| Скачать .docx | Скачать .pdf |
Реферат: Линейные регрессионные модели
Решение контрольной работы по эконометрике
Используя данные Федеральной службы государственной статистики России (за двенадцать месяцев) из периода 2004 - 2005гг., следует:
1. Оценить влияние факторов (X1, X2, X3, X4, X5, X6, X7, X8 ) на изучаемый показатель (Y) и друг на друга с помощью коэффициентов линейной корреляции
Таблица 1.
| в% к предыдущему периоду |
индексы цен платных услуг |
индексы цен производителей |
добыча полезных ископаемых |
обрабатывающие производства |
производство и распределение электроэнергии газа и воды |
индексы тарифов на грузовые перевозки |
железнодорожный транспорт |
автомобильный транспорт |
трубопроводный транспорт |
|
|
Y |
X1 |
X2 |
X3 |
X4 |
X5 |
X6 |
X7 |
X8 |
| ицпу |
пр |
дпи |
оп |
прэгв |
гп |
жт |
ат |
тт |
|
| июл.04 |
101,3 |
101,2 |
102,9 |
100,7 |
100,1 |
102,1 |
100 |
101,3 |
105 |
| авг.04 |
101 |
101,8 |
103,9 |
101,4 |
100,2 |
100,2 |
100 |
100,4 |
100 |
| сен.04 |
100,6 |
103,1 |
105 |
103,1 |
100 |
100,3 |
100 |
101,9 |
100,6 |
| окт.04 |
101,2 |
101,8 |
103,6 |
101,4 |
99,9 |
95,4 |
100 |
101,5 |
87,4 |
| ноя.04 |
100,8 |
102 |
104,5 |
101,5 |
100 |
100,7 |
100 |
101,9 |
101,1 |
| дек.04 |
101 |
100,1 |
100,8 |
99,8 |
99,9 |
102,1 |
100 |
100,6 |
105,8 |
| янв.05 |
108,8 |
100,5 |
95,7 |
100,9 |
104,9 |
113,9 |
108,8 |
103,2 |
122,6 |
| фев.05 |
102,2 |
101,3 |
98,4 |
100,9 |
106,3 |
100,1 |
100 |
100,8 |
100,1 |
| мар.05 |
101,2 |
102,5 |
109,6 |
101 |
100,3 |
100 |
100 |
100,3 |
99,9 |
| апр.05 |
100,8 |
102,5 |
108,9 |
101,1 |
100,3 |
103,5 |
100 |
101 |
107,7 |
| май.05 |
100,8 |
102,7 |
109,7 |
101 |
100,1 |
100,3 |
100 |
100,5 |
100 |
| июн.05 |
100,9 |
100,1 |
99,3 |
100,3 |
100,1 |
101,7 |
100 |
100,6 |
103,7 |
Коэффициент линейной корреляции, с помощью которого можно оценить влияние факторов (X1, X2, X3, X4, X5, X6, X7, X8 ) на изучаемый показатель (Y) и друг на друга, вычисляется по формуле:
![]() ,
,
где ![]() - среднее квадратическое отклонение фактора
- среднее квадратическое отклонение фактора ![]() .
.
![]() - среднее квадратическое отклонение изучаемого показателя
- среднее квадратическое отклонение изучаемого показателя ![]() . Если
. Если ![]() =0, то факторы не могут влиять на изучаемый показатель, так как связь между ними будет отсутствовать. Чем ближе
=0, то факторы не могут влиять на изучаемый показатель, так как связь между ними будет отсутствовать. Чем ближе ![]() к 1, тем сильнее связь между факторами и изучаемым показателем. Рассмотрим сначала как влияет X1
на изучаемый показатель Y. Произведем предварительные расчеты в таблице:
к 1, тем сильнее связь между факторами и изучаемым показателем. Рассмотрим сначала как влияет X1
на изучаемый показатель Y. Произведем предварительные расчеты в таблице:
Таблица 2.
