| Похожие рефераты | Скачать .docx | Скачать .pdf |
Реферат: Курсовая Работа - Аппроксимация функций
Министерство образования Российской Федерации
Санкт-Петербургский государственный горный институт им. Г.В. Плеханова
(технический университет)
КУРСОВАЯ РАБОТА
По дисциплине ИНФОРМАТИКА
(наименование учебной дисциплины согласно учебному плану)
ПОЯСНИТЕЛЬНАЯ ЗАПИСКА
Тема: Аппроксимация функций методом наименьших квадратов
Автор: студент гр. ИЗ-99-1 /________________/ Брук Б.М. (подпись) (Ф.И.О.)
ОЦЕНКА: _____________
Дата: ___________________
ПРОВЕРИЛ
Руководитель проекта ст. преподаватель /________________/ Быкова Е.В.
(должность) (подпись) (Ф.И.О.)
Санкт-Петербург
2000 год
| Министерство образования Российской Федерации Санкт-Петербургский государственный горный институт им. Г.В. Плеханова (технический университет) |
|
| УТВЕРЖДАЮ Заведующий кафедрой /______________/ доц. /Прудинский Г.А./ "___"__________2000 г. |
|
Кафедра Информатики и компьютерных технологий
КУРСОВАЯ РАБОТА
По дисциплине ИНФОРМАТИКА
(наименование учебной дисциплины согласно учебному плану)
ЗАДАНИЕ
Студенту группы ИЗ-99-1 Брук Б.М.
(шифр группы) (Ф.И.О.)
1. Тема проекта: Использование информационных технологий для решения прикладных задач на примере построения аппроксимации функции методом наименьших квадратов.
2. Исходные данные к проекту: Вариант №22, Задана таблица значений двух наблюдаемых переменных «X» и «Y».
3. Содержание пояснительной записки: Пояснительная записка включает в себя задание на выполнение работы, титульный лист, аннотацию, оглавление, введение, собственно тест пояснительной записки, выводы, библиографический список.
4. Перечень графического материала: Представление результатов в виде графиков, блок-схема.
5. Срок сдачи законченного проекта: 1.12.00
Руководитель проекта ст. преподаватель /_______________/ Быкова Е.В. (должность) (подпись) (Ф.И.О.)
Дата выдачи задания: 7.09.00
Санкт-Петербург
2000 год
Аннотация.
Пояснительная записка представляет собой отчет о выполнении курсовой работы. В ней рассматриваются вопросы по получению эмпирических формул методом наименьших квадратов (МНК). Расчеты проведены средствами пакета Microsoft Excel, в Turbo Pascal 7.0.
Страниц - 32, таблиц - 8, рис.5.
The Summary
The explanatory note presents a report: in which we discuss questions of the construction of the empirical formulas using method of the least squares in Microsoft Excel. Also this task is presented in Turbo Pascal 7.0.
Pages - 32, tables - 8, pic.5.
Оглавление.
Введение. 4
1. Постановка задачи. 6
2. Расчетные формулы. 7
2.1 Построение эмпирических формул методом наименьших квадратов. 7
2.2 Линеаризация экспоненциальной зависимости. 9
2.3 Элементы теории корреляции. 10
3. Расчет коэффициентов аппроксимации в Microsoft Excel. 13
4. Построение графиков в Excel и использование функции ЛИНЕЙН. 21
5. Программа на языке Pascal. 24
5.1. Блок-схема. 24
5.2. Результаты расчета Pascal. 29
Заключение. 30
Список литературы. 31
Введение.
Аппроксимация (от латинского "approximate" -"приближаться")- приближенное выражение каких-либо математических объектов (например, чисел или функций) через другие более простые, более удобные в пользовании или просто более известные. В научных исследованиях аппроксимация применяется для описания, анализа, обобщения и дальнейшего использования эмпирических результатов.
