнения 6 блокирует выдачу запрещенной комбинации.
После приема и обработки m повторений, определяющих второй порог срабатывания, информационные элементы со вторых выходов счетчиков мажоритарных проверок поступают одновременно в блок запоминания 5 и блок сравнения 6. Поступившие информационные элементы вытесняют из блока запоминания 5 в блок сравнения 6 ранее запомненный результат. В блоке сравнения 6 сравниваются результаты первого и второго этапов обработки. При их совпадении продолжает исполняться сообщение, декодированное на первом этапе. При несовпадении блок сравнения 6 выдает сигнал на прекращение исполнения сообщения, декодированного на первом этапе и выдает для исполнения сообщение, декодированное на втором этапе. В случае имевшей место на первом этапе блокировки блок сравнения 6 выдает для исполнения сообщение, декодированное на втором этапе. Выбором соответствующего значения m обеспечивается то, что в абсолютном большинстве случаев сообщения, декодированные на первом и втором этапах, будут совпадать и время приема определится величиной
![]()
что в ![]() раз меньше, чем время приема в известных устройствах.
раз меньше, чем время приема в известных устройствах.
Если ![]() – реализуемое кодовое расстояние циклического мажоритарного М (n, k) – кода [7, 115], которое аналогично минимальному расстоянию, то кратность гарантийно исправляемых ошибок определяется соотношением
– реализуемое кодовое расстояние циклического мажоритарного М (n, k) – кода [7, 115], которое аналогично минимальному расстоянию, то кратность гарантийно исправляемых ошибок определяется соотношением
![]()
В общем виде реализуемое расстояние определяется выражением
![]() , причем
, причем ![]() .
.
Реализуемое кодовое расстояние, соответствующее т повторениям первого этапа обработки,
![]()
а кратность исправляемых ошибок
![]() (19)
(19)
Второй этап обработки характеризуется приемом N повторений, реализуемое кодовое расстояние которых
![]()
а кратность исправляемых ошибок
![]() (20)
(20)
Характеристики (19) и (20) позволяют определить достоверность информации первого и второго этапов обработки по методике (п. 3.3).
Таким образом, можно отметить, что наряду с разработанными процедурами обнаружения и исправления ошибок циклические коды хорошо совместимы с процедурой поэтапного принятия решений, что повышает эффективность их использования при передаче информации в информационных системах.
5. Мажоритарное декодирование кодов с повторением
5.1 Адаптивное мажоритарное декодирование кодов с повторением
Представляет интерес разработка мажоритарных кодирующих устройств, имеющих возможность перестраиваться в зависимости от качества каналов связи и вместе с тем сохраняющих простоту технической реализации. Рассмотрим некоторые из наиболее перспективных направлений построения такого типа устройств. [5, 57]
Определение метода. В соответствии с этим методом запоминают 1-ю посылку, сравнивают его со следующей и дополнительно запоминают позиции несовпадающих элементов. При приеме каждого последующего повторения производят его сравнение и выявляют несовпадения с предыдущим результатом, на место которого записывают совпадающие элементы принимаемого повторения, те несовпадающие элементы, которые соответствуют хранимым в данный момент несовпадениям, а остальные элементы принимаемого повторения перед записью инвертируют. Кроме того, при приеме нечетного повторения логически складывают выявленные и хранимые несовпадения, на место которых записывают результат логического сложения. При приеме четного повторения выполняют операцию логического умножения для выявленных и хранимых несовпадений, на месте которых записывают результат логического перемножения. На рис. 4 изображен граф, соответствующий данному методу, где показано

Рис. 4.
![]() – состояние одноименных элементов памяти;
– состояние одноименных элементов памяти; ![]() – «1» и «0» четного и нечетного повторений.
– «1» и «0» четного и нечетного повторений.
Начальное состояние памяти устанавливается после приема первой пары элементов ![]()
Ориентированный граф (стрелка) определяет переход системы из одного состояния в другое в зависимости от вида последующих принимаемых элементов.
Рассмотрим действие метода на примере мажоритарного анализа кода с тремя и пятью посылками. Для наглядности предполагаем, что имеют место искажения и поэтому посылки 1,2, 3-я не совпадают:
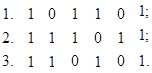
Запоминают 1-ю посылку. Сравнивают 2-ю и 1-ю посылки и запоминают 2-ю посылку на месте 1-й.