| |
|
|
|
|
|
| июл.04 |
101,3 |
101,2 |
10251,56 |
10261,69 |
10241,44 |
| авг.04 |
101 |
101,8 |
10281,8 |
10201 |
10363,24 |
| сен.04 |
100,6 |
103,1 |
10371,86 |
10120,36 |
10629,61 |
| окт.04 |
101,2 |
101,8 |
10281,6 |
10241,44 |
10363,24 |
| ноя.04 |
100,8 |
102 |
10281,6 |
10160,64 |
10404 |
| дек.04 |
101 |
100,1 |
10110,1 |
10201 |
10020,01 |
| янв.05 |
108,8 |
100,5 |
10934,4 |
11837,44 |
10100,25 |
| фев.05 |
102,2 |
101,3 |
10352,86 |
10444,84 |
10261,69 |
| мар.05 |
101,2 |
102,5 |
10373 |
10241,44 |
10506,25 |
| апр.05 |
100,8 |
102,5 |
10332 |
10160,64 |
10506,25 |
| май.05 |
100,8 |
102,7 |
10352,16 |
10160,64 |
10547,29 |
| июн.05 |
100,9 |
100,1 |
10100,09 |
10180,81 |
10020,01 |
| Сумма |
1220,6 |
1219,6 |
124023,03 |
124211,94 |
123963,3 |
| Среднее значение |
101,71667 |
101,6333 |
10336,96666 |
10350,995 |
10330,27 |
![]()
Из таблицы находим среднее квадратическое отклонение фактора ![]() :
:
![]() =
=![]() =0,9679876;
=0,9679876;
среднее квадратическое отклонение изучаемого показателя ![]() :
:
![]() =
=![]() =2,1718655.
=2,1718655.
Полученные значения подставляем в формулу:
![]() =
=![]() =-0,41056
=-0,41056
Коэффициент линейной корреляции равен 0,3 ≤ ![]() =
=![]() ≤0,7. Это говорит о том, что связь между изучаемым показателем (Y) и фактором
≤0,7. Это говорит о том, что связь между изучаемым показателем (Y) и фактором ![]() умеренная.
умеренная.
Аналогично оценивается влияние остальных факторов на изучаемый показатель (Y).
![]() =
=![]()
Коэффициент линейной корреляции равен 0,3 ≤ ![]() =
=![]() ≤0,7. Это говорит о том, что связь между изучаемым показателем (Y) и фактором Х2 умеренная.
≤0,7. Это говорит о том, что связь между изучаемым показателем (Y) и фактором Х2 умеренная.
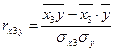 =
=![]()
![]()
Коэффициент линейной корреляции равен ![]() =
=![]() < 0,3. Это говорит о том, что связь между изучаемым показателем (Y) и фактором Х3 слабая.
< 0,3. Это говорит о том, что связь между изучаемым показателем (Y) и фактором Х3 слабая.
![]() =
=![]()
![]()
Коэффициент линейной корреляции равен 0,3 ≤ ![]() =
=![]() ≤0,7. Это говорит о том, что связь между изучаемым показателем (Y) и фактором Х4 умеренная.
≤0,7. Это говорит о том, что связь между изучаемым показателем (Y) и фактором Х4 умеренная.
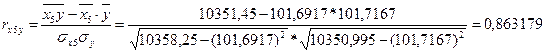
Коэффициент линейной корреляции равен 0,7 < ![]() =
=![]() Это говорит о том, что связь между изучаемым показателем (Y) и фактором Х5 близка к линейной (тесная).
Это говорит о том, что связь между изучаемым показателем (Y) и фактором Х5 близка к линейной (тесная).
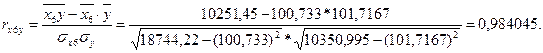
Коэффициент линейной корреляции равен 0,7 < ![]() =
=![]() Это говорит о том, что связь между изучаемым показателем (Y) и фактором Х6 близка к линейной (тесная).
Это говорит о том, что связь между изучаемым показателем (Y) и фактором Х6 близка к линейной (тесная).
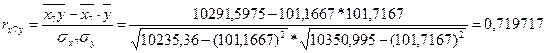
Коэффициент линейной корреляции равен 0,7 < ![]() =
=![]() Это говорит о том, что связь между изучаемым показателем (Y) и фактором Х7 близка к линейной (тесная).