Как известно, между величинами может существовать точная (функциональная) связь, когда одному значению аргумента соответствует одно определенное значение, и менее точная (корреляционная) связь, когда одному конкретному значению аргумента соответствует приближенное значение или некоторое множество значений функции, в той или иной степени близких друг к другу. При ведении научных исследований, обработке результатов наблюдения или эксперимента обычно приходиться сталкиваться со вторым вариантом. При изучении количественных зависимостей различных показателей, значения которых определяются эмпирически, как правило, имеется некоторая их вариабельность. Частично она задается неоднородностью самих изучаемых объектов неживой и, особенно, живой природы, частично обуславливается погрешностью наблюдения и количественной обработке материалов. Последнюю составляющую не всегда удается исключить полностью, можно лишь минимизировать ее тщательным выбором адекватного метода исследования и аккуратностью работы. Поэтому при выполнении любой научно-исследовательской работы возникает проблема выявления подлинного характера зависимости изучаемых показателей, этой или иной степени замаскированных неучтенностью вариабельности значений. Для этого и применяется аппроксимация - приближенное описание корреляционной зависимости переменных подходящим уравнением функциональной зависимости, передающим основную тенденцию зависимости (или ее "тренд").
При выборе аппроксимации следует исходить из конкретной задачи исследования. Обычно, чем более простое уравнение используется для аппроксимации, тем более приблизительно получаемое описание зависимости. Поэтому важно считывать, насколько существенны и чем обусловлены отклонения конкретных значений от получаемого тренда. При описании зависимости эмпирически определенных значений можно добиться и гораздо большей точности, используя какое-либо более сложное, много параметрическое уравнение. Однако нет никакого смысла стремиться с максимальной точностью передать случайные отклонения величин в конкретных рядах эмпирических данных. Гораздо важнее уловить общую закономерность, которая в данном случае наиболее логично и с приемлемой точностью выражается именно двухпараметрическим уравнением степенной функции. Таким образом, выбирая метод аппроксимации, исследователь всегда идет на компромисс: решает, в какой степени в данном случае целесообразно и уместно «пожертвовать» деталями и, соответственно, насколько обобщенно следует выразить зависимость сопоставляемых переменных. Наряду с выявлением закономерностей, замаскированных случайными отклонениями эмпирических данных от общей закономерности, аппроксимация позволяет также решать много других важных задач: формализовать найденную зависимость; найти неизвестные значения зависимой переменной путем интерполяции или, если это допустимо, экстраполяции.
1. Постановка задачи.
Во всех вариантах требуется:
1. Используя метод наименьших квадратов функцию , заданную таблично, аппроксимировать
а) многочленом первой степени ;
б) многочленом второй степени ;
в) экспоненциальной зависимостью .
2. Для каждой зависимости вычислить коэффициент детерминированности.
3. Вычислить коэффициент корреляции (только в случае а).
4. Для каждой зависимости построить линию тренда.
5. Используя функцию ЛИНЕЙН вычислить числовые характеристики зависимости y от x .
6. Сравнить свои вычисления с результатами, полученными при помощи функции ЛИНЕЙН.
7. Сделать вывод, какая из полученных формул наилучшим образом аппроксимирует функцию .
8. Написать программу на одном из языков программирования и сравнить результаты счета с полученными выше.
2. Расчетные формулы.
2.1 Построение эмпирических формул методом наименьших квадратов
Очень часто, особенно при анализе эмпирических данных возникает необходимость найти в явном виде функциональную зависимость между величинами x и y , которые получены в результате измерений.
При аналитическом исследовании взаимосвязи между двумя величинами x и y производят ряд наблюдений и в результате получается таблица значений:
| x |
¼ |
¼ |
| y |
¼ |
¼ |
Эта таблица обычно получается как итог каких-либо экспериментов, в которых (независимая величина) задается экспериментатором, а получается в результате опыта. Поэтому эти значения будем называть эмпирическими или опытными значениями.
Между величинами x и y существует функциональная зависимость, но ее аналитический вид обычно неизвестен, поэтому возникает практически важная задача - найти эмпирическую формулу
(2.1.1)
(где - параметры), значения которой при возможно мало отличались бы от опытных значений .
Обычно указывают класс функций (например, множество линейных, степенных, показательных и т.п.) из которого выбирается функция , и далее определяются наилучшие значения параметров.
Если в эмпирическую формулу (2.1.1) подставить исходные , то получим теоретические значения , где .
Разности называются отклонениями и представляют собой расстояния по вертикали от точек до графика эмпирической функции.
Согласно методу наименьших квадратов наилучшими коэффициентами считаются те, для которых сумма квадратов отклонений найденной эмпирической функции от заданных значений функции
(2.1.2)
будет минимальной.
Поясним геометрический смысл метода наименьших квадралтов.