Позиции несовпадений
![]()
запоминают дополнительно. Таким образом, используют 2 n элементов памяти, где n – число элементов в одной посылке (в примере n = 6). Третью посылку сравнивают со второй. Совпадающие элементы 3-й посылки без изменений записывают на место 2-й посылки:
![]()
Аналогично записывают несовпадающие элементы 3-й посылки, которым соответствуют ранее запомненные несовпадения, а именно 4-й и 5-й элементы
![]()
Остальные несовпадающие элементы 3-й посылки перед записью инвертируют, следовательно, 3-й элемент
![]()
Таким образом, вместо второй посылки окажется записан результат мажоритарной обработки «два из трех»
![]() (21)
(21)
Несовпадения 2-й 3-й посылок
![]()
Логически складывают с хранимыми несовпадениями
 (22)
(22)
А результат логического сложения (22) записывают на место ранее хранимых несовпадений.
Таким образом, к концу приема 3-й посылки в n элементах памяти хранится результат мажоритарной обработки и в n-элементах памяти – несовпадения (22).
Если к концу приема 3-й посылки оценка состояния канала связи указывает на необходимость продолжения приема посылки и декодирования по критерию «три из пяти», то осуществляют прием 4-й и 5-й посылок
![]()
Четвертую посылку сравнивают с результатом мажоритарной обработки (21) и выявляют несовпадения
![]() (23)
(23)
На место результата (21) записывают совпадающие элементы 4-й посылки, т.е. 2-й и 6-й:
![]() (24)
(24)
и несовпадающие элементы, которым соответствуют хранимые несовпадения (6,3), т.е. 3, 4 и 5-й элементы:
![]() (25)
(25)
Остальные элементы 4-й посылки перед записью инвертируют, поэтому 1-й элемент
![]() (26)
(26)
Таким образом, из (24), (25) и (26) формируется промежуточный результат
![]()
Ранее хранимые несовпадения (22) логически перемножают с выявленными несовпадениями (23):
 (27)
(27)
и результат (27) записывают на место несовпадений (22).
Таким образом, и на этом этапе оказываются задействованными только 2n элементов памяти.
Продолжают прием 5-й посылки, сравнивают ее с промежуточным результатом (26) и выявляют несовпадения:
![]() (28)
(28)
Совпадающие 2, 3, 6-й элементы 5-й посылки записывают на место промежуточного результата (26) без изменения
![]()
Аналогично записывают несовпадающие элементы, которым соответствуют хранимые несовпадения (27), т.е. 4 и 5-й элементы:
![]() (29)
(29)
Остальные элементы 5-й посылки перед записью получают 1-й элемент
![]() (30)
(30)
В результате из (28), (29) и (30) формируется результат мажоритарной обработки «три из пяти»
![]()
который записывается на место промежуточного результата (26). Вероятностные характеристики метода «![]() из
из ![]() » имеют следующий вид:
» имеют следующий вид:
![]()

5.2 Расширение области адаптивного мажоритарного декодирования кодов с повторением
При снижении качества канала связи в течение длительного времени оказывается целесообразным введение дополнительной избыточности путем увеличения числа передач кодов с повторением, с последующей мажоритарной обработкой. При этом возможна поэтапная обработка принимаемых посылок без потери промежуточных результатов [5, 60].
Определение метода. В соответствии с этим методом подсчитывают число единиц в одноименных элементах ![]() посылок, где
посылок, где ![]() – 2,3,…, М, и полученное число
– 2,3,…, М, и полученное число ![]() для каждого из
для каждого из ![]() элементов в виде цифрового кода последовательно записывают. При приеме очередной посылки упомянутые цифровые коды последовательно и синхронно считывают. Корректируют, увеличивая на единицу те числа
элементов в виде цифрового кода последовательно записывают. При приеме очередной посылки упомянутые цифровые коды последовательно и синхронно считывают. Корректируют, увеличивая на единицу те числа ![]() , которым соответствуют единичные элементы очередной посылки, при условии, что
, которым соответствуют единичные элементы очередной посылки, при условии, что ![]() , и вновь последовательно перезаписывают. При этом результат мажоритарной обработки образуют каждый раз в момент приема нечетных посылок по правилу: если
, и вновь последовательно перезаписывают. При этом результат мажоритарной обработки образуют каждый раз в момент приема нечетных посылок по правилу: если ![]() – формируют информационную единицу, а если
– формируют информационную единицу, а если ![]() – формируют нуль.