Это говорит о том, что связь между изучаемым показателем (Y) и фактором Х7 близка к линейной (тесная).
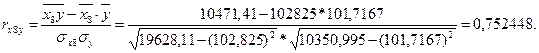
Коэффициент линейной корреляции равен 0,7 < ![]() =
=![]() Это говорит о том, что связь между изучаемым показателем (Y) и фактором Х8 близка к линейной (тесная).
Это говорит о том, что связь между изучаемым показателем (Y) и фактором Х8 близка к линейной (тесная).
Влияние факторов друг на друга рассчитывается аналогично. Все полученные данные представим в таблице.
Таблица 3.
| Y |
X1 |
X2 |
X3 |
X4 |
X5 |
X6 |
X7 |
X8 |
|
| Y |
1 |
||||||||
| X1 |
-0,41056 |
1 |
|||||||
| X2 |
-0,62049 |
0,817335 |
1 |
||||||
| X3 |
-0,14167 |
0,750202 |
0,304572 |
1 |
|||||
| X4 |
0,684791 |
-0,31544 |
-0,63666 |
-0,13627 |
1 |
||||
| X5 |
0,863179 |
-0,39974 |
-0,4795 |
-0,21126 |
0,494364 |
1 |
|||
| X6 |
0,984045 |
-0,36981 |
-0,55741 |
-0,09167 |
0,560132 |
0,89804 |
1 |
||
| X7 |
0,719717 |
-0,08272 |
-0,45151 |
0,36154 |
0,360766 |
0,610648 |
0,762909 |
1 |
|
| X8 |
0,752448 |
-0,40384 |
-0,42926 |
-0,26069 |
0,440197 |
0,978356 |
0,790727 |
0,493109 |
1 |
Из свойств корреляции известно, что если ![]() > 0, то связь прямая (
> 0, то связь прямая (![]() ); если
); если ![]() < 0, то связь обратная
< 0, то связь обратная ![]() ). Факторы (Х1), (Х3), (Х2) имеют обратную связь с ицпу, то есть если индекс цен платных услуг растет, они падают, и наоборот. Факторы (Х4), (Х5), (Х6), (Х7), (Х8) имеют прямую связь с индексом цен платных услуг (вместе с ним растут или падают).
). Факторы (Х1), (Х3), (Х2) имеют обратную связь с ицпу, то есть если индекс цен платных услуг растет, они падают, и наоборот. Факторы (Х4), (Х5), (Х6), (Х7), (Х8) имеют прямую связь с индексом цен платных услуг (вместе с ним растут или падают).
Самая сильная связь наблюдается между индексом цен платных услуг и железнодорожным транспортом. Самая слабая связь наблюдается между обрабатывающим производством и производством и распределением электроэнергии, газа и воды.
2. Используя процедуру выбора факторов, предложить и построить линейные регрессионные модели изучаемого показателя. Оценить качество моделей
При процедуре выбора факторов должны выполняться следующие условия:
Факторы должны быть количественно измеримы или допускать кодировку. В нашем случае это условие выполняется.
Факторы должны "объяснять" поведение изучаемого показателя согласно принятым положениям экономической теории. Это должно подтверждаться индексами корреляции факторов с показателями. Это условие тоже выполняется, так как для всех факторов индексы корреляции рассчитаны.
Факторы не должны находиться в точной функциональной связи (допустим, коллинеарной). Включение в модель факторов с индексами корреляции, близкими по модулю к единице может привести к нежелательным последствиям:
1) факторы будут дублировать друг друга, и будет затруднена экономическая интерпретация параметров модели;
2) система уравнений для определения параметров может оказаться плохо обусловленной и повлечь ненадежность полученных уравнений регрессии т нежелательность их использования для анализа и прогноза.
При наличии корреляции ≥0,7 между факторами один из них следует исключить. Оставить рекомендуется тот, который при достаточно тесной связи с показателем имеет более слабую связь с другими факторами.
Рассмотрим таблицу 3, используя метод исключения, отберем факторы для построения регрессионных моделей. Так как связь между факторами должна быть слабой, исключим все факторы, коэффициент корреляции которых больше или равен по модулю 0,3. Для построения модели оставляем факторы сильно или умеренно влияющие на данный показатель, то есть коэффициент корреляции должен быть больше или равен 0,3.