Каждая пара чисел из исходной таблицы определяет точку на плоскости . Используя формулу (2.1.1) при различных значениях коэффициентов можно построить ряд кривых, которые являются графиками функции (2.1.1). Задача состоит в определении коэффициентов таким образом, чтобы сумма квадратов расстояний по вертикали от точек до графика функции (2.1.1) была наименьшей.
Построение эмпирической формулы состоит из двух этапов: выяснение общего вида этой формулы и определение ее наилучших параметров.
Если неизвестен характер зависимости между данными величинами x и y , то вид эмпирической зависимости является произвольным. Предпочтение отдается простым формулам, обладающим хорошей точностью. Удачный выбор эмпирической формулы в значительной мере зависит от знаний исследователя в предметной области, используя которые он может указать класс функций из теоретических соображений. Большое значение имеет изображение полученных данных в декартовых или в специальных системах координат (полулогарифмической, логарифмической и т.д.). По положению точек можно примерно угадать общий вид зависимости путем установления сходства между построенным графиком и образцами известных кривых.
Определение наилучших коэффициентов входящих в эмпирическую формулу производят хорошо известными аналитическими методами.
Для того, чтобы найти набор коэффициентов , которые доставляют минимум функции S , определяемой формулой (2.1.2), используем необходимое условие экстремума функции нескольких переменных - равенство нулю частных производных. В результате получим нормальную систему для определения коэффициентов :
(2.1.3)
Таким образом, нахождение коэффициентов сводится к решению системы (2.1.3).
Эта система упрощается, если эмпирическая формула (2.1.1) линейна относительно параметров , тогда система (2.1.3) - будет линейной.
Конкретный вид системы (2.1.3) зависит от того, из какого класса эмпирических формул мы ищем зависимость (2.1.1). В случае линейной зависимости система (2.1.3) примет вид:
 (2.1.4)
(2.1.4)
Эта линейная система может быть решена любым известным методом (методом Гаусса, простых итераций, формулами Крамера).
В случае квадратичной зависимости система (2.1.3) примет вид:
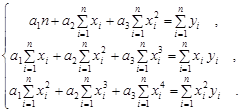 (2.1.5)
(2.1.5)
2.2 Линеаризация экспоненциальной зависимости.
В ряде случаев в качестве эмпирической формулы берут функцию в которую неопределенные коэффициенты входят нелинейно. При этом иногда задачу удается линеаризовать, т.е. свести к линейной. К числу таких зависимостей относится экспоненциальная зависимость
(2.2.1)
где и неопределенные коэффициенты.
Линеаризация достигается путем логарифмирования равенства (2.2.1), после чего получаем соотношение
(2.2.2)
Обозначим и соответственно через и , тогда зависимость (2.2.1) может быть записана в виде , что позволяет применить формулы (2.1.4) с заменой на и на .
2.3 Элементы теории корреляции.
График восстановленной функциональной зависимости по результатам измерений называется кривой регрессии. Для проверки согласия построенной кривой регрессии с результатами эксперимента обычно вводят следующие числовые характеристики: коэффициент корреляции (линейная зависимость), корреляционное отношение и коэффициент детерминированности. При этом результаты обычно группируют и представляют в форме корреляционной таблицы. В каждой клетке этой таблицы приводятся численности тех пар , компоненты которых попадают в соответствующие интервалы группировки по каждой переменной. Предполагая длины интервалов группировки (по каждой переменной) равными между собой, выбирают центры (соответственно ) этих интервалов и числа в качестве основы для расчетов.
Коэффициент корреляции является мерой линейной связи между зависимыми случайными величинами: он показывает, насколько хорошо в среднем может быть представлена одна из величин в виде линейной функции от другой.
Коэффициент корреляции вычисляется по формуле:
, (2.3.1)
где , и ¾ среднее арифметическое значение соответственно по x и y.
Коэффициент корреляции между случайными величинами по абсолютной величине не превосходит 1. Чем ближе к 1, тем теснее линейная связь между x и y.
В случае нелинейной корреляционной связи условные средние значения располагаются около кривой линии. В этом случае в качестве характеристики силы связи рекомендуется использовать корреляционное отношение, интерпретация которого не зависит от вида исследуемой зависимости.