– формируют нуль.
Рассмотрим действие способа на примере мажоритарного декодирования кодов с ![]() повторением, где
повторением, где ![]() = 2,3,…, 7, т.е. М = 7. Как было отмечено, для записи цифровых кодов необходимо
= 2,3,…, 7, т.е. М = 7. Как было отмечено, для записи цифровых кодов необходимо ![]() элементов памяти. Если
элементов памяти. Если ![]() = 5, то в частном случае можно использовать три пятиразрядных регистра сдвига. Для наглядности предположим, что имеют место искажения и поэтому посылки, приведенные в табл. 1, не совпадают:
= 5, то в частном случае можно использовать три пятиразрядных регистра сдвига. Для наглядности предположим, что имеют место искажения и поэтому посылки, приведенные в табл. 1, не совпадают:
Таблица 1
| Номер посылки | Номер разрядов посылок | ||||
| 1 | 2 | 3 | 4 | 5 | |
| 1 | 1 | 1 | 0 | 1 | 1 |
| 2 | 0 | 1 | 1 | 0 | 1 |
| 3 | 1 | 1 | 0 | 1 | 1 |
| 4 | 0 | 0 | 1 | 0 | 0 |
| 5 | 1 | 1 | 0 | 0 | 1 |
| 6 | 1 | 1 | 0 | 0 | 1 |
| 7 | 0 | 1 | 0 | 1 | 1 |
| 8 | 1 | 0 | 1 | 0 | 1 |
| 9 | 1 | 1 | 1 | 0 | 0 |
| 10 | 0 | 0 | 0 | 1 | 0 |
| 11 | 1 | 1 | 0 | 0 | 1 |
| 12 | 0 | 1 | 1 | 0 | 1 |
| 13 | 1 | 0 | 0 | 0 | 0 |
Память представим в виде трех регистров сдвига Р1, Р2 и РЗ, где i-й столбец предназначен для записи цифрового кода, соответствующего числу единиц в i-х элементах принятых комбинаций.
Так, для пяти комбинаций из табл. 1 цифровые коды в памяти будут следующие:
т.е. для первого элемента принято 3 единицы, для второго – 4, для третьего – 2 и т.д. Рассмотрим действие способа. Для приведенных в табл. 1 данных.
Принимают первую посылку, подсчитывают число единиц и цифровые коды записывают в регистры сдвига со стороны 5-х разрядов, продвигая их с каждым новым принимаемым элементом влево. Таким образом, к концу приема 1-й посылки содержимое регистров будет следующее:
Регистр |
1 | 2 | 3 | 4 | 5 | Регистр |
1 | 2 | 3 | 4 | 5 | ||
| P1 | 1 | 0 | 0 | 0 | 1 | 20 | P1 | 1 | 1 | 0 | 1 | 1 | 20 |
| P2 | 1 | 0 | 1 | 1 | 1 | 21 | P2 | 0 | 0 | 0 | 0 | 0 | 21 |
| P3 | 0 | 1 | 0 | 0 | 0 | 22 | P3 | 0 | 0 | 0 | 0 | 0 | 22 |
т.е. в регистре Р1 запишется 1-я посылка, Принимают 2-ю посылку и одновременно последовательно и синхронно считывают цифровые коды (см. п. 5.1) начиная с первых разрядов регистров. Цифровые разряды регистров (см. п. 5.1) корректируют и увеличивают на единицу для тех элементов, для которых в данный момент принимают единицу, т.е. для 2, 3, 5-го элементов, и новый результат опять перезаписывают, (так как в данный момент все ![]() ). По окончании приема 2-й посылки в регистрах будем иметь цифровые коды:
). По окончании приема 2-й посылки в регистрах будем иметь цифровые коды:
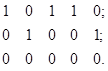 (31)
(31)
Так ![]() (трехкратное повторение), то
(трехкратное повторение), то ![]() и
и ![]() и результат мажоритарной обработки будет:
и результат мажоритарной обработки будет:
![]()
Этот же результат можно получить повторно, считывая цифровые коды (31) из регистров и применяя к ним известное правило. При необходимости осуществляют прием очередных посылок.