Следующее необходимое условие при построении регриссионных моделей: Число включаемых факторов должно в 6 раз меньше объема наблюдений, по которым строится регрессия. N-число наблюдений в нашем случае равно 12. Тогда m ≤ ![]() , то есть m=1 или m=2.
, то есть m=1 или m=2.
Число параметров при факторах в линейной модели совпадают с их количеством: m=p.
Итак, можно предложить следующие регрессионные модели:
1. ![]()
2. ![]() .
.
3. ![]() .
.
Используя инструмент РЕГРЕССИЯ, оценим 1 модель.
1 этап. Оценка значимости модели в целом.
Таблица 4.
| ВЫВОД ИТОГОВ |
|||||
| Регрессионная статистика |
|||||
| Множественный R |
0,985324602 |
||||
| R-квадрат |
0,970864572 |
||||
| Нормированный R-квадрат |
0,963580715 |
||||
| Стандартная ошибка |
0,453164887 |
||||
| Наблюдения |
11 |
||||
| Дисперсионный анализ |
|||||
|
|
df |
SS |
MS |
F |
Значимость F |
| Регрессия |
2 |
54,74441 |
27,3722 |
133,289901 |
0,00000072 |
| Остаток |
8 |
1,642867 |
0, 205358 |
||
| Итого |
10 |
56,38727 |
|||
| Модель линейной регрессии с двумя фактором Х1 и X6 значима в целом согласно F-критерию (F=133,2899) с приемлемым уровнем значимости 0,00000072 ≤ 0,05 Итак, получаем модель
|
|||||
|
|
Коэф-ты |
Станд. ошибка |
t-стат. |
P-Значение |
|
| Y-пересечение |
27,18887556 |
17,92439 |
1,516864 |
0,16777466 |
|
| Х1 |
-0,1220023 |
0,146648 |
-0,83194 |
0,42957614 |
|
| Х6 |
0,86279739 |
0,058131 |
14,84242 |
0,000000418 |
|
Согласно критерию Стьюдента 2 параметра модели a=27,18 и ![]() =-0,122 незначимы с приемлемыми уровнями
=-0,122 незначимы с приемлемыми уровнями ![]() >0,05 и
>0,05 и ![]() >0,05. Следовательно, эта модель неудачна и не может быть использована к анализу и прогнозу индекса цен платных услуг. Следует изменить спецификацию модели (необходимо убрать фактор Х1).
>0,05. Следовательно, эта модель неудачна и не может быть использована к анализу и прогнозу индекса цен платных услуг. Следует изменить спецификацию модели (необходимо убрать фактор Х1).
Используя инструмент РЕГРЕССИЯ, оценим 2 модель.
1 этап. Оценка значимости модели в целом.
Таблица 5.
| ВЫВОД ИТОГОВ |
|||||
| Регрессионная статистика |
|||||
| Множественный R |
0,984045 |
||||
| R-квадрат |
0,968344 |
||||
| Нормированный R-квадрат |
0,964827 |
||||
| Стандартная ошибка |
0,445346 |
||||
| Наблюдения |
11 |
||||
| Дисперсионный анализ |
|||||
|
|
df |
SS |
MS |
F |
Значимость F |
| Регрессия |
1 |
54,60227273 |
54,60227 |
275,3055768 |
0,0000000468 |
| Остаток |
9 |
1,785 |
0, 198333 |
||
| Итого |
10 |
56,38727273 |
|||
| Модель линейной регрессии с фактором X6 значима в целом согласно F-критерию (F=275,306) с приемлемым уровнем значимости 0,0000000468 ≤ 0,05 Итак, получаем модель
2 этап. Оценка параметров модели. |
|||||
|
|
Коэф-ты |
Станд. ошибка |
t-стат. |
P-Значение |
|
| Y-пересечение |
12,98182 |
5,351909883 |
2,425642 |
0,038255004 |
|
| X6 |
0,880682 |
0,05307763 |
16,59233 |
0,0000000468 |
|
Согласно критерию Стьюдента 2 параметра модели a=12,98 и b=0,88 значимы с приемлемыми уровнями ![]() <0,05 и
<0,05 и ![]() <0,05.