Корреляционное отношение вычисляется по формуле:
, (2.3.2)
где , а числитель характеризует рассеяние условных средних около безусловного среднего .
Всегда . Равенство соответствует некоррелированным случайным величинам; тогда и только тогда, когда имеется точная функциональная связь между y и x. В случае линейной зависимости y от x корреляционное отношение совпадает с квадратом коэффициента корреляции. Величина используется в качестве индикатора отклонения регрессии от линейной.
Корреляционное отношение является мерой корреляционной связи y с x в какой угодно форме, но не может дать представления о степени приближенности эмпирических данных к специальной форме. Чтобы выяснить насколько точно построенная кривая отражает эмпирические данные вводится еще одна характеристика ¾ коэффициент детерминированности.
Для его описания рассмотрим следующие величины. - полная сумма квадратов, где среднее значение .
Можно доказать следующее равенство
.
Первое слагаемое равно и называется остаточной суммой квадратов. Оно характеризует отклонение экспериментальных данных от теоретических.
Второе слагаемое равно и называется регрессионной суммой квадратов и оно характеризует разброс данных.
Очевидно, что справедливо следующее равенство .
Коэффициент детерминированности определяется по формуле:
. (2.3.3)
Чем меньше остаточная сумма квадратов по сравнению с общей суммой квадратов, тем больше значение коэффициента детерминированности , который показывает, насколько хорошо уравнение, полученное с помощью регрессионного анализа, объясняет взаимосвязи между переменными. Если он равен 1, то имеет место полная корреляция с моделью, т.е. нет различия между фактическим и оценочным значениями y. В противоположном случае, если коэффициент детерминированности равен 0, то уравнение регрессии неудачно для предсказания значений y.
Коэффициент детерминированности всегда не превосходит корреляционное отношение. В случае когда выполняется равенство то можно считать, что построенная эмпирическая формула наиболее точно отражает эмпирические данные.
3. Расчет коэффициентов аппроксимации в Microsoft Excel.
Вариант №22
Функция y=f(x) задана таблицей 1
Таблица 1
Исходные данные.
| 12.85 |
154.77 |
9.65 |
81.43 |
7.74 |
55.86 |
5.02 |
24.98 |
1.86 |
3.91 |
| 12.32 |
145.59 |
9.63 |
80.97 |
7.32 |
47.63 |
4.65 |
22.87 |
1.76 |
3.22 |
| 11.43 |
108.37 |
9.22 |
79.04 |
7.08 |
48.03 |
4.53 |
20.32 |
1.11 |
1.22 |
| 10.59 |
100.76 |
8.44 |
61.76 |
6.87 |
36.85 |
3.24 |
9.06 |
0.99 |
1.10 |
| 10.21 |
98.32 |
8.07 |
60.54 |
5.23 |
25.65 |
2.55 |
6.23 |
0.72 |
0.53 |
Требуется выяснить - какая из функций - линейная, квадратичная или экспоненциальная наилучшим образом аппроксимирует функцию заданную таблицей 1.
Решение.
Поскольку в данном примере каждая пара значений встречается один раз, то между и существует функциональная зависимость.
Для проведения расчетов данные целесообразно расположить в виде таблицы 2, используя средства табличного процессора Microsoft Excel.
Таблица 2

Расчет сумм.
Поясним как таблица 2 составляется.
Шаг 1. В ячейки A2:A26 заносим значения .
Шаг 2. В ячейки B2:B26 заносим значения .
Шаг 3. В ячейку C2 вводим формулу =A2^2.
Шаг 4. В ячейки C3:C26 эта формула копируется.
Шаг 5. В ячейку D2 вводим формулу =A2*B2.
Шаг 6. В ячейки D3:D26 эта формула копируется.
Шаг 7. В ячейку F2 вводим формулу =A2^4.
Шаг 8. В ячейки F3:F26 эта формула копируется.
Шаг 9. В ячейку G2 вводим формулу =A2^2*B2.
Шаг 10. В ячейки G3:G26 эта формула копируется.
Шаг 11. В ячейку H2 вводим формулу =LN(B2).
Шаг 12. В ячейки H3:H26 эта формула копируется.
Шаг 13. В ячейку I2 вводим формулу =A2*LN(B2).
Шаг 14. В ячейки I3:I26 эта формула копируется.
Последующие шаги делаем с помощью автосуммирования .