После приема 4-й посылки цифровые коды в регистре будут

– а после приема 5-й посылки:

Так как в этом случае ![]() = 3 (пятикратное повторение), то
= 3 (пятикратное повторение), то
![]() и
и ![]() .
.
и результат мажоритарной обработки будет
![]()
Аналогично осуществляется прием и обработка очередных посылок и после окончания приема 10-й посылки в регистрах будет следующие цифровые коды:

Так как ![]() = М = 7, то при приеме 11-й посылки
= М = 7, то при приеме 11-й посылки ![]() остается без изменения (не корректируется) и в регистры перезапишутся цифровые коды
остается без изменения (не корректируется) и в регистры перезапишутся цифровые коды

В этом случае ![]() = 6,
= 6, ![]() и
и ![]() .
.
Поэтому результат мажоритарной обработки будет
![]()
При приеме 12-й посылки ![]() , и следовательно
, и следовательно ![]() не корректируются. В регистры перезапишутся цифровые коды:
не корректируются. В регистры перезапишутся цифровые коды:
Те же цифровые коды и по той же причине не корректируют при приеме 13-й посылки. Поэтому в регистры перезапишутся цифровые коды
В этом случае ![]() = М = 7,
= М = 7, ![]() и результат мажоритарной обработки будет:
и результат мажоритарной обработки будет:
![]()
Реализация известных способов для рассмотренных методов потребовала бы 12![]() элементов памяти, т.е. сложность этого устройства оказалась бы в четыре раза большей. Чрезмерная сложность и ограничивала до настоящего времени применение указанных устройств в адаптивных системах связи.
элементов памяти, т.е. сложность этого устройства оказалась бы в четыре раза большей. Чрезмерная сложность и ограничивала до настоящего времени применение указанных устройств в адаптивных системах связи.
5.3 Мажоритарное декодирование избыточных ( n, к) – кодов с повторением
Данный метод относится к комбинированным методам защиты информации от ошибок, в которых сочетаются исправление части ошибок посредством мажоритарной обработки (2m– 1) повторений с последующей проверкой полученного результата на наличие или отсутствие ошибок по контрольным проверкам избыточного (n, k) – кода.
Вероятностные характеристики метода. Если используется трехкратное повторение комбинаций избыточного (n, k) – кода, для которого ![]() – кратность гарантийно обнаруживаемых ошибок, то после мажоритарной обработки будем иметь
– кратность гарантийно обнаруживаемых ошибок, то после мажоритарной обработки будем иметь
![]() .
.
Вероятность необнаружения ошибок в этом случае
![]() (32)
(32)
или
![]() (33)
(33)
где (32) – приближенное выражение.
Потери информации при этом оцениваются по формуле
![]() . (34)
. (34)
В тех случаях, когда мажоритарной обработке подвергается (2m– 1) повторений, ![]() может быть получено из следующего приближенного выражения:
может быть получено из следующего приближенного выражения:
![]() .(35)
.(35)

Рис. 5
Характеристики метода для канала с группирующимися ошибками. Из рис. 5 следует, что к необнаруживаемым ошибкам относятся ошибки, содержащие t (t= 0,1…,![]() ) искажений типа единицы, j (j= 0,1,2,…,
) искажений типа единицы, j (j= 0,1,2,…, ![]() -t) искажений типа двойки при t + j<
-t) искажений типа двойки при t + j< ![]() и i искажений типа тройки (i =
и i искажений типа тройки (i = ![]() +1-j,
+1-j, ![]() +2-j,…, n-t-j). Отметим, что
+2-j,…, n-t-j). Отметим, что ![]() ; в этом случае число необнаруживаемых ошибок определенной кратности
; в этом случае число необнаруживаемых ошибок определенной кратности
![]()
а общее число ошибок данной кратности – ![]()
Предполагая все ошибки равновероятными и зная суммарную вероятность этих ошибок P[(t + 2j + 3i), Зn], можно определить вероятность необнаруженных ошибок рассматриваемой кратности
![]()
Суммируя ![]() по всем значениям t, j и i, получим выражение для определения полной вероятности необнаружения ошибок:
по всем значениям t, j и i, получим выражение для определения полной вероятности необнаружения ошибок:
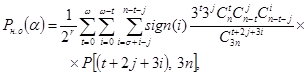 (36)
(36)
где ![]()
![]() – коэффициент, учитывающий обнаружение ошибок более высокой кратности, чем
– коэффициент, учитывающий обнаружение ошибок более высокой кратности, чем ![]() .