<0,05.
3 этап. Проверка наличия необходимых свойств у остатка модели.
Таблица 6.
| ВЫВОД ОСТАТКА |
|||
| Наблюдение |
Предсказанное Y |
Остатки |
Стандартные остатки |
| 1 |
101,05 |
-0,05 |
-0,118345267 |
| 2 |
101,05 |
-0,45 |
-1,065107404 |
| 3 |
101,05 |
0,15 |
0,355035801 |
| 4 |
101,05 |
-0,25 |
-0,591726335 |
| 5 |
101,05 |
-0,05 |
-0,118345267 |
| 6 |
108,8 |
0,00000000000132 |
0,000000000003128 |
| 7 |
101,05 |
1,15 |
2,721941143 |
| 8 |
101,05 |
0,15 |
0,355035801 |
| 9 |
101,05 |
-0,25 |
-0,591726335 |
| 10 |
101,05 |
-0,25 |
-0,591726335 |
| 11 |
101,05 |
-0,15 |
-0,355035801 |
График 1.
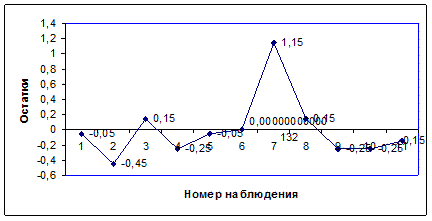
Проверяем случайность остатков Первое, что требуется, это чтобы график остатков располагался в горизонтальной полосе, симметричной относительно оси абсцисс. Согласно предпосылкам МНК возмущение должно быть случайной величиной с нулевым математическим ожиданием. Это имеет место для получения однофакторной регрессии. График остатка (возмущения, ошибки) располагается в горизонтальной полосе. Имеется большое количество локальных экстремумов (максимумов и минимумов). ![]() -значит остатки случайные.
-значит остатки случайные.
Согласно следующей предпосылке остатки должны быть равноизменчивы. Для проверки этой предпосылки используем в Microsoft Excel инструмент "Среднее значение".
![]()
![]()
![]() -0,000000000000006
-0,000000000000006![]() .
.
Проверка на гомоскедастичность по методу Гольдфельда-Квандта невозможна, так как недостаточно наблюдений (должно быть n>12m) /
Проверим отсутствие автокорреляции остатков. Для этого чаще всего используют критерий Дарбина Уотсона (d-критерий):
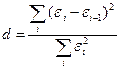 .
.
![]() находится в Microsoft Excel при помощи инструмента "СУММКВРАЗН"
находится в Microsoft Excel при помощи инструмента "СУММКВРАЗН"
![]() =3,215
=3,215
![]() , берется из таблицы 4.1 "SS"/ "остаток"
, берется из таблицы 4.1 "SS"/ "остаток"
![]() 1,785
1,785
d=![]() .
.
Критерий Дарбина Уотсона (d-критерий): n=12, m=1, ![]() , dl=0,97,du=1,33
, dl=0,97,du=1,33
I dl II du III IV 4-du V 4-dl VI
![]() 0 0,97 1,33 2 2,67 3,03 4
0 0,97 1,33 2 2,67 3,03 4
d=1,801![]() III, IV. Значит нет оснований отклонить предположение об отсутствии автокорреляции соседних остатков по d-критерию с уровнем значимости
III, IV. Значит нет оснований отклонить предположение об отсутствии автокорреляции соседних остатков по d-критерию с уровнем значимости ![]() .
.
Следующее необходимое условие: остатки должны иметь распределение Гаусса. можно ограничиться критерием размахов (RS - критерий).
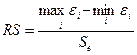 .
.
![]() -стандартная ошибка модели
-стандартная ошибка модели
![]() =0,445346.
=0,445346.
![]() находится в Microsoft Excel при помощи функции "МАКС".
находится в Microsoft Excel при помощи функции "МАКС".
![]() =1,15.
=1,15.
![]() находится в Microsoft Excel при помощи функции "МИН".
находится в Microsoft Excel при помощи функции "МИН".
![]() =-0,45.
=-0,45.