Шаг 15. В ячейку A27 вводим формулу =СУММ(A2:A26).
Шаг 16. В ячейку B27 вводим формулу =СУММ(B2:B26).
Шаг 17. В ячейку C27 вводим формулу =СУММ(C2:C26).
Шаг 18. В ячейку D27 вводим формулу =СУММ(D2:D26).
Шаг 19. В ячейку E27 вводим формулу =СУММ(E2:E26).
Шаг 20. В ячейку F27 вводим формулу =СУММ(F2:F26).
Шаг 21. В ячейку G27 вводим формулу =СУММ(G2:G26).
Шаг 22. В ячейку H27 вводим формулу =СУММ(H2:H26).
Шаг 23. В ячейку I27 вводим формулу =СУММ(I2:I26).
Аппроксимируем функцию линейной функцией . Для определения коэффициентов и воспользуемся системой
Используя итоговые суммы таблицы 2, расположенные в ячейках A27, B27, C27 и D27, запишем систему в виде
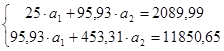
решив которую, получим ![]() и
и ![]() .
.
Таким образом, линейная аппроксимация имеет вид ![]() .
.
Решение системы проводили, пользуясь средствами Microsoft Excel. Результаты представлены в таблице 3.
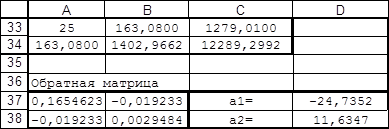 |
Таблица 3
Результаты коэффициентов линейной аппроксимации.
В таблице 3 в ячейках A37:B38 записана формула {=МОБР(A33:B34)}.
В ячейках D37:D38 записана формула {=МУМНОЖ(A37:B38;C33:C34)}.
Далее аппроксимируем функцию квадратичной функцией . Для определения коэффициентов , и воспользуемся системой
Используя итоговые суммы таблицы 2,
расположенные в ячейках A27, B27, C27, D27, E27, F27 и G27 запишем систему в виде

решив которую, получим ![]() ,
, ![]() и
и ![]() .
.
Таким образом, квадратичная аппроксимация имеет вид
![]() .
.
Решение системы проводили, пользуясь средствами Microsoft Excel. Результаты представлены в таблице 4.
 |
Таблица 4
Результаты коэффициентов квадратичной аппроксимации.
В таблице 4 в ячейках E38:G40 записана формула {=МОБР(E33:G35)}.
В ячейках I38:I40 записана формула {=МУМНОЖ(E38:G40;H33:H35)}.
Теперь аппроксимируем функцию экспоненциальной функцией . Для определения коэффициентов и прологарифмируем значения и используя итоговые суммы таблицы 2, расположенные в ячейках A27, C27, H27 и I27 получим систему

где .
Решив систему, найдем ![]() ,
, ![]() .
.
После потенцирования получим ![]() .
.
Таким образом, экспоненциальная аппроксимация имеет вид
![]() .
.
Решение системы проводили, пользуясь средствами Microsoft Excel. Результаты представлены в таблице 5.
Таблица 5
 |
Результаты коэффициентов экспоненциальной аппроксимации.
В таблице 5 в ячейках D45:E46 записана формула {=МОБР(D42:943)}.
В ячейках G45:G46 записана формула {=МУМНОЖ(D45:E46;F42:F43)}.
В ячейке G47 записана формула =EXP(G45).
Вычислим среднее арифметическое и по формулам:
Результаты расчета и средствами Microsoft Excel представлены в таблице 6.
Таблица 6
 |
Вычисление средних значений X и Y.
В ячейке F49 записана формула =A26/25.
В ячейке F50 записана формула =B26/25.
Для того, чтобы рассчитать коэффициент корреляции и коэффициент детерминированности данные целесообразно расположить в виде таблицы 7, которая является продолжением таблицы 2.
Таблица 7

Вычисление остаточных сумм.
Поясним как таблица 7 составляется.
Ячейки A2:A27 и B2:B27 уже заполнены (см. табл. 2).
Далее делаем следующие шаги.
Шаг 1. В ячейку J2 вводим формулу =(A2-$F$49)*(B2-$F$50).
Шаг 2. В ячейки J3:J26 эта формула копируется.
Шаг 3. В ячейку K2 вводим формулу =(A2-$F$49)^2.