.
В определенных случаях можно уменьшить вероятность необнаруженных ошибок соответствующим выбором верхнего предела для переменных t и j, если независимо от результата контрольных проверок избыточного кода браковать информацию в случаях, когда число несовпадений (искажения типа единицы и двойки) в одноименных элементах превысит некоторый порог ![]() . Не все составляющие выражения (36) имеют одинаковый вес. Некоторые из них убывают очень быстро. Это позволяет использовать приближенную формулу:
. Не все составляющие выражения (36) имеют одинаковый вес. Некоторые из них убывают очень быстро. Это позволяет использовать приближенную формулу:
![]() (37)
(37)
Считая, что потери информации обусловливаются неисправляемыми ошибками, последние можно оценить при помощи выражения (см. п. 5.1). В том случае, когда число несовпадений ограничивается параметром ![]() необходимо в выражении (см. п. 5.1) в качестве верхнего предела использовать
необходимо в выражении (см. п. 5.1) в качестве верхнего предела использовать![]() . Потери информации при этом несколько возрастают.
. Потери информации при этом несколько возрастают.
5.4 Поэтапная обработка кодов с повторением
В [5, 56] рассматривается способ передачи и приема поэтапно закодированных сообщений. Использование этого способа для кодов с повторением позволяет наилучшим образом использовать вводимую избыточность, обеспечивая наибольшую верность без снижения оперативности управления и увеличения потерь информации.
Сравнительный анализ алгоритмов декодирования кодов c повторением. В соответствии с первым алгоритмом прием посылок и декодирование с обнаружением ошибок осуществляется до тех пор, пока в очередном сообщении не будут обнаружены ошибки. В этом случае достоверность определяется как функция:
![]()
а оперативность управления как
![]() , (38)
, (38)
где V – скорость модуляции. Следовательно, имеет место высокая оперативность и низкая достоверность, поскольку для повышения достоверности не используется вся вводимая избыточность.
В соответствии со вторым алгоритмом декодирования осуществляют ![]() посылок, мажоритарную обработку по критерию большинства и декодирование с обнаружением ошибок результата мажоритарной обработки. В данном случае достоверность определяется как функция:
посылок, мажоритарную обработку по критерию большинства и декодирование с обнаружением ошибок результата мажоритарной обработки. В данном случае достоверность определяется как функция:
![]() причем
причем ![]() <<
<< ![]() .
.
Однако оперативность управления резко снижается и характеризуется выражением
![]()
т.е.
![]()
![]()
Алгоритм поэтапного декодирования кодов с повторением сочетает преимущества как первого, так и второго из рассмотренных выше алгоритмов. В соответствии с этим алгоритмом осуществляется прием и декодирование повторных посылок сообщения и первое правильно декодированное сообщение в качестве предварительного решения выдается для начала исполнения. Этим обеспечивается высокая оперативность управления. Повторные посылки сообщения накапливаются, обрабатываются мажоритарным способом и декодируются. Декодированное сообщение сравнивается с предварительным решением. При их совпадении предварительное решение не изменяется. При несовпадении предварительное решение бракуется и в качестве окончательного решения выдается сообщение, декодированное после накопления и мажоритарной обработки. Этот метод характеризуется высокой оперативностью управления (![]() ) и большим значением достоверности передаваемой информации (
) и большим значением достоверности передаваемой информации (![]() ). Возможны различные модификации разработанного алгоритма поэтапного декодирования, обусловленные заданными требованиями по достоверности доведения информации и оперативности управления. Определим области целесообразного применения тех или других алгоритмов декодирования кодов с повторением.
). Возможны различные модификации разработанного алгоритма поэтапного декодирования, обусловленные заданными требованиями по достоверности доведения информации и оперативности управления. Определим области целесообразного применения тех или других алгоритмов декодирования кодов с повторением.
Области применения алгоритмов декодирования кодов с повторением. Решение поставленной задачи выполняется
![]()

Рис. 6.