RS=3,59
Критерий размахов, RS - критерий: n=12, α =0,05, a=2,8, b=3,91.
Если a <RS < b, то остатки имеют нормальный закон распределения с уровнем α =0,05.
2,8 <3,59 < 3,91.
Вывод: Все предпосылки регрессионного анализа выполняются с уровнем α =0,05. Значит модель успешно прошла проверку оценки ее качества.
Используя инструмент РЕГРЕССИЯ, оценим 3 модель.
1 этап. Оценка значимости модели в целом.
Таблица 7.
| ВЫВОД ИТОГОВ |
|||||
| Регрессионная статистика |
|||||
| Множественный R |
0,863178866 |
||||
| R-квадрат |
0,745077754 |
||||
| Нормированный R-квадрат |
0,71675306 |
||||
| Стандартная ошибка |
1,263784889 |
||||
| Наблюдения |
11 |
||||
| Дисперсионный анализ |
|||||
|
|
df |
SS |
MS |
F |
Значимость F |
| Регрессия |
1 |
42,01290252 |
42,0129 |
26,30488273 |
0,000620555 |
| Остаток |
9 |
14,37437021 |
1,597152 |
||
| Итого |
10 |
56,38727273 |
|||
| Модель линейной регрессии с фактором X5 значима в целом согласно F-критерию (F=26,304) с приемлемым уровнем значимости 0,0000000468 ≤ 0,05 Итак, получаем модель
|
|||||
|
|
Коэф-ты |
Станд. ошибка |
t-стат. |
P-Значение |
Нижние 95% |
| Y-пересечение |
55,68196551 |
8,991138974 |
6, 192982 |
0,00016021 |
35,34258057 |
| Х5 |
0,453226954 |
0,088368512 |
5,128829 |
0,000620555 |
0,253323338 |
Согласно критерию Стьюдента 2 параметра модели a=55,68 и b=0,453 значимы с приемлемыми уровнями ![]() <0,05 и
<0,05 и ![]() <0,05.
<0,05.
3 этап. Проверка наличия необходимых свойств у остатка модели.
Таблица 8.
| ВЫВОД ОСТАТКА |
|||
| Наблюдение |
Предсказанное 101,3 |
Остатки |
Стандартные остатки |
| 1 |
101,0953062 |
-0,095306249 |
-0,079492648 |
| 2 |
101,1406289 |
-0,540628945 |
-0,450925589 |
| 3 |
98,91981687 |
2,280183127 |
1,901845857 |
| 4 |
101,3219197 |
-0,521919726 |
-0,43532068 |
| 5 |
101,9564375 |
-0,956437461 |
-0,797741462 |
| 6 |
107,3045155 |
1,495484488 |
1,247347611 |
| 7 |
101,0499836 |
1,150016446 |
0,959201034 |
| 8 |
101,0046609 |
0, 195339141 |
0,162927675 |
| 9 |
102,5909552 |
-1,790955196 |
-1,493792616 |
| 10 |
101,1406289 |
-0,340628945 |
-0,284110403 |
| 11 |
101,7751467 |
-0,87514668 |
-0,729938779 |
График 2.
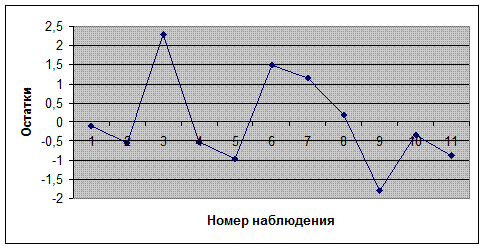
Проверяем случайность остатков. Согласно предпосылкам МНК возмущение должно быть случайной величиной с нулевым математическим ожиданием. Это имеет место для получения однофакторной регрессии. График остатка (возмущения, ошибки) располагается в горизонтальной полосе. Имеется большое количество локальных экстремумов (максимумов и минимумов). ![]() -значит остатки случайные.
-значит остатки случайные.
Согласно следующей предпосылке остатки должны быть равно изменчивы. Для проверки этой предпосылки используем в Microsoft Excel инструмент "Среднее значение".
![]()
![]()
![]() -0,0000000000000026
-0,0000000000000026![]() .