Шаг 4. В ячейки K3:K26 эта формула копируется.
Шаг 5. В ячейку L2 вводим формулу =(B2-$F$50)^2.
Шаг 6. В ячейки L3:L26 эта формула копируется.
Шаг 7. В ячейку M2 вводим формулу =($D$37+$D$38*A2-B2)^2.
Шаг 8. В ячейки M3:M26 эта формула копируется.
Шаг 9. В ячейку N2 вводим формулу
=($I$38+$I$39*A2+$I$40*A2^2-B2)^2.
Шаг 10. В ячейки N3:N26 эта формула копируется.
Шаг 11. В ячейку O2 вводим формулу
=($G$47*EXP($G$46*A2)-B2)^2.
Шаг 12. В ячейки O3:O26 эта формула копируется.
Последующие шаги делаем с помощью автосуммирования .
Шаг 13. В ячейку J27 вводим формулу =СУММ(J2:J26).
Шаг 14. В ячейку K27 вводим формулу =СУММ(K2:K26).
Шаг 15. В ячейку L27 вводим формулу =СУММ(L2:L26).
Шаг 16. В ячейку M27 вводим формулу =СУММ(M2:M26).
Шаг 17. В ячейку N27 вводим формулу =СУММ(N2:N26).
Шаг 18. В ячейку O27 вводим формулу =СУММ(O2:O26).
Теперь проведем расчеты коэффициента корреляции по формуле
(только для линейной аппроксимации)
и коэффициента детерминированности по формуле . Результаты расчетов средствами Microsoft Excel представлены в таблице 8.
Таблица 8
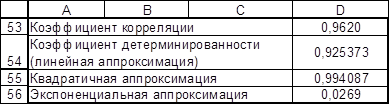 |
Результаты расчета.
В таблице 8 в ячейке D53 записана формула =J27/(K27*L27)^(1/2).
В ячейке D54 записана формула =1- M27/L27.
В ячейке D55 записана формула =1- N27/L27.
В ячейке D56 записана формула =1- O27/L27.
Анализ результатов расчетов показывает, что квадратичная аппроксимация наилучшим образом описывает экспериментальные данные.
4. Построение графиков в Excel и использование функции ЛИНЕЙН.
Рассмотрим результаты эксперимента, приведенные в исследованном выше примере.
Исследуем характер зависимости в три этапа:
· Построим график зависимости.
· Построим линию тренда (![]() ,
, ![]() ,
, ![]() ).
).
· Получим числовые характеристики коэффициентов этого уравнения.

Рис.4.1. График зависимости
y от
x

Рис.4.2. График линейной аппроксимации

Рис.4.3. График квадратичной аппроксимации.

Рис.4.4. График экспоненциальной аппроксимации.
Примечание:
Полученное при построении линии тренда значение коэффициента детерминированности для экспоненциальной зависимости ![]() не совпадает с истинным значением
не совпадает с истинным значением ![]() , поскольку при вычислении коэффициента детерминированности используются не истинные значения , а преобразованные значения с дальнейшей линеаризацией.
, поскольку при вычислении коэффициента детерминированности используются не истинные значения , а преобразованные значения с дальнейшей линеаризацией.
 |
5. Программа на языке Pascal.
 |
5.1. Схема алгоритма.