в предположении использования каналов связи с независимыми ошибками, характеризуемых одним параметром–вероятностью искажения одного элемента комбинации ![]() .
.
Алгоритм декодирования, в соответствии с которым первая правильно декодированная посылка сообщения выдается получателю, обеспечивает следующие характеристики.
Достоверность информации может быть вычислена по формуле
![]()
Потери информации характеризуются выражением
![]()
При ![]() может быть использовано приближенное выражение
может быть использовано приближенное выражение
![]()
Минимальное время доведения информации до получателя характеризуется выражением (38).
На рис. 6 приведена зависимость ![]() для
для ![]() при условии, что
при условии, что ![]() .
.
В соответствии со вторым алгоритмом осуществляется накопление ![]() повторных посылок сообщения, мажоритарная обработка по критерию большинства и декодирование с обнаружением ошибок результата мажоритарной обработки. Правильно декодированное сообщение выдается получателю. В случае обнаружения ошибок сообщение бракуется и осуществляется очередной цикл, состоящий из накопления новых
повторных посылок сообщения, мажоритарная обработка по критерию большинства и декодирование с обнаружением ошибок результата мажоритарной обработки. Правильно декодированное сообщение выдается получателю. В случае обнаружения ошибок сообщение бракуется и осуществляется очередной цикл, состоящий из накопления новых ![]() посылок, мажоритарной обработки и декодирования. Таких циклов может быть от 1 до
посылок, мажоритарной обработки и декодирования. Таких циклов может быть от 1 до ![]() .
.
Достоверность, надежность доведения информации и оперативность управления могут быть вычислены по следующим формулам:
![]()
![]()
![]()
![]()
Сравнительный анализ показывает, что
![]() <
< ![]() и
и ![]() <
< ![]() .
.
На рис. 6.6 приведена зависимость ![]() из которой видно, что при
из которой видно, что при ![]()
![]() ,
,
а при ![]() ,
, ![]() .
.
Критическое значение длины кодовой комбинации может быть вычислено по формуле
![]()
Третий алгоритм предусматривает выдачу получателю 1-й правильно декодированной посылки сообщения, накопление всех повторных посылок, мажоритарную обработку по критерию большинства, декодирование результата мажоритарной обработки и его сравнение с результатом первого правильного декодирования.
Достоверность, надежность доведения информации и оперативность управления вычисляются по следующим формулам:
![]()
![]()
![]() ;
;
![]()
Сравнительный анализ показывает, что
![]() , а
, а ![]()
На рис. 6 приведены зависимости, из которых видно, что при
![]()
![]() ; при
; при ![]() ; при
; при ![]() ; а при
; а при ![]() .
.
Критические значения длины кодовой комбинации ![]() и
и ![]() могут быть определены по следующим формулам:
могут быть определены по следующим формулам:
![]()
![]()
В соответствии с четвертым алгоритмом накапливают ![]() повторных посылок сообщения, обрабатывают их по критерию большинства, декодируют и при необнаружении ошибок результат декодирования выдают получателю и запоминают. Запоминается также результат мажоритарной обработки. Продолжают накапливать повторные посылки сообщения и при этом каждые
повторных посылок сообщения, обрабатывают их по критерию большинства, декодируют и при необнаружении ошибок результат декодирования выдают получателю и запоминают. Запоминается также результат мажоритарной обработки. Продолжают накапливать повторные посылки сообщения и при этом каждые ![]() посылок обрабатывают по критерию большинства и запоминают результат обработки. После приема всех посылок сообщения
посылок обрабатывают по критерию большинства и запоминают результат обработки. После приема всех посылок сообщения ![]() результатов мажоритарных обработок обрабатывают по критерию большинства, результат обработки декодируют и сравнивают с результатом первого правильного декодированного сообщения. При их совпадении первое решение не меняется, а при несовпадении отменяется исполнение предварительного решения и получателю выдается последнее решение.
результатов мажоритарных обработок обрабатывают по критерию большинства, результат обработки декодируют и сравнивают с результатом первого правильного декодированного сообщения. При их совпадении первое решение не меняется, а при несовпадении отменяется исполнение предварительного решения и получателю выдается последнее решение.