.
Проверка на гомоскедастичность по методу Гольдфельда-Квандта невозможна, так как недостаточно наблюдений (должно быть n>12m) /
Проверим отсутствие автокорреляции остатков. Для этого чаще всего используют критерий Дарбина Уотсона (d-критерий):
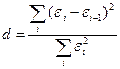 .
.
![]() находится в Microsoft Excel при помощи инструмента "СУММКВРАЗН"
находится в Microsoft Excel при помощи инструмента "СУММКВРАЗН"
![]() =29,573
=29,573
![]() , берется из таблицы 4.1 "SS"/ "остаток"
, берется из таблицы 4.1 "SS"/ "остаток"
![]() 14,374
14,374
d=![]() .
.
Критерий Дарбина Уотсона (d-критерий): n=12, m=1, ![]() , dl=0,97,du=1,33
, dl=0,97,du=1,33
![]() I dl II du III IV 4-du V 4-dl VI
I dl II du III IV 4-du V 4-dl VI
0 0,97 1,33 2 2,67 3,03 4
d=2,057![]() III, IV. Значит нет оснований отклонить предположение об отсутствии автокорреляции соседних остатков по d-критерию с уровнем значимости
III, IV. Значит нет оснований отклонить предположение об отсутствии автокорреляции соседних остатков по d-критерию с уровнем значимости ![]() . Следующее необходимое условие: остатки должны иметь распределение Гаусса. можно ограничиться критерием размахов (RS - критерий).
. Следующее необходимое условие: остатки должны иметь распределение Гаусса. можно ограничиться критерием размахов (RS - критерий).
 .
.
![]() -стандартная ошибка модели
-стандартная ошибка модели
![]() =1,263784889.
=1,263784889.
![]() находится в Microsoft Excel при помощи функции "МАКС".
находится в Microsoft Excel при помощи функции "МАКС".
![]() =.2,280183127
=.2,280183127
![]() находится в Microsoft Excel при помощи функции "МИН".
находится в Microsoft Excel при помощи функции "МИН".
![]() =-1,790955196
=-1,790955196
RS=3,22138
Критерий размахов, RS - критерий: n=12, α =0,05, a=2,8, b=3,91.
Если a <RS < b, то остатки имеют нормальный закон распределения с уровнем α =0,05.
2,8 <3,22138 < 3,91.
Вывод: Все предпосылки регрессионного анализа выполняются с уровнем α =0,05. Значит модель успешно прошла проверку оценки ее качества.
3. Предложить модели тренда изучаемого показателя. Оценить качество моделей
Линейный тренд у показателя связан с ситуацией, когда наибольшим является коэффициент автокорреляции первого порядка.
![]() >0,7, при это
>0,7, при это ![]() , где a,b
, где a,b![]() R.
R.
При выборе модели тренда нельзя выбирать функцию тренда с числом параметров при факторе время больше шестой части n, то есть m>![]() .
.
Существует несколько видов тренда (линейный, полиномиальный, степенной, логарифмический, гиперболический). Из них необходимо выбрать наилучший вид тренда.
Построим графики основных типов тренда. Для выявления наилучшего уравнения тренда определим параметры трендов. Результаты расчетов представим в таблице 9. Согласно, данным этой таблицы наилучшей моделью тренда является полиномиальный тренд, для которого значение коэффициента детерминации наиболее высокое.
График 3. Линейный тренд.
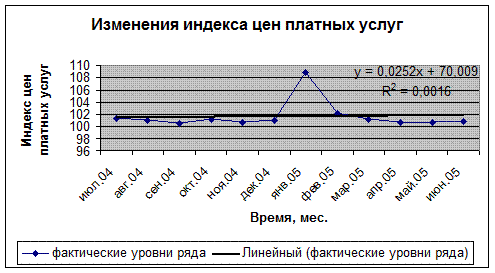
График 4. Полиномиальный тренд.
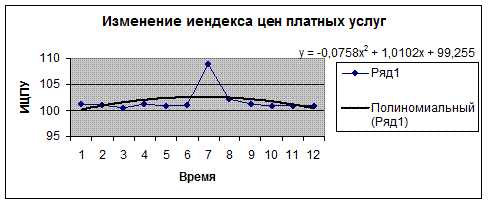
График 5. Степенной тренд.