 |
Рис.5.1. Блок-схема
program Kramer;
uses CRT;
const
n=25;
type
TArrayXY = array[1..2,1..n] of real;
TArray = array[1..n] of real;
var
SumX,SumY,SumX2,SumXY,SumX3,SumX4,SumX2Y,SumLnY,SumXLnY: real;
OPRlin,OPRkvadr,OPRa1,OPRa2,OPRa3:real;
a1lin,a2lin,a1kvadr,a2kvadr,a3kvadr,a1exp,a2exp,cexp:real;
Xsr,Ysr,S1,S2,S3,Slin,Skvadr,Sexp:real;
Kkor,KdetLin,KdetKvadr,KdetExp:real;
i:byte;
const
ArrayXY:TArrayXY=((12.85,12.32,11.43,10.59,10.21,9.65,9.63,9.22,8.44,8.07,7.74,7.32,7.08,6.87,5.23,5.02,4.65,4.53,3.24,2.55,1.86,1.76,1.11,0.99,0.72) , (154.77
145.59,108.37,100.76,98.32,81.43,80.97,79.04,61.76,60.54,55.86,47.63,48.03,36.85,25.65,24.98,22.87,20.32,9.06,6.23,3.91,3.22,1.22,1.10,0.53));
begin
ClrScr;
SumX:=0.0;
SumY:=0.0;
SumXY:=0.0;
SumX2:=0.0;
SumX3:=0.0;
SumX4:=0.0;
SumX2Y:=0.0;
SumLnY:=0.0;
SumXLnY:=0.0;
{ Вычисление сумм x, y, x*y, x^2, x^3, x^4, (x^2)*y, Ln(y), x*Ln(y) }
for i:=1 to n do
begin
SumX:=SumX+ArrayXY[1,i];
SumY:=SumY+ArrayXY[2,i];
SumXY:=SumXY+ArrayXY[1,i]*ArrayXY[2,i];
SumX2:=SumX2+sqr(ArrayXY[1,i]);
SumX3:=SumX3+ArrayXY[1,i]*ArrayXY[1,i]*ArrayXY[1,i];
SumX4:=SumX4+sqr(ArrayXY[1,i])*sqr(ArrayXY[1,i]);
SumX2Y:=SumX2Y+sqr(ArrayXY[1,i])*ArrayXY[2,i];
SumLnY:=SumLnY+ln(ArrayXY[2,i]);
SumXLnY:=SumXLnY+ArrayXY[1,i]*ln(ArrayXY[2,i])
end;
{ Вычисление коэффициентов }
OPRlin:=0.0;
a1lin:=0.0;
a2lin:=0.0;
a1kvadr:=0.0;
OPRkvadr:=0.0;
a2kvadr:=0.0;
a2kvadr:=0.0;
a1exp:=0.0;
a2exp:=0.0;
OPRlin:=n*SumX2-SumX*SumX;
a1lin:=(SumX2*SumY-SumX*SumXY)/OPRlin;
a2lin:=(n*SumXY-SumX*SumY)/OPRlin;
OPRkvadr:=n*SumX2*SumX4+SumX*SumX3*SumX2+SumX2*SumX*SumX3- SumX2*SumX2*SumX2-n*SumX3*SumX3-SumX*SumX*SumX4;
a1kvadr:=(SumY*SumX2*SumX4+SumX*SumX2Y*SumX3+SumX2*SumXY*SumX3- SumX2*SumX2*SumX2Y-SumY*SumX3*SumX3-SumX*SumXY*SumX4)/OPRkvadr;
a2kvadr:=(n*SumXY*SumX4+SumY*SumX3*SumX2+SumX2*SumX*SumX2Y-SumX2*SumX2*SumXY-n*SumX3*SumX2Y-SumY*SumX*SumX4)/OPRkvadr;
a3kvadr:=(n*SumX2*SumX2Y+SumX*SumXY*SumX2+SumY*SumX*SumX3-SumY*SumX2*SumX2-n*SumXY*SumX3-SumX*SumX*SumX2Y)/OPrkvadr;
a2exp:=(n*SumXLnY-SumX*SumLnY)/OPRlin;
cexp:=(SumX2*SumLnY-SumX*SumXLnY)/OPRlin;
a1exp:=exp(cexp);
{ Вычисление средних арифметических x и y }
Xsr:=SumX/n;
Ysr:=SumY/n;
S1:=0.0;
S2:=0.0;
S3:=0.0;
Slin:=0.0;
Skvadr:=0.0;
Sexp:=0.0;
Kkor:=0.0;
KdetLin:=0.0;
KdetKvadr:=0.0;
KdetExp:=0.0;
for i:=1 to n do
begin
S1:=S1+(ArrayXY[1,i]-Xsr)*(ArrayXY[2,i]-Ysr);
S2:=S2+sqr(ArrayXY[1,i]-Xsr);
S3:=S3+sqr(ArrayXY[2,i]-Ysr);
Slin:=Slin+sqr(a1lin+a2lin*ArrayXY[1,i]-ArrayXY[2,i]);
Skvadr:=Skvadr+sqr(a1kvadr+a2kvadr*ArrayXY[1,i]+a3kvadr*ArrayXY[1,i]*ArrayXY[1,i]-ArrayXY[2,i]);
Sexp:=Sexp+sqr(a1exp*exp(a2exp*ArrayXY[1,i])-ArrayXY[2,i]);
end;
{ Вычисление коэффициентов корреляции и детерминированности }
Kkor:=S1/sqrt(S2*S3);
KdetLin:=1-Slin/S3;
KdetKvadr:=1-Skvadr/S3;
KdetExp:=1-Sexp/S3;
{ Вывод результатов }
WriteLn('Линейная функция');
WriteLn('a1=',a1lin:8:5);
WriteLn('a2=',a2lin:8:5);
WriteLn('Квадратичная функция');
WriteLn('a1=',a1kvadr:8:5);
WriteLn('a2=',a2kvadr:8:5);
WriteLn('a3=',a3kvadr:8:5);
WriteLn('Экспоненциальная функция');