Достоверность, надежность доведения информации и оперативность управления вычисляются по следующим формулам:
![]()
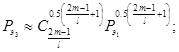
![]()
![]()
Сравнительный анализ показывает, что
![]() ;
; ![]()
Однако достоверность предварительного решения четвертого алгоритма выше, чем третьего. Проще оказывается и аппаратурная реализация четвертого алгоритма.
На рис. 6 приведена зависимость ![]() , из (которой можно сделать вывод, что для всех значений
, из (которой можно сделать вывод, что для всех значений ![]() ). При
). При
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() .
.
Критические значения длины кодовой комбинации можно вычислить по формулам:
 ;
;

Методика выбора алгоритмов декодирования. Исходными данными для выбора алгоритмов декодирования кодов с повторениями являются заданные значения достоверности ![]() , надежности доведения информации до управляемых объектов
, надежности доведения информации до управляемых объектов ![]() , оперативности управления
, оперативности управления ![]() и длины информационной части кодовой комбинации к, обусловленной количеством передаваемых сообщений и разнообразием их признаков, а также характеристиками каналов
и длины информационной части кодовой комбинации к, обусловленной количеством передаваемых сообщений и разнообразием их признаков, а также характеристиками каналов ![]() .
.
На первом этапе выбираются характеристики обнаруживающего ошибки кода (![]() и
и ![]() ) для кодирования одного повторения сообщения.
) для кодирования одного повторения сообщения.
Вычисляются основные параметры с использованием приведенных формул и строятся графические зависимости ![]() . Для заданных характеристик канала связи и различных значений
. Для заданных характеристик канала связи и различных значений ![]() .
.
Когда ![]() и
и ![]() при
при ![]() выбирается четвертый алгоритм декодирования. При
выбирается четвертый алгоритм декодирования. При ![]() следует отдать предпочтение третьему алгоритму, хотя это и приведет к усложнению аппаратурной реализации.
следует отдать предпочтение третьему алгоритму, хотя это и приведет к усложнению аппаратурной реализации.
При ![]() , а также
, а также ![]() выбирается третий алгоритм при условии, что
выбирается третий алгоритм при условии, что ![]() . В противном случае следует увеличить
. В противном случае следует увеличить ![]() и произвести новую оценку.
и произвести новую оценку.
При ![]() может быть выбран четвертый алгоритм при условии что
может быть выбран четвертый алгоритм при условии что ![]() , как обладающий большей достоверностью, или второй алгоритм при
, как обладающий большей достоверностью, или второй алгоритм при ![]() и
и ![]() .
.
Таким образом, на основе метода адаптивного мажоритарного декодирования кодов с повторением, базирующегося на принципе циклического сдвига с насыщением индексов состояния одноименных элементов принимаемой информации, синтезированы мажоритарные декодирующие устройства, обеспечивающие достижение требуемой помехоустойчивости приема при значительно меньшей сложности технической реализации. Новый метод является перспективным для использования в информационных системах при многократном считывании информации с магнитных и лазерных носителей, так как позволяет снизить исходные требования к вероятности ошибки на один знак и соответственно повысить плотность записи информации.
Сравнительная оценка различных алгоритмов поэтапного декодирования избыточных (![]() ,
, ![]() ) – кодов с повторением позволила определить области их предпочтительного использования и разработать методику выбора требуемого алгоритма.
) – кодов с повторением позволила определить области их предпочтительного использования и разработать методику выбора требуемого алгоритма.
В последние двадцать пять лет XX столетия на смену аналоговым методам передачи сообщений приходят и начинают широко внедряться цифровые методы. Цифровые системы связи в начале XXI века полностью заменят аналоговые. Эта революция в области передачи сигналов была подготовлена в 40-х годах, когда были изобретены два исключительно важных для последующего развития техники связи вида преобразования аналоговых сигналов в цифровую форму – импульсно – кодовая и дельта – модуляция.
В середине XX века в связи с проблемами военной радиосвязи рождаются идеи использования в качестве несущего колебания широкополосных сигналов, а не гармонических. Широкое использование таких сигналов в системах фиксированной и подвижной связи начинается в последней четверти XX века.
По указанным в работе причинам представляется актуальной проблема создания методов защитыот ошибок для каналов передачи информации и других протокольных уровней, основанных на применении кодов, обеспечивающих заданную вероятность ошибки при использовании произвольных дискретных каналовсвязи с обеспечением высоких вероятностно-временных характеристик обмена при простой реализации алгоритмов кодирования и декодирования.