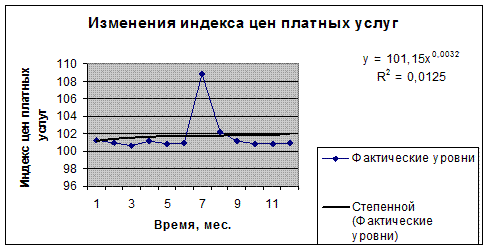
График 6. Экспоненциальный тренд.
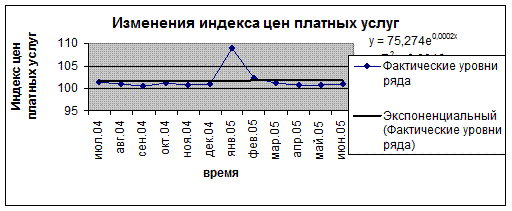
Таблица 9.
| Тип тренда |
Уравнение |
|
| Линейный |
|
0,0016 |
| Полиномиальный |
|
0,1371 |
| Степенной |
|
0,0125 |
| Экспоненциальный |
|
0,0016 |
Итак, рассмотрим модель тренда![]() . Но у показателя Y явно нет никакой тенденции (тренда), так как для
. Но у показателя Y явно нет никакой тенденции (тренда), так как для ![]()
![]() =0.1371<0,3. Модель неудачна.
=0.1371<0,3. Модель неудачна.
4. Используя значимые в целом и по параметрам модели (с приемлемым уровнем значимости), для которых выполняются все предпосылки метода наименьших квадратов (свойств остатков), получит прогнозы изучаемого показателя на два следующих месяца.
Модели ![]() ,
, ![]() значимы в целом и по параметрам и для них выполняются все предпосылки МНК. По этим моделям можно строить прогнозы изучаемого показателя. Различают точечный и доверительный прогнозы показателя. Точечный прогноз получают путем подстановки в уравнение регрессии значения фактора x, и он имеет нулевую вероятность. Этот прогноз полезен при формировании доверительного прогноза.
значимы в целом и по параметрам и для них выполняются все предпосылки МНК. По этим моделям можно строить прогнозы изучаемого показателя. Различают точечный и доверительный прогнозы показателя. Точечный прогноз получают путем подстановки в уравнение регрессии значения фактора x, и он имеет нулевую вероятность. Этот прогноз полезен при формировании доверительного прогноза.
Пусть в модели ![]() Х5 в последующих два будет увеличиваться на столько на сколько и в прошлом месяце 1,7% (в% к предыдущему периоду). Значит Х5 в следующем периоде уменьшится на 1%.
Х5 в последующих два будет увеличиваться на столько на сколько и в прошлом месяце 1,7% (в% к предыдущему периоду). Значит Х5 в следующем периоде уменьшится на 1%.
![]() 1,017*101,69
1,017*101,69![]() 103,41
103,41
![]() 55,68+0,453*103,41=102,52.
55,68+0,453*103,41=102,52.
Доверительная вероятность равна 95%
![]()
где 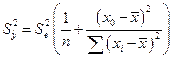
![]()
![]() =1,59,
=1,59, ![]() =0,55, тогда
=0,55, тогда
102,52-5,12*0,55≤![]() ≤102,52+5,12*0,55
≤102,52+5,12*0,55
99,704≤![]() ≤105,33.
≤105,33.
4. Сравнить полученные прогнозы показателей с фактическими данными
Получили, что в последующих двух месяцах изучаемый показатель будет колебаться в интервале от 99,704 до 105,33.
В июле ![]() 0,99*101,69
0,99*101,69![]() 100,67
100,67
![]() 55,68+0,453*100,67=101
55,68+0,453*100,67=101![]() 100,9 (как и фактические данные).
100,9 (как и фактические данные).
В августе![]() 0,98*101,69
0,98*101,69![]() 99,65
99,65
![]() 55,68+0,453*99,65
55,68+0,453*99,65![]() 100,82 (как и фактические данные)
100,82 (как и фактические данные)