WriteLn('a1=',a1exp:8:5);
WriteLn('a2=',a2exp:8:5);
WriteLn('c=',cexp:8:5);
WriteLn('Xcp=',Xsr:8:5);
WriteLn('Ycp=',Ysr:8:5);
WriteLn('Коэффициент корреляции ',Kkor:8:5);
WriteLn('Коэффициент детерминированности (линейная аппроксимация) ',KdetLin:2:5);
WriteLn('Коэффициент детерминированности (квадратическая аппроксимация) ',KdetKvadr:2:5);
WriteLn('Коэффициент детерминированности (экспоненциальная аппроксимация) ',KdetExp:2:5);
end.
5.2. Результаты расчета Pascal.
Коэффициенты линейной функции
a1=-24.73516
a2=11.63471
Коэффициенты квадратичной функции
a1= 1.59678
a2=-0.62145
a3= 0.95543
Коэффициенты экспоненциальной функции
a1= 1.65885
a2= 0.40987
c= 0.50613
Xcp= 6.52320
Ycp=51.16040
Коэффициент корреляции 0.96196
Коэффициент детерминированности (линейная аппроксимация) 0.92537
Коэффициент детерминированности (квадратическая аппроксимация) 0.99409
Коэффициент детерминированности (экспоненциальная аппроксимация) 0.02691
Заключение.
Сделаем заключение по результатам полученных данных:
1. Анализ результатов расчетов показывает, что квадратичная аппроксимация наилучшим образом описывает экспериментальные данные т.к. согласно таблице 8 коэффициент корреляции - 0,9620; Коэффициенты детерминированности линейной аппроксимации - 0,9253; квадратической аппроксимации – 0,994; экспоненциальной аппроксимация – 0,0269.
2. Сравнивая результаты, полученные при помощи функции ЛИНЕЙН видим что они полностью совпадают с вычислениями, проведенными выше. Это указывает на то, что вычисления верны.
3. Полученное при построении линии тренда значение коэффициента детерминированности для экспоненциальной зависимости не совпадает с истинным значением поскольку при вычислении коэффициента детерминированности используются не истинные значения y, а преобразованные значения ln(y) с дальнейшей линеаризацией.
4. Результаты полученные с помощью программы на языке PASCAL полностью совпадают со значениями приведенными выше. Это говорит о верности вычислений.
Список литературы.
1. Ахметов К.С. Windows 95 для всех. - М.:ТОО "КомпьютерПресс", 1995.
2. Вычислительная техника и программирование. Под ред. А.В. Петрова. М.: Высшая школа, 1991.
3. Гончаров A., Excel 97 в примерах. — СПб: Питер, 1997.
4. Левин А., Самоучитель работы на компьютере. - М.: Международное агентство А.Д.Т., 1996.
5. Информатика: Методические указания к курсовой работе. Санкт-Петербургский горный институт. Сост. Д.Е. Гусев, Г.Н. Журов. СПб, 1999
Похожие рефераты:
Использование возможностей Microsoft Excel в решении производственных задач
Редактирование и отладка программ с помощью Pascal
Билеты на государственный аттестационный экзамен по специальности Информационные Системы
Решение обратной задачи вихретокового контроля
Особенности эконометрического метода
Теория организации и системный анализ
Коммутация в сетях с использованием асинхронного метода переноса и доставки
СИНГУЛЯРНОЕ РАЗЛОЖЕНИЕ В ЛИНЕЙНОЙ ЗАДАЧЕ МЕТОДА НАИМЕНЬШИХ КВАДРАТОВ
Теоретические основы математических и инструментальных методов экономики