Более сильная постановка задачи состоит в построении таких каналов передачи информации, в которых контролируется достигаемая верность и потребителю информации предоставляется возможность оперативно менять требования по гарантированной верности, принимая сообщение с нужной верностью и отказываясь от тех сообщений, верность которых не удовлетворяет потребителя информации.
Литература
1. Аксенов Б.Е., Александров А.М. Об одном методе исследования потоков ошибок в каналах связи. – В кн.: Проблемы передачи информации. Вып. 4. М., 1968, т. 4, с. 79–83.
2. Берлекэмп Э.Р. Техника кодирования с исправлением ошибок. ТИИЭР, 1980, т. 68, №5, с. 24–58.
3. Бородин Л.Ф. Введение в теорию помехоустойчивого кодирования. – М.: Сов. радио, 1968. – 408 с.
4. Касаткин А.С., Кузьмин И.В. Оценка эффективности автоматизированных систем контроля. – М.: Энергия, 1967. – 80 с.
5. Ключко В.И. Защита от ошибок при обмене информацией в АСУ. – М.: МО, 1980. – 256 с.
6. Ключко В.И., Березняков Г.Е. Коды с циклической проверочной матрицей. – В кн.: Приборы и системы автоматики, X.: Изд-во Харьк. ун-та, 1972, вып. 24, 250 с.
7. Колесник В.Д. Мирончиков Е.Т. Декодирование циклических кодов. – М.: Связь, 1968. – 252 с.
8. Коржик В.И., Фанк Л.М. Помехоустойчивое кодирование дискретных сообщений в каналах со случайной структурой. – М.: Связь, 1975. – 270 с.
9. Кузьмин И.В. Оценка эффективности и оптимизации АСКУ. – М.: Сов. радио, 1971. – 294 с.
10. Кузьмин И.Б., Кедрус В.А. Основы теории информации и кодирования. – К.: Вища шк. Головное изд-во, 1977 – 280 с.
11. Мартынов Е.М. Синхронизация в системах передачи дискретной информации. – М.: Связь, 1972. – 216 с.
12. Мельников Ю. Н Достоверность информации в сложных системах. – М.: Сов. радио, 1973. – 192 с.
13. Месси Д.Л., Кастелло Д.Д., Юстесен И. Веса многочленов и кодовые конструкции. – В кн.: Кибернетический сборник. М.: Мир, 1974, №11, с. 24–47.
14. Мизин И.А. Уринсон JI. С., Храмешин Г.К. Передача информации в сетях с коммутацией сообщений. – М.: Связь, 1972. – 319 с.
15. Нейфах А.Е. Сверточные коды для передачи дискретной информации. – М.: Наука, 1979. – 222 с.
16. Новопашный Г.Н. Информационно-измерительные системы. – М.: Высш, шк., 1977. – 208 с.
17. Новоселов О.Н., Фомин А.Ф. Основы теории и расчета информационно-измерительных систем. – М.: Машиностроение, 1980. – 280 с.
18. Орнатский П.П. Теоретические основы информационно- измерительной техники. – К.: Вища шк., Головное изд-во. 1976. – 436 с.
19. Передача информации с обратной связью. Под ред. З.М. Каневского. – М.: Связь, 1976. – 352 с.
20. Патерсон У., Уэлдон Э. Коды, исправляющие ошибки. – М.: Мир, 1976. – 590 с.
21. Самойленко С.И. Помехоустойчивое кодирование. – М.: Наука, 1966. – 239 с.
22. Справочник по кодированию информации / Под ред. проф. Н.Т. Березюка. – X.: Вища шк., Изд-во при Харьк. ун-те, 1978. – 252 с.
23. Финк Л.М. Теория передачи дискретных сообщений. – М.: Сов. радио. 1970. – 728 с.
24. Цымбал В.П. Теория информации и кодирование. – К.: Вища шк., Головное изд-во, 1982. – 304 с.
25. Цымбал В.П., Клешко Г.Н., Ливийский Г.В. Представление и поиск данных в информационной системе. – К.: КИНХ, 1973. – 401 с.
26. Четвериков В.Н. Преобразование и передача информации в АСУ. – М.: Высш. шк., 1974. – 320 с.